このトピックでは、リソーススケジューリングに関連する一般的な問題について説明します。
7. 障害発生時の自動再実行回数が設定されているにもかかわらず、ノードがタイムアウトした後に自動再実行がトリガーされない
9. O&M ページでインスタンスリストを照会すると、「503 Service Temporarily Unavailable」エラーが発生する
11. Python で開発されたトリガーベースのノードから OpenAPI を呼び出すための Python ドキュメントはありますか?
13. アップグレード後、以前は機能していた OpenAPI 呼び出しが「tenantId cannot be empty」エラーで失敗する
14. 通常のスケジューリングが構成されているにもかかわらず、ノードが O&M の自動トリガータスクページで一時停止として表示される
1. リソーススケジューリングダッシュボードにデータが表示されない、または表示時間が更新されない
Prometheus コンポーネントがインストールされているかどうか、および Prometheus への接続が正常かどうかを確認します。
Prometheus コンポーネントがインストールされていない場合は、Dataphin デプロイメントチームに連絡してください。コンポーネントがインストールされているが、表示時間が古い場合は、Prometheus への接続が異常である可能性があります。トラブルシューティングについては、Dataphin O&M チームに連絡してください。次の手順に従って、接続が異常かどうかを判断することもできます。
Dataphin クラスタにログインします。
kubectl get pods -n dataphin | grep rsコマンドを実行して、rs ポッドを見つけます。kubectl describe pod <pod_name> -n dataphinコマンドを実行して、プライマリ rs ポッドを見つけます。dataphin-rs-scheduler-rpc-serviceラベルのステータスがactiveかどうかを確認します。ステータスがactiveの場合は、プライマリポッドです。ステータスがstandbyの場合は、セカンダリポッドです。kubectl exec -it <pod_name> -n dataphin -- bashコマンドを実行して、プライマリ rs ポッドにログインします。cd /home/admin/logs/dataphin-rsコマンドを実行して、rs ログディレクトリに移動します。Prometheus 接続の異常に関するメッセージについてログを確認します。
grep "failed to connect to" <log_file>コマンドを実行して検索できます。ログにこの情報が含まれている場合、接続は異常です。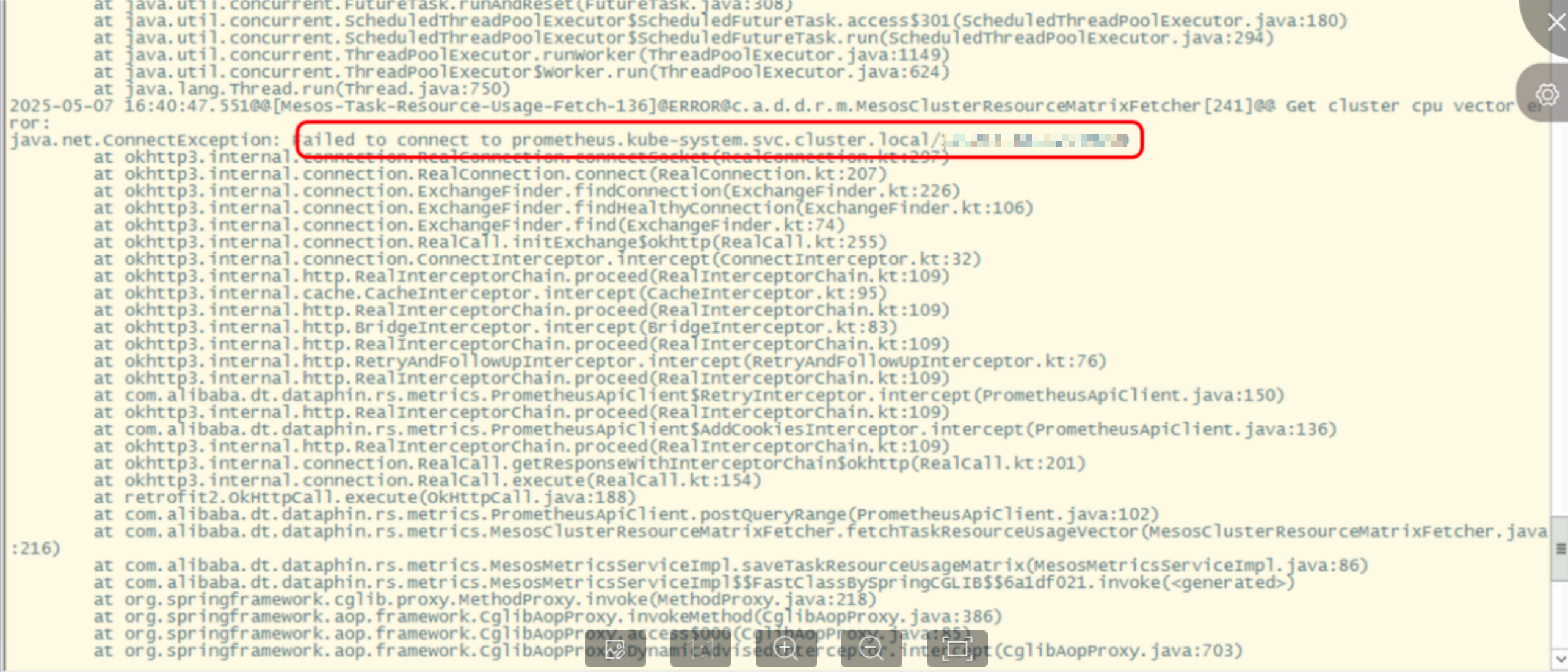
2. ノードが正常に実行された後に再実行される
ノードに上流依存関係があるかどうかを確認します。ある場合、上流ノードの再実行は下流ノードの再実行をトリガーします。
3. [リソース設定] ページが表示されない
<管理センター> > <システム設定> > <リソース設定> ページを表示するには、ライセンスをインポートする必要があります。
4. ノードの実行時に「リソース待機中」メッセージが表示される
次の条件を順番に確認します。
現在のリソースグループで多くのノードが実行されています。
実行時間の長い大きなノードが、リソースグループのリソースを継続的に占有しています。
現在のリソースグループが正しく構成されていません。<管理センター> > <システム設定> > <リソース設定> に移動して、リソースグループを構成できます。
現在のテナントのリソース構成が適切ではありません。現在のテナントのリソース値が変更されると、そのテナントのリソースグループがそれに応じて調整されます。
たとえば、ランタイムログが Sending to agent e405****-****-****-****-****2fc2 のようなメッセージで終わる場合、ノードはスケジューリングクラスタに正常に送信されました。ただし、スケジューリングクラスタがノードポッドを作成しようとしたときに問題が発生した可能性があります。考えられる理由には、次のものがあります。
スケジューリングクラスタに残りのリソースが不足しているため、新しいノードポッドを作成できません。
スケジューリングクラスタに障害が発生している可能性があります。一般的な問題には、ネットワークプラグインまたはクロックの例外が含まれます。
4.1. テナントリソース不足の提案
リソースグループ内の優先度の低いノードを停止して、リソースを解放します。
テナントのリソースグループの割り当て比率を増やします。
ピーク時のリソース競合を防ぐために、オフピークスケジューリングを使用します。
リソースの使用率に基づいて、ノードのリソース構成を最適化します。ノードリソースの使用率は、リソースダッシュボードで確認できます。
4.2. クラスタリソース不足の提案
リソースグループ内の優先度の低いノードを停止して、リソースを解放します。
ピーク時のリソース競合を防ぐために、オフピークスケジューリングを使用します。
リソースの使用率に基づいて、ノードのリソース構成を最適化します。ノードリソースの使用率は、リソースダッシュボードで確認できます。
クラスタリソースをスケールアウトします。
5. 共有ノードの実行時に「リソース待機中」メッセージが表示されるが、リソースは十分にある
リソースが十分にあるにもかかわらず「リソース待機中」メッセージが表示される場合は、共有ノードの同時実行制限が原因である可能性があります。同時実行共有ノードの数が構成済みの制限を超えると、新しいノードはブロックされ、待機状態になります。
同時実行制限は、共有ノードの種類によって異なります。
SQL タイプのデフォルト:デフォルトでは、1 つの共有コンテナポッドが作成されます。1 つの共有コンテナポッドは 200 ノードを同時に実行できます。
Python および Shell タイプのデフォルト:デフォルトでは、1 つの共有コンテナポッドが作成されます。1 つの共有コンテナポッドは 15 ノードを同時に実行できます。
必要に応じて、共有コンテナポッドの数とポッドあたりの同時実行ノードの数を変更できます。
6. ランタイム診断のリソース消費インスタンスは、現在のリソースグループまたは現在のテナントに属していますか?
ランタイム診断のリソース消費インスタンスは、現在のテナントに属しています。
7. 障害発生時の自動再実行回数が設定されているにもかかわらず、ノードがタイムアウトした後に自動再実行がトリガーされない
デフォルトでは、ノードのタイムアウトは、障害発生時の自動再実行をトリガーしません。タイムアウトしたノードの自動再実行を有効にするには、 > <グローバル構成> > <ランタイム構成> > <再実行構成> に移動し、対応するスイッチをオンにします。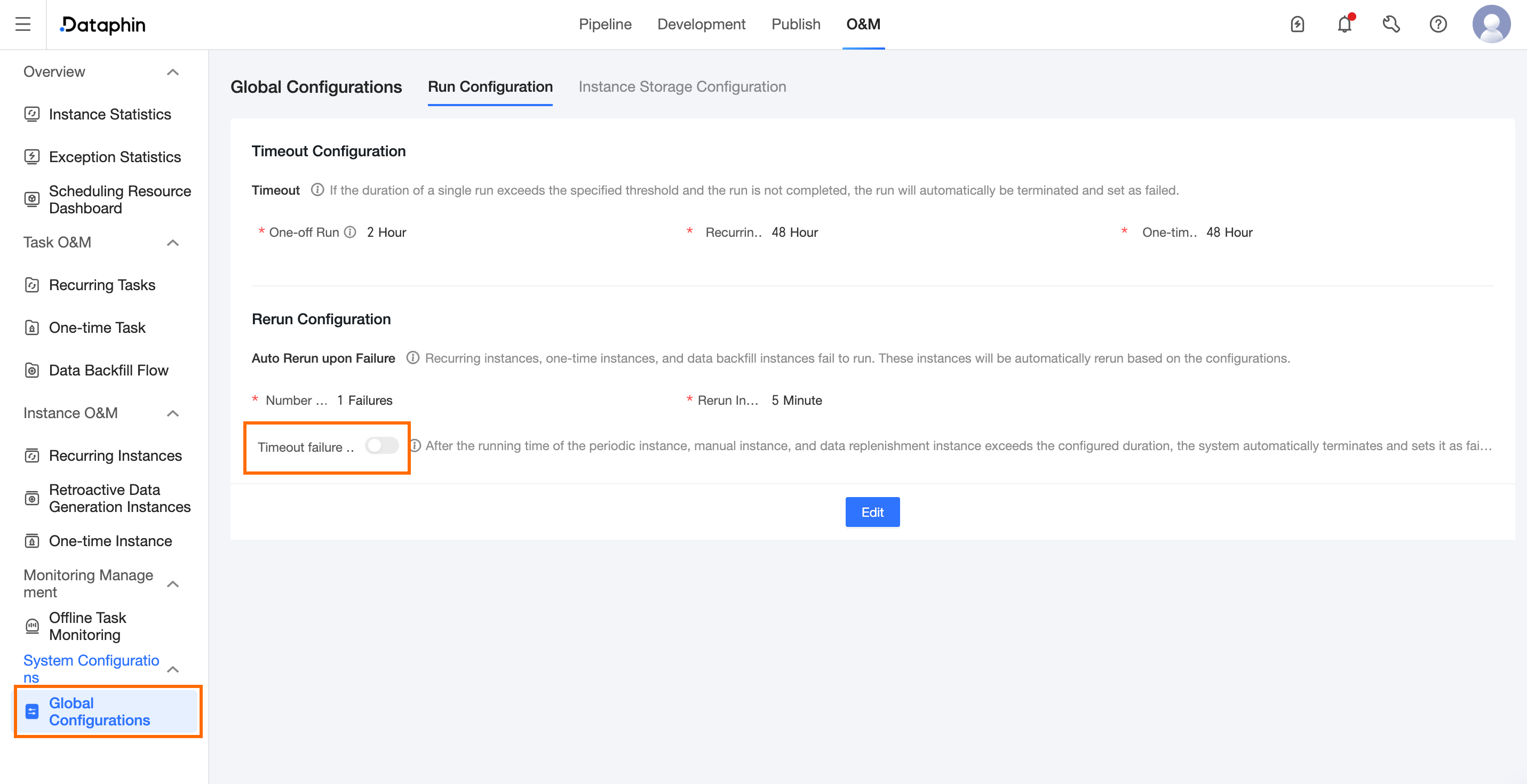
8. オフラインタスクランタイムリソース
オフラインタスクランタイムリソースの詳細については、「ノードランタイムリソース」をご参照ください。
たとえば、各ポッドが 50 ノードを処理する 20 ポッドを起動する Python 共有ノードタイプの場合、必要なリソースは次のように計算できます。
1 つのポッドで消費されるリソースは、ベースリソースとノードリソースで構成されます。ベースリソースは 0.5 コアと 4,096 MB(4 GB)です。デフォルトの Python ノードリソースは 0.1 コアと 256 MB です。したがって、1 つのポッドに必要な合計リソースは 0.6 コアと 4,352 MB です。20 ポッドをデプロイする場合、必要なリソースは 20 × 0.6 コア = 12 コア、20 × 4,352 MB = 87,040 MB(85 GB)です。
9. O&M ページでインスタンスリストを照会すると、「503 Service Temporarily Unavailable」エラーが発生する
まず、リクエストが Web Application Firewall(WAF)によってブロックされているかどうかを確認します。WAF は、SQL インジェクションやクロスサイトスクリプティング(XSS)攻撃などの悪意のあるトラフィックを検出してブロックするために使用されるネットワークセキュリティツールです。
10. ランタイムログのタイムスタンプの順序が正しくない

タイムスタンプの順序は正しくありません。ノードランタイムログは、3 つのステージのログの組み合わせです。中央部分は、サーバーから定期的にポーリングされるログで構成されています。3 つのステージのログは、時間順にソートされていません。
11. Python で開発されたトリガーベースのノードから OpenAPI を呼び出すための Python ドキュメントはありますか?
現在、一部の API のみが Python での開発をサポートしています。これらには、パブリッククラウドで公開されている API と O&M 関連の API が含まれます。
参照:
トリガーベースのノードの概要:Dataphin v4.0:システム間のスケジューリング依存関係はもはや問題ではありません
API ドキュメント:GetInstanceUpDownStream - インスタンスの上流と下流のインスタンスを照会する
トリガーベースのノードを開発するための手順:詳細については、「トリガーベースのノードを開発するための手順」をご参照ください。
12. コメントアウトされたリソースアノテーションが、ノード最適化の推奨事項でカウントされる
コメントアウトされたリソースアノテーションは引き続き有効です。リソースがカウントされないようにするには、アノテーションを完全に削除する必要があります。
13. アップグレード後、以前は機能していた OpenAPI 呼び出しが「tenantId cannot be empty」エラーで失敗する
このエラーは、V3.0 より前のバージョンの Dataphin からアップグレードした場合に発生します。Dataphin V3.x 以降、tenantId パラメーターが必要です。
14. 通常のスケジューリングが構成されているにもかかわらず、ノードが O&M の自動トリガータスクページで一時停止として表示される
ノードが属するプロジェクトの定期スケジューリングが [無効、実行をスキップ] に設定されているかどうかを確認します。設定されている場合は、この設定を [有効、自動スケジュール] に変更します。