ACS クラスターは、複数の GPU Pod を単一の GPU-HPN ノードにスケジューリングすることをサポートしています。これらの Pod は、NVLink などのテクノロジーを使用して GPU 間でデータを転送できます。GPU デバイス間の効率的かつ公平な通信を確保するため、ACS はさまざまなノードタイプのパーティション制約に基づいてデバイスをスケジューリングします。このトピックでは、ACS GPU のパーティションスケジューリングの仕組みについて説明し、シナリオ例を示します。
前提条件
「gpu-hpn」コンピュートクラスと、対応するノードタイプを持つ Pod のみがサポートされます。
背景情報
ノード上の GPU デバイスは、1 つ以上のチャンネルを使用して相互接続し、通信します。ACS は、異なる GPU 要件を持つ Pod を同じ GPU-HPN ノードで実行することをサポートしています。効率的かつ公平な GPU 通信を確保し、Pod 間の相互干渉を防ぐため、ACS は GPU トポロジーに基づいて Pod をスケジューリングします。リクエストされた GPU の数に応じて、ACS はノードの GPU を複数のパーティションに分割し、最適なデバイスセットを割り当てます。
次の図は、8 つの GPU を持つノードを示しています。これらの GPU は 4 つずつ 2 つのグループに配置されています。各グループ内では GPU が直接相互接続されており、グループ間は PCIe を介して接続されています。
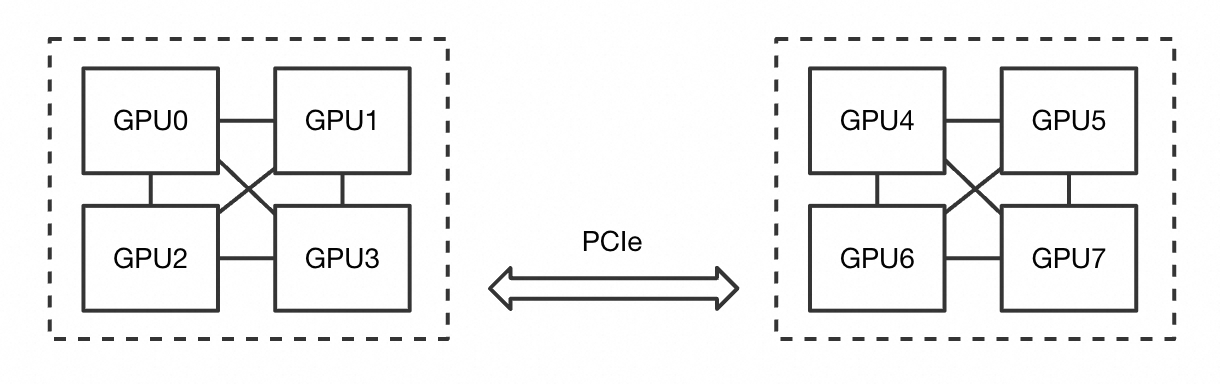
ACS パーティションは、Pod 仕様に基づいて次のように分割されます。
Pod がリクエストする GPU 数 | 考えられるデバイス割り当て結果 |
8 | [0,1,2,3,4,5,6,7] |
4 | [0,1,2,3], [4,5,6,7] |
2 | [0,1], [2,3], [4,5], [6,7] |
1 | [0], [1], [2], [3], [4], [5], [6], [7] |
ノード上で Pod の作成と削除が行われると、GPU デバイスが使用不可能なパーティションに断片化されることがあります。この断片化により、新しい Pod のスケジューリングが妨げられ、Pending 状態のままになる可能性があります。この問題を解決するには、既存の Pod のデバイス割り当てを確認し、ビジネスの優先度に基づいて一部を排除します。これにより、Pending 状態の Pod のためにリソースが解放されます。
GPU-HPN ノードのパーティションの照会
パーティションと GPU カードタイプは、ACS GPU-HPN ノードのモデルによって異なります。
gpu.p16en-16XL
このノードには、P16EN タイプの GPU が 16 基搭載されています。異なる GPU 要件を持つ Pod に対して、パーティションは次のように作成されます。
Pod がリクエストする GPU 数 | デバイス割り当て結果 (オプション) |
16 | [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15] |
8 | [0,1,2,3,4,5,6,7], [8,9,10,11,12,13,14,15] |
4 | [0,1,2,3], [4,5,6,7], [8,9,10,11], [12,13,14,15] |
2 | [0,3], [1,2], [4,7], [5,6], [8,11], [9,10], [12,15], [13,14] |
1 | [0], [1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12], [13], [14], [15] |
Pod のスケジューリング結果の照会
デバイス割り当て結果
GPU-HPN Pod の場合、デバイス割り当て結果は Pod のアノテーションで確認できます。フォーマットは次のとおりです。
apiVersion: v1
kind: Pod
metadata:
annotations:
alibabacloud.com/device-allocation: '{"gpus": {"minor": [0,1,2,3]}}'パーティションの断片化によるスケジューリング失敗メッセージ
Pod がスケジューリングできない場合、Pending 状態のままになります。kubectl describe pod コマンドを実行して、その理由を確認できます。Insufficient Partitioned GPU Devices を含む 0/5 nodes are available: xxx のようなメッセージは、ノード上の GPU リソースの断片化が原因でスケジューリングが失敗したことを示します。以下に例を示します。
kubectl describe pod pod-demo以下は出力例です。他の部分は省略されています。
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 26m default-scheduler 0/5 nodes are available: 2 Node(s) Insufficient Partitioned GPU Devices, 1 Node(s) xxx, 2 Node(s) xxx.よくある質問
パーティションの断片化を回避するためのノードリソースとポリシーの計画方法
ノードに異なるグループタグを設定して、アプリケーション Pod が必要とする GPU の数に基づいてリソースを管理できます。たとえば、8 つの GPU を必要とする大規模なタスクと、1 つの GPU を必要とする小規模なタスクを、それぞれ異なるノードにスケジューリングします。
断片化が原因でクラスター内に Pending 状態の Pod が存在する場合、デスケジューリングなどのメカニズムを使用して、優先度の低いタスクを排除できます。これにより、Pending 状態の Pod のためにリソースが解放されます。
クラスターのノード数が少なく、グループタグを使用した計画ができず、アプリケーションの GPU 要件が多様である場合は、GPU Pod のキャパシティ予約を使用してリソース需要を満たすことができます。
パーティションの断片化を解決するために排除する Pod の選択方法
Pending 状態の Pod のリソース仕様 (例:8 GPU) を特定します。
ターゲットノードで Pod のアノテーションを確認します。デバイス割り当て結果を
alibabacloud.com/device-allocationプロパティで見つけます。割り当て結果に基づいて、排除する Pod を特定します。解放されたデバイスが、Pending 状態の Pod のリソース要件とパーティション制約を満たしていることを確認してください。たとえば、8 基の P16EN GPU のリクエストでは、デバイス [0,1,2,3,4,5,6,7] または [8,9,10,11,12,13,14,15] のすべてが未割り当てである必要があります。
evictやdeleteなどのコマンドを使用して Pod を排除します。
カスタムスケジューラを使用する際のパーティションに関する注意事項
カスタムスケジューラが Pod をノードに割り当てると、ACS はそのノード上で当該 Pod のデバイス割り当てを処理します。割り当て中に、ACS は断片化を防ぐために Pod を密にパッキングしようとします。
カスタムスケジューラは、ノードの合計 GPU 容量のみを考慮する必要があります。GPU リソースについては、MostAllocated ノードスケジューリングポリシーを優先してください。これにより、パーティションの断片化を減らすことができます。
各種スケジューラによる ACS GPU HPN トポロジー対応の処理方法
スケジューラタイプ | 条件 | 説明 |
ACS デフォルトスケジューラ | 次のすべての条件を満たしていること:
次のいずれかの条件を満たしていること:
詳細については、「kube-scheduler」をご参照ください。 | スケジューラは、ノード上の現在のパーティション割り当てを認識します。パーティション要件を満たさないノードは、スケジューリングの対象とはなりません。Pod スケジューリングが失敗した場合の対応するイベントには、 |
ACK デフォルトスケジューラ | 次のすべての条件を満たしていること:
詳細については、「kube-scheduler」をご参照ください。 | |
上記のスケジューラタイプ、条件、または構成を満たさない場合 | スケジューラはパーティショントポロジーを認識しません。GPU-HPN ノードは、割り当て中にデバイスを密にパッキングしようとします。パーティション要件が満たされない場合、Pod は要件が満たされるまでノード上で Pending 状態のままになります。対応するメッセージには | |