このトピックでは、コンソールを使用する方法と手動で行う方法の 2 つのケースで、セルフマネージド ClickHouse クラスターを ApsaraDB for ClickHouse Enterprise Edition に移行する方法について説明します。
前提条件
セルフマネージドクラスター:データベースアカウントとパスワードが作成済みであること。このアカウントには、データベースとテーブルに対する読み取り権限および SYSTEM コマンドの実行権限が必要です。アカウント認証情報を含む外部テーブルを移行する必要がある場合は、
displaySecretsInShowAndSelect権限も必要です。ターゲットクラスター:データベースアカウントとパスワードが作成済みであり、そのアカウントが最高権限を持っていることを確認してください。
ネットワーク接続
セルフマネージドクラスターとターゲットクラスターが同じ VPC 内にある場合、ターゲットクラスターのすべてのノードの IP アドレスと、ノードのスイッチの IPv4 CIDR ブロックを、セルフマネージドクラスターのホワイトリストに追加してください。
ApsaraDB for ClickHouse クラスターのホワイトリストの設定方法については、「ホワイトリストの設定」をご参照ください。
セルフマネージドクラスターのホワイトリストを設定するには、その製品ドキュメントをご参照ください。
SELECT * FROM system.clusters WHERE internal_replication = 1;コマンドを実行して、ApsaraDB for ClickHouse クラスター内のすべてのノードの IP アドレスをクエリします。
セルフマネージドクラスターとターゲットクラスターが異なる VPC にある場合、またはセルフマネージドクラスターがオンプレミス IDC や他のクラウドプロバイダーでホストされている場合は、まずネットワーク接続の問題を解決してください。詳細については、「ターゲットクラスターとデータソース間のネットワーク接続の確立」をご参照ください。
説明このシナリオでは、IP マッピングを使用して、異なる VPC 間の CIDR ブロックの競合を防ぐことができます。IP マッピングを使用する場合は、マッピングされた IP アドレスも両方のクラスターのホワイトリストに追加する必要があります。
移行の検証
データ移行を開始する前に、テスト環境を構築して互換性、パフォーマンス、移行の実現可能性を検証することを強く推奨します。この検証が完了した後にのみ、本番環境でデータ移行を実行してください。このステップは、潜在的な問題を早期に特定して解決し、スムーズな移行を保証し、本番環境を保護するために不可欠です。
移行タスクを作成してデータ移行を実行します。
パフォーマンスボトルネックを分析し、移行の実現可能性を検証します。
クラウドの互換性を検証するには、次のいずれかの方法を使用します。
手動検証:「互換性の分析と解決」をご参照ください。
コンソール検証:「(オプション) SQL 互換性の確認」をご参照ください。
移行方法
移行方法 | メリット | デメリット | ユースケース |
コンソール移行 | 視覚的なワークフローを提供し、メタデータの移行を自動化します。 | クラスター全体の完全移行および増分移行に限定され、特定のデータベースやテーブル、または既存データの一部を移行することはサポートしていません。 | クラスター全体の移行。 |
手動移行 | 移行するデータベースとテーブルをきめ細かく制御できます。 | 手順が複雑で、メタデータの移行を手動で行う必要があります。 |
|
操作手順
コンソール移行
注意事項
移行中
移行中のデータベースとテーブルに対して、移行先クラスターでのマージプロセスは一時停止しますが、セルフマネージドクラスターでは継続します。
説明移行タスクの実行時間が長すぎると、移行先クラスターに過剰なメタデータが蓄積される可能性があります。移行タスクの推奨期間は 5 日以内です。この制限を超えたタスクは、システムによって自動的にキャンセルされます。
移行先クラスターは
defaultクラスターを使用する必要があります。セルフマネージドクラスターが異なる名前を使用している場合、システムは分散テーブル内のクラスター定義を自動的にdefaultに変換します。
サポートされる内容
移行プロセスでは、一部のエンジンについてデータベースとテーブルの構造が変換されます。エンジンの変換に関する詳細については、以下の表をご参照ください。
データベース構造:次の表に、サポートされているデータベースエンジンタイプを示します。
エンジン名
変換の説明
AtomicReplicatedエンジンに置き換えられますReplicated変更なし
OrdinaryReplicatedエンジンに置き換えられますテーブル構造:次の表に、サポートされているテーブルエンジンタイプを示します。
エンジン名
変換の説明
MaterializedView変更なし
ViewGenerateRandomBufferURLNullMergeSharedMergeTreeSharedVersionedCollapsingMergeTreeSharedSummingMergeTreeSharedReplacingMergeTreeSharedAggregatingMergeTreeSharedCollapsingMergeTreeSharedGraphiteMergeTreeMergeTreeSharedMergeTreeに置き換えられますReplicatedMergeTreeVersionedCollapsingMergeTreeSharedVersionedCollapsingMergeTreeに置き換えられますReplicatedVersionedCollapsingMergeTreeSummingMergeTreeSharedSummingMergeTreeに置き換えられますReplicatedSummingMergeTreeReplacingMergeTreeSharedReplacingMergeTreeに置き換えられますReplicatedReplacingMergeTreeAggregatingMergeTreeSharedAggregatingMergeTreeに置き換えられますReplicatedAggregatingMergeTreeReplicatedCollapsingMergeTreeSharedCollapsingMergeTreeに置き換えられますCollapsingMergeTreeGraphiteMergeTreeSharedGraphiteMergeTreeに置き換えられますReplicatedGraphiteMergeTreeデータ:
MergeTreeファミリーのテーブル内のデータに対して増分移行がサポートされています。
システムは、上記のデータベースとテーブルの構造を自動的に移行できます。その他の構造は、移行中に発生した警告やエラーに基づいて手動で処理する必要があります。
データがこれらの条件を満たさない場合は、手動移行を実行できます。
クラスターへの影響
セルフマネージドクラスター
セルフマネージドクラスターからデータを読み取ると、その CPU とメモリ使用量が増加します。
DDL 操作は許可されません。
移行先クラスター
移行先クラスターにデータを書き込むと、その CPU とメモリ使用量が増加します。
移行に含まれるデータベースとテーブルに対して DDL 操作は許可されません。この制限は、移行に含まれないデータベースとテーブルには適用されません。
移行中のテーブルとデータベースのマージプロセスは一時停止します。これは他のテーブルとデータベースには影響しません。
移行完了後、クラスターは一定期間、頻繁にマージ操作を実行します。これにより I/O 使用率が増加し、ビジネスリクエストのレイテンシーが高くなる可能性があります。潜在的な影響を軽減するために、「移行後のマージ時間の計算」を参照し、それに応じて計画してください。
ステップ 1:クラスターの確認とシステムテーブルの有効化
データ移行を開始する前に、セルフマネージドクラスターの config.xml ファイルを設定して増分移行を有効にします。設定は、system.part_log および system.query_log システムテーブルがすでに有効になっているかどうかによって異なります。
システムテーブルが有効になっていない場合
system.part_log と system.query_log を有効にしていない場合は、config.xml ファイルに以下の設定を追加してください。
system.part_log
<part_log>
<database>system</database>
<table>part_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log>system.query_log
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>システムテーブルが有効になっている場合
-
config.xml ファイル内の
system.part_logとsystem.query_logの設定が以下の内容と一致していることを確認してください。不一致があると、データ移行が失敗したり、遅延したりする可能性があります。system.part_log
<part_log> <database>system</database> <table>part_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </part_log>system.query_log
<query_log> <database>system</database> <table>query_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </query_log> -
設定を変更した後、
drop table system.part_logとdrop table system.query_logステートメントを実行します。ビジネステーブルにデータを挿入すると、system.part_logとsystem.query_logテーブルが自動的に再作成されます。
ステップ 2:クラスターの互換性の設定
ターゲットクラスターがセルフマネージドクラスターと可能な限り互換性を持つようにするため、「ターゲットクラスターへの接続」を参照してターゲットクラスターに接続し、compatibility パラメーターをセルフマネージドクラスターのバージョンに合わせて変更します。
互換性を古いバージョンに設定すると、ParallelReplica などの一部の新機能が無効になります。
例:
SELECT currentProfiles(); // 現在のプロファイル名を取得します。
SELECT
profile_name,
setting_name,
value
FROM system.settings_profile_elements
WHERE (setting_name = 'compatibility') AND (profile_name = 'xxxx'); // 互換性設定の値を確認します。
ALTER PROFILE XXXX SETTINGS compatibility = '23.8'; // 互換性の値を設定します。ステップ 3:移行タスクの作成
ApsaraDB for ClickHouse コンソールにログインします。クラスターリスト ページで、Enterprise Edition インスタンスのリスト を選択し、ターゲットクラスターの ID をクリックします。
ナビゲーションウィンドウで、 を選択します。
移行タスクの作成 をクリックします。
ソースインスタンスとターゲットインスタンスの選択
パラメーター
説明
例
タスク名
移行タスクの一意の名前。大文字と小文字は区別されません。名前には英字と数字のみ使用できます。
MigrationTask1229
配信元インスタンスクラスター名
SELECT * FROM system.clusters;を実行して、ご利用のセルフマネージドクラスターのクラスター名を取得します。default
VPC IP アドレス
クラスター内の各シャードの IP アドレスとポートをカンマで区切って入力します。形式:
IP:PORT,IP:PORT,....次の SQL ステートメントを使用して、ご利用のセルフマネージドクラスターの IP アドレスとポートを取得できます。
SELECT shard_num, replica_num, host_address as ip, port FROM system.clusters WHERE cluster = '<cluster_name>' and replica_num = 1;パラメーターの説明:
cluster_name:ご利用のセルフマネージドクラスターの名前。
replica_num=1 は最初のレプリカセットを選択します。別のレプリカセットを選択するか、各シャードから手動で 1 つのレプリカを選択することもできます。
重要ClickHouse クラスターの VPC ドメイン名または SLB アドレスは使用できません。
NAT を使用して IP アドレスとポートを Alibaba Cloud にマッピングする場合、ご利用のネットワーク設定に従って、マッピングされた IP アドレスとポートを設定する必要があります。
192.168.0.5:9000,192.168.0.6:9000
データベースアカウント
セルフマネージドクラスターのデータベースアカウント。
test
データベースパスワード
セルフマネージドクラスターのデータベースアカウントのパスワード。
test******
ソースインスタンスのカーネルバージョン
バージョン取得 をクリックします。
22.8.5.29
ソースインスタンスのバージョンに基づいて、次のように進めます。
ソースインスタンスのバージョンが 22.10 以降の場合:次のステップ をクリックします。
ソースインスタンスのバージョンが 22.10 より前の場合:プロンプトに従って ターゲットインスタンス情報 を入力し、次のステップ をクリックします。
バージョンの取得に失敗した場合:これは、ソースインスタンス情報が正しくないか、ネットワークが切断されている場合に発生する可能性があります。プロンプトに従って問題を解決し、再度 バージョン取得 をクリックします。
説明以前のコミュニティ版と Enterprise Edition の間のパラメーターの非互換性のため、ソースインスタンスのバージョンが 22.10 より前の場合、ソースからターゲットにデータをプッシュしてデータを同期する必要があります。このシナリオでは、ターゲットインスタンスの IP アドレスをセルフマネージドネットワークにマッピングする必要があります。セルフマネージドネットワークと Enterprise Edition インスタンスが同じ VPC 内にある場合、または VPC ピアリング接続を介して接続されている場合は、接続に元の IP アドレスを使用できます。
接続性と設定の確認
チェックの開始 をクリックします。
チェック中に、右上隅の
 アイコンをクリックしてリアルタイムの進捗状況を確認できます。
アイコンをクリックしてリアルタイムの進捗状況を確認できます。チェックが完了したら、結果に基づいて進めます。
結果レベル と確認項目を選択し、
アイコンをクリックして対応する結果を表示できます。結果レベルは以下のように説明されます。成功:すべてのチェックに合格した場合、次のステップ をクリックして続行します。
警告:これらは非ブロッキング項目です。警告がワークロードや移行タスクに影響するかどうかを手動で確認する必要があります。警告を無視するか、問題を解決して再度 チェックの開始 をクリックできます。
エラー:これらはブロッキング項目です。提供された情報を使用してエラーを解決し、再度 チェックの開始 をクリックする必要があります。
エラーメッセージと解決策については、「よくある質問」をご参照ください。
データベースとテーブルの構造の確認
接続性と設定のチェックに合格したら、データベースとテーブルの構造の確認に進みます。このステップは、移行するデータベースの選択、移行するテーブルの選択、データベースとテーブルの構造の確認の 3 つのサブステップで構成されます。
重要移行するデータベースの選択と移行するテーブルの選択のサブステップはオプションです。ソースインスタンスからすべてのデータベースとテーブルを移行したい場合は、これら 2 つのサブステップをスキップして、直接サブステップ 3 (データベースとテーブルの構造の確認) に進むことができます。
サブステップ 1:移行するデータベースの選択 (オプション)
[ソースをクエリ] をクリックします。システムはソースインスタンス上のすべてのデータベースを自動的にクエリします。
クエリ中に、[クエリ結果] をクリックしてリアルタイムの結果を表示できます。
クエリが完了したら、ビジネス要件に基づいて移行するデータベースを選択します。選択が完了したら、[確認] をクリックします。
サブステップ 2:移行するテーブルの選択 (オプション)
データベースを選択すると、テーブルを選択するインターフェイスが表示されます。[ソースをクエリ] をクリックします。システムは選択されたデータベース内のすべてのテーブルを自動的にクエリします。
クエリ中に、[クエリ結果] をクリックしてリアルタイムの結果を表示できます。
クエリが完了したら、ビジネス要件に基づいて移行するテーブルを選択します。選択が完了したら、[確認] をクリックします。
説明デフォルトでは、すべてのテーブルが選択されています。特定のテーブルのみを移行する必要がある場合は、対応するデータベースの全選択チェックボックスの選択を解除し、ドロップダウンリストを展開して必要なテーブルを選択します。
サブステップ 3:データベースとテーブルの構造の確認
チェックの開始 をクリックします。システムはデータベース構造、テーブル構造、および UDF をチェックして、ソースインスタンスとターゲットインスタンス間の非互換性を特定します。
チェック中に、結果レベルと確認項目でフィルタリングし、更新アイコンをクリックしてリアルタイムの結果を表示できます。
チェック結果は、成功、警告、エラーの 3 つのレベルに分類されます。
チェック成功:[次へ] をクリックして移行を続行します。
チェック中に警告が発生
結果レベルを警告に設定し、対応する確認項目を見つけて警告の詳細を確認します。
重要警告レベルの確認項目は非ブロッキングです。警告がワークロードや移行タスクに影響するかどうかを確認する必要があります。確認後、2 つの選択肢があります。
警告を無視して [次へ] をクリックして移行を続行します。
提供された詳細に基づいて警告を解決し、再度 チェックの開始 をクリックしてデータベースとテーブルの構造を再チェックします。警告メッセージと解決策については、このトピックのよくある質問セクションをご参照ください。
チェック失敗
結果レベルをエラーに設定し、対応する確認項目を見つけてエラーの詳細を確認します。
重要エラーレベルの確認項目はブロッキングです。提供された詳細に基づいてエラーを解決し、再度 チェックの開始 をクリックしてデータベースとテーブルの構造を再チェックする必要があります。エラーメッセージと解決策については、このトピックのよくある質問セクションをご参照ください。
データベースとテーブルの構造の移行
移行開始 をクリックします。
移行中に、右上隅の
アイコンをクリックしてリアルタイムの進捗状況を確認できます。移行が完了したら、結果に基づいて進めます。
結果については、ステップ 5 をご参照ください。
(オプション) SQL 互換性の確認
SQL 互換性チェックは、セルフマネージドインスタンスからの SQL ステートメントをターゲットインスタンスでリプレイし、異なるカーネルバージョン間の構文の互換性を検証します。
このステップをスキップするには、互換性検証をスキップ をクリックします。
このチェックを実行するには、リクエストリプレイ時間 を選択し、チェックの開始 をクリックします。チェックに合格した場合は、次のステップ をクリックします。チェックに失敗した場合は、ステップ 5 の解決策をご参照ください。
重要インスタンスのデータベースとテーブルにはデータが含まれていないため、このチェックは構文の互換性のみを検証します。データを使用してテストするには、次のステップで一部のデータを移行できます。
SQL リプレイに使用されるクライアントバージョンとターゲットインスタンスの不一致により、誤検知が発生する可能性があります。エラーが発生した場合は、SQL ステートメントを手動で実行して結果を検証してください。
Kafka/RabbitMQ エンジンテーブルの記録とクリーンアップ
同期を開始する前に、セルフマネージドクラスター上の Kafka/RabbitMQ エンジンテーブルとその下流のマテリアライズドビューの定義を記録し、暗黙的なテーブルを処理してから、これらのテーブルを削除して移行例外を回避します。
セルフマネージドクラスターにログインし、すべての Kafka および RabbitMQ エンジンテーブルとその下流の依存関係をクエリします。
/* create_table_query: テーブル定義 dependencies_database: 下流の依存テーブルのデータベース dependencies_table: 下流の依存テーブルの名前 dependencies_database と dependencies_table から、Kafka/RabbitMQ テーブルに依存するマテリアライズドビューを特定できます。 */ SELECT * FROM system.tables WHERE engine IN ('RabbitMQ', 'Kafka');マテリアライズドビューの定義を表示し、そのターゲットテーブルが暗黙的なテーブルであるかどうかを確認します。
/* マテリアライズドビューの定義を表示します。 マテリアライズドビューのターゲットテーブルが暗黙的なテーブルである場合、次の点に注意してください: マテリアライズドビューを削除すると、暗黙的なテーブルも削除され、データ損失が発生します。 例:CREATE MATERIALIZED VIEW [db.]table_name [TO[db.]name] で、TO が指定されていない場合、 システムは自動的に暗黙的なテーブルを作成します。これは '.inner_id.<TABLE_UUID>' または '.inner.<TABLE>' の形式になることがあります。 */ SELECT * FROM system.tables WHERE database='<DATABASE>' AND name = '<MATERIALIZED_VIEW_NAME>';マテリアライズドビューのターゲットテーブルが暗黙的なテーブルである場合、後でマテリアライズドビューが削除されたときにデータ損失を防ぐために、新しい名前に変更します。
-- 暗黙的なターゲットテーブルの名前を変更してデータを保持します RENAME TABLE <DATABASE>.`.inner_id.<TABLE_UUID>` TO <DATABASE>.<new_target_table_name>;Kafka/RabbitMQ エンジンテーブルとその下流のマテリアライズドビューを削除します。
-- 最初にマテリアライズドビューを削除します DROP TABLE <DATABASE>.<MATERIALIZED_VIEW_NAME>; -- 次に Kafka/RabbitMQ エンジンテーブルを削除します DROP TABLE <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME>;
重要記録したすべての DDL ステートメントを必ず保存してください。後でセルフマネージドクラスターとターゲットクラスターの両方でこれらのテーブルを再作成するために必要になります。RENAME 操作を実行した場合は、マテリアライズドビューを再作成する際に TO 句を使用して、名前が変更されたターゲットテーブルを指すようにしてください。
同期の開始
同期の開始 をクリックします。
同期中に、右上隅の
アイコンをクリックしてリアルタイムの進捗状況を確認できます。セルフマネージドクラスターで、以前に保存した DDL ステートメントを使用して、Kafka/RabbitMQ エンジンテーブルとその下流のマテリアライズドビューを再作成します。再作成後、増分データは再び流れ込み、ターゲットクラスターに自動的に同期されます。
重要以前に暗黙的なターゲットテーブルに対して RENAME 操作を実行した場合は、マテリアライズドビューを再作成する際に TO 句を使用して、名前が変更されたターゲットテーブルを指すようにしてください。詳細については、「CREATE MATERIALIZED VIEW」をご参照ください。
CREATE MATERIALIZED VIEW [db.]table_name [TO[db.]name]。
-- セルフマネージドクラスターで Kafka/RabbitMQ エンジンテーブルを再作成します CREATE TABLE <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME> (...) ENGINE = Kafka/RabbitMQ SETTINGS ...; -- マテリアライズドビューを再作成します (名前が変更されたターゲットテーブルを指します) CREATE MATERIALIZED VIEW <DATABASE>.<MATERIALIZED_VIEW_NAME> TO <DATABASE>.<new_target_table_name> AS SELECT ... FROM <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME>;プロセスが データを移行する ステージに達したら、データを移行する タブに切り替え、
アイコンをクリックして 移行の進行状況 と 推定残り時間 を表示します。重要移行の進行状況 を注意深く監視する必要があります。推定残り時間 に基づいて、セルフマネージドクラスターへの書き込みを積極的に停止し、Kafka および RabbitMQ エンジンを使用するテーブルを処理する必要があります。
バックグラウンドプロセスは、5 日を超えて実行されるタスクを自動的にキャンセルします。移行タスクにさらに時間が必要な場合は、チケットを送信してしきい値の調整をリクエストしてください。
移行の進行状況 が 100% に達し、ソースインスタンスへの書き込みが停止したことを確認したら、停止 をクリックしてデータ移行を終了し、次のステップに進みます。
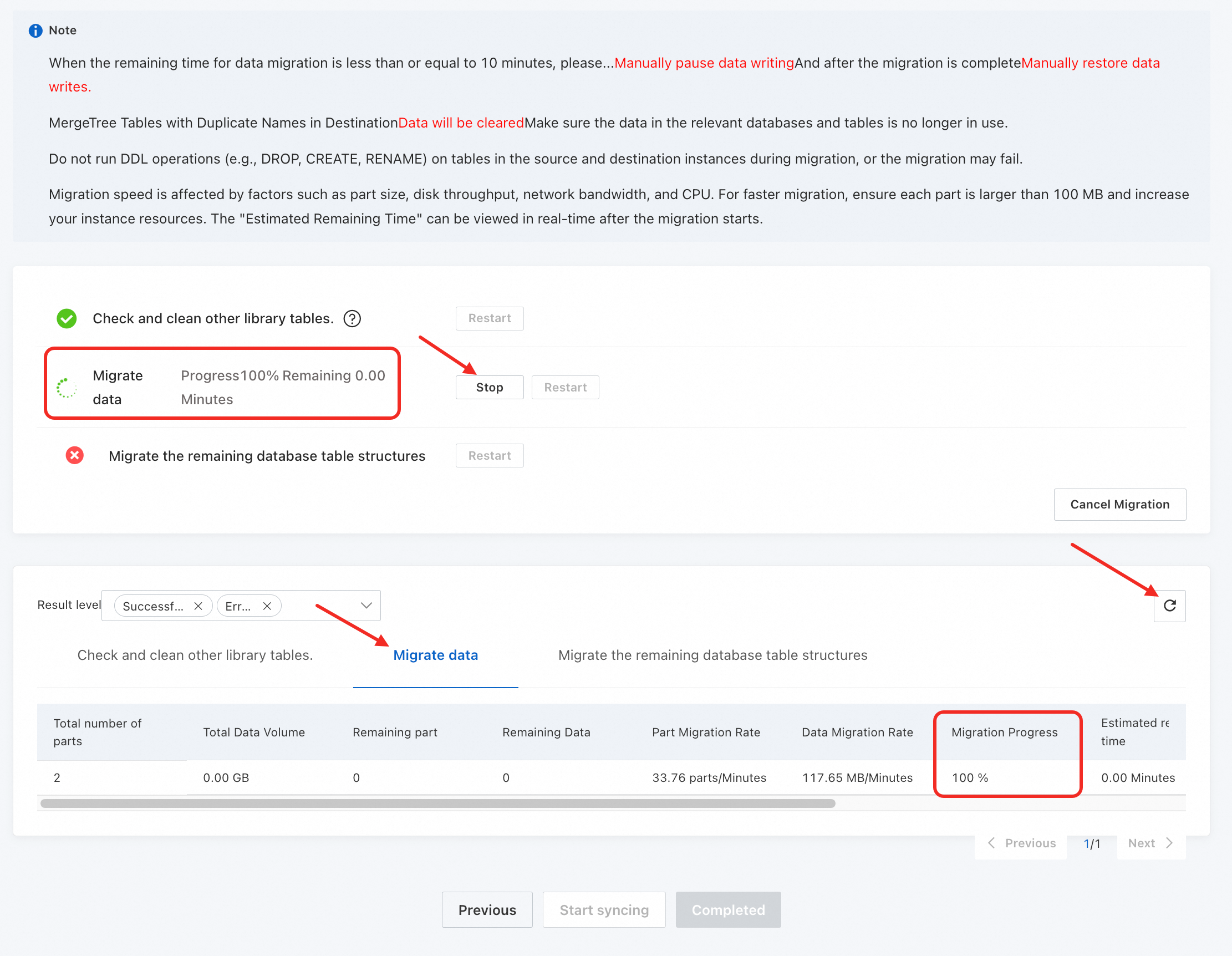
同期が完了したら、終了 をクリックします。
重要同期の開始ステップが完了すると、移行タスクはロックされ、移行プロセスを変更できなくなります。前のステップ、次のステップ、または リフレッシュ ボタンを使用して、完了したステップの結果を表示することはできます。
ステップ 4:非 MergeTree テーブルのデータ移行
移行タスク中、非 MergeTree テーブルはテーブル構造の移行のみをサポートするか (例:MySQL テーブル)、移行を全くサポートしません (例:Log テーブル)。したがって、移行タスクが完了した後、ターゲットクラスターには構造はあるがビジネスデータがないテーブルが含まれる可能性があります。次のようにビジネスデータを手動で移行する必要があります。
セルフビルドクラスターにログインし、データ移行が必要な非 MergeTree テーブルを特定します。
SELECT `database` AS database_name, `name` AS table_name, `engine` FROM `system`.`tables` WHERE (`engine` NOT LIKE '%MergeTree%') AND (`engine` != 'Distributed') AND (`engine` != 'MaterializedView') AND (`engine` NOT IN ('Kafka', 'RabbitMQ')) AND (`database` NOT IN ('system', 'INFORMATION_SCHEMA', 'information_schema')) AND (`database` NOT IN ( SELECT `name` FROM `system`.`databases` WHERE `engine` IN ('MySQL', 'MaterializedMySQL', 'MaterializeMySQL', 'Lazy', 'PostgreSQL', 'MaterializedPostgreSQL', 'SQLite') ))ターゲットクラスターにログインし、remote 関数を使用してデータを移行します。
手動移行
セルフマネージド ClickHouse から Enterprise Edition への移行
ApsaraDB for ClickHouse Enterprise Edition では、ソーステーブルにシャードやレプリカがあるかどうかに関わらず、対応するターゲットテーブルを作成するだけで済みます。システムは自動的に SharedMergeTree テーブルエンジンを使用するため、ターゲットテーブルの定義で複雑なエンジンパラメーターを省略できます。ApsaraDB for ClickHouse Enterprise Edition クラスターは、垂直および水平スケーリングを自動的に処理するため、レプリケーションとシャーディングの実装詳細について心配する必要はありません。
概要
以下の手順では、セルフマネージド ClickHouse クラスターから ApsaraDB for ClickHouse Enterprise Edition クラスターへの移行方法について説明します。
ソースクラスターに読み取り専用ユーザーを追加します。
ターゲットクラスターにソーステーブルの構造を複製します。
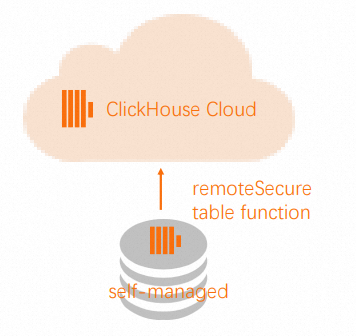
ソースクラスターが外部ネットワークからアクセス可能な場合は、ソースクラスターからターゲットクラスターにデータをプルします。そうでない場合は、ソースクラスターからターゲットクラスターにデータをプッシュします。
(オプション) ターゲットクラスターの許可リストからソースクラスターの IP アドレスを削除します。
ソースクラスターから読み取り専用ユーザーを削除します。
操作手順
ソースクラスターで以下の操作を実行します。この手順では、ソーステーブルにすでにデータが含まれていることを前提としています。
db.tableテーブルに読み取り専用ユーザーを追加します。CREATE USER exporter IDENTIFIED WITH SHA256_PASSWORD BY 'password-here' SETTINGS readonly = 1;GRANT SELECT ON db.table TO exporter;ソーステーブルの構造をコピーします。
SELECT create_table_query FROM system.tables WHERE database = 'db' and table = 'table'
ターゲットクラスターで以下の操作を実行します。
データベースを作成します。
CREATE DATABASE dbソーステーブルの
CREATE TABLEステートメントを使用して、ターゲットテーブルを作成します。説明CREATE TABLEステートメントを実行する際、ENGINEをSharedMergeTreeに変更し、パラメーターを省略します。ApsaraDB for ClickHouse Enterprise Edition クラスターは常にテーブルを複製し、正しいパラメーターを提供します。ORDER BY、PRIMARY KEY、PARTITION BY、SAMPLE BY、TTL、およびSETTINGS句は、テーブルの構造とメタデータを定義します。これらの句を保持して、ターゲットの ApsaraDB for ClickHouse Enterprise Edition クラスターでテーブルが正しく作成されるようにしてください。CREATE TABLE db.table ...Remote関数を使用してデータをプルまたはプッシュします。説明ソースの ClickHouse サーバーが外部ネットワークからアクセスできない場合は、ターゲットクラスターからデータをプルするのではなく、ソースクラスターからデータをプッシュします。
Remote関数はSELECT(プル) とINSERT(プッシュ) の両方の操作をサポートします。ターゲットクラスターで、
Remote関数を使用してソーステーブルからデータをプルします。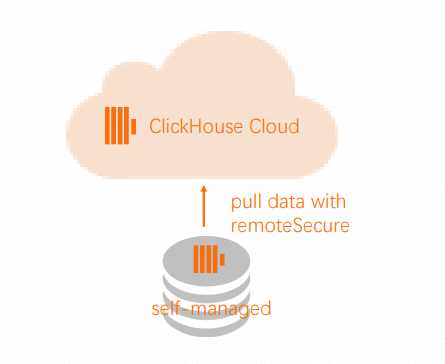
INSERT INTO db.table SELECT * FROM remote('source-hostname:9000', db, table, 'exporter', 'password-here')ソースクラスターで、
Remote関数を使用してターゲットクラスターにデータをプッシュします。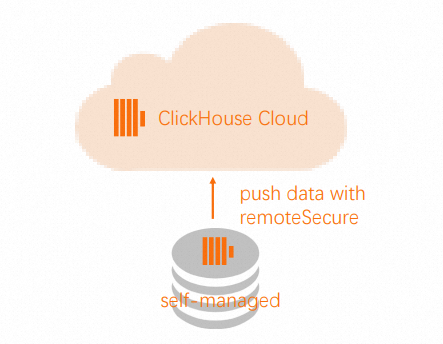 説明
説明Remote関数がご利用の ApsaraDB for ClickHouse Enterprise Edition クラスターに接続できるように、ソースクラスターの IP アドレスをターゲットクラスターのホワイトリストに追加してください。詳細については、「ホワイトリストの設定」をご参照ください。INSERT INTO FUNCTION remote('target-hostname:9000', 'db.table', 'default', 'PASS') SELECT * FROM db.table
よくある質問
接続性と設定のエラー
エラーメッセージ | 説明 | 解決策 |
| セルフビルドクラスターへのネットワーク接続がタイムアウトしました。 | エラーメッセージを使用してネットワークの問題をトラブルシューティングします。 |
| 移行タスクの設定で指定されたクラスターがセルフビルドクラスターで見つかりませんでした。 | SQL を使用してセルフビルドクラスターで正しいクラスター名をクエリし、移行タスクの設定を更新します。 |
| セルフビルドクラスターに次のシステムテーブルの 1 つ以上がありません: | セルフビルドクラスターに不足しているシステムテーブルを作成します。 |
| セルフビルドクラスターのタイムゾーンがターゲットクラスターのタイムゾーンと一致しません。 | クラスターのタイムゾーン設定を合わせます。 |
| ターゲットクラスターの | ターゲットクラスターの 重要 互換性を古いバージョンに設定すると、ParallelReplica などの機能が無効になります。 |
データベースとテーブルスキーマのエラー
エラーメッセージ | 説明 | 解決策 |
| データベースとテーブルのスキーマがセルフビルドクラスターのノード間で一貫していません。 | セルフビルドクラスターの各ノードでスキーマを確認し、不一致を解決します。 |
| データベースとテーブルのスキーマ内のパスワードが非表示になっています。 |
注意:この操作には displaySecretsInShowAndSelect アカウント権限が必要です。 |
| 移行プロセスは、セルフビルドクラスターのデータベースエンジンをサポートしていません。 | データベースエンジンをターゲットインスタンスでサポートされているものに変更します。 |
| セルフビルドクラスターのデータベースエンジンは移行でサポートされていません。 | 移行例外を回避するために、システムはエンジンを自動的に Replicated データベースに置き換えます。 |
| セルフビルドクラスターのデータベースエンジンは移行でサポートされていません。 | Data Transmission Service (DTS) を使用してデータを同期するか、ターゲットインスタンスに同じ名前のデータベースを作成して移行例外を回避します。 |
| 特定のエンジンを使用するテーブルの移行はサポートされていません。 | 移行プロセスはこのエンジンを自動的に無視します。 |
| ApsaraDB for ClickHouse Enterprise Edition では、分散テーブルエンジンの使用は推奨されません。 | セルフビルドクラスターで分散テーブルを削除します。移行後、基になる MergeTree テーブルを直接クエリします。 |
| この警告は、到達不能の可能性がある IP アドレスをフラグ付けしますが、アクセシビリティの問題を確認するものではありません。 | ターゲットインスタンスが参照されている IP アドレスに到達できることを確認してください。そうでない場合は、接続を確立し、IP アドレスをホワイトリストに追加します。 |
| 特定のエンジンを使用するテーブルでは、スキーマのみが移行され、データ移行はサポートされていません。 | remote 関数などを使用して、データを手動で移行します。 |
| 特定のエンジンを使用するテーブルの移行はサポートされていません。 | ターゲットインスタンスに同じ名前の MergeTree テーブルを作成し、データを手動で移行します。 |
| 特定のエンジンを使用するテーブルの移行はサポートされていません。 | 手順セクションのステップ 4 をご参照ください。 |
| スキーマチェックが成功するためには、ターゲットインスタンスの対応するテーブルが空である必要があります。 | ターゲットインスタンスの対応するテーブルからデータを削除します。 |
| 移行でサポートされているのは、 | ターゲットインスタンスに必要な関数を手動で作成します。 |
その他
その他の移行問題の解決策については、「よくある質問」をご参照ください。