セルフマネージド ClickHouse クラスターからクラウドにデータを移行した後、互換性やパフォーマンスの問題が発生することがあります。スムーズな移行を確保し、本番環境への影響を避けるために、まずテスト環境でデータを移行することをお勧めします。これにより、互換性とパフォーマンスのボトルネックを分析し、関連する問題を事前に解決できます。
背景情報
ビジネス運用の初期段階では、セルフマネージド ClickHouse クラスターをデプロイしている場合があります。ビジネスの進化に伴い、安定性の向上、O&M コストの削減、ディザスタリカバリ能力の向上のために、これらのクラスターからクラウドにデータを移行したいと考えるかもしれません。移行後、以下の問題が発生する可能性があります。
バージョンの互換性の問題。
MaterializedMySQL エンジンの互換性の問題。
SQL 互換性の問題。
ビジネスを ApsaraDB for ClickHouse に移行した後、CPU リソースが枯渇し、メモリが不足することがあります。
これらの問題を解決するためには、移行中に互換性とパフォーマンスに焦点を当てる必要があります。
互換性分析と解決
パラメーターの互換性
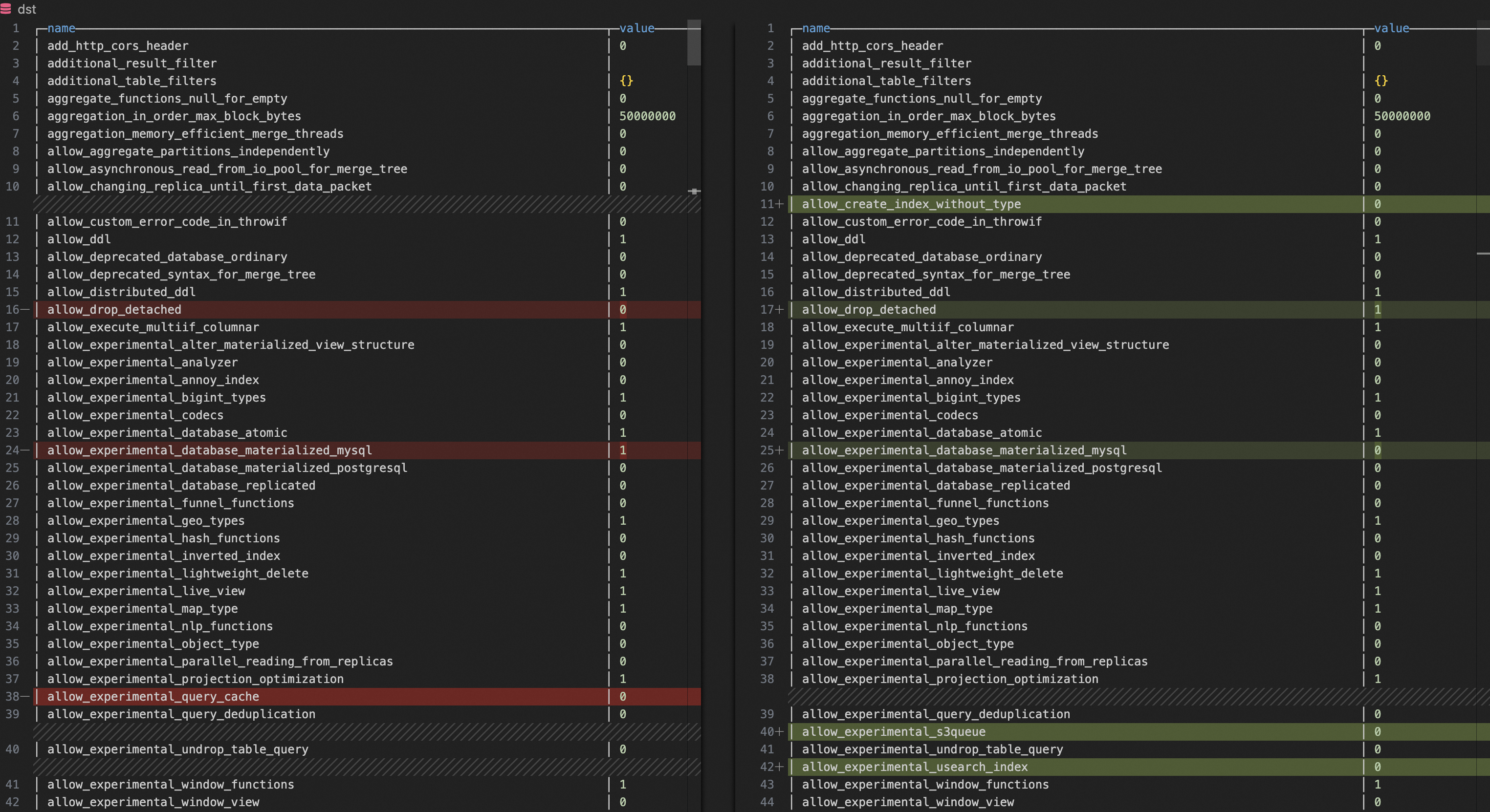
セルフマネージド ClickHouse クラスターと ApsaraDB for ClickHouse クラスターの構成パラメーターを取得できます。
SELECT name, groupArrayDistinct(value) AS value FROM clusterAllReplicas(`default`, system.settings) GROUP BY name ORDER BY name ASCVS Code などのテキスト比較ツールを使用して、2 つのクラスターのパラメーターを比較できます。不一致が見つかった場合は、ApsaraDB for ClickHouse クラスターのパラメーターをセルフマネージド ClickHouse クラスターのパラメーターに合わせることができます。
互換性に影響を与える一般的なパラメーター: `compatibility`、`prefer_global_in_and_join`、`distributed_product_mode`。
パフォーマンスに影響を与える一般的なパラメーター: `max_threads`、`max_bytes_to_merge_at_max_space_in_pool`、`prefer_global_in_and_join`。
MaterializedMySQL の互換性
セルフマネージド ClickHouse クラスターが MySQL データベースからデータを同期している場合、移行後も ApsaraDB for ClickHouse クラスターは MySQL データベースからデータを同期し続ける必要があります。したがって、MaterializedMySQL エンジンの互換性に注意する必要があります。
MaterializedMySQL エンジンは各ノードに `ReplacingMergeTree` テーブルを作成し、各ノードは同じデータを保持します。しかし、MaterializedMySQL エンジンのコミュニティ版はもはやメンテナンスされていません。MySQL データを ApsaraDB for ClickHouse に同期する主な方法は DTS を使用することです。MaterializedMySQL エンジンのコミュニティ版がメンテナンスされていないため、DTS は MySQL データを ApsaraDB for ClickHouse に同期する際に `MaterializedMySQL` テーブルの代わりに `ReplacingMergeTree` テーブルを使用します。この実装では、ApsaraDB for ClickHouse クラスターの各ノードに分散テーブルとローカルの `ReplacingMergeTree` テーブルが作成されます。ApsaraDB for ClickHouse はその後、分散テーブルを介して各ノードにデータを分散します。このアプローチは、セルフマネージド ClickHouse クラスターから ApsaraDB for ClickHouse に移行する際に、ビジネスに影響を与える可能性のある互換性の問題を引き起こす可能性があります。最も一般的な問題は次のとおりです。
問題 1: セルフマネージド ClickHouse クラスターでは、MaterializedMySQL が各シャードにデータを同期します。DTS を使用してクラウドに移行した後、`MaterializedMySQL` テーブルが `ReplacingMergeTree` テーブルに置き換えられ、データは分散テーブルを介して各ノードに分散されます。この変更は、分散テーブルに関連する `IN` および `JOIN` クエリに影響を与えます。詳細については、「分散テーブルでサブクエリを使用するとエラーが発生するのはなぜですか?」をご参照ください。
問題 2: クラウドに移行し、`MaterializedMySQL` テーブルを `ReplacingMergeTree` テーブルに置き換えた後、`ReplacingMergeTree` テーブルのデータマージ速度が十分に速くない場合があります。これにより、セルフマネージドクラスターからの結果と比較して、クエリ結果に重複データが多くなる可能性があります。この問題を解決するには、次のソリューションを使用できます。
ソリューション 1: ApsaraDB for ClickHouse で、
SET global final=1コマンドを実行してクエリ中にデータをマージできます。このパラメーターはクエリデータが重複しないことを保証しますが、より多くの CPU とメモリを消費します。ソリューション 2: ApsaraDB for ClickHouse で、ターゲットの `ReplacingMergeTree` テーブルの `min_age_to_force_merge_seconds` および `min_age_to_force_merge_on_partition_only` パラメーターを変更できます。これにより、ターゲットテーブルがより頻繁にマージされ、過剰な重複データの生成が防止されます。以下に例を示します。
ALTER TABLE <AIM_TABLE> MODIFY SETTING min_age_to_force_merge_on_partition_only = 1, min_age_to_force_merge_seconds = 60;min_age_to_force_merge_on_partition_only
説明: このパラメーターは、MergeTree テーブルエンジンのマージポリシーを制御するために使用されます。このパラメーターを 1 に設定すると、パーティション内の強制データマージが有効になります。
デフォルト値: 0 (無効)
min_age_to_force_merge_seconds
説明: パーツの強制マージの時間間隔。
デフォルト値: 3600
単位: 秒
SQL 互換性検証
Python 環境をインストールできます。
この検証には、基本的な Python 3 環境が必要です。検証には、すでに Python 3 環境が含まれている Alibaba Cloud ECS インスタンス (Linux を実行) を使用することをお勧めします。ECS インスタンスの購入方法の詳細については、「インスタンスの購入」をご参照ください。
Alibaba Cloud ECS 環境を使用していない場合は、自分で Python 環境をインストールする必要があります。Python 環境のインストール方法の詳細については、Python 公式ウェブサイトをご参照ください。
ClickHouse 用の Python クライアントライブラリをインストールできます。
ターミナルまたはコマンドプロンプトで次のコマンドを実行できます。
pip3 install clickhouse_driver検証に使用するサーバーが、ApsaraDB for ClickHouse クラスターとセルフマネージド ClickHouse クラスターの両方とネットワーク経由で通信できることを確認できます。
検証サーバーと ApsaraDB for ClickHouse クラスター間のネットワーク接続の問題を解決する方法の詳細については、「ターゲットクラスターとデータソース間のネットワーク接続の問題を解決するにはどうすればよいですか?」をご参照ください。
Python スクリプトを実行して、セルフマネージド ClickHouse クラスターから SELECT リクエストを抽出し、ApsaraDB for ClickHouse クラスターで実行して、ApsaraDB for ClickHouse との SQL 互換性を検証できます。スクリプトは次のとおりです。
from clickhouse_driver import connect import datetime import logging # pip3 install clickhouse_driver が必要です。 # セルフマネージドインスタンスの VPC エンドポイント。 host_old='HOST_OLD' # セルフマネージドインスタンスの TCP ポート。 port_old=TCP_PORT_OLD # セルフマネージドインスタンスのユーザー名。 user_old='USER_OLD' # セルフマネージドインスタンスのユーザーのパスワード。 password_old='PASSWORD_OLD' # ApsaraDB for ClickHouse クラスターの VPC エンドポイント。 host_new='HOST_NEW' # ApsaraDB for ClickHouse クラスターの TCP ポート。 port_new=TCP_PORT_NEW # ApsaraDB for ClickHouse クラスターのユーザー名。 user_new='USER_NEW' # ApsaraDB for ClickHouse クラスターのユーザーのパスワード。 password_new='PASSWORD_NEW' # ログを設定します。 logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s') def create_connection(host, port, user, password): """ClickHouse への接続を確立します。""" return connect(host=host, port=port, user=user, password=password) def get_query_hashes(cursor): """過去 2 日間の query_hash リストをクエリします。""" get_queryhash_sql = ''' select distinct normalized_query_hash from system.query_log where type='QueryFinish' and `is_initial_query`=1 and `user` not in ('default', 'aurora') and lower(`query`) not like 'select 1%' and lower(`query`) not like 'select timezone()%' and lower(`query`) not like '%dms-websql%' and lower(`query`) like 'select%' and `event_time` > now() - INTERVAL 2 DAY; ''' cursor.execute(get_queryhash_sql) return cursor.fetchall() def get_sql_info(cursor, queryhash): """過去 2 日間の指定された query_hash の SQL 情報をクエリします (検索範囲は 3 日間です)。""" get_sqlinfo_sql = f''' select `event_time`, `query_duration_ms`, `read_rows`, `read_bytes`, `memory_usage`, `databases`, `tables`, `current_database`, `query` from system.query_log where `event_time` > now() - INTERVAL 3 DAY and `type`='QueryFinish' and `normalized_query_hash`='{queryhash}' limit 1 ''' cursor.execute(get_sqlinfo_sql) sql_info = cursor.fetchone() if sql_info: return [info.strftime('%Y-%m-%d %H:%M:%S') if isinstance(info, datetime.datetime) else info for info in sql_info[:-1]],sql_info[-1] return None def execute_sql_on_new_db(cursor, current_database, query_sql, execute_failed_sql): """新しいノードで SQL クエリを実行し、失敗した SQL クエリを記録します。""" try: cursor.execute(f"USE {current_database};") cursor.execute(query_sql) except Exception as error: logging.error(f'query_sql execute in new db failed: {query_sql}') execute_failed_sql[query_sql] = error def main(): # 接続を確立します。 conn_old = create_connection( host=host_old, port=port_old, user=user_old, password=password_old ) conn_new = create_connection( host=host_new, port=port_new, user=user_new, password=password_new ) # カーソルを作成します。 cursor_old = conn_old.cursor() cursor_new = conn_new.cursor() # 古いノードから query_hash リストを取得します。 old_query_hashes = get_query_hashes(cursor_old) # 古いノードから SQL 実行情報を取得します。 old_db_execute_dir = {} for queryhash in old_query_hashes: sql_info,query = get_sql_info(cursor_old, queryhash[0]) if sql_info: old_db_execute_dir[query] = sql_info # 古いノードへのカーソルと接続を閉じます。 cursor_old.close() conn_old.close() # 新しいノードで SQL クエリを実行します。これは最も重要な検証ステップです。 execute_failed_sql = {} keys_list = list(old_db_execute_dir.keys()) for query_sql in old_db_execute_dir: position = keys_list.index(query_sql) current_database = old_db_execute_dir[query_sql][-1] logging.info(f"new db test the {position + 1}th/{len(old_db_execute_dir)}, running sql: {query_sql}\n") execute_sql_on_new_db(cursor_new, current_database, query_sql, execute_failed_sql) # 新しいノードから query_hash リストを取得します。 new_query_hashes = get_query_hashes(cursor_new) new_db_execute_dir = {} for queryhash in new_query_hashes: sql_info,query = get_sql_info(cursor_new, queryhash[0]) if sql_info: new_db_execute_dir[query] = sql_info # 新しいノードへのカーソルと接続を閉じます。 cursor_new.close() conn_new.close() # 古いバージョンと新しいバージョンのノードの SQL 実行情報を出力します。 for query_sql in new_db_execute_dir: if query_sql in old_db_execute_dir: logging.info(f'succeed sql: {query_sql}') logging.info(f'old sql info: {old_db_execute_dir[query_sql]}') logging.info(f'new sql info: {new_db_execute_dir[query_sql]}\n') # 実行に失敗した SQL クエリを出力します。 for query_sql in execute_failed_sql: logging.error('\033[31m{}\033[0m'.format(f'failed sql: {query_sql}')) logging.error('\033[31m{}\033[0m'.format(f'failed error: {execute_failed_sql[query_sql]}\n')) if __name__ == "__main__": main()結果を検証し、問題を解決できます。
SQL 互換性の検証は複雑です。エラーが発生した場合は、特定のエラーメッセージに基づいてトラブルシューティングと解決を行う必要があります。
パフォーマンス分析と最適化
セルフマネージドクラスターはすでにサービスを実行しているため、段階的なクラウド移行テストとパフォーマンスの最適化を実行することは困難です。サービスが ApsaraDB for ClickHouse に切り替えられた後、インスタンスで CPU の完全使用やメモリ不足などの問題が発生する可能性があります。ApsaraDB for ClickHouse サービスに切り替えた後に ApsaraDB for ClickHouse インスタンスのパフォーマンスが低下した場合、次の方法を使用して問題のあるテーブルまたはクエリを迅速に特定し、パフォーマンスのボトルネックを特定できます。宛先インスタンスでパフォーマンスの低下を引き起こしているテーブルまたはクエリがすでにわかっている場合は、ステップ 3: SQL パフォーマンスの分析 に進むことができます。
ステップ 1: 全体的なパフォーマンスボトルネックの原因となっている主要なテーブルを特定する
フレームグラフと `query_log` の分析は、パフォーマンス問題の原因となっている主要なテーブルを特定するための 2 つの方法です。フレームグラフの作成はより複雑ですが、提供される情報はより直感的です。`query_log` テーブルの分析はより簡単で、外部ツールを必要としませんが、自分で情報を分析する必要があります。両方の方法を併用できます。
フレームグラフを作成する
`trace_log` をエクスポートできます。
`clickhouse-client` を使用して ApsaraDB for ClickHouse インスタンスにログインできます。ログイン方法の詳細については、「コマンドラインインターフェイスを使用して ClickHouse クラスターに接続する」をご参照ください。
次のコマンドを実行して `trace_log` をエクスポートし、
cpu_trace_log.txtを生成できます。-- trace_type = 'CPU' は CPU トレースを示します。 -- trace_type = 'Real' はリアルタイムトレースを示します。 /clickhouse/bin/clickhouse-client -h <IP> --port <port> -q "SELECT arrayStringConcat(arrayReverse(arrayMap(x -> concat( addressToLine(x), '#', demangle(addressToSymbol(x)) ), trace)), ';') AS stack, count() AS samples FROM system.trace_log WHERE trace_type = 'CPU' and event_time >= '2025-01-08 19:31:00' and event_time < '2025-01-08 19:33:00' group by trace order by samples desc FORMAT TabSeparated settings allow_introspection_functions=1" > cpu_trace_log.txt次の表にパラメーターを示します。
パラメーター
説明
IP
ApsaraDB for ClickHouse の VPC エンドポイント。
port
ApsaraDB for ClickHouse の TCP ポート。
上記のパラメーターに加えて、ターゲット期間のトレースログを取得するために `event_time` も設定する必要があります。
`clickhouse-flamegraph` を使用してフレームグラフを作成できます。
`clickhouse-flamegraph` をインストールできます。ダウンロードとインストールの詳細については、clickhouse-flamegraph をご参照ください。
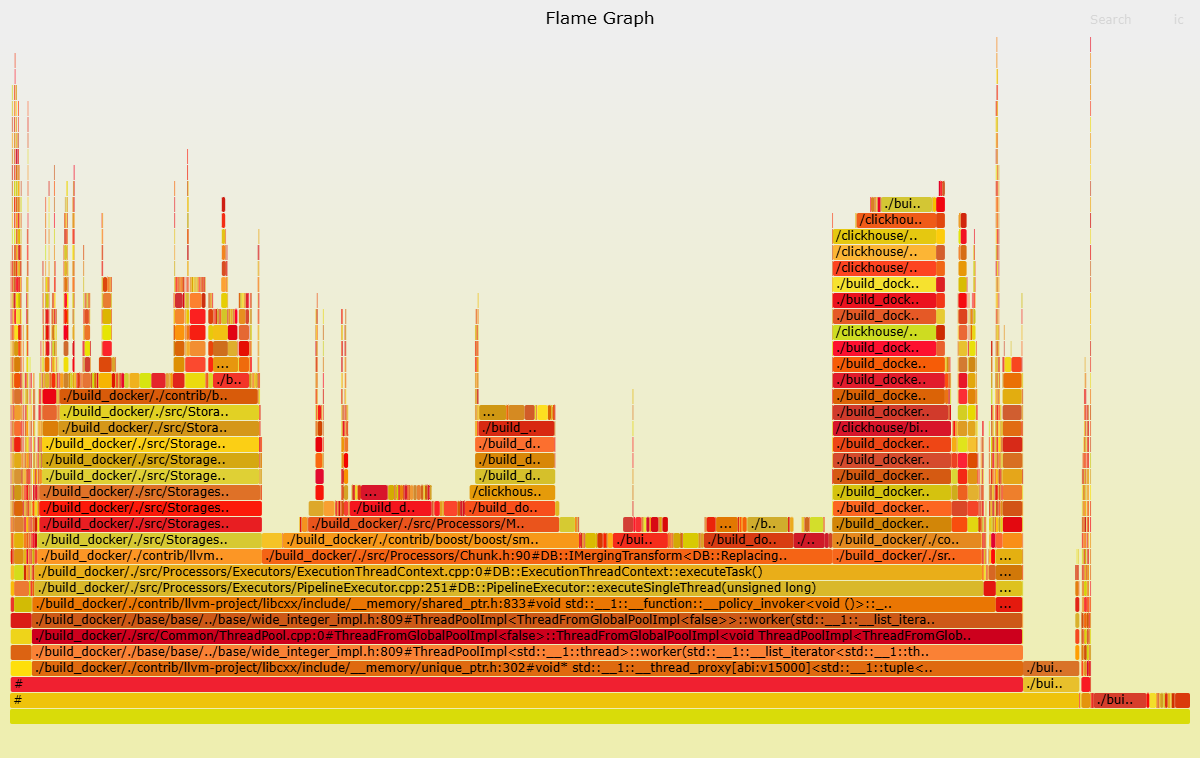
次のコマンドを実行して、フレームグラフを生成および分析できます。
cat cpu_trace_log.txt | flamegraph.pl > cpu_trace_log.svg次のフレームグラフでは、`ReplacingSortedMerge` 関数など、宛先インスタンスで大量の CPU リソースを消費する関数を観察できます。したがって、`ReplacingMergeTree` テーブルに対する SQL クエリに焦点を当てることができます。
query_log の分析
CPU とメモリを大量に消費する `SELECT` リクエストを持つテーブルは、必ずしも全体的なパフォーマンスが低いことを示すわけではありません。それは、高い CPU とメモリ使用量を引き起こす可能性が高いことを示唆しているだけです。したがって、セルフマネージド ClickHouse クラスターと ApsaraDB for ClickHouse クラスターの両方で関連するコマンドを同時に実行して、TOP N 比較を実行する必要があります。大きな違いがあるテーブルを特定した後、関連する `SELECT` 文を特定する必要があります。次の例は、高い CPU またはメモリ使用量を持つテーブルを特定する方法を示しています。
CPU 問題のあるテーブルの特定
SELECT
tables,
first_value(query),
count() AS cnt,
groupArrayDistinct(normalizedQueryHash(query)) AS normalized_query_hash,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS sum_user_cpu,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS sum_system_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS avg_user_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS avg_system_cpu,
sum(memory_usage) as sum_memory_usage,
avg(memory_usage) as avg_memory_usage
FROM clusterAllReplicas(default, system.query_log)
WHERE (event_time > '2025-01-08 19:30:00') AND (event_time < '2025-01-08 20:30:00') AND (query_kind = 'Select')
GROUP BY tables
ORDER BY sum_user_cpu DESC
LIMIT 5メモリ問題のあるテーブルの特定
SELECT
tables,
first_value(query),
count() AS cnt,
groupArrayDistinct(normalizedQueryHash(query)) AS normalized_query_hash,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS sum_user_cpu,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS sum_system_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS avg_user_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS avg_system_cpu,
sum(memory_usage) as sum_memory_usage,
avg(memory_usage) as avg_memory_usage
FROM clusterAllReplicas(default, system.query_log)
WHERE (event_time > '2025-01-08 19:30:00') AND (event_time < '2025-01-08 20:30:00') AND (query_kind = 'Select')
GROUP BY tables
ORDER BY sum_memory_usage
LIMIT 5ステップ 2: パフォーマンスボトルネックの原因となっている主要な SQL クエリを特定する
前のステップでパフォーマンスボトルネックの原因となっているテーブルを特定したら、問題の原因となっている特定の SQL クエリを特定できます。以下に例を示します。
CPU 問題を引き起こす SQL クエリの特定
SELECT
tables,
first_value(query),
count() AS cnt,
normalizedQueryHash(query) AS normalized_query_hash,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS sum_user_cpu,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS sum_system_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS avg_user_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS avg_system_cpu,
sum(memory_usage) as sum_memory_usage,
avg(memory_usage) as avg_memory_usage
FROM clusterAllReplicas(default, system.query_log)
WHERE (event_time > '2025-01-08 19:30:00') AND (event_time < '2025-01-08 20:30:00') AND (query_kind = 'Select') AND has(tables, '<AIM_TABLE>')
GROUP BY
tables,
normalized_query_hash
ORDER BY sum_user_cpu DESC
LIMIT 5メモリ問題を引き起こす SQL クエリの特定
SELECT
tables,
first_value(query),
count() AS cnt,
normalizedQueryHash(query) AS normalized_query_hash,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS sum_user_cpu,
sum(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS sum_system_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')]) AS avg_user_cpu,
avg(ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')]) AS avg_system_cpu,
sum(memory_usage) as sum_memory_usage,
avg(memory_usage) as avg_memory_usage
FROM clusterAllReplicas(default, system.query_log)
WHERE (event_time > '2025-01-08 19:30:00') AND (event_time < '2025-01-08 20:30:00') AND (query_kind = 'Select') AND has(tables, 'AIM_TABLE')
GROUP BY
tables,
normalized_query_hash
ORDER BY sum_memory_usage
LIMIT 5次の表にパラメーターを示します。
`AIM_TABLE`: パフォーマンス問題を特定したいテーブル。
上記のパラメーターに加えて、ターゲット期間のデータを取得するために `event_time` も設定する必要があります。
ステップ 3: SQL パフォーマンスを分析する
`EXPLAIN` 文と `system.query_log` テーブルを使用して、ターゲット文を分析できます。
`EXPLAIN` を使用してターゲット SQL を分析できます。`EXPLAIN` の出力の各フィールドの意味については、EXPLAIN をご参照ください。
EXPLAIN PIPELINE <SQL with performance issues>`system.query_log` テーブルを使用してターゲット SQL を分析できます。
SELECT hostname () AS host, * FROM clusterAllReplicas (`default`, system.query_log) WHERE event_time > '2025-01-18 00:00:00' AND event_time < '2025-01-18 03:00:00' AND initial_query_id = '<INITIAL_QUERY_ID>' AND type = 'QueryFinish' ORDER BY query_start_time_microseconds次の表にパラメーターを示します。
`INITIAL_QUERY_ID`: ターゲット検索文のクエリ ID。
上記のパラメーターに加えて、ターゲット期間のデータを取得するために `event_time` も設定する必要があります。
次の返されたフィールドに注目する必要があります。
ProfileEvents: このフィールドは、詳細なクエリ実行イベントカウンターと統計情報を提供し、メトリック比較のためにクエリのパフォーマンスとリソース使用量を分析するのに役立ちます。クエリイベントの詳細については、events をご参照ください。
Settings: このフィールドは、クエリ実行中に使用されたさまざまな構成パラメーターを提供します。これらのパラメーターは、クエリの動作とパフォーマンスに影響を与える可能性があります。このフィールドを表示することで、ターゲット SQL をよりよく理解し、最適化できます。クエリパラメーターの詳細については、settings をご参照ください。
query_duration_ms: このフィールドは、クエリの合計実行時間を示します。サブクエリが特に遅いことがわかった場合は、サブクエリの `query_id` を使用してログファイルでその実行詳細を見つけることができます。ログレベルの変更方法の詳細については、「config.xml パラメーターの設定」をご参照ください。
上記の方法のいずれもターゲット文のパフォーマンス低下の原因を特定するのに役立たない場合は、セルフマネージド ClickHouse クラスターから文の関連情報を取得できます。次に、この情報を ApsaraDB for ClickHouse の文の情報と比較して、クラウドへの移行後のパフォーマンス低下の理由を分析します。
ステップ 4: SQL の最適化
パフォーマンス問題の原因となっている SQL を特定したら、それに応じて最適化できます。次のセクションでは、いくつかの最適化戦略を説明します。特定の問題は、実際の状況に基づいて分析および処理する必要があります。
インデックスの最適化: ターゲット文を分析し、フィルタリングに頻繁に使用される列を特定し、それらにインデックスを作成できます。
データの型: 適切なデータの型を使用すると、ストレージスペースを削減し、クエリのパフォーマンスを向上させることができます。
クエリの最適化:
クエリ列の最適化: `SELECT *` の使用を避け、必要な列のみを選択して I/O とネットワーク転送を削減できます。
WHERE 句の最適化: `WHERE` 句でプライマリキーとインデックスフィールドを使用できます。
PREWHERE の使用: 複雑なフィルター条件の場合、
PREWHERE句を使用して事前にデータをフィルタリングし、後で処理するデータ量を減らすことができます。JOIN の最適化: 分散テーブルの場合、`GLOBAL JOIN` を使用して `JOIN` のパフォーマンスを向上させることができます。
パラメーター設定の最適化: クエリ設定を調整することでパフォーマンスを最適化できます。たとえば、
max_threadsを増やすと、より多くの CPU コアを利用できますが、過剰に構成してリソース競合を引き起こさないように注意してください。クエリパラメーターの詳細については、settings をご参照ください。クエリのパラメーター設定を表示する方法の詳細については、「ステップ 3: SQL パフォーマンスの分析」をご参照ください。マテリアライズドビュー: 頻繁に実行される複雑なクエリの場合、マテリアライズドビューを作成して結果を事前に計算し、クエリのパフォーマンスを向上させることができます。
データ圧縮: ClickHouse はデフォルトでデータ圧縮を有効にします。圧縮アルゴリズムとレベルを調整することで、ストレージとクエリのパフォーマンスをさらに最適化できます。
より大きなキャッシュの構成: 結果が頻繁に変わらない頻繁に実行されるクエリの場合、ApsaraDB for ClickHouse はクエリキャッシュを使用してパフォーマンスを向上させます。現在のキャッシュが不十分であるとわかった場合は、`uncompressed_cache_size` パラメーターを変更して、より大きなキャッシュスペースを設定できます。パラメーターの変更方法の詳細については、「config.xml パラメーターの設定」をご参照ください。