Service Mesh (ASM) でアプリケーションのサービスレベル目標 (SLO) を構成すると、Prometheus ルールが自動的に生成されます。このルールは、SLO メトリックの記録ルールと、エラーバジェット消費率のアラート機能ルールを定義します。これらの SLO をアクティブにするには、生成されたルールをご利用の Prometheus システムにインポートします。
次のプロシージャでは、Prometheus Operator で管理されるインスタンスにルールをインポートし、SLO メトリックとアラートが正しく機能することを確認する方法について説明します。
前提条件
開始する前に、以下が完了していることを確認してください。
Container Service for Kubernetes (ACK) クラスターで Prometheus モニタリングが有効になっていること。詳細については、「オープンソース Prometheus を使用した ACK クラスターのモニタリング」および「自己管理型 Prometheus インスタンスを使用した ASM インスタンスのモニタリング」をご参照ください。
Prometheus Operator によるルールの選択方法
Prometheus Operator は、カスタムリソース定義 (CRD) を使用して Prometheus 構成を管理します。記録ルールとアラート機能ルールを追加するには、PrometheusRule カスタムリソース (CR) を作成します。Prometheus Operator は、Prometheus CR の ruleSelector フィールドに基づいて、ロードする PrometheusRule オブジェクトを決定します。
ruleSelectorがmatchLabelsを指定している場合、PrometheusRuleは同じラベルを持つ必要があります。ruleSelectorが空の場合、ラベルはオプションです。
ご利用の Prometheus デプロイメントが Prometheus Operator を使用していない場合は、セットアップに適した方法を使用して生成されたルールをインポートしてください。ガイダンスについては、Prometheus ドキュメントをご参照ください。
ステップ 1: ruleSelector ラベルの取得
Prometheus Operator が PrometheusRule オブジェクトに必要とするラベルを決定するには、Prometheus CR の ruleSelector フィールドを確認します。
「ACK コンソール」にログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
「クラスター」ページで、管理するクラスターの名前をクリックし、左側のナビゲーションウィンドウで「ワークロード」>「カスタムリソース」を選択します。
[CRDs]タブで、[PrometheusRule]をクリックします。
[リソース オブジェクト] タブで、[名前空間] ドロップダウンリストから [モニタリング] を選択します。[ack-prometheus-operator-prometheus] を検索し、[操作] 列の [YAML の編集] をクリックします。
ruleSelectorフィールドを見つけます。一般的な構成は次のようになります。この例では、選択されるには、すべてのPrometheusRuleに両方のラベル (app: ack-prometheus-operatorとrelease: ack-prometheus-operator) が含まれている必要があります。ruleSelector: matchLabels: app: ack-prometheus-operator release: ack-prometheus-operator
ステップ 2: PrometheusRule のデプロイ
次の内容で
prometheusrule.yamlという名前のファイルを作成します。labelsフィールドを、ステップ 1 のmatchLabelsの値と一致するように設定します。specの内容を、ASM コンソールから生成された Prometheus ルールに置き換えます。
apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: app: ack-prometheus-operator release: ack-prometheus-operator name: asm-rules namespace: monitoring spec: # Replace with the generated Prometheus rule.PrometheusRuleをご利用の ACK クラスターに適用します。kubectl apply -f prometheusrule.yaml
ステップ 3: ルールがロードされていることの確認
PrometheusRule が適用されると、Prometheus Operator コントローラーはルール構成を Prometheus ConfigMap に自動的に書き込みます。ACK コンソールまたはコマンドラインのいずれかを通じてこれを確認します。
オプション A: ACK コンソール
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理対象のクラスターの名前をクリックし、左側のナビゲーションウィンドウで [設定] > [ConfigMap] を選択します。
「[ConfigMap]」ページで、[Namespace] ドロップダウンリストから [モニタリング] を選択し、Prometheus ConfigMap を見つけ、[操作] 列の [YAML の編集] をクリックします。
ASM SLO ルールが ConfigMap に表示されていることを確認します。次の図は、インポートが成功したことを示しています。

オプション B: コマンドライン
次のコマンドを実行して、PrometheusRule リソースを一覧表示します。
kubectl get prometheusrules -n monitoring出力には、asm-rules PrometheusRule が含まれている必要があります。
ステップ 4: SLO がアクティブであることの確認
記録ルールとアラート機能ルールの確認
ローカルポート 9090 を Prometheus サービスに転送します。
kubectl --namespace monitoring port-forward svc/ack-prometheus-operator-prometheus 9090ブラウザで http://localhost:9090 を開き、Prometheus コンソールにアクセスします。
[Prometheus] ページで、クエリボックスに
asm_slo_infoを入力し、[Execute] をクリックします。クエリで結果が返された場合、記録ルールはアクティブです。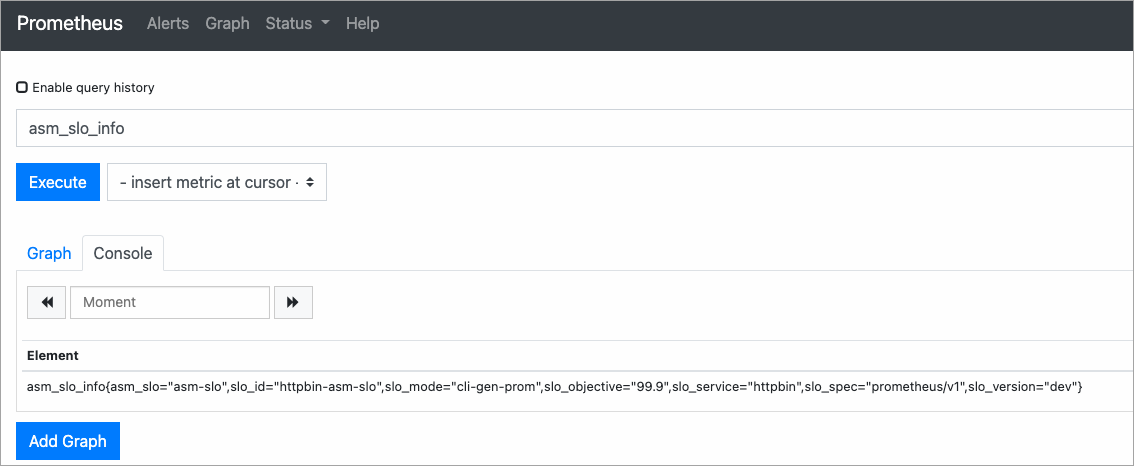
トップナビゲーションバーで、[アラート] をクリックして、アラートルールが読み込まれていることを確認します。

SLO メトリックを検証するためのトラフィックのシミュレーション
次のシナリオを使用して、メトリックとアラートが正しく応答することを確認します。
シナリオ 1: 通常トラフィック (成功率 99.5%)
このスクリプトは、200 のリクエストを送信し、そのうち 1 つだけが 500 エラーを返します。これにより、成功率 99.5% をシミュレートします。
#!/bin/bash
for i in $(seq 200)
do
if (( $i == 100 ))
then
curl -I http://<ingress-gateway-ip>/status/500;
else
curl -I http://<ingress-gateway-ip>/;
fi
echo "OK"
sleep 0.01;
done;<ingress-gateway-ip> をイングレスゲートウェイの IP アドレスに置き換えます。詳細については、「イングレスゲートウェイサービスのデプロイ」をご参照ください。
スクリプトが完了したら、Prometheus コンソールで slo:period_error_budget_remaining:ratio をクエリして、残りのエラーバジェットを確認します。1 に近い値は、ほとんどのバジェットが手つかずであることを示します。
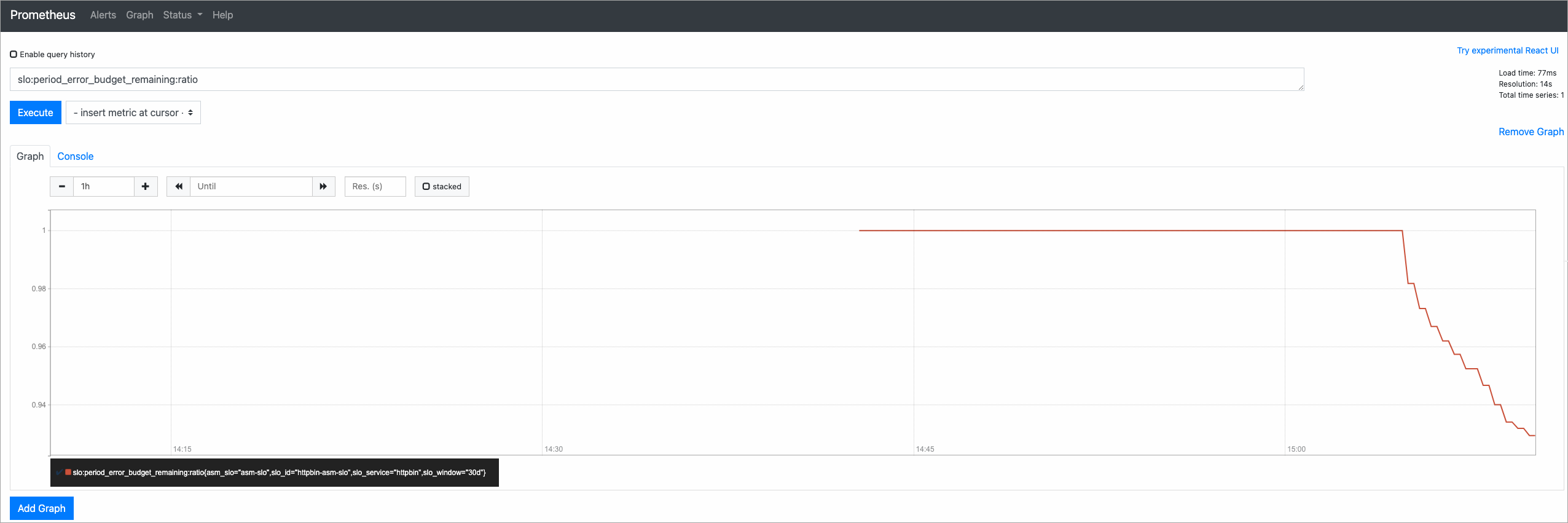
シナリオ 2: エラートラフィック (失敗率 50%)
このスクリプトは、成功と失敗のリクエストを交互に送信して、50% のエラー率をシミュレートし、消費率アラートをトリガーします。
#!/bin/bash
for i in $(seq 200)
do
curl -I http://<ingress-gateway-ip>/
curl -I http://<ingress-gateway-ip>/status/500;
echo "OK"
sleep 0.01;
done;スクリプトの実行が完了した後、Prometheus コンソールで [アラート] ページを開きます。バーンレートがしきい値を超えると、アラートが発生します。
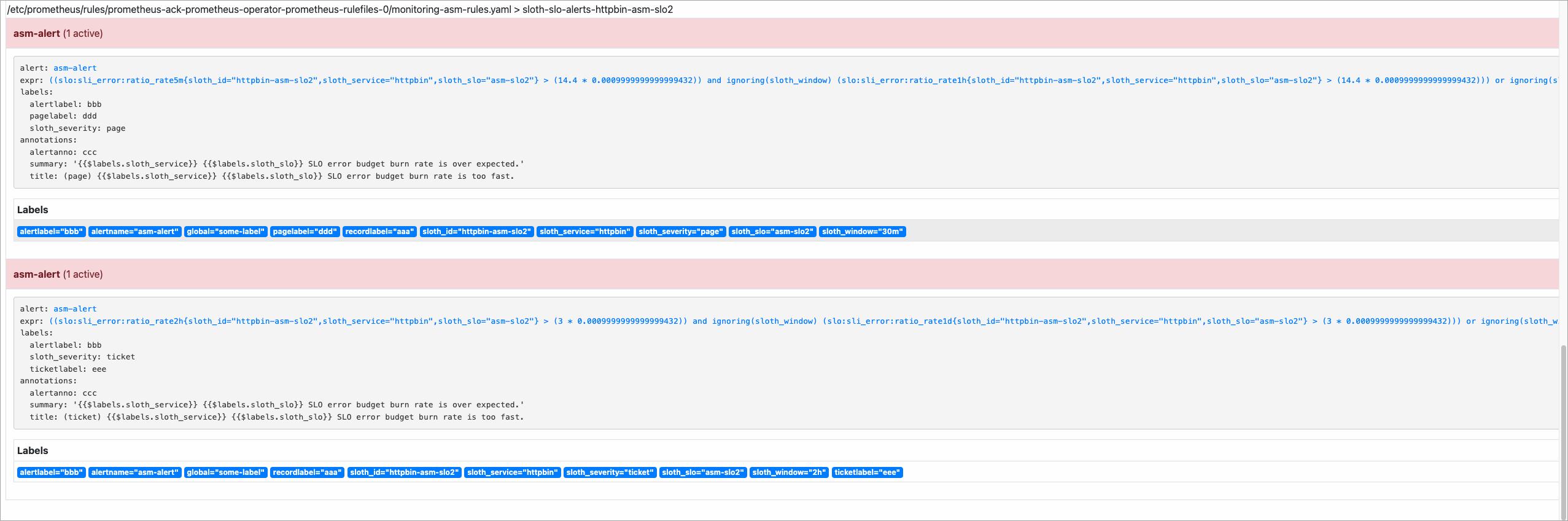
SLO メトリックリファレンス
次の表は、モニタリングに使用される SLO メトリックについて説明しています。エラーバジェットやマルチウィンドウ消費率アラート機能などの SLO の概念の詳細については、「SLO の概要」をご参照ください。
| メトリック | 説明 | 解釈 |
|---|---|---|
slo:period_error_budget_remaining:ratio | 30 日間のコンプライアンス期間中の残りのエラーバジェットの比率。 | 1 = 全予算利用可能。0 = 予算を使い果たした。0 から 1 の間の値は部分的な消費を示します。 |
slo:sli_error:ratio_rate30d | 30 日間のコンプライアンス期間中の平均エラー率。 | 値が低いほど、サービスの信頼性が高いことを示します。 |
slo:period_burn_rate:ratio | 30 日間のコンプライアンス期間中にエラーバジェットが消費されるレート。 | 1 = 予算が予想レートで正確に消費される。1 を超える値は、持続可能な消費よりも速い消費を示します。 |
slo:current_burn_rate:ratio | 短いタイムウィンドウに基づいた現在の消費率。 | 1 を超える値は、予算が持続可能な消費よりも速く消費されていることを示し、アラートをトリガーする可能性があります。 |
Alertmanager でのアラート表示
Alertmanager は Prometheus からアラートを収集し、メールや Webhook エンドポイントなどの構成済みレシーバーにルーティングします。
ローカルポート 9093 を Alertmanager サービスに転送します。
kubectl --namespace monitoring port-forward svc/ack-prometheus-operator-alertmanager 9093ブラウザで http://localhost:9093 を開き、Alertmanager コンソールにアクセスします。
「[Alertmanager]」ページで、
 アイコンをクリックして、アラートの詳細を展開して表示します。
アイコンをクリックして、アラートの詳細を展開して表示します。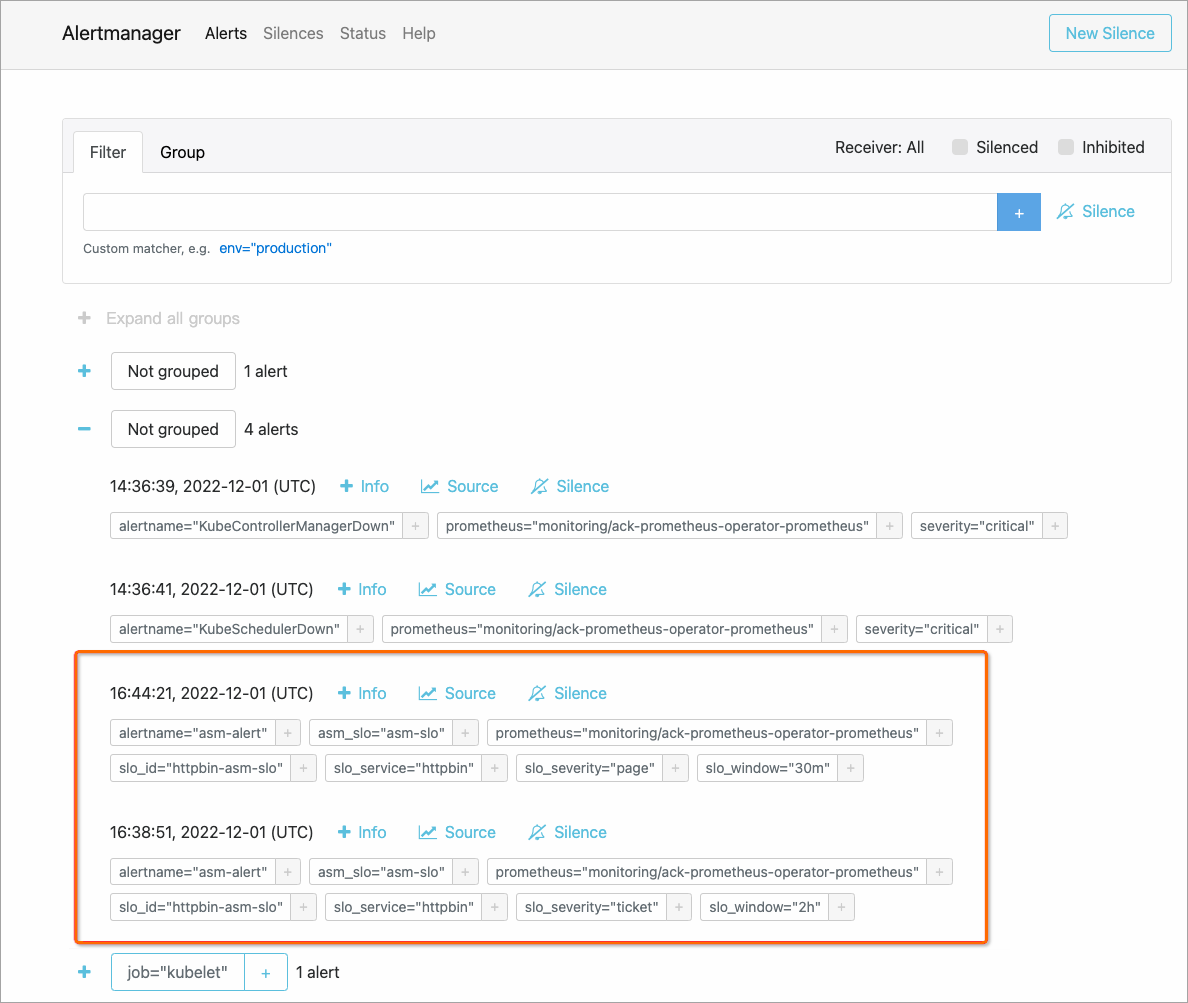
次のステップ
SLO ターゲットを追加または変更するには、「ASM でアプリケーションの SLO を構成」をご参照ください。
SLO の概念、メトリック、およびマルチウィンドウ消費率アラート機能の詳細については、「SLO の概要」をご参照ください。