Kubernetes クラスターに Low-Rank Adaptation(LoRA)テクノロジーに基づく微調整を伴う大規模言語モデル(LLM)をデプロイすることは、カスタマイズされた推論機能を提供するための柔軟で効率的な方法です。このトピックでは、Service Mesh (ASM)内でマルチ LoRA を使用して LLM 推論サービスを微調整する方法、さまざまな LoRA モデルのトラフィック分散ポリシーを定義する方法、および LoRA モデルのグレイリリースを実装する方法について説明します。
始める前に
このトピックを読む前に、以下を理解する必要があります:
Container Service for Kubernetes(ACK)クラスターに GPU アクセラレーションノードプールを追加する方法または ACK Pro クラスターで ACS の計算能力を使用する方法
このトピックを読むことで、以下について学ぶことができます:
LoRA およびマルチ LoRA テクノロジーの背景情報。
LoRA 微調整モデルのグレイリリースシナリオの実装原則。
マルチ LoRA テクノロジーを使用して LoRA モデルのグレイリリースを実装する手順。
背景情報
LoRA とマルチ LoRA
LoRA は、医療、金融、教育など、さまざまなセクターの特定のニーズに合わせて、費用対効果の高い方法で大規模言語モデル(LLM)を微調整するために広く採用されているテクノロジーです。これにより、推論のために単一のベース LLM に複数の LoRA モデルの重みをデプロイすることができ、マルチ LoRA テクノロジーとして知られる効率的な GPU リソースの共有が可能になります。 vLLM プラットフォームは、複数の LoRA モデルのロードと推論をサポートしています。
LoRA 微調整モデルのグレイリリースシナリオ
マルチ LoRA シナリオでは、複数の LoRA モデルを単一の LLM 推論サービスにロードできます。異なるモデルへのリクエストは、リクエスト内のモデル名によって区別され、さまざまな LoRA モデル間でグレイテストを実行して、ベース LLM に対する微調整の効果を評価できます。
前提条件
GPU ノードプールを持つ ACK マネージドクラスターを作成したか、GPU 計算能力のために推奨ゾーンで ACS クラスターを選択したことを確認します。詳細については、「ACK マネージドクラスターを作成する」および「ACS クラスターを作成する」をご参照ください。
ACK マネージドクラスターに ACK Virtual Node コンポーネントをインストールして、ACS GPU 計算機能を利用できます。詳細については、「ACK での ACS GPU 計算能力」をご参照ください。
v1.24 以降の ASM インスタンスにクラスターが追加されます。詳細については、「ASM インスタンスにクラスターを追加する」をご参照ください。
イングレスゲートウェイが作成され、ポート 8080 で HTTP サービスが有効になります。詳細については、「イングレスゲートウェイを作成する」をご参照ください。
(オプション) サイドカーがデフォルトの名前空間に挿入されます。詳細については、「サイドカープロキシの自動挿入を有効にする」をご参照ください。
説明可観測性の実際の操作を調べたくない場合は、サイドカーの挿入をスキップできます。
手順
このプラクティスでは、vLLM を使用してクラスターにベースモデルとして Llama2 ラージモデルをデプロイし、このベースモデルに基づいて sql-lora から sql-lora-4、および tweet-summary から tweet-summary-4 という名前の 10 個の LoRA モデルを登録します。必要に応じて、GPU アクセラレーションノードまたは ACS クラスターを持つ ACK クラスターで検証することを選択します。
ステップ 1: サンプルの LLM 推論サービスをデプロイする
以下に示すコンテンツを使用して vllm-service.yaml を作成します。
説明このトピックで説明されているイメージには、16 GiB 以上のビデオメモリを搭載した GPU が必要です。 16 GiB のビデオメモリを搭載した T4 カードタイプでは、このアプリケーションを起動するための十分なリソースが提供されません。 ACK クラスターには A10 カードタイプ、ACS クラスターには第 8 世代 GPU B を使用することをお勧めします。モデルの詳細については、チケットを送信してサポートを受けてください。
LLM イメージのサイズが大きいため、事前に ACR に保存し、プルに内部ネットワークアドレスを使用することをお勧めします。パブリックネットワークから直接プルすると、クラスターの EIP 帯域幅構成によっては、待機時間が長くなる可能性があります。
ACK クラスター
ACS クラスター
データプレーンのクラスターの kubeconfig ファイルを使用して、LLM 推論サービスをデプロイします。
kubectl apply -f vllm-service.yaml
ステップ 2: ASM ゲートウェイルールを構成する
ASM ゲートウェイでポート 8080 のリスニングを有効にするには、ゲートウェイルールをデプロイします。
次の内容で gateway.yaml という名前のファイルを作成します。
apiVersion: networking.istio.io/v1 kind: Gateway metadata: name: llm-inference-gateway namespace: default spec: selector: istio: ingressgateway servers: - hosts: - '*' port: name: http-service number: 8080 protocol: HTTPゲートウェイルールを作成します。
kubectl apply -f gateway.yaml
ステップ 3: LLM 推論サービスのルーティングと負荷分散を構成する
ASM kubeconfig を使用して、LLM 推論サービスのルーティングを有効にします。
kubectl patch asmmeshconfig default --type=merge --patch='{"spec":{"gatewayAPIInferenceExtension":{"enabled":true}}}'InferencePool リソースをデプロイします。
InferencePool リソースは、ラベルセレクターを介してクラスター内の一連の LLM 推論サービスワークロードを定義します。 ASM は、作成した InferencePool に基づいて、LLM 推論サービスの vLLM 負荷分散を有効にします。
以下に示すコンテンツを使用して inferencepool.yaml を作成します。
apiVersion: inference.networking.x-k8s.io/v1alpha1 kind: InferencePool metadata: name: vllm-llama2-7b-pool spec: targetPortNumber: 8000 selector: app: vllm-llama2-7b-poolデータプレーンクラスターの kubeconfig を使用して、InferencePool リソースを作成します。
kubectl apply -f inferencepool.yaml
InferenceModel リソースをデプロイします。
InferenceModel は、InferencePool 内の特定のモデルのトラフィック分散ポリシーを指定します。
以下に示すコンテンツを使用して inferencemodel.yaml を作成します。
apiVersion: inference.networking.x-k8s.io/v1alpha1 kind: InferenceModel metadata: name: inferencemodel-sample spec: modelName: lora-request poolRef: group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama2-7b-pool targetModels: - name: tweet-summary weight: 10 - name: tweet-summary-1 weight: 10 - name: tweet-summary-2 weight: 10 - name: tweet-summary-3 weight: 10 - name: tweet-summary-4 weight: 10 - name: sql-lora weight: 10 - name: sql-lora-1 weight: 10 - name: sql-lora-2 weight: 10 - name: sql-lora-3 weight: 10 - name: sql-lora-4 weight: 10この構成では、モデル名
lora-requestのリクエストの 50% が tweet-summary LoRA モデルに転送され、残りの 50% が sql-lora LoRA モデルに転送されます。InferenceModel リソースを作成します。
kubectl apply -f inferencemodel.yaml
LLMRoute リソースを作成します。
LLMRoute リソースを作成して、ゲートウェイのルーティングルールを設定します。これにより、ポート 8080 で受信されたすべてのリクエストが、InferencePool リソースを参照するサンプルの LLM 推論サービスに転送されます。
以下に示すコンテンツを使用して llmroute.yaml を作成します。
apiVersion: istio.alibabacloud.com/v1 kind: LLMRoute metadata: name: test-llm-route spec: gateways: - llm-inference-gateway host: test.com rules: - backendRefs: - backendRef: group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama2-7b-poolLLMRoute リソースを作成します。
kubectl apply -f llmroute.yaml
ステップ 4: 実行結果を確認する
次のコマンドを複数回実行して、テストを開始します。
curl -H "host: test.com" ${ASM gateway IP}:8080/v1/completions -H 'Content-Type: application/json' -d '{
"model": "lora-request",
"prompt": "Write as if you were a critic: San Francisco",
"max_tokens": 100,
"temperature": 0
}' -v次のような出力が表示されます。
{"id":"cmpl-2fc9a351-d866-422b-b561-874a30843a6b","object":"text_completion","created":1736933141,"model":"tweet-summary-1","choices":[{"index":0,"text":", I'm a newbie to this forum. Write a summary of the article.\nWrite a summary of the article.\nWrite a summary of the article. Write a summary of the article. Write a summary of the article. Write a summary of the article. Write a summary of the article. Write a summary of the article. Write a summary of the article. Write a summary of the article. Write a summary of the article. Write a summary","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":2,"total_tokens":102,"completion_tokens":100,"prompt_tokens_details":null}}model フィールドは、どのモデルがサービスを提供しているかを示しています。複数回のリクエストの後、tweet-summary モデルと sql-lora モデルのリクエスト量比が約 1:1 であることがわかります。
(オプション) ステップ 5: LLM サービスの可観測性メトリックとダッシュボードを構成する
InferencePool および InferenceMode リソースを使用してクラスター内の LLM 推論サービスを宣言し、ルーティングポリシーを設定した後、ログとモニタリングメトリックを介して LLM 推論サービスの可観測性を表示できます。
モニタリングメトリックを収集するには、ASM コンソールで LLM トラフィック可観測性機能を有効にします。
追加のログ フィールド、メトリック、およびメトリック ディメンションを組み込むことで、LLM 推論リクエストの可観測性を向上させます。詳細な構成手順については、「トラフィックの監視: ASM を使用して LLM トラフィックを効率的に管理する」をご参照ください。
構成が完了すると、
modelディメンションが ASM モニタリングメトリックに組み込まれます。これらのメトリックは、可観測性モニタリングフレームワーク内で Prometheus を利用するか、サービスメッシュモニタリング用にセルフホスト型 Prometheus を統合することで収集できます。ASM は 2 つの新しいメトリックを導入します。
asm_llm_proxy_prompt_tokens(入力トークンの数を表します)とasm_llm_proxy_completion_tokens(すべてのリクエストの出力トークンの数を表します)。これらのメトリックを組み込むには、Prometheus に次のルールを追加します。詳細については、「その他の Prometheus サービス検出構成」をご参照ください。scrape_configs: - job_name: asm-envoy-stats-llm scrape_interval: 30s scrape_timeout: 30s metrics_path: /stats/prometheus scheme: http kubernetes_sd_configs: - role: pod relabel_configs: - source_labels: - __meta_kubernetes_pod_container_port_name action: keep regex: .*-envoy-prom - source_labels: - __address__ - __meta_kubernetes_pod_annotation_prometheus_io_port action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:15090 target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: - __meta_kubernetes_namespace action: replace target_label: namespace - source_labels: - __meta_kubernetes_pod_name action: replace target_label: pod_name metric_relabel_configs: - action: keep source_labels: - __name__ regex: asm_llm_.*
vLLM サービスのモニタリングメトリックを収集します。
LLM 推論リクエストのモニタリングメトリックは、主に外部 LLM 推論リクエストのスループットに関係します。 vLLM サービスによって公開されているメトリックを収集し、その内部状態を監視するために、vLLM サービスポッドに Prometheus コレクターのアノテーションを追加します。
... annotations: prometheus.io/path: /metrics # メトリックが公開される HTTP パス prometheus.io/port: "8000" # メトリックが公開されるポート。vLLM サーバーのリスニングポートです。 prometheus.io/scrape: "true" # 現在のポッドのメトリックをスクレイプするかどうか ...Prometheus のデフォルトのサービス検出メカニズムを使用して、vLLM サービスに関連するメトリックを取得します。 詳細については、「デフォルトのサービス検出」をご参照ください。
vLLM サービスの主要なメトリックは、vLLM ワークロードの内部状態に関する洞察を提供します。
メトリック名
説明
vllm:gpu_cache_usage_perc
vLLM の GPU キャッシュ使用率。 vLLM が起動すると、KV キャッシュのためにできるだけ多くの GPU ビデオメモリを事前に占有します。 vLLM サーバーの場合、キャッシュ使用率が低いほど、GPU が新しいリクエストにリソースを割り当てるためのスペースが増えます。
vllm:request_queue_time_seconds_sum
待機状態キューで費やされた時間。 LLM 推論リクエストが vLLM サーバーに到着した後、すぐに処理されない場合があり、vLLM スケジューラがプリフィルとデコードをスケジュールするのを待つ必要があります。
vllm:num_requests_running
vllm:num_requests_waiting
vllm:num_requests_swapped
推論を実行中、待機中、およびメモリにスワップされたリクエストの数。 vLLM サービスの現在のリクエスト圧力を評価するために使用できます。
vllm:avg_generation_throughput_toks_per_s
vllm:avg_prompt_throughput_toks_per_s
プリフィルステージで消費され、デコードステージで生成される 1 秒あたりのトークン数。
vllm:time_to_first_token_seconds_bucket
リクエストが vLLM サービスに送信されてから最初のトークンが応答されるまでのレイテンシレベル。 このメトリックは通常、クライアントがリクエストコンテンツを出力してから最初の応答を取得するまでの時間を表し、LLM ユーザーエクスペリエンスに影響を与える重要なメトリックです。
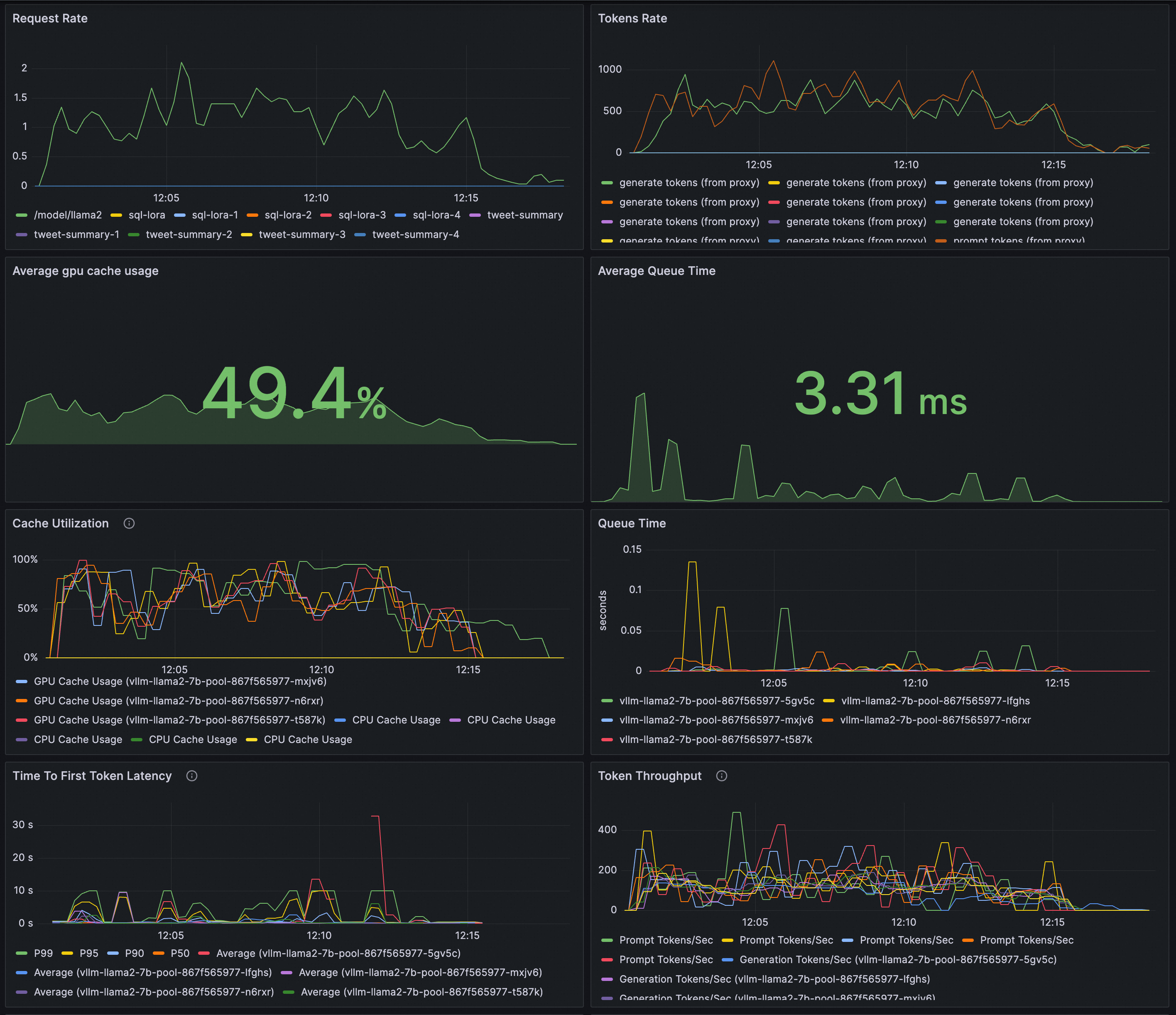
LLM 推論サービスを監視するための Grafana ダッシュボードを構成します。
Grafana ダッシュボードを介して vLLM でデプロイされた LLM 推論サービスを観測します。
ASM 監視メトリックを使用して、リクエストレートとトークンスループットを監視します。
vLLM 監視メトリックを使用して、LLM 推論サービスのワークロードの内部状態を評価します。
Grafana コンソールでデータソース(Prometheus インスタンス)を作成できます。 ASM および vLLM の監視メトリックが Prometheus インスタンスによって収集されていることを確認してください。
LLM 推論サービスの可観測性ダッシュボードを作成するには、以下に示すコンテンツを Grafana にインポートします。
Copyright 2023