Kafka の Topic 間でメッセージが流れる際、配信前にコンテンツの分割、ルーティング、エンリッチ、またはマスキングが必要になることがよくあります。データクレンジングは、Function Compute のテンプレートを利用して、これらの変換をインラインで処理します。
仕組み
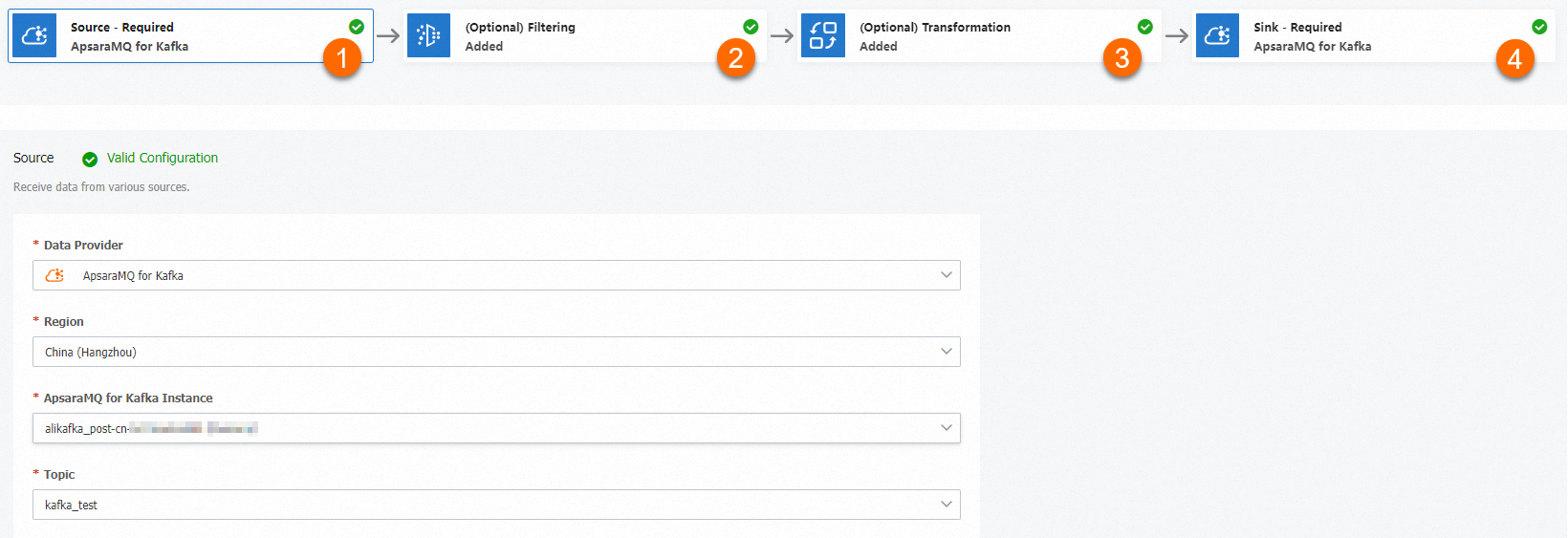
データクレンジングタスクは、4 段階のパイプラインに従います。
[ソース]:メッセージを消費する ApsaraMQ for Kafka インスタンスと Topic。
[フィルタリング] (オプション):処理するメッセージを選択するパターンマッチングルール。フィルターが設定されていない場合、すべてのメッセージが通過します。
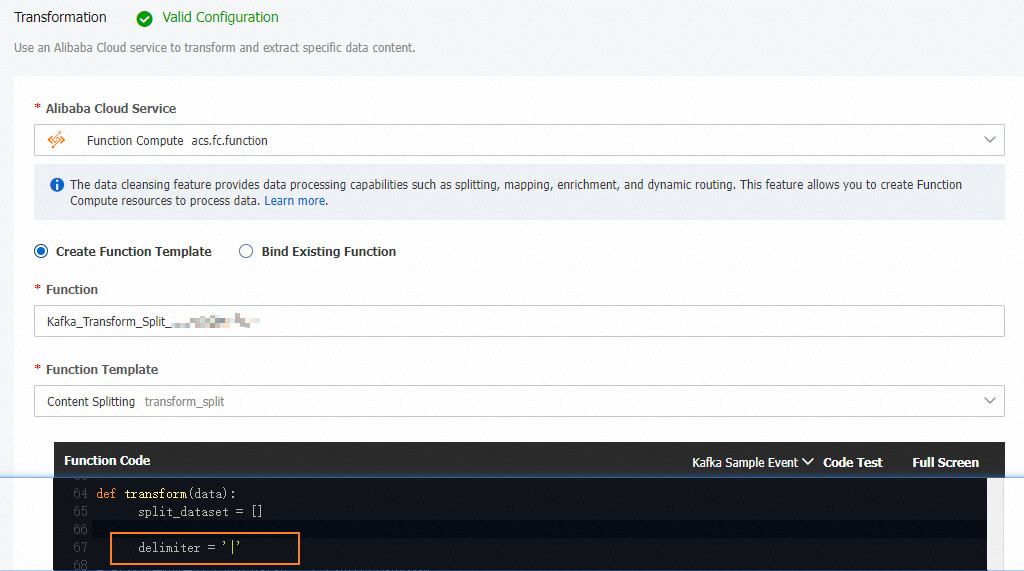
[変換]:メッセージ本文を処理する Function Compute テンプレート。コンテンツ分割、動的ルーティング、コンテンツエンリッチメント、コンテンツマッピングの 4 つの組み込みオペレーターが利用可能です。
[シンク]:処理されたメッセージを配信する ApsaraMQ for Kafka インスタンスと Topic。
タスクを作成すると、対応する関数が Function Compute コンソールに表示されます。それを開くと、テンプレートが提供する以上の処理ロジックを表示または編集できます。
データクレンジングは、ApsaraMQ for RocketMQ、ApsaraMQ for MQTT、ApsaraMQ for RabbitMQ、および Simple Message Queue (旧称:MNS) でも利用できます。
オペレーター
| オペレーター | 説明 |
|---|---|
| コンテンツ分割 | 正規表現に基づいて単一のメッセージを複数のメッセージに分割し、それぞれを個別にシンクに送信します。 |
| 動的ルーティング | メッセージ本文を正規表現と照合し、一致結果に基づいて各メッセージを異なる送信先 Topic にルーティングします。一致しなかったメッセージはデフォルトの Topic に送信されます。 |
| コンテンツエンリッチメント | メッセージ内のフィールドに基づいて外部データ (たとえば、MySQL データベースのデータ) を検索し、その結果をメッセージ本文に追加します。 |
| コンテンツマッピング | 正規表現を適用してメッセージ本文を変換します。たとえば、機密フィールドのマスキングやメッセージサイズの削減などです。 |
オペレーターの例
メッセージを個別のレコードに分割
複数のレコードを含む単一のメッセージを、レコードごとに 1 つの個別のメッセージに分割します。
入力:セミコロンで区切られた学生レコードのリストを含むメッセージ。
[Jack, Male, Class 4; Alice, Female, Class 3; John, Male, Class 4]出力:それぞれが 1 つの学生レコードを含む 3 つの個別のメッセージ。
[アリス、女性、クラス 3][Alice, Female, Class 3][John, Male, Class 4]
コンテンツパターンによるメッセージのルーティング
コンテンツパターンに基づいて、メッセージを異なる送信先 Topic にルーティングします。
入力:複数のブランドの商品エントリを含むメッセージ。
[BrandA, toothpaste, $12.98, 100g
BrandB, toothpaste, $7.99, 80g
BrandC, toothpaste, $1.99, 100g]ルーティングルール:
BrandAで始まるメッセージはBrandA-item-topicとBrandA-discount-topicに送信されます。BrandBで始まるメッセージはBrandB-item-topicとBrandB-discount-topicに送信されます。その他すべてのメッセージは
Unknown-brand-topicに送信されます。
これらのルールは JSON で定義されます。
{
"defaultTopic": "Unknown-brand-topic",
"rules": [
{
"regex": "^BrandA",
"targetTopics": [
"BrandA-item-topic",
"BrandA-discount-topic"
]
},
{
"regex": "^BrandB",
"targetTopics": [
"BrandB-item-topic",
"BrandB-discount-topic"
]
}
]
}
外部データによるメッセージのエンリッチメント
外部データソースでフィールド値を検索し、外部データをメッセージに追加します。
入力:アカウント ID とホスト IP を含むアクセスログエントリ。
{
"accountID": "164901546557****",
"hostIP": "192.168.XX.XX"
}エンリッチメントソース:IP アドレスをリージョンにマッピングする MySQL テーブル。
CREATE TABLE `tb_ip` (
`IP` VARCHAR(256) NOT NULL,
`Region` VARCHAR(256) NOT NULL,
`ISP` VARCHAR(256) NOT NULL,
PRIMARY KEY (`IP`)
);出力:region フィールドが追加された元のメッセージ。
{
"accountID": "164901546557****",
"hostIP": "192.168.XX.XX",
"region": "beijing"
}
メッセージ内の機密フィールドのマスク
正規表現を使用して、メッセージ内の特定のフィールドを変換またはマスクします。
入力:従業員 ID や電話番号などの機密データを含む従業員登録レコード。
James, Employee ID 1, 131 1111 1111
Mary, Employee ID 2, 132 2222 2222
David, Employee ID 3, 133 3333 3333出力:機密フィールドがマスクされた同じレコード。
Ja*, Employee ID *, ***********
Ma*, Employee ID *, ***********
Dav*, Employee ID *, ***********
データクレンジングタスクの作成
操作手順
ApsaraMQ for Kafka コンソールにログインします。左側のナビゲーションウィンドウで、 を選択します。[タスクの作成] をクリックします。
[タスクの作成] ページで 4 つのパイプラインステージを設定します。各テンプレートは基本的な処理ロジックを提供します。これをカスタマイズするには、タスク作成後に Function Compute コンソールで対応する関数を開きます。
ステージ 設定 [ソース] と [シンク] 異なる ApsaraMQ for Kafka インスタンスを選択します。 [フィルタリング] イベントをフィルターするためのマッチングルールを指定します。すべてのイベントをマッチングさせる場合は、空白のままにします。詳細については、「メッセージフィルタリング」をご参照ください。 [変換] Function Compute テンプレートを選択します: [コンテンツ分割]、[コンテンツマッピング]、[コンテンツエンリッチメント]、または [動的ルーティング]。この例では、[コンテンツ分割] テンプレートが選択されています。