このトピックでは、AnalyticDB for PostgreSQL の OpenAPI を活用し、Python を開発環境として、検索拡張生成(RAG)アプリケーションを迅速に構築する方法について説明します。
アーキテクチャ
RAG アーキテクチャは、大規模言語モデル(LLM)の機能を強化するために情報検索システムを活用します。これにより、業界特化データや自社独自の文書などの関連するコンテキスト情報を提供します。以下の図に RAG アーキテクチャを示します。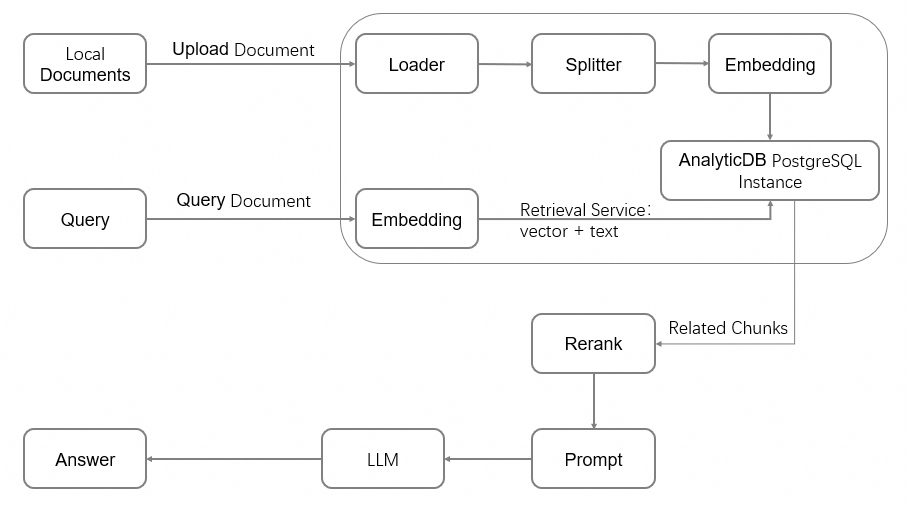
本クイックスタートでは、AnalyticDB for PostgreSQL が独自開発した FastANN ベクトルエンジンを使用します。OpenAPI を通じて文書処理機能を提供します。
OpenAPI は、以下の AI サービス機能をカプセル化しています:
マルチテナント管理。
文書処理:ロード、分割、埋め込み、およびマルチモード処理。
検索機能:ベクトル検索、フルテキストインデックス、および再ランキング。
事前準備
Alibaba Cloud アカウントが必要です。アカウントをお持ちでない場合は、Alibaba Cloud 公式サイトにて登録できます。
サービスリンクロールの権限付与。初めて AnalyticDB for PostgreSQL を使用する場合、コンソール上でサービスリンクロールの作成を許可する必要があります。以下の手順を実行してください:
- AnalyticDB for PostgreSQL コンソール にログインします。
ページ右上隅の インスタンス作成 をクリックします。
サービス関連付けの役割を作成する ダイアログボックスが表示されたら、OK をクリックします。
Alibaba Cloud アカウントまたは RAM ユーザーが、AnalyticDB for PostgreSQL の管理権限(権限)(AliyunGPDBFullAccess)を有している必要があります。
AccessKey の作成 を済ませている必要があります。
課金
インスタンスを作成すると、そのコンピューティングおよびストレージリソースに対して課金されます。詳細については、「課金」をご参照ください。
無料トライアル
Alibaba Cloud では、ストレージエラスティックモードのインスタンス向けに無料トライアルを提供しています。初めて AnalyticDB for PostgreSQL をご利用になる場合は、Alibaba Cloud 無料トライアル から無料トライアルを申請できます。無料トライアルの対象外の場合は、本トピックの手順に従ってコンソールからインスタンスを作成してください。
操作手順
インスタンスの作成
- AnalyticDB for PostgreSQL コンソール にログインします。
ページ右上隅の インスタンス作成 をクリックして購入ページを開きます。
インスタンス購入ページで、コアパラメーターを設定してインスタンスタイプを素早く選択します。その他のパラメーターはデフォルト値のままでも構いません。各パラメーターの詳細については、「インスタンスの作成」をご参照ください。
設定項目
説明
本チュートリアルの例
製品タイプ
サブスクリプション:前払い方式の課金方法です。インスタンス作成時に料金を支払います。長期利用に適しており、従量課金と比較してコスト効率が優れています。契約期間が長いほど割引率が高くなります。
従量課金:後払い方式の課金方法です。1 時間単位で課金されます。短期利用に適しています。使用後にすぐにインスタンスをリリースすることで、コストを節約できます。
従量課金
リージョンおよびゾーン
インスタンスの地理的位置です。
インスタンス作成後は、リージョンおよびゾーンを変更できません。接続したい ECS インスタンスと同じリージョンにインスタンスを作成してください。これにより、イントラネット相互通信が可能になります。
中国 (杭州):ゾーン J
インスタンスリソースタイプ
エラスティックストレージモード:独立したディスクのスケールアウトおよびスムーズなオンラインスケールアウトをサポートします。
Serverless Pro:必要なコンピューティングリソースのみを指定します。ストレージリソースを予約する必要はありません。
エラスティックストレージモード
データベースエンジンバージョン
より豊かな機能体験を得るために、7.0 Standard Edition を選択してください。6.0 Standard Edition もサポートされています。
7.0 Standard Edition
インスタンスエディション
パフォーマンス専有型(Basic Edition):ほとんどのビジネス分析シナリオに適しています。
High-availability Edition:コアビジネスサービスに推奨されます。
パフォーマンス専有型(Basic Edition)
ベクトルエンジン最適化
有効 を選択します。
有効
Virtual Private Cloud
VPC の ID を選択します。
同じリージョン内の ECS インスタンスとイントラネット相互通信を行うには、ECS インスタンスと同じ VPC を選択してください。既存の VPC を選択するか、ページに表示される指示に従って VPC および vSwitch を作成できます。
vpc-xxxx
vSwitch
VPC 内の vSwitch を選択します。利用可能な vSwitch がない場合は、該当ゾーンに vSwitch リソースがありません。別のゾーンに切り替えるか、ページに表示される指示に従って現在のゾーンで vSwitch を作成 できます。
vsw-xxxx
今すぐ購入 をクリックし、注文情報を確認して 今すぐアクティブ化 をクリックします。
支払いが完了したら、管理コンソール をクリックしてインスタンス一覧へ移動し、新規インスタンスを確認します。
説明AnalyticDB for PostgreSQL インスタンスの初期化には時間がかかります。次のステップに進む前に、インスタンスのステータスが 実行中 に変更されるのを待ってください。
初期アカウントの作成
AnalyticDB for PostgreSQL では、以下の 2 種類のユーザーが提供されます:
特権ユーザー:初期アカウントは、RDS_SUPERUSER ロールを持つ特権ユーザーであり、データベースに対するすべての操作権限を付与されます。
一般ユーザ:デフォルトでは、一般ユーザには権限が付与されていません。特権ユーザー、または GRANT 権限を持つ他のユーザーが、データベースオブジェクトに対する権限を明示的に一般ユーザに付与する必要があります。「ユーザーの作成および管理」をご参照ください。
左側のナビゲーションウィンドウで、アカウント管理 をクリックします。
初期アカウントの作成 をクリックします。アカウントの作成 ウィンドウで、アカウント名を入力し、パスワードを設定してから、OK をクリックします。
パラメーター
説明
アカウント
初期アカウントの名前です。
小文字、数字、アンダースコア(_)を含めることができます。
小文字で始まり、小文字または数字で終わる必要があります。
「gp」で始めてはいけません。
長さは 2~16 文字である必要があります。
新しいパスワード および パスワードの確認
初期アカウントのパスワードです。
大文字、小文字、数字、特殊文字のうち、少なくとも 3 種類を含める必要があります。
特殊文字には
! @ # $ % ^ & * ( ) _ + - =が含まれます。長さは 8~32 文字である必要があります。
重要セキュリティのため、定期的にパスワードを変更し、過去のパスワードを再利用しないでください。
開発環境の準備
Python 環境を確認します。
本チュートリアルでは Python 3 SDK を使用します。以下のコマンドを実行して、Python 3.9 以降および pip がインストールされているかを確認します。
Python が未インストールの場合、またはバージョンが要件を満たさない場合は、Python のインストール を行ってください。
python -V pip --versionSDK のインストール。
身分認証およびクライアント構築のため、
alibabacloud_gpdb20160503およびalibabacloud_tea_openapiSDK をインストールします。本チュートリアルで使用する SDK のバージョンは以下のとおりです。pip install --upgrade alibabacloud_gpdb20160503 alibabacloud_tea_openapi環境変数の設定。
身分認証情報やインスタンス ID などの機密情報を、ハードコーディングによる情報漏洩を防ぐために環境変数として設定します。
Linux および macOS
vim ~/.bashrcコマンドを実行して、~/.bashrcファイルを開きます。macOS の場合、
vim ~/.bash_profileを実行します。設定ファイルに以下の内容を追加します。
RAM ユーザー一覧ページでユーザー名をクリックし、RAM ユーザーの AccessKey ID および AccessKey シークレットを取得します。
AnalyticDB for PostgreSQL コンソール で、インスタンス ID およびリージョン ID を確認します。
# AccessKey ID を RAM ユーザーの AccessKey ID に置き換えます。 export ALIBABA_CLOUD_ACCESS_KEY_ID="access_key_id" # AccessKey シークレットを RAM ユーザーの AccessKey シークレットに置き換えます。 export ALIBABA_CLOUD_ACCESS_KEY_SECRET="access_key_secret" # AnalyticDB for PostgreSQL のインスタンス ID(例:gp-bp166cyrtr4p*****)に置き換えます。 export ADBPG_INSTANCE_ID="instance_id" # AnalyticDB for PostgreSQL インスタンスが配置されているリージョン ID(例:cn-hangzhou)に置き換えます。 export ADBPG_INSTANCE_REGION="instance_region"Vim エディターで Esc キーを押した後、
:wqを入力して保存・終了します。source ~/.bashrcコマンドを実行して、設定ファイルを有効化します。macOS の場合、
source ~/.bash_profileを実行します。
Windows
現在のセッションで一時的に環境変数を設定するには、CMD で以下のコマンドを実行します。
# AccessKey ID を RAM ユーザーの AccessKey ID に置き換えます。 set ALIBABA_CLOUD_ACCESS_KEY_ID=access_key_id # AccessKey シークレットを RAM ユーザーの AccessKey シークレットに置き換えます。 set ALIBABA_CLOUD_ACCESS_KEY_SECRET=access_key_secret # AnalyticDB for PostgreSQL のインスタンス ID(例:gp-bp166cyrtr4p*****)に置き換えます。 set ADBPG_INSTANCE_ID=instance_id # AnalyticDB for PostgreSQL インスタンスが配置されているリージョン ID(例:cn-hangzhou)に置き換えます。 set ADBPG_INSTANCE_REGION=instance_region
データベース環境の準備
操作手順
ベクトルデータベースの作成など、各種操作を実行するクライアントを構築します。
ベクトルデータベースの初期化。
すべてのベクトルデータは固定の `knowledgebase` データベースに格納されます。したがって、各インスタンスに対して 1 回だけ初期化を行います。ベクトルデータベースの初期化では、以下の操作が実行されます:
`knowledgebase` データベースを作成し、読み取りおよび書き込み権限を付与します。
中国語トークナイザおよびフルテキストインデックス関連機能を作成します。この機能はデータベースレベルです。
ドキュメントライブラリを作成するための名前空間を作成します。
チャンク化されたテキストおよびベクトルデータを格納するためのドキュメントライブラリ(DocumentCollection)を作成します。
サンプルコード
実行前に、account および account_password を実際のデータベースアカウントおよびパスワードに置き換えてください。その他の設定情報も必要に応じて変更できます。
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_gpdb20160503.client import Client
from alibabacloud_gpdb20160503 import models as gpdb_20160503_models
import os
# --- 環境変数から認証およびインスタンス情報を取得 ---
ALIBABA_CLOUD_ACCESS_KEY_ID = os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID']
ALIBABA_CLOUD_ACCESS_KEY_SECRET = os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET']
ADBPG_INSTANCE_ID = os.environ['ADBPG_INSTANCE_ID']
ADBPG_INSTANCE_REGION = os.environ['ADBPG_INSTANCE_REGION']
# AnalyticDB for PostgreSQL API クライアントを構築して返却
def get_client():
config = open_api_models.Config(
access_key_id=ALIBABA_CLOUD_ACCESS_KEY_ID,
access_key_secret=ALIBABA_CLOUD_ACCESS_KEY_SECRET
)
config.region_id = ADBPG_INSTANCE_REGION
# https://api.aliyun.com/product/gpdb
if ADBPG_INSTANCE_REGION in ("cn-beijing", "cn-hangzhou", "cn-shanghai", "cn-shenzhen", "cn-hongkong",
"ap-southeast-1"):
config.endpoint = "gpdb.aliyuncs.com"
else:
config.endpoint = f'gpdb.{ADBPG_INSTANCE_REGION}.aliyuncs.com'
return Client(config)
# ベクトルデータベースの初期化
def init_vector_database(account, account_password):
request = gpdb_20160503_models.InitVectorDatabaseRequest(
region_id=ADBPG_INSTANCE_REGION,
dbinstance_id=ADBPG_INSTANCE_ID,
manager_account=account,
manager_account_password=account_password
)
response = get_client().init_vector_database(request)
print(f"init_vector_database response code: {response.status_code}, body:{response.body}")
# 名前空間の作成
def create_namespace(account, account_password, namespace, namespace_password):
request = gpdb_20160503_models.CreateNamespaceRequest(
region_id=ADBPG_INSTANCE_REGION,
dbinstance_id=ADBPG_INSTANCE_ID,
manager_account=account,
manager_account_password=account_password,
namespace=namespace,
namespace_password=namespace_password
)
response = get_client().create_namespace(request)
print(f"create_namespace response code: {response.status_code}, body:{response.body}")
# ドキュメントコレクションの作成
def create_document_collection(account,
account_password,
namespace,
collection,
metadata: str = None,
full_text_retrieval_fields: str = None,
parser: str = None,
embedding_model: str = None,
metrics: str = None,
hnsw_m: int = None,
pq_enable: int = None,
external_storage: int = None,):
request = gpdb_20160503_models.CreateDocumentCollectionRequest(
region_id=ADBPG_INSTANCE_REGION,
dbinstance_id=ADBPG_INSTANCE_ID,
manager_account=account,
manager_account_password=account_password,
namespace=namespace,
collection=collection,
metadata=metadata,
full_text_retrieval_fields=full_text_retrieval_fields,
parser=parser,
embedding_model=embedding_model,
metrics=metrics,
hnsw_m=hnsw_m,
pq_enable=pq_enable,
external_storage=external_storage
)
response = get_client().create_document_collection(request)
print(f"create_document_collection response code: {response.status_code}, body:{response.body}")
if __name__ == '__main__':
# AnalyticDB for PostgreSQL インスタンスの初期データベースアカウント。
account = "testacc"
# 初期アカウントのパスワード。
account_password = "Test1234"
# 作成する名前空間の名前。
namespace = "ns1"
# 名前空間のパスワード。これは、後続のデータ読み取りおよび書き込み操作で使用されます。
namespace_password = "ns1password"
# 作成するドキュメントライブラリの名前。
collection = "dc1"
metadata = '{"title":"text", "page":"int"}'
full_text_retrieval_fields = "title"
embedding_model = "m3e-small"
init_vector_database(account, account_password)
create_namespace(account, account_password, namespace, namespace_password)
create_document_collection(account,account_password, namespace, collection,
metadata=metadata, full_text_retrieval_fields=full_text_retrieval_fields,
embedding_model=embedding_model)パラメーター
パラメーター | 説明 |
account | AnalyticDB for PostgreSQL インスタンスの初期データベースアカウントです。 |
account_password | 初期アカウントのパスワードです。 |
namespace | 作成する名前空間の名前です。 |
namespace_password | 名前空間のパスワードです。これは、後続のデータ読み取りおよび書き込み操作で使用されます。 |
collection | 作成するドキュメントライブラリの名前です。 |
metadata | カスタムマップ構造のメタデータです。キーはフィールド名、値はフィールド型です。 |
full_text_retrieval_fields | カスタムのカンマ区切りフルテキストインデックスフィールドです。これらのフィールドは、メタデータのキーである必要があります。 |
parser | フルテキストインデックス パラメーターで、トークナイザを指定します。デフォルト値は zh_cn です。 |
embedding_model | |
metrics | ベクトルインデックス パラメーターで、インデックスアルゴリズムです。 |
hnsw_m | ベクトルインデックス パラメーター:HNSW アルゴリズムにおける最大隣接数で、1~1000 の範囲です。 |
pq_enable | ベクトルインデックス パラメーターで、PQ(Product quantization)アルゴリズムによる高速化を有効にするかどうかを指定します。 |
external_storage | ベクトルインデックス パラメーターで、mmap キャッシュを使用するかどうかを指定します。 重要 external_storage パラメーターはバージョン 6.0 のみでサポートされています。バージョン 7.0 ではサポートされていません。 |
テーブルスキーマの確認
上記のコードが正常に実行された後、データベースにログインして、以下のようにテーブルスキーマを確認できます。
AnalyticDB for PostgreSQL コンソール にログインします。
対象インスタンスの製品ページ右上隅にある ログインデータベース をクリックできます。
インスタンスへのログイン ページで、データベースアカウント および データベースパスワード を入力し、ログイン をクリックします。
正常にログインすると、対象インスタンスに「knowledgebase」という新しいデータベースが表示されます。「knowledgebase」データベース内には「ns1」というスキーマが作成され、そのスキーマ下には「dc1」というテーブルが作成されます。テーブルスキーマは以下のとおりです。
フィールド | 型 | フィールド ソース | 説明 |
id | text | 固定フィールド | 主キーで、単一のテキストチャンクの UUID を表します。 |
vector | real[] | 固定フィールド | ベクトルデータの ARRAY。その長さは、指定された埋め込みモデルの次元数に対応します。 |
doc_name | text | 固定フィールド | ドキュメント名です。 |
content | text | 固定フィールド | ドキュメントが Loader および Splitter によって処理された後に得られる単一のテキストチャンクです。 |
loader_metadata | json | 固定フィールド | Loader による解析時に生成されるドキュメントのメタデータです。 |
to_tsvector | TSVECTOR | 固定フィールド | フルテキストインデックスフィールドを格納します。データソースは、full_text_retrieval_fields で指定されたフィールドデータです。「content」はデフォルトのフィールドです。本呼び出しシナリオでは、「content」と「title」の両方のデータソースからフルテキスト検索が実行されます。 |
title | text | メタデータ定義 | ユーザー定義です。 |
page | int | メタデータ定義 | ユーザー定義です。 |
ドキュメント管理
ドキュメントのアップロード。
本トピックでは、ローカルドキュメントの非同期アップロードを例として説明します。サンプルコードは以下のとおりです:
import time import io from typing import Dict, List, Any from alibabacloud_tea_util import models as util_models from alibabacloud_gpdb20160503 import models as gpdb_20160503_models def upload_document_async( namespace, namespace_password, collection, file_name, file_path, metadata: Dict[str, Any] = None, chunk_overlap: int = None, chunk_size: int = None, document_loader_name: str = None, text_splitter_name: str = None, dry_run: bool = None, zh_title_enhance: bool = None, separators: List[str] = None): with open(file_path, 'rb') as f: file_content_bytes = f.read() request = gpdb_20160503_models.UploadDocumentAsyncAdvanceRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=namespace, namespace_password=namespace_password, collection=collection, file_name=file_name, metadata=metadata, chunk_overlap=chunk_overlap, chunk_size=chunk_size, document_loader_name=document_loader_name, file_url_object=io.BytesIO(file_content_bytes), text_splitter_name=text_splitter_name, dry_run=dry_run, zh_title_enhance=zh_title_enhance, separators=separators, ) response = get_client().upload_document_async_advance(request, util_models.RuntimeOptions()) print(f"upload_document_async response code: {response.status_code}, body:{response.body}") return response.body.job_id def wait_upload_document_job(namespace, namespace_password, collection, job_id): def job_ready(): request = gpdb_20160503_models.GetUploadDocumentJobRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=namespace, namespace_password=namespace_password, collection=collection, job_id=job_id, ) response = get_client().get_upload_document_job(request) print(f"get_upload_document_job response code: {response.status_code}, body:{response.body}") return response.body.job.completed while True: if job_ready(): print("successfully load document") break time.sleep(2) if __name__ == '__main__': job_id = upload_document_async("ns1", "Ns1password", "dc1", "test.pdf", "/root/test.pdf") wait_upload_document_job("ns1", "Ns1password", "dc1", job_id)パラメーター
パラメーター
説明
namespace
ドキュメントライブラリが配置されている名前空間の名前です。
namespace_password
名前空間のパスワードです。
collection
ドキュメントを格納するドキュメントライブラリの名前です。
file_name
ドキュメント名(ファイル名拡張子を含む)です。
file_path
ローカルドキュメントのパスです。最大ファイルサイズは 200 MB です。
metadata
ドキュメントのメタデータです。ドキュメントライブラリ作成時に指定したメタデータと一致させる必要があります。
chunk_overlap
大規模データのチャンク分割戦略です。チャンク分割時に連続するチャンク間で重複するデータ量です。最大値は chunk_size を超えられません。
chunk_size
大規模データのチャンク分割戦略です。データを小さな部分に分割する際の各チャンクのサイズです。最大値は 2048 です。
document_loader_name
未指定の場合は、ファイル名拡張子に基づいて自動的にローダーが選択されます。詳細については、「ドキュメント理解」をご参照ください。
text_splitter_name
チャンカーの名前です。ドキュメントチャンク分割の詳細については、「ドキュメントチャンク分割」をご参照ください。
dry_run
ドキュメント理解およびチャンク分割のみを実行し、ベクトル化およびストレージは実行しないかどうかを指定します。有効な値は以下のとおりです:
true:ドキュメント理解およびチャンク分割のみを実行します。
false(デフォルト):まずドキュメント理解およびチャンク分割を実行し、その後ベクトル化およびストレージを実行します。
zh_title_enhance
中国語タイトル強化を有効にするかどうかを指定します。有効な値は以下のとおりです:
true:中国語タイトル強化を有効にします。
false:中国語タイトル強化を無効にします。
separators
大規模データチャンク分割戦略のデリミタです。通常、このパラメーターを指定する必要はありません。
(任意)その他のドキュメント管理操作。
ドキュメント一覧の確認
def list_documents(namespace, namespace_password, collection): request = gpdb_20160503_models.ListDocumentsRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=namespace, namespace_password=namespace_password, collection=collection, ) response = get_client().list_documents(request) print(f"list_documents response code: {response.status_code}, body:{response.body}") if __name__ == '__main__': list_documents("ns1", "Ns1password", "dc1")パラメーター
パラメーター
説明
namespace
ドキュメントライブラリが配置されている名前空間の名前です。
namespace_password
名前空間のパスワードです。
collection
ドキュメントライブラリの名前です。
ドキュメント詳細の確認
def describe_document(namespace, namespace_password, collection, file_name): request = gpdb_20160503_models.DescribeDocumentRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=namespace, namespace_password=namespace_password, collection=collection, file_name=file_name ) response = get_client().describe_document(request) print(f"describe_document response code: {response.status_code}, body:{response.body}") if __name__ == '__main__': describe_document("ns1", "Ns1password", "dc1", "test.pdf")パラメーター
パラメーター
説明
namespace
ドキュメントライブラリが配置されている名前空間の名前です。
namespace_password
名前空間のパスワードです。
collection
ドキュメントライブラリの名前です。
file_name
ドキュメント名です。
応答パラメーター
パラメーター
説明
DocsCount
ドキュメントが分割されたチャンクの数です。
TextSplitter
ドキュメントスプリッターの名前です。
DocumentLoader
ドキュメントローダーの名前です。
FileExt
ドキュメントのファイル名拡張子です。
FileMd5
ドキュメントの MD5 ハッシュ値です。
FileMtime
ドキュメントの最新アップロード時間です。
FileSize
ファイルサイズ(バイト単位)です。
FileVersion
ドキュメントのバージョンで、INT 型です。ドキュメントがアップロードおよび更新された回数を示します。
ドキュメントの削除
def delete_document(namespace, namespace_password, collection, file_name): request = gpdb_20160503_models.DeleteDocumentRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=namespace, namespace_password=namespace_password, collection=collection, file_name=file_name ) response = get_client().delete_document(request) print(f"delete_document response code: {response.status_code}, body:{response.body}") if __name__ == '__main__': delete_document("ns1", "Ns1password", "dc1", "test.pdf")パラメーター
パラメーター
説明
namespace
ドキュメントライブラリが配置されている名前空間の名前です。
namespace_password
名前空間のパスワードです。
collection
ドキュメントライブラリの名前です。
file_name
ドキュメント名です。
ドキュメント取得
本セクションでは、プレーンテキスト取得を例として説明します。サンプルコードは以下のとおりです:
def query_content(namespace, namespace_password, collection, top_k,
content,
filter_str: str = None,
metrics: str = None,
use_full_text_retrieval: bool = None):
request = gpdb_20160503_models.QueryContentRequest(
region_id=ADBPG_INSTANCE_REGION,
dbinstance_id=ADBPG_INSTANCE_ID,
namespace=namespace,
namespace_password=namespace_password,
collection=collection,
content=content,
filter=filter_str,
top_k=top_k,
metrics=metrics,
use_full_text_retrieval=use_full_text_retrieval,
)
response = get_client().query_content(request)
print(f"query_content response code: {response.status_code}, body:{response.body}")
if __name__ == '__main__':
query_content('ns1', 'Ns1password', 'dc1', 10, 'What is ADBPG?')パラメーター
パラメーター | 説明 |
namespace | ドキュメントライブラリが配置されている名前空間の名前です。 |
namespace_password | 名前空間のパスワードです。 |
collection | ドキュメントライブラリの名前です。 |
top_k | 返却する上位 k 個の取得結果の数です。 |
content | 取得対象のテキストコンテンツです。 |
filter_str | 取得前のフィルター文です。 |
metrics | ベクトル距離アルゴリズムです。このパラメーターを設定しないことを推奨します。インデックス作成時に使用したアルゴリズムが計算に使用されます。 |
use_full_text_retrieval | フルテキストインデックスを使用するかどうかを指定します。有効な値は以下のとおりです:
|
応答パラメーター
パラメーター | 説明 |
Id | 分割後のチャンクの UUID です。 |
FileName | ドキュメント名です。 |
Content | 取得されたコンテンツで、分割後のチャンクです。 |
LoaderMetadata | ドキュメントアップロード時に生成されたメタデータです。 |
Metadata | ユーザー定義のメタデータです。 |
RetrievalSource | 取得ソースです。有効な値は以下のとおりです:
|
Score | 指定された類似度アルゴリズムに基づいて算出された類似度スコアです。 |
LangChain との統合
LangChain は、大規模言語モデル(LLM)に基づくアプリケーションを構築するためのオープンソースフレームワークです。一連のインターフェイスおよびツールを通じて、モデルを外部データと接続します。本セクションでは、AnalyticDB for PostgreSQL の取得機能を LangChain に統合し、Q&A システムを実装する方法について説明します。
モジュールのインストール。
pip install --upgrade langchain openai tiktokenAdbpgRetriever の構築。
from langchain_core.retrievers import BaseRetriever from langchain_core.callbacks import CallbackManagerForRetrieverRun from langchain_core.documents import Document class AdbpgRetriever(BaseRetriever): namespace: str = None namespace_password: str = None collection: str = None top_k: int = None use_full_text_retrieval: bool = None def query_content(self, content) -> List[gpdb_20160503_models.QueryContentResponseBodyMatchesMatchList]: request = gpdb_20160503_models.QueryContentRequest( region_id=ADBPG_INSTANCE_REGION, dbinstance_id=ADBPG_INSTANCE_ID, namespace=self.namespace, namespace_password=self.namespace_password, collection=self.collection, content=content, top_k=self.top_k, use_full_text_retrieval=self.use_full_text_retrieval, ) response = get_client().query_content(request) return response.body.matches.match_list def _get_relevant_documents( self, query: str, *, run_manager: CallbackManagerForRetrieverRun ) -> List[Document]: match_list = self.query_content(query) return [Document(page_content=i.content) for i in match_list]チェーンの作成。
from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain.schema import StrOutputParser from langchain_core.runnables import RunnablePassthrough OPENAI_API_KEY = "YOUR_OPENAI_API_KEY" os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY template = """質問に回答するには、以下のコンテキストのみを使用してください: {context} 質問:{question} """ prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() def format_docs(docs): return "\n\n".join([d.page_content for d in docs]) retriever = AdbpgRetriever(namespace='ns1', namespace_password='Ns1password', collection='dc1', top_k=10, use_full_text_retrieval=True) chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | model | StrOutputParser() )Q&A。
chain.invoke("What is AnalyticDB PostgreSQL?") # 応答: # AnalyticDB PostgreSQL は、Alibaba Cloud が提供するクラウドネイティブのオンライン分析処理(OLAP)サービスです。オープンソースの PostgreSQL データベース拡張に基づき、高性能かつ大容量のデータウェアハウスソリューションを提供します。 # これは、PostgreSQL の柔軟性および互換性と、データ分析およびレポート向けの高い同時実行性および高速クエリ性能を組み合わせたものです。 # # AnalyticDB PostgreSQL は、大規模データセットの処理に特に適しており、リアルタイム分析および意思決定支援をサポートします。企業がデータマイニング、ビジネスインテリジェンス(BI)、レポート、およびデータ可視化を実行するための強力なツールです。 # マネージドサービスとして、データウェアハウスの管理および運用保守(O&M)を簡素化し、ユーザーがインフラストラクチャの下層ではなくデータ分析に集中できるようにします。 # 主な特徴は以下のとおりです: # # 高性能分析:列指向ストレージおよび Massively Parallel Processing(MPP)アーキテクチャを採用し、大量のデータを迅速にクエリおよび分析します。 # 容易なスケーラビリティ:データ量およびクエリ性能要件に応じて、リソースを水平および垂直方向に容易にスケールできます。 # PostgreSQL 互換性:PostgreSQL SQL 言語および PostgreSQL エコシステムのほとんどのツールをサポートするため、既存の PostgreSQL ユーザーが簡単に移行および適応できます。 # セキュリティおよび信頼性:データのバックアップ、回復、暗号化などの機能を提供し、データのセキュリティおよび信頼性を確保します。 # クラウドネイティブ統合:Data Integration やデータ可視化ツールなど、他の Alibaba Cloud サービスと緊密に統合されています。 # まとめると、AnalyticDB PostgreSQL は、クラウド環境で複雑なデータ分析およびレポートを実行するための高性能かつスケーラブルなクラウドデータウェアハウスサービスです。
付録
フルテキストインデックス
取得精度を向上させるため、AnalyticDB for PostgreSQL は、ベクトル類似度に加えてフルテキストインデックスをサポートしています。また、ベクトル類似度取得と同時に使用することで、二重パス取得を実現できます。
フルテキストインデックスフィールドの定義。
フルテキストインデックスを使用する前に、フルテキストインデックスのデータソースとなるフィールドを指定する必要があります。ドキュメントライブラリインタフェースでは、デフォルトで `content` フィールドが使用されます。その他のカスタムメタデータフィールドも指定できます。
トークン化
ドキュメントライブラリを作成する際に、`Parser` フィールドをトークナイザとして指定できます。ほとんどの場合、デフォルトの中国語 `zh_cn` を使用します。特殊なトークン化文字要件がある場合は、Alibaba Cloud の技術サポートにお問い合わせください。
データを挿入する際、トークナイザは指定されたフルテキストインデックスフィールドのデータをデリミタに基づいて分割し、後続のフルテキストインデックス使用のために `to_tsvector` に保存します。
埋め込みモデル
AnalyticDB for PostgreSQL は、以下の埋め込みモデルをサポートしています:
embedding_model | ディメンション | 説明 |
m3e-small | 512 | moka-ai/m3e-small 由来。中国語のみをサポートし、英語はサポートしません。 |
m3e-base | 768 | moka-ai/m3e-base 由来。中国語および英語をサポートします。 |
text2vec | 1024 | GanymedeNil/text2vec-large-chinese 由来。中国語および英語をサポートします。 |
text-embedding-v1 | 1536 | Alibaba Cloud Model Studio の汎用テキスト埋め込み由来。中国語および英語をサポートします。 |
text-embedding-v2 | 1536 | text-embedding-v1 のアップグレード版です。 |
clip-vit-b-32(マルチモーダル) | 512 | 画像をサポートするオープンソースのマルチモーダルモデルです。 |
カスタム埋め込みモデルは、現時点ではサポートされていません。
さらに多くのモデルがサポートされています。詳細については、「ドキュメントライブラリの作成」をご参照ください。
ベクトルインデックス
ベクトルインデックスは、以下のパラメーターをサポートしています:
パラメーター | 説明 |
metrics | 類似度距離計測アルゴリズムです。有効な値は以下のとおりです:
|
hnsw_m | HNSW アルゴリズムにおける最大隣接数です。OpenAPI は、ベクトルのディメンションに応じて自動的に異なる値を設定します。 |
pq_enable | PQ ベクトル次元削減機能を有効にするかどうかを指定します。有効な値は以下のとおりです:
PQ ベクトル次元削減は、既存のベクトルサンプルデータに基づいて学習を行います。データ量が 500,000 未満の場合、このパラメーターを設定しないことを推奨します。 |
external_storage | mmap を使用して HNSW インデックスを構築するかどうかを指定します。有効な値は以下のとおりです:
重要 external_storage パラメーターはバージョン 6.0 のみでサポートされています。バージョン 7.0 ではサポートされていません。 |
ドキュメント理解
ドキュメントの種類に応じて、適切なローダーを選択します:
UnstructuredHTMLLoader:
.htmlUnstructuredMarkdownLoader:
.mdPyMuPDFLoader:
.pdfPyPDFLoader:
.pdfRapidOCRPDFLoader:
.pdfJSONLoader:
.jsonCSVLoader:
.csvRapidOCRLoader:
.png、.jpg、.jpeg、または.bmpUnstructuredFileLoader:
.eml、.msg、.rst、.txt、.xml、.docx、.epub、.odt、.pptx、または.tsv
`document_loader_name` を指定しない場合、ドキュメントのファイル名拡張子に基づいて自動的にローダーが決定されます。PDF のように複数のローダーが存在するドキュメントタイプの場合は、いずれかを指定できます。
ドキュメントチャンク分割
ドキュメントチャンク分割の効果は、`chunk_overlap`、`chunk_size`、`text_splitter_name`、および によって決まります。`text_splitter_name` の有効な値は以下のとおりです:
ChineseRecursiveTextSplitter:RecursiveCharacterTextSplitter を継承しています。デフォルトのデリミタとして
["\n\n","\n", "。|!|?","\.\s|\!\s|\?\s", ";|;\s", ",|,\s"]を使用し、正規表現によるマッチングを行います。中国語テキストに対しては RecursiveCharacterTextSplitter よりも優れた性能を発揮します。SpacyTextSplitter は、
["\n\n", "\n", " ", ""]をデフォルトの区切り文字として使用します。これは、c++、go、java、js、php、proto、python、rst、ruby、rust、scala、swift、markdown、latex、html、sol、csharpなどの複数のプログラミング言語のチャンキングをサポートします。RecursiveCharacterTextSplitter:デフォルトのデリミタは
\n\nです。Spacy ライブラリの en_core_web_sm モデルを使用して分割を行い、英語ドキュメントに対して良好な性能を発揮します。MarkdownHeaderTextSplitter:Markdown タイプの場合、
[ ("#", "head1"), ("##", "head2"), ("###", "head3"), ("####", "head4") ]を使用して分割します。