Arena を使用して DeepSpeed 分散トレーニングジョブを実行し、TensorBoard を使用して結果を可視化します。
前提条件
開始する前に、以下を確認してください:
-
GPU 加速ノードを備えた Container Service for Kubernetes (ACK) クラスター。 詳細については、「GPU 加速ノードを備えた ACK クラスターの作成」をご参照ください。
-
バージョン 0.9.10 以降の
ack-arenaCLI を含む、クラウドネイティブ AI スイートがインストールされていること。 詳細については、「クラウドネイティブ AI スイートのデプロイ」をご参照ください。 -
バージョン 0.9.10 以降の Arena クライアントがインストールされていること。 詳細については、「Arena クライアントの設定」をご参照ください。
-
クラスター内に永続ボリューム要求 (PVC) が作成されていること。 詳細については、「共有 NAS ボリュームの設定」をご参照ください。
仕組み
ACK での DeepSpeed ジョブは、ランチャー・ワーカーのトポロジーで実行されます:
-
ランチャーノードは、分散トレーニングの実行を調整します。ランチャーノードは GPU を使用しません。
-
ワーカーノードは、実際のトレーニングを実行します。各ワーカーは 1 つ以上の GPU を受け取り、DeepSpeed トレーニングスクリプトを実行します。
ノード間の通信には SSH を使用するため、すべてのイメージに OpenSSH がインストールされている必要があります。
トレーニングジョブには、パスワードレス SSH を通じてのみアクセスします。本番環境では Kubernetes Secret を保護してください。
サンプル設定
このガイドでは、マスクされた言語モデルをトレーニングするサンプルを使用します。microsoft/DeepSpeedExamples のサンプルコードとデータセットは、イメージ registry.cn-beijing.aliyuncs.com/acs/deepspeed:hello-deepspeed にプリパッケージされています。このサンプルでは、training-data という名前の PVC (共有 NAS ボリュームでバックアップ) を使用してトレーニング結果を保存します。
カスタムイメージの使用
独自のトレーニングコードを使用するには、次のいずれかのアプローチを選択します:
-
ACK DeepSpeed ベースイメージからビルド:
registry.cn-beijing.aliyuncs.com/acs/deepspeed:v072_base -
独自のベースイメージからビルド: Dockerfile に従い、イメージに OpenSSH をインストールします。
プライベート Git リポジトリからのコードの同期
--sync-mode=git と --sync-source を渡して、ランタイムにトレーニングコードをプルします。Arena は git-sync を使用してリポジトリを同期します。GIT_SYNC_USERNAME および GIT_SYNC_PASSWORD 環境変数を使用して認証情報を設定します。
DeepSpeed ジョブの送信と監視
ステップ 1:利用可能な GPU リソースの確認
arena top node期待される出力:
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated)
cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 0 0
cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 0 0
cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 0
cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 0
cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 0
---------------------------------------------------------------------------------------------------
Allocated/Total GPUs In Cluster:
0/3 (0.0%)3 つの GPU 加速ノードが利用可能です。
ステップ 2:DeepSpeed ジョブの送信
次のコマンドは、1 つのランチャーノードと 3 つのワーカーノード (それぞれが 1 つの GPU を使用) を持つ deepspeed-helloworld という名前のジョブを送信します:
arena submit deepspeedjob \
--name=deepspeed-helloworld \
--gpus=1 \
--workers=3 \
--image=registry.cn-beijing.aliyuncs.com/acs/deepspeed:hello-deepspeed \
--data=training-data:/data \
--tensorboard \
--logdir=/data/deepspeed_data \
"deepspeed /workspace/DeepSpeedExamples/HelloDeepSpeed/train_bert_ds.py --checkpoint_dir /data/deepspeed_data"パラメーター
| パラメーター | 必須 | 説明 | デフォルト |
|---|---|---|---|
--name |
はい | グローバルに一意のジョブ名 | — |
--image |
はい | ランタイム用のコンテナイメージ | — |
--gpus |
いいえ | 各ワーカーノードに割り当てられる GPU | 0 |
--workers |
いいえ | ワーカーノードの数 | 1 |
--data |
いいえ | ランタイムに PVC をマウントします。フォーマット: <pvc-name>:<mount-path>。arena data list を実行して、利用可能な PVC を表示します。 |
— |
--tensorboard |
いいえ | TensorBoard サービスを有効にします。--logdir と一緒に使用する必要があります。 |
— |
--logdir |
いいえ | TensorBoard がイベントファイルを読み取るパス。--tensorboard と一緒に使用する必要があります。 |
/training_logs |
イメージにバンドルする代わりにプライベート Git リポジトリからコードを同期するには、これらのフラグを追加します:
arena submit deepspeedjob \
...
--sync-mode=git \
--sync-source=<private-git-repo-url> \
--env=GIT_SYNC_USERNAME=<username> \
--env=GIT_SYNC_PASSWORD=<password> \
"deepspeed /workspace/DeepSpeedExamples/HelloDeepSpeed/train_bert_ds.py --checkpoint_dir /data/deepspeed_data"送信後の期待される出力:
trainingjob.kai.alibabacloud.com/deepspeed-helloworld created
INFO[0007] The Job deepspeed-helloworld has been submitted successfully
INFO[0007] You can run `arena get deepspeed-helloworld --type deepspeedjob` to check the job statusステップ 3:ジョブが実行中であることの確認
すべての Arena トレーニングジョブをリスト表示します:
arena list期待される出力:
NAME STATUS TRAINER DURATION GPU(Requested) GPU(Allocated) NODE
deepspeed-helloworld RUNNING DEEPSPEEDJOB 3m 3 3 192.168.9.69ジョブごとの GPU 使用量を確認します:
arena top job期待される出力:
NAME STATUS TRAINER AGE GPU(Requested) GPU(Allocated) NODE
deepspeed-helloworld RUNNING DEEPSPEEDJOB 4m 3 3 192.168.9.69
Total Allocated/Requested GPUs of Training Jobs: 3/3クラスター全体の GPU 使用量を確認します:
arena top node期待される出力:
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated)
cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 0 0
cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 0 0
cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 1
cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 1
cn-beijing.192.1xx.x.xx 192.1xx.x.xx <none> Ready 1 1
---------------------------------------------------------------------------------------------------
Allocated/Total GPUs In Cluster:
3/3 (100%)ステップ 4:ジョブ詳細と TensorBoard URL の取得
arena get deepspeed-helloworld期待される出力:
Name: deepspeed-helloworld
Status: RUNNING
Namespace: default
Priority: N/A
Trainer: DEEPSPEEDJOB
Duration: 6m
Instances:
NAME STATUS AGE IS_CHIEF GPU(Requested) NODE
---- ------ --- -------- -------------- ----
deepspeed-helloworld-launcher Running 6m true 0 cn-beijing.192.1xx.x.x
deepspeed-helloworld-worker-0 Running 6m false 1 cn-beijing.192.1xx.x.x
deepspeed-helloworld-worker-1 Running 6m false 1 cn-beijing.192.1xx.x.x
deepspeed-helloworld-worker-2 Running 6m false 1 cn-beijing.192.1xx.x.x
Your tensorboard will be available on:
http://192.1xx.x.xx:31870最後の 2 行は、TensorBoard が有効になっている場合にのみ表示されます。
ステップ 5:TensorBoard でのトレーニング結果の表示
-
TensorBoard サービスをローカルポートに転送します:
kubectl port-forward svc/deepspeed-helloworld-tensorboard 9090:6006 -
ブラウザで
localhost:9090を開きます。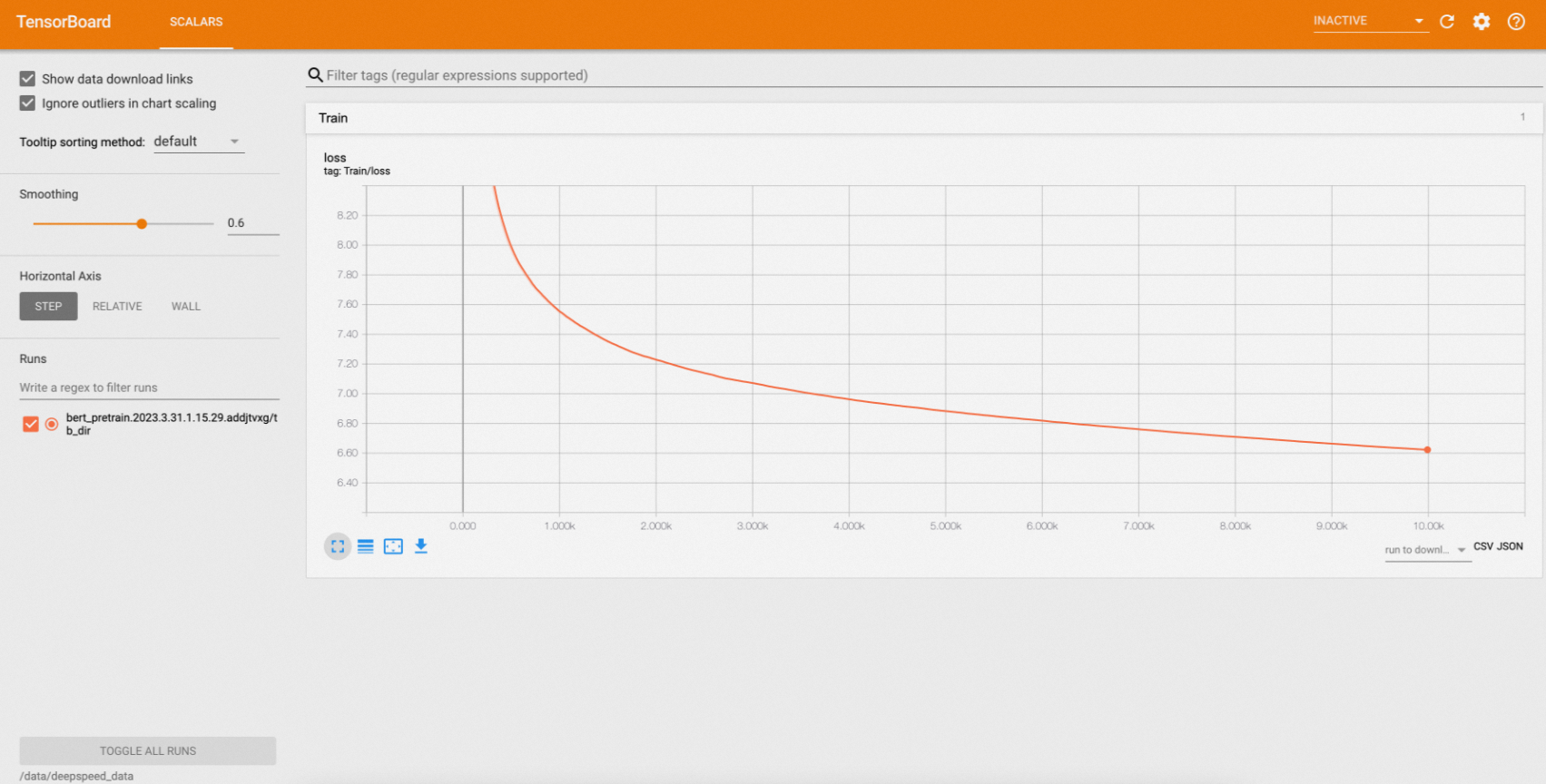
ステップ 6:トレーニングログの表示
ジョブからすべてのログを出力します:
arena logs deepspeed-helloworld期待される出力:
deepspeed-helloworld-worker-0: [2023-03-31 08:38:11,201] [INFO] [logging.py:68:log_dist] [Rank 0] step=7050, skipped=24, lr=[0.0001], mom=[(0.9, 0.999)]
deepspeed-helloworld-worker-0: [2023-03-31 08:38:11,254] [INFO] [timer.py:198:stop] 0/7050, RunningAvgSamplesPerSec=142.69733028759384, CurrSamplesPerSec=136.08094834473613, MemAllocated=0.06GB, MaxMemAllocated=1.68GB
deepspeed-helloworld-worker-0: 2023-03-31 08:38:11.255 | INFO | __main__:log_dist:53 - [Rank 0] Loss: 6.7574
deepspeed-helloworld-worker-0: [2023-03-31 08:38:13,103] [INFO] [logging.py:68:log_dist] [Rank 0] step=7060, skipped=24, lr=[0.0001], mom=[(0.9, 0.999)]
deepspeed-helloworld-worker-0: [2023-03-31 08:38:13,134] [INFO] [timer.py:198:stop] 0/7060, RunningAvgSamplesPerSec=142.69095076844823, CurrSamplesPerSec=151.8552037291255, MemAllocated=0.06GB, MaxMemAllocated=1.68GB
deepspeed-helloworld-worker-0: 2023-03-31 08:38:13.136 | INFO | __main__:log_dist:53 - [Rank 0] Loss: 6.7570
deepspeed-helloworld-worker-0: [2023-03-31 08:38:14,924] [INFO] [logging.py:68:log_dist] [Rank 0] step=7070, skipped=24, lr=[0.0001], mom=[(0.9, 0.999)]
deepspeed-helloworld-worker-0: [2023-03-31 08:38:14,962] [INFO] [timer.py:198:stop] 0/7070, RunningAvgSamplesPerSec=142.69048436022115, CurrSamplesPerSec=152.91029839772997, MemAllocated=0.06GB, MaxMemAllocated=1.68GB
deepspeed-helloworld-worker-0: 2023-03-31 08:38:14.963 | INFO | __main__:log_dist:53 - [Rank 0] Loss: 6.7565リアルタイムでログをストリーミングするには -f を使用します。最後の N 行のみを出力するには -t N を使用します:
# リアルタイムでログをストリーミング
arena logs deepspeed-helloworld -f
# 最後の 5 行を出力
arena logs deepspeed-helloworld -t 5-t 5 の期待される出力:
deepspeed-helloworld-worker-0: [2023-03-31 08:47:08,694] [INFO] [launch.py:318:main] Process 80 exits successfully.
deepspeed-helloworld-worker-2: [2023-03-31 08:47:08,731] [INFO] [launch.py:318:main] Process 44 exits successfully.
deepspeed-helloworld-worker-1: [2023-03-31 08:47:08,946] [INFO] [launch.py:318:main] Process 44 exits successfully.
/opt/conda/lib/python3.8/site-packages/apex/pyprof/__init__.py:5: FutureWarning: pyprof will be removed by the end of June, 2022
warnings.warn("pyprof will be removed by the end of June, 2022", FutureWarning)arena logs --help を実行して、利用可能なすべてのログオプションを確認します。