このトピックでは、Container Service for Kubernetes (ACK) の複数ノードに DeepSeek-R1-671B モデルをデプロイするためのベストプラクティスについて説明します。 671B モデルに対して単一 GPU のメモリが不足している問題に対処するために、ハイブリッド並列戦略 (パイプライン並列 = 2 + テンソル並列 = 8) が提案されています。 Arena と組み合わせることで、2 つの ecs.ebmgn8v.48xlarge ノード (8 × 96GB) で効率的な分散デプロイメントを実装できます。 このトピックでは、ACK にデプロイされた DeepSeek-R1 を Dify プラットフォームにシームレスに統合して、長いテキストの理解をサポートするエンタープライズレベルのインテリジェントな Q&A システムを構築する方法についても説明します。
背景情報
DeepSeek
DeepSeek-R1 は、DeepSeek が提供する第一世代の推論モデルであり、大規模拡張学習を使用して大規模言語モデル (LLM) の推論パフォーマンスを向上させます。 統計によると、DeepSeek-R1 は数学的推論とプログラミングのパフォーマンスにおいて他のクローズドソースモデルよりも優れています。 モデルのパフォーマンスは、特定のセクターでは OpenAI-o1 シリーズに匹敵するか、それを上回ります。 DeepSeek-R1 は、作成、ライティング、Q&A などの知識に関連するセクターでも優れています。 DeepSeek は、Qwen や Llama などのより小さなモデルに推論機能を抽出して、これらのモデルの推論パフォーマンスを微調整します。 DeepSeek から抽出された 14B モデルは、オープンソースの QwQ-32B モデルを上回っています。 DeepSeek から抽出された 32B モデルと 70B モデルも新記録を樹立しました。 DeepSeek の詳細については、「DeepSeek AI GitHub リポジトリ」をご参照ください。
vLLM
vLLM は、高性能で使いやすい LLM 推論サービス フレームワークです。 vLLM は、Qwen モデルを含む、最も一般的に使用される LLM をサポートしています。 vLLM は、PagedAttention 最適化、連続バッチ処理、モデル量子化などのテクノロジーによって強化されており、LLM の推論効率を大幅に向上させます。 vLLM フレームワークの詳細については、「vLLM GitHub リポジトリ」をご参照ください。
Arena
前提条件
GPU アクセラレーション ノードを含む ACK クラスタが作成されていること。 詳細については、「ACK クラスタに GPU アクセラレーション ノードまたは ASIC アクセラレーション ノードを追加する」をご参照ください。 推奨モデル:
ecs.ebmgn8v.48xlarge (8 × 96GB)。重要ドライバー バージョン 550.x 以降を使用してください。 ノード プールにラベルを追加することでドライバー バージョンを指定できます。 たとえば、GPU ノード プールに次のラベルを追加して、ドライバー バージョン 550.144.03 を指定します。
ack.aliyun.com/nvidia-driver-version: 550.144.03.ACK クラスタで Kubernetes 1.28 以降が実行されていること。
(オプション) クラウドネイティブ AI スイートがインストールされていること。 詳細については、「クラウドネイティブ AI スイートをインストールする」をご参照ください。
(オプション) バージョン 0.14.0 以降の Arena クライアントがインストールされていること。 詳細については、「Arena クライアントを設定する」をご参照ください。
1. 複数ノードへのデプロイ
1.1 モデルの分割
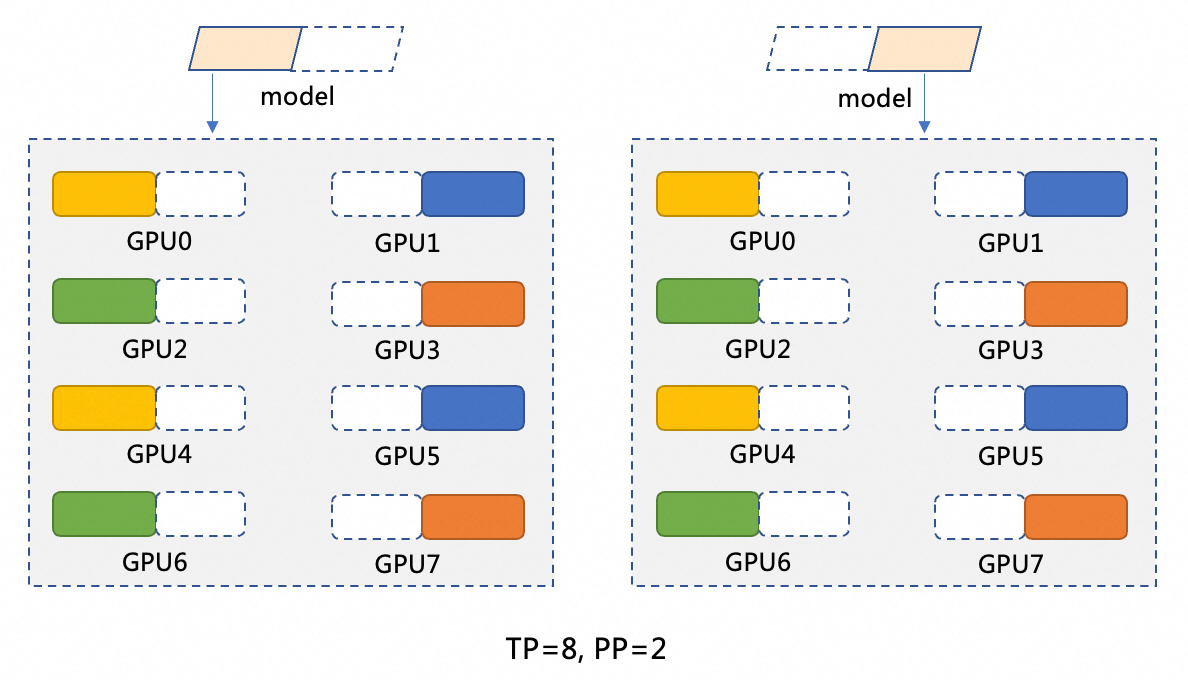
DeepSeek-R1 は 6,710 億個のパラメーターを提供します。 各 GPU は最大 96 GB のメモリを提供できますが、モデル全体を読み込むには不十分です。 この問題を解決するには、モデルを分割する必要があります。 このトピックでは、TP=8 および PP=2 の分割方法を使用します。 次の図は、分割方法を示しています。 モデル並列 (PP=2) は、モデルを 2 つのフェーズに分割します。 各フェーズは、GPU アクセラレーション ノードで実行されます。 たとえば、モデル M は M1 と M2 に分割されます。 M1 は最初の GPU アクセラレーション ノードで実行され、結果を 2 番目の GPU アクセラレーション ノードで実行される M2 に渡します。 データ並列 (TP=8) は、各フェーズ (M1 または M2) で 8 つの GPU で計算操作を実行します。 M1 フェーズでは、入力データは 8 つの部分に分割され、8 つの GPU で処理されます。 各 GPU は 1 つの部分を処理し、その後、システムは 8 つの GPU からの計算結果をマージします。
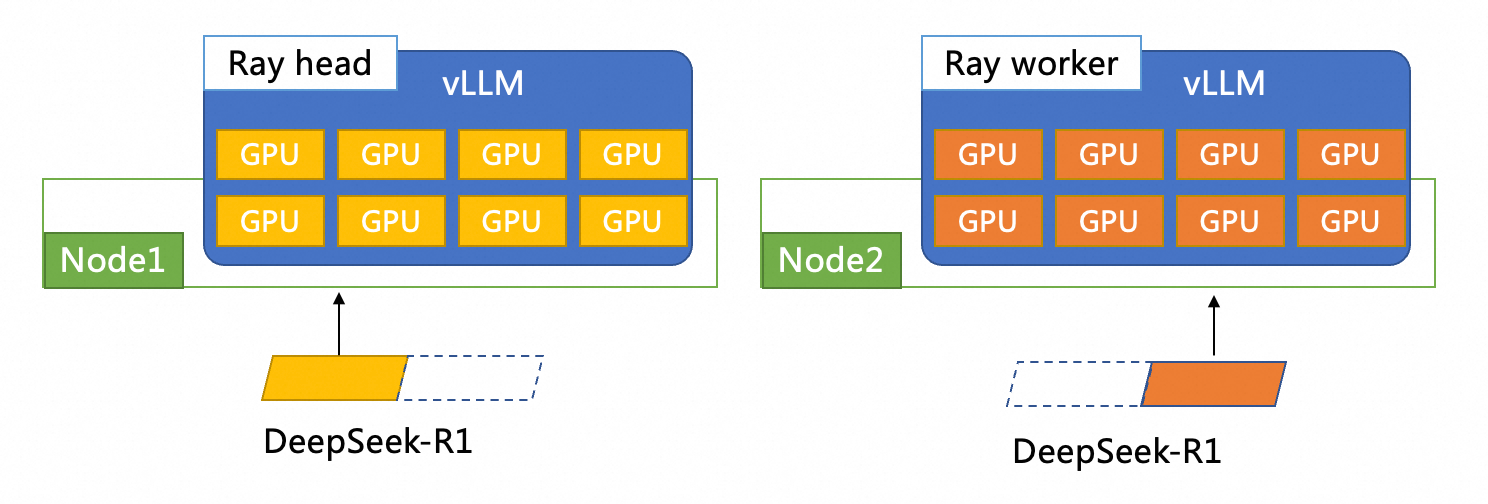
このトピックでは、vLLM + ray を使用して DeepSeek-R1 モデルを分散方式でデプロイします。 次の図は、デプロイメント全体のアーキテクチャを示しています。 2 つの vLLM ポッドが 2 つの ECS インスタンスにデプロイされます。 各 vLLM ポッドには 8 つの GPU があります。 ポッドの 1 つは Ray ヘッドノードとして機能し、もう 1 つのポッドは Ray ワーカーノードとして機能します。
1.2 モデルのダウンロード
このセクションの例では、DeepSeek-R1 を使用して、Object Storage Service (OSS) からモデルをダウンロードし、モデルを OSS にアップロードし、ACK クラスタに永続ボリューム (PV) と永続ボリューム要求 (PVC) を作成する方法について説明します。
Apsara File Storage NAS (NAS) にモデルをアップロードする方法の詳細については、「静的にプロビジョニングされた NAS ボリュームをマウントする」をご参照ください。
ファイルのダウンロードとアップロードを高速化するには、してファイルを OSS バケットに直接コピーできます。
モデル ファイルをダウンロードします。
次のコマンドを実行して Git をインストールします。
# yum install git または apt install git を実行します。 yum install git次のコマンドを実行して、Git Large File Support (LFS) プラグインをインストールします。
# yum install git-lfs または apt install git-lfs を実行します。 yum install git-lfs次のコマンドを実行して、ModelScope の DeepSeek-R1 リポジトリをオンプレミス マシンにクローンします。
GIT_LFS_SKIP_SMUDGE=1 git clone https://modelscope.cn/models/deepseek-ai/DeepSeek-R1次のコマンドを実行して DeepSeek-R1 ディレクトリにアクセスし、LFS によって管理されている大きなファイルをプルします。
cd DeepSeek-R1 git lfs pull
DeepSeek-R1 ファイルを OSS にアップロードします。
OSS コンソール にログインして、作成した OSS バケットの名前を表示およびコピーします。
OSS バケットの作成方法の詳細については、「バケットを作成する」をご参照ください。
OSS リソースを管理するために ossutil をインストールおよび設定します。 詳細については、「ossutil をインストールする」をご参照ください。
次のコマンドを実行して、OSS に DeepSeek-R1 という名前のディレクトリを作成します。
ossutil mkdir oss://<Your-Bucket-Name>/models/DeepSeek-R1次のコマンドを実行して、モデル ファイルを OSS にアップロードします。
ossutil cp -r ./DeepSeek-R1 oss://<Your-Bucket-Name>/models/DeepSeek-R1
宛先クラスタの PV と PVC を設定します。 詳細については、「静的にプロビジョニングされた ossfs 1.0 ボリュームを使用する」をご参照ください。
PV を作成する
ACK コンソール にログインします。 左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、目的のクラスタを見つけて名前をクリックします。 左側のウィンドウで、 を選択します。
[永続ボリューム] ページで、右上隅にある [作成] をクリックします。
[永続ボリュームの作成] ダイアログボックスで、パラメーターを設定します。
次の表に、PV のパラメーターを示します。
パラメーター
説明
PV タイプ
この例では、[OSS] を選択します。
ボリューム名
この例では、[llm-model] と入力します。
アクセス証明書
OSS バケットにアクセスするために使用される AccessKey ペア。 AccessKey ペアは、AccessKey ID と AccessKey シークレットで構成されます。
バケット ID
前の手順で作成した OSS バケットを選択します。
OSS パス
/models/DeepSeek-R1などのモデルのパスを入力します。
PVC を作成する
[クラスタ] ページで、目的のクラスタを見つけて名前をクリックします。 左側のウィンドウで、 を選択します。
[永続ボリューム要求] ページで、右上隅にある [作成] をクリックします。
[永続ボリューム要求の作成] ページで、パラメーターを入力します。
次の表に、PVC のパラメーターを示します。
パラメーター
説明
PVC タイプ
この例では、[OSS] を選択します。
名前
この例では、[llm-model] と入力します。
割り当てモード
この例では、[既存のボリューム] を選択します。
既存のストレージ クラス
[PV の選択] ハイパーリンクをクリックし、作成した PV を選択します。
1.3 モデルのデプロイ
LeaderWorkerSet をインストールします。
ACK コンソール にログインします。
左側のナビゲーションウィンドウで、[クラスタ] をクリックし、作成したクラスタの名前をクリックします。
左側のナビゲーションウィンドウで、 をクリックします。 [Helm] ページで、[デプロイ] をクリックします。
[基本情報] ステップで、[アプリケーション名] と [名前空間] を入力し、[チャート] セクションで [lws] を見つけて、[次へ] をクリックします。 この例では、アプリケーション名 ([lws]) と名前空間 ([lws-system]) を使用します。
[パラメーター] ステップで、最新の [チャートバージョン] を選択し、[OK] をクリックして [lws] をインストールします。
モデルをデプロイします。
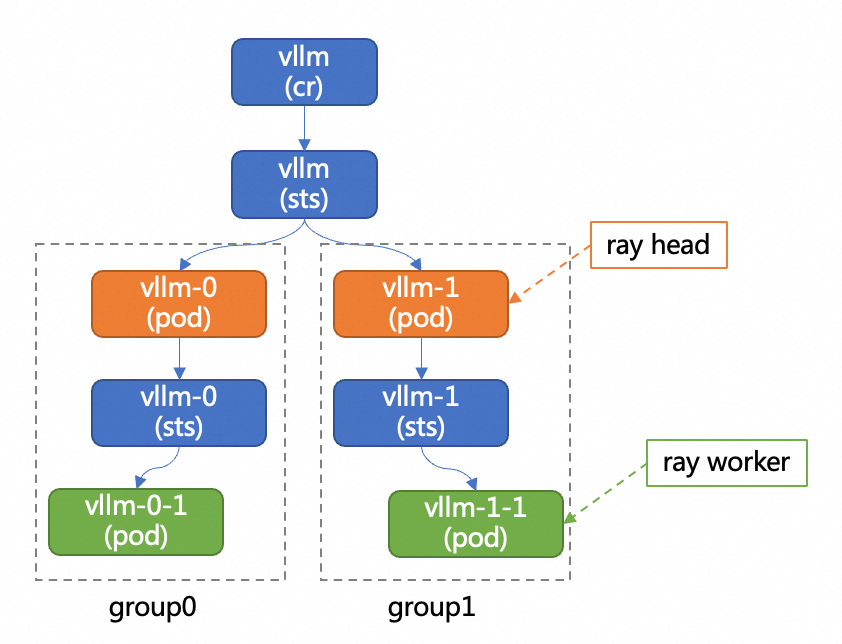
次の図は、vLLM 分散デプロイメント アーキテクチャの図を示しています。
Arena を使用してモデルをデプロイする
次のコマンドを実行してサービスをデプロイします。
arena serve distributed \ --name=vllm-dist \ --version=v1 \ --restful-port=8080 \ --image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.10.0 \ --readiness-probe-action="tcpSocket" \ --readiness-probe-action-option="port: 8080" \ --readiness-probe-option="initialDelaySeconds: 30" \ --readiness-probe-option="periodSeconds: 30" \ --share-memory=30Gi \ --data=llm-model:/models/DeepSeek-R1 \ --leader-num=1 \ --leader-gpus=8 \ --leader-command="bash /vllm-workspace/examples/online_serving/multi-node-serving.sh leader --ray_cluster_size=\$(LWS_GROUP_SIZE); python3 -m vllm.entrypoints.openai.api_server --model /models/DeepSeek-R1 --port 8080 --trust-remote-code --served-model-name deepseek-r1 --gpu-memory-utilization 0.95 --tensor-parallel-size 8 --pipeline-parallel-size 2 --enforce-eager" \ --worker-num=1 \ --worker-gpus=8 \ --worker-command="bash /vllm-workspace/examples/online_serving/multi-node-serving.sh worker --ray_address=\$(LWS_LEADER_ADDRESS)"予想される出力:
configmap/vllm-dist-v1-cm created service/vllm-dist-v1 created leaderworkerset.leaderworkerset.x-k8s.io/vllm-dist-v1-distributed-serving created INFO[0002] The Job vllm-dist has been submitted successfully INFO[0002] You can run `arena serve get vllm-dist --type distributed-serving -n default` to check the job status次のコマンドを実行して、推論サービスのデプロイの進行状況を表示します。
arena serve get vllm-dist予想される出力:
Name: vllm-dist Namespace: default Type: Distributed Version: v1 Desired: 1 Available: 1 Age: 3m Address: 192.168.138.65 Port: RESTFUL:8080 GPU: 16 Instances: NAME STATUS AGE READY RESTARTS GPU NODE ---- ------ --- ----- -------- --- ---- vllm-dist-v1-distributed-serving-0 Running 3m 1/1 0 8 cn-beijing.10.x.x.x vllm-dist-v1-distributed-serving-0-1 Running 3m 1/1 0 8 cn-beijing.10.x.x.x
kubectl を使用してモデルをデプロイする
DeepSeek_R1.yamlファイルを実行して、モデル サービスをデプロイします。apiVersion: leaderworkerset.x-k8s.io/v1 kind: LeaderWorkerSet metadata: name: vllm-dist spec: replicas: 1 leaderWorkerTemplate: size: 2 restartPolicy: RecreateGroupOnPodRestart leaderTemplate: metadata: labels: role: leader spec: volumes: - name: model persistentVolumeClaim: claimName: llm-model - name: dshm emptyDir: medium: Memory sizeLimit: 15Gi containers: - name: vllm-leader image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.10.0 command: - sh - -c - >- bash /vllm-workspace/examples/online_serving/multi-node-serving.sh leader --ray_cluster_size=$(LWS_GROUP_SIZE); python3 -m vllm.entrypoints.openai.api_server --model /models/DeepSeek-R1 --port 8080 --trust-remote-code --served-model-name deepseek-r1 --gpu-memory-utilization 0.95 --tensor-parallel-size 8 --pipeline-parallel-size 2 --enforce-eager resources: limits: nvidia.com/gpu: "8" requests: nvidia.com/gpu: "8" ports: - containerPort: 8080 readinessProbe: initialDelaySeconds: 30 periodSeconds: 30 tcpSocket: port: 8080 volumeMounts: - mountPath: /models/DeepSeek-R1 name: model - mountPath: /dev/shm name: dshm workerTemplate: spec: volumes: - name: model persistentVolumeClaim: claimName: llm-model - name: dshm emptyDir: medium: Memory sizeLimit: 15Gi containers: - name: vllm-worker image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.10.0 command: - sh - -c - "bash /vllm-workspace/examples/online_serving/multi-node-serving.sh worker --ray_address=$(LWS_LEADER_ADDRESS)" resources: limits: nvidia.com/gpu: "8" requests: nvidia.com/gpu: "8" ports: - containerPort: 8080 volumeMounts: - mountPath: /models/DeepSeek-R1 name: model - mountPath: /dev/shm name: dshm --- apiVersion: v1 kind: Service metadata: name: vllm-dist-v1 spec: type: ClusterIP ports: - port: 8080 protocol: TCP targetPort: 8080 selector: leaderworkerset.sigs.k8s.io/name: vllm-dist role: leaderkubectl create -f DeepSeek_R1.yaml次のコマンドを実行して、推論サービスのデプロイの進行状況を表示します。
kubectl get po |grep vllm-dist予想される出力:
NAME READY STATUS RESTARTS AGE vllm-dist-0 1/1 Running 0 20m vllm-dist-0-1 1/1 Running 0 20m
モデル推論リクエストを転送するためのオンプレミス ポートを作成します。
kubectl port-forwardコマンドを実行して、オンプレミス環境と推論サービス間のポート フォワーディングを設定します。説明kubectl port-forwardコマンドを実行してポート フォワーディングを設定する場合、サービスは本番環境では信頼性、安全性、または拡張性がありません。 このサービスは、開発とデバッグにのみ使用できます。 本番環境では、このコマンドを実行してポート フォワーディングを設定しないでください。 ACK クラスタでの本番を容易にするために使用されるネットワーキング ソリューションの詳細については、「Ingress 管理」をご参照ください。kubectl port-forward svc/vllm-dist-v1 8080:8080推論サービスにリクエストを送信します。
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{ "model": "deepseek-r1", "prompt": "San Francisco is a", "max_tokens": 10, "temperature": 0.6 }'予想される出力:
{"id":"cmpl-15977abb0adc44d9aa03628abe9fcc81","object":"text_completion","created":1739346042,"model":"ds","choices":[{"index":0,"text":" city that needs no introduction. Known for its iconic","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":15,"completion_tokens":10,"prompt_tokens_details":null}}
2. Dify を使用して DeepSeek Q&A アシスタントを構築する
Container Service for Kubernetes クラスタに Dify をインストールして設定できます。 詳細については、「ack-dify をインストールする」をご参照ください。
2.1. DeepSeek モデルを設定する
Dify プラットフォームにログインします。 プロフィール写真をクリックし、[設定] をクリックします。 左側のナビゲーションウィンドウで、[モデル プロバイダー] をクリックします。
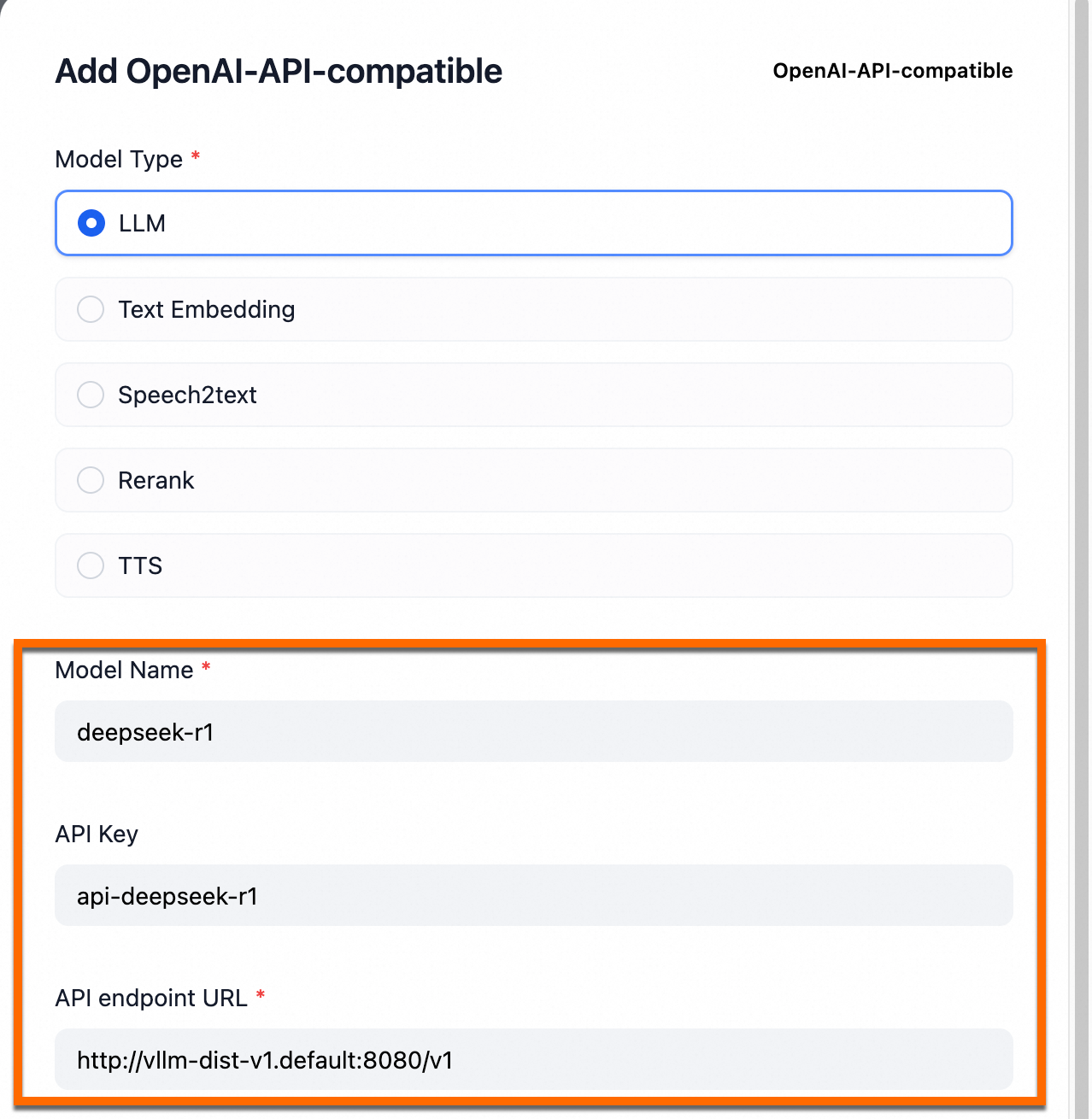
OpenAI-API-compatibleを見つけて、[追加]をクリックします。
次の表にパラメーターを示します。
パラメーター
設定
注記
モデル名
deepseek-r1このパラメーターは変更できません。
API キー
例:
api-deepseek-r1ビジネス要件に基づいてこのパラメーターを設定できます。
API エンドポイント URL
http://vllm-dist-v1.default:8080/v1このパラメーターは変更できません。 このパラメーターの値は、2 番目のステップでデプロイされたローカル DeepSeek サービスの名前です。
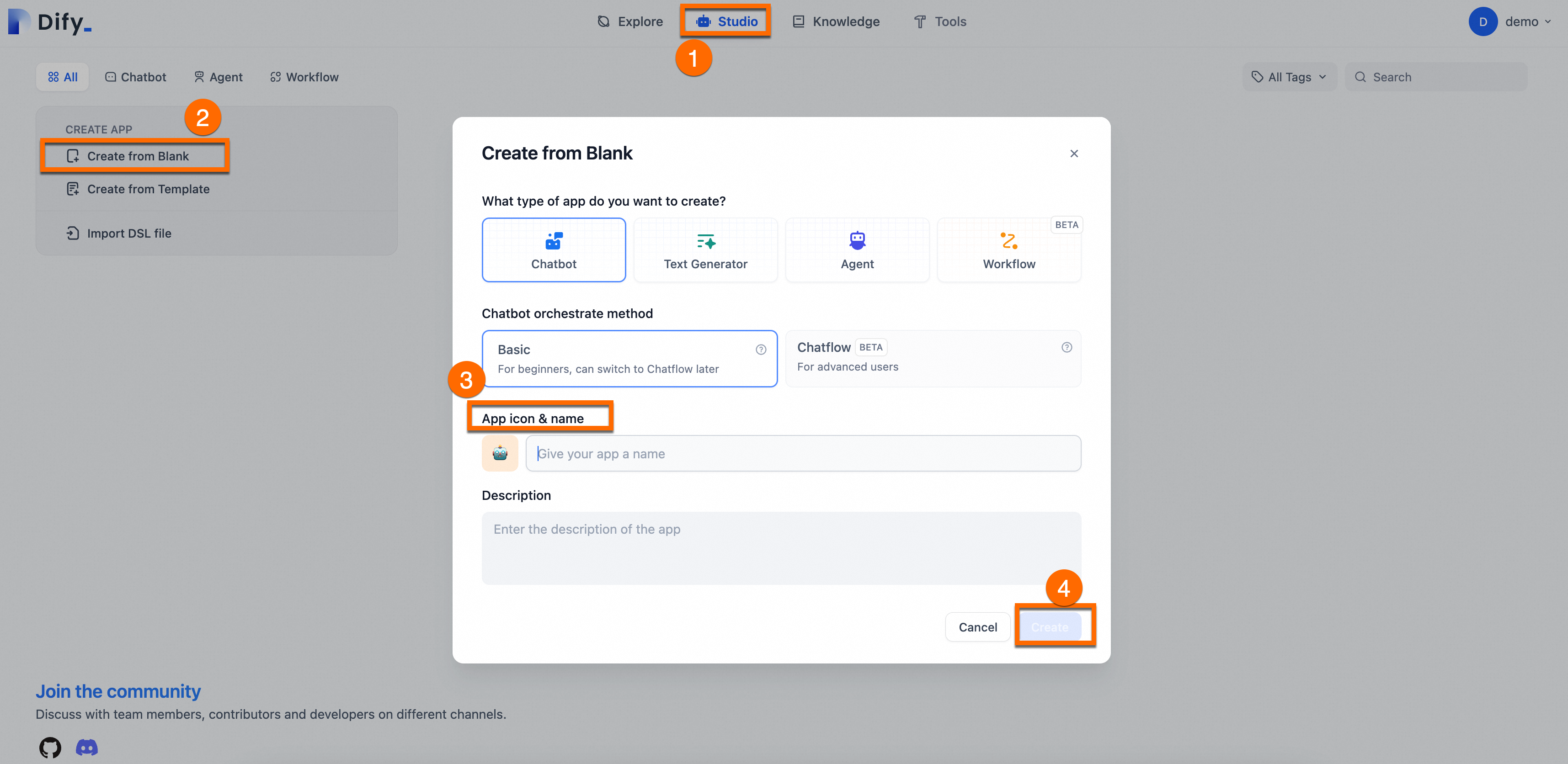
2.2. Q&A アシスタントを作成する
[スタジオ] > [空白から作成] を選択します。 アシスタントの [名前] と [説明] を指定します。 その他のパラメーターにはデフォルト設定を使用します。
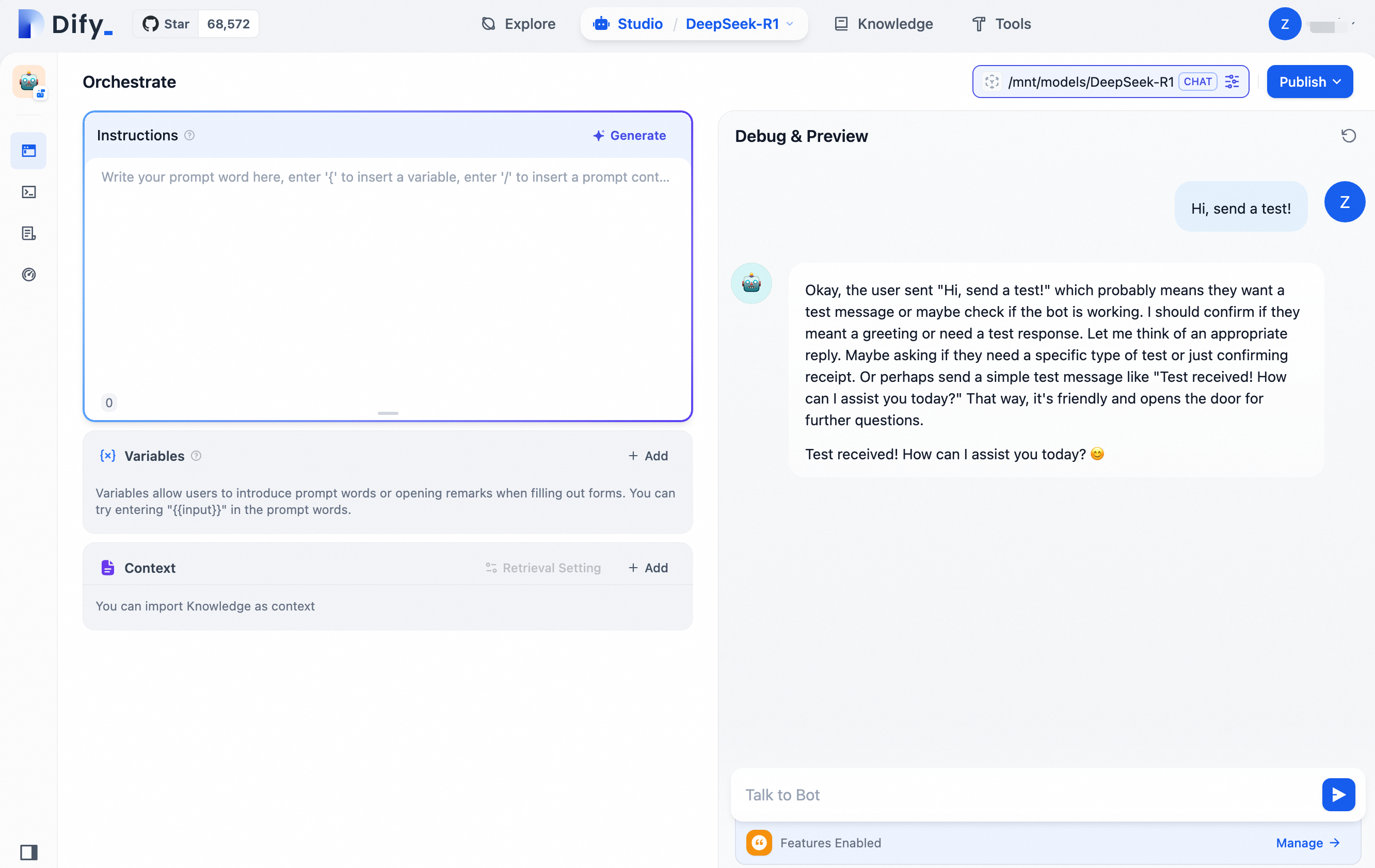
2.3 AI 搭載 Q&A アシスタントをテストする
ページの右側で、DeepSeek との会話を開始できます。
設定済みの DeepSeek Q&A アシスタントを個人の本番環境に統合できます。 詳細については、「本番環境での使用」をご参照ください。
