System Observer Monitoring (SysOM) は、OS カーネルレベルのコンテナ監視手法です。Container Service for Kubernetes (ACK) を使用すると、SysOM に基づいて OS カーネルレベルでコンテナを監視できます。この機能は、コンテナ化アプリケーションのデプロイと移行をより適切に行い、コンテナを監視するのに役立ちます。
前提条件
開始する前に、以下を確認してください。
Kubernetes バージョン 1.18.8 以降の ACK マネージドクラスター、または 2021 年 10 月以降に作成された ACK Serverless クラスターがあること。詳細については、「ACK マネージドクラスターの作成」および「ACK Serverless クラスターの作成」をご参照ください。既存のクラスターを更新するには、「ACK クラスターの手動更新」をご参照ください。
Managed Service for Prometheus が有効になっていること。詳細については、「Managed Service for Prometheus の有効化」をご参照ください。
ack-sysom-monitor が収集するデータ
ack-sysom-monitor は、拡張 Berkeley Packet Filter (eBPF) テクノロジーを使用してノードおよびコンテナのメトリックを収集し、カーネルレベルでメトリックを強化する SysOM コンポーネントです。標準システムメトリックに加えて、Pod カーネルレベル監視およびノードカーネルレベル監視をサポートする拡張メトリックを提供し、システムジッター、遅延、リソースリーク、Pod メモリ例外などの一般的な問題を特定するのに役立ちます。
課金
ack-sysom-monitor を有効にすると、関連コンポーネントが自動的に監視メトリクスを Managed Service for Prometheus に送信します。これらのメトリックは、カスタムメトリックとして課金されます。
この機能を有効化する前に、カスタムメトリックの課金方法を理解するために、課金概要を読みます。料金は、クラスターのサイズおよび実行中のアプリケーションの数によって異なります。リソース使用量のモニタリングと制御を行うには、リソース使用量の表示を参照します。
ack-sysom-monitor の有効化
ARMS コンソールにログインします。
左側のナビゲーションウィンドウで、[インテグレーションセンター] をクリックします。
「[インテグレーションセンター]」ページの[インフラストラクチャ]セクションで、[SysOM システム監視]を見つけ、クリックします。
[SysOM System Observation] パネルの [統合の開始] ステップで、統合する ACK クラスターを選択し、[OK] をクリックします。
モニタリングデータの表示
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、対象のクラスターを見つけ、その名前をクリックします。 左側のペインで、[操作] > [Prometheus モニタリング] を選択します。
[Prometheus モニタリング] ページで、[SysOM] タブをクリックします。
ack-sysom-monitorは 2 つのモニタリングビューをサポートしています:ノードカーネルレベルのモニタリング — [SysOM - Nodes] タブで、各ノードの CPU、メモリ、スケジューリング、ストレージ、ネットワークのメトリックを表示できます。
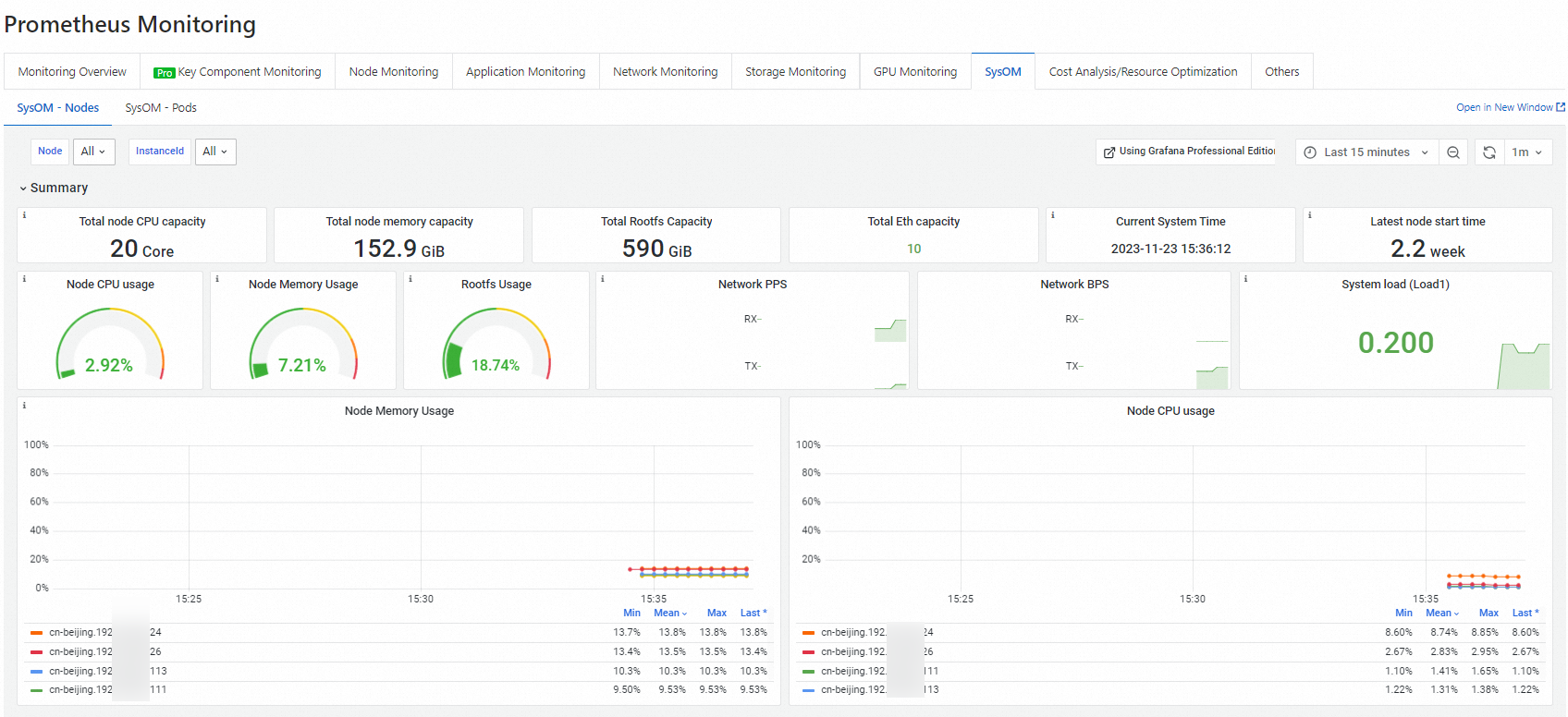
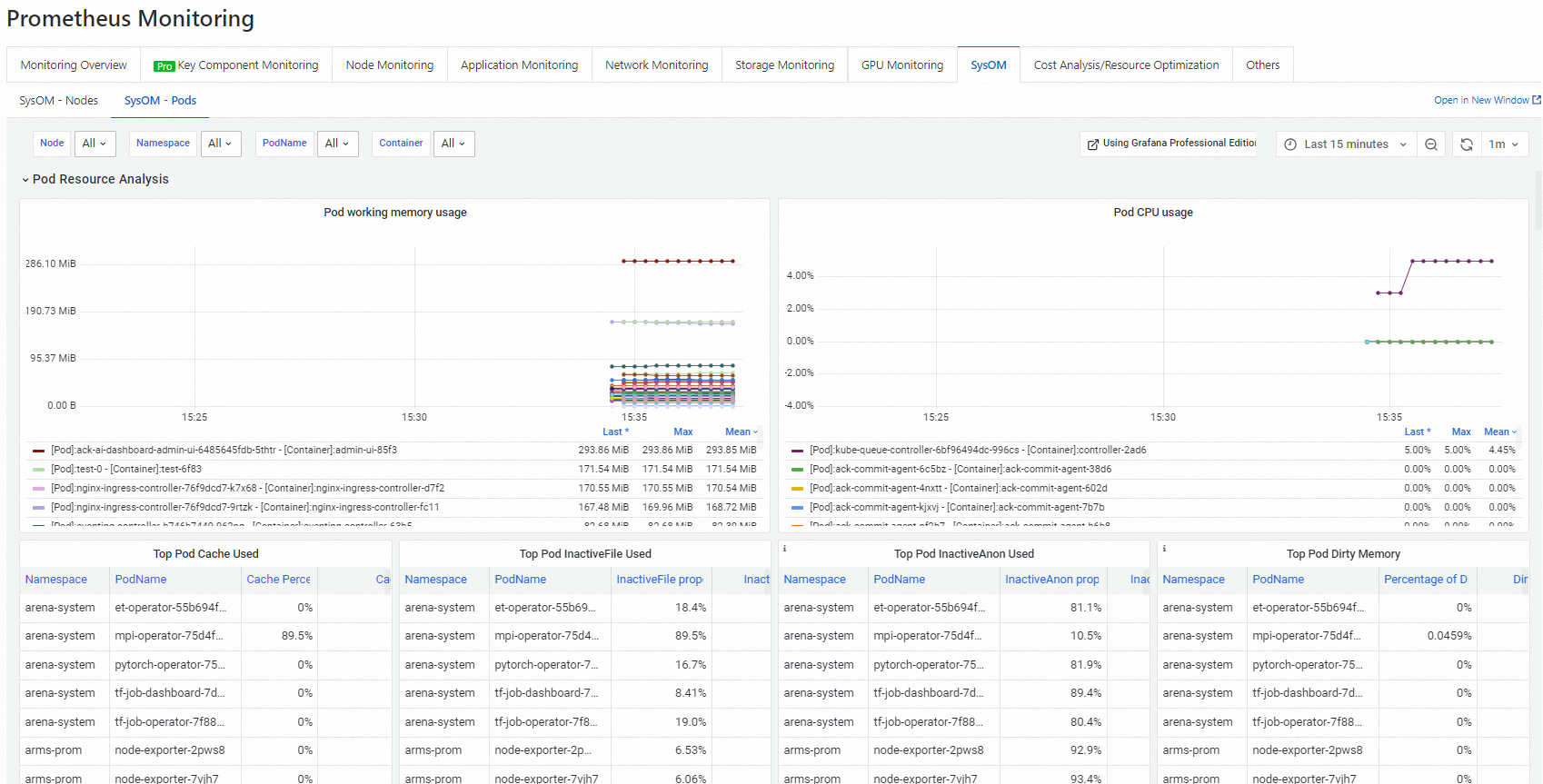
Pod カーネルレベルのモニタリング — [SysOM - Pods] タブで、各 Pod のメモリ、CPU、ネットワーク、および I/O メトリックをリアルタイムで表示します。
次のステップ
課金を停止するには、ack-sysom-monitor コンポーネントをアンインストールします。詳細については、「コンポーネントの管理」をご参照ください。
メトリック
ack-sysom-monitor が提供するすべてのメトリックは、Prometheus データモデルに準拠しています。
以下にリストされているすべてのメトリクスタイプは gauge です。診断シナリオ
以下の表を使用して、症状からメトリックに移動します。
| 症状 | 関連メトリック |
|---|---|
| CPU スロットリングまたはスケジューリング遅延 | sysom_proc_schedstat、sysom_cpu_dist、sysom_container_cpu_stat、sysom_container_cpu_cfsquota |
| 高負荷または D状態プロセスの多さ | sysom_proc_stat_counters、sysom_proc_loadavg |
| メモリプレッシャーまたは OOM イベント | sysom_proc_vmstat、sysom_container_memory_gdrcm_latency、sysom_container_memory_cdrcm_latency、sysom_container_memory_cpt_latency |
| ページキャッシュによるメモリジッター | sysom_container_memory_filecache |
| cgroup リーク | sysom_cgroups |
| ディスク I/O レイテンシまたはスループットの問題 | sysom_proc_disks、sysom_container_blkio_stat |
| ネットワークパケット損失または再送 | sysom_proc_pkt_status、sysom_net_retrans_count |
| 高い TCP RTT または接続異常 | sysom_net_health_hist、sysom_net_health_count、sysom_net_tcp_count |
| ソケットまたはバッファ枯渇 | sysom_sock_stat |
ノードメトリック
ノードメトリックには、CPU とスケジューリング、メモリ、ストレージ、ネットワーク、およびその他のシステムメトリックが含まれます。
CPU とスケジューリング
メトリック | タイプ | 単位 | 説明 |
sysom_proc_cpu_total | gauge | % | ノード全体の CPU アップタイムの内訳 (状態別): ユーザーモード、カーネルモード、softirq、hardirq、アイドル、および iowait。このメトリックを使用して、どの状態が CPU 時間を消費しているかを特定します。 |
sysom_proc_cpus | gauge | % | 個々の CPU コアごとの CPU アップタイムの内訳 (状態別): ユーザーモード、カーネルモード、softirq、hardirq、アイドル、および iowait。このメトリックを使用して、コアごとの不均衡を検出します。 |
sysom_proc_sirq | gauge | % | 各 softirq タイプ (HI、TIMER、NET_TX、NET_RX、BLOCK、IRQ_POLL、TASKLET、SCHED、HRTIMER、および RCU) の発生数。NET_RX または NET_TX の急増は、ネットワーク飽和を示す可能性があります。 |
sysom_proc_stat_counters | gauge | - | 実行中または D状態のプロセス数、システム起動時間、およびコンテキストスイッチ数。D状態のカウントが高い場合は、I/O またはロック競合を示します。 |
sysom_proc_loadavg | gauge | - | 1分、5分、および 15分間隔の平均負荷、実行キュー長、および総プロセス数。このメトリックを使用して、持続的な負荷傾向を評価します。 |
sysom_proc_schedstat | gauge | ns (ナノ秒) | CPU スケジューリングレイテンシ: 実行キューでプロセスが待機する時間、および CPU タイムスライスの長さ。待機時間の増加は、スケジューリングプレッシャーを示します。 |
sysom_cpu_dist | gauge | - | CPU スケジューリング間隔の分布 — プロセスが CPU を解放してから再度スケジュールされるまでの待機時間。カウントは 1 µs、10 µs、100 µs、1 ms、10 ms、100 ms、および 1 s でバケット化されます。長いテールレイテンシは、スケジューリングジッターを示します。 |
メモリ
メトリック | タイプ | 単位 | 説明 |
sysom_proc_meminfo | gauge | KiB | ノードレベルのメモリ使用量 (カテゴリ別): 合計、空き、利用可能、キャッシュ、バッファ、SReclaimable、および SUnreclaim。このメトリックを使用して、全体的なメモリプレッシャーを把握します。 |
sysom_proc_vmstat | gauge | - | 詳細なメモリページ統計とイベント: 空きページ、ダーティページ、読み書きされたページ、非アクティブリストから再利用されたページ、およびメモリ不足 (OOM) キラーの呼び出し。OOM キラーのアクティビティは、重大なメモリ枯渇を示します。 |
sysom_proc_buddyinfo | gauge | - | カーネルバディシステムアロケーターの状態: 各メモリゾーンとノードにおけるさまざまなサイズの利用可能なブロック。このメトリックを使用して、割り当て失敗を引き起こす可能性のあるメモリ断片化を検出します。 |
ストレージ
メトリック | タイプ | 単位 | 説明 |
sysom_proc_disks | gauge | - | ディスクごとおよびパーティションごとの I/O 統計: 読み取り/書き込みリクエスト数とバイト、マージ数、処理中のリクエスト、およびリクエスト完了までの合計時間。このメトリックを使用して、ディスクスループットとレイテンシの問題を診断します。 |
sysom_fs_stat | gauge | - | マウントされたファイルシステムごとのファイルシステム使用量: ブロックサイズ、使用済みおよび利用可能なブロック、および使用済みおよび利用可能な inode。このメトリックを使用して、障害を引き起こす前にディスクまたは inode 枯渇を捕捉します。 |
ネットワーク
メトリック | タイプ | 単位 | 説明 |
sysom_proc_networks | gauge | - | NIC ごとのデータ転送統計: 受信および送信されたパケットとバイト、ドライバーレベルの破棄、および送信/受信エラー。このメトリックを使用して、NIC レベルのパケット損失を検出します。 |
sysom_proc_pkt_status | gauge | - | ネットワークプロトコルスタックイベント: パケットドロップ、バッファオーバーフロー、およびアサーション失敗。このメトリックを使用して、スタック内でパケットがどこで失われているかを特定します。 |
sysom_sock_stat | gauge | - | ソケットとバッファの使用量: 総ソケット数、raw、TCP、および UDP ソケット数、TIME_WAIT または孤立状態の TCP ソケット、および TCP/UDP ソケットメモリ使用量。TIME_WAIT または孤立状態のカウントが高い場合は、アプリケーションロジックまたはシステムパラメーターによって引き起こされる接続処理の問題を示す可能性があります。 |
sysom_softnets | gauge | - | CPU ごとの NIC ソフト割り込み統計: ソフト割り込みごとの受信および送信パケット数、および受信ソフト割り込みを処理するために |
sysom_net_health_hist | gauge | - | ノード上のすべての TCP 接続におけるラウンドトリップタイム (RTT) 分布 (10 ms、100 ms、および 1 s でバケット化)。このメトリックを使用して、TCP レイテンシの劣化を検出します。 |
sysom_net_health_count | gauge | - | ノード上の TCP 接続の平均 RTT。 |
sysom_net_retrans_count | gauge | - | TCP 再送統計: タイプ別 (SYN、SYN-ACK、RESET) の再送パケット数 (タイムアウトによる再送を含む)。カウントの増加は、ネットワークの不安定性または輻輳を示します。 |
sysom_net_tcp_count | gauge | - | TCP 接続統計: アクティブ接続数、受信および送信されたセグメント、再送されたセグメント、および受信失敗。 |
sysom_net_udp_count | gauge | - | UDP 統計: 受信および送信されたパケット、送信/受信バッファエラー、および利用可能なポートがないためにドロップされたパケット。 |
sysom_net_ip_count | gauge | - | IP レイヤー統計: 転送、受信、および送信されたパケット。 |
sysom_net_icmp_count | gauge | - | ICMP 統計: 受信および送信されたパケット、および送信/受信失敗。 |
その他のシステムメトリック
メトリック | タイプ | 単位 | 説明 |
sysom_cgroups | gauge | - | サブシステム全体で使用中の cgroup の数: CPU、Cpuacct、Memory、Pids、Blkio、および Devices。減少することなく着実に増加するカウントは、cgroup リークを示す可能性があります。 |
sysom_uptime | gauge | s (秒) | 最後の起動からのシステムアップタイム、およびシステムアイドル時間。 |
コンテナメトリック
コンテナメトリックには、CPU とスケジューリング、メモリ、I/O、およびネットワークメトリックが含まれます。
CPU とスケジューリング
メトリック | タイプ | 単位 | 説明 |
sysom_container_cpu_stat | gauge | - | cgroup ごとの CPU スロットリング統計: CPU 制限が適用された回数、総適用回数、および適用総期間。このメトリックを使用して、リソースクォータの調整が必要かどうかを判断します。 |
sysom_container_cpu_acctstat | gauge | % | コンテナタスクの CPU 使用率 (モード別): ユーザー、カーネル、および合計。このメトリックを使用して、コンテナがカーネル空間とユーザースペースで CPU をどのように消費しているかを把握します。 |
sysom_container_cpu_cfsquota | gauge | - | コンテナ cgroup の完全公平スケジューラ (CFS) 構成。 |
メモリ
メトリック | タイプ | 単位 | 説明 |
sysom_container_memory_stat | gauge | KiB | コンテナのメモリ使用量 (カテゴリ別): 合計、空き、利用可能、キャッシュ、バッファ、SReclaimable、および SUnreclaim。このメトリックを使用して、コンテナごとの全体的なメモリ消費量を評価します。 |
sysom_container_memory_filecache | gauge | KiB | コンテナごとのページキャッシュ使用量: 最もページキャッシュを消費している上位 10 ファイル、ファイルサイズ、および占有されている総ページキャッシュ。このメトリックを使用して、ページキャッシュの過剰使用がメモリプレッシャー、レイテンシ、またはジッターを引き起こしているコンテナを特定します。 |
sysom_container_memory_gdrcm_latency | gauge | 回 | メモリリソース不足によるメモリ再利用によって引き起こされる遅延。1~5 ms、5~10 ms、10~100 ms、100~500 ms、500~1,000 ms、および 1,000 ms 超の 6 つの範囲で遅延をカウントします。このメトリックを使用して、コンテナパフォーマンスに影響を与えるノードレベルのメモリプレッシャーを検出します。 |
sysom_container_memory_cdrcm_latency | gauge | 回 | メモリ cgroup の不足に起因するメモリ回収による遅延。 Note このメトリックは、現在のメモリ cgroup が非ルート cgroup であるか、現在のメモリ cgroup にメモリ制限が構成されている場合にのみ有効です。 |
sysom_container_memory_cpt_latency | gauge | 時刻 | コンテナ内のプロセスがメモリを要求したが、ノードにメモリが不足しているか、メモリ断片が過剰に存在する場合にトリガーされるカーネルメモリ調整によって引き起こされる遅延。同じ 6 つの範囲で遅延をカウントします。このメトリックを使用して、コンテナ割り当てに影響を与えるメモリ断片化を検出します。 |
I/O
メトリック | タイプ | 単位 | 説明 |
sysom_container_blkio_stat | gauge | - | コンテナのディスクのブロック I/O 統計: 読み取り/書き込みリクエスト数とバイト、キューに入れられたリクエスト数とバイト、およびリクエスト待機時間。このメトリックを使用して、コンテナレベルでの I/O ボトルネックを診断します。 |
ネットワーク
メトリック | タイプ | 単位 | 説明 |
sysom_container_network_stat | gauge | - | コンテナごとの仮想 NIC データ転送統計: 受信および送信されたパケットとバイト、およびデバイスレベルの破棄。ネットワークプロトコルスタックによってドロップされたパケットは含まれません。 |