GPU モニタリングは、NVIDIA Data Center GPU Manager (DCGM) を使用して、クラスター内の GPU ノードをモニタリングします。このトピックでは、3 つの異なる GPU リクエストモードのモニタリング結果を表示する方法について説明します。
前提条件
-
ACK マネージドクラスターを作成済みであること。
-
クラスターの GPU モニタリングを有効化済みであること。
-
GPU 共有コンポーネントをインストール済みであること。
背景情報
GPU モニタリングは、クラスター内の GPU ノードの包括的なモニタリングを提供します。クラスターレベル、ノードレベル、Pod レベルのモニタリングダッシュボードを利用できます。詳細については、「ダッシュボードの説明」をご参照ください。
-
クラスターレベルの GPU モニタリングダッシュボードでは、クラスター全体の GPU 使用率、GPU メモリ使用量、XID エラー検出など、クラスター全体または特定のノードプールに関する情報を表示できます。
-
ノードレベルの GPU モニタリングダッシュボードでは、GPU の詳細、GPU 使用率、GPU メモリ使用量など、特定のノードに関する情報を表示できます。
-
Pod レベルの GPU モニタリングダッシュボードでは、リクエストされた GPU リソースや GPU 使用率など、特定の Pod に関する情報を表示できます。
このトピックでは、3 つの異なる GPU リクエストモードのモニタリング結果を示します。

注意事項
-
GPU メトリックは 15 秒間隔で収集されます。これにより、Grafana モニタリングダッシュボードに表示されるデータに遅延が生じる場合があります。その結果、ダッシュボードではノードに利用可能な GPU メモリがないと表示されていても、Pod がそのノードに正常にスケジューリングされることがあります。これは、実行中の Pod がスクレイピングの間 (15 秒のウィンドウ内) に GPU リソースを解放し、スケジューラーが次のメトリック収集の前に保留中の Pod をノードに配置した場合に発生する可能性があります。
-
モニタリングダッシュボードは、Pod 仕様の
resources.limitsフィールドでリクエストされた GPU リソースのみを追跡します。詳細については、「コンテナのリソース管理」をご参照ください。以下のいずれかの方法で GPU リソースを使用する場合、モニタリングダッシュボードのデータが不正確になる可能性があります:
-
ノード上で GPU アプリケーションを直接実行する。
-
docker runコマンドを使用してコンテナを起動し、GPU アプリケーションを実行する。 -
Pod の
envセクションでNVIDIA_VISIBLE_DEVICES環境変数を設定 (例:NVIDIA_VISIBLE_DEVICES=allまたはNVIDIA_VISIBLE_DEVICES=<GPU ID>) して GPU リソースをリクエストし、その後 GPU プログラムを実行する。 -
Pod の
securityContextでprivileged: trueを設定し、その Pod 内で GPU プログラムを実行する。 -
NVIDIA_VISIBLE_DEVICES環境変数が設定されていない Pod で GPU プログラムを実行するが、その Pod のコンテナイメージがデフォルトでNVIDIA_VISIBLE_DEVICES=allを設定している。
-
-
GPU カードに割り当てられた GPU メモリは、必ずしも使用済み GPU メモリと同じではありません。たとえば、カードの合計 GPU メモリが 16 GiB で、そのうち 5 GiB を Pod に割り当てるとします。Pod の起動コマンドが
sleep 1000の場合、Pod は実行中の状態になりますが、1,000 秒間 GPU を使用しません。この場合、割り当てられた GPU メモリは 5 GiB ですが、使用済み GPU メモリは 0 GiB となります。
手順1:ノードプールの作成
GPU モニタリングダッシュボードでは、フルカード、または GPU メモリ単位で GPU リソースをリクエストする Pod のメトリックを表示できます。これには、コンピューティング性能のリクエストも含まれます。
この例では、クラスターに 3 つのノードプールを作成し、異なる GPU リクエストモードでの Pod のスケジューリングとリソース使用状況を示します。ノードプールの作成に関する詳細な手順については、「ノードプールの作成」をご参照ください。ノードプールの設定は次のとおりです:
|
パラメーター |
説明 |
例 |
|
[名前] |
1 番目のノードプールの名前。 |
exclusive |
|
2 番目のノードプールの名前。 |
share-mem |
|
|
3 番目のノードプールの名前。 |
share-mem-core |
|
|
[インスタンスタイプ] |
ノードのインスタンスタイプ。この例では、10 GiB の GPU メモリを必要とする「TensorFlow Benchmark」プロジェクトを使用します。選択するインスタンスタイプは 10 GiB を超える GPU メモリを提供する必要があります。 |
ecs.gn7i-c16g1.4xlarge |
|
[想定ノード数] |
ノードプールで維持するノードの総数。 |
1 |
|
[ノードラベル (Labels)] |
このノードプールはフルカードリクエスト用です。特定のノード label は必要ありません。 |
なし |
|
2 番目のノードプールの label。これは、GPU リソースを GPU メモリ単位でリクエストすることを示します。 |
ack.node.gpu.schedule=cgpu |
|
|
3 番目のノードプールの label。これは、GPU リソースを GPU メモリ単位でリクエストし、コンピューティング性能のリクエストもサポートすることを示します。 |
ack.node.gpu.schedule=core_mem |
手順2:GPU アプリケーションのデプロイ
ノードプールを作成した後、ノードで GPU テスト Job を実行して、GPU メトリックが正しく収集されることを確認します。各 Job の label とスケジューリング関係の詳細については、「スケジューリングの有効化」をご参照ください。3 つの Job の詳細は次のとおりです:
|
名前 |
ノードプール |
GPU リソース |
|
tensorflow-benchmark-exclusive |
exclusive |
nvidia.com/gpu: 1 GPU カードを 1 枚リクエストします。 |
|
tensorflow-benchmark-share-mem |
share-mem |
aliyun.com/gpu-mem: 10 10 GiB の GPU メモリをリクエストします。 |
|
tensorflow-benchmark-share-mem-core |
share-mem-core |
10 GiB の GPU メモリと GPU カード 1 枚のコンピューティング性能の 30% をリクエストします。 |
-
Job マニフェストファイルを作成します。
-
次の YAML コンテンツを含む tensorflow-benchmark-exclusive.yaml という名前のファイルを作成します。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-exclusive spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-exclusive spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: nvidia.com/gpu: 1 # GPU カードを 1 枚リクエストします。 workingDir: /root restartPolicy: Never -
次の YAML コンテンツを含む tensorflow-benchmark-share-mem.yaml という名前のファイルを作成します。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-share-mem spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-share-mem spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: aliyun.com/gpu-mem: 10 # 10 GiB の GPU メモリをリクエストします。 workingDir: /root restartPolicy: Never -
次の YAML コンテンツを含む tensorflow-benchmark-share-mem-core.yaml という名前のファイルを作成します。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-share-mem-core spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-share-mem-core spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: aliyun.com/gpu-mem: 10 # 10 GiB の GPU メモリをリクエストします。 aliyun.com/gpu-core.percentage: 30 # カード 1 枚のコンピューティング性能の 30% をリクエストします。 workingDir: /root restartPolicy: Never
-
-
次のコマンドを実行して Job をデプロイします:
kubectl apply -f tensorflow-benchmark-exclusive.yaml kubectl apply -f tensorflow-benchmark-share-mem.yaml kubectl apply -f tensorflow-benchmark-share-mem-core.yaml -
次のコマンドを実行して Pod のステータスを確認します:
kubectl get pod実行結果の例:
NAME READY STATUS RESTARTS AGE tensorflow-benchmark-exclusive-7dff2 1/1 Running 0 3m13s tensorflow-benchmark-share-mem-core-k24gz 1/1 Running 0 4m22s tensorflow-benchmark-share-mem-shmpj 1/1 Running 0 3m46s出力から、すべての Pod が
Running状態であり、Job が正常にデプロイされたことがわかります。
手順3:GPU ダッシュボードの表示
GPUs - クラスターディメンション
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のウィンドウで、 を選択します。
-
「Prometheus モニタリング」ページで、GPU 監視 タブをクリックし、次に GPU - クラスターの次元 タブをクリックします。クラスターレベルのモニタリングダッシュボードには、次の情報が表示されます。詳細については、「クラスターディメンションのモニタリングダッシュボード」をご参照ください。
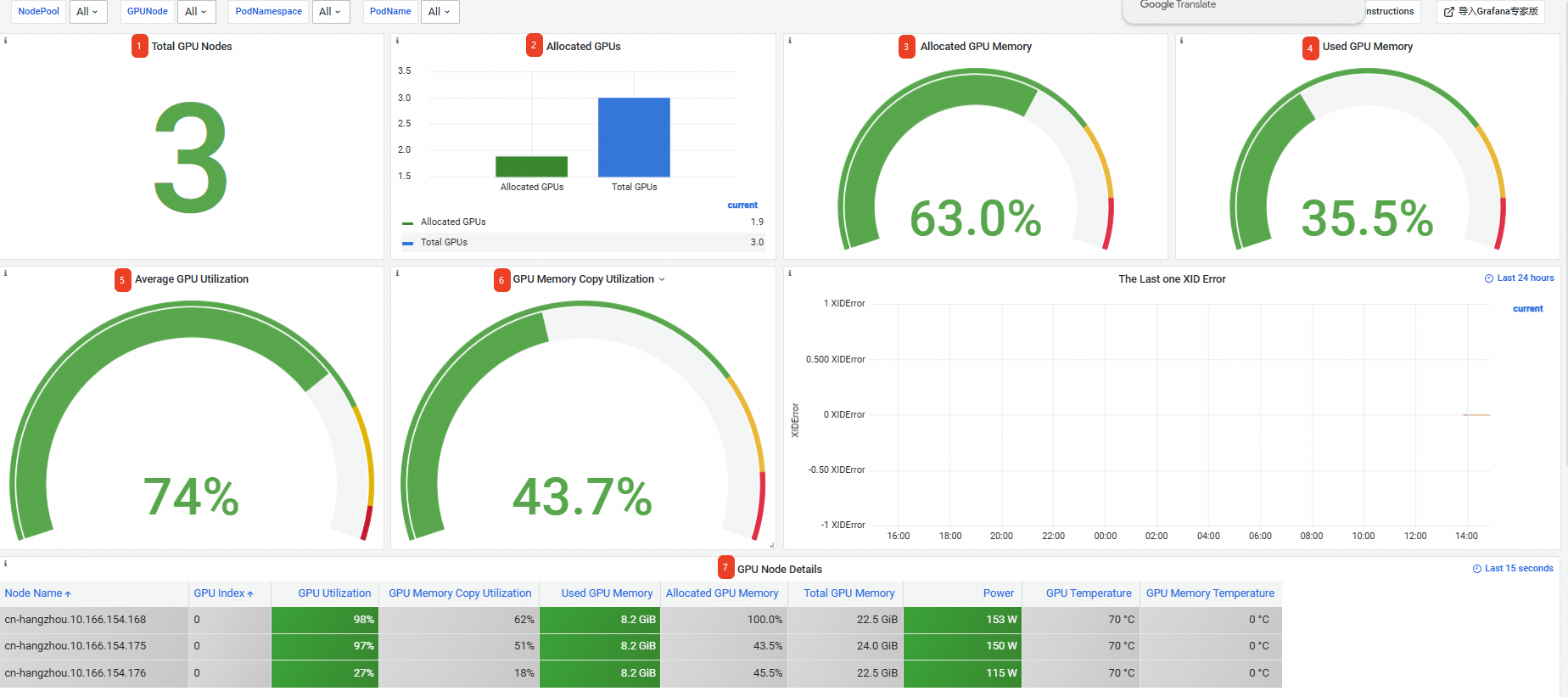
番号
パネル
説明
①
合計 GPU ノード数
3 つの GPU ノードがあります。
②
割り当て済み GPU
3 つの GPU のうち、合計 1.9 が割り当てられています。
説明フルカードリクエストの場合、1 枚のカードの割り当て率は 1 です。共有 GPU スケジューリングの場合、割り当て率は、カード上の割り当て済み GPU メモリとそのカードの合計 GPU メモリの比率です。
③
割り当て済み GPU メモリ
GPU メモリの 63.0% が割り当てられています。
④
使用済み GPU メモリ
GPU メモリの 35.5% が使用されています。
⑤
平均 GPU 使用率
すべてのカードの平均使用率は 74% です。
⑥
GPU メモリコピー使用率
すべてのカードの平均メモリコピー使用率は 43.7% です。
⑦
GPU ノード詳細
クラスター内の GPU ノードに関する情報。ノード名、GPU カードインデックス、GPU 使用率、メモリコントローラー使用率などが含まれます。
GPUs - ノード
Prometheus モニタリングページで、GPU 監視 タブをクリックし、次に GPU - ノード タブをクリックします。 [GPUNode] ドロップダウンリストから、対象のノードを選択します。 この例では cn-hangzhou.10.166.154.xxx を使用します。 ノードレベルのモニタリングダッシュボードには、次の情報が表示されます。
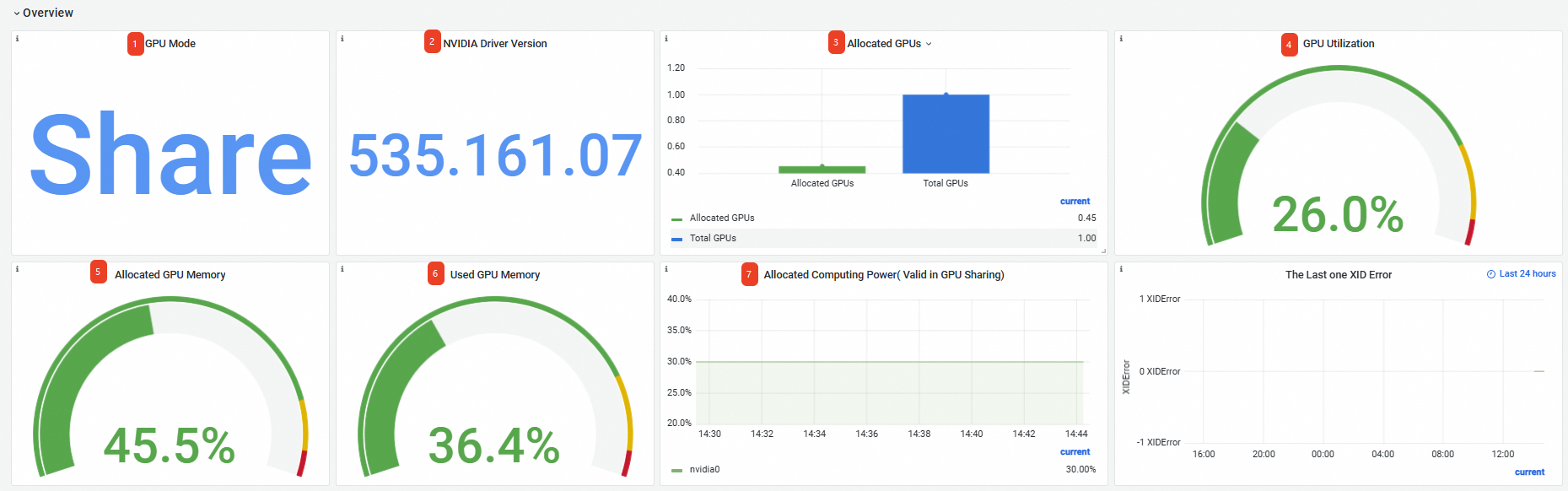

Pod 情報に加えて、[GPU Process Details] パネルには、[Container Name]、[Allocate Mode]、[Process Id]、[Process Name]、[Process Type]、[GPU Index]、[使用済み GPU メモリ]、[SM Utilization]、[GPU Memory Copy Util]、[Decode Utilization]、[Encode Utilization] の列が含まれます。
|
パネルグループ |
番号 |
パネル |
説明 |
|
概要 |
① |
GPU モード |
ノードは共有モードで動作し、GPU メモリとコンピューティング性能を使用して GPU リソースをリクエストできます。 |
|
② |
NVIDIA ドライバーバージョン |
インストールされている GPU ドライバーのバージョンは 535.161.07 です。 |
|
|
③ |
割り当て済み GPU |
1 GPU のうち、合計 0.45 が割り当てられています。 |
|
|
④ |
GPU 使用率 |
平均 GPU 使用率は 26% です。 |
|
|
⑤ |
割り当て済み GPU メモリ |
合計 GPU メモリの 45.5% が割り当てられています。 |
|
|
⑥ |
使用済み GPU メモリ |
合計 GPU メモリの 36.4% が使用されています。 |
|
|
⑦ |
割り当て済みコンピューティング性能 |
GPU カード 0 のコンピューティング性能の 30% が割り当てられています。 説明
「割り当て済みコンピューティングパワー」パネルにデータが表示されるのは、ノードでコンピューティングパワーの割り当てが有効化されている場合のみです。この例では、このパネルにデータが表示されるのは、 |
|
|
使用率 |
⑧ |
GPU 使用率 |
GPU カード 0 の使用率は、最小 0% から最大 33% の範囲にあり、平均は 12% です。 |
|
⑨ |
メモリコピー使用率 |
GPU カード 0 のメモリコピー使用率は、最小 0% から最大 22% の範囲にあり、平均は 8% です。 |
|
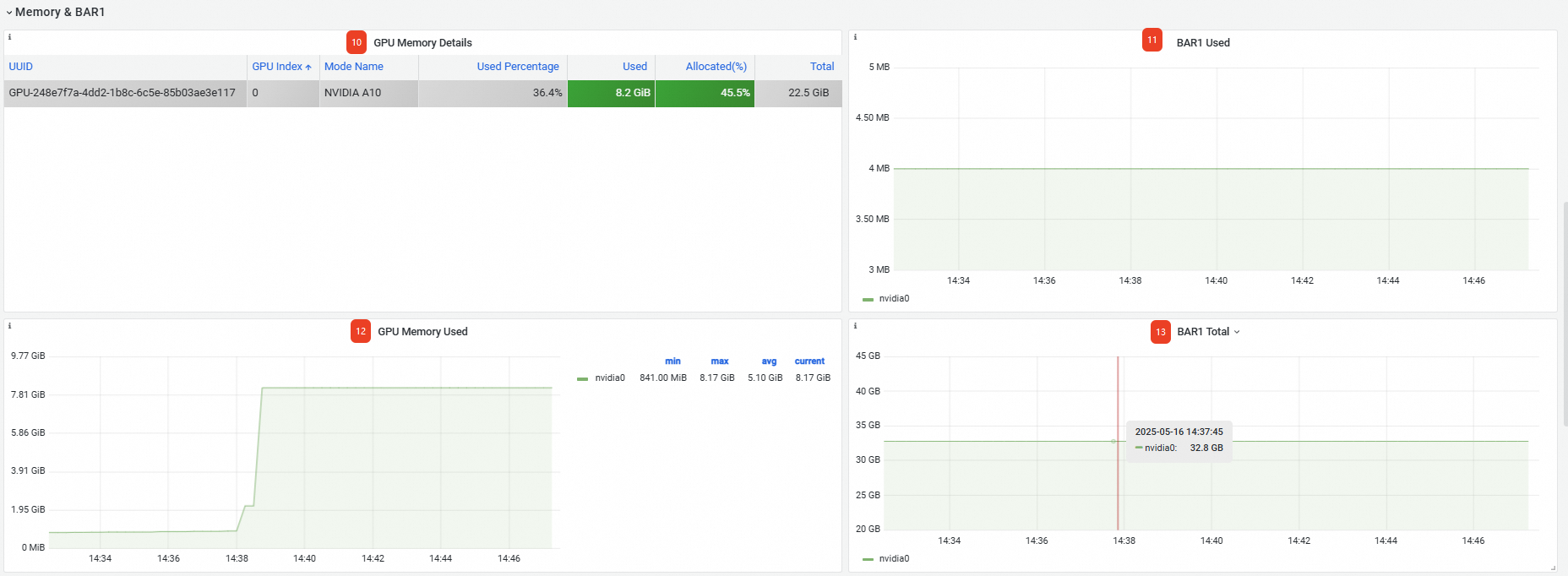
|
メモリ & BAR1 |
⑩ |
GPU メモリ詳細 |
GPU カードの詳細 (UUID、インデックス、モデルなど) を表示します。 |
|
⑪ |
使用済み BAR1 |
使用済みの BAR1 メモリは 4 MB です。 |
|
|
⑫ |
使用済みメモリ |
カードの使用済み GPU メモリは 8.17 GB です。 |
|
|
⑬ |
合計 BAR1 |
合計 BAR1 メモリは 32.8 GB です。 |
|
|
GPU プロセス |
⑭ |
GPU プロセス詳細 |
GPU プロセスの詳細 (各プロセスを含む Pod の名前空間と名前など) を表示します。 |
ページの下部で、より高度なメトリックを表示することもできます。詳細については、「GPUs - ノード」をご参照ください。
高度なメトリックは、[GPU Process] (2 パネル)、[Profiling] (12 パネル)、[Temperature & Energy] (4 パネル)、[クロック] (6 パネル)、[Retired Pages] (2 パネル)、[Violation] (6 パネル) の 6 つのパネルグループに整理されています。これらのパネルグループはデフォルトで折りたたまれています。パネルグループをクリックすると展開されます。
GPUs - アプリケーション Pod ディメンション
「Prometheus モニタリング」ページで、GPU 監視 タブをクリックし、次に GPU - ポッド タブをクリックします。このダッシュボードには、各 Pod の GPU メトリクスがテーブルに表示されます。以下で説明するフィールドに加えて、このテーブルには [Pod ソース]、[割り当てモード] (排他または共有)、[SM 使用率]、[GPU メモリコピー使用率]、[デコード使用率]、[エンコード使用率] などの列が含まれます。
|
番号 |
パネル |
説明 |
|
① |
GPU Pod 詳細 |
GPU リソースをリクエストする Pod に関する情報 (名前空間、名前、ノード、使用済み GPU メモリなど) を表示します。 説明
|
ページの下部で、より高度なメトリックを表示することもできます。詳細については、「GPUs - アプリケーション Pod ディメンション」をご参照ください。
高度なメトリックパネルグループには、[Pod Metrics (GPU Device)] (6 パネル)、[Pods Metrics (Host Resource)] (8 パネル)、[GPU Utilization (Associated with Pod)] (4 パネル)、[GPU Memory & BAR1 (Associated with Pod)] (5 パネル)、[GPU Profiling (Associated with Pod)] (12 パネル)、[GPU Temperature & Energy (Associated with Pod)] (4 パネル)、[GPU クロック (Associated with Pod)] (6 パネル) が含まれます。