ACK Edge クラスタでは、データセンターおよびエッジの GPU アクセラレーションノードを管理できます。複数のリージョンおよび環境にわたる異種計算能力を管理できます。ACK Edge クラスタ を Managed Service for Prometheus に接続できます。これにより、データセンターおよびエッジの GPU アクセラレーションノードを、クラウド内のノードと同じ方法で監視できます。
エッジノードの可観測性原則
ACK Edge クラスタでは、Express Connect 回線またはインターネットを使用して、データセンター、サードパーティクラウドベンダー、IoT デバイスなどの Infrastructure as a Service(IaaS)リソースにアクセスできます。エッジノードは、Managed Service for Prometheus がエッジノードにアクセスできるように、Express Connect 回線を使用してクラウドと通信します。これにより、可観測性が期待どおりに実行されることが保証されます。Managed Service for Prometheus は、Raven を使用して、インターネット経由でエッジノードを監視します。次の図は、手順を示しています。

Managed Service for Prometheus は、ノードの IP アドレスではなく、ノード名に基づいてメトリックを収集します。ドメイン名解決中に、CoreDNS は Hosts プラグインを構成して、エッジノード名を Raven サービスに解決します。
Managed Service for Prometheus が Raven サービスにアクセスすると、サービスのバックエンドからゲートウェイノードを選択して、エッジのネットワークドメインと通信します。
ゲートウェイノードの Raven-agent は、オンプレミスデータセンターのゲートウェイノードの Raven-agent と暗号化されたチャネルを確立します。レイヤー 3 およびレイヤー 7 のネットワーク通信がサポートされています。
オンプレミスデータセンターネットワークドメインのゲートウェイノードで、Raven-agent はターゲットノードの GPU コレクションポートにアクセスして、モニタリングデータを取得します。
エッジ GPU アクセラレーションノードを監視する
手順 1: Managed Service for Prometheus を有効にする
ACK コンソール にログインします。左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、管理するクラスタを見つけ、その名前をクリックします。左側のウィンドウで、 を選択します。
[prometheus 監視] ページで、手順に従って必要なコンポーネントをインストールし、関連するダッシュボードを確認します。
システムは自動的にコンポーネントをインストールし、ダッシュボードを確認します。インストールが完了したら、各タブをクリックしてメトリックを表示します。
手順 2: エッジ GPU アクセラレーションノードを追加する
エッジ GPU アクセラレーションノードを追加する方法の詳細については、「GPU アクセラレーションノードを追加する」をご参照ください。
手順 3:接続された GPU アクセラレーションノードにアプリケーションをデプロイして、GPU 関連メトリックの正確性を検証する
この例では、TensorFlow ベンチマークプロジェクトを使用します。排他的 GPU スケジューリング機能が使用されます。エッジ GPU アクセラレーションノードで GPU リソースを共有するアプリケーションを実行することもできます。詳細については、「複数の GPU 共有を操作する」をご参照ください。
ジョブを作成し、tensorflow.yaml ファイルとして保存します。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-exclusive spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-exclusive spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: nvidia.com/gpu: 1 #GPU を申請します。 workingDir: /root restartPolicy: Neverクラスタにジョブをデプロイします。
kubectl apply -f tensorflow.yaml
手順 4:GPU 監視ダッシュボードを表示する
ACK コンソール にログインします。左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、管理するクラスタを見つけ、その名前をクリックします。左側のウィンドウで、 を選択します。
[prometheus 監視] ページで、[GPU 監視] タブをクリックします。
[GPU - クラスタディメンション] タブをクリックして、クラスタのダッシュボードを表示します。詳細については、「クラスタダッシュボードを表示する」をご参照ください。

[GPU - ノード] タブをクリックして、GPU アクセラレーションノードのダッシュボードを表示します。ダッシュボードの詳細については、「ノードダッシュボードを表示する」をご参照ください。
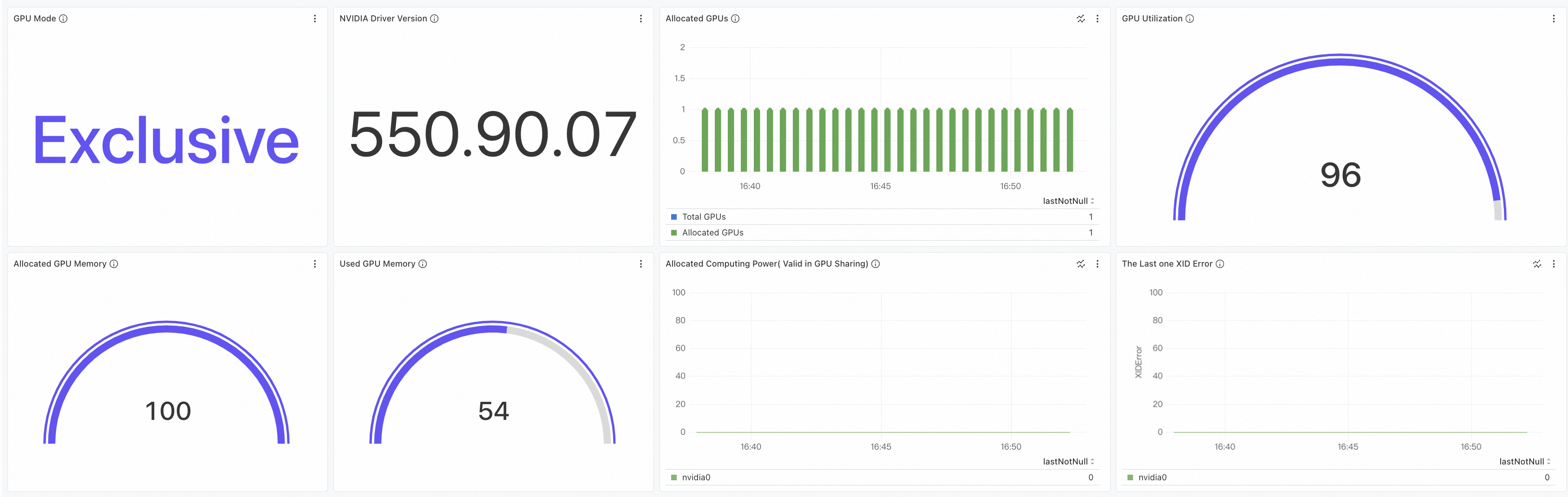
手順 5:エッジ GPU アクセラレーションノードの監視メトリックを表示する
GPU 監視で使用される GPU エクスポーターは、Data Center GPU Manager(DCGM)エクスポーターによって提供されるメトリックと互換性があります。GPU エクスポーターは、特定のシナリオの要件を満たすために、カスタムメトリックも提供します。DCGM エクスポーターの詳細については、「DCGM exporter」をご参照ください。
GPU 監視には、「DCGM エクスポーターでサポートされているメトリック」と「カスタムメトリック」が含まれています。次の操作を実行して、GPU 関連のメトリックを表示できます。
ARMS コンソール にログインします。
左側のナビゲーションウィンドウで、 を選択します。
ページ上部のドロップダウンリストから Prometheus インスタンスを選択します。
A セクションで、メトリックを選択し、[クエリを実行] をクリックします。ビジネス要件に基づいてモードを選択します。
