Saat terjadi lonjakan lalu lintas database yang tidak terduga, penskalaan manual ke atas (scale-up) memerlukan waktu—dan jika Anda lupa menurunkan skalanya kembali, Anda akan membayar sumber daya yang tidak lagi diperlukan. Skalabilitas otomatis kinerja, yang didukung oleh Database Autonomy Service (DAS), menangani kedua arah secara otomatis: instans melakukan scale-up ketika pemanfaatan CPU melebihi ambang batas yang Anda tetapkan, dan kembali melakukan scale-down saat beban mereda.
Cara kerja
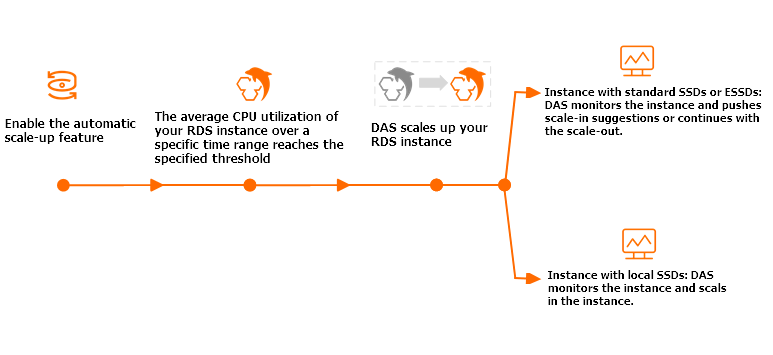
Perilaku penskalaan berbeda antara instans disk cloud dan instans disk lokal premium.
Instans disk cloud (ESSD dan disk performa premium)
Selama Observation Window, sistem memeriksa pemanfaatan CPU secara berkala. Setiap kali rata-rata pemanfaatan CPU mencapai atau melebihi CPU Trigger Threshold, instans melakukan scale-up satu tingkat—CPU, memori, IOPS, dan jumlah koneksi maksimum semuanya meningkat bersamaan. Proses ini berulang hingga instans mencapai Maximum Specifications yang Anda tetapkan.
Scale-down dipicu bila kedua kondisi berikut terpenuhi:
Instans tidak berada dalam Cool-down Period.
Selama Scale-down Observation Window (Observation Window + 10 menit), pemanfaatan CPU tetap di bawah 30% selama lebih dari 99% waktu.
Sistem melakukan scale-down secara bertahap kembali ke spesifikasi sebelum scale-up.
Koneksi sementara yang berlangsung hingga 30 detik dapat terjadi selama perubahan konfigurasi. Jadwalkan perubahan tersebut pada jam sepi dan pastikan aplikasi Anda memiliki mekanisme penghubungan ulang.
Instans disk lokal premium (tujuan umum)
Selama Scale-up Observation Window, jika pemanfaatan CPU mencapai atau melebihi ambang batas, jumlah core CPU dilipatgandakan. IOPS meningkat sebesar 1.000 untuk setiap core CPU tambahan. Memori dan jumlah koneksi maksimum tidak ditingkatkan, dan tidak ada scale-up tambahan setelah penggandaan awal.
Jika sumber daya host tidak mencukupi (kemungkinan kurang dari 1%), scale-up tidak dilakukan.
Scale-down dipicu ketika pemanfaatan CPU tetap di bawah 30% selama lebih dari 99% waktu selama Scale-down Observation Window. Baik CPU maupun IOPS kembali ke level sebelum scale-up.
Operasi scale-up dan scale-down pada instans disk lokal premium selesai dalam waktu 30 detik tanpa alih bencana instans dan tanpa dampak yang terasa bagi pengguna.
Prasyarat
Sebelum memulai, pastikan Anda telah memenuhi hal-hal berikut:
Memiliki instans ApsaraDB RDS for MySQL yang memenuhi semua kriteria berikut:
Metode penagihan: langganan atau pay-as-you-go (instans Serverless melakukan penskalaan otomatis dan tidak memerlukan konfigurasi)
Kelas penyimpanan: disk cloud (tujuan umum atau spesifikasi khusus) atau disk lokal premium (tujuan umum)
Seri produk: Edisi Ketersediaan Tinggi
Tipe instans: Edisi Standar
Wilayah: mendukung fitur deteksi anomali DAS
Saldo akun mencukupi untuk menutupi biaya scale-up
Skalabilitas otomatis kinerja tidak didukung untuk instans yang menggunakan tipe instans yang sudah dihentikan dengan disk cloud. Untuk menggunakan fitur ini, pertama-tama ubah tipe instans yang sudah dihentikan menjadi tipe instans saat ini.
Batasan dan efek samping
Instans hanya-baca
Pengaturan scale-up otomatis pada instans utama tidak diterapkan pada instansi hanya bacanya. Konfigurasikan scale-up otomatis secara terpisah untuk setiap instansi hanya baca.
Setelah failover primer/sekunder
Operasi scale-up hanya berjalan pada instans utama. Jika terjadi alih bencana setelah scale-up:
Instans utama baru (sebelumnya secondary) secara otomatis melakukan scale-up atau scale-down jika memenuhi kondisi pemicu.
Instans secondary baru (sebelumnya primary) secara otomatis melakukan scale-down ke spesifikasi awal jika memenuhi kondisi scale-down.
Efek samping mengaktifkan fitur ini
Versi minor instans ditingkatkan ke versi terbaru jika belum menjalankannya.
Mengaktifkan scale-up otomatis memberikan peran terkait layanan AliyunServiceRoleForDAS kepada DAS, sehingga DAS dapat mengakses sumber daya ApsaraDB.
Penagihan
Instans disk cloud (tujuan umum dan spesifikasi khusus)
Setelah scale-up, biaya dihitung berdasarkan tipe instans baru. Tarif bervariasi tergantung wilayah dan spesifikasi baru. Untuk detailnya, lihat halaman pembelian.
Instans disk lokal premium (tujuan umum)
Ditagih berdasarkan skema pay-as-you-go, ditagih per jam.
Rumus: Biaya per core CPU × Jumlah core CPU tambahan × Durasi scale-up (jam)
Contoh: Sebuah instans di China (Hangzhou) memiliki 4 core CPU. Setelah scale-up, menjadi 8 core. Scale-up berlangsung selama 30 menit. Harga satuan adalah USD 0,083 per core-jam.USD 0,083 per core-jam0,083 (harga satuan) × 4 (jumlah core tambahan) × 0,5 (jam) = USD 0,166
Biaya = 0,083 × 4 × 0,5 = USD 0,166
Harga satuan per wilayah (USD per core-jam)
| Wilayah | Harga satuan |
|---|---|
| China (Zhangjiakou), China (Ulanqab) | 0,063 |
| China (Hong Kong), Korea Selatan (Seoul) | 0,134 |
| Jepang (Tokyo) | 0,100 |
| Malaysia (Kuala Lumpur) | 0,102 |
| Singapura, Indonesia (Jakarta) | 0,155 |
| Jerman (Frankfurt), Inggris (London) | 0,078 |
| AS (Virginia), AS (Silicon Valley) | 0,129 |
| UEA (Dubai) | 0,091 |
| Wilayah lainnya | 0,083 |
Aktifkan skalabilitas otomatis kinerja
Instans disk cloud
Buka halaman RDS Instances. Di pojok kiri atas, pilih wilayah tempat instans Anda berada, lalu klik ID instans.
Pada bagian Configuration Information, klik Settings di samping Automatic Performance Scaling.
Pada kotak dialog, konfigurasikan parameter berikut dan klik OK.
| Parameter | Deskripsi |
|---|---|
| Automatic Performance Scaling | Aktifkan sakelar untuk mengaktifkan fitur ini. |
| Observation Window | Periode sistem memeriksa pemanfaatan CPU. Scale-down Observation Window sama dengan nilai ini ditambah 10 menit. Misalnya, jika Anda mengatur nilai ini menjadi 30 menit, periode observasi scale-down adalah 40 menit. |
| CPU Trigger Threshold | Rata-rata pemanfaatan CPU yang memicu scale-up otomatis. Saat pemanfaatan CPU mencapai atau melebihi nilai ini, scale-up dipicu. |
| Maximum Specifications | Batas atas untuk scale-up otomatis. Harus lebih besar daripada spesifikasi instans saat ini. Spesifikasi saat ini ditampilkan dalam pengaturan. |
| Cool-down Period | Interval minimum antara dua operasi scale-up atau scale-down berturut-turut. DAS terus memantau selama periode tenang tetapi tidak memicu penskalaan. Jika periode tenang dan jendela observasi berakhir bersamaan dan pemanfaatan CPU mencapai ambang batas, DAS memicu penskalaan saat kedua periode berakhir. |
| Whether to retract automatically | Jika diaktifkan, sistem melakukan scale-down secara bertahap ke spesifikasi sebelum scale-up, setelah instans keluar dari Cool-down Period dan pemanfaatan CPU tetap di bawah 30% selama lebih dari 99% waktu selama Scale-down Observation Window. |
Fitur scale-down otomatis dijamin berjalan stabil hanya pada versi arsitektur baru (kindcode=18). Jalankan DescribeDBInstanceAttribute untuk memeriksa versi arsitektur instans.
Instans disk lokal premium
Buka halaman RDS Instances. Di pojok kiri atas, pilih wilayah tempat instans Anda berada, lalu klik ID instans.
Pada kotak dialog, konfigurasikan parameter berikut dan klik OK.
| Parameter | Deskripsi |
|---|---|
| Automatic Performance Scaling | Aktifkan sakelar untuk mengaktifkan fitur ini. |
| Scale-up Observation Window | Periode sistem memeriksa pemanfaatan CPU untuk menentukan apakah akan memicu scale-up. |
| CPU Trigger Threshold | Rata-rata pemanfaatan CPU yang memicu scale-up otomatis. Saat pemanfaatan CPU mencapai atau melebihi nilai ini, scale-up dipicu. |
| Scale-down Observation Window | Periode sistem memeriksa pemanfaatan CPU untuk menentukan apakah akan memicu scale-down. Jika pemanfaatan CPU tetap di bawah 30% selama lebih dari 99% periode ini, scale-down dipicu. |
FAQ
Apa yang terjadi jika instans telah mencapai batas atas serinya?
Beli instans dari seri dengan spesifikasi lebih tinggi. Lalu migrasikan data ke instans baru menggunakan DTS.
Apakah instans terus dipantau selama scale-up?
Ya. Misalnya, jika Observation Window adalah 5 menit dan scale-up membutuhkan 10 menit, total waktu yang berlalu adalah 15 menit. Selama scale-up, sistem memantau instans tetapi tidak memicu scale-up lain hingga scale-up saat ini selesai. Setelah scale-up selesai, jika pemanfaatan CPU dalam Observation Window masih memenuhi ambang batas, scale-up lain dipicu. Proses ini berulang hingga instans mencapai Maximum Specifications.
Langkah selanjutnya
Jika skalabilitas otomatis tidak memenuhi kebutuhan Anda, lakukan penskalaan instans secara manual: Ubah spesifikasi instans.
Jika lonjakan lalu lintas Anda terjadi pada waktu yang dapat diprediksi, gunakan scheduled auto scaling untuk melakukan scale-out pada waktu yang telah ditentukan dan mengembalikan tipe instans asli secara otomatis setelah puncak berakhir.