ChatBI menggunakan teknologi natural language to SQL (NL2SQL) untuk membantu bisnis menghasilkan laporan dengan melakukan kueri data menggunakan bahasa alami. Topik ini menggunakan sistem manajemen restoran "Alixiang" sebagai contoh untuk memandu Anda melalui fitur-fitur utama ChatBI sehingga Anda dapat segera memulai dan menggunakan layanan ini secara efisien.
Aktifkan fitur PolarDB for AI
Tambahkan node AI dan atur akun database untuk terhubung ke node AI tersebut. Untuk informasi selengkapnya, lihat Aktifkan fitur PolarDB for AI.
CatatanJika Anda telah menambahkan node AI saat membeli kluster, Anda dapat langsung mengatur akun database untuk node AI tersebut. Untuk informasi selengkapnya, lihat Buat akun standar.
Akun ini harus memiliki izin baca dan tulis untuk tabel data target agar semua operasi database dalam proses konversi ChatBI dapat dieksekusi.
Gunakan Cluster Endpoint untuk terhubung ke kluster PolarDB. Untuk informasi selengkapnya, lihat Masuk ke PolarDB for AI.
CatatanSaat terhubung ke kluster dari command line, tambahkan opsi
-c.DMS terhubung ke kluster menggunakan Primary address secara default. Anda harus mengubahnya secara manual menjadi Cluster Endpoint. Setelah perubahan dilakukan, tutup jendela SQL asli dan buka yang baru untuk mengeksekusi pernyataan SQL.
Persiapan data
"Alixiang" adalah perusahaan restoran fiktif. Sistem manajemen tagihannya berisi tiga tabel berikut. Anda dapat mengunduhnya dengan mengklik tautan tersebut.
Anda dapat menambahkan komentar untuk tabel dan kolom berdasarkan skema tabel Anda. Hal ini membantu Large Language Model (LLM) lebih memahami struktur data, sehingga meningkatkan akurasi dan efisiensi model selama pemrosesan dan analisis data.
CREATE TABLE restaurant_info (
id INT COMMENT 'ID Outlet',
position VARCHAR(128) COMMENT 'Lokasi outlet',
PRIMARY KEY (id)
) COMMENT='Tabel outlet';
CREATE TABLE menu_info (
id INT COMMENT 'ID item menu',
name VARCHAR(64) COMMENT 'Nama item menu',
type INT COMMENT 'Jenis item menu',
unit_price INT COMMENT 'Harga satuan',
PRIMARY KEY (id)
) COMMENT='Tabel menu';
CREATE TABLE bill_info (
id INT COMMENT 'ID tagihan',
items VARCHAR(512) COMMENT 'Item yang dipesan',
actural_amount INT COMMENT 'Jumlah yang dibayarkan',
restaurant_id INT COMMENT 'ID outlet',
waiter VARCHAR(16) COMMENT 'Pelayan',
diner_count INT COMMENT 'Jumlah tamu',
pay_time DATE COMMENT 'Waktu pemesanan',
PRIMARY KEY (id)
) COMMENT='Tabel tagihan';Gunakan ChatBI
Selanjutnya, Anda dapat menggunakan model NL2SQL PolarDB for AI untuk menghasilkan pernyataan SQL yang sesuai dengan pertanyaan pengguna.
Buat indeks skema tabel
Anda dapat menggunakan pernyataan SQL berikut untuk membuat indeks skema tabel bernama schema_index guna memberikan informasi skema tabel kepada Large Language Model (LLM).
/*polar4ai*/CREATE TABLE schema_index(id integer, table_name varchar, table_comment text_ik_max_word, table_ddl text_ik_max_word, column_names text_ik_max_word, column_comments text_ik_max_word, sample_values text_ik_max_word, vecs vector_768,ext text_ik_max_word, PRIMARY key (id));Tabel ini tidak terlihat secara langsung di database. Anda dapat menjalankan pernyataan SQL berikut untuk melihat informasinya.
/*polar4ai*/SHOW TABLES;Selanjutnya, Anda dapat menggunakan pernyataan SQL berikut untuk mengimpor skema tabel data ke dalam tabel indeks schema_index.
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema') INTO schema_index;Saat mengeksekusi pernyataan tersebut, PolarDB for AI akan melakukan vektorisasi terhadap semua tabel di database saat ini dan mengambil sampel nilai kolom secara default.
Setelah eksekusi, sistem akan mengembalikan task_id dari tugas latar belakang, misalnya bce632ea-97e9-11ee-bdd2-492f4dfe0918. Anda dapat menggunakan SQL berikut untuk mengecek status tugas saat ini. Ketika taskStatus yang dikembalikan bernilai finish, pembuatan indeks telah selesai.
/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;Gunakan model NL2SQL untuk menjawab pertanyaan
Anda dapat mengeksekusi pernyataan SQL berikut untuk menggunakan NL2SQL berbasis LLM secara online. Pada contoh berikut, kueri pengguna adalah Berapa total pendapatan minggu ini?, dan indeks skema tabel yang digunakan adalah schema_index.
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select 'What is the total revenue for this week') WITH (basic_index_name='schema_index');Database perlu menunggu beberapa saat untuk menerima respons dari LLM. Hasil yang diharapkan adalah sebagai berikut:
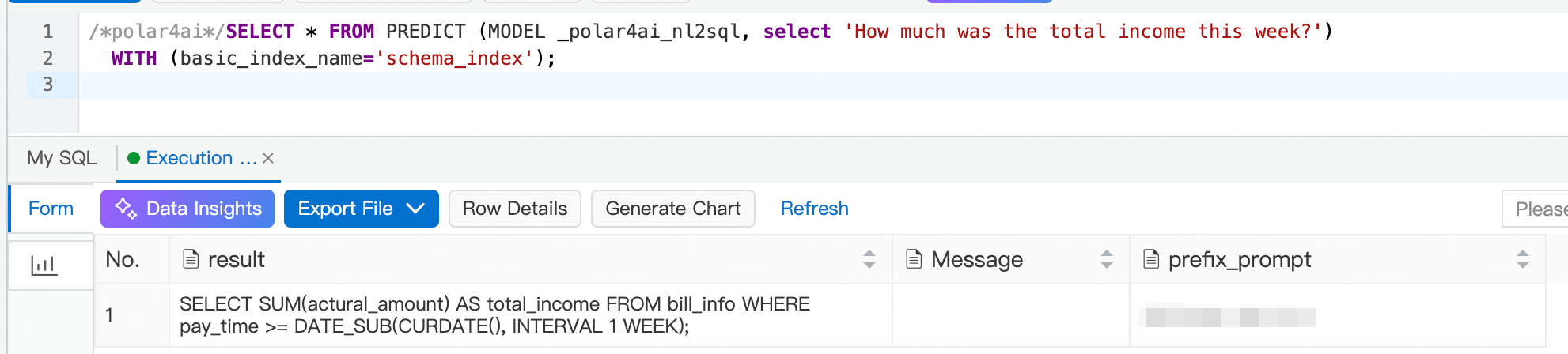
Berdasarkan contoh di atas, Anda juga dapat mengajukan beberapa pertanyaan umum yang mencakup berbagai skenario, seperti GROUP BY, JOIN multi-tabel, ORDER BY, dan formula.
No. | Pertanyaan pengguna | Nilai kembali NL2SQL |
1 | Urutkan outlet berdasarkan pendapatan |
|
2 | Outlet mana di Shanghai yang memiliki pendapatan tertinggi? |
|
3 | Berapa rata-rata pengeluaran per orang di Shanghai? |
|
4 | Apa 10 item menu yang paling sering dipesan bulan ini? |
|
5 | Berapa persentase pertumbuhan pendapatan bulan ke bulan bulan ini dibandingkan bulan lalu? |
|
6 | Outlet mana di Shanghai yang memiliki trafik pelanggan tertinggi? |
|
Seperti yang Anda lihat, model NL2SQL berbasis LLM dapat menjawab pertanyaan pengguna secara efektif, tetapi beberapa respons tidak sesuai harapan. Misalnya, pada pertanyaan kedua, pengguna ingin nama outlet dikembalikan. Jika pertanyaan tersebut diformulasikan ulang menjadi Outlet mana di Shanghai yang memiliki pendapatan tertinggi? Harap kembalikan nama outletnya, model akan mengembalikan pernyataan SQL berikut: SELECT r.name FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id WHERE r.position = 'Shanghai' ORDER BY b.actural_amount DESC LIMIT 1;. Anda juga dapat meningkatkan akurasi dengan melakukan fine-tuning pada model. Bagian berikut membahas isu-isu tersebut.
Lakukan fine-tuning pada model
Konfigurasikan templat pertanyaan
Anda dapat menggunakan templat pertanyaan umum untuk membimbing model dengan memperkenalkan pengetahuan spesifik sehingga model menghasilkan pernyataan SQL berdasarkan pengetahuan tersebut.
Eksekusi SQL berikut untuk membuat tabel templat pertanyaan
polar4ai_nl2sql_pattern.CREATE TABLE `polar4ai_nl2sql_pattern` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `pattern_question` text COMMENT 'Templat pertanyaan', `pattern_description` text COMMENT 'Deskripsi templat', `pattern_sql` text COMMENT 'SQL templat', `pattern_params` text COMMENT 'Parameter templat', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;Nama tabel harus diawali dengan
polar4ai_nl2sql_pattern, dan skema tabel harus mencakup lima kolom dalam pernyataanCREATE TABLEdi atas.Selanjutnya, buat tabel indeks
pattern_indexuntuk templat pertanyaan./*polar4ai*/CREATE TABLE pattern_index(id integer, pattern_question text_ik_max_word, pattern_description text_ik_max_word, pattern_sql text_ik_max_word, pattern_params text_ik_max_word, pattern_tables text_ik_max_word, vecs vector_768, PRIMARY key (id));Kami mengonfigurasi templat untuk pertanyaan kedua, yang digunakan untuk fine-tuning agar mengembalikan alamat outlet.
Eksekusi pernyataan SQL berikut untuk menambahkan pola baru:
INSERT INTO polar4ai_nl2sql_pattern (id, pattern_question, pattern_description, pattern_sql, pattern_params) VALUES ( 1, "Which outlet in #{position} has the highest revenue?", "Which outlet in [location] has the highest revenue?", "SELECT r.position FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id WHERE r.position LIKE '%#{position}%' GROUP BY r.position ORDER BY SUM(b.actural_amount) DESC LIMIT 1;", '[{"table_name":"bill_info","param_info":[{"param_name":"#{position}","value":["Shanghai"]}], "explanation": "Location of consumption"}]' );Pola ini menggunakan slot untuk mencocokkan berbagai lokasi. Masukkan pernyataan SQL yang benar di kolom
pattern_sqldan tandai slot dengan#{}. Kolompattern_paramsdigunakan untuk post-processing tambahan informasi tabel tetapi dapat diabaikan di sini.Selanjutnya, impor informasi templat pertanyaan ke dalam tabel indeks.
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='pattern') INTO pattern_index;Seperti proses pembuatan indeks untuk
schema_index, ID tugas juga dikembalikan. Anda dapat mengeksekusi/*polar4ai*/show task 'xxx-xxx-xxx'untuk melihat status tugas saat ini.CatatanJika data di tabel
polar4ai_nl2sql_patterndiperbarui, Anda perlu membuat ulangpattern_indexdan mengimpor data lagi. Anda dapat menggunakan pernyataan SQL berikut untuk menghapus indeks lama:/*polar4ai*/DROP TABLE pattern_index;Eksekusi ulang pernyataan SQL yang menyebabkan masalah dan tambahkan petunjuk
pattern_index./*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select 'Which outlet in Shanghai has the highest revenue?') WITH (basic_index_name='schema_index',pattern_index_name='pattern_index');
Buat tabel konfigurasi
Jika Anda ingin melakukan pra-pemrosesan pertanyaan atau post-processing pada SQL yang dihasilkan, Anda dapat menggunakan tabel konfigurasi.
Petunjuk makna kosakata
Untuk pertanyaan keenam, karena Large Language Model (LLM) tidak dapat memahami istilah 'foot traffic' secara akurat, Anda dapat melakukan pra-pemrosesan dengan mengonfigurasi tabel polar4ai_nl2sql_llm_config.
CREATE TABLE `polar4ai_nl2sql_llm_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key',
`is_functional` int(11) NOT NULL DEFAULT '1' COMMENT 'Apakah aktif',
`text_condition` text COMMENT 'Kondisi teks',
`query_function` text COMMENT 'Pemrosesan kueri',
`formula_function` text COMMENT 'Informasi formula',
`sql_condition` text COMMENT 'Kondisi SQL',
`sql_function` text COMMENT 'Pemrosesan SQL',
PRIMARY KEY (`id`)
);Masukkan item konfigurasi terkait untuk mengonfigurasi LLM agar menghitung "customer traffic" atau "customer flow" sebagai "jumlah tamu".
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
1,
1,
"customer traffic||customer flow",
"",
"Customer traffic or customer flow is calculated as the sum of the number of diners",
"",
""
);Dalam kasus ini, nilai 1 untuk is_functional menunjukkan bahwa item konfigurasi tersebut valid. Nilai kolom text_condition adalah 'people traffic||customer traffic', yang mencocokkan pertanyaan yang mengandung 'people traffic' atau 'customer traffic'. Kolom formula_function menjelaskan istilah khusus kepada Large Language Model (LLM) menggunakan teks atau formula.
Dalam kasus ini, Anda dapat langsung mengeksekusi pembuatan SQL tanpa perlu membuat tabel indeks atau melakukan vektorisasi. Hasilnya adalah sebagai berikut.

Petunjuk pencarian fuzzy
Pada pertanyaan 3, penggunaan operator = untuk mengambil nama tempat akan gagal jika namanya tidak cocok secara eksak. Oleh karena itu, Anda harus menggunakan pencarian fuzzy untuk pencocokan nama tempat. Anda dapat menambahkan item konfigurasi berikut.
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
2,
1,
"",
"",
"Matching for the outlet location 'position' requires a fuzzy search",
"",
""
);Jika text_condition kosong, item konfigurasi tersebut berlaku secara global. (Gunakan dengan hati-hati.)
Hasilnya ditunjukkan pada gambar di bawah. Seperti yang Anda lihat, pencocokan lokasi berhasil menggunakan pencarian fuzzy.
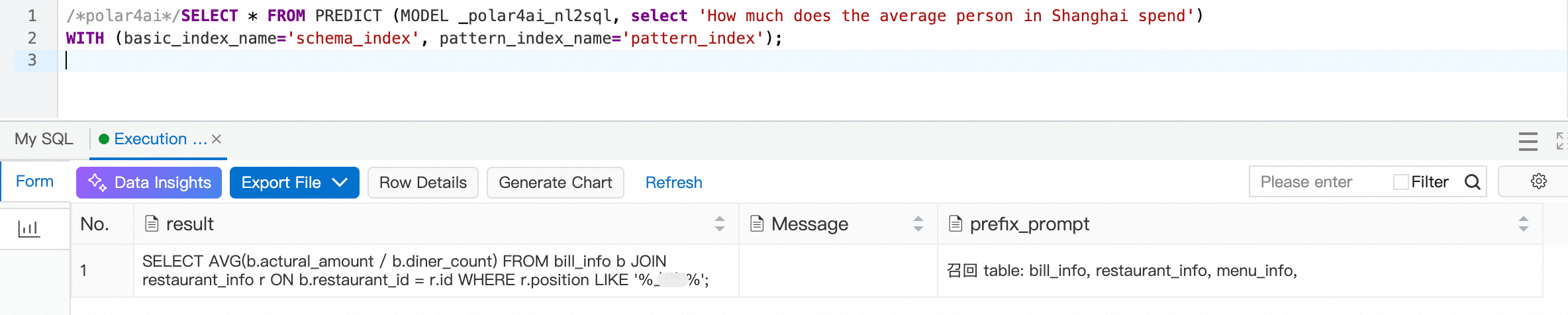
Demikian pula, untuk pertanyaan 5, Anda dapat menambahkan formula perhitungan month-over-month dan year-over-year ke dalam tabel konfigurasi polar4ai_nl2sql_llm_config untuk meningkatkan presisi SQL yang dihasilkan. Anda dapat mencobanya sendiri.
Output grafik
Setelah menghasilkan pernyataan SQL dengan NL2SQL, Anda dapat mengambil hasil kueri dan menampilkannya secara visual menggunakan grafik, seperti grafik kolom, grafik garis, dan grafik lingkaran. Solusi NL2Chart di PolarDB dapat mengeksekusi pernyataan SQL Anda berdasarkan pertanyaan Anda dan mengembalikan laporan yang sesuai. Solusi ini mendukung grafik kolom, grafik lingkaran, dan grafik garis.
Asumsikan pernyataan Anda di NL2SQL adalah sebagai berikut:
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select 'Merchant type statistics') WITH (basic_index_name='schema_index',pattern_index_name='pattern_index');Setelah pernyataan SQL yang sesuai dihasilkan, pastikan pernyataan tersebut berjalan dan mengembalikan hasil yang bermakna serta tidak kosong.
SELECT merchtype AS merchant_type, COUNT(*) AS product_count FROM hkrt_merchant_info GROUP BY merchtype;Gunakan NL2Chart:
Sintaksis
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, <SQL_statement>) WITH (usr_query = <usr_query>, result_type = <result_type>);Parameter
Nama parameter
Deskripsi
Nilai contoh
usr_query
Pertanyaan input pengguna, digunakan untuk memperjelas kebutuhan dalam menghasilkan grafik.
"Statistik penjualan setiap kuartal tahun 2023"
result_type
Menentukan jenis hasil yang dikembalikan. Saat ini hanya mendukung
'IMAGE'.'IMAGE'SQL statement
Pernyataan kueri SQL yang dihasilkan oleh modul NL2SQL, digunakan untuk mengambil data.
SELECT quarter, sales FROM sales_data WHERE year = 2023Contoh: Konversi hasil kueri dari pernyataan SQL yang dihasilkan menjadi grafik
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, SELECT merchtype AS merchant_type, COUNT(*) AS number_of_merchants FROM hkrt_merchant_info GROUP BY merchtype) WITH (usr_query = 'Merchant type statistics', result_type='IMAGE');Hasilnya adalah sebagai berikut:
CatatanTautan yang dikembalikan adalah URL gambar yang berlaku selama 90 menit.
http://db4ai-xxx-xx-xxxx-xxx-xxxx.aliyuncs.com/pc-bpze47ma2c515087l6/OSSAccessKeyId=xxxxxxx&Expires=1716130199&Signature=KvPFzfMebIEmqxPIXURurwwbsXM%3D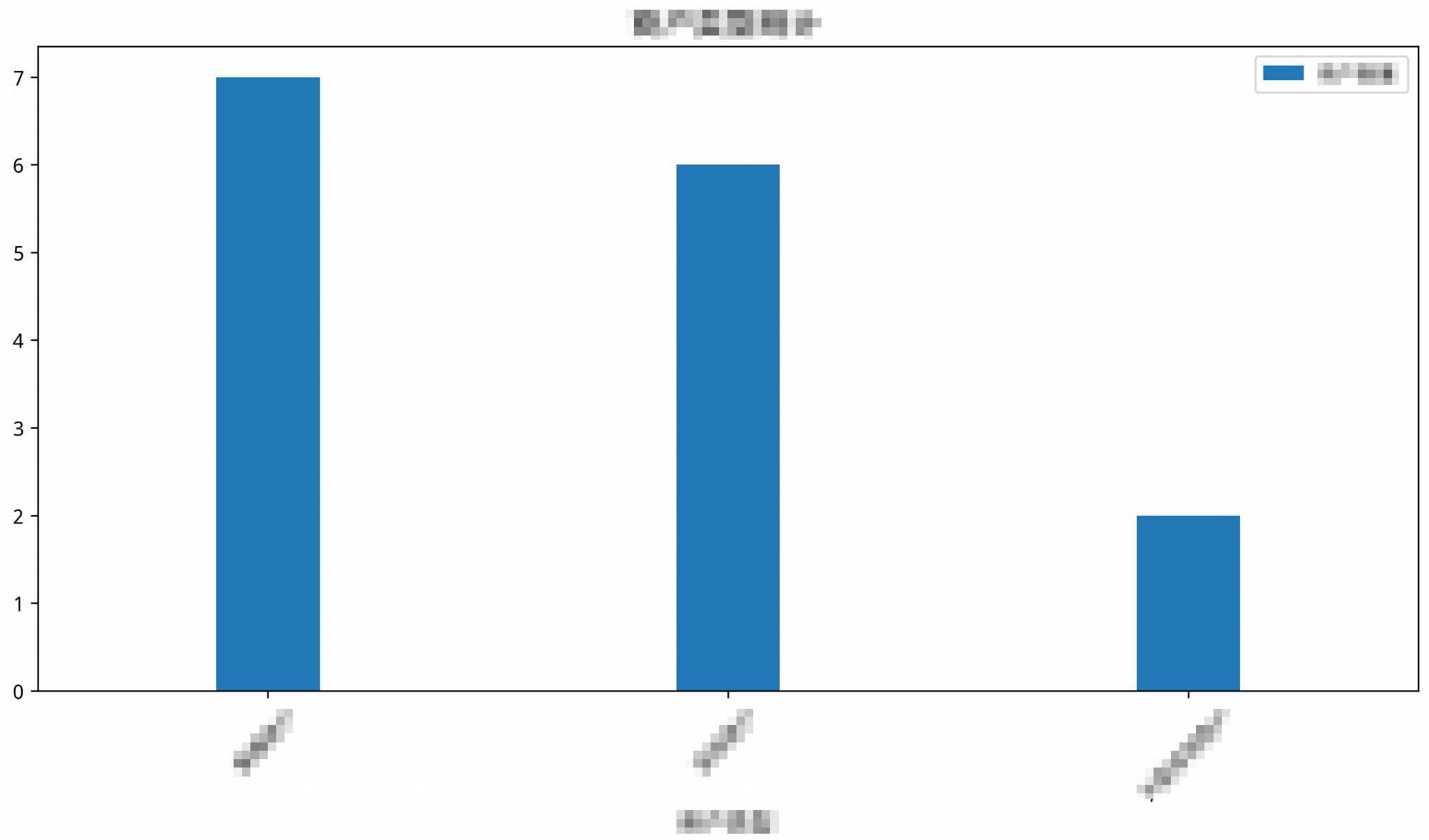
(Opsional) Pemilihan jenis grafik dan pemilihan paksa
Model memilih grafik yang sesuai berdasarkan pemahamannya terhadap pertanyaan pengguna dan data. Kami merekomendasikan menggunakan pertanyaan pengguna untuk membimbing model dalam menghasilkan grafik.
Tabel berikut menunjukkan pemetaan antara jenis pertanyaan dan jenis grafik:
Jenis pertanyaan
Jenis grafik
Contoh pertanyaan pengguna
Deskripsi
Statistik jumlah
Grafik kolom
"Harap berikan statistik penjualan berdasarkan kota"
Menunjukkan perbandingan numerik antar kategori berbeda, seperti jumlah, total, atau frekuensi.
Perubahan tren
Grafik garis
"Harap tunjukkan tren pertumbuhan pengguna selama satu tahun terakhir"
Menunjukkan tren data dari waktu ke waktu atau lintas kategori berurutan, menekankan kontinuitas.
Distribusi proporsi
Grafik lingkaran
"Harap tunjukkan proporsi penjualan setiap lini produk"
Cocok untuk menunjukkan hubungan proporsional bagian terhadap keseluruhan. Datanya harus bersifat kategorikal dan memiliki total yang jelas.
Paksa jenis grafik tertentu dengan memodifikasi parameter
usr_query. Tambahkan perintah tambahan di akhir parameterusr_query:-- Masukkan SQL output ke nl2chart untuk menggambar grafik garis /*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, SELECT merchtype AS merchant_type, COUNT(*) AS number_of_merchants FROM hkrt_merchant_info GROUP BY merchtype ) WITH (usr_query = 'Merchant type statistics, draw a line chart', result_type='IMAGE');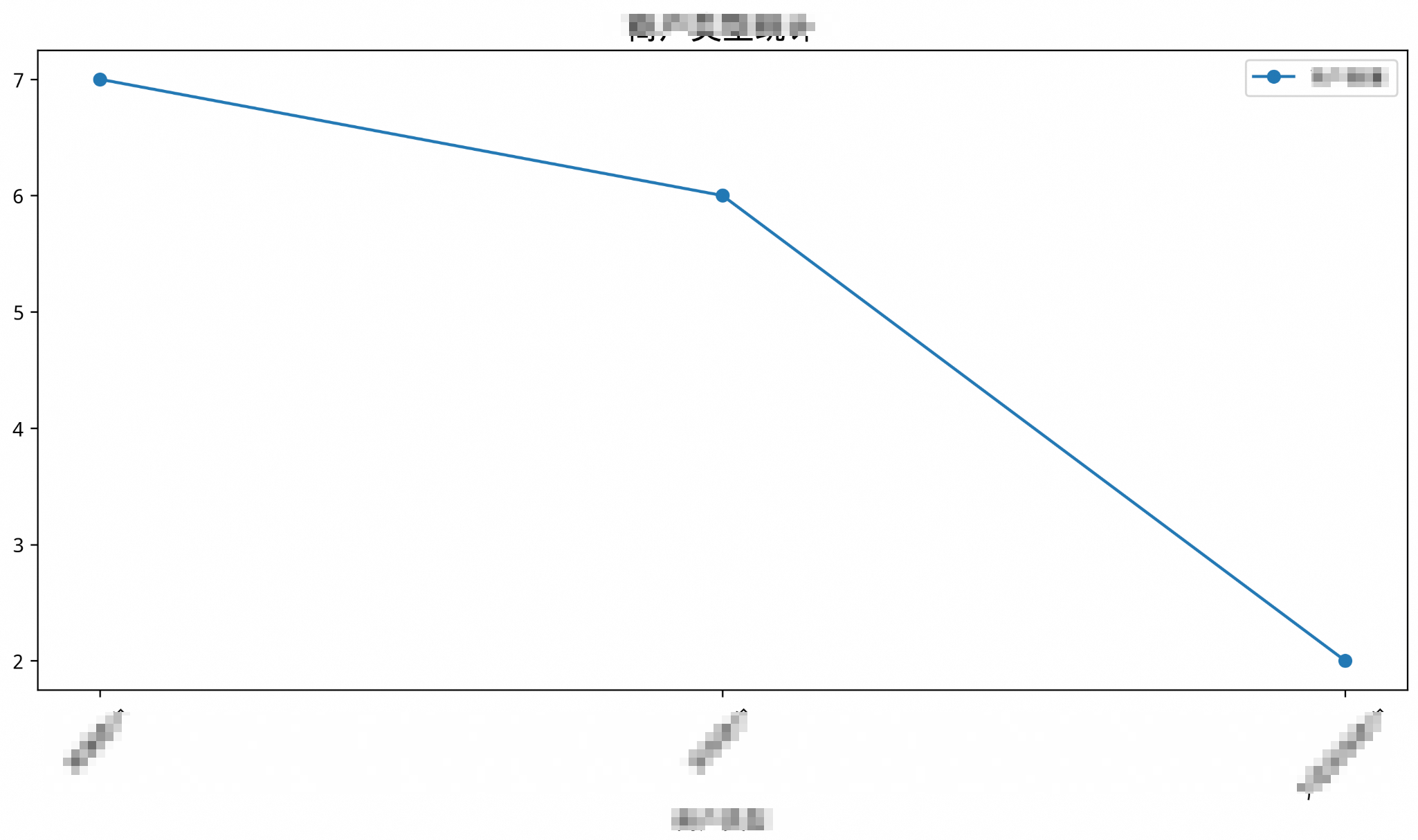
-- Masukkan SQL output ke nl2chart untuk menggambar grafik lingkaran /*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, SELECT merchtype AS merchant_type, COUNT(*) AS number_of_merchants FROM hkrt_merchant_info GROUP BY merchtype ) WITH (usr_query = 'Merchant type statistics, draw a pie chart', result_type='IMAGE');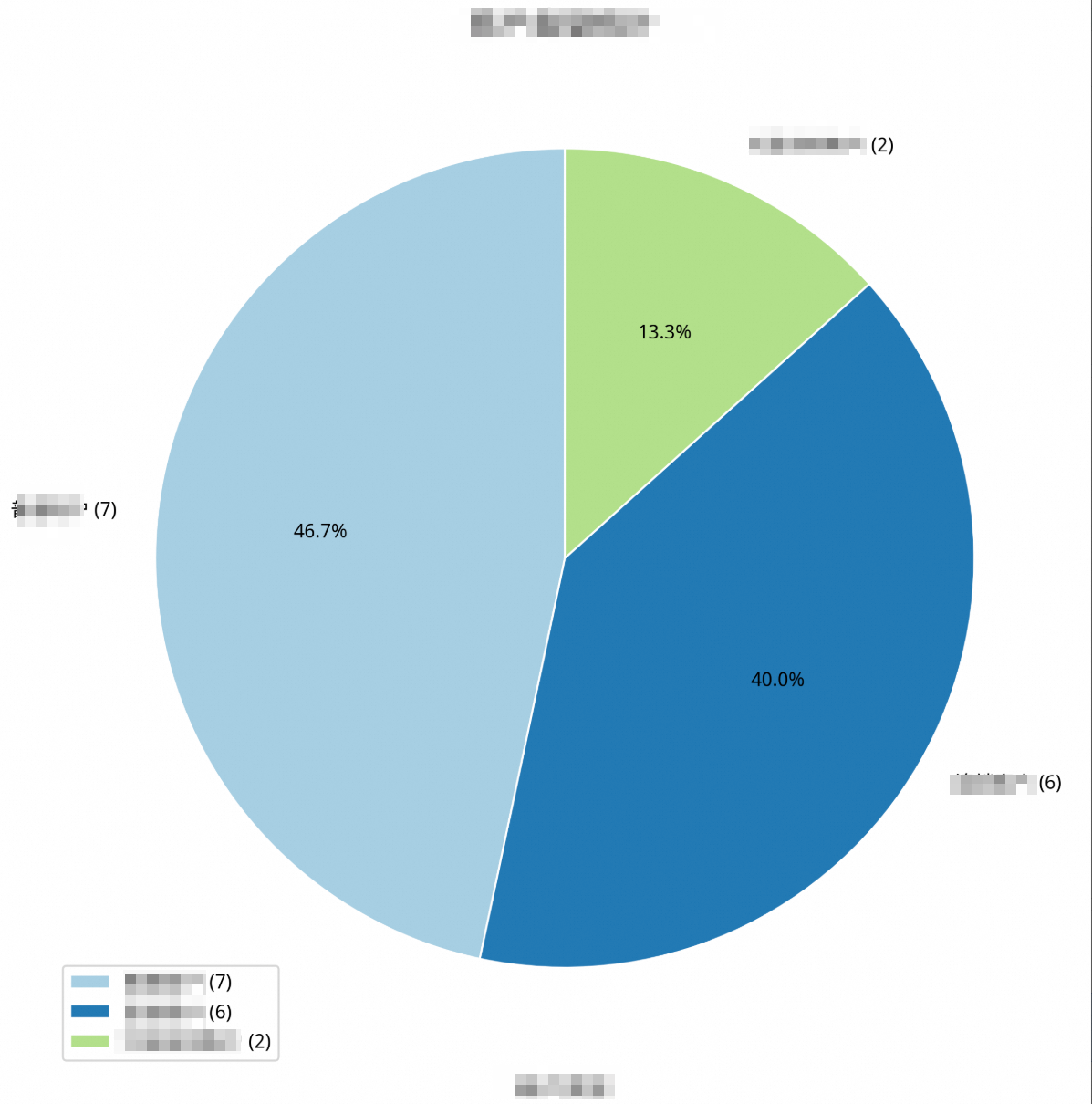
Untuk informasi selengkapnya, lihat NL2Chart: Hasilkan grafik cerdas dari bahasa alami.
Latih ulang dan fine-tune model
Jika model tidak memenuhi kebutuhan bisnis Anda, Anda dapat melatih ulang model dan melakukan fine-tuning pada parameter internalnya untuk mencapai hasil yang lebih baik.
Kondisi
Fitur ini hanya tersedia untuk kluster dengan node AI spesifikasi polar.mysql.x8.2xlarge.gpu (16 core, 125 GB, dan satu GU100).
Hanya satu model yang dapat dilatih dalam satu waktu.
Hanya satu model yang dapat diterapkan dalam satu waktu.
Petunjuk
Latih model
/*polar4ai*/CREATE MODEL udf_qwen14b WITH (model_class='qwen-turbo', model_parameter=(basic_index_name='schema_index', pattern_index_name='pattern_index',training_type='efficient_sft')) as (SELECT '')Parameter
Nama parameter | Deskripsi | Default | Nilai valid/Rentang |
model_class | Jenis model. Saat ini mendukung {'qwen-14b-chat', 'qwen-turbo'}. | None | {'qwen-14b-chat', 'qwen-turbo'} |
model_parameter | Pengaturan parameter model, termasuk parameter wajib dan opsional. | None | None |
basic_index_name | Nama tabel indeks tempat informasi database dalam data pelatihan berasal. Ini harus berupa tabel indeks database. | None | None |
pattern_index_name | Nama tabel indeks tempat informasi templat pertanyaan dalam data pelatihan berasal. Ini harus berupa tabel indeks templat pertanyaan. | None | None |
training_type | Jenis pelatihan. Nilai valid adalah {'efficient_sft', 'sft'}. 'efficient_sft' menunjukkan pelatihan efisien, biasanya menggunakan metode LoRa. 'sft' menunjukkan pelatihan parameter penuh. | None | {'efficient_sft', 'sft'} |
n_epochs | Jumlah epoch. Jumlah kali model belajar dari dataset selama pelatihan. Rentang yang direkomendasikan adalah 1 hingga 3, yang dapat disesuaikan sesuai kebutuhan. | 3 | [1, 200] |
learning_rate | Tingkat pembelajaran. Mewakili bobot inkremental untuk setiap pembaruan data. Tingkat pembelajaran yang lebih besar menghasilkan perubahan parameter yang lebih besar dan berdampak lebih signifikan pada model. | '3e-4' | None |
batch_size | Ukuran batch. Mewakili ukuran langkah data untuk pembaruan parameter model. Ukuran batch yang direkomendasikan adalah 16 atau 32. | 16 | {8, 16, 32} |
lr_scheduler_type | Kebijakan tingkat pembelajaran. Secara dinamis mengubah tingkat pembelajaran yang digunakan saat memperbarui bobot selama pelatihan. | 'linear' | {'linear', 'cosine', 'cosine_with_restarts', 'polynomial', 'constant', 'constant_with_warmup', 'inverse_sqrt', 'reduce_lr_on_plateau'} |
eval_steps | Ukuran langkah interval untuk validasi model, digunakan untuk evaluasi berkala terhadap akurasi dan loss pelatihan. | 50 | [1, 2147483647] |
sequence_length | Panjang urutan data pelatihan. Panjang maksimum satu sampel. Data yang melebihi panjang ini akan dipotong secara otomatis. | 2048 | [500, 2048] |
lr_warmup_ratio | Proporsi total langkah pelatihan yang digunakan untuk warmup. | 0.05 | (0, 1) |
weight_decay | Regularisasi L2, yang membantu mengurangi overfitting. | 0.01 | (0, 0.2) |
gradient_checkpointing | Mengaktifkan atau menonaktifkan gradient checkpointing untuk menghemat Memori GPU. | 'True' | {'True', 'False'} |
use_flash_attn | Menentukan apakah akan menggunakan Flash Attention. | 'True' | {'True', 'False'} |
lora_rank | Ukuran rank dalam pelatihan LoRa, yang memengaruhi sejauh mana data pelatihan memengaruhi model. | 8 | {2, 4, 8, 16, 32, 64} |
lora_alpha | Koefisien penskalaan dalam pelatihan LoRa, digunakan untuk menyesuaikan bobot pelatihan awal. | 32 | {8, 16, 32, 64} |
lora_dropout | Rasio neuron yang di-drop secara acak selama pelatihan. Hal ini mencegah overfitting dan meningkatkan kemampuan generalisasi model. | 0.1 | (0, 0.2) |
lora_target_modules | Memilih modul spesifik model untuk fine-tuning dan optimasi. | 'ALL' | {'ALL', 'AUTO'} |
Lihat model
/*polar4ai*/SHOW model udf_qwen14bHapus model
/*polar4ai*/DROP model udf_qwen14bLihat semua model
/*polar4ai*/SHOW modelsTerapkan model
Model yang telah dilatih hanya dapat digunakan dalam NL2SQL setelah diterapkan.
/*polar4ai*/deploy model udf_qwen14bLihat penerapan
/*polar4ai*/SHOW deployment udf_qwen14bHapus penerapan
/*polar4ai*/DROP deployment udf_qwen14bLihat semua penerapan
/*polar4ai*/SHOW deploymentsGunakan model yang diterapkan untuk bahasa alami ke SQL
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT 'What is the content for id=1?') WITH (basic_index_name='schema_index', llm_model='udf_qwen14b')Parameter
Parameter | Deskripsi |
basic_index_name | Tidak boleh kosong. Anda harus menentukan tabel indeks untuk informasi database yang terkait dengan pertanyaan saat ini. |
llm_model | Opsional. Jika Anda mengosongkannya, model yang belum difine-tuning akan digunakan untuk bahasa alami ke SQL. Jika Anda menentukan nilai, pastikan itu adalah nama penerapan yang berada dalam status "serving". Model yang belum sepenuhnya diterapkan tidak dapat digunakan di sini. |