Sebelum menerapkan alur aplikasi, penting untuk mengevaluasi kinerjanya dalam skenario bisnis Anda. LangStudio menyediakan fitur evaluasi komprehensif untuk alur aplikasi. Fitur ini menggunakan jenis alur aplikasi baru, yaitu Alur Evaluasi, untuk memberi skor pada alur aplikasi berdasarkan dimensi tertentu menggunakan Templat Evaluasi.
Pendahuluan
LangStudio menyediakan fitur evaluasi komprehensif untuk alur aplikasi. Untuk mengirimkan tugas evaluasi, Anda perlu mengonfigurasi set data evaluasi, memetakan input alur aplikasi, dan memilih Templat Evaluasi yang sesuai. Proses evaluasi bekerja sebagai berikut: Alur aplikasi memproses setiap baris dalam set data evaluasi secara batch untuk menghasilkan output. Kemudian, setiap output dievaluasi menggunakan bidang tambahan dari set data. Terakhir, skor digabungkan untuk menentukan akurasi alur aplikasi pada set data yang ditentukan.

Persiapan
Alur aplikasi telah dibuat dan di-debug. Untuk informasi lebih lanjut, lihat Kembangkan Alur Aplikasi.
Set data evaluasi telah diunggah ke OSS dalam format JSON Lines (JSONL). Kode berikut memberikan contoh:
{"history":[],"query": "Jelaskan kemiringan dan keagungan Gunung Hua", "reference": "Gunung Hua berdiri sendiri, menjulang hingga awan; \nTebing curam membelah langit, dengan puncak-puncak kasar namun tampan. \nPohon pinus hijau dan bambu saling bersaing dalam keindahan di tebing; \nMonyet menangis dan elang terbang, disinari oleh pedang cahaya embun beku. \n\nPuncak-puncak berbahaya seperti gunting, pedang bergerigi menunjuk ke langit; \nJalur sempit di lereng curam, di mana tanaman merambat adalah satu-satunya cara. \nAngin dan kabut saling melilit, saat awan muncul dari gua-gua; \nDunia peri yang dalam, dengan tangga surga yang sulit didaki. \n\nPunggung bergerigi bersilangan, seperti tulang belakang naga yang bergelombang; \nJalur berbahaya terus berlanjut, berkelok menuju surga. \nDari puncak pinus kesepian, elang memukul langit luas; \nDi puncak Gunung Hua, pemandangan megah dan heroik.", "contexts": ["Gunung Hua adalah salah satu dari Lima Gunung Besar", "Gunung Hua terkenal karena kemiringannya"]} {"history":[],"query": "Bisakah Anda mencantumkan 5 logam langka? Harap urutkan berdasarkan permintaan global.", "reference": "Logam langka adalah elemen logam yang jarang ditemukan di kerak bumi, tersebar tidak merata, atau sulit ditambang. Mereka memainkan peran penting dalam bidang teknologi tinggi dan industri baru. Peringkat permintaan global dapat berubah seiring waktu dan kemajuan teknologi, tetapi berikut adalah beberapa logam langka yang biasanya memiliki permintaan tinggi. Daftar ini tidak selalu diurutkan berdasarkan permintaan absolut, karena itu bisa bervariasi di waktu yang berbeda.\n\n1. **Kobalt (Co)** - Kobalt adalah komponen utama baterai lithium-ion, terutama dalam kendaraan listrik dan elektronik portabel. Ini juga digunakan untuk memproduksi paduan tahan panas, paduan keras, dan katalis.\n\n2. **Neodimium (Nd)** - Neodimium adalah logam tanah jarang yang terutama digunakan untuk memproduksi magnet kuat, seperti magnet permanen berperforma tinggi. Magnet ini banyak digunakan dalam hard drive komputer, turbin angin, dan motor penggerak kendaraan listrik.\n\n3. **Litium (Li)** - Litium terutama digunakan untuk memproduksi baterai litium. Seiring meningkatnya permintaan untuk kendaraan listrik dan perangkat elektronik portabel, permintaan litium meningkat dengan cepat.\n\n4. **Perak (Ag)** - Meskipun perak tidak sesedikit logam yang tercantum di atas, permintaan industrinya sangat besar. Ini terutama digunakan dalam elektronik, panel surya, perhiasan, dan pembuatan mata uang.\n\n5. **Rutenium (Ru)** - Rutenium adalah logam mulia langka yang banyak digunakan untuk penyimpanan data di hard disk drive dan server kapasitas besar. Ini juga digunakan dalam katalis dan sel elektrokimia.\n\nPermintaan untuk logam-logam ini dipengaruhi oleh banyak faktor, seperti ekonomi global, perkembangan teknologi, dan dukungan kebijakan. Selain itu, seiring waktu dan pasar berubah, logam langka lainnya seperti tantalum, indium, renium, dan logam tanah jarang lainnya mungkin juga muncul dalam daftar logam langka yang paling diminati.", "contexts": ["Logam langka adalah logam dengan kelimpahan rendah di kerak bumi yang kompleks untuk ditambang dan diekstraksi.", "Litium (Li): Digunakan dalam pembuatan baterai.", "Kobalt (Co): Digunakan dalam paduan berperforma tinggi dan pembuatan baterai."]}File contoh: langstudio_eval_demo.jsonl
Koneksi model bahasa besar (LLM) dan penyematan yang diperlukan untuk evaluasi telah dibuat. Untuk informasi lebih lanjut, lihat Konfigurasikan Koneksi.
Catatan: Beberapa templat evaluasi bergantung pada model juri atau model penyematan. Oleh karena itu, Anda harus mengonfigurasi koneksi LLM dan penyematan terkait.
Penagihan
Fitur evaluasi alur aplikasi menggunakan Object Storage Service (OSS) untuk menyimpan set data evaluasi dan PAI-Deep Learning Containers (PAI-DLC) untuk menjalankan tugas evaluasi offline. Akibatnya, biaya penggunaan sumber daya akan dikenakan. Untuk informasi lebih lanjut, lihat Ikhtisar Penagihan OSS dan Penagihan Deep Learning Containers (DLC).
Buat tugas evaluasi alur aplikasi
Setelah men-debug alur aplikasi di halaman orkestrasi, klik Evaluation di sudut kanan atas untuk membuat tugas evaluasi alur aplikasi.
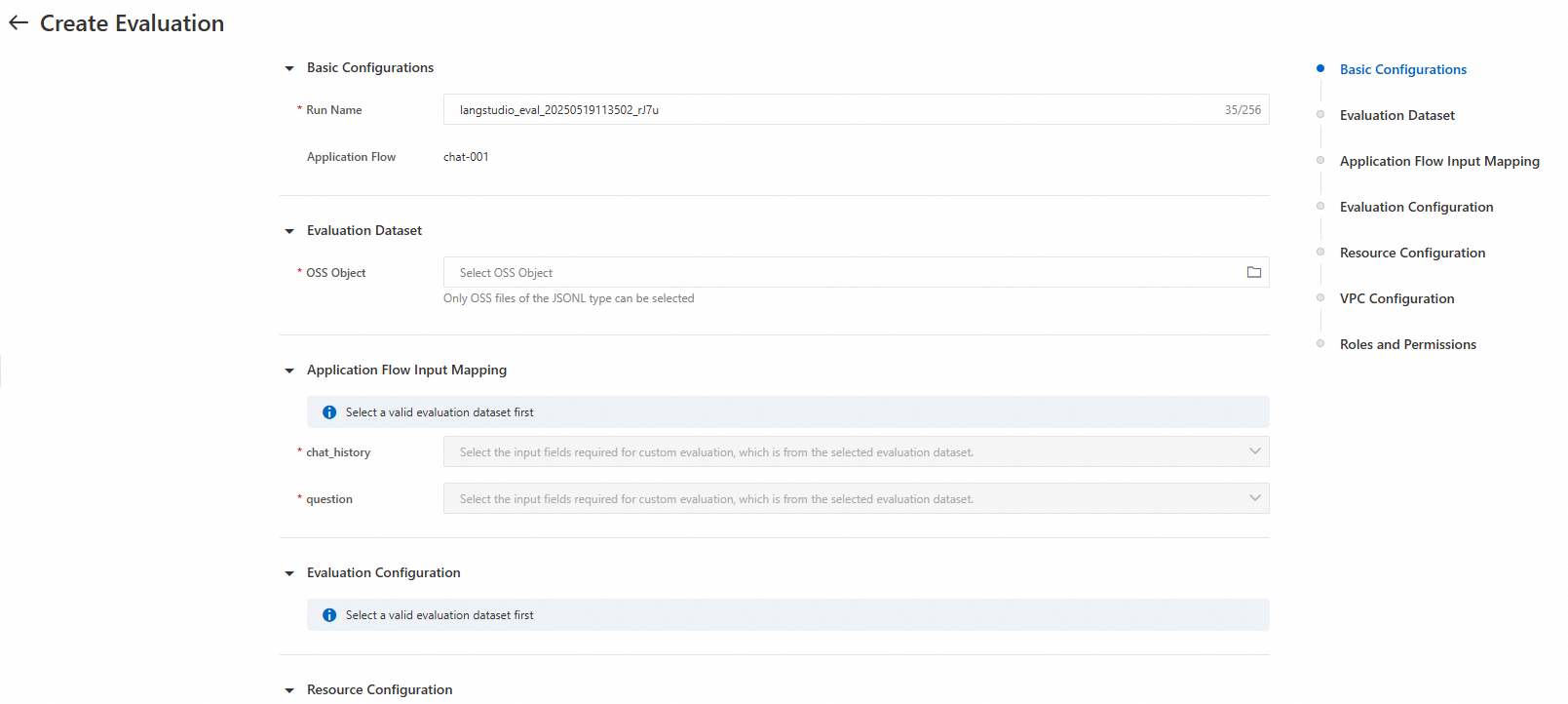
Tabel berikut menjelaskan parameter utama.
Parameter | Deskripsi |
Set data evaluasi | |
File OSS | Pilih file set data evaluasi dalam format JSONL dari OSS. Set data harus berisi bidang 'pertanyaan' dan bidang lain yang diperlukan untuk evaluasi. Bidang 'pertanyaan' digunakan sebagai input untuk alur aplikasi. Bidang lain yang diperlukan digunakan untuk menghitung skor metrik. Untuk informasi lebih lanjut, lihat bagian 'Bidang input' di Lampiran: Templat evaluasi preset. |
Pemetaan input alur aplikasi | |
chat_history/question | Pilih bidang input untuk menjalankan alur aplikasi. Catatan: Sebelum Anda mengevaluasi alur aplikasi, Anda harus terlebih dahulu menjalankannya untuk inferensi. Tugas evaluasi kemudian berjalan berdasarkan hasil inferensi. Oleh karena itu, Anda harus terlebih dahulu memilih bidang input yang diperlukan untuk menjalankan alur aplikasi. |
Konfigurasi evaluasi | |
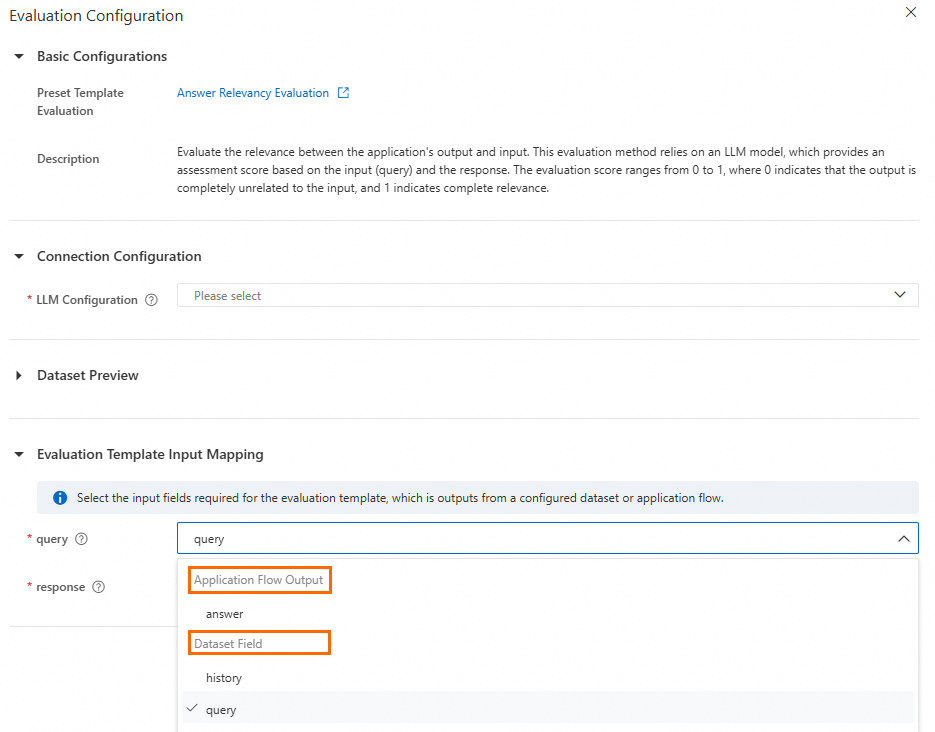
Evaluasi template preset | Sistem menyediakan beberapa templat evaluasi preset. Anda dapat memilih templat sesuai kebutuhan. Jika Anda memilih beberapa templat, hasil evaluasi digabungkan dan ditampilkan di halaman detail tugas. Topik ini menggunakan templat Answer Relevancy sebagai contoh. Saat Anda memilih templat ini, lengkapi konfigurasi berikut:
Parameter utama:
Untuk informasi lebih lanjut tentang templat, lihat Lampiran: Templat evaluasi preset. |
Konfigurasi sumber daya: Sumber daya ini hanya digunakan untuk penjadwalan tugas evaluasi. Kami merekomendasikan Anda memilih sumber daya CPU yang sesuai berdasarkan kompleksitas tugas. | |
Lihat hasil evaluasi
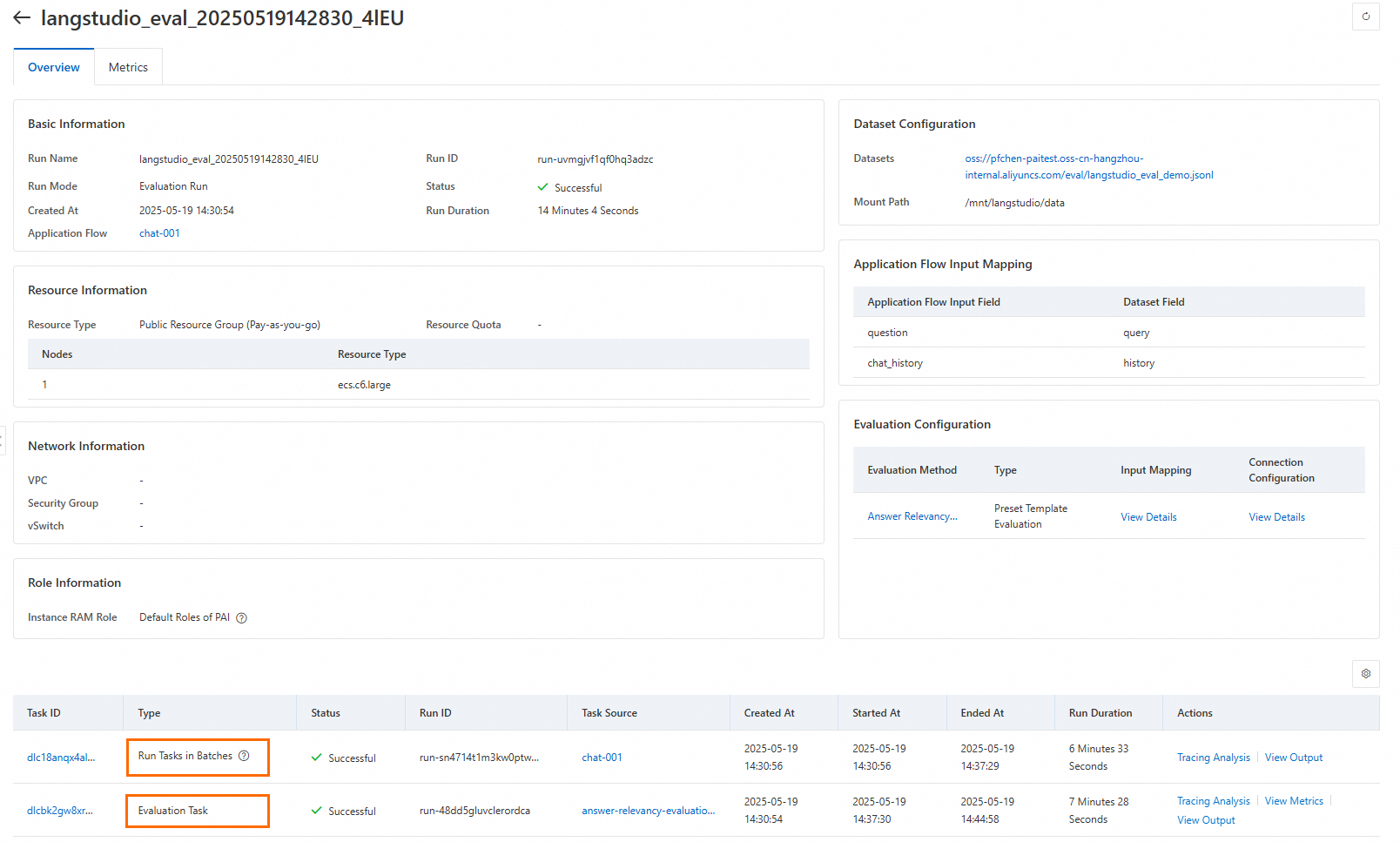
Setelah mengirimkan tugas evaluasi, Anda akan dialihkan ke halaman Overview tugas. Setiap run evaluasi mencakup satu tugas batch run dan N tugas evaluasi metrik, di mana N adalah jumlah templat yang dipilih. Tugas batch run menggunakan alur aplikasi untuk memproses setiap baris dalam set data secara batch dan menghasilkan output. Tugas evaluasi metrik menggunakan bidang tambahan dalam set data evaluasi untuk memberi skor setiap output dari tugas batch run. Di bagian bawah halaman, Anda dapat melihat detail setiap subtugas. Setelah run selesai, Anda dapat melihat jejak, metrik, dan detail output untuk setiap subtugas.
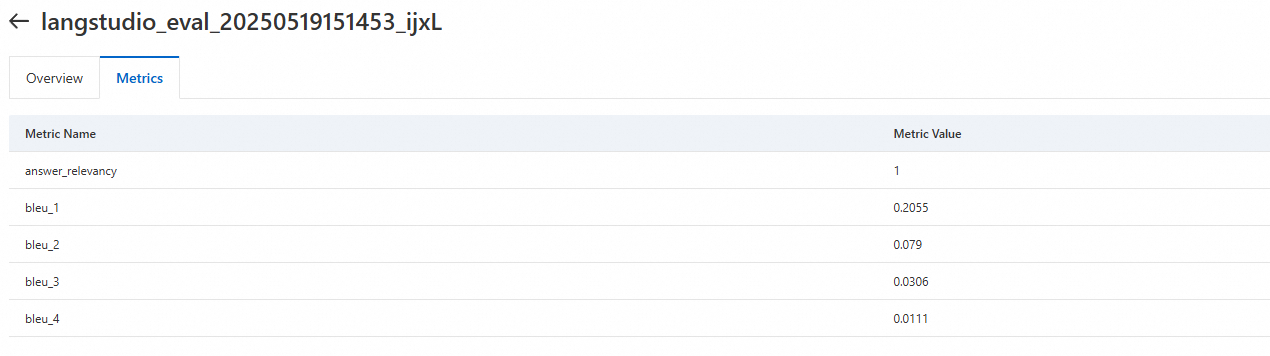
Di halaman Metrics, Anda dapat melihat semua hasil metrik evaluasi. Untuk informasi lebih lanjut tentang nama metrik, lihat Lampiran: Templat Evaluasi Preset.
Lampiran: Template evaluasi preset
LangStudio menyediakan beberapa templat evaluasi bawaan. Anda dapat menggunakan templat ini untuk mengevaluasi kinerja alur aplikasi dari berbagai dimensi berdasarkan nilai metrik:
Nama templat | Deskripsi | Nama metrik | Jenis layanan model yang diperlukan | Bidang input |
Evaluasi Pencocokan Tepat | Mengevaluasi apakah output alur aplikasi (tanggapan) cocok persis dengan jawaban referensi (referensi). Skor antara 0 dan 1. Skor 0 menunjukkan bahwa output tidak cocok dengan referensi. Skor 1 menunjukkan kecocokan persis. | exact_match_score | Tidak diperlukan |
|
Evaluasi Relevansi Jawaban | Mengevaluasi relevansi output alur aplikasi dengan input. Metode ini bergantung pada LLM. LLM memberikan skor berdasarkan input (kueri) dan jawaban alur aplikasi (tanggapan). Skor antara 0 dan 1. Skor 0 menunjukkan bahwa output sepenuhnya tidak relevan dengan input. Skor 1 menunjukkan relevansi sempurna. | answer_relevancy | LLM |
|
Evaluasi Keakuratan Jawaban | Mengevaluasi apakah output alur aplikasi benar. Metode ini bergantung pada LLM. Model memberikan skor berdasarkan pertanyaan (kueri) dan jawaban alur aplikasi (tanggapan). Skor antara 1 dan 5. Skor 1 adalah yang terburuk, dan 5 adalah yang terbaik. | answer_correctness | LLM |
|
Evaluasi Skor BLEU | Mengevaluasi relevansi output alur aplikasi dengan jawaban referensi. Metode ini menggunakan skor BLEU sebagai metrik evaluasi. Ini menghitung skor relevansi antara jawaban referensi (referensi) dan output alur aplikasi (tanggapan). Skor antara 0 dan 1. Skor 0 menunjukkan ketidakrelevanan total. Skor 1 menunjukkan relevansi sempurna. | bleu-1/bleu-2/bleu-3/bleu-4 | Tidak diperlukan |
|
Evaluasi Skor ROUGE | Mengevaluasi relevansi output alur aplikasi (tanggapan) dengan jawaban referensi (referensi). Metode ini menggunakan skor ROUGE sebagai metrik evaluasi. Ini menghitung skor relevansi antara jawaban referensi dan output alur aplikasi. Skor antara 0 dan 1. Skor 0 menunjukkan ketidakrelevanan total. Skor 1 menunjukkan relevansi sempurna. | rouge-1-p/rouge-1-r/rouge-1-f/rouge-l-p/rouge-l-r/rouge-l-f | Tidak diperlukan |
|
Evaluasi Relevansi Konteks | Mengevaluasi relevansi konteks yang diambil oleh alur aplikasi dengan input. Metode ini bergantung pada LLM. LLM memberikan skor berdasarkan input (kueri) dan konteks. Skor antara 0 dan 1. Skor 0 menunjukkan ketidakrelevanan total. Skor 1 menunjukkan relevansi sempurna. | context_relevancy | LLM |
|
Evaluasi Kesetiaan Jawaban | Mengevaluasi apakah jawaban alur aplikasi berasal dari konteks yang diberikan. Metode ini bergantung pada LLM. Model memberikan skor berdasarkan jawaban (tanggapan) dan konteks (konteks). Skor antara 0 dan 1. Skor 0 menunjukkan jawaban yang sepenuhnya direkayasa. Skor 1 menunjukkan bahwa jawaban sepenuhnya sesuai dengan konteks. | answer_faithfulness | LLM |
|
Evaluasi Kemiripan Embedding | Mengevaluasi kesamaan embedding antara output alur aplikasi (tanggapan) dan jawaban referensi (referensi). Metode ini bergantung pada model penyematan. Ini mengonversi jawaban referensi dan output alur aplikasi menjadi vektor embedding dan kemudian menghitung kesamaan kosinus mereka. Skor antara 0 dan 1. Nilai yang lebih tinggi menunjukkan kesamaan yang lebih besar. | embedding_similarity | Embedding |
|