Integrasikan responsible-ai-toolbox ke dalam instans PAI Data Science Workshop (DSW) untuk melakukan analisis keadilan pada model AI. Contoh ini mengevaluasi bias prediksi pendapatan berdasarkan gender dan ras menggunakan FairnessDashboard.
Cara kerja
Analisis keadilan mengidentifikasi dan mengurangi bias dalam sistem AI guna memastikan hasil yang adil bagi semua pengguna. Prinsip utamanya meliputi:
-
Hindari bias: Kurangi bias dalam data dan algoritma agar sistem AI tidak membuat keputusan tidak adil berdasarkan gender, ras, atau usia.
-
Data representatif: Latih model menggunakan set data yang representatif sehingga model melayani semua kelompok pengguna, termasuk minoritas.
-
Transparansi dan interpretabilitas: Terapkan teknik explainable AI (XAI) agar pengguna dan pengambil keputusan memahami bagaimana model menghasilkan output-nya.
-
Pemantauan dan evaluasi berkelanjutan: Pantau sistem AI secara berkala untuk mendeteksi dan memperbaiki bias yang muncul seiring waktu.
-
Keragaman dan inklusi: Bangun tim yang beragam dan pertimbangkan berbagai perspektif selama proses desain dan pengembangan sistem AI.
-
Kepatuhan dan prinsip etika: Ikuti hukum, regulasi, dan standar etika yang berlaku untuk mencegah kerugian atau ketidakadilan.
Contoh berikut menggunakan responsible-ai-toolbox di PAI DSW untuk mengevaluasi apakah model prediksi pendapatan memperlakukan kelompok gender dan ras secara adil.
Prasyarat
-
Instans DSW dengan konfigurasi berikut. Untuk membuatnya, lihat Buat instans DSW.
-
Jenis instans: ecs.gn6v-c8g1.2xlarge (disarankan)
-
Runtime image: Python 3.9 atau versi lebih baru. Contoh ini menggunakan tensorflow-pytorch-develop:2.14-pytorch2.1-gpu-py311-cu118-ubuntu22.04.
-
Model: responsible-ai-toolbox mendukung model regresi dan klasifikasi biner Sklearn, PyTorch, dan TensorFlow.
-
-
Set data pelatihan. Untuk menggunakan set data sampel, lihat Langkah 3: Siapkan set data.
-
Model algoritma. Untuk menggunakan model sampel, lihat Langkah 5: Latih model.
Langkah 1: Buka DSW Gallery
-
Masuk ke Konsol PAI.
-
Di pojok kiri atas, pilih Wilayah Anda.
-
Di panel navigasi sebelah kiri, pilih QuickStart > Notebook Gallery. Cari Responsible AI-Fairness Analysis lalu klik Open in DSW pada kartu tersebut.
-
Pilih instans DSW dan klik Open Notebook. Sistem akan membuka Notebook Responsible AI-Fairness Analysis.
Langkah 2: Impor dependensi
Instal paket raiwidgets yang diperlukan oleh responsible-ai-toolbox.
!pip install raiwidgets==0.34.1Langkah 3: Siapkan set data
Muat set data OpenML 1590 untuk contoh ini.
from raiutils.common.retries import retry_function
from sklearn.datasets import fetch_openml
class FetchOpenml:
def __init__(self):
pass
# Dapatkan set data OpenML dengan data_id = 1590.
def fetch(self):
return fetch_openml(data_id=1590, as_frame=True)
fetcher = FetchOpenml()
action_name = "Dataset download"
err_msg = "Failed to download openml dataset"
max_retries = 5
retry_delay = 60
data = retry_function(fetcher.fetch, action_name, err_msg,
max_retries=max_retries,
retry_delay=retry_delay)Untuk memuat set data CSV Anda sendiri:
import pandas as pd
# Muat set data Anda sendiri dalam format CSV.
# Gunakan pandas untuk membaca file CSV.
data = pd.read_csv(filename)Langkah 4: Pra-pemrosesan data
Dapatkan variabel fitur dan target
Variabel target adalah hasil yang diprediksi oleh model. Variabel fitur mencakup semua variabel lain per instans. Pada contoh ini, target adalah "class", sedangkan fitur relevan meliputi "sex", "race", dan "age":
-
class: Apakah pendapatan tahunan lebih dari 50K.
-
sex: Gender.
-
race: Ras.
-
age: Usia.
Baca data ke dalam X_raw dan tampilkan pratinjaunya:
# Dapatkan variabel fitur, tidak termasuk variabel target.
X_raw = data.data
# Tampilkan 5 baris pertama variabel fitur, tidak termasuk variabel target.
X_raw.head(5)Tetapkan variabel target. "1" menunjukkan pendapatan >50K, dan "0" menunjukkan pendapatan ≤50K.
from sklearn.preprocessing import LabelEncoder
# Konversi variabel target menjadi target klasifikasi biner.
# data.target adalah variabel target "class".
y_true = (data.target == '>50K') * 1
y_true = LabelEncoder().fit_transform(y_true)
import matplotlib.pyplot as plt
import numpy as np
# Lihat distribusi variabel target.
counts = np.bincount(y_true)
classes = ['<=50K', '>50K']
plt.bar(classes, counts)Dapatkan fitur sensitif
Tetapkan gender (sex) dan ras sebagai fitur sensitif. responsible-ai-toolbox mengevaluasi apakah model menunjukkan bias berdasarkan fitur-fitur ini. Tetapkan fitur sensitif Anda sendiri sesuai kebutuhan.
# Definisikan "sex" dan "race" sebagai informasi sensitif.
# Pertama, pilih kolom yang terkait dengan informasi sensitif dari set data untuk membentuk DataFrame `sensitive_features` baru.
sensitive_features = X_raw[['sex','race']]
sensitive_features.head(5)Hapus fitur sensitif dari X_raw.
# Hapus fitur sensitif dari variabel fitur.
X = X_raw.drop(labels=['sex', 'race'],axis = 1)
X.head(5)Encoding dan standarisasi fitur
Standarisasi data untuk responsible-ai-toolbox.
import pandas as pd
from sklearn.preprocessing import StandardScaler
# Lakukan one-hot encoding.
X = pd.get_dummies(X)
# Standarisasi (skala) fitur untuk set data X.
sc = StandardScaler()
X_scaled = sc.fit_transform(X)
X_scaled = pd.DataFrame(X_scaled, columns=X.columns)
X_scaled.head(5)Pemisahan data pelatihan dan pengujian
Pisahkan 20% data menjadi set data uji. Sisanya digunakan untuk pelatihan.
from sklearn.model_selection import train_test_split
# Pisahkan variabel fitur X dan variabel target y menjadi set pelatihan dan pengujian sesuai rasio `test_size`.
X_train, X_test, y_train, y_test = \
train_test_split(X_scaled, y_true, test_size=0.2, random_state=0, stratify=y_true)
# Gunakan seed acak yang sama untuk memisahkan fitur sensitif menjadi set pelatihan dan pengujian guna memastikan konsistensi dengan pemisahan di atas.
sensitive_features_train, sensitive_features_test = \
train_test_split(sensitive_features, test_size=0.2, random_state=0, stratify=y_true)Lihat ukuran set pelatihan dan pengujian.
print("Volume set data pelatihan:", len(X_train))
print("Volume set data uji:", len(X_test))Atur ulang indeks untuk kedua set.
# Atur ulang indeks DataFrame untuk mencegah error indeks.
X_train = X_train.reset_index(drop=True)
sensitive_features_train = sensitive_features_train.reset_index(drop=True)
X_test = X_test.reset_index(drop=True)
sensitive_features_test = sensitive_features_test.reset_index(drop=True)Langkah 5: Latih model
Latih model regresi logistik menggunakan data pelatihan. Tab berikut menampilkan implementasi Sklearn, PyTorch, dan TensorFlow.
Sklearn
from sklearn.linear_model import LogisticRegression
# Buat model regresi logistik.
sk_model = LogisticRegression(solver='liblinear', fit_intercept=True)
# Latih model.
sk_model.fit(X_train, y_train)PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
# Definisikan model regresi logistik.
class LogisticRegression(nn.Module):
def __init__(self, input_size):
super(LogisticRegression, self).__init__()
self.linear = nn.Linear(input_size, 1)
def forward(self, x):
outputs = torch.sigmoid(self.linear(x))
return outputs
# Buat instans model.
input_size = X_train.shape[1]
pt_model = LogisticRegression(input_size)
# Fungsi loss dan pengoptimal.
criterion = nn.BCELoss()
optimizer = optim.SGD(pt_model.parameters(), lr=5e-5)
# Latih model.
num_epochs = 1
X_train_pt = X_train
y_train_pt = y_train
for epoch in range(num_epochs):
# Propagasi maju.
# Konversi DataFrame ke Tensor.
if isinstance(X_train_pt, pd.DataFrame):
X_train_pt = torch.tensor(X_train_pt.values)
X_train_pt = X_train_pt.float()
outputs = pt_model(X_train_pt)
outputs = outputs.squeeze()
# Konversi ndarray ke Tensor.
if isinstance(y_train_pt, np.ndarray):
y_train_pt = torch.from_numpy(y_train_pt)
y_train_pt = y_train_pt.float()
loss = criterion(outputs, y_train_pt)
# Propagasi mundur dan optimasi.
optimizer.zero_grad()
loss.backward()
optimizer.step()TensorFlow
import tensorflow as tf
from tensorflow.keras import layers
# Definisikan model regresi logistik.
tf_model = tf.keras.Sequential([
layers.Dense(units=1, input_shape=(X_train.shape[-1],), activation='sigmoid')
])
# Kompilasi model. Gunakan loss entropi silang biner dan pengoptimal penurunan gradien stokastik.
tf_model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])
# Latih model.
tf_model.fit(X_train, y_train, epochs=1, batch_size=32, verbose=0)Langkah 6: Evaluasi model
Impor FairnessDashboard untuk menghasilkan laporan evaluasi keadilan dari set data uji.
FairnessDashboard mengelompokkan hasil prediksi dan hasil sebenarnya berdasarkan variabel sensitif, lalu membandingkan kinerja prediksi antar kelompok.
Untuk fitur "sex", dashboard menghitung dan membandingkan metrik seperti laju seleksi dan presisi untuk "Male" dan "Female".
Evaluasi model menggunakan salah satu framework berikut:
Sklearn
from raiwidgets import FairnessDashboard
import os
from urllib.parse import urlparse
# Hasilkan prediksi pada set data uji
y_pred_sk = sk_model.predict(X_test)
# Gunakan responsible-ai-toolbox untuk menghitung metrik keadilan untuk setiap kelompok sensitif
metric_frame_sk = FairnessDashboard(sensitive_features=sensitive_features_test,
y_true=y_test,
y_pred=y_pred_sk, locale = 'en')
# Tetapkan URL untuk Pengalihan
metric_frame_sk.config['baseUrl'] = 'https://{}-proxy-{}.dsw-gateway-{}.data.aliyun.com'.format(
os.environ.get('JUPYTER_NAME').replace("dsw-",""),
urlparse(metric_frame_sk.config['baseUrl']).port,
os.environ.get('dsw_region') )
print(metric_frame_sk.config['baseUrl'])PyTorch
from raiwidgets import FairnessDashboard
import torch
import os
from urllib.parse import urlparse
# Uji model dan evaluasi keadilan
pt_model.eval() # Atur model ke mode evaluasi
X_test_pt = X_test
with torch.no_grad():
X_test_pt = torch.tensor(X_test_pt.values)
X_test_pt = X_test_pt.float()
y_pred_pt = pt_model(X_test_pt).numpy()
# Gunakan responsible-ai-toolbox untuk menghitung metrik untuk setiap kelompok sensitif
metric_frame_pt = FairnessDashboard(sensitive_features=sensitive_features_test,
y_true=y_test,
y_pred=y_pred_pt.flatten().round(),locale='en')
# Tetapkan tautan pengalihan URL
metric_frame_pt.config['baseUrl'] = 'https://{}-proxy-{}.dsw-gateway-{}.data.aliyun.com'.format(
os.environ.get('JUPYTER_NAME').replace("dsw-",""),
urlparse(metric_frame_pt.config['baseUrl']).port,
os.environ.get('dsw_region') )
print(metric_frame_pt.config['baseUrl'])TensorFlow
from raiwidgets import FairnessDashboard
import os
from urllib.parse import urlparse
# Uji model dan evaluasi keadilan.
y_pred_tf = tf_model.predict(X_test).flatten()
# Gunakan responsible-ai-toolbox untuk menghitung informasi data untuk setiap kelompok sensitif.
metric_frame_tf = FairnessDashboard(
sensitive_features=sensitive_features_test,
y_true=y_test,
y_pred=y_pred_tf.round(),locale='en')
# Tetapkan tautan pengalihan URL.
metric_frame_tf.config['baseUrl'] = 'https://{}-proxy-{}.dsw-gateway-{}.data.aliyun.com'.format(
os.environ.get('JUPYTER_NAME').replace("dsw-",""),
urlparse(metric_frame_tf.config['baseUrl']).port,
os.environ.get('dsw_region') )
print(metric_frame_tf.config['baseUrl'])Parameter utama:
-
sensitive_features: Fitur sensitif.
-
y_true: Label ground truth.
-
y_pred: Hasil prediksi model.
-
locale (opsional): Bahasa tampilan panel. Mendukung Bahasa Tionghoa Sederhana ("zh-Hans") dan Bahasa Tionghoa Tradisional ("zh-Hant"). Default: Bahasa Inggris ("en").
Langkah 7: Lihat laporan evaluasi
Setelah evaluasi selesai, klik URL untuk melihat laporan.

Pada halaman Fairness dashboard, klik Get started. Pilih fitur sensitif, metrik kinerja, dan metrik keadilan untuk membandingkan hasil antar kelompok.
Saat fitur sensitif adalah "sex"
-
Fitur sensitif: sex
-
Metrik kinerja: Akurasi
-
Metrik keadilan: Perbedaan paritas demografis
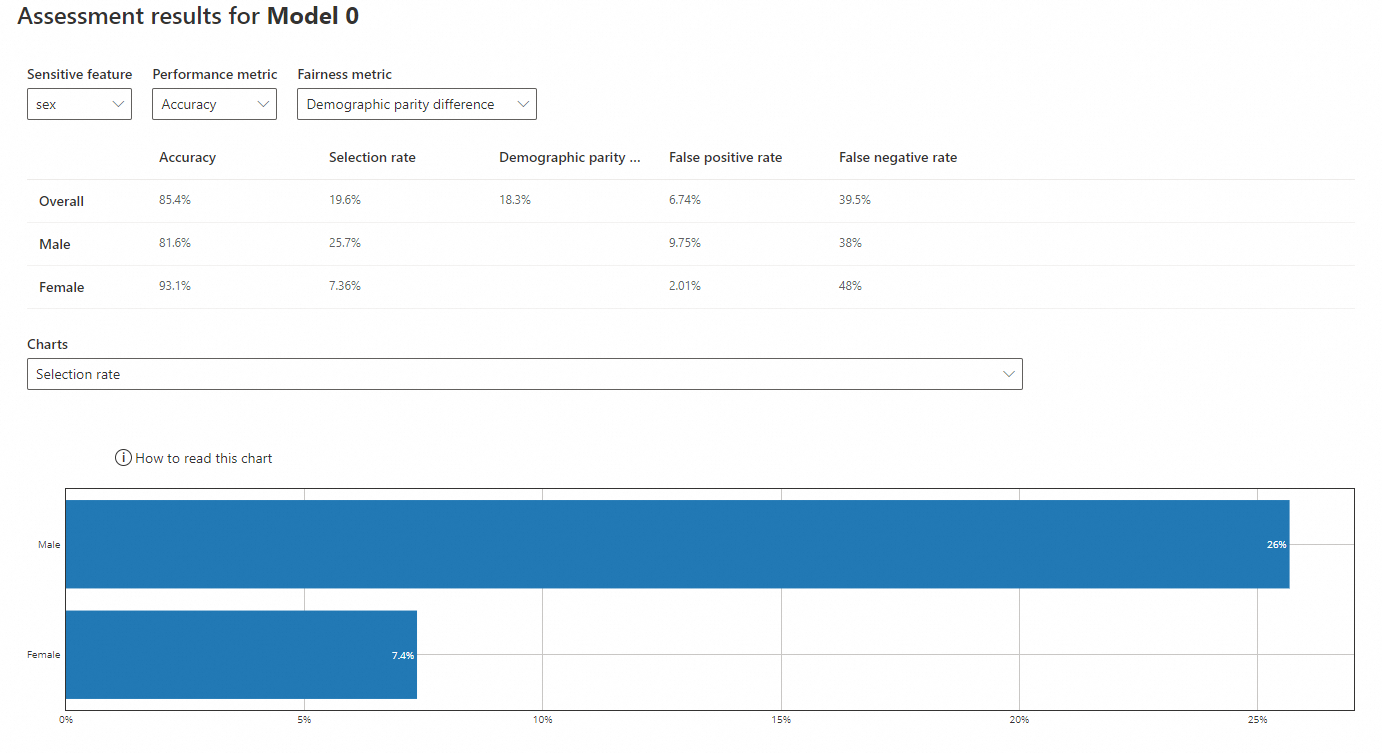
-
Akurasi: Rasio prediksi benar terhadap total sampel. Akurasi model untuk laki-laki (81,6%) lebih rendah daripada perempuan (93,1%), meskipun keduanya mendekati akurasi keseluruhan (85,4%).
-
Laju seleksi: Probabilitas bahwa model memprediksi pendapatan >50K. Laki-laki memiliki laju seleksi lebih tinggi (25,7%) dibanding perempuan (7,36%), yang jauh di bawah laju keseluruhan (19,6%).
-
Perbedaan paritas demografis: Perbedaan probabilitas prediksi positif antar kelompok terlindungi. Nilai yang lebih mendekati 0 menunjukkan bias lebih rendah. Perbedaan keseluruhan adalah 18,3%.
Saat fitur sensitif adalah "race"
-
Fitur sensitif: race
-
Metrik kinerja: Akurasi
-
Metrik keadilan: Perbedaan paritas demografis
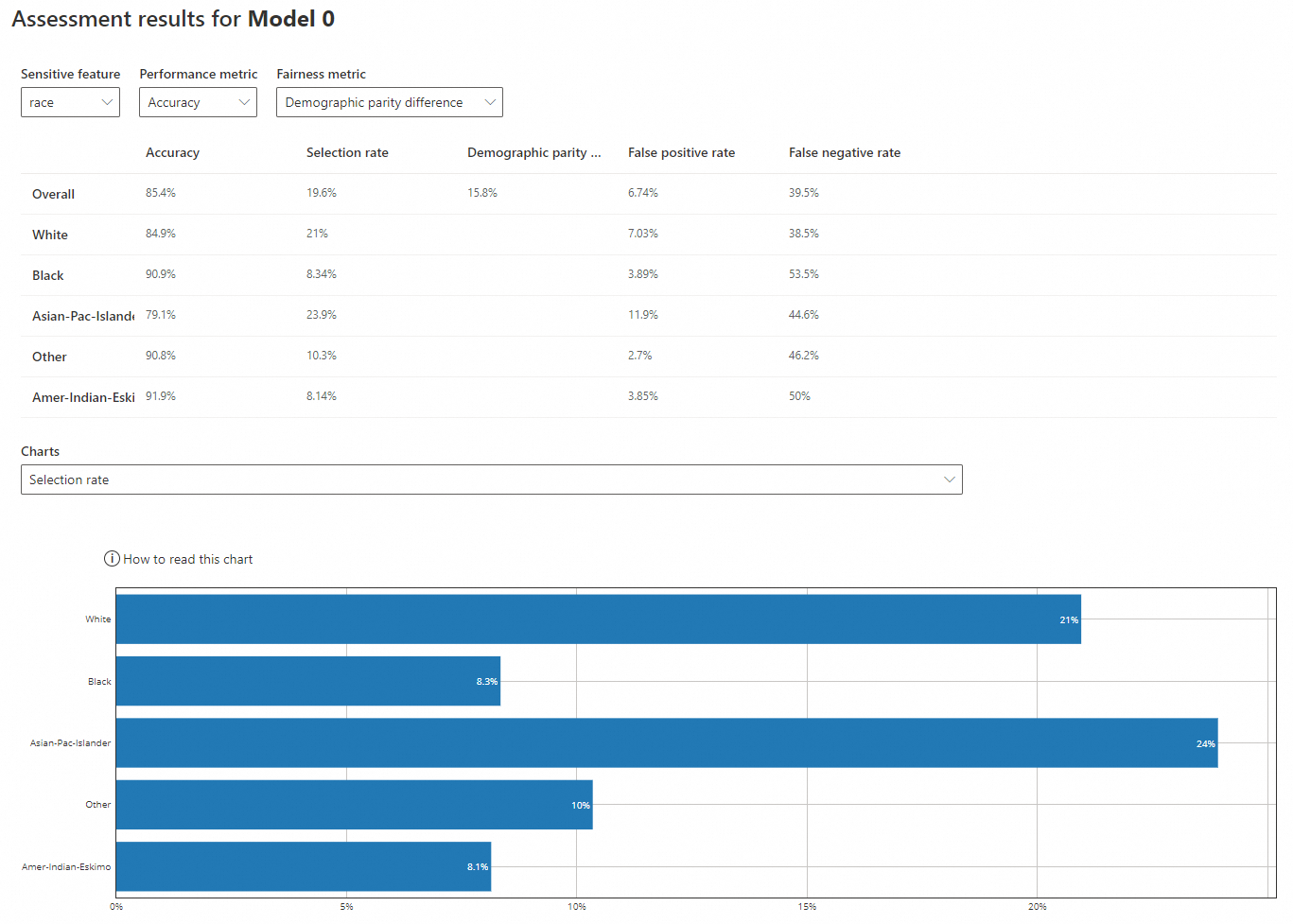
-
Akurasi: Rasio prediksi benar terhadap total sampel. Akurasi "White" (84,9%) dan "Asian-Pac-Islander" (79,1%) lebih rendah daripada "Black" (90,9%), "Other" (90,8%), dan "Amer-Indian-Eskimo" (91,9%), tetapi semua kelompok mendekati akurasi keseluruhan (85,4%).
-
Laju seleksi: Probabilitas bahwa model memprediksi pendapatan >50K. "White" (21%) dan "Asian-Pac-Islander" (23,9%) memiliki laju lebih tinggi daripada "Black" (8,34%), "Other" (10,3%), dan "Amer-Indian-Eskimo" (8,14%), semuanya jauh di bawah laju keseluruhan (19,6%).
-
Perbedaan paritas demografis: Perbedaan probabilitas prediksi positif antar kelompok terlindungi. Nilai yang lebih mendekati 0 menunjukkan bias lebih rendah. Perbedaan keseluruhan adalah 15,8%.