Responsible AI merupakan praktik kritis bagi pengembang dan organisasi yang membangun atau menggunakan model AI. Praktik ini mencakup seluruh siklus hidup model AI, termasuk pengembangan, pelatihan, fine-tuning, evaluasi, dan penerapan, untuk membantu memastikan bahwa sistem AI aman, andal, adil, dan etis. PAI memungkinkan Anda mengintegrasikan alat Responsible AI ke dalam DSW guna melakukan analisis keadilan, analisis kesalahan, dan analisis interpretabilitas pada model AI Anda.
Cara kerja
Sebagai bagian dari praktik Responsible AI, analisis kesalahan merupakan langkah kunci untuk memahami dan meningkatkan performa model. Prinsip utamanya adalah mengidentifikasi, menganalisis, dan menyelesaikan kesalahan dalam prediksi model AI secara sistematis guna meningkatkan akurasi dan keadilan. Prinsip-prinsip inti analisis kesalahan adalah:
Identifikasi kesalahan: Temukan kesalahan prediksi model. Hal ini melibatkan perbandingan antara prediksi model dengan ground truth untuk menemukan ketidaksesuaian. Kesalahan dapat diklasifikasikan ke dalam berbagai jenis, seperti false positives dan false negatives.
Kategorikan kesalahan: Klasifikasikan kesalahan berdasarkan karakteristiknya. Hal ini membantu Anda memahami akar penyebabnya lebih baik, seperti ketidakseimbangan data, fitur yang tidak memadai, atau bias model. Proses ini mungkin memerlukan keahlian domain dan penilaian manusia.
Analisis akar penyebab: Analisis penyebab setiap kategori kesalahan. Langkah ini sangat penting karena secara langsung mengarahkan optimalisasi model. Ini mungkin melibatkan analisis kualitas data, masalah desain model, rekayasa fitur, atau masalah representasi data.
Ambil tindakan korektif: Berdasarkan analisis tersebut, tim pengembang dapat mengambil langkah-langkah spesifik untuk mengatasi masalah model. Langkah-langkah tersebut dapat mencakup pembersihan data, penyeimbangan ulang set data, modifikasi arsitektur model, penambahan fitur baru, atau penggunaan algoritma yang berbeda.
Iterasi dan evaluasi: Analisis kesalahan bukanlah tugas satu kali jalan, melainkan proses iteratif. Setelah setiap modifikasi model, Anda harus melakukan analisis kesalahan lagi untuk menilai apakah perubahan tersebut efektif, meningkatkan performa, atau justru menimbulkan masalah baru.
Dokumentasikan dan laporkan: Untuk memastikan transparansi dan interpretabilitas, dokumentasikan secara menyeluruh proses analisis kesalahan, temuan, dan tindakan korektif. Hal ini juga membantu anggota tim memahami keterbatasan model dan memberikan umpan balik berharga untuk fase proyek lainnya.
Tutorial ini menunjukkan cara melakukan analisis kesalahan pada model AI menggunakan responsible-ai-toolbox di PAI DSW. Tugas contoh adalah memprediksi apakah pendapatan tahunan seseorang lebih dari 50K berdasarkan set data sensus.
Persiapan awal
Sebuah instans DSW. Jika Anda belum memilikinya, lihat Buat instans DSW. Konfigurasi yang direkomendasikan adalah sebagai berikut:
Tipe instans yang direkomendasikan: ecs.gn6v-c8g1.2xlarge
Image: Disarankan Python 3.9 atau versi lebih baru. Dalam tutorial ini, image resmi yang digunakan adalah tensorflow-pytorch-develop:2.14-pytorch2.1-gpu-py311-cu118-ubuntu22.04.
Model: responsible-ai-toolbox mendukung model regresi dan model klasifikasi biner dari framework Scikit-learn.
Set data pelatihan: Gunakan set data pelatihan Anda sendiri. Untuk menggunakan set data contoh dalam tutorial ini, lihat Langkah 3: Siapkan set data.
Model algoritma: Gunakan model algoritma Anda sendiri. Untuk menggunakan model contoh dalam tutorial ini, lihat Langkah 5: Latih model.
Langkah 1: Buka galeri DSW
Masuk ke Konsol PAI.
Di pojok kiri atas, pilih Wilayah sesuai kebutuhan Anda.
Di panel navigasi sebelah kiri, pilih QuickStart > Notebook gallery. Cari "Responsible AI-Error Analysis" dan klik Open in DSW pada kartu tersebut.
Pilih instans DSW dan klik Open Notebook. Notebook "Responsible AI-Error Analysis" akan terbuka.
Langkah 2: Impor dependensi
Instal dependensi raiwidgets untuk responsible-ai-toolbox, yang digunakan untuk evaluasi.
!pip install raiwidgets==0.34.1Impor dependensi Responsible AI dan Scikit-learn untuk pelatihan model.
# Impor dependensi untuk Responsible AI
import zipfile
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
import pandas as pd
from lightgbm import LGBMClassifier
from raiutils.dataset import fetch_dataset
import sklearn
from packaging import version
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformerLangkah 3: Siapkan set data
Unduh dan ekstrak set data sensus. Folder hasil ekstraksi berisi data pelatihan adult-train.csv dan data uji adult-test.csv.
# Tentukan nama file set data.
outdirname = 'responsibleai.12.28.21'
zipfilename = outdirname + '.zip'
# Unduh dan ekstrak set data.
fetch_dataset('https://publictestdatasets.blob.core.windows.net/data/' + zipfilename, zipfilename)
with zipfile.ZipFile(zipfilename, 'r') as unzip:
unzip.extractall('.')Langkah 4: Pra-pemrosesan data
Muat data pelatihan
adult-train.csvdan data ujiadult-test.csv.Pisahkan data pelatihan dan pengujian menjadi variabel fitur dan variabel target. Variabel target adalah hasil aktual yang diprediksi oleh model. Variabel fitur adalah variabel dalam setiap instans data selain variabel target. Dalam contoh ini, variabel target adalah
income, dan variabel fitur mencakupworkclass,education, danmarital-status.Konversi data pelatihan ke format NumPy untuk pelatihan.
# Muat data pelatihan dan data uji.
train_data = pd.read_csv('adult-train.csv', skipinitialspace=True)
test_data = pd.read_csv('adult-test.csv', skipinitialspace=True)
# Definisikan kolom untuk fitur dan variabel target.
target_feature = 'income'
categorical_features = ['workclass', 'education', 'marital-status',
'occupation', 'relationship', 'race', 'gender', 'native-country']
# Definisikan fungsi untuk memisahkan fitur dan variabel target.
def split_label(dataset, target_feature):
X = dataset.drop([target_feature], axis=1)
y = dataset[[target_feature]]
return X, y
# Pisahkan fitur dan variabel target.
X_train_original, y_train = split_label(train_data, target_feature)
X_test_original, y_test = split_label(test_data, target_feature)
# Konversi ke format NumPy.
y_train = y_train[target_feature].to_numpy()
y_test = y_test[target_feature].to_numpy()
# Definisikan sampel uji.
test_data_sample = test_data.sample(n=500, random_state=5)Anda juga dapat memuat set data Anda sendiri. Perintah berikut menunjukkan cara memuat set data dalam format CSV:
import pandas as pd
# Muat set data Anda sendiri dalam format CSV.
# Gunakan pandas untuk membaca file CSV.
try:
data = pd.read_csv(filename)
except:
passLangkah 5: Latih model
Dalam contoh ini, pipeline pelatihan data dibangun menggunakan Scikit-learn untuk melatih model klasifikasi biner.
# Definisikan parameter ohe_params berdasarkan versi scikit-learn.
if version.parse(sklearn.__version__) < version.parse('1.2'):
ohe_params = {"sparse": False}
else:
ohe_params = {"sparse_output": False}
# Definisikan pipeline klasifikasi untuk transformasi fitur. Parameter input X merepresentasikan data pelatihan.
def create_classification_pipeline(X):
pipe_cfg = {
'num_cols': X.dtypes[X.dtypes == 'int64'].index.values.tolist(),
'cat_cols': X.dtypes[X.dtypes == 'object'].index.values.tolist(),
}
num_pipe = Pipeline([
('num_imputer', SimpleImputer(strategy='median')),
('num_scaler', StandardScaler())
])
cat_pipe = Pipeline([
('cat_imputer', SimpleImputer(strategy='constant', fill_value='?')),
('cat_encoder', OneHotEncoder(handle_unknown='ignore', **ohe_params))
])
feat_pipe = ColumnTransformer([
('num_pipe', num_pipe, pipe_cfg['num_cols']),
('cat_pipe', cat_pipe, pipe_cfg['cat_cols'])
])
pipeline = Pipeline(steps=[('preprocessor', feat_pipe),
('model', LGBMClassifier(random_state=0))])
return pipeline
# Buat pipeline pelatihan model klasifikasi.
pipeline = create_classification_pipeline(X_train_original)
# Latih model.
model = pipeline.fit(X_train_original, y_train)Langkah 6: Tambahkan komponen Responsible AI
Jalankan skrip berikut untuk menambahkan komponen analisis kesalahan ke Responsible AI dan gunakan rai_insights untuk melakukan perhitungan.
# Impor komponen dasbor RAI.
from raiwidgets import ResponsibleAIDashboard
from responsibleai import RAIInsights
# Definisikan objek RAIInsights.
from responsibleai.feature_metadata import FeatureMetadata
feature_metadata = FeatureMetadata(categorical_features=categorical_features, dropped_features=[])
rai_insights = RAIInsights(model, train_data, test_data_sample, target_feature, 'classification',
feature_metadata=feature_metadata)
# Tambahkan komponen analisis kesalahan.
rai_insights.error_analysis.add()
# Lakukan komputasi RAI.
rai_insights.compute()Langkah 7: Buat dasbor Responsible AI
Buat kohort berbeda dengan menerapkan filter untuk menganalisis segmen data tertentu. Contohnya meliputi:
Usia kurang dari 65 dan jam-per-minggu lebih dari 40.
Status perkawinan adalah "Never-married" atau "Divorced".
Indeks kurang dari 20.
Prediksi Y adalah >50K.
Y sebenarnya adalah >50K.
Impor
ResponsibleAIDashboarddan gunakan responsible-ai-toolbox untuk menganalisis model.
from raiutils.cohort import Cohort, CohortFilter, CohortFilterMethods
import os
from urllib.parse import urlparse
# Usia kurang dari 65 dan jam-per-minggu lebih dari 40.
cohort_filter_age = CohortFilter(
method=CohortFilterMethods.METHOD_LESS,
arg=[65],
column='age')
cohort_filter_hours_per_week = CohortFilter(
method=CohortFilterMethods.METHOD_GREATER,
arg=[40],
column='hours-per-week')
user_cohort_age_and_hours_per_week = Cohort(name='Cohort Age and Hours-Per-Week')
user_cohort_age_and_hours_per_week.add_cohort_filter(cohort_filter_age)
user_cohort_age_and_hours_per_week.add_cohort_filter(cohort_filter_hours_per_week)
# Status perkawinan adalah "Never-married" atau "Divorced".
cohort_filter_marital_status = CohortFilter(
method=CohortFilterMethods.METHOD_INCLUDES,
arg=["Never-married", "Divorced"],
column='marital-status')
user_cohort_marital_status = Cohort(name='Cohort Marital-Status')
user_cohort_marital_status.add_cohort_filter(cohort_filter_marital_status)
# Indeks kurang dari 20.
cohort_filter_index = CohortFilter(
method=CohortFilterMethods.METHOD_LESS,
arg=[20],
column='Index')
user_cohort_index = Cohort(name='Cohort Index')
user_cohort_index.add_cohort_filter(cohort_filter_index)
# Prediksi Y adalah >50K.
cohort_filter_predicted_y = CohortFilter(
method=CohortFilterMethods.METHOD_INCLUDES,
arg=['>50K'],
column='Predicted Y')
user_cohort_predicted_y = Cohort(name='Cohort Predicted Y')
user_cohort_predicted_y.add_cohort_filter(cohort_filter_predicted_y)
# Y sebenarnya adalah >50K.
cohort_filter_true_y = CohortFilter(
method=CohortFilterMethods.METHOD_INCLUDES,
arg=['>50K'],
column='True Y')
user_cohort_true_y = Cohort(name='Cohort True Y')
user_cohort_true_y.add_cohort_filter(cohort_filter_true_y)
cohort_list = [user_cohort_age_and_hours_per_week,
user_cohort_marital_status,
user_cohort_index,
user_cohort_predicted_y,
user_cohort_true_y]
# Buat dasbor Responsible AI.
metric_frame_tf = ResponsibleAIDashboard(rai_insights, cohort_list=cohort_list, feature_flights="dataBalanceExperience")
# Atur URL untuk pengalihan.
metric_frame_tf.config['baseUrl'] = 'https://{}-proxy-{}.dsw-gateway-{}.data.aliyun.com'.format(
os.environ.get('JUPYTER_NAME').replace("dsw-",""),
urlparse(metric_frame_tf.config['baseUrl']).port,
os.environ.get('dsw_region') )Langkah 8: Lihat analisis kesalahan
Klik URL untuk membuka dasbor Responsible AI.

Lihat analisis kesalahan:
Tree map
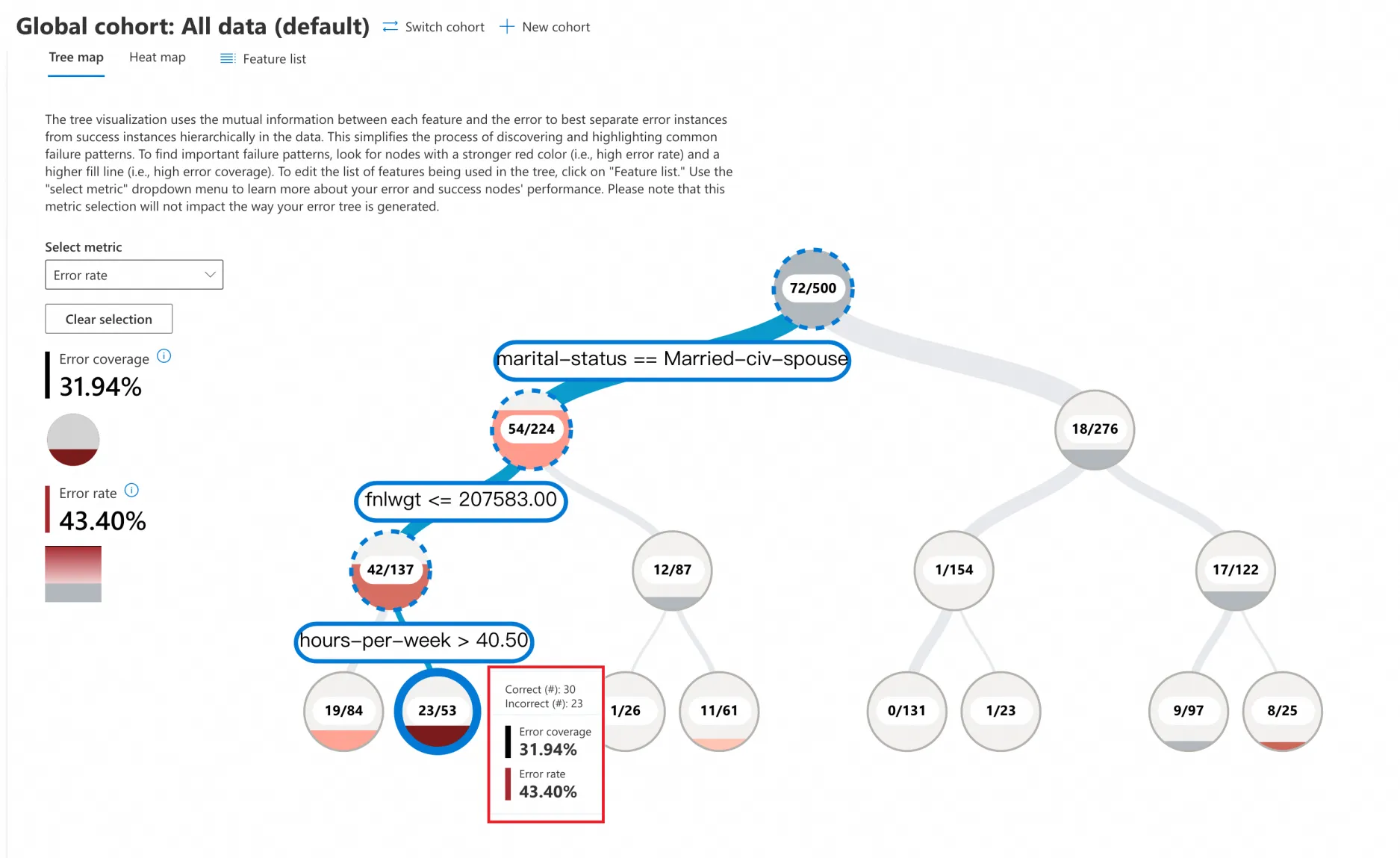
Klik Tree Map. Dari daftar drop-down Select metric, pilih Error rate untuk melakukan analisis kesalahan. Tampilan pohon membagi data menjadi pohon biner berdasarkan nilai fitur model. Sebagai contoh, dua cabang di bawah node akar pohon ini merepresentasikan:
marital-status == Married-civ-spouse(54/224)
marital-status != Married-civ-spouse(18/276)
Contoh ini berisi 500 sampel dengan 72 kesalahan prediksi, menghasilkan laju kesalahan sebesar 14,4% (72/500). Setiap node dalam pohon biner menunjukkan jumlah total titik data yang memenuhi kondisi cabang tersebut, beserta jumlah kesalahan prediksi dan laju kesalahannya.
Fokus pada node berwarna merah. Warna merah yang lebih pekat menunjukkan laju kesalahan yang lebih tinggi.
Dalam contoh ini, klik node daun merah paling gelap. Hal ini mengungkapkan bahwa laju kesalahan prediksi model mencapai 43,40% untuk data yang memenuhi semua kondisi berikut:
marital-status == Married-civ-spouse
fnlwgt <= 207583
hours-per-week > 40,5
Heat map
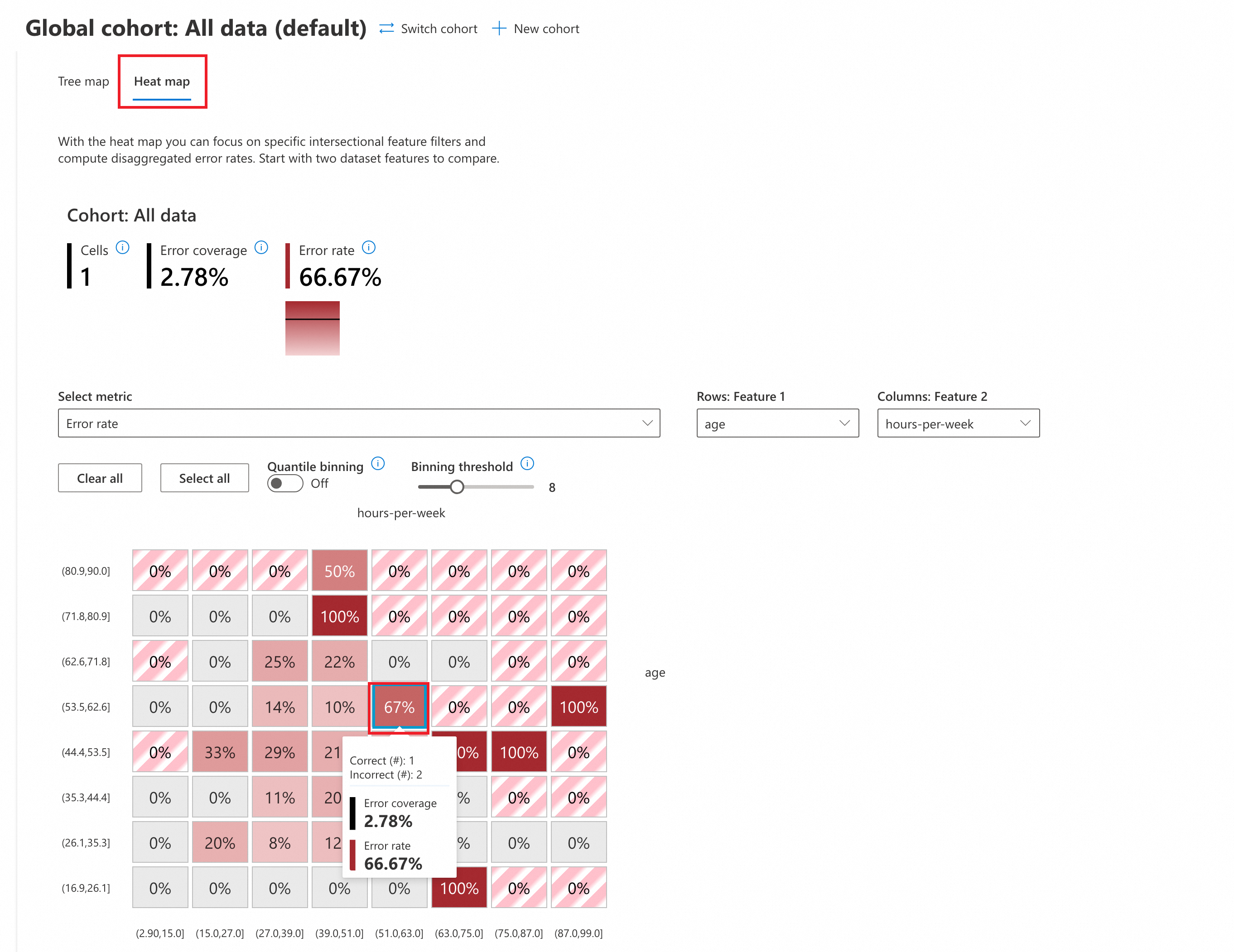
Klik Heat map untuk beralih ke tampilan peta panas. Dari daftar drop-down Select metric, pilih Error rate.
(Opsional) Konfigurasikan parameter:
Pengelompokan kuantil: Metode yang membagi variabel kontinu menjadi beberapa interval, masing-masing berisi jumlah titik data yang sama.
Atur ke OFF untuk menggunakan strategi pengelompokan seragam bawaan, di mana setiap interval memiliki panjang yang sama.
Atur ke ON untuk mengaktifkan pengelompokan kuantil. Setiap interval berisi jumlah titik data yang sama, memastikan distribusi data yang merata di seluruh interval.
Ambang batas pengelompokan: Jumlah interval untuk pengelompokan data. Dalam contoh ini, nilai bawaannya adalah 8, yang membagi
agedanhours-per-weekmenjadi 8 interval yang sama.
Pada peta panas, pilih dua fitur input untuk analisis silang. Contoh ini menggunakan
agedanhours-per-week.Fokus pada sel berwarna merah. Warna merah yang lebih pekat menunjukkan laju kesalahan yang lebih tinggi.
Laju kesalahan tertinggi (hingga 100%) terjadi ketika kedua fitur berada dalam rentang berikut:
age[71,8,80,9], hours-per-week[39,0,51,0]
age[44,4,53,5], hours-per-week[75,0,87,0]
age[16,9,26,1], hours-per-week[63,0,75,0]
...