Transfer pengetahuan dari model guru yang besar ke model siswa yang lebih kecil melalui distilasi model sambil mempertahankan performa.
Distilasi model mengurangi ukuran dan kebutuhan komputasi LLM tanpa mengorbankan performa. Panduan ini mencakup augmentasi data dan distilasi menggunakan model Qwen2.
Alur Kerja
-
Siapkan set data pelatihan sesuai format dan strategi yang ditentukan.
-
Opsional: Augmentasi instruksi
Gunakan Qwen2-1.5B-Instruct-Exp atau Qwen2-7B-Instruct-Exp untuk menghasilkan instruksi yang semantiknya mirip. Augmentasi ini meningkatkan generalisasi selama distilasi.
-
Opsional: Optimalkan instruksi
Gunakan Qwen2-1.5B-Instruct-Refine atau Qwen2-7B-Instruct-Refine untuk memperkaya instruksi—termasuk yang telah diaugmentasi—guna meningkatkan kualitas generasi teks.
-
Hasilkan respons dengan model guru
Gunakan Qwen2-72B-Instruct untuk menghasilkan respons terhadap instruksi dalam set data pelatihan Anda, sehingga mentransfer pengetahuan dari model guru.
-
Gunakan set data instruksi-respons yang telah lengkap untuk melatih model siswa yang lebih kecil dan siap produksi.
Prasyarat
Lengkapi prasyarat berikut:
-
Aktifkan Deep Learning Containers (DLC) dan EAS dari PAI secara bayar sesuai penggunaan dan buat ruang kerja default. Untuk informasi lebih lanjut, lihat Aktifkan PAI dan buat ruang kerja default.
-
Buat Bucket OSS untuk menyimpan data pelatihan dan file model. Untuk informasi lebih lanjut, lihat Mulai Cepat.
Siapkan data instruksi
Siapkan data instruksi mengikuti strategi persiapan data dan persyaratan format data:
Strategi persiapan data
Untuk meningkatkan efektivitas dan stabilitas distilasi model, siapkan data menggunakan strategi berikut:
-
Siapkan minimal beberapa ratus titik data. Semakin banyak data, semakin baik performa model.
-
Pastikan distribusi yang luas dan seimbang: skenario tugas yang beragam, variasi panjang input dan output (contoh pendek maupun panjang), serta distribusi bahasa yang seimbang untuk set data multibahasa.
-
Proses data abnormal. Meskipun jumlahnya kecil, data abnormal dapat memengaruhi hasil fine-tuning. Gunakan metode berbasis aturan untuk membersihkan dan memfilter entri yang tidak valid.
Persyaratan format data
Set data pelatihan harus berupa file JSON dengan satu field: instruction. Field ini berisi instruksi input. Contoh:
[
{
"instruction": "What major measures did governments take to stabilize financial markets during the 2008 financial crisis?"
},
{
"instruction": "What important actions have governments taken to promote sustainable development amid worsening climate change?"
},
{
"instruction": "What major measures did governments take to support economic recovery during the 2001 tech bubble burst?"
}
]Opsional: Augmentasi instruksi
Augmentasi instruksi memperluas set data instruksi yang disediakan pengguna untuk meningkatkan keragaman dan cakupan.
-
Sebagai contoh, diberikan input berikut:
How do I cook fish-flavored shredded pork? How do I prepare for the GRE exam? What should I do if a friend misunderstands me? -
Model menghasilkan output seperti berikut:
Teach me how to cook mapo tofu. Provide a detailed guide for preparing for the TOEFL exam. If you face setbacks at work, how do you adjust your mindset?
Keragaman instruksi memengaruhi generalisasi LLM. Augmentasi instruksi meningkatkan performa model siswa. PAI menyediakan dua model augmentasi instruksi eksklusif berbasis Qwen2: Qwen2-1.5B-Instruct-Exp dan Qwen2-7B-Instruct-Exp. Deploy salah satunya sebagai layanan online EAS:
Deploy model service
Deploy model augmentasi instruksi sebagai layanan online EAS.
-
Buka halaman Model Gallery.
-
Masuk ke Konsol PAI.
-
Di pojok kiri atas, pilih Wilayah Anda.
-
Di panel navigasi kiri, pilih Workspaces, lalu klik nama ruang kerja Anda.
-
Di panel navigasi kiri, pilih .
-
-
Di halaman Model Gallery, cari Qwen2-1.5B-Instruct-Exp atau Qwen2-7B-Instruct-Exp, lalu klik Deploy.
-
Di panel Deploy, tinjau nilai default untuk Model Service Information dan Resource Deployment Information. Ubah sesuai kebutuhan, lalu klik Deploy.
-
Di dialog Billing Notice, klik OK.
Sistem membuka halaman Deployment Task. Ketika Status menunjukkan Running, deployment berhasil.
Call model service
Setelah deployment, gunakan API untuk menjalankan inferensi. Lihat Deploy large language models. Contoh permintaan klien:
-
Dapatkan endpoint layanan dan token.
-
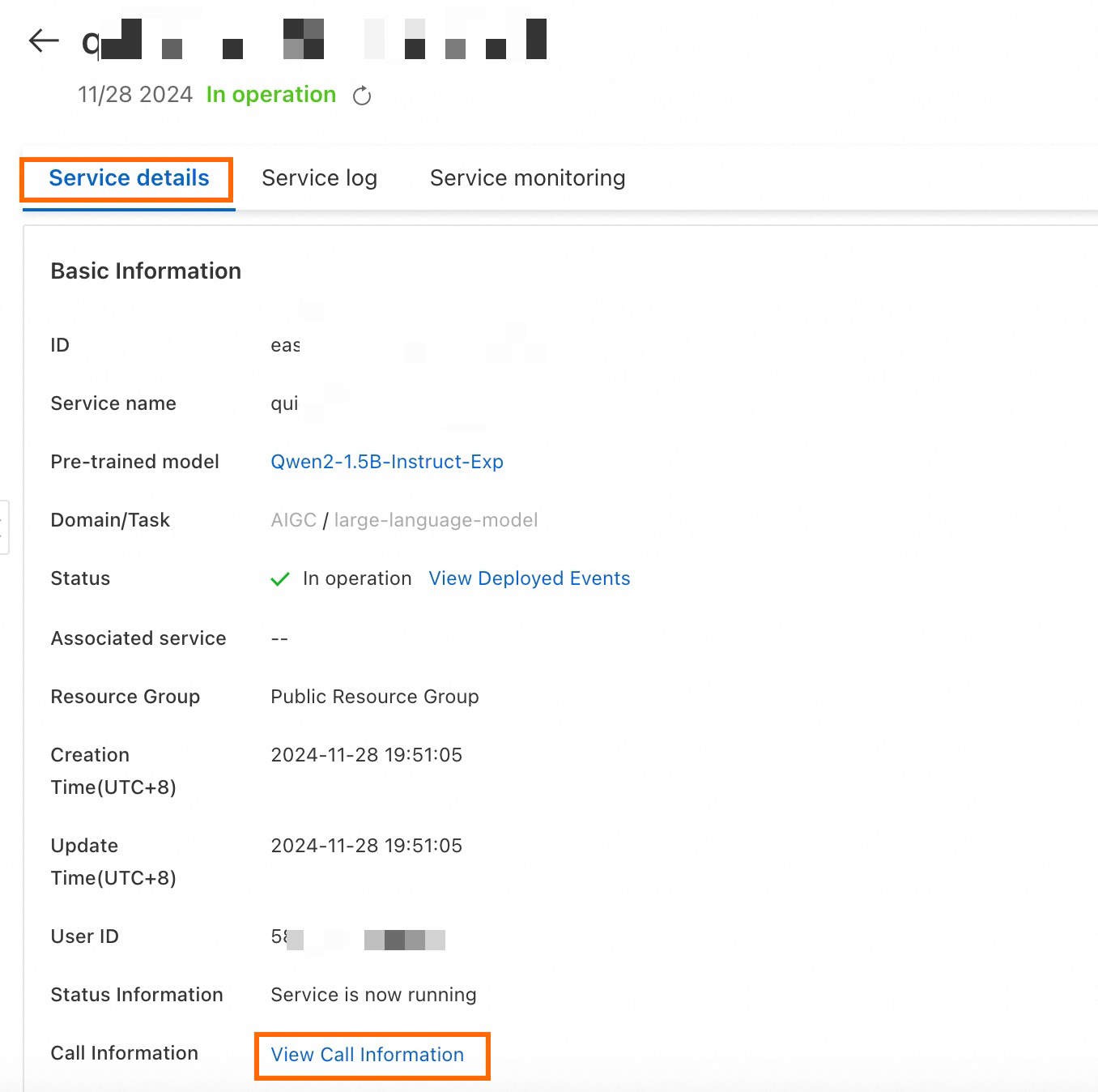
Di halaman Service Details, klik Basic Information, lalu klik View Endpoint Information.
-
Di dialog Endpoint Information, temukan endpoint dan token. Simpan secara lokal.
-
-
Buat dan jalankan skrip Python berikut:
import argparse import json import requests from typing import List def post_http_request(prompt: str, system_prompt: str, host: str, authorization: str, max_new_tokens: int, temperature: float, top_k: int, top_p: float) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "do_sample": True, "eos_token_id": 151645 } response = requests.post(host, headers=headers, json=pload) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] return output if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=50) parser.add_argument("--top-p", type=float, default=0.95) parser.add_argument("--max-new-tokens", type=int, default=2048) parser.add_argument("--temperature", type=float, default=1) parser.add_argument("--prompt", type=str, default="Sing me a song.") args = parser.parse_args() prompt = args.prompt top_k = args.top_k top_p = args.top_p temperature = args.temperature max_new_tokens = args.max_new_tokens host = "EAS HOST" authorization = "EAS TOKEN" print(f" --- input: {prompt}\n", flush=True) system_prompt = "You are an instruction creator. Your goal is to create a new instruction inspired by the [given instruction]." response = post_http_request( prompt, system_prompt, host, authorization, max_new_tokens, temperature, top_k, top_p) output = get_response(response) print(f" --- output: {output}\n", flush=True)Parameter:
-
host: Endpoint layanan.
-
authorization: Token layanan.
-
Batch augmentation
Gunakan layanan EAS untuk memproses instruksi secara batch. Contoh ini membaca set data JSON kustom dan memanggil API model untuk mengaugmentasi instruksi. Buat dan jalankan skrip Python berikut:
import requests
import json
import random
from tqdm import tqdm
from typing import List
input_file_path = "input.json" # Input filename
with open(input_file_path) as fp:
data = json.load(fp)
total_size = 10 # Target total number of samples after expansion
pbar = tqdm(total=total_size)
while len(data) < total_size:
prompt = random.sample(data, 1)[0]["instruction"]
system_prompt = "You are an instruction creator. Your goal is to create a new instruction inspired by the [given instruction]."
top_k = 50
top_p = 0.95
temperature = 1
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": output
}
data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # Output filename
with open(output_file_path, 'w') as f:
json.dump(data, f, ensure_ascii=False)Parameter:
-
host: Endpoint layanan.
-
authorization: Token layanan.
-
file_path: Ganti dengan path lokal ke file set data Anda.
-
Fungsi
post_http_requestdanget_responsesama dengan yang didefinisikan dalam skrip Python di bagian Call model service.
Atau, gunakan komponen LLM-Instruction Expansion (DLC) di PAI-Designer tanpa kode. Lihat Custom pipelines. 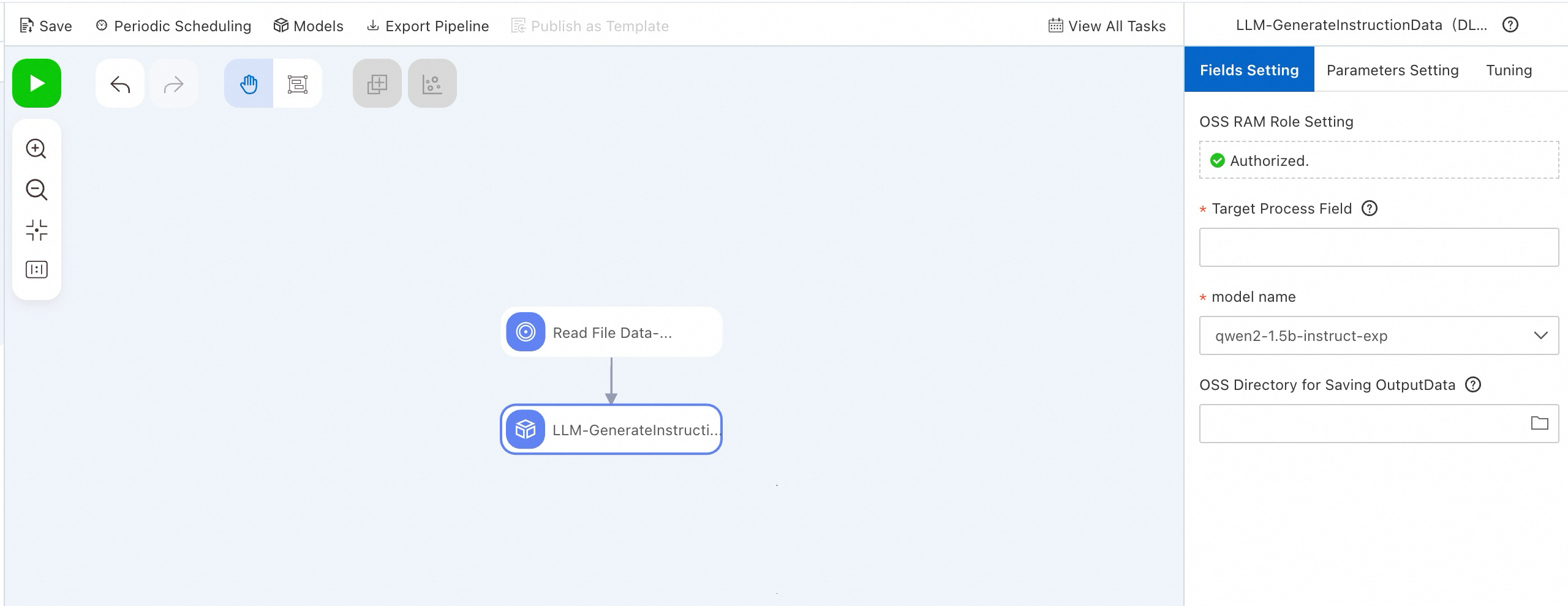
Opsional: Optimalkan instruksi
Optimisasi instruksi menyempurnakan set data instruksi yang disediakan pengguna untuk menghasilkan instruksi yang lebih terperinci dan terstruktur, sehingga menghasilkan respons LLM yang lebih kaya.
-
Sebagai contoh, diberikan input berikut ke model optimisasi instruksi:
How do I cook fish-flavored shredded pork? How do I prepare for the GRE exam? What should I do if a friend misunderstands me? -
Model menghasilkan output seperti berikut:
Provide a detailed Sichuan-style recipe for fish-flavored shredded pork. Include a specific ingredient list—vegetables, pork, and seasonings—along with step-by-step cooking instructions. Also recommend suitable side dishes and staple foods to serve with it. Provide a comprehensive guide covering GRE registration, required documents, study strategies, and recommended review materials. Also suggest effective practice questions and mock exams to help me prepare. Provide a detailed guide on staying calm and rational when misunderstood by a friend—and communicating effectively to resolve it. Include practical advice—for example, how to express your thoughts and feelings, how to avoid escalating misunderstandings, and specific dialogue scenarios and situations for practice.
Detail instruksi memengaruhi kualitas output LLM. Mengoptimalkan instruksi meningkatkan performa model siswa. PAI menyediakan dua model optimisasi instruksi eksklusif berbasis Qwen2: Qwen2-1.5B-Instruct-Refine dan Qwen2-7B-Instruct-Refine. Deploy salah satunya sebagai layanan online EAS:
Deploy model service
-
Buka halaman Model Gallery.
-
Masuk ke Konsol PAI.
-
Di pojok kiri atas, pilih Wilayah Anda.
-
Di panel navigasi kiri, pilih Workspaces, lalu klik nama ruang kerja Anda.
-
Di panel navigasi kiri, pilih .
-
-
Di halaman Model Gallery, cari Qwen2-1.5B-Instruct-Refine atau Qwen2-7B-Instruct-Refine, lalu klik Deploy.
-
Di panel Deploy, tinjau nilai default untuk Model Service Information dan Resource Deployment Information. Ubah sesuai kebutuhan, lalu klik Deploy.
-
Di dialog Billing Notice, klik OK.
Sistem membuka halaman Deployment Task. Ketika Status menunjukkan Running, deployment berhasil.
Call model service
Setelah deployment, gunakan API untuk menjalankan inferensi. Lihat Deploy large language models. Contoh permintaan klien:
-
Dapatkan endpoint layanan dan token.
-
Di halaman Service Details, klik Basic Information, lalu klik View Endpoint Information.
-
Di dialog Endpoint Information, temukan endpoint dan token. Simpan secara lokal.
-
-
Buat dan jalankan skrip Python berikut:
import argparse import json import requests from typing import List def post_http_request(prompt: str, system_prompt: str, host: str, authorization: str, max_new_tokens: int, temperature: float, top_k: int, top_p: float) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "do_sample": True, "eos_token_id": 151645 } response = requests.post(host, headers=headers, json=pload) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] return output if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=2) parser.add_argument("--top-p", type=float, default=0.95) parser.add_argument("--max-new-tokens", type=int, default=256) parser.add_argument("--temperature", type=float, default=0.5) parser.add_argument("--prompt", type=str, default="Sing me a song.") args = parser.parse_args() prompt = args.prompt top_k = args.top_k top_p = args.top_p temperature = args.temperature max_new_tokens = args.max_new_tokens host = "EAS HOST" authorization = "EAS TOKEN" print(f" --- input: {prompt}\n", flush=True) system_prompt = "Optimize this instruction to make it more detailed and specific." response = post_http_request( prompt, system_prompt, host, authorization, max_new_tokens, temperature, top_k, top_p) output = get_response(response) print(f" --- output: {output}\n", flush=True)Parameter:
-
host: Endpoint layanan.
-
Otorisasi: token layanan.
-
Batch optimization
Gunakan layanan EAS untuk memproses instruksi secara batch. Contoh ini membaca set data JSON kustom dan memanggil API model untuk mengoptimalkan instruksi. Buat dan jalankan skrip Python berikut:
import requests
import json
import random
from tqdm import tqdm
from typing import List
input_file_path = "input.json" # Input filename
with open(input_file_path) as fp:
data = json.load(fp)
pbar = tqdm(total=len(data))
new_data = []
for d in data:
prompt = d["instruction"]
system_prompt = "Optimize the following instruction."
top_k = 50
top_p = 0.95
temperature = 1
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": output
}
new_data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # Output filename
with open(output_file_path, 'w') as f:
json.dump(new_data, f, ensure_ascii=False)
Parameter:
-
host: Endpoint layanan.
-
authorization: Token layanan.
-
file_path: Ganti dengan path lokal ke file set data Anda.
-
Fungsi
post_http_requestdanget_responsesama dengan yang didefinisikan dalam skrip Python di bagian Call model service.
Atau, gunakan komponen LLM-Instruction Optimization (DLC) di PAI-Designer tanpa kode. Lihat Custom pipelines. 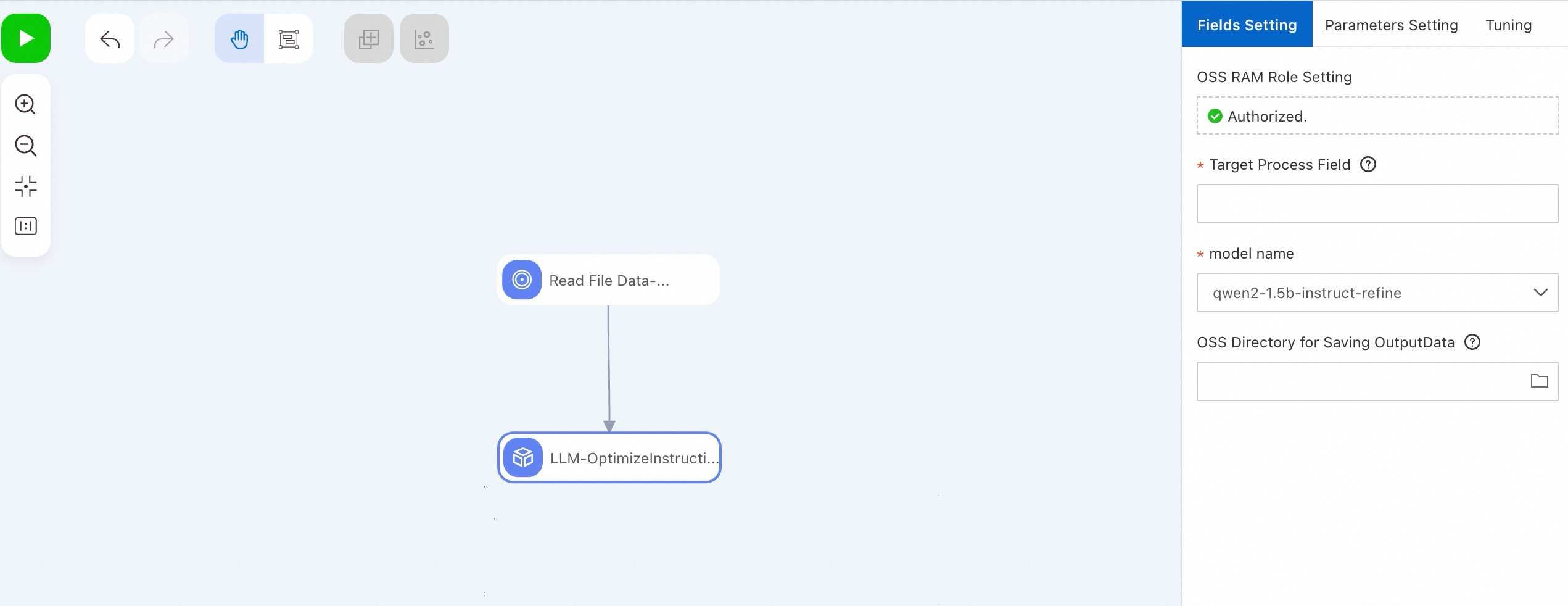
Hasilkan respons dengan model guru
Deploy model service
Setelah mengoptimalkan set data instruksi Anda, deploy LLM guru untuk menghasilkan respons:
-
Buka halaman Model Gallery.
-
Masuk ke Konsol PAI.
-
Di pojok kiri atas, pilih Wilayah Anda.
-
Di panel navigasi kiri, pilih Workspaces, lalu klik nama ruang kerja Anda.
-
Di panel navigasi kiri, pilih .
-
-
Di halaman Model Gallery, cari Qwen2-72B-Instruct, lalu klik Deploy.
-
Di panel Deploy, tinjau nilai default untuk Model Service Information dan Resource Deployment Information. Ubah sesuai kebutuhan, lalu klik Deploy.
-
Di dialog Billing Notice, klik OK.
Sistem membuka halaman Deployment Task. Ketika Status menunjukkan Running, deployment berhasil.
Call model service
Setelah deployment, gunakan API untuk menjalankan inferensi. Lihat Deploy large language models. Contoh permintaan klien:
-
Dapatkan endpoint layanan dan token.
-
Di halaman Service Details, klik Basic Information, lalu klik View Endpoint Information.
-
Di dialog Endpoint Information, temukan endpoint dan token. Simpan secara lokal.
-
-
Buat dan jalankan skrip Python berikut:
import argparse import json import requests from typing import List def post_http_request(prompt: str, system_prompt: str, host: str, authorization: str, max_new_tokens: int, temperature: float, top_k: int, top_p: float) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "do_sample": True, } response = requests.post(host, headers=headers, json=pload) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] return output if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=50) parser.add_argument("--top-p", type=float, default=0.95) parser.add_argument("--max-new-tokens", type=int, default=2048) parser.add_argument("--temperature", type=float, default=0.5) parser.add_argument("--prompt", type=str) parser.add_argument("--system_prompt", type=str) args = parser.parse_args() prompt = args.prompt system_prompt = args.system_prompt top_k = args.top_k top_p = args.top_p temperature = args.temperature max_new_tokens = args.max_new_tokens host = "EAS HOST" authorization = "EAS TOKEN" print(f" --- input: {prompt}\n", flush=True) response = post_http_request( prompt, system_prompt, host, authorization, max_new_tokens, temperature, top_k, top_p) output = get_response(response) print(f" --- output: {output}\n", flush=True)Parameter:
-
host: Endpoint layanan.
-
authorization: Token layanan.
-
Batch teacher model instruction annotation
Contoh ini membaca set data JSON kustom dan memanggil API model untuk menganotasi instruksi. Buat dan jalankan skrip Python berikut:
import json
from tqdm import tqdm
import requests
from typing import List
input_file_path = "input.json" # Input filename
with open(input_file_path) as fp:
data = json.load(fp)
pbar = tqdm(total=len(data))
new_data = []
for d in data:
system_prompt = "You are a helpful assistant."
prompt = d["instruction"]
print(prompt)
top_k = 50
top_p = 0.95
temperature = 0.5
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": prompt,
"output": output
}
new_data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # Output filename
with open(output_file_path, 'w') as f:
json.dump(new_data, f, ensure_ascii=False)Parameter:
-
host: Endpoint layanan.
-
authorization: Token layanan.
-
file_path: Ganti dengan path lokal ke file set data Anda.
-
Fungsi
post_http_requestdanget_responsesama dengan yang didefinisikan dalam skrip di bagian Call model service.
Latih model siswa
Train the model
Setelah mendapatkan respons model guru, latih model siswa di Model Gallery. Solusi ini menggunakan Qwen2-7B-Instruct:
-
Buka halaman Model Gallery.
-
Masuk ke Konsol PAI.
-
Di pojok kiri atas, pilih Wilayah Anda.
-
Di panel navigasi kiri, pilih Workspaces, lalu klik nama ruang kerja Anda.
-
Di panel navigasi kiri, pilih .
-
-
Di halaman Model Gallery, cari dan klik kartu Qwen2-7B-Instruct untuk membuka halaman detailnya.
-
Di halaman detail model, klik Fine-tune di pojok kanan atas.
-
Di panel Fine-tune, atur parameter utama berikut. Biarkan parameter lain pada nilai default.
Parameter
Description
Default value
Dataset configuration
Training dataset
Pilih OSS file or directory dari dropdown, lalu pilih path OSS set data Anda:
-
Klik
 dan pilih Bucket OSS Anda.
dan pilih Bucket OSS Anda. -
Klik Upload file. Unggah file set data Anda ke direktori OSS.
-
Klik OK.
None
Training output configuration
model
Klik
 , lalu pilih direktori penyimpanan OSS Anda.
, lalu pilih direktori penyimpanan OSS Anda.None
tensorboard
Klik
, lalu pilih direktori penyimpanan OSS Anda.None
Compute resource configuration
Job resources
Pilih spesifikasi resource. Sistem merekomendasikan opsi yang sesuai.
None
Hyperparameter configuration
learning_rate
Learning rate. Type: Float.
5e-5
num_train_epochs
Number of training epochs. Type: INT.
1
per_device_train_batch_size
Number of training samples per GPU per iteration. Type: INT.
1
seq_length
Text sequence length. Type: INT.
128
lora_dim
LoRA dimension. Type: INT. If lora_dim>0, use LoRA/QLoRA lightweight training.
32
lora_alpha
LoRA weight. Type: INT. Takes effect only if lora_dim>0 and LoRA/QLoRA lightweight training is used.
32
load_in_4bit
Whether to load the model in 4-bit mode. Type: bool. Valid values:
-
true
-
false
If lora_dim>0, load_in_4bit is true, and load_in_8bit is false, use 4-bit QLoRA lightweight training.
true
load_in_8bit
Whether to load the model in 8-bit mode. Type: bool. Valid values:
-
true
-
false
If lora_dim>0, load_in_4bit is false, and load_in_8bit is true, use 8-bit QLoRA lightweight training.
false
gradient_accumulation_steps
Number of gradient accumulation steps. Type: INT.
8
apply_chat_template
Whether to combine training data with the default chat template. Type: bool. Valid values:
-
true
-
false
For Qwen2 series models, the format is:
-
Question:
<|im_end|>\n<|im_start|>user\n + instruction + <|im_end|>\n -
Answer:
<|im_start|>assistant\n + output + <|im_end|>\n
true
system_prompt
System prompt for training. Type: String.
You are a helpful assistant
-
-
Setelah mengatur parameter, klik Train.
-
Di dialog Billing Notice, klik OK.
Sistem membuka halaman tugas pelatihan.
Deploy model service
Setelah pelatihan, deploy model sebagai layanan EAS.
-
Di halaman tugas pelatihan, klik Deploy di sisi kanan.
-
Di panel deployment, sistem mengatur nilai default untuk Model Service Information dan Resource Deployment Information. Ubah sesuai kebutuhan dan klik Deploy.
-
Di dialog Billing Notice, klik OK.
Sistem membuka halaman Deployment Task. Ketika Status menunjukkan Running, deployment berhasil.
Call model service
Setelah deployment, gunakan API untuk inferensi. Lihat Deploy large language models.
Referensi
-
Lihat EAS overview.
-
PAI-Model Gallery mendukung deployment dan fine-tuning model untuk berbagai skenario, termasuk Llama-3, Qwen1.5, dan Stable Diffusion V1.5. Lihat Scenario-specific practices.