Model Bahasa Besar Multimodal (MLLM) dapat memproses berbagai modalitas data secara bersamaan, mengintegrasikan informasi seperti teks, gambar, dan audio untuk memahami konteks serta tugas kompleks secara komprehensif. Ini cocok untuk skenario yang memerlukan pemahaman lintas modalitas dan generasi. Melalui EAS, Anda dapat menerapkan aplikasi layanan inferensi MLLM dengan satu klik dalam 5 menit untuk mendapatkan kemampuan inferensi LLM. Topik ini menjelaskan cara menerapkan dan memanggil layanan inferensi MLLM melalui EAS.
Informasi latar belakang
Dalam beberapa tahun terakhir, berbagai LLM telah mencapai hasil luar biasa dalam tugas-tugas bahasa. LLM digunakan untuk menghasilkan teks alami dan menunjukkan kemampuan kuat dalam berbagai jenis tugas, seperti analitik sentimen, penerjemahan mesin, dan ringkasan teks. Namun, model-model ini terbatas pada data teks dan tidak dapat memproses bentuk data lainnya, seperti gambar, audio, atau video. Hanya model dengan pemahaman multimodal yang dapat mendekati kemampuan kognitif otak manusia.
Oleh karena itu, MLLM Multimodal telah memicu gelombang penelitian. Dengan penerapan luas LLM seperti GPT-4o di industri, MLLM telah menjadi salah satu aplikasi populer saat ini. Jenis LLM baru ini dapat memproses berbagai modalitas data secara bersamaan, mengintegrasikan informasi seperti teks, gambar, dan audio untuk memahami konteks serta tugas kompleks secara komprehensif.
Ketika Anda perlu mengotomatisasi penerapan MLLM, EAS memberikan solusi satu klik. Melalui EAS, Anda dapat menerapkan aplikasi layanan inferensi MLLM populer dengan satu klik dalam 5 menit untuk mendapatkan kemampuan inferensi LLM.
Prasyarat
Platform for AI (PAI) harus diaktifkan dan ruang kerja default dibuat. Untuk informasi lebih lanjut, lihat Aktifkan PAI dan Buat Ruang Kerja Default.
Jika Anda menggunakan Pengguna RAM untuk menerapkan model, Anda perlu memberikan izin manajemen kepada Pengguna RAM untuk EAS. Untuk informasi lebih lanjut, lihat Dependensi Produk Cloud dan Otorisasi: EAS.
Terapkan layanan model di EAS
Masuk ke Konsol PAI. Pilih Wilayah di bagian atas halaman, pilih ruang kerja yang diinginkan, dan klik Elastic Algorithm Service (EAS).
Klik Deploy Service. Di bagian Custom Model Deployment, klik Custom Deployment.
Di halaman Custom Deployment, konfigurasikan parameter kunci berikut. Untuk informasi tentang parameter lainnya, lihat Parameter untuk Penyebaran Kustom di Konsol.
Parameter
Deskripsi
Environment Context
Deployment Method
Pilih Image-based Deployment dan Enable Web App.
Image Configuration
Pilih Alibaba Cloud Image > chat-mllm-webui > chat-mllm-webui:1.0.
CatatanKami merekomendasikan Anda memilih versi terbaru dari citra ketika Anda menerapkan layanan model.
Command
Setelah Anda memilih citra, sistem akan mengonfigurasi parameter ini secara otomatis. Anda dapat memodifikasi parameter model_type untuk menerapkan model yang berbeda. Tabel berikut menyediakan jenis model yang didukung.
Resource Information
Deploy Resources
Pilih tipe GPU. Kami merekomendasikan Anda memilih tipe instans ml.gu7i.c16m60.1-gu30, yang paling hemat biaya.
Setelah mengonfigurasi parameter, klik Deploy.
Panggil layanan
Gunakan antarmuka web untuk melakukan inferensi model
Di halaman Elastic Algorithm Service (EAS), klik nama layanan target, lalu klik View Web App di sudut kanan atas halaman, dan ikuti instruksi di konsol untuk membuka halaman WebUI.
Di halaman antarmuka web, lakukan inferensi model.
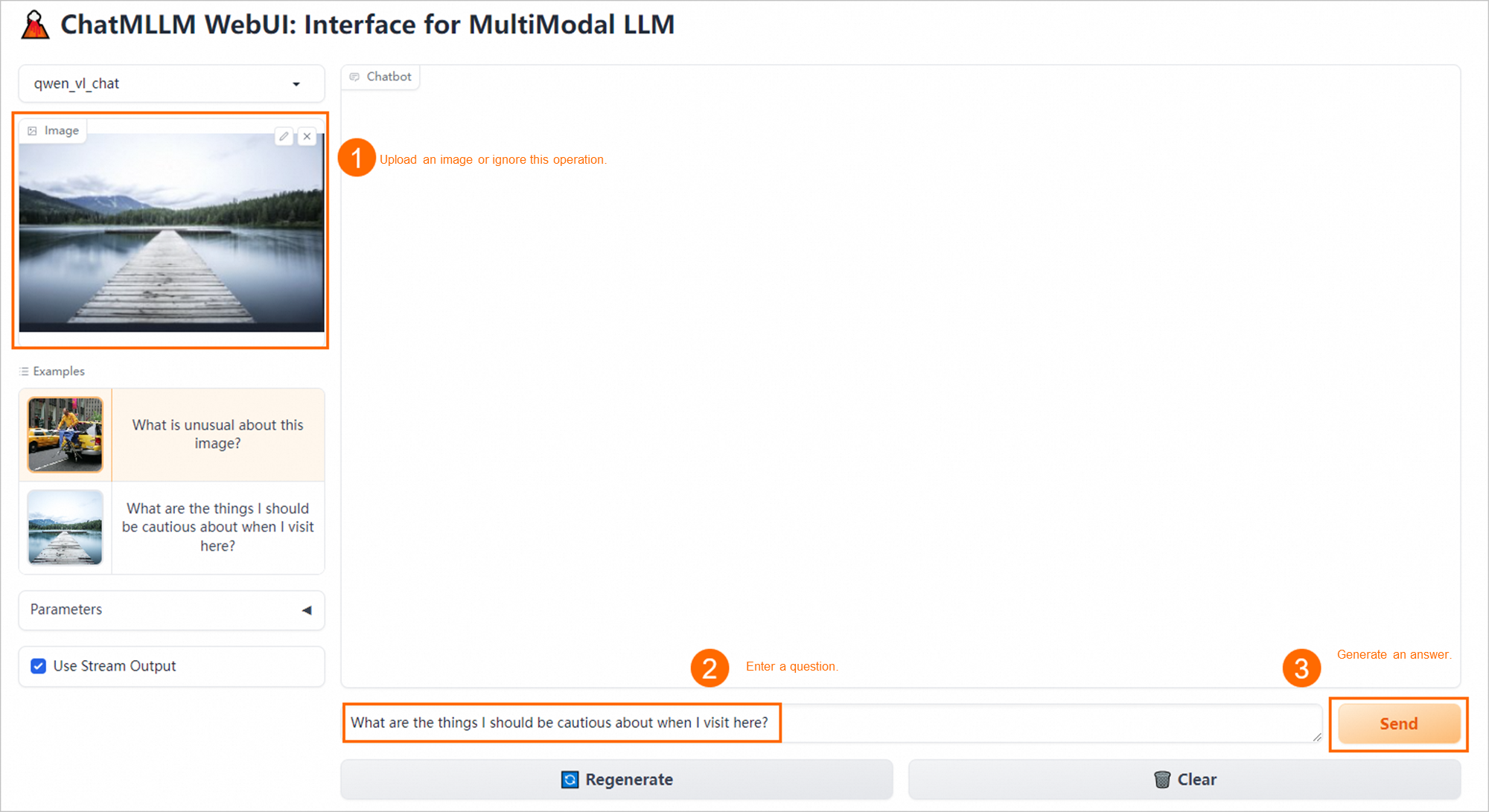
Panggil operasi API untuk melakukan inferensi model
Peroleh endpoint dan token layanan.
Di halaman Elastic Algorithm Service (EAS), klik nama layanan target. Kemudian, di bagian Basic Information, klik View Invocation Information.
Di panel Invocation Information, peroleh Token layanan dan endpoint.
Panggil operasi API untuk melakukan inferensi model.
PAI menyediakan API berikut:
infer forward
Peroleh hasil inferensi.
CatatanWebUI dan pemanggilan API tidak dapat digunakan secara bersamaan. Jika Anda sudah menggunakan WebUI untuk membuat panggilan, pertama-tama jalankan kode
clear chat historyuntuk membersihkan riwayat obrolan, lalu jalankan kodeinfer forwarduntuk mendapatkan hasil inferensi.Parameter kunci yang perlu diganti dalam kode contoh dijelaskan sebagai berikut:
Parameter
Deskripsi
hosts
Endpoint yang Anda peroleh di Langkah 1.
authorization
Token layanan yang Anda peroleh di Langkah 1.
prompt
Isi pertanyaan. Pertanyaan dalam bahasa Inggris direkomendasikan.
image_path
Jalur lokal tempat gambar berada.
Kode contoh berikut memberikan contoh cara menggunakan Python untuk melakukan inferensi model:
import requests import json import base64 def post_get_history(url='http://127.0.0.1:7860', headers=None): r = requests.post(f'{url}/get_history', headers=headers, timeout=1500) data = r.content.decode('utf-8') return data def post_infer(prompt, image=None, chat_history=[], temperature=0.2, top_p=0.7, max_output_tokens=512, use_stream = True, url='http://127.0.0.1:7860', headers={}): datas = { "prompt": prompt, "image": image, "chat_history": chat_history, "temperature": temperature, "top_p": top_p, "max_output_tokens": max_output_tokens, "use_stream": use_stream, } if use_stream: headers.update({'Accept': 'text/event-stream'}) response = requests.post(f'{url}/infer_forward', json=datas, headers=headers, stream=True, timeout=1500) if response.status_code != 200: print(f"Permintaan gagal dengan kode status {response.status_code}") return process_stream(response) else: r = requests.post(f'{url}/infer_forward', json=datas, headers=headers, timeout=1500) data = r.content.decode('utf-8') print(data) def image_to_base64(image_path): """ Mengubah file gambar menjadi string yang dikodekan dalam Base64. :param image_path: Jalur file ke gambar. :return: Representasi string dari gambar yang dikodekan dalam Base64. """ with open(image_path, "rb") as image_file: # Baca data biner gambar image_data = image_file.read() # Enkode data biner ke Base64 base64_encoded_data = base64.b64encode(image_data) # Ubah bytes menjadi string dan hapus karakter baris baru base64_string = base64_encoded_data.decode('utf-8').replace('\n', '') return base64_string def process_stream(response, previous_text=""): MARK_RESPONSE_END = '##END' # JANGAN UBAH buffer = previous_text current_response = "" for chunk in response.iter_content(chunk_size=100): if chunk: text = chunk.decode('utf-8') current_response += text parts = current_response.split(MARK_RESPONSE_END) for part in parts[:-1]: new_part = part[len(previous_text):] if new_part: print(new_part, end='', flush=True) previous_text = part current_response = parts[-1] remaining_new_text = current_response[len(previous_text):] if remaining_new_text: print(remaining_new_text, end='', flush=True) if __name__ == '__main__': # Ganti <service_url> dengan endpoint layanan. hosts = '<service_url>' # Ganti <token> dengan token layanan. head = { 'Authorization': '<token>' } # Dapatkan riwayat obrolan chat_history = json.loads(post_get_history(url=hosts, headers=head))['chat_history'] # Isi pertanyaan. Pertanyaan dalam bahasa Inggris direkomendasikan. prompt = 'Harap jelaskan gambar tersebut' # Ganti path_to_your_image dengan jalur lokal gambar. image_path = 'path_to_your_image' image_base_64 = image_to_base64(image_path) post_infer(prompt = prompt, image = image_base_64, chat_history = chat_history, use_stream=False, url=hosts, headers=head)get chat history
Dapatkan riwayat obrolan.
Parameter kunci yang perlu diganti dalam kode contoh dijelaskan sebagai berikut:
Parameter
Deskripsi
hosts
Konfigurasikan endpoint layanan yang diperoleh di Langkah 1.
authorization
Konfigurasikan Token layanan yang diperoleh di Langkah 1.
Tidak diperlukan parameter input.
Tabel berikut menjelaskan parameter output.
Parameter
Tipe
Catatan
chat_history
List[List]
Riwayat percakapan.
Kode contoh berikut memberikan contoh cara menggunakan Python untuk melakukan inferensi model:
import requests import json def post_get_history(url='http://127.0.0.1:7860', headers=None): r = requests.post(f'{url}/get_history', headers=headers, timeout=1500) data = r.content.decode('utf-8') return data if __name__ == '__main__': # Ganti <service_url> dengan URL layanan hosts = '<service_url>' # Ganti <token> dengan token layanan head = { 'Authorization': '<token>' } chat_history = json.loads(post_get_history(url=hosts, headers=head))['chat_history'] print(chat_history)clear chat history
Hapus riwayat obrolan.
Parameter kunci yang perlu diganti dalam kode contoh dijelaskan sebagai berikut:
Parameter
Deskripsi
hosts
Konfigurasikan endpoint yang diperoleh di Langkah 1.
authorization
Konfigurasikan token layanan yang diperoleh di Langkah 1.
Tidak diperlukan parameter input.
Hasil yang dikembalikan adalah sukses.
Kode contoh berikut memberikan contoh cara menggunakan Python untuk melakukan inferensi model:
import requests import json def post_clear_history(url='http://127.0.0.1:7860', headers=None): r = requests.post(f'{url}/clear_history', headers=headers, timeout=1500) data = r.content.decode('utf-8') return data if __name__ == '__main__': # Ganti <service_url> dengan endpoint layanan. hosts = '<service_url>' # Ganti <token> dengan token layanan. head = { 'Authorization': '<token>' } clear_info = post_clear_history(url=hosts, headers=head) print(clear_info)