Beberapa model dalam Coding Plan Alibaba Cloud Model Studio, seperti qwen3.5-plus dan kimi-k2.5, memiliki kemampuan pemahaman visual bawaan dan dapat langsung memproses input gambar. Untuk model teks biasa seperti glm-5 dan MiniMax-M2.5, Anda dapat menambahkan Skill lokal untuk mengaktifkan kemampuan pemahaman visual.
Menjalankan Skill pemahaman gambar akan mengonsumsi kuota Coding Plan Anda. Tidak ada biaya tambahan lainnya.
Prasyarat
Anda telah berlangganan Coding Plan. Untuk informasi selengkapnya, lihat Memulai.
Anda telah mengonfigurasi koneksi di tool Coding Plan dan dapat melakukan percakapan secara normal. Untuk informasi selengkapnya, lihat Menghubungkan ke tool AI.
Status dukungan visual
Model | Dukungan visual | Deskripsi |
| Ya | Tidak diperlukan konfigurasi tambahan. Gambar dapat dikirim langsung. |
| Tidak | Diperlukan Skill atau Agent untuk memberikan kemampuan visual pada model tersebut. |
Metode 1: Gunakan model visual secara langsung (Direkomendasikan)
Model qwen3.5-plus dan kimi-k2.5 memiliki kemampuan pemahaman visual bawaan. Jika Anda sering perlu memproses gambar, beralih ke model-model ini merupakan pendekatan paling sederhana dan direkomendasikan.
Tool | Cara mengganti model |
Claude Code |
|
OpenCode |
|
Qwen Code |
|
Untuk informasi selengkapnya tentang cara mengganti model di tool pemrograman lainnya, lihat Menghubungkan ke tool AI. Setelah mengganti model, Anda dapat langsung mereferensikan path gambar dalam percakapan, atau menyeret dan melepas (drag and drop) serta menempel (paste) gambar.
Metode 2: Tambahkan kemampuan visual menggunakan Skill atau Agent
Untuk memproses gambar dengan model yang tidak memiliki kemampuan pemahaman visual, seperti glm-5 dan MiniMax-M2.5, Anda dapat mengonfigurasi Skill atau Agent.
Claude Code
Tambahkan Skill
Di folder
.claudedalam direktori proyek Anda, buat folderskills/image-analyzer:mkdir -p .claude/skills/image-analyzerDi folder ini, buat file
SKILL.mddan tambahkan konten berikut:--- name: image-analyzer description: Membantu model tanpa kemampuan visual memahami gambar. Gunakan skill ini saat Anda perlu menganalisis konten gambar, mengekstrak informasi, teks, atau elemen UI dari gambar, atau memahami konten visual apa pun seperti tangkapan layar, grafik, atau diagram arsitektur. Kirim path gambar untuk mendapatkan deskripsi. model: qwen3.5-plus --- qwen3.5-plus memiliki kemampuan pemahaman visual. Gunakan model qwen3.5-plus secara langsung untuk pemahaman gambar.Struktur folder yang dihasilkan adalah sebagai berikut:
.claude/ └── skills/ └── image-analyzer/ └── SKILL.mdMemulai
Di direktori proyek Anda, jalankan
claudeuntuk memulai Claude Code, lalu jalankan/model glm-5untuk beralih ke modelglm-5.Unduh dan alibabacloud.png ke direktori proyek Anda, lalu ajukan pertanyaan berikut:
Load the image-analyzer skill and describe the information displayed in the alibabacloud.png banner.Anda akan menerima respons berikut: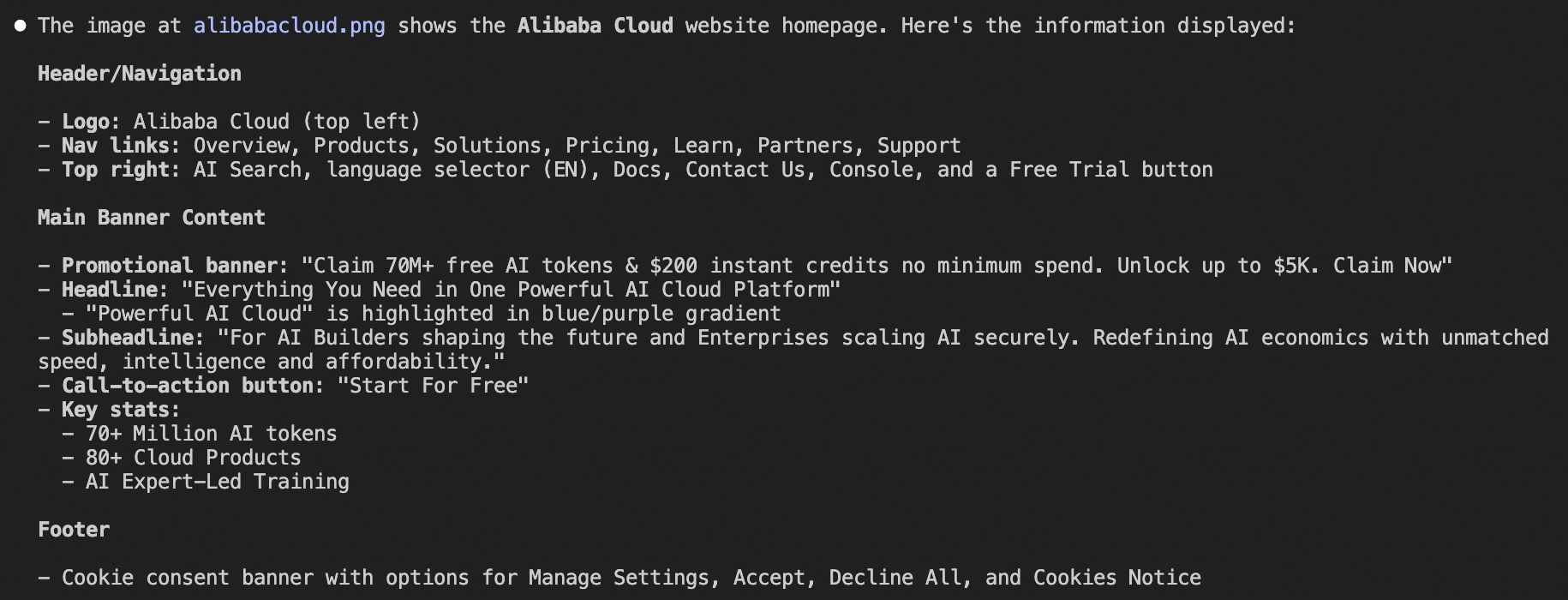
{kind=link}
OpenCode
Tambahkan Agent
Di folder
.opencodedalam direktori proyek Anda, buat folder baruagents.mkdir -p .opencode/agentsDi folder ini, buat file
image-analyzer.mddan tambahkan konten berikut:CatatanBidang model harus menggunakan nama penyedia dan model yang didefinisikan dalam file konfigurasi OpenCode. Misalnya, berdasarkan konfigurasi dalam dokumen OpenCode, nilainya adalah
bailian-coding-plan/qwen3.5-plus.--- description: Menganalisis gambar menggunakan model yang mendukung visi. Gunakan agent ini saat pengguna perlu memahami konten gambar, mengekstrak informasi dari tangkapan layar, diagram, mockup UI, atau konten visual apa pun. Panggil dengan @image-analyzer diikuti path gambar dan pertanyaan Anda. mode: subagent model: bailian-coding-plan/qwen3.5-plus tools: write: false edit: false --- Anda memiliki kemampuan visi. Analisis gambar yang diberikan dan kembalikan deskripsi yang jelas dan terstruktur sesuai permintaan pengguna.Struktur folder yang dihasilkan adalah sebagai berikut:
.opencode/ └── agents/ └── image-analyzer.mdMemulai
Di direktori proyek Anda, jalankan
opencodeuntuk memulai OpenCode, lalu beralih ke modelglm-5.Unduh dan alibabacloud.png ke folder proyek, gunakan tanda
@untuk memanggilimage-analyzer, lalu ajukan pertanyaan berikut:@image-analyzer describe the information displayed in the alibabacloud.png banner.Anda akan menerima respons berikut: