Topik ini menjelaskan cara menggunakan Milvus 2.5 untuk melakukan pencarian teks lengkap, pencocokan kata kunci, dan pencarian hibrida. Versi ini meningkatkan presisi pencarian serta memberikan fleksibilitas lebih besar dalam pencarian kemiripan vektor dan analitik data. Topik ini juga menunjukkan penerapan pencarian hibrida pada tahap Pengambilan (Retrieval) dalam aplikasi Generasi yang Diperkaya dengan Pengambilan Data (RAG) guna menyediakan konteks yang lebih tepat dalam menghasilkan tanggapan.
Informasi latar belakang
Untuk pertama kalinya, Milvus 2.5 menyediakan kemampuan pencarian teks lengkap native dengan mengintegrasikan pustaka mesin pencari berkinerja tinggi Tantivy dan menyertakan algoritma sparse-bm25 bawaan. Fitur ini melengkapi fungsionalitas pencarian semantik yang sudah ada sehingga menghadirkan pengalaman pencarian yang lebih kuat.
Pemisah kata (tokenizer) bawaan: Milvus menerima input teks secara langsung dan menggunakan tokenizer bawaan untuk ekstraksi vektor jarang. Proses ini secara otomatis memisahkan teks menjadi token, menyaring stop words, dan mengekstraksi vektor jarang tanpa memerlukan pra-pemrosesan tambahan.
Statistik BM25 real-time: Frekuensi term (TF) dan frekuensi dokumen invers (IDF) diperbarui secara dinamis saat data dimasukkan, sehingga memastikan hasil pencarian bersifat real-time dan akurat.
Kinerja pencarian hibrida yang ditingkatkan: Pengambilan vektor jarang berdasarkan algoritma tetangga terdekat aproksimasi (ANN) jauh melampaui sistem kata kunci tradisional. Fitur ini mendukung tanggapan dalam tingkat milidetik untuk ratusan juta entri data dan kompatibel dengan kueri hibrida yang mencakup vektor padat.
Prasyarat
Buat instans Milvus dengan Kernel Version 2.5 atau lebih baru. Untuk informasi selengkapnya, lihat Create a Milvus instance.
Aktifkan layanan dan peroleh Kunci API.
Batasan
Fitur ini berlaku untuk instans Milvus dengan Kernel Version 2.5 atau lebih baru.
Panduan ini berlaku untuk kit pengembangan perangkat lunak (SDK) Python untuk
pymilvusversi 2.5 atau lebih baru.Anda dapat menjalankan perintah berikut untuk memeriksa versi yang saat ini terinstal.
pip3 show pymilvusJika versinya lebih lama dari 2.5, gunakan perintah berikut untuk memperbaruinya.
pip3 install --upgrade pymilvus
Prosedur
Langkah 1: Instal pustaka dependensi
pip3 install pymilvus langchain dashscopeLangkah 2: Persiapan Data
Topik ini menggunakan dokumentasi resmi Milvus sebagai contoh. Teks tersebut dipecah menjadi chunk menggunakan SDK LangChain dan digunakan sebagai input untuk model penyematan text-embedding-v2. Hasil penyematan dan teks asli kemudian dimasukkan ke dalam Milvus.
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from pymilvus import MilvusClient, DataType, Function, FunctionType
dashscope_api_key = "<YOUR_DASHSCOPE_API_KEY>"
milvus_url = "<YOUR_MMILVUS_URL>"
user_name = "root"
password = "<YOUR_PASSWORD>"
collection_name = "milvus_overview"
dense_dim = 1536
loader = WebBaseLoader([
'https://raw.githubusercontent.com/milvus-io/milvus-docs/refs/heads/v2.5.x/site/en/about/overview.md'
])
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=256)
# Gunakan LangChain untuk membagi dokumen input berdasarkan chunk_size
all_splits = text_splitter.split_documents(docs)
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", dashscope_api_key=dashscope_api_key
)
text_contents = [doc.page_content for doc in all_splits]
vectors = embeddings.embed_documents(text_contents)
client = MilvusClient(
uri=f"http://{milvus_url}:19530",
token=f"{user_name}:{password}",
)
schema = MilvusClient.create_schema(
enable_dynamic_field=True,
)
analyzer_params = {
"type": "english"
}
# Tambahkan bidang ke skema
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=65535, enable_analyzer=True, analyzer_params=analyzer_params, enable_match=True)
schema.add_field(field_name="sparse_bm25", datatype=DataType.SPARSE_FLOAT_VECTOR)
schema.add_field(field_name="dense", datatype=DataType.FLOAT_VECTOR, dim=dense_dim)
bm25_function = Function(
name="bm25",
function_type=FunctionType.BM25,
input_field_names=["text"],
output_field_names="sparse_bm25",
)
schema.add_function(bm25_function)
index_params = client.prepare_index_params()
# Tambahkan indeks
index_params.add_index(
field_name="dense",
index_name="dense_index",
index_type="IVF_FLAT",
metric_type="IP",
params={"nlist": 128},
)
index_params.add_index(
field_name="sparse_bm25",
index_name="sparse_bm25_index",
index_type="SPARSE_WAND",
metric_type="BM25"
)
# Buat koleksi
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params
)
data = [
{"dense": vectors[idx], "text": doc}
for idx, doc in enumerate(text_contents)
]
# Masukkan data
res = client.insert(
collection_name=collection_name,
data=data
)
print(f"Dihasilkan {len(vectors)} vektor, dimensi: {len(vectors[0])}")
Contoh ini menggunakan parameter berikut. Ganti dengan nilai aktual Anda.
Parameter | Deskripsi |
| Kunci API untuk Alibaba Cloud Model Studio. |
| Alamat Internal IP Address atau alamat Public IP Address instans Milvus. Anda dapat melihatnya pada halaman Details instans Milvus.
|
| Username dan password yang Anda tentukan saat membuat instans Milvus. |
| |
| Nama koleksi. Anda dapat menyesuaikan nama ini. Topik ini menggunakan milvus_overview sebagai contoh. |
| Dimensi vektor padat. Karena model text-embedding-v2 menghasilkan vektor dengan dimensi 1536, atur dense_dim ke 1536. |
Contoh ini memanfaatkan fitur terbaru Milvus 2.5. Dengan membuat objek bm25_function, Milvus secara otomatis mengubah kolom teks menjadi vektor jarang.
Demikian pula, saat memproses dokumen berbahasa Tionghoa, Milvus 2.5 memungkinkan Anda menentukan alat analisis (analyzer) chinese yang sesuai.
Setelah Anda mengonfigurasi analyzer dalam skema, pengaturan tersebut bersifat permanen untuk koleksi tersebut. Untuk mengatur analyzer baru, Anda harus membuat koleksi baru.
# Definisikan parameter tokenizer
analyzer_params = {
"type": "chinese" # Tentukan jenis tokenizer sebagai chinese
}
# Tambahkan bidang teks ke skema dan aktifkan tokenizer
schema.add_field(
field_name="text", # Nama bidang
datatype=DataType.VARCHAR, # Jenis data: string (VARCHAR)
max_length=65535, # Panjang maksimum: 65535 karakter
enable_analyzer=True, # Aktifkan tokenizer
analyzer_params=analyzer_params # Parameter tokenizer
)
Langkah 3: Lakukan pencarian teks lengkap
Milvus 2.5 memungkinkan Anda menggunakan fitur pencarian teks lengkap terbaru melalui API-nya. Kode berikut memberikan contohnya.
from pymilvus import MilvusClient
# Buat client Milvus.
client = MilvusClient(
uri="http://c-xxxx.milvus.aliyuncs.com:19530", # Alamat jaringan publik instans Milvus.
token="<yourUsername>:<yourPassword>", # Username dan password untuk login ke instans Milvus.
db_name="default" # Nama database yang akan dihubungkan. Contoh ini menggunakan database default.
)
search_params = {
'params': {'drop_ratio_search': 0.2},
}
full_text_search_res = client.search(
collection_name='milvus_overview',
data=['what makes milvus so fast?'],
anns_field='sparse_bm25',
limit=3,
search_params=search_params,
output_fields=["text"],
)
for hits in full_text_search_res:
for hit in hits:
print(hit)
print("\n")
"""
{'id': 456165042536597485, 'distance': 6.128782272338867, 'entity': {'text': '## What Makes Milvus so Fast?\n\nMilvus was designed from day one to be a highly efficient vector database system. In most cases, Milvus outperforms other vector databases by 2-5x (see the VectorDBBench results). This high performance is the result of several key design decisions:\n\n**Hardware-aware Optimization**: To accommodate Milvus in various hardware environments, we have optimized its performance specifically for many hardware architectures and platforms, including AVX512, SIMD, GPUs, and NVMe SSD.\n\n**Advanced Search Algorithms**: Milvus supports a wide range of in-memory and on-disk indexing/search algorithms, including IVF, HNSW, DiskANN, and more, all of which have been deeply optimized. Compared to popular implementations like FAISS and HNSWLib, Milvus delivers 30%-70% better performance.'}}
{'id': 456165042536597487, 'distance': 4.760214805603027, 'entity': {'text': "## What Makes Milvus so Scalable\n\nIn 2022, Milvus supported billion-scale vectors, and in 2023, it scaled up to tens of billions with consistent stability, powering large-scale scenarios for over 300 major enterprises, including Salesforce, PayPal, Shopee, Airbnb, eBay, NVIDIA, IBM, AT&T, LINE, ROBLOX, Inflection, etc.\n\nMilvus's cloud-native and highly decoupled system architecture ensures that the system can continuously expand as data grows:\n\n"}}
"""Langkah 4: Pencocokan kata kunci
Pencocokan kata kunci merupakan fitur baru di Milvus 2.5. Fitur ini dapat dikombinasikan dengan pencarian kemiripan vektor untuk mempersempit cakupan pencarian dan meningkatkan kinerja. Untuk menggunakannya, atur kedua parameter enable_analyzer dan enable_match ke True saat mendefinisikan skema.
Mengaktifkan enable_match akan membuat Indeks terbalik untuk bidang tersebut, yang mengonsumsi sumber daya penyimpanan tambahan.
Contoh 1: Pencocokan kata kunci dikombinasikan dengan pencarian vektor
Dalam potongan kode ini, ekspresi filter membatasi hasil pencarian hanya pada dokumen yang mengandung kata 'query' dan 'node'. Pencarian kemiripan vektor kemudian dilakukan pada subset dokumen yang telah difilter.
filter = "TEXT_MATCH(text, 'query') and TEXT_MATCH(text, 'node')"
text_match_res = client.search(
collection_name="milvus_overview",
anns_field="dense",
data=query_embeddings,
filter=filter,
search_params={"params": {"nprobe": 10}},
limit=2,
output_fields=["text"]
)Contoh 2: Kueri pemfilteran skalar
Pencocokan kata kunci juga dapat digunakan untuk pemfilteran skalar dalam operasi kueri. Anda dapat menentukan ekspresi TEXT_MATCH dalam query() untuk mengambil dokumen yang mengandung kata-kata tertentu. Dalam potongan kode ini, ekspresi filter membatasi hasil pencarian hanya pada dokumen yang mengandung 'scalable' atau 'fast'.
filter = "TEXT_MATCH(text, 'scalable fast')"
text_match_res = client.query(
collection_name="milvus_overview",
filter=filter,
output_fields=["text"]
)Langkah 5: Pencarian hibrida dan RAG
Anda dapat menggabungkan pencarian vektor dan pencarian teks lengkap serta menggunakan algoritma Reciprocal Rank Fusion (RRF) untuk menggabungkan hasil dari kedua pencarian tersebut. Proses ini mengoptimalkan ulang pengurutan dan alokasi bobot guna meningkatkan tingkat recall dan akurasi.
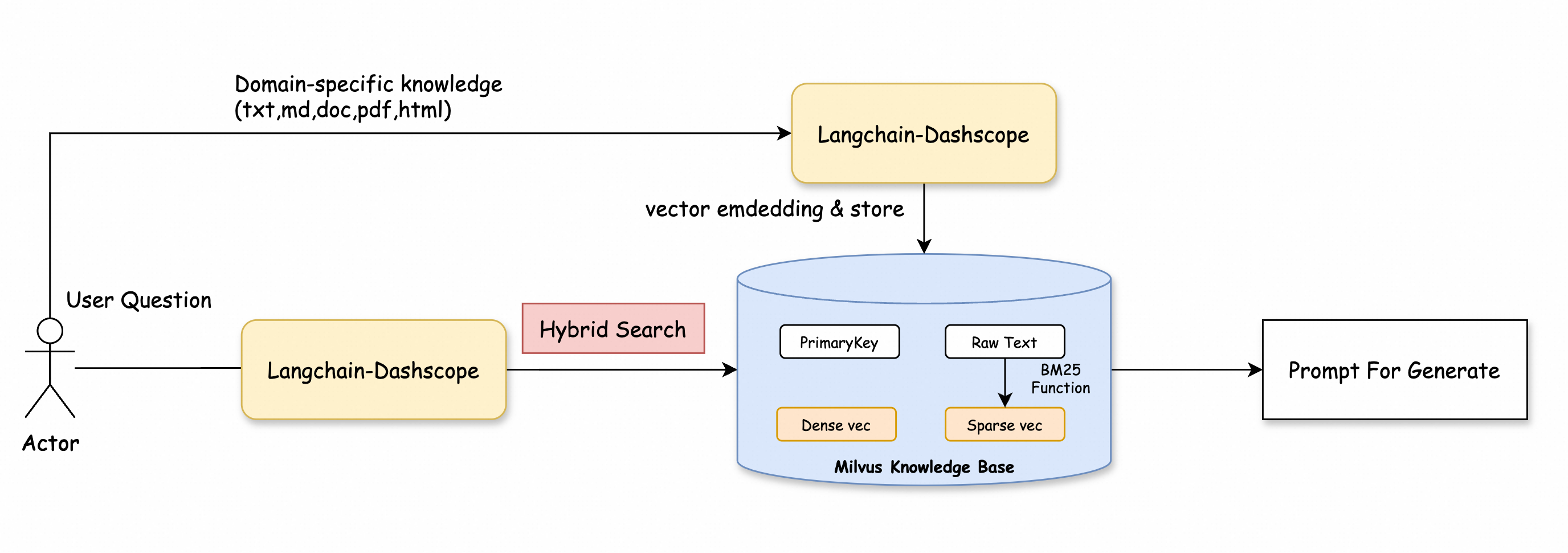
Kode berikut memberikan contohnya.
from pymilvus import MilvusClient
from pymilvus import AnnSearchRequest, RRFRanker
from langchain_community.embeddings import DashScopeEmbeddings
from dashscope import Generation
# Buat client Milvus.
client = MilvusClient(
uri="http://c-xxxx.milvus.aliyuncs.com:19530", # Alamat jaringan publik instans Milvus.
token="<yourUsername>:<yourPassword>", # Username dan password untuk login ke instans Milvus.
db_name="default" # Nama database yang akan dihubungkan. Contoh ini menggunakan database default.
)
collection_name = "milvus_overview"
# Ganti dengan Kunci API DashScope Anda
dashscope_api_key = "<YOUR_DASHSCOPE_API_KEY>"
# Inisialisasi model penyematan
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # Gunakan model text-embedding-v2.
dashscope_api_key=dashscope_api_key
)
# Definisikan kueri
query = "Why does Milvus run so scalable?"
# Lakukan penyematan kueri dan hasilkan representasi vektor yang sesuai
query_embeddings = embeddings.embed_documents([query])
# Atur jumlah hasil top K
top_k = 5 # Ambil 5 dokumen teratas yang relevan dengan kueri
# Definisikan parameter untuk pencarian vektor padat
search_params_dense = {
"metric_type": "IP",
"params": {"nprobe": 2}
}
# Buat permintaan pencarian vektor padat
request_dense = AnnSearchRequest([query_embeddings[0]], "dense", search_params_dense, limit=top_k)
# Definisikan parameter untuk pencarian teks BM25
search_params_bm25 = {
"metric_type": "BM25"
}
# Buat permintaan pencarian teks BM25
request_bm25 = AnnSearchRequest([query], "sparse_bm25", search_params_bm25, limit=top_k)
# Gabungkan kedua permintaan
reqs = [request_dense, request_bm25]
# Inisialisasi algoritma peringkat RRF
ranker = RRFRanker(100)
# Lakukan pencarian hibrida
hybrid_search_res = client.hybrid_search(
collection_name=collection_name,
reqs=reqs,
ranker=ranker,
limit=top_k,
output_fields=["text"]
)
# Ekstrak konteks dari hasil pencarian hibrida
context = []
print("Hasil Top K:")
for hits in hybrid_search_res: # Gunakan variabel yang benar di sini
for hit in hits:
context.append(hit['entity']['text']) # Ekstrak konten teks ke daftar konteks
print(hit['entity']['text']) # Tampilkan setiap dokumen yang diambil
# Definisikan fungsi untuk mendapatkan jawaban berdasarkan kueri dan konteks
def getAnswer(query, context):
prompt = f'''Silakan jawab pertanyaan saya berdasarkan konten berikut:
```
{context}
```
Pertanyaan saya adalah: {query}.
'''
# Panggil modul generasi untuk mendapatkan jawaban
rsp = Generation.call(model='qwen-turbo', prompt=prompt)
return rsp.output.text
# Dapatkan jawaban
answer = getAnswer(query, context)
print(answer)
# Cuplikan output yang diharapkan
"""
Milvus sangat scalable karena arsitektur sistemnya yang cloud-native dan sangat terdesentralisasi. Arsitektur ini memungkinkan sistem terus berkembang seiring pertumbuhan data. Selain itu, Milvus mendukung tiga mode penyebaran yang mencakup berbagai...
"""