MaxCompute mendukung penulisan data real-time dan pembaruan kunci primer dalam hitungan menit menggunakan tabel Delta, sehingga mengurangi latensi dari ingesti data hingga ketersediaan kueri menjadi 5–10 menit.
Pipeline batch tradisional hanya menampilkan data pada hari berikutnya, yang terlalu lambat untuk event sensitif waktu seperti log perilaku pelanggan, komentar, peringkat, atau like seputar konten viral. Ingesti near-real-time menyinkronkan data inkremental ke tabel Delta dalam hitungan menit. Jika Anda sudah memiliki task produksi yang menulis ke lapisan gudang data operasional (ODS) di MaxCompute, Anda dapat memanfaatkan fitur UPSERT tabel Delta untuk mengingesti data tanpa mengubah task tersebut. UPSERT mencegah catatan duplikat, meningkatkan efisiensi penyimpanan, serta mengurangi biaya penyimpanan.
Cara kerja ingesti near-real-time
Solusi ini menggunakan konektor Flink untuk menulis data streaming ke tabel Delta MaxCompute melalui sesi upsert yang dikelola oleh layanan tunnel.

Menulis data Flink ke tabel Delta
Konektor Flink menulis data ke tabel Delta MaxCompute melalui proses enam langkah berikut.
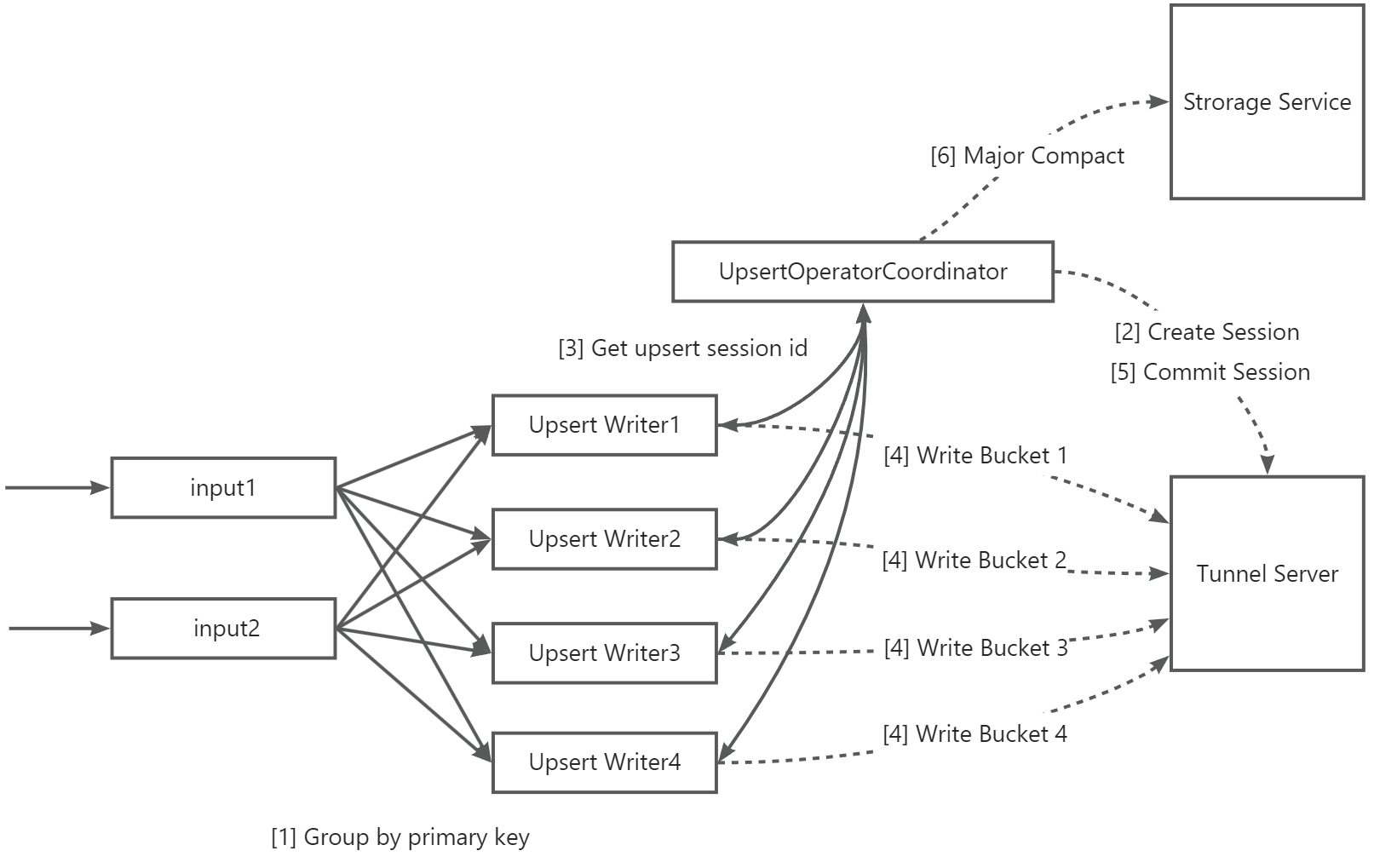
| Langkah | Deskripsi |
|---|---|
| 1 | Data dikelompokkan berdasarkan kunci primer dan ditulis secara konkuren ke tabel. Sebagai alternatif, kelompokkan data berdasarkan kolom kunci partisi ketika: data ditulis secara konkuren ke sejumlah besar partisi, data terdistribusi merata di seluruh partisi, dan tabel memiliki kurang dari 10 bucket. |
| 2 | UpsertWriterTask mengurai partisi tempat data tersebut berada dan mengirim permintaan ke UpsertOperatorCoordinator. UpsertOperatorCoordinator membuat sesi upsert untuk penulisan real-time ke partisi-partisi tersebut. |
| 3 | UpsertOperatorCoordinator mengembalikan ID sesi upsert ke UpsertWriterTask. |
| 4 | UpsertWriterTask membuat Upsert Writer berdasarkan sesi tersebut dan terhubung ke MaxCompute Tunnel Server untuk terus-menerus menulis data. Dalam mode cache file, data dibuffer ke disk lokal node Flink dan dikirim ke Tunnel Server ketika ukuran file mencapai ambang batas atau checkpoint dimulai. |
| 5 | Ketika checkpoint dimulai, Upsert Writer mengirimkan semua data ke Tunnel Server dan memicu commit. Data menjadi terlihat setelah commit berhasil. |
| 6 | Jika kompaksi mayor otomatis diaktifkan, UpsertOperatorCoordinator memulai operasi kompaksi mayor ke Storage Service ketika jumlah commit partisi melebihi ambang batas. Peringatan
Kompaksi mayor dapat meningkatkan latensi untuk impor data real-time tergantung pada ukuran data tabel. Gunakan kompaksi mayor otomatis dengan hati-hati. |
Untuk panduan lengkap, lihat Gunakan Flink untuk menulis data ke tabel Delta.
Optimalkan parameter UPSERT untuk throughput
Parameter UPSERT default sesuai untuk sebagian besar beban kerja, tetapi Anda dapat menyesuaikannya untuk mencapai target throughput tertentu atau menstabilkan kinerja saat jumlah partisi tinggi. Untuk daftar lengkap parameter, lihat Parameter untuk pernyataan UPSERT.
Dasar: bucket dan paralelisme sink
Dua parameter menentukan batas throughput maksimum Anda:
-
Jumlah bucket: Estimasi throughput tulis maksimum adalah 1 MB/detik × jumlah bucket. Atur nilai ini berdasarkan laju ingesti berkelanjutan Anda.
-
`sink.parallelism`: Atur nilai ini sama dengan jumlah bucket untuk kinerja optimal. Minimal, jumlah bucket harus merupakan kelipatan bulat dari
sink.parallelism.
Jumlah bucket yang dialokasikan untuk setiap node sink adalah: jumlah bucket ÷ sink.parallelism.
Tabel non-partisi
Kapan digunakan: Data Anda tidak memiliki kolom kunci partisi, atau Anda menulis ke satu partisi logis.
Jika peningkatan sink.parallelism tidak meningkatkan throughput, bottleneck kemungkinan berada di hulu node sink. Optimalkan pipeline pemrosesan data hulu terlebih dahulu.
Jika upsert.writer.buffer-size ÷ buckets-per-sink-node turun di bawah 128 KB, efisiensi transmisi jaringan menurun. Tingkatkan upsert.writer.buffer-size untuk memulihkan kinerja.
Untuk meningkatkan throughput, naikkan upsert.flush.concurrent (default: 2). Pantau kinerja saat menaikkan nilainya—nilai yang terlalu tinggi menyebabkan beberapa bucket melakukan flush secara bersamaan, yang mengakibatkan kemacetan jaringan dan penurunan throughput keseluruhan.
Partisi sedikit
Kapan digunakan: Anda menulis ke sejumlah kecil partisi secara konkuren.
Terapkan panduan untuk tabel non-partisi di atas, dan pertimbangkan juga:
-
Saat checkpoint, penulisan ke setiap partisi di-commit secara independen, yang dapat membatasi throughput keseluruhan.
-
Memori buffer maksimum per node sink adalah
upsert.writer.buffer-size × jumlah partisi. Jika terjadi error kehabisan memori (OOM), kurangiupsert.writer.buffer-size. -
Tingkatkan
upsert.commit.thread-num(default:16) untuk memparalelkan commit selama checkpoint. Jangan melebihi32—di atas ambang batas tersebut, masalah akibat konkurensi berlebihan justru menurunkan kinerja.
Banyak partisi (mode cache file)
Kapan digunakan: Anda menulis ke sejumlah besar partisi secara konkuren dan waktu commit checkpoint menjadi bottleneck.
Terapkan panduan untuk partisi sedikit di atas, dan pertimbangkan juga:
-
Data untuk setiap partisi di-cache ke file lokal dan ditulis ke MaxCompute secara konkuren selama checkpoint.
-
sink.file-cached.writer.num(default:16) mengontrol jumlah partisi yang ditulis secara konkuren oleh satu node sink. Jangan atur nilai ini di atas32. -
Jumlah efektif bucket tulis konkuren adalah
sink.file-cached.writer.num × upsert.flush.concurrent. Sesuaikan kedua parameter ini secara bersamaan, tetapi pastikan hasil perkaliannya cukup rendah untuk menghindari kemacetan jaringan.
Untuk daftar lengkap parameter mode cache file, lihat Parameter untuk penulisan data dalam mode cache file.
Referensi parameter utama
| Parameter | Default | Maksimum yang direkomendasikan | Deskripsi |
|---|---|---|---|
sink.parallelism |
— | — | Paralelisme node sink; atur sama dengan jumlah bucket |
upsert.writer.buffer-size |
— | — | Ukuran buffer per bucket; tingkatkan jika throughput turun di bawah 128 KB per bucket |
upsert.flush.concurrent |
2 | — | Jumlah bucket yang melakukan flush secara konkuren; tingkatkan secara bertahap dan pantau kemacetan jaringan |
upsert.commit.thread-num |
16 | 32 | Jumlah thread untuk commit partisi paralel selama checkpoint; di atas 32, masalah akibat konkurensi berlebihan mengurangi throughput |
sink.file-cached.writer.num |
16 | 32 | Jumlah writer partisi konkuren dalam mode cache file; di atas 32, kemacetan jaringan mengurangi throughput |
Saat penyesuaian tidak membantu
Jika target throughput masih belum tercapai setelah penyetelan:
-
Kuota kelompok sumber daya Tunnel publik untuk setiap Proyek memiliki batas maksimum. Ketika batas tersebut tercapai, penulisan ditolak, sehingga mengurangi throughput efektif. Beralihlah ke kelompok sumber daya Tunnel eksklusif atau kurangi konkurensi.
-
Pipeline pemrosesan data hulu yang memberi data ke konektor mungkin menjadi bottleneck. Profil dan optimalkan pipeline hulu tersebut.
Ketahanan dan penanganan error
Rancang pipeline Anda untuk menangani mode kegagalan berikut sebelum masuk ke produksi.
Checkpoint kedaluwarsa sebelum selesai
Error: Checkpoint xxx expired before completing
Terlalu banyak partisi ditulis selama satu interval checkpoint, sehingga fase commit melebihi timeout checkpoint.
Untuk mengatasinya:
-
Tingkatkan interval checkpoint Flink agar fase commit memiliki lebih banyak waktu untuk menyelesaikan.
-
Aktifkan mode cache file dengan mengatur
sink.file-cached.enableketrue.
Untuk parameter mode cache file, lihat Lampiran: Parameter konektor Flink versi baru.
OperatorEvent hilang, failover task dipicu
Error: org.apache.flink.util.FlinkException: An OperatorEvent from an OperatorCoordinator to a task was lost. Triggering task failover to ensure consistency.
Komunikasi antara JobManager dan TaskManager terputus. Task akan mencoba ulang secara otomatis. Jika hal ini terus berulang, tingkatkan sumber daya task untuk menstabilkan koneksi.
Offset timestamp delapan jam setelah menulis data TIMESTAMP
Tipe TIMESTAMP Flink tidak membawa informasi zona waktu. MaxCompute memperlakukan nilai TIMESTAMP masuk sebagai UTC+0, lalu mengonversinya ke zona waktu yang dikonfigurasi Proyek saat membaca—menghasilkan offset tampak delapan jam untuk Proyek UTC+8.
Ganti kolom TIMESTAMP di tabel sink MaxCompute Anda dengan TIMESTAMP_LTZ. TIMESTAMP_LTZ membawa konteks zona waktu sepanjang pipeline, sehingga tidak terjadi offset konversi saat pembacaan.
Error Tengine saat penulisan data
Error: Halaman HTML dari Tengine dengan Sorry, the page you are looking for is currently unavailable.
Layanan Tunnel sementara tidak tersedia. Tunggu hingga layanan pulih—task Flink akan mencoba ulang secara otomatis dan melanjutkan penulisan begitu Tunnel dipulihkan.
SlotExceeded: kuota tulis terlampaui
Error: java.io.IOException: RequestId=xxxxxx, ErrorCode=SlotExceeded, ErrorMessage=Your slot quota is exceeded.
Jumlah slot tulis konkuren telah melebihi kuota Proyek. Kurangi konkurensi tulis (turunkan sink.parallelism) atau tingkatkan paralelisme kelompok sumber daya Tunnel eksklusif untuk memperluas kuota yang tersedia.