Alur kerja batch MaxCompute tradisional mengimpor data inkremental dalam hitungan jam atau hari dan memerlukan pekerjaan penggabungan ETL yang kompleks—mengakibatkan latensi tinggi, biaya penyimpanan tinggi, dan pemeliharaan yang sulit. Arsitektur terintegrasi untuk penyimpanan dan pemrosesan data penuh serta inkremental near real-time mengatasi hal ini dengan memperkenalkan tabel Delta: format tabel terpadu yang mendukung upsert berbasis kunci primer, kueri perjalanan waktu (time travel), dan tata kelola data otomatis dalam satu sistem terkelola penuh. Anda dapat mengurangi latensi data end-to-end dari hitungan jam atau hari menjadi 5–10 menit tanpa menjalankan pipeline ETL terpisah.
Latar Belakang
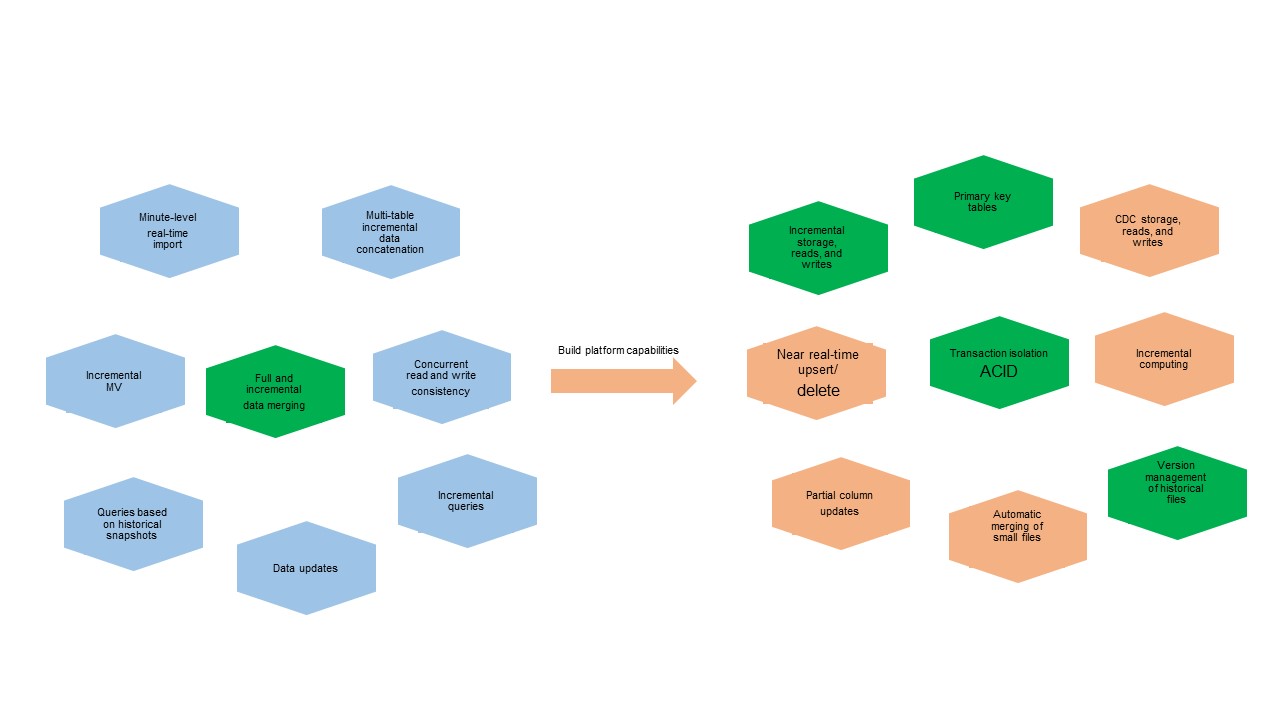
Seiring meningkatnya volume data dan semakin menuntutnya skenario bisnis, impor data near real-time memerlukan mesin platform dengan isolasi transaksi dan penggabungan file kecil otomatis. Penggabungan data penuh dan inkremental memerlukan kemampuan untuk menyimpan, membaca, dan menulis data inkremental menggunakan kunci primer.
Sebelum adanya arsitektur terintegrasi ini, tiga solusi sebelumnya telah mengatasi kebutuhan tersebut, masing-masing dengan kompromi dalam hal biaya, kemudahan penggunaan, latensi, dan throughput:
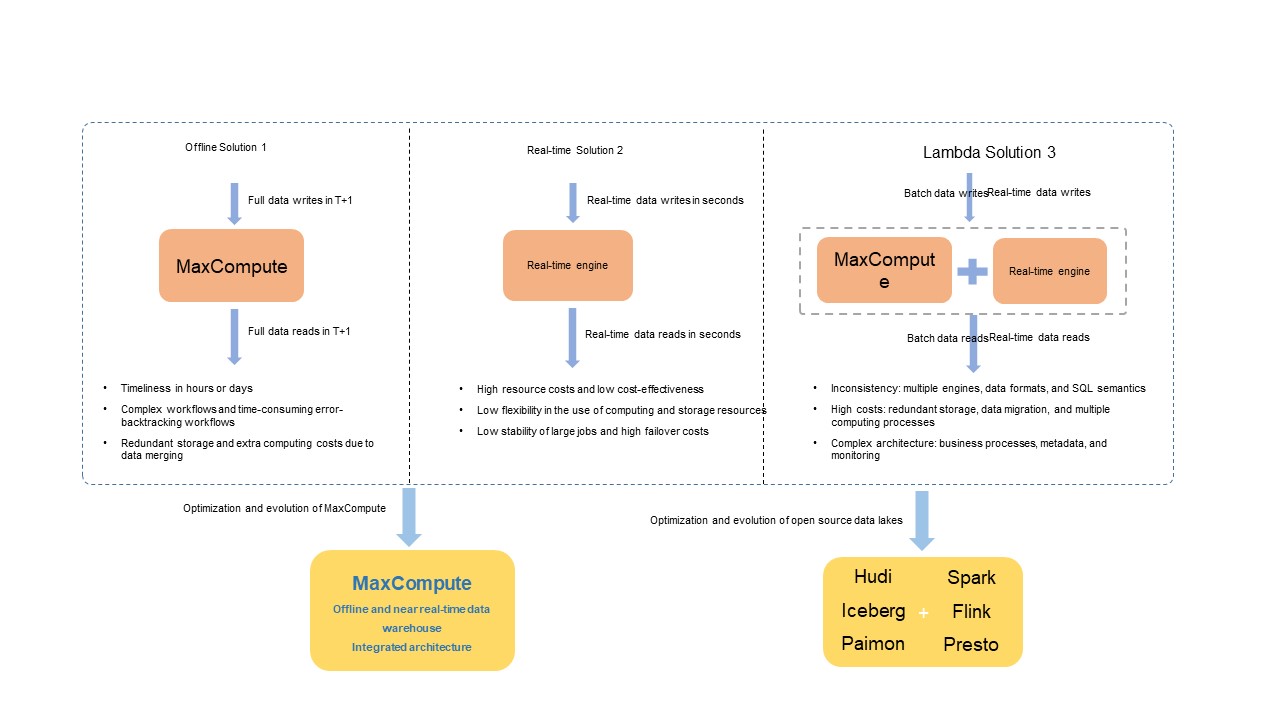
Dalam ekosistem open-source, mesin seperti Spark, Flink, dan Trino—yang diintegrasikan dengan format data lake seperti Apache Hudi, Delta Lake, Apache Iceberg, dan Apache Paimon—menyelesaikan isu serupa dalam arsitektur Lambda dengan menggabungkan mesin komputasi terbuka dan penyimpanan data terpadu.
Arsitektur terintegrasi untuk penyimpanan dan pemrosesan data penuh serta inkremental near real-time
Arsitektur terintegrasi MaxCompute mendukung berbagai sumber data. Anda dapat mengimpor data penuh dan inkremental ke layanan penyimpanan khusus menggunakan alat pengembangan kustom. Layanan manajemen data backend secara otomatis mengoptimalkan dan mengatur struktur penyimpanan data. Mesin komputasi terpadu menangani pemrosesan data inkremental near real-time maupun batch. Layanan metadata terpadu mengelola metadata transaksi dan file.
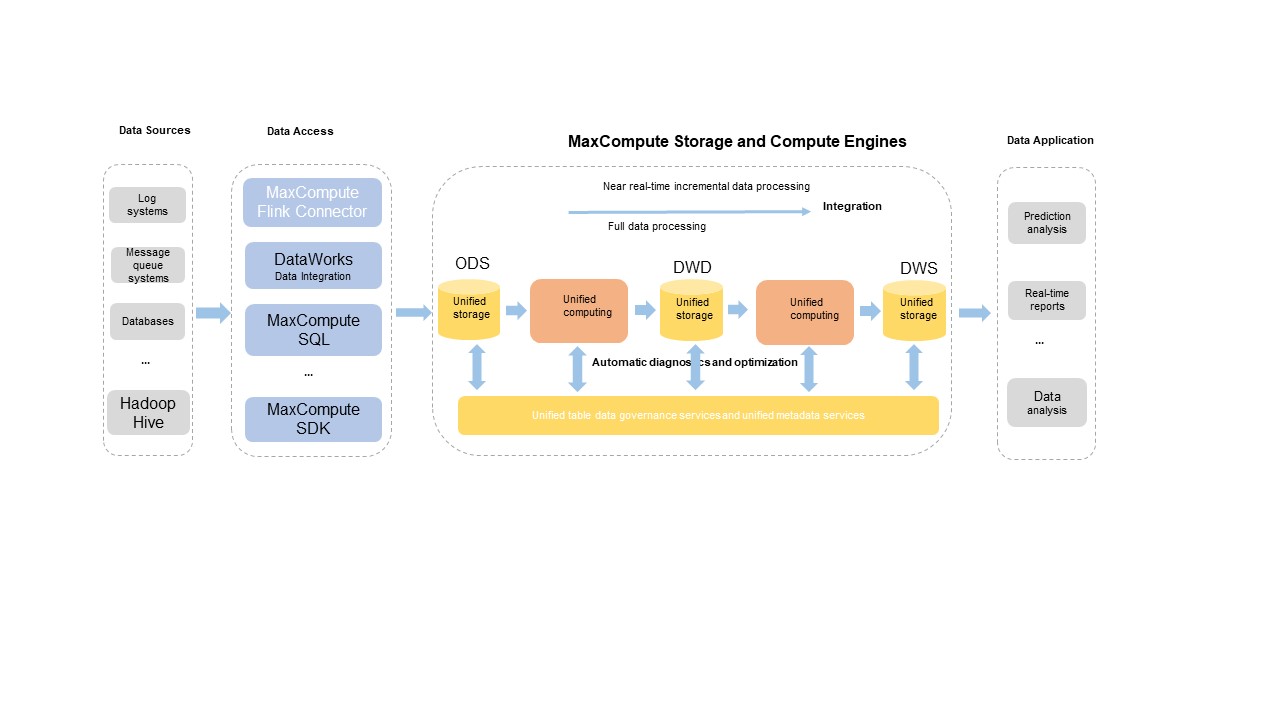
Arsitektur ini mendukung kemampuan inti berikut:
-
Tabel kunci utama
-
Upsert real-time
-
Kueri perjalanan waktu (time travel)
-
Kueri inkremental
-
Operasi bahasa manipulasi data (DML) SQL
-
Tata kelola dan optimasi otomatis data tabel
Untuk detail cara kerja arsitektur dan operasi terkait, lihat Ikhtisar Delta Table dan Operasi dasar.
Manfaat arsitektur
Arsitektur terintegrasi ini mendukung fitur utama umum dari format data lake open-source seperti Apache Hudi dan Apache Iceberg untuk mempermudah migrasi antar proses bisnis. Sebagai arsitektur native platform yang dikembangkan oleh Alibaba Cloud, arsitektur ini juga memberikan keunggulan berikut:
| Keunggulan | Deskripsi |
|---|---|
| Integrasi terpadu | Menggunakan layanan penyimpanan, layanan metadata, dan mesin komputasi terpadu untuk integrasi yang mendalam dan efisien—memberikan penyimpanan hemat biaya, manajemen file efisien, efisiensi kueri tinggi, dan kueri perjalanan waktu pada data inkremental. |
| Sintaksis SQL lengkap | Menyediakan sistem sintaksis SQL serbaguna yang dirancang untuk mendukung semua fitur inti. |
| Alat impor data teroptimalkan | Menyediakan alat yang sangat disesuaikan untuk impor data dalam skenario bisnis kompleks. |
| Kompatibilitas mulus | Terintegrasi dengan skenario bisnis MaxCompute yang sudah ada tanpa memerlukan migrasi data atau biaya tambahan untuk penyimpanan dan komputasi. |
| Manajemen file otomatis | Mencapai manajemen file sepenuhnya otomatis untuk stabilitas dan performa operasi baca-tulis yang lebih tinggi, dengan optimasi efisiensi penyimpanan otomatis. |
| Terkelola penuh, tanpa konfigurasi | Berdasarkan layanan terkelola penuh MaxCompute—langsung tersedia tanpa biaya akses tambahan. Buat Delta table dan arsitektur langsung berlaku. |
| Jadwal pengembangan otonom | Memelihara jadwal pengembangan yang otonom dan terkendali. |
Skenario bisnis
Format tabel dan tata kelola data
Pembuatan tabel

MaxCompute memperkenalkan Delta tables dengan format data tabel terpadu untuk mendukung arsitektur terintegrasi. Delta tables mendukung semua fitur alur kerja pemrosesan batch yang ada serta alur kerja baru seperti penyimpanan dan pemrosesan data inkremental near real-time.
Untuk membuat Delta table, tentukan kunci primer dan atur "transactional"="true" dalam pernyataan CREATE TABLE:
CREATE TABLE tt2 (pk BIGINT NOT NULL PRIMARY KEY, val STRING) tblproperties ("transactional"="true");
CREATE TABLE par_tt2 (pk BIGINT NOT NULL PRIMARY KEY, val STRING) PARTITIONED BY (pt STRING) tblproperties ("transactional"="true");Kunci primer menjamin keunikan baris. Properti transactional mengaktifkan mekanisme transaksi ACID (atomicity, consistency, isolation, dan durability) dengan isolasi snapshot untuk operasi baca dan tulis. Untuk detail lebih lanjut, lihat Operasi tabel.
Parameter kunci untuk Delta tables
Untuk referensi parameter lengkap, lihat bagian "Parameter untuk Delta tables" dalam Operasi tabel.
write.bucket.num
Menentukan jumlah bucket per tabel partisi atau non-partisi, serta jumlah node penulisan konkuren. Nilai default adalah 16. Nilai valid: (0, 4096].
-
Untuk tabel partisi: nilai dapat diubah dan secara otomatis berlaku untuk partisi baru.
-
Untuk tabel non-partisi: nilai tidak dapat diubah setelah pembuatan.
Lebih banyak bucket meningkatkan paralelisme penulisan dan kueri, tetapi juga menghasilkan lebih banyak file kecil—meningkatkan biaya penyimpanan dan mengurangi efisiensi baca. Ikuti panduan berikut saat menentukan ukuran bucket:
| Skenario | Rekomendasi |
|---|---|
| Data < 1 GB (non-partisi atau partisi) | 4–16 bucket |
| Data > 1 GB | Pertahankan setiap bucket antara 128 MB–256 MB |
| Data > 1 TB | Pertahankan setiap bucket antara 500 MB–1 GB |
| Tabel partisi dengan > 500 partisi, masing-masing berisi puluhan MB | 1–2 bucket per partisi untuk menghindari pembengkakan file kecil |
acid.data.retain.hours
Menentukan rentang waktu data historis yang tersedia untuk kueri perjalanan waktu. Nilai default adalah 24. Nilai valid: [0, 168] (satuan: jam).
-
Atur ke
0untuk menonaktifkan kueri perjalanan waktu dan secara signifikan mengurangi biaya penyimpanan data historis. -
Untuk data historis yang lebih tua dari 168 jam (7 hari), hubungi dukungan teknis MaxCompute.
Tetapkan periode retensi yang sesuai dengan kebutuhan bisnis Anda. Periode retensi yang lebih lama meningkatkan biaya penyimpanan dan dapat memperlambat kueri. Setelah periode retensi berakhir, sistem secara otomatis mereklamasi dan membersihkan data historis, termasuk log operasi dan file data—setelah itu Anda tidak dapat lagi mengkueri data tersebut melalui perjalanan waktu. Untuk membersihkan data historis secara paksa sebelum periode berakhir, jalankan perintah purge.
Evolusi skema
Delta tables mendukung evolusi skema lengkap, termasuk penambahan dan penghapusan kolom. Saat mengkueri data historis dengan perjalanan waktu, sistem membaca data berdasarkan skema pada versi historis tersebut.
Kunci primer tidak dapat dimodifikasi.
Contoh berikut menambahkan kolom:
ALTER TABLE tt2 ADD columns (val2 string);Untuk sintaksis DDL lengkap, lihat Operasi tabel.
Format data tabel
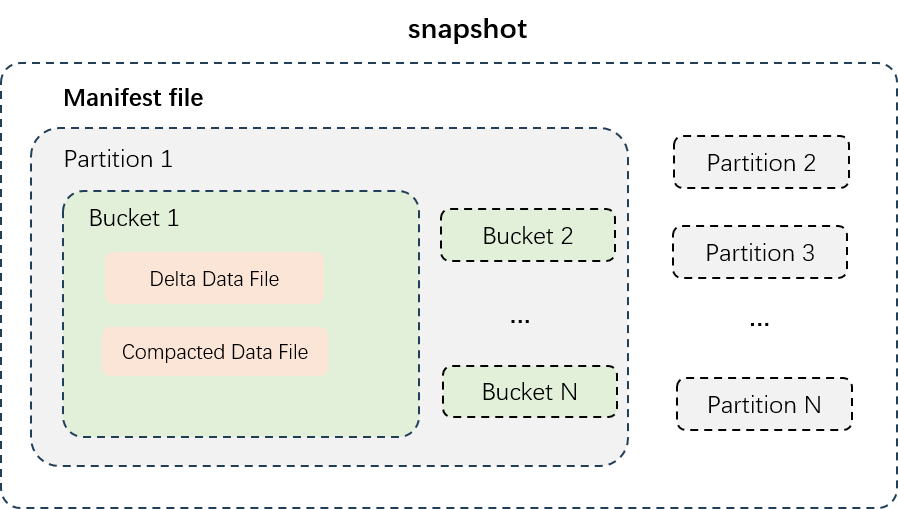
Gambar di atas menunjukkan struktur data tabel partisi. File data secara fisik diisolasi berdasarkan partisi (disimpan dalam direktori terpisah), dan data setiap partisi dibagi menjadi bucket. Delta tables menggunakan dua jenis file data:
| Jenis file | Deskripsi | Format penyimpanan | Paling cocok untuk |
|---|---|---|---|
| File data delta | Data inkremental yang dihasilkan setelah setiap penulisan transaksi atau penggabungan file kecil. Menyimpan data historis antara semua baris untuk mendukung baca-tulis near real-time. | Berorientasi baris (Avro) | Ingesti near real-time; perjalanan waktu pada versi terbaru |
| File data compacted | Dihasilkan setelah file delta dikompaksi. Hanya menyimpan catatan terbaru per kunci primer—tanpa riwayat antara. Dioptimalkan untuk kueri cepat. | Berorientasi kolom (AliORC) | Kueri analitis; pembacaan batch throughput tinggi |
Tata kelola dan optimasi data otomatis
Masalah: pembengkakan file kecil
Delta tables mendukung impor data inkremental near real-time dalam hitungan menit. Dalam skenario penulisan bertrafik tinggi dengan banyak bucket, jumlah file data inkremental kecil dapat meningkat pesat, menyebabkan permintaan akses berlebihan, biaya tinggi, dan efisiensi I/O rendah. Operasi UPDATE dan DELETE intensif semakin memperparah masalah ini dengan menghasilkan banyak catatan historis antara yang redundan.
Solusi: empat layanan tata kelola otomatis
Mesin penyimpanan MaxCompute secara otomatis mengelola dan mengoptimalkan data yang disimpan tanpa konfigurasi manual. Mesin penyimpanan secara cerdas mengidentifikasi karakteristik data di berbagai dimensi dan menerapkan kebijakan secara otomatis.
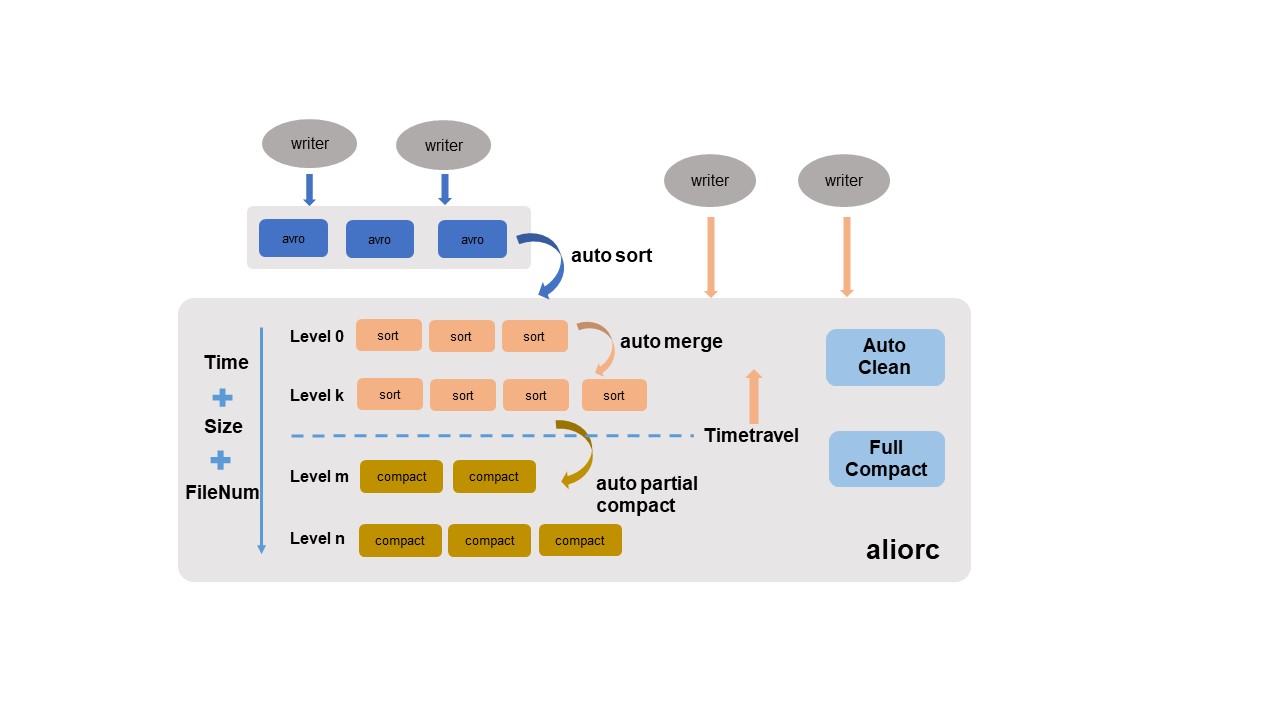
| Layanan | Fungsinya |
|---|---|
| Auto sort | Mengonversi file Avro berorientasi baris yang ditulis secara real time menjadi file AliORC berorientasi kolom. Mengurangi biaya penyimpanan dan meningkatkan performa baca. |
| Auto merge | Menggabungkan file kecil secara berkala, menganalisis ukuran file, jumlah, dan deret waktu penulisan, lalu menggabungkan berdasarkan level. Data historis antara dipertahankan untuk menjaga integritas perjalanan waktu. |
| Auto partial compact | Menggabungkan file dan membersihkan catatan historis yang berada di luar jendela retensi perjalanan waktu. Mengurangi biaya penyimpanan akibat beban kerja UPDATE/DELETE intensif dan meningkatkan efisiensi baca. |
| Auto clean | Menghapus file asli setelah auto sort, auto merge, atau auto partial compact menghasilkan file pengganti baru. Membebaskan ruang penyimpanan secara real time. |
Auto partial compact hanya membersihkan catatan historis yang waktu pembuatannya berada di luar jendela retensi perjalanan waktu.
Untuk skenario yang memerlukan performa kueri puncak, picu kompaksi mayor secara manual:
SET odps.merge.task.mode=service;
ALTER TABLE tt2 compact major;Kompaksi mayor mengonsolidasi semua data dalam setiap bucket, membersihkan semua data historis, dan menghasilkan file AliORC berorientasi kolom. Ini menimbulkan overhead eksekusi tambahan dan meningkatkan biaya penyimpanan file baru. Gunakan hanya bila diperlukan.
Untuk informasi lebih lanjut, lihat COMPACTION.
Penulisan data
Upsert near real-time dalam hitungan menit
Mengapa Delta tables: Pemrosesan batch tradisional mengimpor data inkremental ke tabel atau partisi baru dalam hitungan jam atau hari, lalu memicu proses ETL offline untuk menggabungkan data inkremental tersebut dengan data tabel yang ada. Hal ini memiliki latensi panjang serta biaya sumber daya dan penyimpanan tinggi.
Dengan Delta tables, pipeline upsert mempertahankan latensi 5 hingga 10 menit dari penulisan data hingga kueri. Tidak diperlukan proses penggabungan ETL yang kompleks, sehingga mengurangi biaya komputasi dan penyimpanan.
Berbagai sumber data umum digunakan di sistem produksi—database, sistem log, antrian pesan. MaxCompute menyediakan plugin konektor Flink open-source yang bekerja dengan DataWorks Data Integration dan alat impor data lainnya. Plugin ini mendukung desain dan pengembangan kustom yang dioptimalkan untuk konkurensi tinggi, toleransi kesalahan, dan skenario pengiriman transaksi.
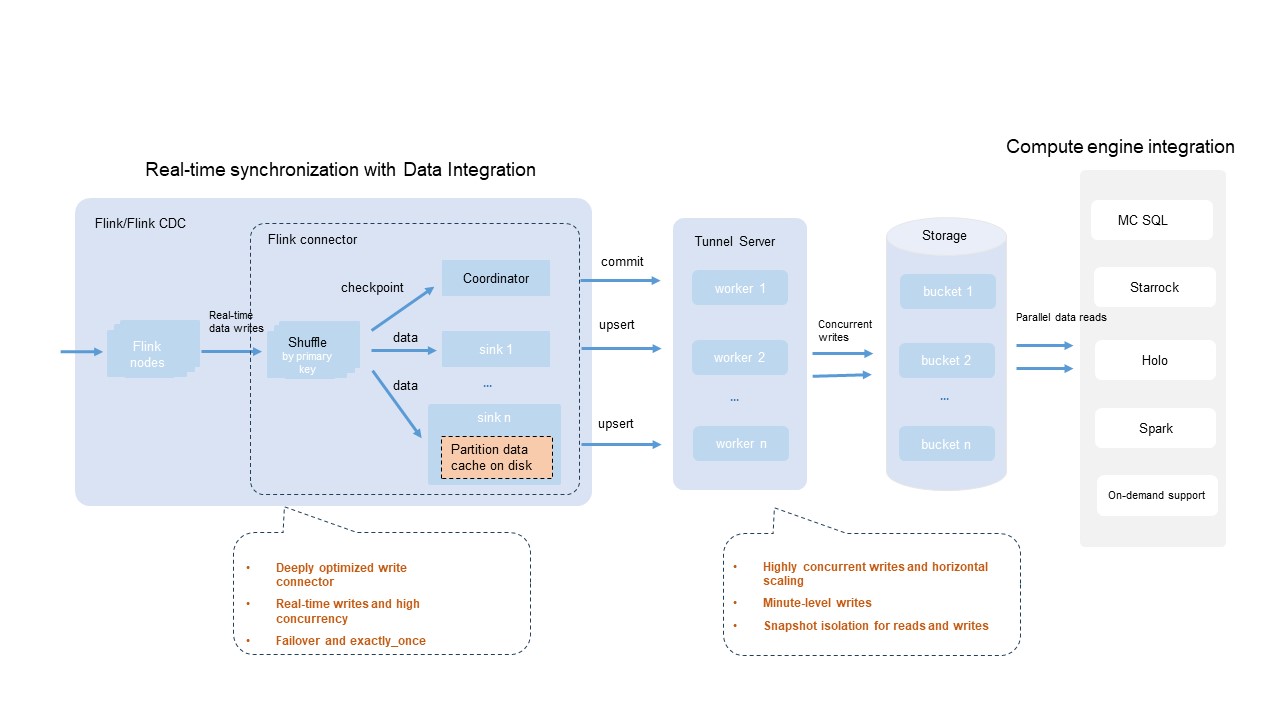
Kemampuan utama integrasi konektor Flink:
| Kemampuan | Deskripsi |
|---|---|
| Kompatibilitas Mesin yang Luas | Sebagian besar mesin komputasi dan alat yang kompatibel dengan ekosistem Flink mendukung penerapan Flink yang menggunakan konektor Flink MaxCompute untuk menulis data ke Delta tables secara real time. |
| Paralelisme penulisan yang dapat dikonfigurasi | Sesuaikan parameter write.bucket.num untuk menyetel paralelisme penulisan. Untuk performa penulisan terbaik, atur write.bucket.num ke kelipatan integer dari paralelisme sink Flink. |
| Semantik tepat-sekali (exactly-once semantics) | Menggunakan mekanisme checkpoint bawaan Flink untuk toleransi kesalahan, memastikan pemrosesan data mengikuti semantik tepat-sekali. |
| Penulisan partisi skala besar | Mendukung penulisan ke ribuan partisi secara simultan. |
| Visibilitas near real-time | Data terlihat dalam hitungan menit, dengan isolasi snapshot untuk operasi baca dan tulis. |
Throughput trafik bervariasi tergantung lingkungan dan konfigurasi. Perkirakan throughput maksimum berdasarkan kapasitas pemrosesan satu bucket (1 MB/detik). Grup sumber daya Tunnel bersama digunakan secara default untuk MaxCompute Tunnel, yang dapat menyebabkan throughput tidak stabil di bawah konflik sumber daya berat. Batasan juga diterapkan pada konsumsi sumber daya.
Sinkronisasi data real-time dari database menggunakan DataWorks Data Integration
Banyak sistem produksi menggabungkan pemrosesan transaksi online (OLTP), pemrosesan analitis online (OLAP), dan mesin analisis offline. Alur kerja umum adalah menyinkronkan catatan baru dari satu tabel atau seluruh database ke MaxCompute secara real time untuk analisis.
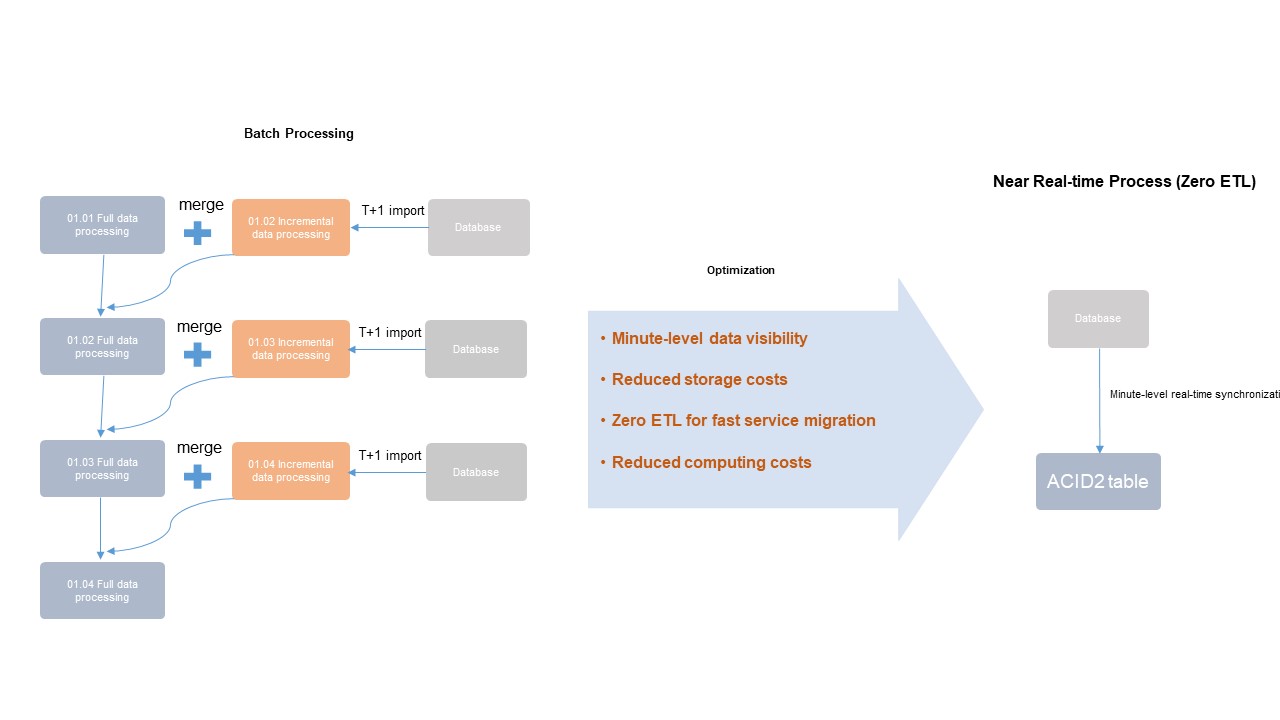
Gambar di atas membandingkan dua pendekatan:
-
Kiri (pemrosesan batch): Data inkremental diimpor ke tabel atau partisi baru dalam hitungan jam atau hari. Proses ETL offline kemudian menggabungkan data inkremental tersebut dengan data tabel yang ada. Hal ini memiliki latensi tinggi serta biaya sumber daya dan penyimpanan tinggi.
-
Kanan (arsitektur terintegrasi): Catatan baru dibaca dari database dalam hitungan menit. Tidak diperlukan ekstraksi atau penggabungan data periodik—Delta tables menangani pembaruan secara langsung, meminimalkan biaya komputasi dan penyimpanan.
Pemrosesan batch menggunakan pernyataan DML SQL dan upsert
Modul Compiler, Optimizer, dan Runtime mesin SQL dimodifikasi dan dioptimalkan untuk operasi Delta table. Ini mencakup penguraian sintaksis, rencana optimasi, logika deduplikasi berbasis kunci primer, dan upsert waktu proses untuk menyediakan dukungan sintaksis SQL lengkap.
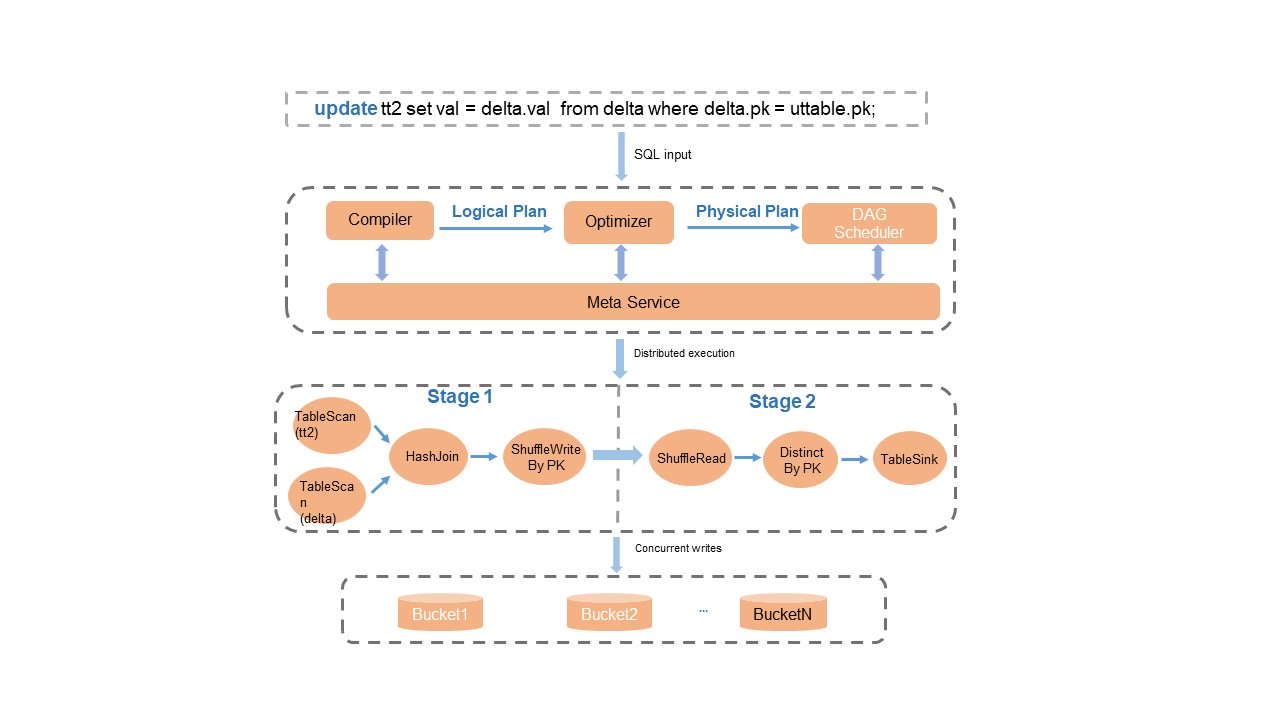
Perilaku utama:
-
Konsistensi transaksi: Setelah pemrosesan data selesai, layanan metadata melakukan deteksi konflik transaksi dan pembaruan metadata atomik, memastikan isolasi baca/tulis dan konsistensi transaksi.
-
Upsert yang disederhanakan: Sistem secara otomatis menggabungkan catatan berdasarkan kunci primer selama kueri pada Delta tables. Untuk skenario yang menggabungkan operasi INSERT dan UPDATE, gunakan
INSERT INTOdaripada sintaksisUPDATEatauMERGE INTOyang kompleks—hal ini mengurangi I/O baca dan menghemat sumber daya komputasi.
Untuk sintaksis DML SQL lengkap, lihat Operasi DML.
Kueri data
Kueri perjalanan waktu (time travel queries)
Kueri perjalanan waktu memungkinkan Anda mengkueri versi historis Delta table. Kasus penggunaan umum meliputi:
-
Pemulihan data: Mengembalikan data ke versi historis tertentu setelah modifikasi atau penghapusan tidak disengaja.
-
Pelacakan historis: Mengecek atau menganalisis ulang data bisnis dari titik waktu tertentu di masa lalu.
Contoh kueri:
-- Kueri data historis pada timestamp tertentu.
SELECT * FROM tt2 TIMESTAMP AS OF '2024-04-01 01:00:00';
-- Kueri data historis dari 5 menit sebelum waktu saat ini.
SELECT * FROM tt2 TIMESTAMP AS OF CURRENT_TIMESTAMP() - 300;
-- Kueri data historis dari commit kedua terakhir.
SELECT * FROM tt2 TIMESTAMP AS OF GET_LATEST_TIMESTAMP('tt2', 2);Gambar berikut menunjukkan cara kerja kueri perjalanan waktu:
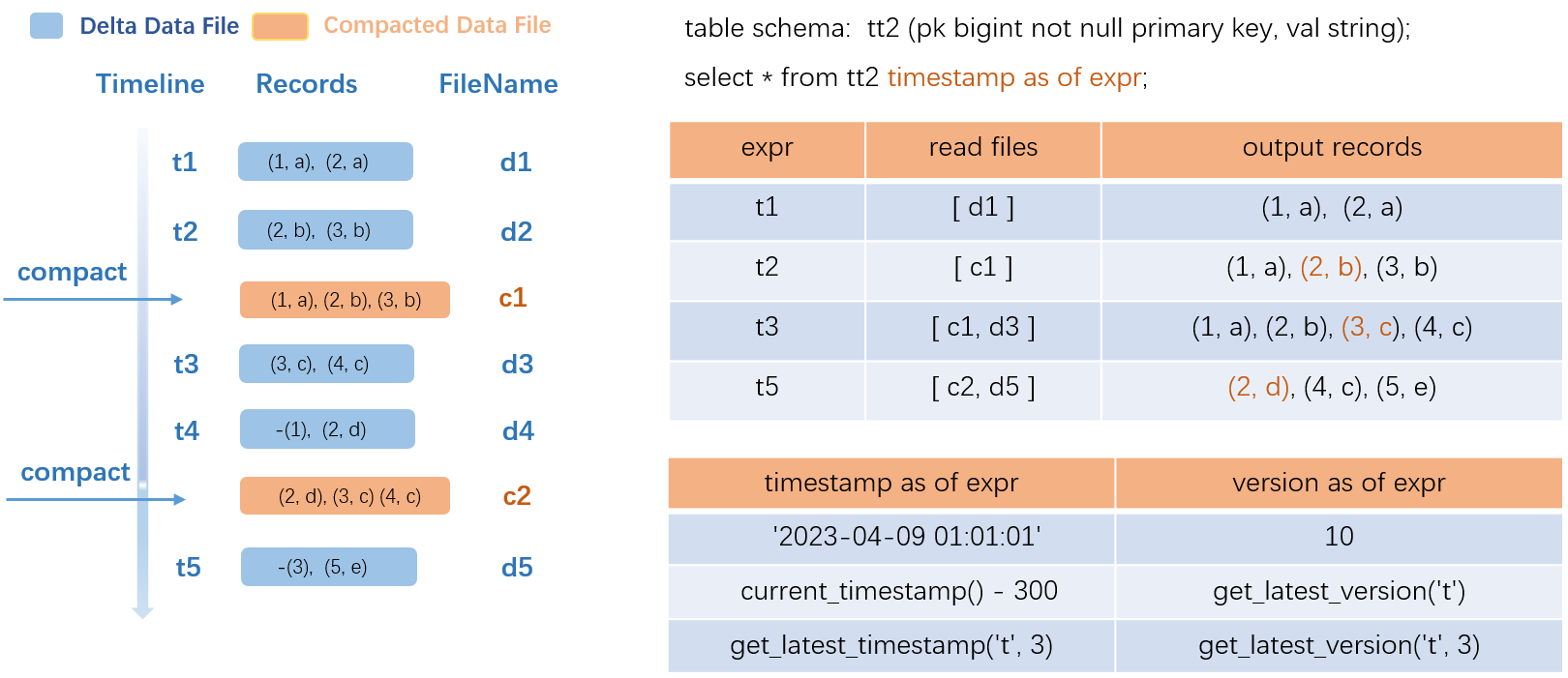
Contoh menggunakan tabel transaksional bernama src:
-
Sisi kiri (proses pembaruan data): Transaksi t1 hingga t5 masing-masing menghasilkan file data delta. COMPACTION dijalankan pada t2 dan t4, menghasilkan file compacted c1 dan c2. Di c1, catatan historis antara
(2,a)dihapus dan catatan terbaru(2,b)dipertahankan. -
Resolusi kueri: Untuk mengkueri data historis pada t1, sistem hanya membaca file delta d1. Untuk mengkueri pada t2, sistem membaca file compacted c1 dan mengembalikan tiga catatan. Untuk mengkueri pada t3, sistem membaca c1 dan file delta d3, lalu menggabungkannya untuk output. COMPACTION yang lebih sering mempercepat kueri tetapi meningkatkan overhead operasional—pilih kebijakan pemicu berdasarkan kebutuhan Anda.
Sintaksis SQL mendukung konstanta, fungsi umum, serta klausa TIMESTAMP AS OF expr dan VERSION AS OF expr untuk kueri historis yang presisi. Untuk detailnya, lihat Kueri perjalanan waktu.
Kueri inkremental
MaxCompute merancang dan mengembangkan sintaksis kueri inkremental SQL baru untuk mengoptimalkan kueri inkremental dan komputasi inkremental untuk Delta tables. Setelah Anda mengirimkan pernyataan kueri inkremental SQL, mesin MaxCompute mengurai versi data inkremental historis yang akan dikueri, mengambil file data compacted yang relevan, menggabungkan data file, dan mengembalikan output.
Gambar berikut menunjukkan proses kueri inkremental:

Contoh menggunakan tabel transaksional yang sama src dengan transaksi t1 hingga t5 dan file compacted c1 (pada t2) dan c2 (pada t4):
-
Jika
beginadalah t1-1 danendadalah t1, sistem hanya membaca file delta d1 pada t1. -
Jika
endadalah t2, sistem membaca file delta d1 dan d2. -
Jika
beginadalah t1 danendadalah t2-1, rentang kueri mencakup t1 hingga t2. Tidak ada data inkremental dalam rentang ini, sehingga baris kosong dikembalikan.
Data dalam file compacted c1 dan c2 yang dihasilkan oleh COMPACTION tidak dianggap sebagai data baru untuk output kueri inkremental.
Untuk sintaksis kueri inkremental dan batasan parameternya, lihat bagian "Parameter dan batasan kueri inkremental" dalam Kueri perjalanan waktu dan kueri inkremental.
Pelewatan data berbasis kunci primer yang dioptimalkan
Distribusi data dan indeks Delta table dibangun berdasarkan nilai kolom kunci primer. Saat Anda mengkueri berdasarkan kunci primer, sistem melakukan penyaringan di beberapa level untuk secara signifikan mengurangi data yang dibaca—meningkatkan efisiensi kueri hingga ratusan hingga ribuan kali lipat.
Contoh: Tabel Delta berisi 100 juta catatan. Penyaringan berdasarkan satu nilai kunci primer mungkin hanya memerlukan pembacaan 10.000 catatan.
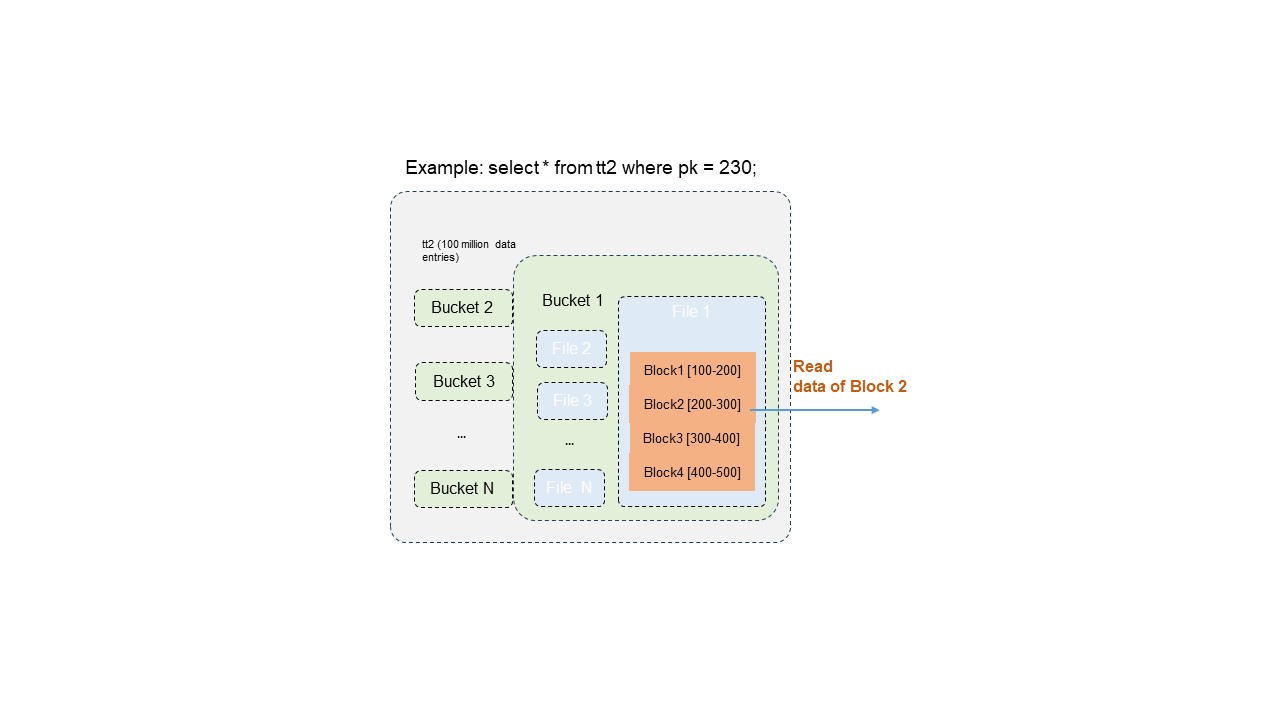
Proses penyaringan tiga level:
-
Pemangkasan bucket (bucket pruning): Menemukan bucket yang berisi kunci primer target, menghilangkan pemindaian semua bucket lainnya.
-
Pemangkasan file data (data file pruning): Di dalam bucket target, mengidentifikasi hanya file data yang berisi nilai kunci primer tersebut.
-
Penyaringan rentang level blok (block-level range filtering): Menerapkan penyaringan akurat berdasarkan distribusi nilai kunci primer di dalam blok file, mengekstraksi hanya blok yang berisi nilai target.
Rencana kueri dan analisis SQL yang dioptimalkan
Setiap bucket dalam Delta table menyimpan data yang unik dan diurutkan berdasarkan nilai kunci primer. Pengoptimal SQL memanfaatkan properti ini untuk menghilangkan operasi mahal:
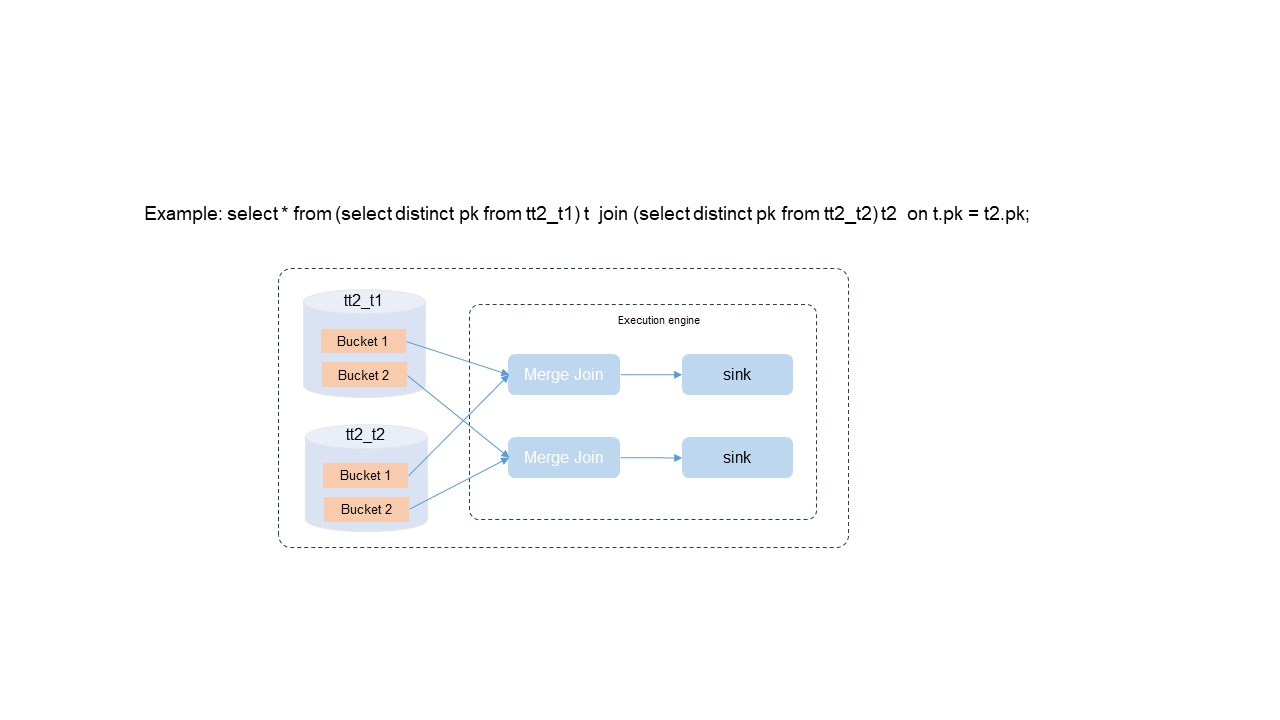
| Optimasi | Cara kerjanya | Manfaat |
|---|---|---|
| Eliminasi DISTINCT | Keunikan kunci primer menjamin tidak ada duplikat, sehingga pengoptimal melewati operasi DISTINCT sepenuhnya. | Menghilangkan overhead komputasi yang tidak perlu. |
| Bucket local join | Ketika kunci gabungan (join key) sesuai dengan kunci primer, pengoptimal memilih kebijakan join lokal bucket daripada shuffle global. | Mengurangi pertukaran data skala besar antar node, menurunkan konsumsi sumber daya dan meningkatkan throughput. |
| Merge join tanpa pengurutan | Data di setiap bucket sudah diurutkan berdasarkan kunci primer. Pengoptimal menggunakan algoritma merge join daripada melakukan pengurutan awal. | Menyederhanakan komputasi dan menghemat sumber daya komputasi. |
Setelah menghilangkan DISTINCT, pengurutan, dan shuffle global, performa kueri meningkat sebesar 100%.