Topik ini menjelaskan titik-titik masalah bisnis yang dapat diatasi oleh solusi gudang data hampir real-time serta fitur arsitektural utamanya.
Informasi latar belakang
Seiring dengan meningkatnya kompleksitas skenario pemrosesan data, tampilan data terbaru dalam hitungan detik atau pembaruan tingkat baris tidak diperlukan dalam banyak kasus. Sebagai gantinya, pemrosesan data hampir real-time dalam hitungan menit atau jam serta pemrosesan batch untuk sejumlah besar data menjadi kebutuhan utama. MaxCompute menyediakan tabel Delta untuk memenuhi kebutuhan penyimpanan dan pemrosesan data penuh maupun inkremental secara hampir real-time.
Analisis situasi saat ini
Dalam skenario bisnis berlatensi rendah yang memerlukan pemrosesan batch data dalam jumlah besar, Anda dapat menggunakan MaxCompute untuk memenuhi kebutuhan tersebut. Dalam skenario berlatensi tinggi yang memerlukan pemrosesan data real-time tingkat detik atau aliran (streaming), sistem pemrosesan data real-time atau aliran diperlukan. Namun, dalam skenario komprehensif seperti kombinasi pemrosesan data hampir real-time tingkat menit/jam dan pemrosesan batch data berskala besar, penggunaan satu mesin tunggal atau beberapa mesin federasi dapat menimbulkan masalah tertentu.

Masalah tertentu dapat muncul jika Anda hanya menggunakan MaxCompute untuk pemrosesan batch dalam skenario tertentu, seperti yang ditunjukkan pada gambar di atas. Misalnya, penggunaan MaxCompute dalam skenario di mana data inkremental tingkat menit dan data penuh perlu digabungkan dan disimpan secara terus-menerus akan menghasilkan biaya komputasi dan penyimpanan tambahan. Jika MaxCompute digunakan dalam skenario di mana logika pemrosesan data kompleks harus dikonversi menjadi pemrosesan batch harian (T+1), kompleksitas tautan pemrosesan meningkat dan latensi tidak dapat memenuhi kebutuhan bisnis. Di sisi lain, penggunaan sistem pemrosesan data real-time saja dalam skenario ini dapat menyebabkan biaya sumber daya tinggi, efisiensi biaya rendah, dan ketidakstabilan dalam pemrosesan batch data berskala besar. Dalam banyak kasus, arsitektur Lambda digunakan sebagai solusi. Arsitektur ini menggunakan MaxCompute untuk pemrosesan batch data penuh dan sistem pemrosesan data real-time untuk pemrosesan data inkremental guna memenuhi persyaratan latensi tinggi. Namun, arsitektur Lambda dapat menimbulkan masalah seperti ketidaksesuaian data antara beberapa set mesin pemrosesan dan penyimpanan, biaya tambahan akibat redundansi penyimpanan dan komputasi, arsitektur yang kompleks, serta siklus pengembangan yang panjang.
Untuk mengatasi masalah tersebut, ekosistem open source data besar meluncurkan berbagai solusi dalam beberapa tahun terakhir. Solusi yang paling populer adalah integrasi mendalam antara mesin pemrosesan data open source seperti Spark, Flink, atau Presto dengan danau data open source seperti Hudi, Delta Lake, dan Iceberg untuk menerapkan mesin komputasi terpadu dan penyimpanan data. Solusi ini membantu menyelesaikan serangkaian masalah yang disebabkan oleh arsitektur Lambda. Arsitektur penyimpanan dan pemrosesan data inkremental dikembangkan berdasarkan arsitektur MaxCompute. Arsitektur ini menyediakan solusi terpadu untuk pemrosesan data batch dan pemrosesan data inkremental hampir real-time, mempertahankan efisiensi biaya pemrosesan batch, serta memenuhi kebutuhan bisnis untuk pembacaan, penulisan, dan pemrosesan data inkremental tingkat menit. Arsitektur ini juga menyediakan fitur praktis seperti operasi UPSERT dan time travel, memperluas skenario bisnis, mengurangi biaya komputasi, penyimpanan, dan migrasi data, serta meningkatkan pengalaman pengguna.
Arsitektur hampir real-time MaxCompute
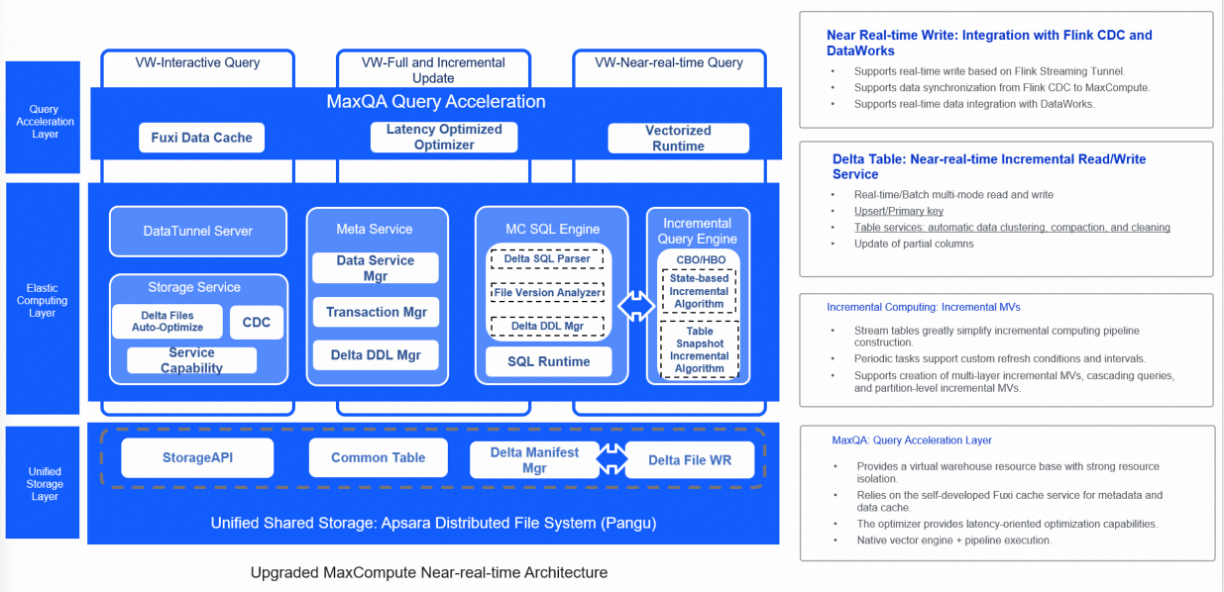
Gambar di atas menunjukkan arsitektur baru di mana MaxCompute mendukung skenario bisnis komprehensif secara efisien. Dalam arsitektur ini, MaxCompute mendukung berbagai sumber data untuk mengimpor data inkremental dan penuh ke sistem penyimpanan terpadu menggunakan alat akses khusus. Layanan manajemen data latar belakang secara otomatis mengoptimalkan struktur penyimpanan data. Mesin komputasi terpadu digunakan untuk mendukung pemrosesan data inkremental hampir real-time dan pemrosesan batch data berskala besar. Layanan metadata terpadu mendukung manajemen transaksi dan manajemen metadata file. Arsitektur baru ini memberikan beberapa manfaat, termasuk mengatasi masalah yang terjadi saat hanya menggunakan sistem pemrosesan batch, seperti redundansi komputasi dan penyimpanan serta latensi rendah; mencegah konsumsi sumber daya tinggi dari sistem pemrosesan data real-time atau aliran; menghilangkan ketidaksesuaian data antara beberapa sistem dalam arsitektur Lambda; serta mengurangi biaya penyimpanan redundan dan biaya migrasi data antar sistem.
Arsitektur terintegrasi ujung ke ujung ini memenuhi kebutuhan bisnis untuk optimasi komputasi dan penyimpanan pemrosesan data inkremental serta latensi tingkat menit, memastikan efisiensi keseluruhan pemrosesan batch, dan secara efektif mengurangi biaya sumber daya.
Fitur inti
Gudang data hampir real-time MaxCompute menyediakan tiga fungsi utama: Tabel MC Delta yang mendukung impor data tingkat menit, kemampuan komputasi inkremental yang lebih baik dalam menyeimbangkan latensi dan throughput, serta MCQA2.0 yang ditingkatkan untuk respons kueri tingkat detik.
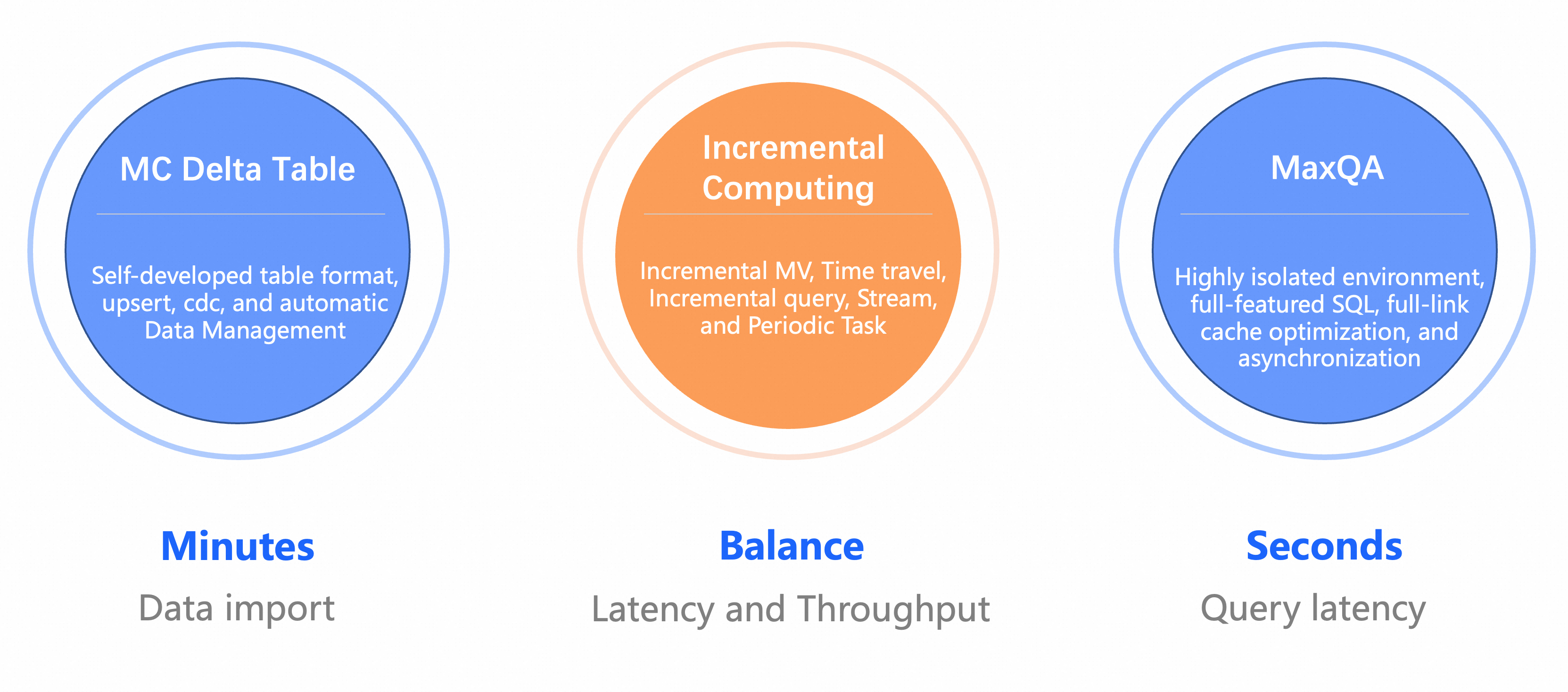
Ketiga fitur inti tersebut adalah sebagai berikut:
Format Tabel Delta: Mendukung impor data tingkat menit. Format tabel ini menggunakan AliORC sebagai format file dasar, mendukung semantik UPSERT, dan menyediakan metode CDC (Change Data Capture) standar untuk membaca dan menulis data inkremental. Format ini bergantung pada layanan penyimpanan MaxCompute dan layanan meta global untuk manajemen data otomatis.
Komputasi Inkremental: Berdasarkan format Tabel Delta, MaxCompute menambahkan serangkaian kemampuan komputasi inkremental seperti tampilan materialisasi inkremental, Time Travel, dan Stream Table. Selain itu, tampilan materialisasi inkremental dan tugas yang dijadwalkan secara berkala memberikan frekuensi pemicu yang berbeda, memberikan pengguna lebih banyak opsi untuk menyeimbangkan latensi dan throughput.
Akselerasi Kueri MCQA2.0: Ini merupakan peningkatan lengkap untuk akselerasi kueri MaxCompute. Stabilitas kinerja ditingkatkan melalui lingkungan yang sangat terbatas, dan dukungan MCQA 1.0 diperluas dari hanya kueri DQL SELECT menjadi fungsionalitas SQL penuh, termasuk DDL dan DML. Kinerja lebih ditingkatkan melalui metode cache dan optimasi ujung ke ujung seperti pemrosesan asinkron dari beberapa langkah dalam pipeline pengiriman pekerjaan.
Yang paling penting, kemampuan baru ini dibangun dan diimplementasikan berdasarkan mesin SQL asli MaxCompute. Pengguna MaxCompute dapat menganalisis sejumlah besar data dengan efisiensi biaya yang lebih tinggi tanpa mengubah kebiasaan pengembangan mereka.
Manfaat
Untuk mendukung skenario bisnis dan migrasi dari danau data open source seperti Hudi dan Iceberg, arsitektur baru menyediakan fitur umum tertentu. Arsitektur baru yang dikembangkan sendiri juga memberikan manfaat berikut dalam hal fitur, kinerja, stabilitas, dan integrasi:
Menyediakan desain terpadu untuk penyimpanan, metadata, dan mesin komputasi untuk mencapai integrasi mendalam dan efisien. Arsitektur baru ini memberikan manfaat seperti biaya penyimpanan rendah, manajemen file data yang efisien, dan efisiensi kueri tinggi. Selain itu, sejumlah besar aturan optimasi untuk kueri batch MaxCompute dapat digunakan kembali oleh time travel dan kueri inkremental.
Menyediakan sintaks SQL terpadu lengkap untuk mendukung semua fitur arsitektur baru. Hal ini memudahkan operasi pengguna.
Menyediakan alat impor data yang dioptimalkan dan disesuaikan secara mendalam untuk mendukung berbagai skenario bisnis yang kompleks.
Berintegrasi mulus dengan skenario bisnis yang ada dari MaxCompute untuk mengurangi biaya migrasi, penyimpanan, dan komputasi.
Mendukung manajemen otomatis file data untuk memastikan stabilitas baca/tulis yang lebih baik serta mendukung optimasi otomatis efisiensi penyimpanan dan biaya.
Sepenuhnya dikelola di MaxCompute. Anda dapat menggunakan arsitektur baru langsung tanpa biaya akses tambahan. Anda hanya perlu membuat tabel Delta untuk menggunakan fitur arsitektur baru.
Merupakan arsitektur yang dikembangkan sendiri. Anda dapat mengelola pengembangan data untuk kebutuhan bisnis Anda berdasarkan arsitektur baru.