Dokumen ini menjelaskan penyebab dan solusi error Out of Memory (OOM) di Hologres. Error OOM terjadi ketika konsumsi memori suatu kueri melebihi memori sistem yang tersedia, sehingga memicu pengecualian. Dokumen ini juga menjelaskan cara memantau konsumsi memori di Hologres, menganalisis skenario penggunaan memori tinggi, mengidentifikasi error OOM beserta penyebabnya, serta memberikan solusi.
Analisis konsumsi memori
Lihat konsumsi memori
Total konsumsi: Konsol Hologres menyediakan ringkasan konsumsi memori untuk instans Anda, yang merupakan agregasi nilai dari semua node. Untuk informasi selengkapnya, lihat Metrik pemantauan.
Konsumsi per kueri: Bidang
memory_bytesmemperkirakan konsumsi memori dari satu kueri. Perlu diperhatikan bahwa nilai ini bersifat perkiraan dan mungkin tidak akurat. Untuk informasi selengkapnya, lihat Lihat dan analisis log kueri lambat.
Penanganan penggunaan memori tinggi
Pantau penggunaan memori keseluruhan instans Hologres menggunakan metrik di Konsol Hologres (lihat Metrik pemantauan untuk detailnya). Penggunaan memori yang terus-menerus melebihi 80% dianggap tinggi. Hologres melakukan pre-alokasi memori untuk metadata dan cache guna meningkatkan kecepatan komputasi, sehingga penggunaan idle normal berkisar antara 30–50%. Namun, penggunaan yang mendekati 100% menunjukkan adanya masalah yang berdampak pada stabilitas dan performa sistem. Bagian-bagian berikut menjelaskan penyebab, dampak, dan solusi untuk penggunaan memori tinggi.
Penyebab
Konsumsi memori tinggi dari metadata
Penggunaan memori metadata yang tinggi merupakan indikator utama masalah ini. Seiring peningkatan volume data dalam tabel, metadata yang diperlukan untuk mengelolanya juga bertambah, sehingga mengonsumsi lebih banyak memori. Hal ini dapat menyebabkan penggunaan memori tinggi bahkan saat tidak ada tugas yang sedang berjalan. Sebagai praktik terbaik, satu Table Group sebaiknya tidak melebihi 10.000 tabel (termasuk partisi, tetapi tidak termasuk foreign table). Selain itu, jumlah shard yang tinggi dalam satu Table Group dapat meningkatkan fragmentasi file dan akumulasi metadata, sehingga mengonsumsi memori tambahan.
Konsumsi memori tinggi dari komputasi
Penggunaan memori kueri yang tinggi merupakan indikator utama masalah ini, biasanya terjadi ketika kueri memindai volume data besar atau melibatkan logika komputasi kompleks, seperti banyak fungsi
COUNT DISTINCT, operasiJOINyang kompleks,GROUP BYpada beberapa kolom, atau window function.
Dampak utama
Stabilitas
Konsumsi memori berlebihan, terutama dari metadata, secara langsung mengurangi memori yang tersedia untuk kueri. Hal ini dapat menyebabkan error sporadis seperti
SERVER_INTERNAL_ERROR,ERPC_ERROR_CONNECTION_CLOSED, atauTotal memory used by all existing queries exceeded memory limitation.Performa
Penggunaan memori tinggi, terutama akibat metadata berlebihan, menghabiskan ruang cache yang dibutuhkan untuk kueri. Akibatnya, tingkat hit cache menurun dan latensi kueri meningkat.
Solusi
Jika penggunaan memori tinggi disebabkan oleh metadata berlebihan: Gunakan tabel
hg_table_infountuk mengelola tabel Anda. Untuk informasi selengkapnya, lihat Kueri dan analisis statistik tabel. Pertimbangkan untuk menghapus data atau tabel yang tidak lagi dikueri, serta kurangi desain tabel partisi yang tidak perlu untuk membebaskan memori.Jika penggunaan memori tinggi disebabkan oleh komputasi: Optimalkan SQL Anda secara terpisah untuk kasus penggunaan write dan query. Untuk informasi selengkapnya, lihat Cara mengatasi error OOM selama kueri dan Cara mengatasi error OOM selama impor dan ekspor data.
Solusi umum: Tingkatkan spesifikasi komputasi dan penyimpanan instans Anda. Untuk informasi selengkapnya, lihat Daftar instans.
Identifikasi error OOM
Error OOM terjadi ketika memori komputasi melebihi batas alokasinya (misalnya, 20 GB atau lebih). Contoh pesan error khas ditunjukkan di bawah ini:
Total memory used by all existing queries exceeded memory limitation.
memory usage for existing queries=(2031xxxx,184yy)(2021yyyy,85yy)(1021121xxxx,6yy)(2021xxx,18yy)(202xxxx,14yy); Used/Limit: xy1/xy2 quota/sum_quota: zz/100Interpretasi pesan error sebagai berikut:
queries=(query_id, memory_used_by_query)Bagian ini, seperti
queries=(2031xxxx,184yy), menunjukkan konsumsi memori dari masing-masing kueri. Misalnya,queries=(2031xxxx,18441803528)berarti kueri denganquery_id=2031xxxxmengonsumsi sekitar 18 GB memori pada satu node selama eksekusi. Pesan error biasanya mencantumkan 5 kueri dengan konsumsi memori tertinggi, yang dapat membantu mengidentifikasi penyebab utamanya. Detail lebih lanjut tersedia di Lihat dan analisis log kueri lambat.Used/Limit: xy1/xy2Segmen ini menampilkan rasio
compute_memory_used_on_nodeterhadapcompute_memory_limit_on_nodedalam byte. NilaiUsedmerepresentasikan total memori komputasi yang dikonsumsi oleh semua kueri yang sedang dieksekusi pada node tersebut. Misalnya,Used/Limit: 33288093696/33114697728menandakan bahwa total memori yang digunakan kueri pada node tersebut mencapai 33,2 GB, melebihi batas memori elastis node sebesar 33,1 GB, sehingga memicu error OOM.quota/sum_quota: zz/100Di sini,
zzmenunjukkan persentase total resource instans yang dialokasikan ke kelompok sumber daya tertentu. Misalnya,quota/sum_quota: 50/100menunjukkan bahwa kelompok sumber daya dikonfigurasi dan menggunakan 50% dari total resource instans.
Penyebab dasar error OOM
Berbeda dengan beberapa sistem yang "Spill to Disk" saat memori tidak mencukupi, Hologres secara default memprioritaskan komputasi in-memory untuk memastikan efisiensi kueri optimal. Pilihan desain mendasar ini berarti bahwa jika permintaan memori suatu kueri melebihi resource yang tersedia, error OOM akan terjadi secara langsung, bukan menurunkan performa melalui penggunaan disk.
Alokasi dan batas memori
Instans Hologres beroperasi sebagai sistem terdistribusi, terdiri atas beberapa node yang jumlahnya bervariasi sesuai spesifikasi instans. Untuk detail lebih lanjut, lihat Manajemen instans.
Setiap node dalam instans Hologres biasanya memiliki 16 vCPU dan memori 64 GB. Error OOM dipicu jika salah satu node yang terlibat dalam kueri kehabisan memorinya. Memori 64 GB ini dibagi untuk berbagai keperluan: komputasi kueri, proses backend, cache, dan metadata. Meskipun versi sebelumnya (sebelum V1.1.24) menerapkan batas memori tetap 20 GB untuk node komputasi, Hologres V1.1.24 dan versi setelahnya telah menghapus batasan ini. Memori kini disesuaikan secara dinamis. Sistem terus memantau penggunaan memori dan, ketika konsumsi metadata rendah, secara cerdas mengalokasikan sisa memori yang tersedia untuk eksekusi kueri, sehingga memaksimalkan performa runtime.
Cara mengatasi error OOM selama kueri
Penyebab.
Rencana eksekusi salah: Hal ini dapat disebabkan oleh statistik yang tidak akurat, urutan join yang tidak tepat, atau masalah optimasi lainnya.
Konkurensi kueri tinggi: Banyak kueri yang secara bersamaan mengonsumsi memori dalam jumlah besar.
Kueri kompleks: Kueri yang secara inheren kompleks atau memindai volume data besar.
UNION ALLoperations: Kueri yang mengandungUNION ALLdapat meningkatkan paralelisme pelaksana, sehingga meningkatkan penggunaan memori.Alokasi kelompok sumber daya tidak mencukupi: Kelompok sumber daya dikonfigurasi tetapi dialokasikan resource yang tidak memadai.
Kesenjangan data atau pemangkasan shard: Hal ini dapat menyebabkan beban tidak seimbang dan tekanan memori tinggi pada node tertentu.
Analisis dan solusi:
Penyebab: Alokasi kelompok sumber daya tidak mencukupi
Solusi: Untuk mengatasi error OOM akibat alokasi resource yang tidak mencukupi, manfaatkan fitur Serverless Computing. Fitur ini memungkinkan Anda menggunakan resource komputasi serverless yang melimpah selain resource khusus instans Anda, sehingga secara efektif menghindari konflik sumber daya dan menyediakan kapasitas komputasi lebih besar. Untuk ikhtisar dan petunjuk penggunaan, lihat Serverless Computing dan Panduan Serverless Computing.
Untuk Hologres V3.0 dan versi setelahnya, Query Queue menawarkan solusi otomatis: kueri OOM dapat dijalankan ulang secara otomatis menggunakan resource komputasi serverless tanpa perlu definisi manual. Untuk informasi selengkapnya, lihat Kontrol kueri besar.
Penyebab: Rencana eksekusi salah
Tipe 1: Statistik tidak akurat
Jalankan
EXPLAIN <SQL>untuk melihat rencana eksekusi. Seperti yang ditunjukkan pada gambar di bawah,rows=1000menunjukkan statistik yang hilang atau tidak akurat, sehingga menghasilkan rencana eksekusi tidak efisien yang mengonsumsi resource berlebihan dan memicu error OOM.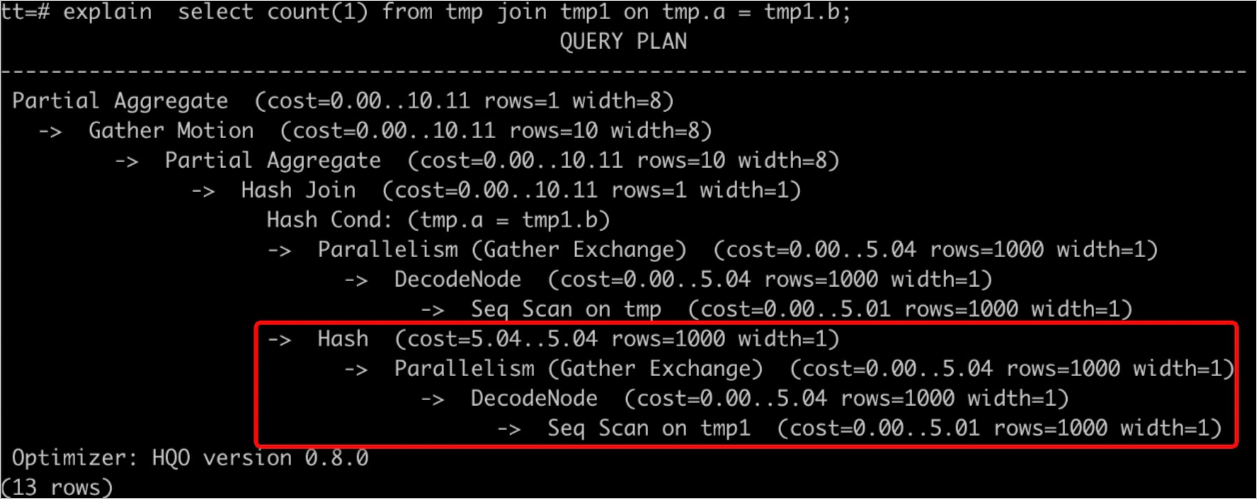
Solusi meliputi hal-hal berikut:
Jalankan perintah
ANALYZE <tablename>untuk memperbarui statistik tabel.Aktifkan auto analyze untuk memperbarui statistik secara otomatis. Untuk informasi selengkapnya, lihat ANALYZE dan AUTO ANALYZE.
Tipe 2: Urutan join salah
Saat menggunakan Hash Join, tabel yang lebih kecil idealnya ditetapkan sebagai sisi 'build' untuk membangun tabel hash, sehingga mengoptimalkan penggunaan memori. Gunakan
EXPLAIN <SQL>untuk memeriksa rencana eksekusi. Jika rencana menunjukkan bahwa tabel yang lebih besar digunakan untuk membangun tabel hash, ini merupakan urutan join yang tidak efisien dan dapat dengan mudah menyebabkan error OOM. Penyebab umum meliputi hal-hal berikut:Statistik tabel usang. Misalnya, pada gambar di bawah, statistik tabel bagian atas tidak diperbarui, sehingga menghasilkan
rows=1000.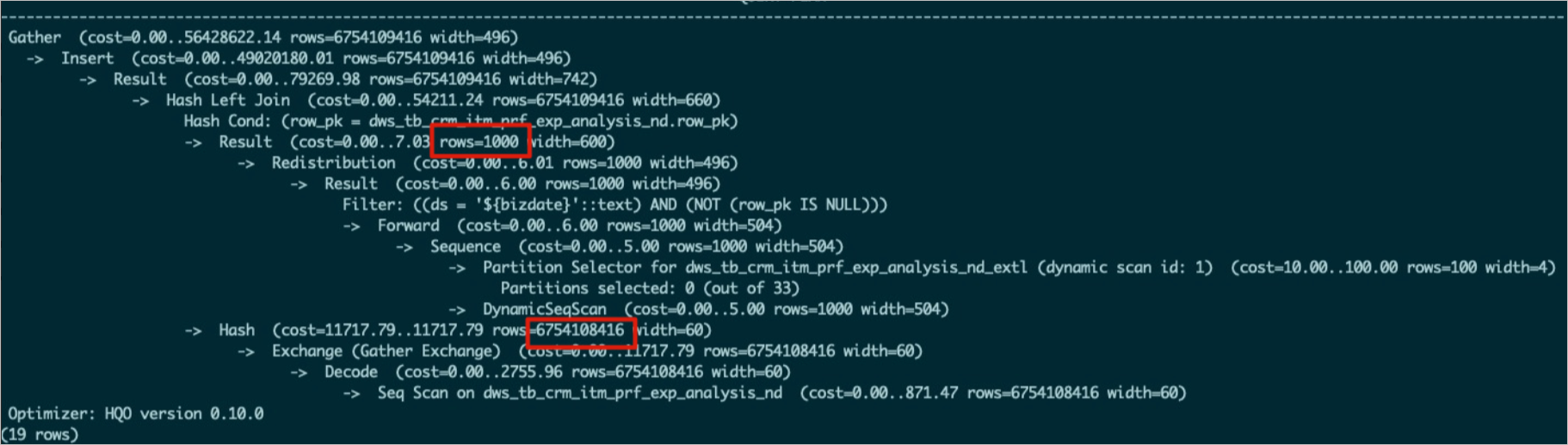
Pengoptimal gagal menghasilkan rencana eksekusi optimal.
Solusi:
Jalankan
ANALYZE <tablename>pada semua tabel yang terlibat dalam join untuk memastikan statistik mutakhir. Hal ini membantu pengoptimal menentukan urutan join yang benar.Jika urutan join tetap salah setelah menjalankan
ANALYZE <tablename>, sesuaikan parameter GUC. Tetapkanoptimizer_join_order = queryuntuk memaksa pengoptimal mengikuti urutan join yang ditentukan dalam pernyataan SQL. Pendekatan ini sangat cocok untuk kueri kompleks.SET optimizer_join_order = query; SELECT * FROM a JOIN b ON a.id = b.id; -- Tabel b digunakan sebagai sisi build dari tabel hash.Anda juga dapat menyesuaikan kebijakan urutan join sesuai kebutuhan.
Parameter
Deskripsi
set optimizer_join_order = <value>
Parameter ini mengontrol algoritma Join Order pengoptimal. Nilai yang valid:
query: Tidak melakukan transformasi Join Order. Join dieksekusi secara ketat sesuai urutan yang ditentukan dalam kueri SQL. Pengaturan ini memiliki overhead pengoptimal paling rendah.greedy: Menggunakan algoritma greedy untuk mengeksplorasi kemungkinan Join Order. Opsi ini menghasilkan overhead pengoptimal moderat.exhaustive(default): Menggunakan algoritma perencanaan dinamis untuk transformasi Join Order. Tujuannya adalah menghasilkan rencana eksekusi optimal tetapi memiliki overhead pengoptimal tertinggi.
Tipe 3: Estimasi tabel hash salah
Selama hash join, input yang lebih kecil (tabel atau subkueri) idealnya ditetapkan sebagai input build untuk membangun tabel hash, sehingga mengoptimalkan performa dan menghemat memori. Namun, karena kompleksitas kueri atau statistik yang tidak akurat, sistem dapat salah memperkirakan volume data dan secara keliru memilih relasi yang lebih besar sebagai input build. Hal ini mengakibatkan pembangunan tabel hash yang terlalu besar, mengonsumsi memori signifikan, dan memicu error OOM.
Seperti yang ditunjukkan pada gambar di bawah,
Hash (cost=727353.45..627353.35 , rows=970902134 width=94)merepresentasikan input build, danrows=970902134menunjukkan volume data yang diperkirakan untuk membangun tabel hash. Jika tabel aktual berisi data lebih sedikit, estimasinya tidak akurat.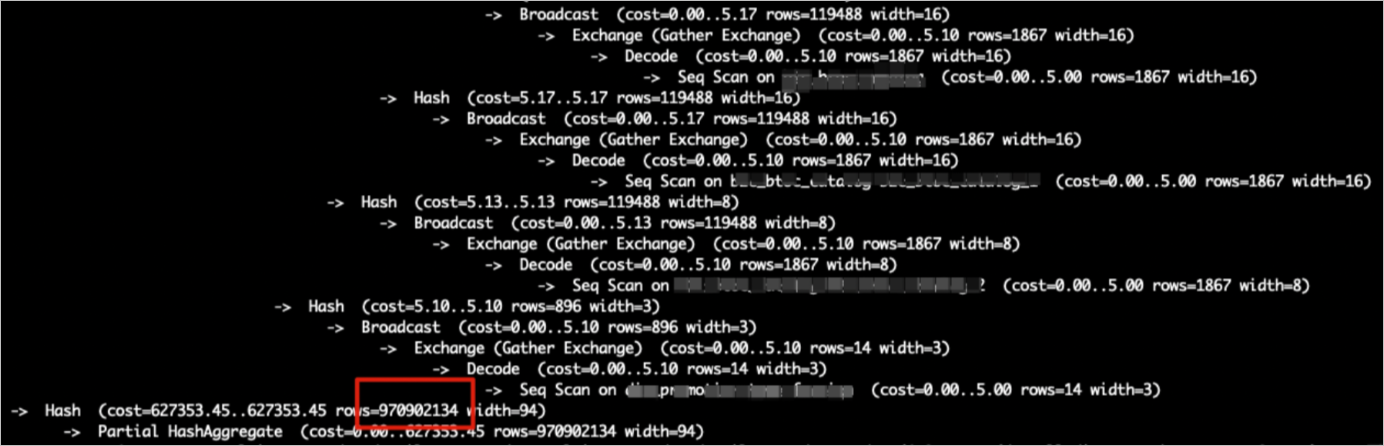
Solusi:
Verifikasi statistik: Periksa apakah statistik tabel subkueri mutakhir dan akurat. Jika tidak, jalankan
ANALYZE <tablename>untuk memperbaruinya.Nonaktifkan estimasi tabel hash: Matikan estimasi ukuran tabel hash mesin eksekusi menggunakan parameter berikut:
CatatanParameter ini secara default bernilai
off. Namun, parameter ini mungkin telah diaktifkan dalam skenario tuning tertentu. Jika saat ini diaktifkan, pastikan Anda mengaturnya kembali keoff.SET hg_experimental_enable_estimate_hash_table_size =off;
Tipe 4: Broadcasting tabel besar
Broadcasting melibatkan penyalinan data ke semua shard. Metode ini hanya efisien jika tabel dan jumlah shard keseluruhan kecil. Dalam operasi join, rencana eksekusi pertama-tama melakukan broadcast data input build lalu membangun tabel hash. Artinya, setiap shard menerima dan memproses seluruh dataset input build. Dataset besar atau jumlah shard berlebihan dapat mengonsumsi memori signifikan, sering kali menyebabkan error OOM.
Misalnya, tabel dengan 80 juta baris mungkin muncul dalam rencana eksekusi hanya dengan estimasi 1 baris, dengan hanya 80 baris yang seharusnya terlibat dalam broadcast—ketidakkonsistenan yang jelas. Namun, eksekusi aktual melakukan broadcast seluruh 80 juta baris, mengonsumsi memori berlebihan dan memicu error OOM.
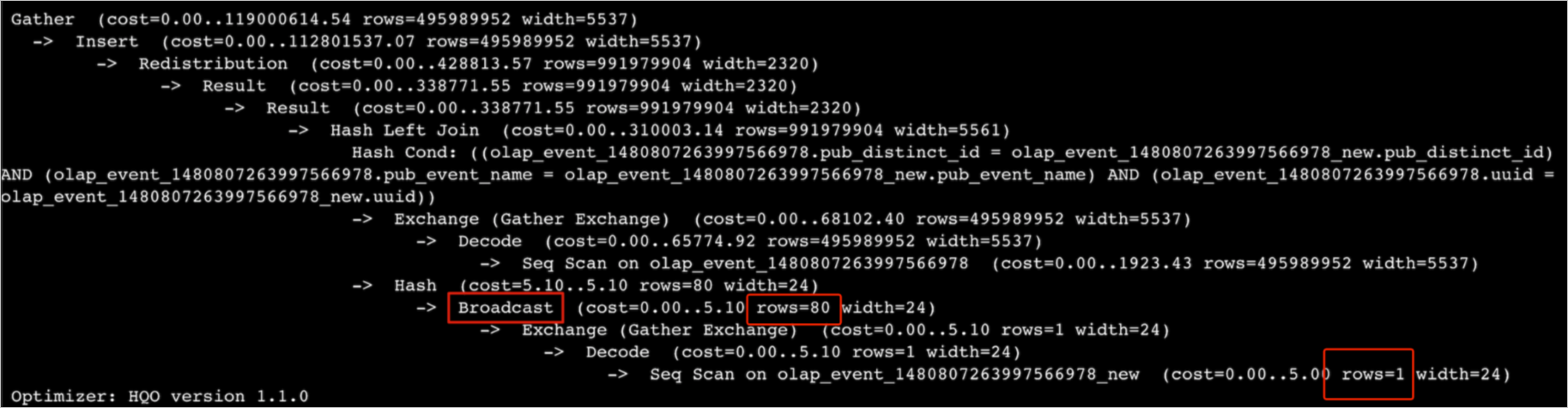
Solusi:
Periksa apakah estimasi jumlah baris dalam rencana eksekusi sesuai dengan kenyataan. Jika tidak, jalankan
ANALYZE tablenameuntuk memperbarui statistik.Nonaktifkan broadcasting dan tulis ulang sebagai operator redistribusi menggunakan parameter GUC berikut.
SET optimizer_enable_motion_broadcast = off;
Penyebab: Konkurensi kueri tinggi
Jika metrik Queries Per Second (QPS) melonjak signifikan, atau jika error OOM melaporkan
HGERR_detl memory usage for existing queries=(2031xxxx,184yy)(2021yyyy,85yy)(1021121xxxx,6yy)(2021xxx,18yy)(202xxxx,14yy);dengan setiap kueri menggunakan memori relatif minimal, maka konkurensi kueri tinggi kemungkinan besar menjadi penyebabnya. Solusi:Kurangi konkurensi write: Jika operasi write berkontribusi, kurangi konkurensinya. Untuk informasi selengkapnya, lihat Cara mengatasi error OOM selama impor dan ekspor data.
Terapkan arsitektur pemisahan baca/tulis: Terapkan arsitektur pemisahan baca/tulis dengan instans primary dan secondary (penyimpanan bersama).
Tingkatkan spesifikasi komputasi instans Anda.
Penyebab: Kueri kompleks
Jika satu kueri memicu error OOM karena kompleksitas inherennya atau volume data besar yang dipindainya, pertimbangkan pendekatan berikut:
Pre-komputasi data: Lakukan pre-komputasi dan tulis data yang telah dibersihkan ke Hologres untuk menghindari operasi ETL skala besar secara langsung di Hologres.
Tambahkan kondisi filter.
Optimalkan SQL: Optimalkan pernyataan SQL itu sendiri—misalnya, dengan menggunakan teknik seperti Fixed Plan atau optimasi Count Distinct. Untuk informasi selengkapnya, lihat Optimalkan performa kueri.
Penyebab: UNION ALL
Seperti yang ditunjukkan di bawah, ketika pernyataan SQL mengandung banyak subkueri
UNION ALL, pelaksana memprosesnya secara konkuren. Hal ini dapat membebani memori dan menyebabkan error OOM.subquery1 UNION ALL subquery2 UNION ALL subquery3 ...Solusi: Paksa eksekusi serial menggunakan parameter berikut untuk mengurangi error OOM. Perlu diketahui bahwa hal ini akan mengakibatkan performa kueri lebih lambat.
SET hg_experimental_hqe_union_all_type=1; SET hg_experimental_enable_fragment_instance_delay_open=on;Penyebab: Konfigurasi kelompok sumber daya tidak wajar
Error OOM melaporkan:
memory usage for existing queries=(3019xxx,37yy)(3022xxx,37yy)(3023xxx,35yy)(4015xxx,30yy)(2004xxx,2yy); Used/Limit: xy1/xy2 quota/sum_quota: zz/100. Jika zz kecil—misalnya, 10 (menunjukkan hanya 10% dari total resource instans dialokasikan ke kelompok sumber daya)—alokasi terbatas ini secara signifikan membatasi memori yang tersedia untuk kueri yang dieksekusi dalam kelompok tersebut, sehingga meningkatkan kemungkinan error OOM.
Solusi: Atur ulang kuota kelompok sumber daya. Setiap kelompok sumber daya sebaiknya menerima setidaknya
30%dari total resource instans untuk memastikan kapasitas memori yang memadai.Penyebab: Kesenjangan data atau pemangkasan shard
Jika penggunaan memori keseluruhan instans rendah tetapi error OOM tetap terjadi, penyebabnya biasanya kesenjangan data atau pemangkasan shard, yang memusatkan tekanan memori pada satu atau beberapa node.
CatatanPemangkasan shard adalah teknik optimasi kueri yang hanya memindai subset shard, bukan semua shard.
Periksa kesenjangan data: Gunakan kueri SQL berikut.
hg_shard_idadalah bidang tersembunyi bawaan di setiap tabel yang menunjukkan shard tempat setiap baris berada.SELECT hg_shard_id, count(1) FROM t1 GROUP BY hg_shard_id;Periksa pemangkasan shard: Periksa rencana eksekusi untuk indikasi Shard Pruning. Misalnya, jika pemilih shard menunjukkan
l0[1], artinya hanya data dari satu shard tertentu yang dipilih untuk kueri.-- Kunci distribusi adalah x. Berdasarkan kondisi filter x=1, Anda dapat dengan cepat menemukan shard. SELECT count(1) FROM bbb WHERE x=1 GROUP BY y;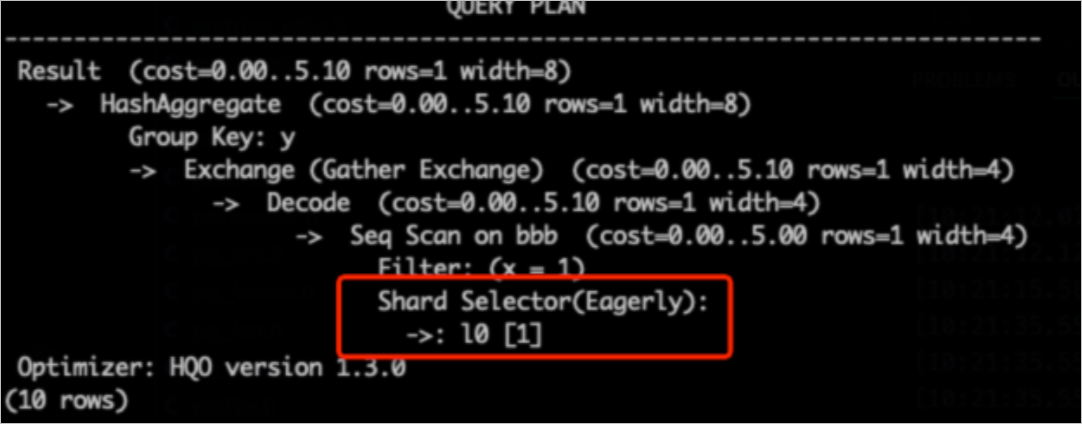
Solusi:
Rancang kunci distribusi yang sesuai untuk mencegah kesenjangan data.
Jika logika bisnis secara inheren menyebabkan kesenjangan data, modifikasi logika aplikasi yang sesuai.
Penyebab: GROUP BY multi-tahap dengan kardinalitas tinggi
Mulai Hologres V3.0, agregasi multi-tahap pada data dengan kardinalitas tinggi rentan terhadap error OOM. Hal ini sering terjadi ketika kolom
GROUP BYtidak sejalan dengan distribusi data (yaitu, kunci distribusi bukan subset dari kunciGROUP BY). Dalam situasi ini, setiap instance konkuren pada tahap agregasi awal harus memelihara tabel hash yang sangat besar untuk pengelompokan, sehingga menciptakan tekanan memori tinggi. Untuk mengurangi hal ini, aktifkan agregasi bertahap dengan mengatur parameter berikut:-- Gunakan parameter GUC untuk mengatur jumlah maksimum baris dalam tabel hash agregasi. Pernyataan SQL berikut menunjukkan bahwa partial_agg_hash_table dapat memiliki maksimal 8192 baris. Nilai default adalah 0, yang berarti tidak ada batas. SET hg_experimental_partial_agg_hash_table_size = 8192;
Cara mengatasi error OOM selama impor dan ekspor data
Error OOM dapat terjadi selama operasi transfer data di dalam Hologres. Hal ini berlaku untuk transfer antar tabel internal maupun interaksi dengan foreign table. Skenario umum terjadinya error semacam ini adalah selama impor data dari MaxCompute ke Hologres.
Solusi 1: Gunakan Serverless Computing untuk impor dan ekspor
Fitur Serverless Computing memungkinkan Anda memanfaatkan resource Serverless tambahan untuk tugas impor dan ekspor, melengkapi resource khusus instans Anda. Hal ini menyediakan kapasitas komputasi lebih besar dan membantu menghindari konflik sumber daya, sehingga menjadi solusi efektif untuk mengatasi masalah OOM selama transfer data. Untuk ikhtisar, lihat Serverless Computing. Untuk petunjuk penggunaan detail, lihat Panduan Serverless Computing.
Solusi 2: Kendalikan konkurensi pemindaian untuk tabel lebar atau kolom lebar
Dalam skenario impor MaxCompute, error OOM selama write dapat terjadi ketika tabel lebar atau kolom lebar dikombinasikan dengan konkurensi pemindaian tinggi. Gunakan parameter berikut untuk mengontrol konkurensi impor dan mengurangi error OOM ini.
Kendalikan konkurensi pemindaian untuk tabel lebar (skenario umum)
CatatanTerapkan parameter berikut bersama pernyataan SQL Anda. Utamakan dua parameter pertama. Jika error OOM masih terjadi, kurangi nilai-nilainya lebih lanjut.
-- Tetapkan konkurensi maksimum untuk mengakses foreign table. Nilai default sama dengan jumlah vCPU instans. Nilai maksimum adalah 128. Jangan atur nilai besar untuk mencegah kueri pada foreign table, terutama dalam skenario impor data, memengaruhi kueri lain dan menyebabkan error system busy. Parameter ini berlaku di Hologres V1.1 dan versi setelahnya. SET hg_foreign_table_executor_max_dop = 32; -- Sesuaikan ukuran batch untuk setiap pembacaan dari tabel MaxCompute. Nilai default adalah 8192. SET hg_experimental_query_batch_size = 4096; -- Tetapkan konkurensi maksimum untuk mengeksekusi pernyataan DML saat mengakses foreign table. Nilai default adalah 32. Parameter ini dioptimalkan untuk skenario impor dan ekspor data guna mencegah operasi impor mengonsumsi resource sistem berlebihan. Parameter ini berlaku di Hologres V1.1 dan versi setelahnya. SET hg_foreign_table_executor_dml_max_dop = 16; -- Tetapkan ukuran split untuk mengakses tabel MaxCompute. Parameter ini dapat menyesuaikan konkurensi. Nilai default adalah 64 MB. Jika tabel besar, tingkatkan nilai ini untuk mencegah terlalu banyak split memengaruhi performa. Parameter ini berlaku di Hologres V1.1 dan versi setelahnya. SET hg_foreign_table_split_size = 128;Kendalikan konkurensi pemindaian untuk kolom lebar
Jika Anda telah menyetel parameter untuk tabel lebar tetapi masih mengalami error OOM, periksa apakah data Anda mencakup kolom lebar. Jika ya, sesuaikan parameter berikut untuk mengatasi masalah tersebut.
-- Sesuaikan paralelisme shuffle untuk kolom lebar guna mengurangi akumulasi data. SET hg_experimental_max_num_record_batches_in_buffer = 32; -- Sesuaikan ukuran batch untuk setiap pembacaan dari tabel MaxCompute. Nilai default adalah 8192. SET hg_experimental_query_batch_size=128;
Penyebab: Data duplikat berlebihan dalam foreign table
Ketika foreign table berisi jumlah data duplikat yang substansial, performa impor dapat menurun secara signifikan, sering kali menyebabkan error OOM. Definisi "data duplikat substansial" bersifat kontekstual dan bervariasi tergantung kasus penggunaan. Misalnya, tabel dengan 100 juta baris yang memiliki 80 juta duplikat biasanya dianggap sangat terduplikasi. Anda harus menilai hal ini berdasarkan konteks bisnis spesifik Anda.
Solusi: Hilangkan duplikasi data sebelum mengimpornya, atau impor dalam batch lebih kecil untuk menghindari pemuatan volume besar data duplikat secara simultan.