Tema ini menjelaskan skenario inferensi real-time dan cara menggunakan instans yang dipercepat GPU dalam mode idle untuk membangun layanan inferensi real-time hemat biaya dengan latensi rendah.
Skema
Karakteristik beban kerja inferensi real-time
Beban kerja inferensi real-time sering kali memiliki satu atau lebih karakteristik berikut:
Latensi Rendah
Beban kerja inferensi real-time memiliki persyaratan tinggi terhadap waktu respons setiap permintaan. Latensi ekor panjang harus dalam ratusan milidetik untuk 90% permintaan.
Tautan Inti
Dalam kebanyakan kasus, beban kerja inferensi real-time dihasilkan dalam tautan bisnis inti, sehingga memerlukan tingkat keberhasilan tinggi dan tidak dapat menanggung pengulangan yang diperpanjang. Berikut adalah beberapa contoh:
Konten promosi pada halaman peluncuran dan halaman utama: Iklan produk dan rekomendasi yang sesuai dengan preferensi individu pengguna perlu ditampilkan secara cepat dan mencolok di halaman peluncuran dan halaman utama pengguna.
Layanan streaming real-time: Dalam skenario seperti co-streaming, live streaming, dan pemutaran ultra-rendah latensi, aliran audio dan video harus ditransmisikan dengan latensi ujung-ke-ujung yang sangat rendah. Kinerja super resolusi video berbasis AI real-time dan pengenalan video juga harus dijamin.
Trafik Fluktuatif
Trafik bisnis berfluktuasi sesuai dengan kebiasaan pengguna, mengalami jam sibuk dan sepi.
Pemanfaatan Sumber Daya Rendah
Dalam kebanyakan kasus, sumber daya GPU direncanakan berdasarkan puncak trafik, yang mengakibatkan sejumlah besar sumber daya tidak aktif selama jam sepi. Tingkat pemanfaatan sumber daya umumnya kurang dari 30%.
Manfaat menggunakan Function Compute dalam skenario inferensi real-time
Instans yang Dipercepat GPU dalam Mode Idle
Function Compute menawarkan fitur mode idle untuk instans yang disediakan dengan percepatan GPU. Jika Anda ingin mengurangi cold start dan memenuhi persyaratan latensi rendah beban kerja inferensi real-time, Anda dapat mengonfigurasi instans yang disediakan dengan percepatan GPU dengan mode idle diaktifkan. Untuk informasi lebih lanjut, lihat Jenis Instans dan Mode Penggunaan. Fitur mode idle untuk instans yang dipercepat GPU memberikan manfaat berikut:
Pemanggilan Instans Cepat: Function Compute membekukan instans yang dipercepat GPU berdasarkan beban kerja real-time Anda, dan secara otomatis membuka pembekuan saat ada permintaan masuk. Perhatikan bahwa proses pembukaan pembekuan membutuhkan dua hingga tiga detik.
Layanan Hemat Biaya: Pengukuran durasi eksekusi instans dalam mode disediakan dan on-demand bervariasi. Instans yang disediakan dalam mode idle dibebankan dengan harga satuan lebih rendah dibandingkan yang aktif. Untuk informasi lebih lanjut, lihat Bagaimana saya dikenakan biaya untuk menggunakan layanan inferensi real-time di Function Compute? Meskipun biaya keseluruhan menggunakan instans yang disediakan dengan percepatan GPU dalam mode idle lebih tinggi dibandingkan menggunakan instans on-demand, tetap lebih dari 50% lebih rendah daripada biaya membangun kluster GPU di lingkungan on-premises Anda.
Mekanisme Penjadwalan Permintaan yang Dioptimalkan untuk Skenario Inferensi
Function Compute menyediakan mekanisme penjadwalan cerdas bawaan untuk mencapai keseimbangan beban antara instans yang dipercepat GPU yang berbeda dalam suatu fungsi. Penjadwalan cerdas Function Compute mendistribusikan permintaan inferensi secara merata ke instans yang dipercepat GPU di backend, yang meningkatkan pemanfaatan keseluruhan kluster inferensi.
Instans yang dipercepat GPU dalam mode idle
Setelah fungsi GPU diterapkan, Anda dapat menggunakan instans yang disediakan dengan percepatan GPU dengan mode idle diaktifkan untuk menyediakan kemampuan infrastruktur untuk skenario inferensi real-time. Function Compute melakukan penskalaan horizontal pod otomatis (HPA) pada instans yang disediakan dengan percepatan GPU, menyesuaikan sumber daya secara dinamis berdasarkan kebijakan penskalaan berbasis metrik dan beban kerja. Permintaan inferensi diprioritaskan dialokasikan ke instans yang disediakan dengan percepatan GPU untuk diproses. Instans yang disediakan membantu mengurangi cold start, yang memungkinkan layanan inferensi Anda secara konsisten merespons dengan latensi rendah.
Mode idle membantu mengurangi biaya
Setelah Anda mengaktifkan fitur mode idle, penagihan untuk instans yang dipercepat GPU ditentukan oleh dua harga satuan terpisah: satu untuk GPU idle dan lainnya untuk GPU aktif. Function Compute secara otomatis mengumpulkan statistik dan menagih biaya berdasarkan status instans.
Dalam contoh yang ditunjukkan pada gambar berikut, instans yang dipercepat GPU melewati lima jendela waktu (T0 hingga T4) dari pembuatan hingga penghancuran. Instans tersebut aktif di T1 dan T3, dan idle di T0, T2, dan T4. Rumus berikut digunakan untuk menghitung total biaya: (T0 + T2 + T4) x Harga satuan GPU idle + (T1 + T3) x Harga satuan GPU aktif. Untuk informasi lebih lanjut tentang harga satuan GPU idle dan GPU aktif, lihat Ikhtisar Penagihan.
Cara kerjanya
Function Compute menerapkan pembekuan instan dan pemulihan untuk instans yang dipercepat GPU berdasarkan teknologi canggih Alibaba Cloud. Saat instans yang dipercepat GPU tidak memproses permintaan, Function Compute secara otomatis membekukan instans dan menagih Anda berdasarkan harga satuan GPU idle. Mekanisme ini mengoptimalkan pemanfaatan sumber daya dan meminimalkan biaya. Saat permintaan inferensi baru tiba, Function Compute mengaktifkan instans untuk mengeksekusi permintaan secara mulus. Dalam hal ini, Anda dikenakan biaya berdasarkan harga satuan GPU aktif.
Proses ini sepenuhnya transparan bagi pengguna dan tidak memengaruhi pengalaman pengguna. Pada saat yang sama, Function Compute memastikan akurasi dan keandalan tak tergoyahkan dari layanan inferensi Anda bahkan ketika instans dibekukan, memberikan pengguna kemampuan komputasi yang stabil dan hemat biaya.
Durasi aktivasi instans GPU idle
Durasi aktivasi instans GPU idle bervariasi berdasarkan beban kerja. Tabel berikut mencantumkan durasi dalam skenario inferensi tipikal untuk referensi Anda.
Jenis beban kerja inferensi | Durasi aktivasi (detik) |
OCR/NLP | 0,5–1 |
Stable Diffusion | 2 |
LLM | 3 |
Durasi aktivasi bervariasi berdasarkan ukuran model. Durasi aktual yang berlaku.
Catatan penggunaan
Versi CUDA
Kami merekomendasikan Anda menggunakan CUDA 12.2 atau versi lebih lama.
Izin Gambar
Kami merekomendasikan Anda menjalankan gambar kontainer sebagai pengguna root default.
Login Instans
Anda tidak dapat login ke instans GPU idle karena GPU-nya dibekukan.
Rotasi Instans yang Baik
Function Compute memutar instans GPU idle berdasarkan beban kerja. Untuk memastikan kualitas layanan, kami merekomendasikan Anda menambahkan hook siklus hidup ke instans fungsi untuk pemanasan model dan pra-inferensi. Dengan cara ini, layanan inferensi Anda dapat disediakan segera setelah peluncuran instans baru. Untuk informasi lebih lanjut, lihat Pemanasan Model.
Pemanasan Model dan Pra-Inferensi
Untuk mengurangi latensi bangun pertama kali instans GPU idle, kami merekomendasikan Anda menggunakan hook
initializedalam kode Anda untuk memanaskan atau memuat model Anda terlebih dahulu. Untuk informasi lebih lanjut, lihat Pemanasan Model.Konfigurasi Instans yang Disediakan
Saat Anda mengaktifkan sakelar Mode Idle, instans GPU yang disediakan yang ada untuk fungsi dimatikan dengan lembut. Instans yang disediakan dialokasikan ulang setelah dilepaskan untuk periode waktu singkat.
Server Metrik Bawaan dari Kerangka Inferensi
Untuk meningkatkan kompatibilitas dan kinerja GPU idle, kami merekomendasikan Anda menonaktifkan Server Metrik Bawaan dari kerangka inferensi Anda, seperti NVIDIA Triton Inference Server dan TorchServe.
Spesifikasi instans yang dipercepat GPU
Hanya fungsi yang dikonfigurasi dengan ukuran penuh GPU yang mendukung mode idle. Untuk informasi lebih lanjut tentang spesifikasi instans yang dipercepat GPU, lihat Spesifikasi Instans.
Mekanisme penjadwalan permintaan yang dioptimalkan untuk skenario inferensi
Cara kerjanya
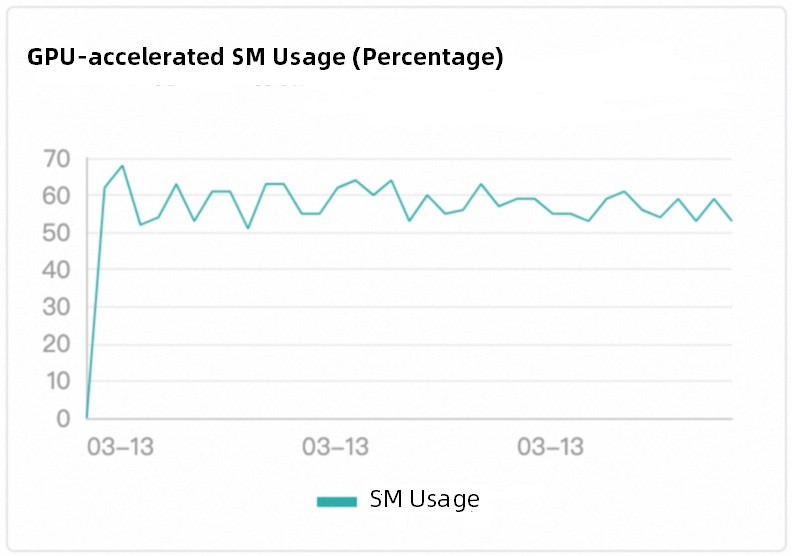
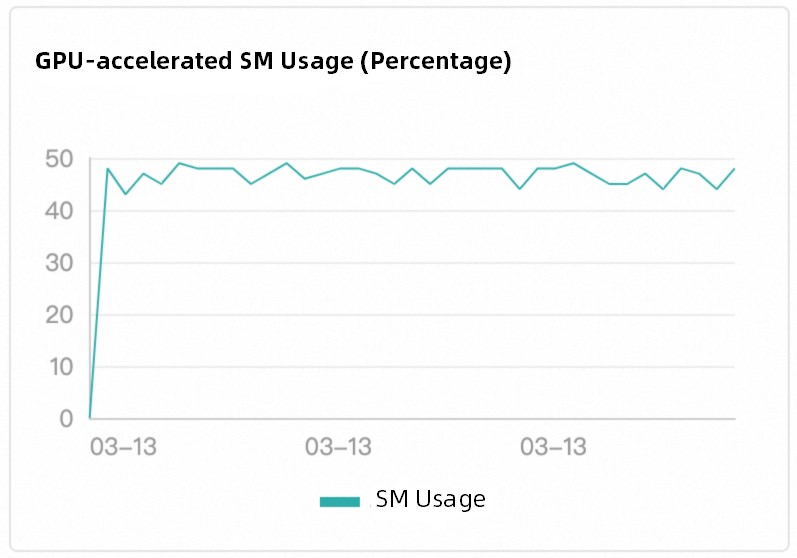
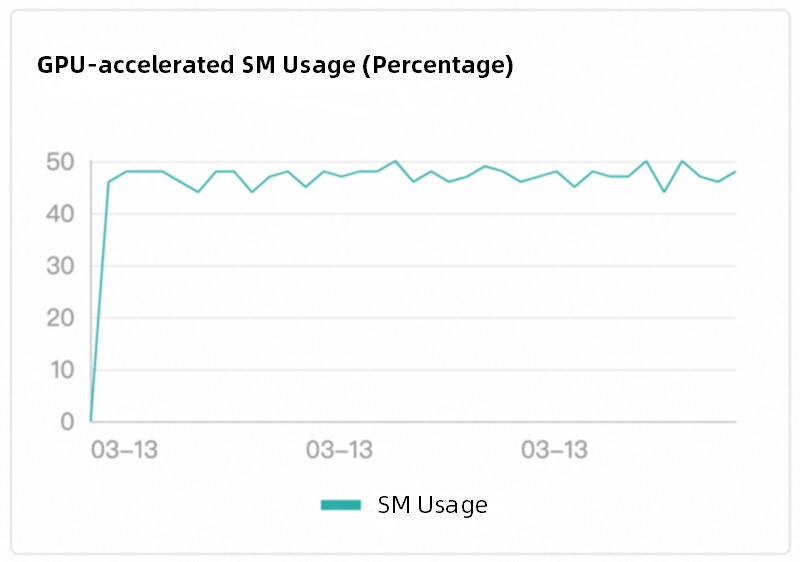
Function Compute mengadopsi penjadwalan cerdas berbasis beban kerja, strategi yang secara signifikan unggul dibandingkan metode penjadwalan round-robin konvensional. Platform ini memantau status eksekusi tugas instans yang dipercepat GPU secara real-time, dan segera mengirimkan permintaan baru ke instans yang dipercepat GPU yang sedang berjalan saat instans menjadi idle. Mekanisme ini memastikan penggunaan GPU yang efisien dan mengurangi pemborosan sumber daya dan hotspot. Ini juga memastikan bahwa keseimbangan beban instans yang dipercepat GPU sesuai dengan pemanfaatan daya komputasi GPU. Gambar berikut menunjukkan contoh di mana GPU Tesla T4 digunakan.
Efek penjadwalan
Logika penjadwalan bawaan Function Compute mengimplementasikan keseimbangan beban di antara instans yang dipercepat GPU yang berbeda. Penjadwalan ini tidak terasa oleh pengguna.
Instans 1 | Instans 2 | Instans 3 |
|
|
|
Dukungan Kontainer
Instans yang dipercepat GPU dari Function Compute hanya dapat digunakan dalam runtime Custom Container. Untuk informasi lebih lanjut tentang runtime Custom Container, lihat Pengantar Custom Container.
Fungsi Custom Container memerlukan server web yang dibawa dalam gambar untuk mengeksekusi jalur kode yang berbeda dan memicu fungsi melalui acara atau permintaan HTTP. Mode server web cocok untuk skenario eksekusi permintaan multi-jalur seperti pembelajaran AI dan inferensi.
Metode Penyebaran
Anda dapat menerapkan model Anda di Function Compute dengan menggunakan salah satu metode berikut:
Gunakan konsol Function Compute. Untuk informasi lebih lanjut, lihat Buat Fungsi di Konsol Function Compute.
Panggil SDK. Untuk informasi lebih lanjut, lihat Daftar Operasi Berdasarkan Fungsi.
Gunakan Serverless Devs. Untuk informasi lebih lanjut, lihat Perintah Umum Serverless Devs.
Untuk lebih banyak contoh penyebaran, lihat start-fc-gpu.
Pemanasan Model
Untuk mengatasi waktu pemrosesan awal yang lama setelah model diluncurkan, Function Compute menyediakan fitur pemanasan model. Fitur ini memungkinkan model langsung masuk ke kondisi kerja setelah diluncurkan.
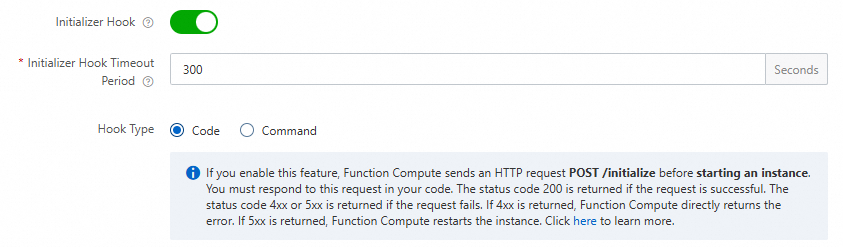
Kami merekomendasikan Anda mengonfigurasi hook siklus hidup initialize di Function Compute. Function Compute secara otomatis mengeksekusi logika bisnis dalam hook untuk memanaskan model Anda. Untuk informasi lebih lanjut, lihat Hook Siklus Hidup untuk Instans Fungsi.
Tambahkan jalur invokasi
/initializemetode POST ke server HTTP yang Anda bangun, dan letakkan logika pemanasan model di bawah jalur/initialize. Anda bisa membuat model melakukan inferensi sederhana untuk mencapai efek pemanasan.Kode sampel berikut memberikan contoh dalam Python:
def prewarm_inference(): res = model.inference() @app.route('/initialize', methods=['POST']) def initialize(): request_id = request.headers.get("x-fc-request-id", "") print("FC Initialize Start RequestId: " + request_id) # Prewarm model and perform naive inference task. prewarm_inference() print("FC Initialize End RequestId: " + request_id) return "Function is initialized, request_id: " + request_id + "\n"Di halaman Rincian Fungsi, pilih , lalu klik Modify untuk mengonfigurasi hook siklus hidup.
Konfigurasikan penskalaan otomatis dalam skenario inferensi real-time
Gunakan Serverless Devs
Prasyarat
Pastikan operasi berikut telah selesai di wilayah tempat instans yang dipercepat GPU berada:
Instans Enterprise Edition atau Personal Edition Container Registry dibuat. Kami merekomendasikan Anda membuat instans Enterprise Edition Container Registry. Untuk informasi lebih lanjut, lihat Dorong Gambar ke Instans Enterprise Edition Container Registry dan Tarik Gambar dari Instans.
Namespace dan repositori gambar dibuat. Untuk informasi lebih lanjut, lihat Dorong Gambar ke Instans Enterprise Edition Container Registry dan Tarik Gambar dari Instans dan Gunakan Instans Enterprise Edition Container Registry untuk Membangun Gambar.
Serverless Devs diinstal. Untuk informasi lebih lanjut, lihat Memulai Cepat.
Serverless Devs dikonfigurasi. Untuk informasi lebih lanjut, lihat Konfigurasi Serverless Devs.
1. Terapkan fungsi
Jalankan perintah berikut untuk mengkloning proyek:
git clone https://github.com/devsapp/start-fc-gpu.gitJalankan perintah berikut untuk masuk ke direktori proyek:
cd /root/start-fc-gpu/fc-http-gpu-inference-paddlehub-nlp-porn-detection-lstm/src/Potongan kode berikut menunjukkan struktur proyek.
. ├── hook │ └── index.js └── src ├── code │ ├── Dockerfile │ ├── app.py │ ├── hub_home │ │ ├── conf │ │ ├── modules │ │ └── tmp │ └── test │ └── client.py └── s.yamlJalankan perintah berikut untuk menggunakan Docker membangun gambar dan mendorong gambar ke repositori gambar Anda:
export IMAGE_NAME="registry.cn-shanghai.aliyuncs.com/fc-gpu-demo/paddle-porn-detection:v1" # sudo docker build -f ./code/Dockerfile -t $IMAGE_NAME . # sudo docker push $IMAGE_NAMEPentingKerangka kerja PaddlePaddle berukuran besar dan membutuhkan sekitar satu jam untuk membangun gambar untuk pertama kalinya. Function Compute menyediakan gambar publik berbasis VPC untuk Anda gunakan langsung. Jika Anda menggunakan gambar publik, Anda tidak perlu menjalankan perintah docker build atau docker push sebelumnya.
Edit file s.yaml.
edition: 3.0.0 name: container-demo access: default vars: region: cn-shanghai resources: gpu-best-practive: component: fc3 props: region: ${vars.region} description: This is the demo function deployment handler: not-used timeout: 1200 memorySize: 8192 cpu: 2 gpuMemorySize: 8192 diskSize: 512 instanceConcurrency: 1 runtime: custom-container environmentVariables: FCGPU_RUNTIME_SHMSIZE: '8589934592' customContainerConfig: image: >- registry.cn-shanghai.aliyuncs.com/serverless_devs/gpu-console-supervising:paddle-porn-detection port: 9000 internetAccess: true logConfig: enableRequestMetrics: true enableInstanceMetrics: true logBeginRule: DefaultRegex project: z**** logstore: log**** functionName: gpu-porn-detection gpuConfig: gpuMemorySize: 8192 gpuType: fc.gpu.tesla.1 triggers: - triggerName: httpTrigger triggerType: http triggerConfig: authType: anonymous methods: - GET - POSTJalankan perintah berikut untuk menerapkan fungsi:
sudo s deploy --skip-push true -t s.yamlSetelah eksekusi, URL dikembalikan dalam output. Salin URL ini untuk pengujian selanjutnya. Contoh URL:
https://gpu-poretection-****.cn-shanghai.fcapp.run.
2. Uji fungsi dan lihat data pemantauan
Jalankan perintah curl untuk memanggil fungsi. Potongan kode berikut memberikan contoh. URL yang diperoleh pada langkah sebelumnya digunakan dalam perintah ini.
curl https://gpu-poretection-gpu-****.cn-shanghai.fcapp.run/invoke -H "Content-Type: text/plain" --data "Nice to meet you"Jika keluaran berikut dikembalikan, pengujian berhasil.
[{"text": "Nice to meet you", "porn_detection_label": 0, "porn_detection_key": "not_porn", "porn_probs": 0.0, "not_porn_probs": 1.0}]%Masuk ke Konsol Function Compute. Di panel navigasi kiri, klik Functions. Pilih wilayah. Temukan fungsi yang ingin Anda kelola dan klik nama fungsi tersebut. Di halaman Rincian Fungsi, pilih untuk melihat perubahan metrik terkait GPU.
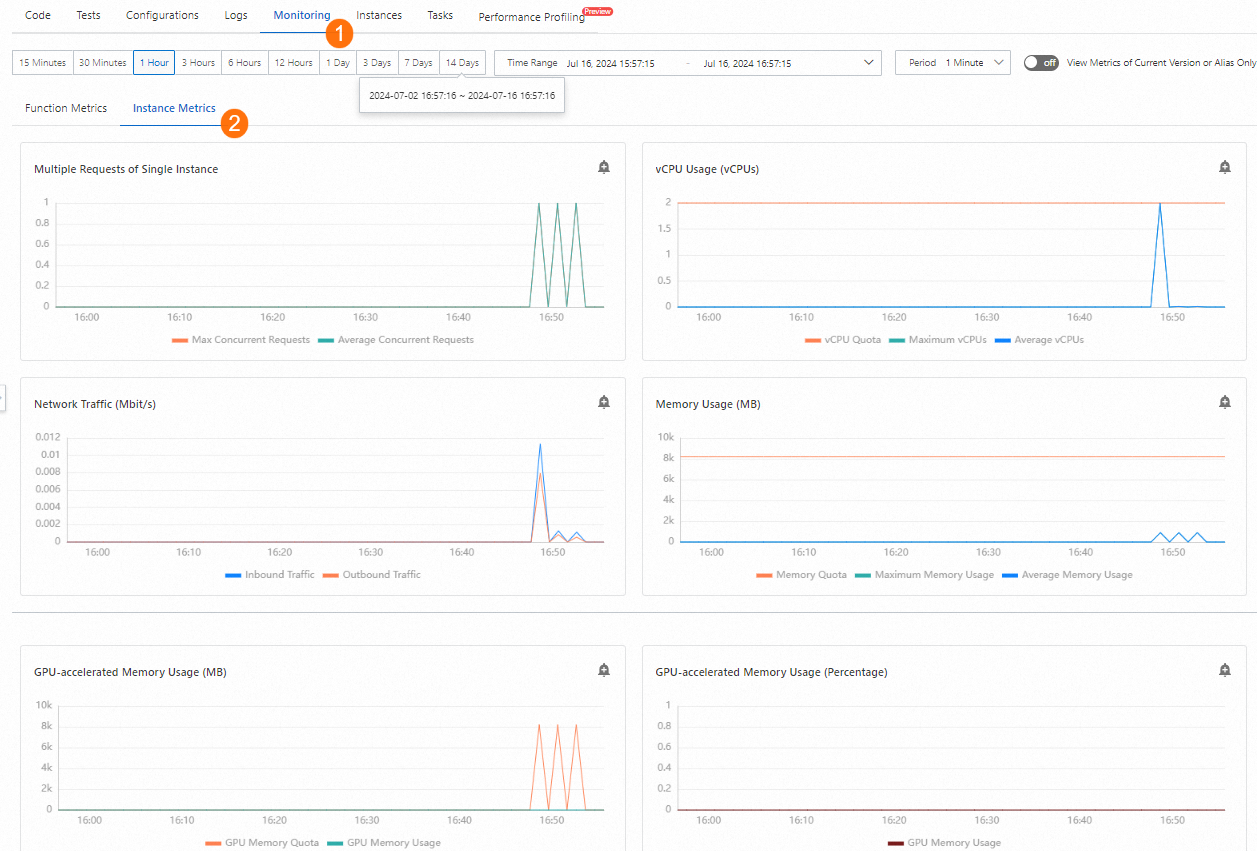
3. Konfigurasikan kebijakan penskalaan otomatis
Di direktori tempat file s.yaml berada, buat template provision.json.
Potongan kode berikut memberikan contoh template. Template ini menggunakan konkurensi instans sebagai metrik pelacakan. Jumlah instans minimum adalah 2 dan jumlah maksimum adalah 30.
{ "targetTrackingPolicies": [ { "name": "scaling-policy-demo", "startTime": "2024-07-01T16:00:00.000Z", "endTime": "2024-07-30T16:00:00.000Z", "metricType": "ProvisionedConcurrencyUtilization", "metricTarget": 0.3, "minCapacity": 2, "maxCapacity": 30 } ] }Jalankan perintah berikut untuk menerapkan kebijakan penskalaan:
sudo s provision put --target 1 --targetTrackingPolicies ./provision.json --qualifier LATEST -t s.yaml -a {access}Jalankan perintah
sudo s provision listuntuk verifikasi. Dalam output, nilaitargetdancurrentsama, yang berarti bahwa instans yang disediakan dialokasikan sesuai harapan dan kebijakan penskalaan otomatis berhasil diterapkan.[2023-05-10 14:49:03] [INFO] [FC] - Getting list provision: gpu-best-practive-service gpu-best-practive: - serviceName: gpu-best-practive-service qualifier: LATEST functionName: gpu-porn-detection resource: 143199913651****#gpu-best-practive-service#LATEST#gpu-porn-detection target: 1 current: 1 scheduledActions: null targetTrackingPolicies: - name: scaling-policy-demo startTime: 2024-07-01T16:00:00.000Z endTime: 2024-07-30T16:00:00.000Z metricType: ProvisionedConcurrencyUtilization metricTarget: 0.3 minCapacity: 2 maxCapacity: 30 currentError: alwaysAllocateCPU: trueModel Anda berhasil diterapkan dan siap digunakan ketika instans yang disediakan dibuat.
Lepaskan instans yang disediakan untuk suatu fungsi.
Jalankan perintah berikut untuk menonaktifkan kebijakan penskalaan otomatis dan atur jumlah instans yang disediakan menjadi 0:
sudo s provision put --target 0 --qualifier LATEST -t s.yaml -a {access}Jalankan perintah berikut untuk memeriksa apakah kebijakan penskalaan otomatis dinonaktifkan:
s provision list -a {access}Jika keluaran berikut dikembalikan, kebijakan penskalaan otomatis dinonaktifkan:
[2023-05-10 14:54:46] [INFO] [FC] - Getting list provision: gpu-best-practive-service End of method: provision
Gunakan konsol Function Compute
Prasyarat
Fungsi GPU telah dibuat. Untuk informasi lebih lanjut, lihat Buat Fungsi Custom Container.
Prosedur
Masuk ke Konsol Function Compute. Di panel navigasi kiri, klik Functions. Di bilah navigasi atas, pilih wilayah. Di halaman yang muncul, temukan fungsi yang ingin Anda kelola. Dalam konfigurasi fungsi, aktifkan metrik tingkat instans untuk fungsi tersebut.
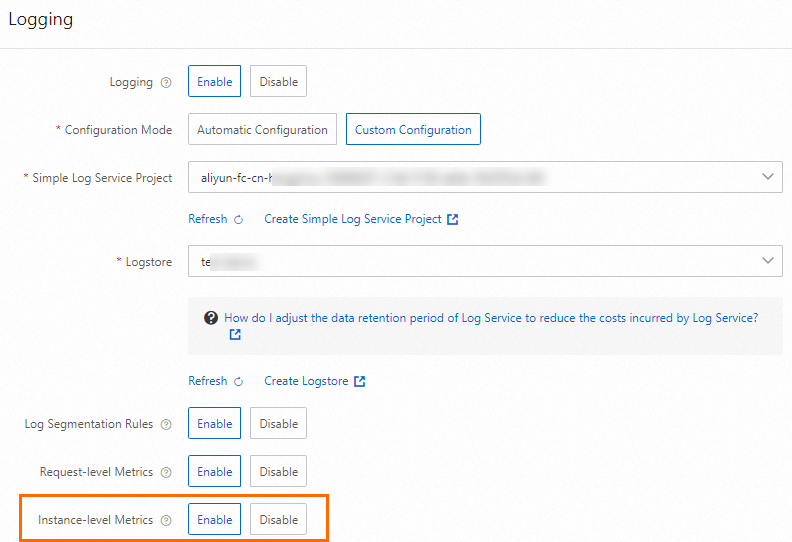
Di halaman Rincian Fungsi, pilih untuk mendapatkan URL pemicu HTTP untuk pengujian selanjutnya.
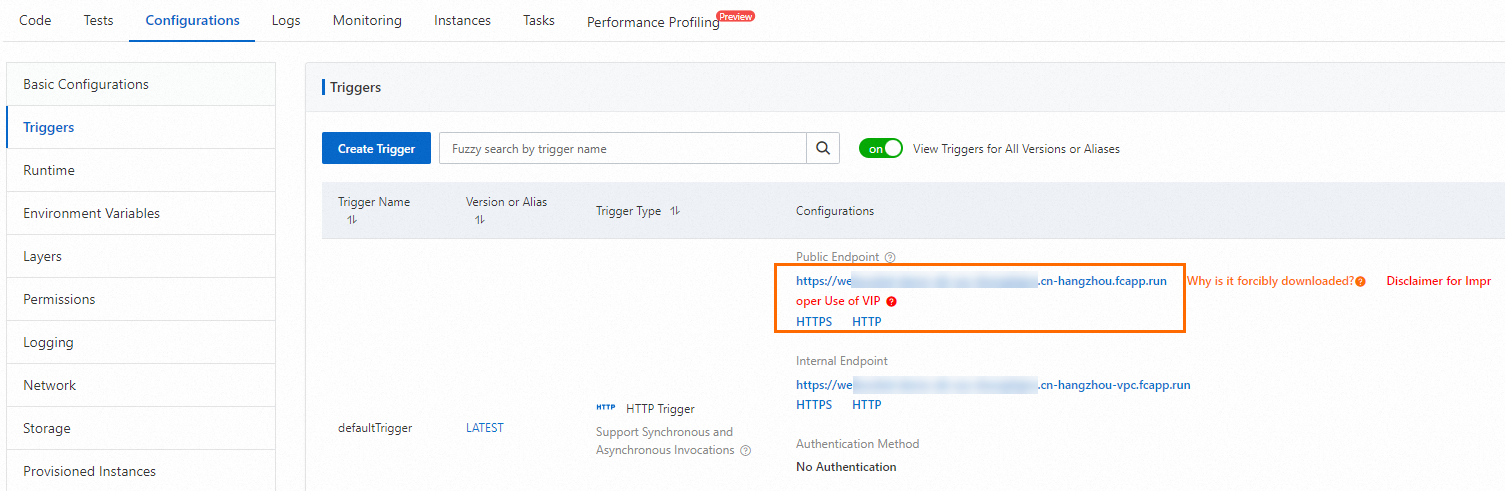
Jalankan perintah curl untuk menguji fungsi. Di halaman Rincian Fungsi, pilih untuk melihat perubahan metrik terkait GPU.
curl https://gpu-poretection****.cn-shanghai.fcapp.run/invoke -H "Content-Type: text/plain" --data "Nice to meet you"Di halaman Rincian Fungsi, pilih . Kemudian, klik Create Provisioned Instance Policy untuk mengonfigurasi kebijakan penskalaan otomatis.
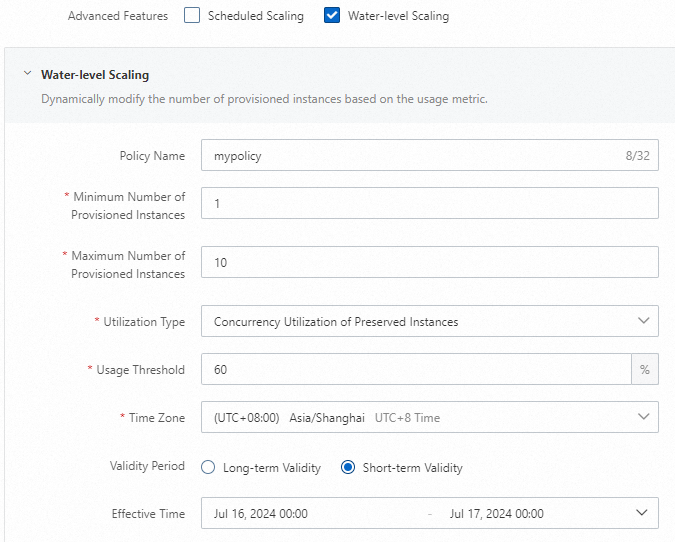
Setelah konfigurasi selesai, Anda dapat memilih di halaman Rincian Fungsi untuk melihat perubahan instans yang disiapkan.
Jika Anda tidak lagi memerlukan instans yang disiapkan dengan percepatan GPU, hapus instans tersebut sesegera mungkin.
Tanya Jawab Umum
Bagaimana saya dikenakan biaya untuk menggunakan layanan inferensi real-time di Function Compute?
Untuk informasi tentang penagihan Function Compute, lihat Ikhtisar Penagihan. Metode penagihan instans yang disiapkan berbeda dari instans on-demand. Perhatikan rincian tagihan Anda.
Mengapa latensi masih terjadi setelah saya mengonfigurasi kebijakan penskalaan otomatis?
Anda dapat menggunakan kebijakan penskalaan otomatis yang lebih agresif untuk menyediakan node terlebih dahulu guna mencegah tekanan kinerja yang disebabkan oleh lonjakan permintaan mendadak.
Mengapa jumlah instans tidak bertambah saat metrik pelacakan mencapai ambang batas?
Metrik Function Compute dikumpulkan pada tingkat menit. Mekanisme skala keluar hanya dipicu ketika nilai metrik tetap di atas ambang batas untuk periode waktu tertentu.