Pada 21 Februari 2024, Google secara resmi merilis Gemma, family model open-source pertamanya, dengan versi 2B dan 7B yang tersedia. Anda dapat menggunakan instans GPU dan mode idle Function Compute untuk mendeploy layanan model Gemma secara cepat dan hemat biaya.
Prasyarat
Function Compute telah diaktifkan. Untuk informasi selengkapnya, lihat Quick start.
Namespace dan repository image telah dibuat. Untuk informasi selengkapnya, lihat Create a namespace dan Create an image repository.
Prosedur
Saat Anda mendeploy layanan model Gemma, Anda dikenai biaya berdasarkan sumber daya yang digunakan, seperti sumber daya GPU, vCPU, memori, penggunaan disk, lalu lintas Internet keluar, dan pemanggilan fungsi. Untuk informasi selengkapnya, lihat Billing overview.
Buat aplikasi
Ikuti langkah-langkah berikut untuk mendapatkan nama domain dan alamat repository Container Registry (ACR) Anda.
Login ke Konsol Container Registry, pilih wilayah tempat fungsi Anda berada, lalu klik Manage pada kartu instans Edisi Perusahaan target.
Di panel navigasi kiri, klik Access Control, lalu pilih tab Internet. Aktifkan sakelar entri akses jika dalam keadaan mati. Untuk mengizinkan semua perangkat di internet login ke repository Anda, hapus semua daftar izin IP publik. Jika tidak, konfigurasikan daftar izin IP publik sesuai kebutuhan Anda. Setelah konfigurasi selesai, simpan Domain Name instans ACR tersebut.

Di panel navigasi kiri, klik Container Registry Repository, lalu klik Repository Name repository target untuk membuka halaman detail repository tersebut.
Simpan Public Endpoint repository tersebut.

Unduh bobot model Gemma. Anda dapat mengunduh model dari Hugging Face atau ModelScope. Topik ini menggunakan model Gemma-2b-it dari ModelScope sebagai contoh. Untuk informasi selengkapnya, lihat Gemma-2b-it.
PentingJika Anda menggunakan Git untuk mengunduh model, Anda harus terlebih dahulu menginstal ekstensi Git Large File Storage (LFS), jalankan
git lfs installuntuk menginisialisasi Git LFS, lalu jalankangit cloneuntuk mengunduh model. Jika tidak, model yang diunduh mungkin tidak lengkap karena ukurannya yang besar, sehingga layanan Gemma tidak dapat berjalan dengan benar.Buat Dockerfile dan file kode layanan model bernama
app.py.Dockerfile
FROM registry.cn-shanghai.aliyuncs.com/modelscope-repo/modelscope:fc-deploy-common-v17 WORKDIR /usr/src/app COPY . . RUN pip install -U transformers RUN pip install -U accelerate CMD [ "python3", "-u", "/usr/src/app/app.py" ] EXPOSE 9000app.py
from flask import Flask, request from transformers import AutoTokenizer, AutoModelForCausalLM model_dir = '/usr/src/app/gemma-2b-it' app = Flask(__name__) tokenizer = AutoTokenizer.from_pretrained(model_dir) model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto") @app.route('/invoke', methods=['POST']) def invoke(): request_id = request.headers.get("x-fc-request-id", "") print("FC Invoke Start RequestId: " + request_id) text = request.get_data().decode("utf-8") print(text) input_ids = tokenizer(text, return_tensors="pt").to("cuda") outputs = model.generate(**input_ids, max_new_tokens=1000) response = tokenizer.decode(outputs[0]) print("FC Invoke End RequestId: " + request_id) return str(response) + "\n" if __name__ == '__main__': app.run(debug=False, host='0.0.0.0', port=9000)Untuk informasi selengkapnya tentang semua Header HTTP yang didukung oleh Function Compute, lihat Common request headers.
Setelah menyelesaikan langkah ini, struktur direktori kode menjadi sebagai berikut:
. |-- app.py |-- Dockerfile `-- gemma-2b-it |-- config.json |-- generation_config.json |-- model-00001-of-00002.safetensors |-- model-00002-of-00002.safetensors |-- model.safetensors.index.json |-- README.md |-- special_tokens_map.json |-- tokenizer_config.json |-- tokenizer.json `-- tokenizer.model 1 directory, 12 filesJalankan perintah berikut untuk membuat dan mendorong gambar kontainer. Ganti
{REPO_ENDPOINT}dengan titik akhir publik repository image target yang diperoleh pada Langkah 1, dan ganti{REGISTRY}dengan Domain Name instans ACR.IMAGE_NAME={REPO_ENDPOINT}:gemma-2b-it docker login --username=mu****@test.aliyunid.com {REGISTRY} docker build -f Dockerfile -t $IMAGE_NAME . docker push $IMAGE_NAMEPentingJika Anda membuat image pada Mac dengan Apple silicon, ganti perintah
docker buildpada baris ke-3 dengan perintah berikut untuk membuat image yang kompatibel dengan Function Compute:docker build --platform linux/amd64 -f Dockerfile -t $IMAGE_NAME .Buat fungsi.
Login ke Konsol Function Compute. Di panel navigasi kiri, klik Function.
Di bilah navigasi atas, pilih wilayah. Pada halaman Function, klik Create Function.
Pada halaman Create Function, pilih Container Image, konfigurasikan parameter berikut, lalu klik Create.
Tabel berikut menjelaskan parameter utama. Gunakan nilai default untuk parameter lainnya.
Parameter
Deskripsi
Image Configurations
Image Selection Mode
Pilih Use ARC Images.
Container Image
Klik Select a Container Registry image di bawah, lalu pada panel Select Container Image, pilih image yang telah Anda dorong pada Langkah 3.
Listening Port
Atur parameter ini ke 9000.
Advanced Settings
GPU Acceleration
Pilih Enable GPU.
GPU Type
Pilih NVIDIA T4.
Specifications
GPU Memory Specifications: 16 GB.
vCPU Capacity: 2 vCPUs.
Memory Capacity: 16 GB.
Setelah status fungsi berubah menjadi OK, aktifkan mode idle untuk fungsi tersebut.

Pada halaman detail fungsi, klik tab Configuration. Di panel navigasi kiri, klik Provision Instance, lalu klik Create Provisioned Instance Policy.
Pada panel Create Provisioned Instance Policy, atur Version or Alias ke LATEST, atur Provisioned Instances ke 1, atur Idle Mode ke Enable, lalu klik OK.
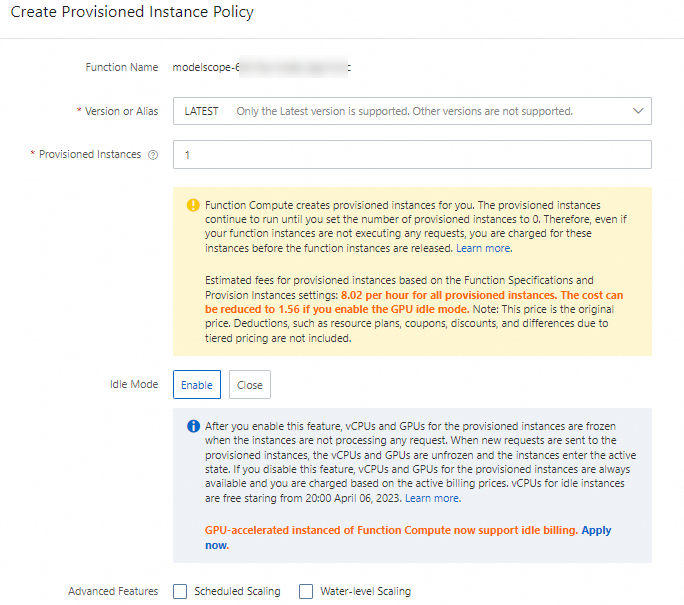
Setelah Current Provisioned Instances berubah menjadi 1 dan pesan Idle Mode Enabled muncul, instans yang disediakan untuk fungsi berakselerasi GPU berhasil dimulai.

Gunakan layanan Google Gemma
Pada halaman detail fungsi, klik tab Configuration. Di panel navigasi kiri, klik Trigger. Pada halaman Triggers, dapatkan URL trigger.
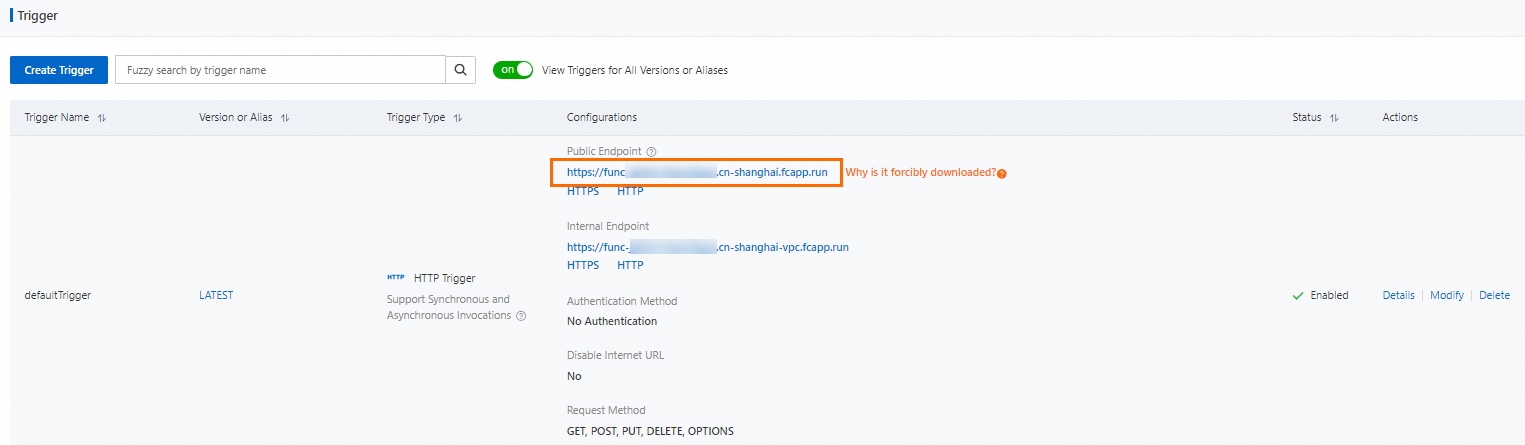
Jalankan perintah berikut untuk memanggil fungsi.
curl -X POST -d "who are you" https://func-i****-****.cn-shanghai.fcapp.run/invokeOutput yang diharapkan:
<bos>who are you? I am a large language model, trained by Google. I am a conversational AI that can understand and generate human language, and I am able to communicate and provide information in a comprehensive and informative way. What can I do for you today?<eos>Pada halaman detail fungsi, klik tab Instances. Temukan instans target dan klik Instance Metrics pada kolom Actions. Pada tab Instance Metrics, lihat metrik tersebut.
Anda dapat melihat bahwa penggunaan memori GPU instans turun ke nol saat tidak ada pemanggilan fungsi. Ketika permintaan pemanggilan fungsi baru tiba, Function Compute dengan cepat memulihkan dan mengalokasikan sumber daya memori GPU yang diperlukan. Hal ini membantu mengurangi biaya.
CatatanUntuk melihat metrik instans, Anda harus terlebih dahulu mengaktifkan fitur logging untuk instans tersebut. Untuk informasi selengkapnya, lihat Configure logging.
Setelah pemanggilan fungsi selesai, Function Compute secara otomatis menempatkan instans GPU ke dalam mode idle. Tidak diperlukan tindakan manual. Saat permintaan pemanggilan berikutnya tiba, Function Compute membangunkan instans tersebut dan mengaktifkannya untuk melayani permintaan.
Hapus sumber daya
Jika Anda tidak lagi memerlukan fungsi ini, hapus sumber dayanya untuk menghindari biaya tambahan. Jika Anda berencana menggunakan aplikasi ini dalam jangka panjang, lewati bagian ini.
Kembali ke halaman ikhtisar Konsol Function Compute. Di panel navigasi kiri, klik Function.
Temukan fungsi yang ingin dihapus, pilih pada kolom Actions. Pada kotak dialog yang muncul, pilih I confirm that I want to delete the above resources and this function. I understand that these resources cannot be retrieved after deletion., lalu klik Delete Function.
Penagihan
Uji coba gratis: Jika Anda pengguna Function Compute baru, Anda dapat mengklaim kuota percobaan untuk mencoba aplikasi yang disediakan dalam topik ini. Untuk informasi selengkapnya, lihat Trial quota. Kuota percobaan tidak mencakup biaya penggunaan disk. Anda dikenai biaya untuk penggunaan disk yang melebihi 512 MB dengan skema bayar sesuai penggunaan.
Untuk informasi selengkapnya tentang penagihan Function Compute, lihat Billing overview.
Referensi
Untuk informasi selengkapnya tentang Gemma, family model open-source dari Google, lihat gemma-open-models.
Untuk detail tentang mode idle dan contoh penagihan untuk instans GPU, lihat Billing overview.