Topik ini menjelaskan cara menggunakan layanan Model Studio untuk analisis data.
Informasi latar belakang
Model Studio adalah platform terpadu bagi pengembang AI dan tim bisnis untuk membangun aplikasi berbasis model bahasa besar (LLM). Platform ini mengintegrasikan secara mendalam kemampuan komputasi real-time dari Realtime Compute for Apache Flink. Anda dapat dengan cepat memanggil kemampuan LLM dari Model Studio dan menggabungkannya dengan pipeline pemrosesan data real-time Flink untuk memperpendek proses dari ingest data hingga pengambilan keputusan cerdas. Bagian-bagian berikut menjelaskan dua kasus penggunaan model inti:
Model chat/completions: Model chat/completions adalah LLM berbasis generasi dialog dan pemahaman teks. Model ini banyak digunakan dalam skenario seperti analisis sentimen, pengenalan maksud, dan sistem tanya-jawab.
Analisis sentimen: Melakukan klasifikasi sentimen secara real-time terhadap komentar media sosial bisnis Anda untuk mengidentifikasi sentimen pengguna sebagai positif, negatif, atau netral.
Layanan pelanggan cerdas: Menyediakan interaksi bahasa alami untuk sistem layanan pelanggan cerdas, didukung oleh kemampuan generasi dialog.
Moderasi konten: Mendeteksi secara otomatis konten sensitif atau pelanggaran kebijakan dalam teks guna meningkatkan efisiensi audit keamanan konten.
Model embedding: Model embedding mengonversi teks menjadi representasi vektor berdimensi tinggi. Aplikasi umumnya mencakup pencarian semantik, sistem rekomendasi, dan pembangunan graf pengetahuan.
Pencarian semantik: Memungkinkan pencarian semantik berbasis relevansi dengan melakukan vektorisasi deskripsi produk atau kueri pengguna.
Sistem rekomendasi: Menggunakan vektorisasi teks untuk menemukan keterkaitan antara minat pengguna dan fitur produk, sehingga meningkatkan akurasi rekomendasi.
Graf pengetahuan: Mengonversi teks tak terstruktur ke format vektor untuk menyederhanakan ekstraksi pengetahuan dan pemodelan hubungan selanjutnya.
Prasyarat
Anda telah mengaktifkan ruang kerja Flink. Untuk informasi lebih lanjut, lihat Aktifkan Realtime Compute for Apache Flink.
Anda telah mengaktifkan ruang kerja Model Studio dan menetapkan koneksi jaringan ke konsol pengembangan Realtime Compute for Apache Flink. Untuk mengakses Model Studio melalui VPC, lihat Akses API model atau aplikasi di Model Studio melalui jaringan pribadi.
Jika Anda mengakses Model Studio menggunakan nama domain, Anda harus mendaftarkannya di konsol pengembangan Realtime Compute for Apache Flink. Untuk informasi lebih lanjut, lihat Kelola nama domain.
Batasan
Fitur ini hanya didukung pada Ververica Runtime (VVR) 11.1 dan versi yang lebih baru.
Langkah 1: Daftarkan model Studio Model
Untuk informasi lebih lanjut, lihat Konfigurasikan model.
Model chat/completions
Kode SQL contoh berikut menunjukkan cara mendaftarkan model qwen-turbo:
CREATE MODEL ai_analyze_sentiment
INPUT (`input` STRING)
OUTPUT (`content` STRING)
WITH (
'provider'='bailian',
'endpoint'='<base_url>/compatible-mode/v1/chat/completions', -- Titik akhir untuk tugas model chat/completions.
'api-key' = '<YOUR KEY>',
'model'='qwen-turbo', -- Model Qwen-turbo.
'system-prompt' = 'Klasifikasikan teks di bawah ini ke dalam salah satu label berikut: [positive, negative, neutral, mixed]. Hanya tampilkan labelnya.'
);Ganti bagian <base_url> dari nilai parameter endpoint sesuai dengan metode akses Anda:
Untuk akses Internet ke Model Studio, ganti
<base_url>denganhttps://dashscope-intl.aliyuncs.com.Untuk akses jaringan pribadi ke Model Studio melalui VPC, ganti
<base_url>denganhttps://vpc-ap-southeast-1.dashscope.aliyuncs.com.CatatanParameter
endpointhanya mendukung protokol HTTPS.
Model embedding
Kode SQL contoh berikut menunjukkan cara mendaftarkan model text-embedding-v3:
CREATE MODEL embedding_model
INPUT (`input` STRING)
OUTPUT (`embeddings` ARRAY<FLOAT>)
WITH (
'provider'='bailian',
'endpoint'='https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings', -- Titik akhir untuk tugas model embedding.
'api-key' = '<YOUR KEY>',
'model'='text-embedding-v3' -- Model text-embedding-v3.
);Langkah 2: Buat pekerjaan
Buat draf pekerjaan streaming SQL. Untuk informasi lebih lanjut, lihat Pekerjaan Flink SQL.
Langkah 3: Tulis pekerjaan SQL untuk analisis LLM
Model chat/completions
Gunakan fungsi AI ML_PREDICT untuk memanggil model ai_analyze_sentiment yang telah didaftarkan dan melakukan analisis sentimen terhadap ulasan film.
Throughput operator Flink yang terkait dengan pernyataan ML_PREDICT dibatasi lajunya oleh Model Studio. Ketika batas permintaan ke Model Studio tercapai, tekanan balik terjadi pada pekerjaan Flink, dan operator ML_PREDICT menjadi bottleneck. Pembatasan laju yang parah dapat memicu error timeout pada operator terkait, yang menyebabkan pekerjaan restart. Anda dapat memeriksa kondisi pembatasan laju untuk berbagai model di Model Studio. Untuk informasi lebih lanjut, lihat Batasan QPS dan token. Anda juga dapat menghubungi manajer bisnis atau spesialis pra-penjualan dan purna-jual untuk mengetahui cara menghapus batasan tersebut.
Salin kode SQL contoh berikut ke editor SQL.
-- Buat tabel sink temporary.
CREATE TEMPORARY TABLE print_sink(
id BIGINT,
movie_name VARCHAR,
predict_label VARCHAR,
actual_label VARCHAR
) WITH (
'connector' = 'print', -- Gunakan konektor print.
'logger' = 'true' -- Tampilkan hasil di konsol.
);
-- Buat tampilan data temporary untuk membuat data uji.
-- | id | movie_name | comment | actual_label |
-- | 1 | Her Story | My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving. | POSITIVE |
-- | 2 | The Dumpling Queen | Unremarkable. | NEGATIVE |
CREATE TEMPORARY VIEW movie_comment(id, movie_name, user_comment, actual_label)
AS VALUES (1, 'Her Story', 'My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving.', 'positive'), (2, 'The Dumpling Queen', 'Unremarkable.', 'negative');
INSERT INTO print_sink
SELECT id, movie_name, content as predict_label, actual_label
FROM ML_PREDICT(
TABLE movie_comment,
MODEL ai_analyze_sentiment, -- Model Qwen-turbo yang telah didaftarkan.
DESCRIPTOR(user_comment)); Model embedding
Gunakan fungsi AI ML_PREDICT untuk memanggil model embedding_model yang telah didaftarkan, menghasilkan embedding untuk ulasan film, lalu menulis hasilnya ke Milvus (pratinjau publik).
Throughput operator Flink yang terkait dengan pernyataan ML_PREDICT dibatasi lajunya oleh Model Studio. Ketika batas permintaan ke Model Studio tercapai, tekanan balik terjadi pada pekerjaan Flink, dan operator ML_PREDICT menjadi bottleneck. Pembatasan laju yang parah dapat memicu error timeout pada operator terkait, yang menyebabkan pekerjaan restart. Anda dapat memeriksa kondisi pembatasan laju untuk berbagai model di Model Studio. Untuk informasi lebih lanjut, lihat Batasan QPS dan token. Anda juga dapat menghubungi manajer bisnis atau spesialis pra-penjualan dan purna-jual untuk mengetahui cara menghapus batasan tersebut.
Salin kode SQL contoh berikut ke editor SQL.
-- Buat tabel sink temporary bernama milvus_sink.
CREATE TEMPORARY TABLE milvus_sink
(
id STRING,
movie_name STRING,
user_comment STRING,
embeddings ARRAY<FLOAT>,
PRIMARY KEY (id) NOT ENFORCED
)
WITH (
'connector' = 'milvus',
'endpoint' = '<YOUR-ENDPOINT>',
'port' = '<YOUR-PORT>',
'userName' = '<YOUR-USERNAME>',
'password' = '<YOUR-PASSWORD>',
'databaseName' = 'default',
'collectionName' = 'movie-comment-embeddings'
);
-- Buat tampilan data temporary untuk membuat data uji.
-- | id | movie_name | comment |
-- | 1 | Her Story |My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving.|
-- | 2 | The Dumpling Queen | Unremarkable. |
CREATE TEMPORARY VIEW movie_comment(id, movie_name, user_comment)
AS VALUES ('1', 'Her Story', 'My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving.'), ('2', 'The Dumpling Queen', 'Unremarkable.');
INSERT INTO
milvus_sink
SELECT
id,
movie_name,
user_comment,
embeddings
FROM
ML_PREDICT (
TABLE movie_comment,
MODEL embedding_model, -- Model text-embedding-v3 yang telah didaftarkan.
DESCRIPTOR (user_comment)
);Langkah 4: Sebarkan dan jalankan pekerjaan
Sebarkan dan jalankan pekerjaan. Untuk informasi lebih lanjut, lihat Pekerjaan Flink SQL.
Langkah 5: Lihat hasil analisis
Model chat/completions
Verifikasi bahwa status pekerjaan adalah FINISHED.
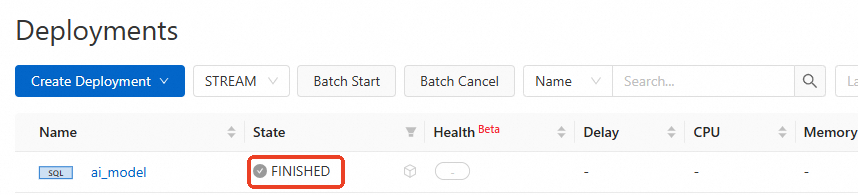
Di konsol , buka halaman Deployments dan klik nama pekerjaan target.
Di tab Logs, klik subtab Task Managers dan pilih current TaskManager.
Klik Log dan cari log yang terkait dengan PrintSinkOutputWriter.
Label prediksi model
predict_labelcocok dengan label aktualactual_label.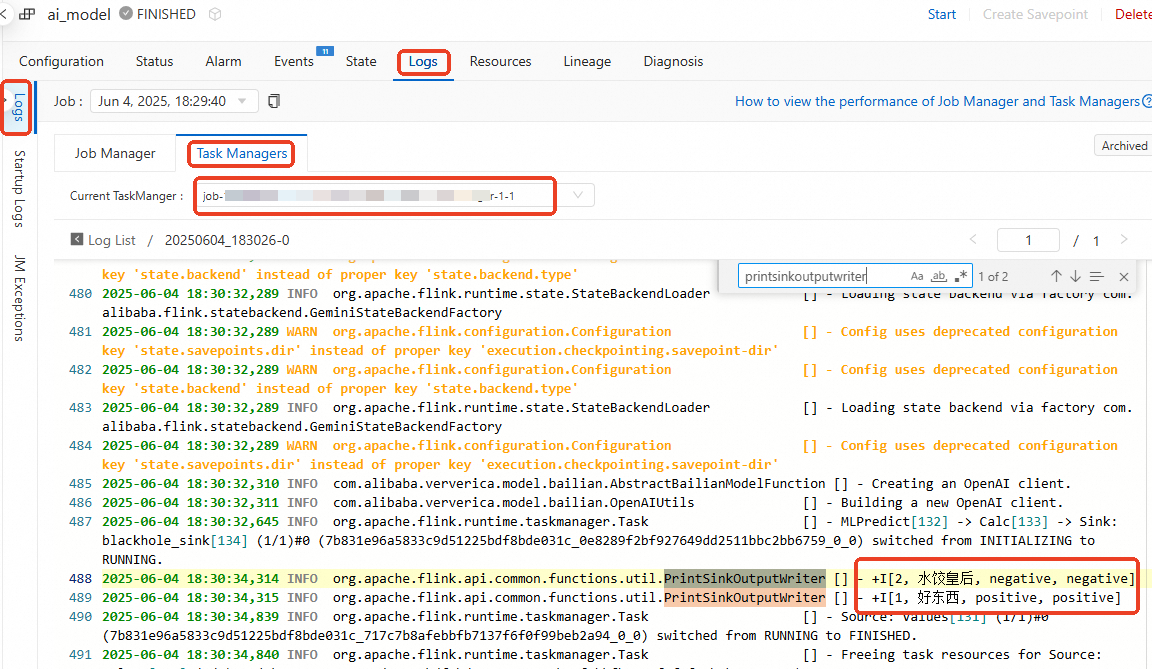
Dokumen terkait
Pernyataan Data Definition Language (DDL) untuk model AI: Konfigurasikan model
Fungsi AI: ML_PREDICT
Layanan pencarian vektor: Milvus (pratinjau publik)