Topik ini menjelaskan cara membangun danau data terpadu (data lakehouse) yang mengintegrasikan pemrosesan aliran dan batch menggunakan tabel materialized. Topik ini juga menjelaskan cara menyesuaikan tingkat kesegaran data pada tabel materialized untuk beralih dari pemrosesan batch ke stream processing serta mengaktifkan pembaruan data real-time.
Pengenalan tabel materialized
Tabel materialized adalah jenis tabel baru dalam Flink SQL yang menyederhanakan pipa data pemrosesan batch dan aliran serta menyediakan pengalaman pengembangan terintegrasi. Saat membuat tabel materialized, Anda tidak perlu mendeklarasikan bidang atau tipe datanya—cukup tentukan tingkat kesegaran data dan pernyataan kueri. Mesin Flink secara otomatis melakukan inferensi skema tabel materialized dari pernyataan kueri tersebut dan membuat pipa data untuk mempertahankan tingkat kesegaran data yang ditentukan. Untuk informasi selengkapnya, lihat Manajemen tabel materialized.
Diagram pipa data lakehouse real-time
-
Flink membuat lapisan Operational Data Store (ODS) dengan menulis data dari sumber data ke Paimon.
-
Flink membuat lapisan DWD dengan melakukan join dan memperkaya data dari lapisan ODS, lalu menulis hasilnya ke tabel materialized.
-
Anda dapat membuat lapisan layanan gudang data (DWS) untuk kueri aplikasi dengan membangun beberapa tabel materialized yang memiliki tingkat kesegaran data berbeda dan melakukan statistik bisnis multi-dimensi.

Prasyarat
-
Ruang kerja Realtime Compute for Apache Flink telah dibuat. Untuk informasi selengkapnya, lihat Aktifkan Realtime Compute for Apache Flink.
-
Jika Anda menggunakan pengguna Resource Access Management (RAM) atau Peran RAM, pastikan pengguna atau peran tersebut memiliki izin yang diperlukan untuk mengakses Konsol Realtime Compute for Apache Flink. Untuk informasi selengkapnya, lihat Manajemen izin.
Langkah 1: Siapkan data uji
-
(Opsional) Buat katalog Paimon.
Fitur tabel materialized didasarkan pada Apache Paimon. Anda harus membuat katalog Paimon dengan tipe metastore Filesystem . Jika Anda sudah membuatnya, langkah ini dapat dilewati. Untuk informasi selengkapnya, lihat Buat katalog Paimon.
-
Masuk ke Konsol Realtime Compute for Apache Flink.
-
Pada kolom Actions ruang kerja yang dituju, klik Console.
-
Di panel navigasi sebelah kiri, pilih Data Management dan klik Create Catalog. Lalu, pilih Apache Paimon dan klik Next.
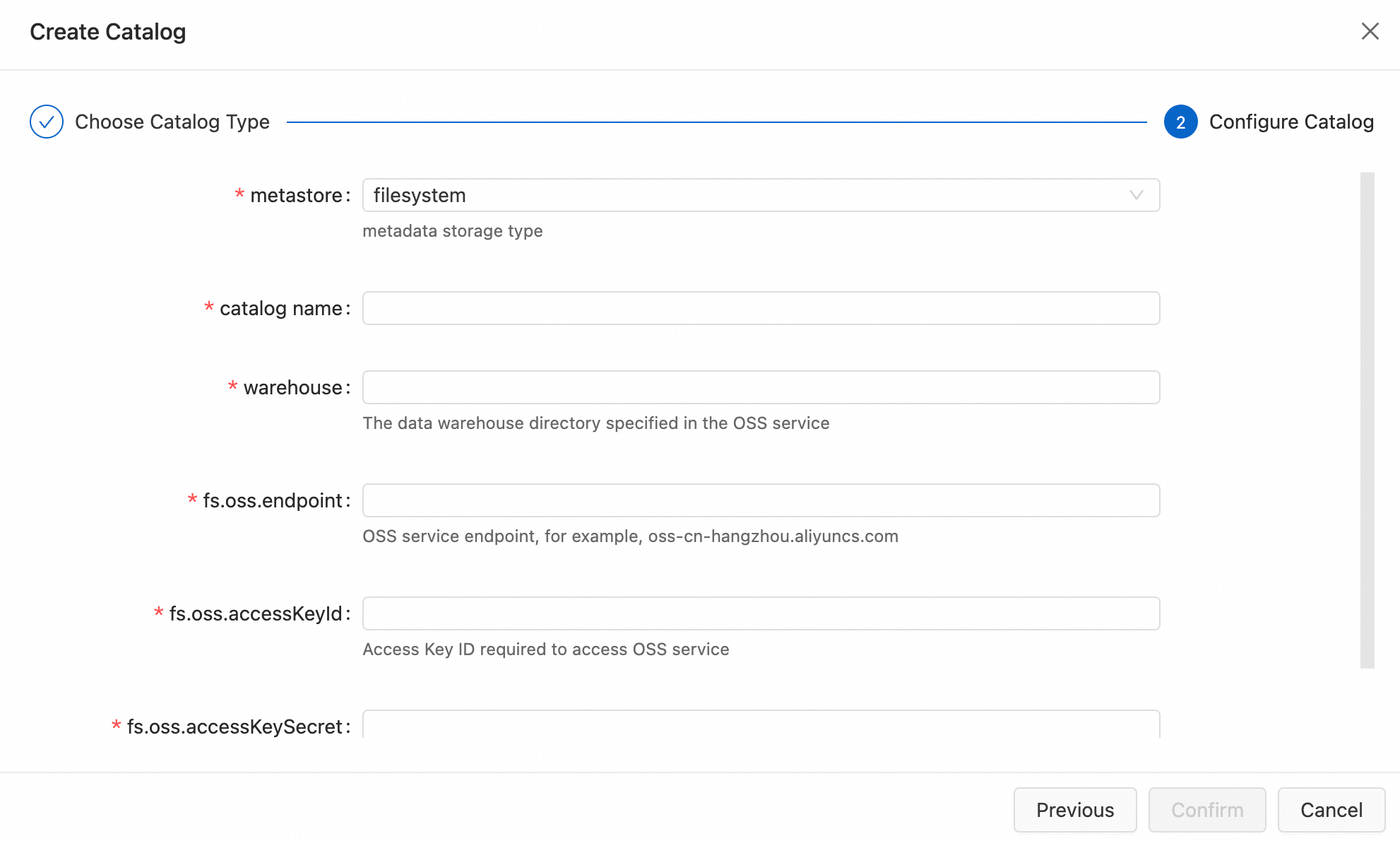
Deskripsi parameter:
Parameter
Deskripsi
Catatan
metastore
Tipe metastore.
Dalam contoh ini, digunakan Filesystem.
catalog name
Nama katalog Paimon.
Masukkan nama kustom. Contoh ini menggunakan paimon.
warehouse
Direktori gudang data di Object Storage Service (OSS).
Formatnya adalah
oss://<bucket>/<object>, dengan:-
<bucket>: Nama bucket OSS Anda.
-
`` adalah path tempat data Anda disimpan.
Anda dapat melihat nama bucket dan objek Anda di Konsol OSS.
fs.oss.endpoint
Titik akhir layanan OSS.
Jika Flink dan OSS berada di Wilayah yang sama, gunakan titik akhir internal. Jika tidak, gunakan titik akhir publik. Untuk informasi selengkapnya, lihat Wilayah dan titik akhir.
fs.oss.accessKeyId
ID AccessKey dari Akun Alibaba Cloud atau Pengguna RAM yang memiliki izin baca dan tulis pada OSS.
Untuk informasi selengkapnya tentang cara mendapatkan Pasangan Kunci Akses, lihat Buat Pasangan Kunci Akses. Untuk mencegah Pasangan Kunci Akses Anda terekspos dalam teks biasa, kami menyarankan Anda menggunakan variabel. Untuk informasi selengkapnya, lihat Kelola variabel.
fs.oss.accessKeySecret
Rahasia AccessKey dari Akun Alibaba Cloud atau Pengguna RAM yang memiliki izin baca dan tulis pada OSS.
-
-
-
Buat tabel ods_user_log dan ods_dim_product.
-
Masuk ke Konsol Realtime Compute for Apache Flink.
-
Untuk ruang kerja yang dituju, klik Console di kolom Actions.
-
Di panel navigasi sebelah kiri, pilih . Salin dan tempel kode berikut untuk membuat tabel sumber.
Contoh ini menggunakan katalog Paimon bernama paimon dan database default.
CREATE TABLE `paimon`.`default`.`ods_user_log` ( item_id INT NOT NULL, user_id INT NOT NULL, vtime TIMESTAMP(6), ds VARCHAR(10) NOT NULL ) PARTITIONED BY(ds) WITH ( 'bucket' = '4', -- Tentukan 4 bucket. 'bucket-key' = 'item_id' -- Tentukan kunci bucket. Data dengan item_id yang sama ditempatkan di bucket yang sama. ); CREATE TABLE `paimon`.`default`.`ods_dim_product` ( item_id INT NOT NULL, title VARCHAR(255), pict_url VARCHAR(255), brand_id INT, seller_id INT, PRIMARY KEY(item_id) NOT ENFORCED ) WITH ( 'bucket' = '4', 'bucket-key' = 'item_id' ); -
Klik Run di pojok kanan atas untuk membuat tabel data yang sesuai.
-
Di panel navigasi sebelah kiri, pilih Data Management. Lalu, klik Katalog Paimon yang sesuai dan klik Refresh untuk melihat tabel baru.
-
-
Gunakan konektor Faker data generator untuk menghasilkan data simulasi dan menulis data tersebut ke tabel Paimon.
-
Di panel navigasi sebelah kiri, pilih .
-
Klik New, pilih Blank Stream Draft, klik Next, lalu klik Create.
-
Salin pernyataan SQL berikut ke editor.
CREATE TEMPORARY TABLE `user_log` ( item_id INT, // ID Produk user_id INT, // ID Pengguna vtime TIMESTAMP, ds AS DATE_FORMAT(CURRENT_DATE,'yyyyMMdd') ) WITH ( 'connector' = 'faker', -- Konektor Faker 'fields.item_id.expression'='#{number.numberBetween ''0'',''1000''}', -- Hasilkan bilangan acak antara 0 dan 1000. 'fields.user_id.expression'='#{number.numberBetween ''0'',''100''}', 'fields.vtime.expression'='#{date.past ''5'',''HOURS''}', -- Hasilkan data dari 5 jam terakhir berdasarkan tanggal dan waktu saat ini. 'rows-per-second' = '3' -- Hasilkan 3 baris per detik. ); CREATE TEMPORARY TABLE `dim_product` ( item_id INT NOT NULL, title VARCHAR(255), pict_url VARCHAR(255), brand_id INT, seller_id INT, PRIMARY KEY(item_id) NOT ENFORCED ) WITH ( 'connector' = 'faker', -- Konektor Faker 'fields.item_id.expression'='#{number.numberBetween ''0'',''1000''}', 'fields.title.expression'='#{book.title}', 'fields.pict_url.expression'='#{internet.domainName}', 'fields.brand_id.expression'='#{number.numberBetween ''1000'',''10000''}', 'fields.seller_id.expression'='#{number.numberBetween ''1000'',''10000''}', 'rows-per-second' = '3' -- Hasilkan 3 baris per detik. ); BEGIN STATEMENT SET; INSERT INTO `paimon`.`default`.`ods_user_log` SELECT item_id, user_id, vtime, CAST(ds AS VARCHAR(10)) AS ds FROM `user_log`; INSERT INTO `paimon`.`default`.`ods_dim_product` SELECT item_id, title, pict_url, brand_id, seller_id FROM `dim_product`; END; -
Di pojok kanan atas, klik Deploy.
-
Di panel navigasi sebelah kiri, klik . Untuk penerapan yang dituju, klik Start di kolom Actions, pilih Stateless Start, lalu klik Start.
-
-
Kueri data simulasi.
Di panel navigasi sebelah kiri, pilih . Salin pernyataan SQL berikut ke editor SQL dan klik Run di pojok kanan atas.
SELECT * FROM `paimon`.`default`.ods_dim_product LIMIT 10; SELECT * FROM `paimon`.`default`.ods_user_log LIMIT 10;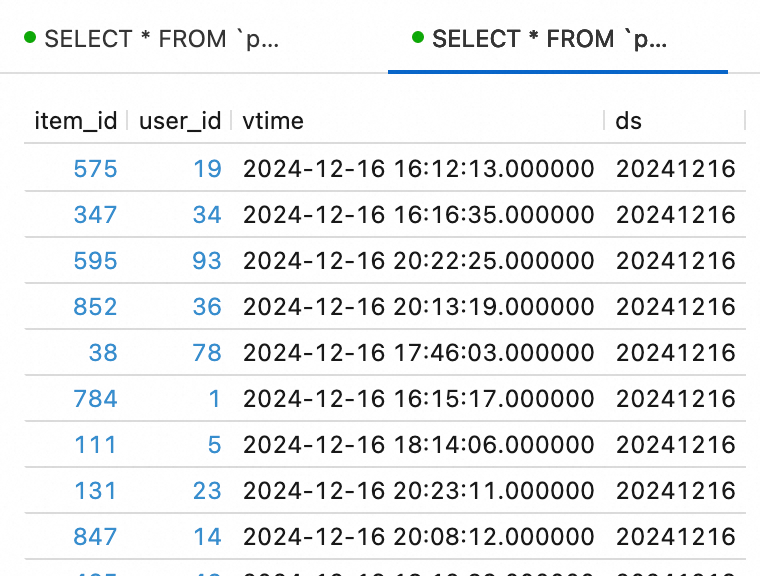
Langkah 2: Membuat tabel materialisasi
Bagian ini menjelaskan cara membuat tabel materialized `dwd_user_log_product` untuk lapisan DWD dengan melakukan join pada tabel sumber. Anda kemudian akan membangun lapisan DWS dengan membuat tabel materialized turunan berdasarkan tabel `dwd_user_log_product` untuk melakukan analitik bisnis.
-
Bangun lapisan DWD gudang data dengan membuat tabel materialized dwd_user_log_product.
-
Di panel navigasi sebelah kiri, pilih Data Management dan klik Katalog Paimon yang dituju.
-
Klik database yang dituju ("default" dalam contoh ini), lalu klik Create Materialized Table. Salin pernyataan SQL berikut ke editor SQL dan klik Create.
-- Logika pelebaran lapisan DWD CREATE MATERIALIZED TABLE dwd_user_log_product( PRIMARY KEY (item_id) NOT ENFORCED ) PARTITIONED BY(ds) WITH ( 'partition.fields.ds.date-formatter' = 'yyyyMMdd' ) FRESHNESS = INTERVAL '1' HOUR -- Segarkan setiap 1 jam. AS SELECT l.ds, l.item_id, l.user_id, l.vtime, r.brand_id, r.seller_id FROM `paimon`.`default`.`ods_user_log` l INNER JOIN `paimon`.`default`.`ods_dim_product` r ON l.item_id = r.item_id;
-
-
Bangun lapisan DWS gudang data dan lakukan analitik bisnis multi-dimensi berdasarkan tabel materialized dwd_user_log_product.
Topik ini menggunakan pembuatan tabel materialized `dws_overall` sebagai contoh. Tabel ini menghitung jumlah tampilan halaman (PV) dan pengunjung unik (UV) harian per jam. Anda dapat membuat tabel materialized `dws_overall` dengan mengikuti langkah-langkah pada bagian sebelumnya.
// Hitung PV dan UV harian. CREATE MATERIALIZED TABLE dws_overall( PRIMARY KEY(ds, hh) NOT ENFORCED ) PARTITIONED BY(ds) WITH ( 'partition.fields.ds.date-formatter' = 'yyyyMMdd' ) FRESHNESS = INTERVAL '1' HOUR -- Segarkan setiap 1 jam. AS SELECT ds, COALESCE(hh, 'day') AS hh, count(*) AS pv, count(distinct user_id) AS uv FROM (SELECT ds, date_format(vtime, 'HH') AS hh, user_id FROM `paimon`.`default`.`dwd_user_log_product`) tmp GROUP BY GROUPING SETS(ds, (ds, hh));
Langkah 3: Perbarui tabel materialized
Mulai pembaruan
Dalam contoh ini, tingkat kesegaran data adalah 1 jam. Setelah Anda mengklik Start Update, pembaruan data akan tertinggal setidaknya 1 jam dari tabel dasar.
-
Di panel navigasi sebelah kiri, klik Data Lineage, lalu cari tabel materialized yang dituju.
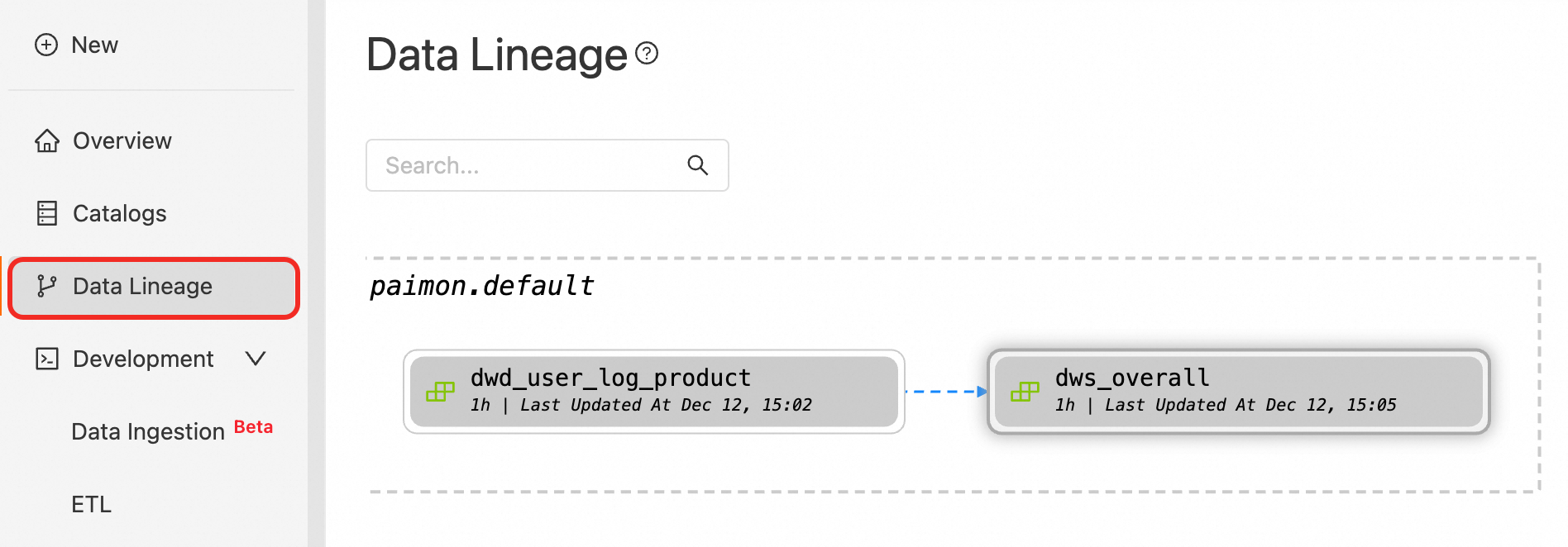
-
Klik tampilan tabel materialized yang sesuai, lalu klik Start Update di pojok kanan bawah halaman.
Isi ulang data
Pengisian ulang data memungkinkan Anda menulis ulang data historis untuk partisi tertentu atau seluruh tabel. Ini dapat digunakan untuk memperbaiki hasil stream processing. Untuk pekerjaan batch yang belum mencapai waktu jadwalnya, Anda juga dapat mengisi ulang data agar segera ditulis dan diperbarui.
Pilih tampilan tabel materialized dwd_user_log_product dan klik Manual Update di pojok kanan bawah halaman. Di kotak dialog yang muncul, masukkan tanggal runtime sebagai nama partisi, misalnya 20241216. Centang kotak Cascade Update Downstream Associated Materialized Tables dan klik Confirm. Di kotak dialog konfirmasi, klik Confirm lagi untuk menimpa data yang sesuai dan memulai pembaruan.
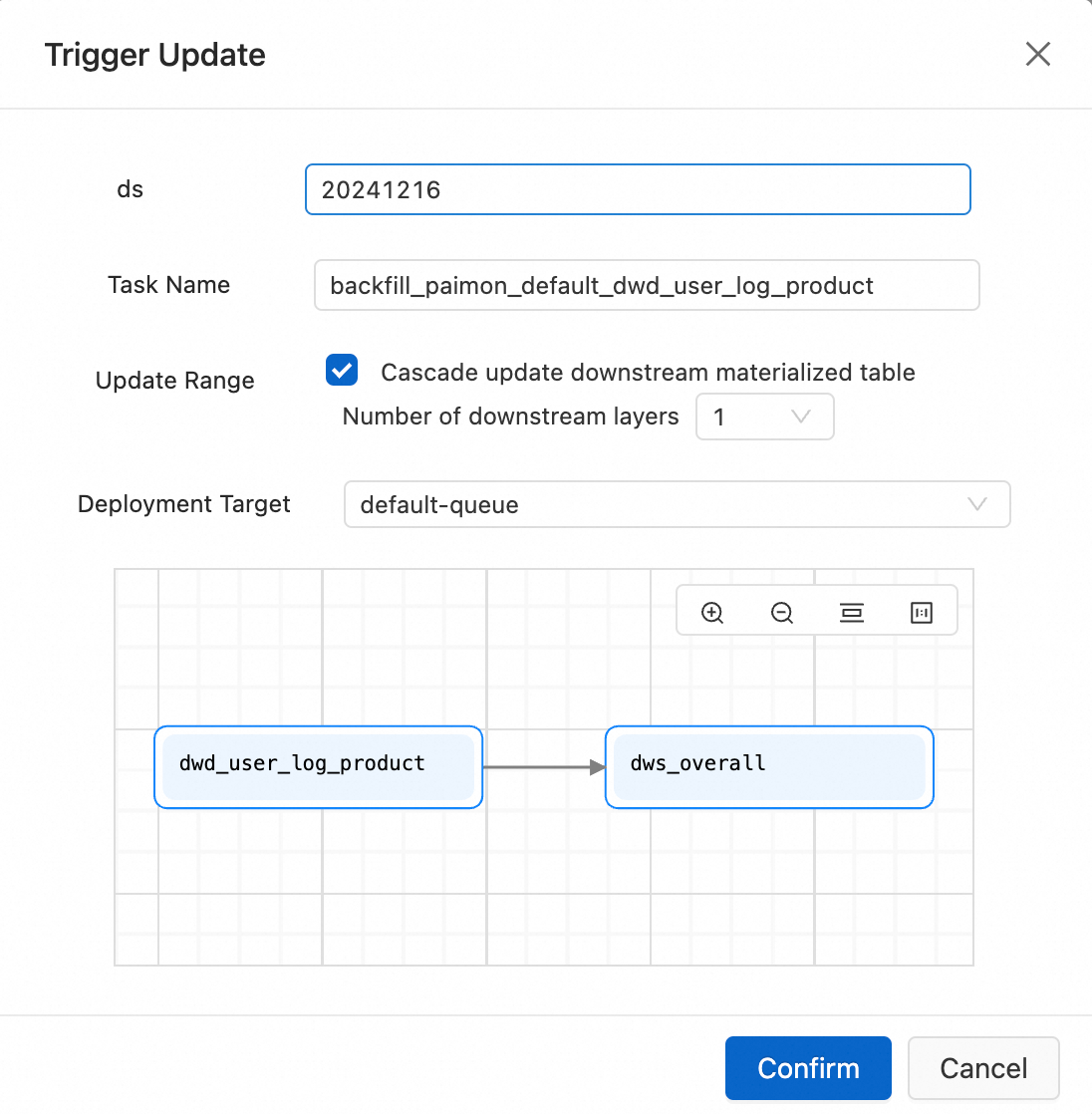
Untuk informasi selengkapnya tentang cara mengisi ulang data, lihat Isi ulang data historis.
Ubah tingkat kesegaran data
Anda dapat mengubah tingkat kesegaran data untuk memperbarui tabel materialized setiap hari, setiap jam, setiap menit, atau setiap detik sesuai kebutuhan.
Untuk mengubah tingkat kesegaran data tabel materialized dwd_user_log_product dan dws_overall, klik tampilan tabel yang dituju. Lalu, klik Modify Data Freshness di pojok kanan bawah halaman dan atur tingkat kesegaran data ke level menit untuk pembaruan real-time.
Untuk informasi selengkapnya tentang cara mengubah tingkat kesegaran data, lihat Ubah tingkat kesegaran data.
Langkah 4: Kueri tabel materialized
Pratinjau data
Anda dapat melihat pratinjau 100 baris data terbaru dalam tabel materialized.
-
Di panel navigasi sebelah kiri, Anda dapat mengklik Data Lineage dan mencari tabel materialized yang dituju.
-
Setelah mengklik tampilan tabel materialized yang dituju, klik Details di pojok kanan bawah halaman.
-
Pada tab Data Preview, klik ikon Query.
Kueri data
Di panel navigasi sebelah kiri, buka . Salin pernyataan SQL berikut ke editor SQL, pilih potongan kode tersebut, lalu klik Run untuk mengkueri tabel materialized dws_overall.
SELECT * FROM `paimon`.`default`.dws_overall ORDER BY hh;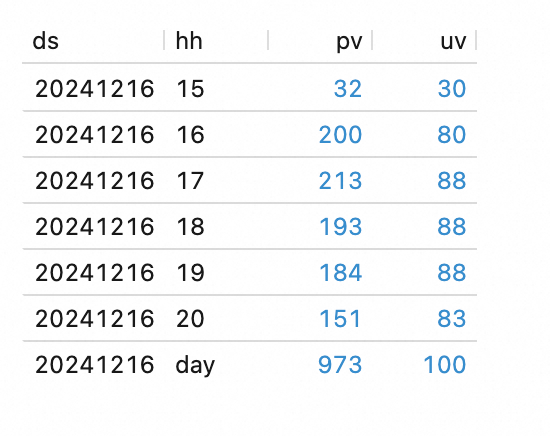
Referensi
-
Untuk informasi selengkapnya tentang tabel materialized, lihat Manajemen tabel materialized.
-
Untuk informasi selengkapnya tentang cara membuat dan menggunakan tabel materialized, lihat Buat dan gunakan tabel materialized.