Tutorial ini menyediakan contoh konkret untuk menunjukkan cara menggunakan fitur utama Realtime Compute for Apache Flink dalam pemrosesan batch.
Fitur
Realtime Compute for Apache Flink menyediakan fitur utama berikut untuk mendukung pemrosesan batch Flink:
Peta pengembangan pekerjaan: Pada tab Drafts halaman SQL Editor, Anda dapat membuat draft batch yang kemudian diterapkan dan dieksekusi sebagai deployment batch.
Manajemen deployment: Pada halaman Deployments, Anda dapat langsung menerapkan deployment batch JAR atau Python. Pilih BATCH dari daftar drop-down di bagian atas untuk melihat deployment batch yang telah diterapkan. Perluas deployment batch target untuk melihat daftar instans pekerjaannya. Biasanya, instans pekerjaan dari satu deployment batch berbagi logika pemrosesan yang sama tetapi menggunakan parameter berbeda, seperti tanggal data yang diproses.
Kueri data: Pada tab Scripts halaman SQL Editor, Anda dapat menjalankan pernyataan DDL atau kueri singkat untuk manajemen dan eksplorasi data cepat. Kueri singkat ini dijalankan dalam sesi Flink yang telah dibuat sebelumnya, memungkinkan eksekusi kueri sederhana dengan latensi rendah melalui penggunaan ulang resource.
Manajemen data: Pada halaman Catalogs, Anda dapat membuat dan melihat katalog, termasuk database dan tabel yang dikandungnya. Anda juga dapat melihatnya pada tab Catalogs halaman SQL Editor untuk meningkatkan efisiensi pengembangan.
Orkestrasi tugas (Pratinjau Publik): Pada halaman Workflows, Anda dapat menggunakan antarmuka visual untuk mendefinisikan alur kerja yang mengatur dependensi di antara deployment batch. Anda dapat memicu alur kerja secara manual atau menjadwalkannya agar berjalan secara berkala.
Mengelola antrian resource: Pada halaman Queue Management, Anda dapat mempartisi resource dalam ruang kerja untuk mencegah konflik sumber daya antara deployment stream dan batch, serta di antara deployment dengan prioritas berbeda.
Prasyarat
Anda telah membuat ruang kerja Realtime Compute for Apache Flink. Untuk informasi lebih lanjut, lihat Aktifkan Realtime Compute for Apache Flink.
Anda telah mengaktifkan Object Storage Service (OSS). Untuk informasi lebih lanjut, lihat Panduan cepat konsol. Kelas penyimpanan bucket OSS harus Standard. Untuk informasi lebih lanjut, lihat Kelas penyimpanan.
Tutorial ini menggunakan Apache Paimon untuk menyimpan data dan memerlukan Ververica Runtime (VVR) 8.0.5 atau versi yang lebih baru.
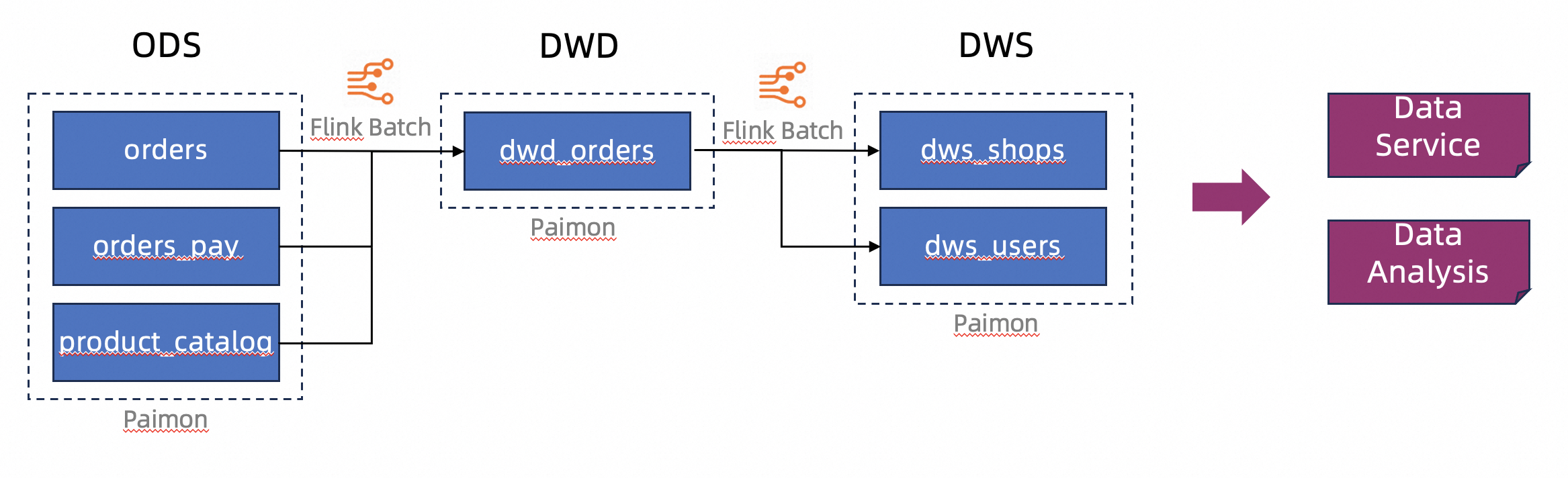
Skenario contoh
Tutorial ini menggunakan platform e-commerce sebagai contoh, di mana data disimpan dalam format danau data terpadu Apache Paimon. Tutorial ini mensimulasikan struktur gudang data dengan beberapa lapisan: Operational Data Store (ODS), Data Warehouse Detail (DWD), dan Data Warehouse Service (DWS). Anda akan menggunakan kemampuan pemrosesan batch Flink untuk memproses dan membersihkan data sebelum menuliskannya ke tabel Paimon guna membangun struktur data berlapis.
Persiapan
Buat skrip.
Pada tab Scripts, Anda dapat membuat katalog yang berisi database dan tabel, serta memasukkan data sampel ke dalam tabel tersebut.
Buat katalog Paimon.
Pada editor di tab Scripts, masukkan pernyataan SQL berikut.
CREATE CATALOG `my_catalog` WITH ( 'type' = 'paimon', 'metastore' = 'filesystem', 'warehouse' = '<warehouse>', 'fs.oss.endpoint' = '<fs.oss.endpoint>', 'fs.oss.accessKeyId' = '<fs.oss.accessKeyId>', 'fs.oss.accessKeySecret' = '<fs.oss.accessKeySecret>' );Tabel berikut menjelaskan parameter-parameter tersebut.
Parameter
Deskripsi
Wajib
Keterangan
type
Jenis katalog.
Ya
Atur nilainya ke
paimon.metastore
Jenis metastore.
Ya
Dalam tutorial ini, atur nilainya ke
filesystem. Untuk informasi lebih lanjut tentang jenis lainnya, lihat Mengelola Katalog Paimon.warehouse
Direktori gudang data di Object Storage Service (OSS).
Ya
Formatnya adalah
oss://<bucket>/<object>, di mana:bucket: Nama bucket OSS Anda.object: Jalur tempat data Anda disimpan.
Anda dapat menemukan jalur bucket dan object di konsol OSS.
fs.oss.endpoint
Titik akhir Object Storage Service (OSS).
Tidak
Diperlukan jika bucket OSS yang ditentukan oleh
warehouseberada di wilayah berbeda dari ruang kerja Flink Anda, atau jika bucket tersebut dimiliki oleh Akun Alibaba Cloud yang berbeda.Untuk informasi lebih lanjut, lihat Wilayah dan titik akhir.
fs.oss.accessKeyId
ID AccessKey dari Akun Alibaba Cloud atau Pengguna RAM yang memiliki izin baca dan tulis pada bucket OSS.
Tidak
Diperlukan jika bucket OSS yang ditentukan oleh
warehouseberada di wilayah berbeda dari ruang kerja Flink Anda, atau jika bucket tersebut dimiliki oleh Akun Alibaba Cloud yang berbeda. Untuk informasi tentang cara memperoleh Pasangan Kunci Akses, lihat Buat Pasangan Kunci Akses.fs.oss.accessKeySecret
Rahasia AccessKey yang sesuai dengan ID AccessKey.
Tidak
Pilih kode tersebut dan klik Run di sebelah kiri.
Pesan
The following statement has been executed successfully!menunjukkan bahwa katalog berhasil dibuat. Anda sekarang dapat melihat katalog tersebut di halaman Catalogs atau pada tab Catalogs halaman SQL Editor.
Prosedur
Langkah 1: Buat tabel ODS dan masukkan data uji
Untuk menyederhanakan tutorial ini, kami langsung memasukkan data uji ke dalam tabel ODS guna mengisi tabel DWD dan DWS berikutnya. Di lingkungan produksi, Anda biasanya menggunakan pemrosesan aliran Flink untuk membaca data dari sumber eksternal dan menuliskannya ke data lake sebagai lapisan ODS. Untuk informasi lebih lanjut, lihat Memulai dengan Paimon: Fitur dasar.
Pada editor di tab Scripts, masukkan pernyataan SQL berikut dan klik Run di sebelah kiri.
CREATE DATABASE `my_catalog`.`order_dw`; USE `my_catalog`.`order_dw`; CREATE TABLE orders ( order_id BIGINT, user_id STRING, shop_id BIGINT, product_id BIGINT, buy_fee BIGINT, create_time TIMESTAMP, update_time TIMESTAMP, state INT ); CREATE TABLE orders_pay ( pay_id BIGINT, order_id BIGINT, pay_platform INT, create_time TIMESTAMP ); CREATE TABLE product_catalog ( product_id BIGINT, catalog_name STRING ); -- Insert test data INSERT INTO orders VALUES (100001, 'user_001', 12345, 1, 5000, TO_TIMESTAMP('2023-02-15 16:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100002, 'user_002', 12346, 2, 4000, TO_TIMESTAMP('2023-02-15 15:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100003, 'user_003', 12347, 3, 3000, TO_TIMESTAMP('2023-02-15 14:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100004, 'user_001', 12347, 4, 2000, TO_TIMESTAMP('2023-02-15 13:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100005, 'user_002', 12348, 5, 1000, TO_TIMESTAMP('2023-02-15 12:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100006, 'user_001', 12348, 1, 1000, TO_TIMESTAMP('2023-02-15 11:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100007, 'user_003', 12347, 4, 2000, TO_TIMESTAMP('2023-02-15 10:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1); INSERT INTO orders_pay VALUES (2001, 100001, 1, TO_TIMESTAMP('2023-02-15 17:40:56')), (2002, 100002, 1, TO_TIMESTAMP('2023-02-15 17:40:56')), (2003, 100003, 0, TO_TIMESTAMP('2023-02-15 17:40:56')), (2004, 100004, 0, TO_TIMESTAMP('2023-02-15 17:40:56')), (2005, 100005, 0, TO_TIMESTAMP('2023-02-15 18:40:56')), (2006, 100006, 0, TO_TIMESTAMP('2023-02-15 18:40:56')), (2007, 100007, 0, TO_TIMESTAMP('2023-02-15 18:40:56')); INSERT INTO product_catalog VALUES (1, 'phone_aaa'), (2, 'phone_bbb'), (3, 'phone_ccc'), (4, 'phone_ddd'), (5, 'phone_eee');CatatanTabel yang dibuat dalam tutorial ini adalah tabel append-only Paimon, yang tidak memiliki kunci primer. Tabel-tabel ini menawarkan performa penulisan batch yang lebih baik daripada tabel dengan kunci primer, tetapi tidak mendukung operasi pembaruan berbasis kunci.
Hasil eksekusi akan berisi beberapa sub-tab, dan pesan
The following statement has been executed successfully!menunjukkan bahwa pernyataan DDL terkait berhasil dieksekusi.Pernyataan DML seperti INSERT mengembalikan JobId, yang menunjukkan bahwa pekerjaan Flink sedang berjalan dalam sesi Flink. Klik Flink UI di sebelah kiri tab Results untuk melihat status eksekusi pernyataan SQL tersebut. Tunggu beberapa detik hingga proses selesai.
Jelajahi data tabel ODS.
Pada editor di tab Scripts, masukkan pernyataan SQL berikut dan klik Run di sebelah kiri.
SELECT count(*) as order_count FROM `my_catalog`.`order_dw`.`orders`; SELECT count(*) as pay_count FROM `my_catalog`.`order_dw`.`orders_pay`; SELECT * FROM `my_catalog`.`order_dw`.`product_catalog`;Pernyataan SQL ini juga dijalankan dalam sesi Flink. Anda dapat melihat hasilnya pada halaman hasil masing-masing.
order_countuntuk tabel orders adalah 7.pay_countuntuk tabel orders_pay adalah 7. Tabel product_catalog berisi 5 catatan denganproduct_iddari 1 hingga 5 dan nilaicatalog_namemasing-masing phone_aaa, phone_bbb, phone_ccc, phone_ddd, dan phone_eee.
Langkah 2: Buat tabel DWD dan DWS
Pada editor di tab Scripts, masukkan pernyataan SQL berikut dan klik Run di sebelah kiri.
USE `my_catalog`.`order_dw`;
CREATE TABLE dwd_orders (
order_id BIGINT,
order_user_id STRING,
order_shop_id BIGINT,
order_product_id BIGINT,
order_product_catalog_name STRING,
order_fee BIGINT,
order_create_time TIMESTAMP,
order_update_time TIMESTAMP,
order_state INT,
pay_id BIGINT,
pay_platform INT COMMENT 'platform 0: phone, 1: pc',
pay_create_time TIMESTAMP
) WITH (
'sink.parallelism' = '2'
);
CREATE TABLE dws_users (
user_id STRING,
ds STRING,
total_fee BIGINT COMMENT 'Total amount paid on the current day'
) WITH (
'sink.parallelism' = '2'
);
CREATE TABLE dws_shops (
shop_id BIGINT,
ds STRING,
total_fee BIGINT COMMENT 'Total amount paid on the current day'
) WITH (
'sink.parallelism' = '2'
);Tabel yang dibuat di sini juga merupakan tabel append-only Paimon. Saat tabel Paimon digunakan sebagai sink Flink, Flink tidak secara otomatis melakukan inferensi parallelism. Anda harus secara eksplisit mengatur parallelism untuk menghindari potensi error.
Langkah 3: Buat dan terapkan deployment DWD dan DWS
Buat dan terapkan deployment DWD.
Buat deployment pembaruan tabel DWD.
Pada halaman , buat blank batch draft bernama
dwd_orders. Kami menyarankan memilih versi engine dengan tag recommended. Gunakan dialek Flink SQL default. Salin pernyataan SQL berikut ke dalam editor. Karena tabel DWD adalah tabel append-only Paimon, gunakan pernyataanINSERT OVERWRITEuntuk menimpa seluruh tabel.INSERT OVERWRITE my_catalog.order_dw.dwd_orders SELECT o.order_id, o.user_id, o.shop_id, o.product_id, c.catalog_name, o.buy_fee, o.create_time, o.update_time, o.state, p.pay_id, p.pay_platform, p.create_time FROM my_catalog.order_dw.orders as o, my_catalog.order_dw.product_catalog as c, my_catalog.order_dw.orders_pay as p WHERE o.product_id = c.product_id AND o.order_id = p.order_idDi pojok kanan atas halaman, klik Deploy, lalu klik OK untuk menerapkan deployment
dwd_orders.
Buat dan terapkan deployment DWS.
Buat deployment pembaruan tabel DWS.
Mengikuti langkah-langkah yang sama seperti pada membuat deployment pembaruan tabel DWD, buat dua draft batch bernama
dws_shopsdandws_users. Salin pernyataan SQL berikut ke dalam editor masing-masing.INSERT OVERWRITE my_catalog.order_dw.dws_shops SELECT order_shop_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd') as ds, SUM(order_fee) as total_fee FROM my_catalog.order_dw.dwd_orders WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL GROUP BY order_shop_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd');INSERT OVERWRITE my_catalog.order_dw.dws_users SELECT order_user_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd') as ds, SUM(order_fee) as total_fee FROM my_catalog.order_dw.dwd_orders WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL GROUP BY order_user_id, DATE_FORMAT(pay_create_time, 'yyyyMMdd');Di pojok kanan atas halaman, klik Deploy, lalu klik OK untuk menerapkan deployment
dws_shopsdandws_users.
Langkah 4: Mulai dan lihat deployment DWD dan DWS
Mulai deployment DWD dan lihat datanya.
Buka halaman . Pilih BATCH dari daftar drop-down. Temukan deployment
dwd_ordersdan klik Start di kolom Actions.Instans pekerjaan dengan status STARTING muncul dalam daftar instans pekerjaan batch.
Saat status instans pekerjaan berubah menjadi FINISHED, pemrosesan data selesai.
Jelajahi hasil data.
Pada editor di tab Scripts, masukkan pernyataan SQL berikut dan klik Run di sebelah kiri untuk mengkueri data di tabel DWD.
SELECT * FROM `my_catalog`.`order_dw`.`dwd_orders`;Hasilnya ditunjukkan pada gambar berikut.

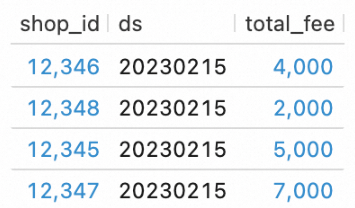
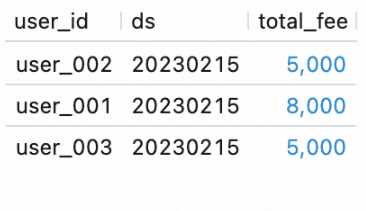
Mulai deployment DWS dan lihat datanya.
Pada halaman , pilih BATCH dari daftar drop-down. Temukan deployment
dws_shopsdandws_users, lalu klik Start di kolom Actions untuk masing-masing.Pada editor di tab Scripts, masukkan pernyataan SQL berikut dan klik Run di sebelah kiri untuk mengkueri data di tabel DWS.
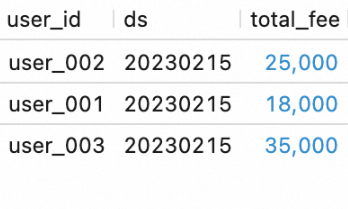
SELECT * FROM `my_catalog`.`order_dw`.`dws_shops`; SELECT * FROM `my_catalog`.`order_dw`.`dws_users`;Hasilnya ditunjukkan pada gambar-gambar berikut.
Langkah 5: Bangun pipeline batch dengan orkestrasi tugas
Pada langkah ini, Anda akan mengatur deployment-deployment tersebut ke dalam alur kerja, sehingga dapat dipicu bersama dan dijalankan secara berurutan.
Buat alur kerja.
Di panel navigasi sebelah kiri, pilih , lalu klik Create Workflow.
Pada panel yang muncul, masukkan
wf_orderssebagai nama. Biarkan jenis penjadwalan sebagai default (Manual Scheduling), pilihdefault-queueuntuk Resource Queue, lalu klik Create untuk membuka editor alur kerja.Edit alur kerja.
Klik node awal, beri nama
v_dwd_orders, dan pilih deploymentdwd_ordersuntuknya.Klik Add Task untuk membuat node bernama
v_dws_shops. Pilih deploymentdws_shopsuntuknya dan tetapkanv_dwd_orderssebagai node hulu.Klik Add Task lagi untuk membuat node bernama
v_dws_users. Pilih deploymentdws_usersuntuknya dan tetapkanv_dwd_orderssebagai node hulu.Di pojok kanan atas, klik Save lalu OK.
Picu alur kerja secara manual.
CatatanAnda juga dapat mengubah alur kerja agar berjalan sesuai jadwal berkala. Pada halaman Workflows, klik Edit Workflow di sebelah kanan alur kerja dan ubah mode penjadwalan menjadi Periodic Scheduling. Untuk informasi lebih lanjut, lihat Orkestrasi tugas (Pratinjau Publik).
Sebelum memicu alur kerja, masukkan data baru ke dalam tabel ODS untuk memverifikasi hasil eksekusi alur kerja.
Pada editor di tab Scripts, masukkan pernyataan SQL berikut dan klik Run di sebelah kiri.
USE `my_catalog`.`order_dw`; INSERT INTO orders VALUES (100008, 'user_001', 12346, 1, 10000, TO_TIMESTAMP('2023-02-15 17:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100009, 'user_002', 12347, 2, 20000, TO_TIMESTAMP('2023-02-15 18:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1), (100010, 'user_003', 12348, 3, 30000, TO_TIMESTAMP('2023-02-15 19:40:56'), TO_TIMESTAMP('2023-02-15 18:42:56'), 1); INSERT INTO orders_pay VALUES (2008, 100008, 1, TO_TIMESTAMP('2023-02-15 20:40:56')), (2009, 100009, 1, TO_TIMESTAMP('2023-02-15 20:40:56')), (2010, 100010, 1, TO_TIMESTAMP('2023-02-15 20:40:56'));Klik Flink UI di sebelah kiri tab Results untuk memantau status pekerjaan.
Pada halaman , temukan alur kerja yang dibuat pada langkah sebelumnya, klik Execute di kolom Actions, lalu klik OK untuk memicu alur kerja.
Klik nama alur kerja untuk membuka halaman Workflow Instance List and Details, tempat Anda dapat melihat daftar instans alur kerja.
Klik ID instans alur kerja yang sedang berjalan untuk membuka halaman detail eksekusinya dan amati status setiap node. Tunggu hingga seluruh alur kerja selesai.
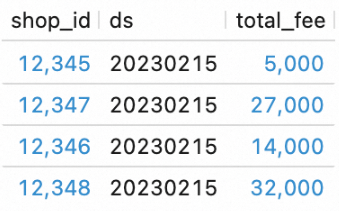
Lihat hasil eksekusi alur kerja.
Pada editor di tab Scripts, masukkan pernyataan SQL berikut dan klik Run di sebelah kiri.
SELECT * FROM `my_catalog`.`order_dw`.`dws_shops`; SELECT * FROM `my_catalog`.`order_dw`.`dws_users`;Lihat hasil eksekusi alur kerja.
Anda dapat melihat bahwa alur kerja telah memproses data baru dari lapisan ODS dan menuliskannya ke tabel DWS.
Dokumen terkait
Untuk mempelajari lebih lanjut tentang prinsip dan penyetelan konfigurasi pemrosesan batch Flink, lihat Panduan penyetelan pemrosesan batch Flink.
Untuk membangun data lakehouse streaming menggunakan Flink dan Paimon, lihat Bangun data lakehouse streaming dengan Paimon dan StarRocks.
Selain mengembangkan pekerjaan Flink di konsol Realtime Compute for Apache Flink, Anda juga dapat mengembangkan pekerjaan ini secara lokal. Untuk informasi lebih lanjut, lihat Kembangkan dengan ekstensi VS Code.