Anda dapat menggunakan Alibaba Cloud Elasticsearch untuk melakukan pencarian teks lengkap dan analisis semantik pada data di PolarDB-X, yang merupakan versi terbaru dari Distributed Relational Database Service (DRDS). Layanan Integrasi Data dari DataWorks memungkinkan Anda mensinkronkan sejumlah besar data dari PolarDB-X ke Alibaba Cloud ES dalam hitungan menit.
Informasi Latar Belakang
DataWorks adalah platform komprehensif untuk pengembangan dan tata kelola big data yang mengintegrasikan fitur seperti pengembangan data, penjadwalan tugas, dan manajemen data. Anda dapat menggunakan tugas sinkronisasi di DataWorks untuk dengan cepat memindahkan data dari berbagai sumber data ke Alibaba Cloud ES.
Sumber data berikut didukung:
Database Alibaba Cloud: ApsaraDB for RDS (MySQL, PostgreSQL, SQL Server), ApsaraDB for MongoDB, dan ApsaraDB for HBase
Alibaba Cloud PolarDB-X (ditingkatkan dari DRDS)
Alibaba Cloud MaxCompute
Alibaba Cloud Object Storage Service (OSS)
Alibaba Cloud Tablestore
Sumber data mandiri, seperti HDFS, Oracle, FTP, dan DB2.
Skenario:
Sinkronkan big data dari database atau tabel ke Alibaba Cloud Elasticsearch dalam mode offline. Untuk informasi lebih lanjut, lihat Buat Tugas Sinkronisasi Batch untuk Menyinkronkan Semua Data dalam Database ke Elasticsearch.
Sinkronkan big data penuh dan bertahap ke Alibaba Cloud Elasticsearch secara real-time. Untuk informasi lebih lanjut, lihat Sinkronkan Seluruh Database MySQL ke Elasticsearch Secara Real-Time.
Prasyarat
Anda telah membuat instans PolarDB-X. Untuk informasi lebih lanjut, lihat .
Anda telah membuat kluster Alibaba Cloud Elasticsearch dan mengaktifkan fitur Auto Indexing untuk kluster tersebut. Untuk informasi lebih lanjut, lihat Buat Kluster Alibaba Cloud Elasticsearch dan Konfigurasikan File YML.
Anda telah membuat ruang kerja DataWorks. Untuk informasi lebih lanjut, lihat Buat Ruang Kerja.
Anda hanya dapat menyinkronkan data ke Alibaba Cloud ES. Kluster Elasticsearch yang dikelola sendiri tidak didukung.
Instans PolarDB-X, instans ES, dan ruang kerja DataWorks harus berada di wilayah yang sama.
Instans PolarDB-X, instans ES, dan ruang kerja DataWorks harus berada di zona waktu yang sama. Jika tidak, perbedaan zona waktu mungkin terjadi antara data sumber dan tujuan setelah sinkronisasi.
Penagihan
Untuk informasi lebih lanjut tentang biaya instans ES, lihat Item yang Dapat Ditagih ES.
Untuk informasi lebih lanjut tentang penagihan grup sumber daya eksklusif untuk Integrasi Data, lihat Penagihan Grup Sumber Daya Eksklusif untuk Integrasi Data (Langganan).
Prosedur
Langkah 1: Persiapkan data sumber
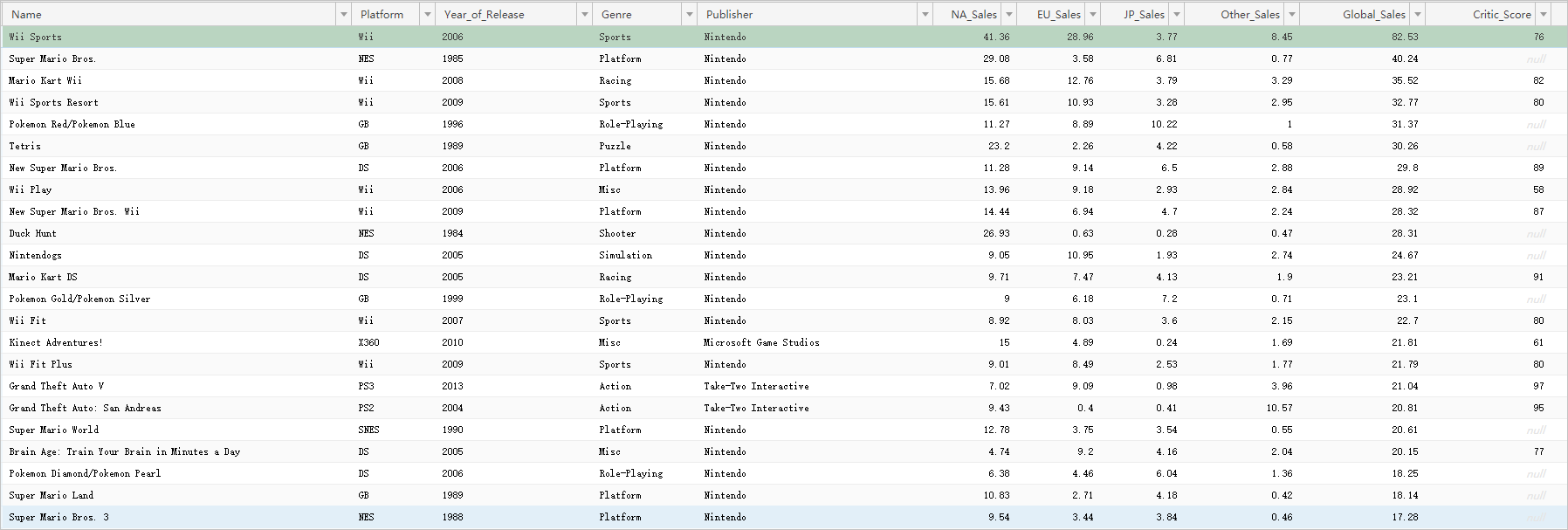
Masukkan data ke dalam instans PolarDB-X 1.0.
Untuk informasi lebih lanjut, lihat dan Operasi SQL Dasar. Gambar berikut menunjukkan data uji yang digunakan dalam topik ini.
Langkah 2: Beli dan buat grup sumber daya eksklusif
Beli grup sumber daya eksklusif untuk Integrasi Data dan sambungkan VPC dan ruang kerja ke grup sumber daya tersebut. Grup sumber daya eksklusif memastikan transmisi data yang cepat dan stabil.
Masuk ke Konsol DataWorks.
Di bilah menu atas, pilih wilayah. Di panel navigasi di sebelah kiri, klik Resource Group.
Di tab Resource Groups, klik .
Di halaman DataWorks Exclusive Resources (Subscription), atur Resource Type menjadi Exclusive Resource Group For Data Integration, masukkan nama untuk grup sumber daya, lalu klik Buy Now untuk membeli grup sumber daya eksklusif.
Untuk informasi lebih lanjut, lihat Langkah 1: Buat Grup Sumber Daya Eksklusif untuk Integrasi Data.
Di kolom Actions dari grup sumber daya eksklusif yang Anda buat, klik Network Settings untuk menyambungkan virtual private cloud (VPC). Untuk informasi lebih lanjut, lihat Sambungkan VPC.
CatatanDalam contoh ini, grup sumber daya eksklusif untuk Integrasi Data digunakan untuk menyinkronkan data melalui VPC. Untuk informasi lebih lanjut tentang cara menggunakan grup sumber daya eksklusif untuk Integrasi Data untuk menyinkronkan data melalui Internet, lihat Konfigurasikan Daftar Putih Alamat IP.
Untuk menyinkronkan data, grup sumber daya eksklusif harus terhubung ke VPC tempat instans PolarDB-X dan Elasticsearch berada. Oleh karena itu, Anda harus menyambungkan grup sumber daya eksklusif ke VPC, Zone, dan VSwitch dari instans PolarDB-X dan instans Elasticsearch. Untuk melihat informasi VPC untuk sebuah instans, lihat Lihat Informasi Dasar Instans Elasticsearch.
PentingSetelah Anda menyambungkan VPC, Anda harus menambahkan blok CIDR dari VSwitch ke daftar putih akses privat dari instans PolarDB-X dan Elasticsearch. Untuk informasi lebih lanjut, lihat Konfigurasikan Daftar Putih Akses Publik atau Privat untuk Instans Elasticsearch.
Di pojok kiri atas halaman, klik ikon kembali untuk kembali ke halaman Resource Groups.
Temukan grup sumber daya eksklusif yang Anda buat dan klik Attach Workspace di kolom Actions untuk menyambungkan ruang kerja target ke grup sumber daya.
Untuk informasi lebih lanjut, lihat Langkah 2: Asosiasikan Grup Sumber Daya Eksklusif untuk Integrasi Data dengan Ruang Kerja.
Langkah 3: Tambahkan sumber data
Tambahkan sumber data PolarDB-X dan Elasticsearch di layanan Integrasi Data dari DataWorks.
Pergi ke halaman Data Integration di DataWorks.
Masuk ke Konsol DataWorks.
Di panel navigasi di sebelah kiri, klik Workspaces.
Di kolom Operation dari ruang kerja target, pilih .
Di panel navigasi di sebelah kiri, klik Data Source.
Tambahkan sumber data PolarDB-X.
Di halaman Data Source, klik Add Data Source.
Di halaman Add Data Source, cari dan pilih DRDS.
Di halaman Add DRDS Data Source, konfigurasikan parameter untuk sumber data dan uji konektivitasnya. Setelah uji konektivitas berhasil, klik Complete.
Untuk informasi lebih lanjut, lihat Tambahkan Sumber Data PolarDB-X.
Tambahkan sumber data Elasticsearch dengan cara yang sama. Untuk informasi lebih lanjut, lihat Tambahkan Sumber Data Elasticsearch.
Langkah 4: Konfigurasikan dan jalankan tugas sinkronisasi data
Tugas sinkronisasi batch berjalan pada grup sumber daya eksklusif. Grup sumber daya mengambil data dari sumber data di Integrasi Data dan menulis data tersebut ke Elasticsearch.
Anda dapat menggunakan Antarmuka tanpa kode atau editor kode untuk mengonfigurasi tugas sinkronisasi batch. Topik ini menggunakan Antarmuka tanpa kode sebagai contoh. Untuk informasi lebih lanjut tentang cara menggunakan editor kode untuk mengonfigurasi tugas sinkronisasi batch, lihat Konfigurasikan Tugas Sinkronisasi Batch Menggunakan Editor Kode dan Elasticsearch Writer.
Topik ini menjelaskan cara membuat tugas sinkronisasi offline di Data Development Warisan (DataStudio).
Pergi ke halaman Data Development di DataWorks.
Masuk ke Konsol DataWorks.
Di panel navigasi di sebelah kiri, klik Workspaces.
Di kolom Actions dari ruang kerja target, pilih .
Buat tugas sinkronisasi batch.
Di panel navigasi di sebelah kiri, pergi ke tab Pengembangan Data. Klik ikon
 dan pilih . Buat alur bisnis sesuai petunjuk.
dan pilih . Buat alur bisnis sesuai petunjuk.Klik kanan alur bisnis yang Anda buat dan pilih .
Di kotak dialog Create Node, masukkan nama untuk node dan klik Confirm.
Konfigurasikan jaringan dan sumber daya.
Di bagian Source, atur Source menjadi DRDS dan Data Source menjadi nama sumber data dari mana Anda ingin menyinkronkan data.
Di bagian Resource Group, pilih grup sumber daya eksklusif.
Di bagian Destination, atur Destination menjadi Elasticsearch dan Data Source menjadi nama sumber data ke mana Anda ingin menyinkronkan data.
Klik Berikutnya.
Konfigurasikan tugas.
Di bagian Source, pilih tabel dari mana Anda ingin menyinkronkan data.
Di bagian Destination, konfigurasikan parameter untuk tujuan.
Di bagian Field Mapping, konfigurasikan pemetaan antara Source Fields dan Target Fields. Untuk informasi lebih lanjut, lihat Konfigurasikan Tugas Sinkronisasi Offline di Antarmuka tanpa Kode.
Dalam contoh ini, Source Field default digunakan dan hanya Destination Field yang dimodifikasi. Di sebelah kanan Destination Field, klik ikon
 . Di kotak dialog yang muncul, masukkan konfigurasi bidang.
. Di kotak dialog yang muncul, masukkan konfigurasi bidang.{"name":"Name","type":"text"} {"name":"Platform","type":"text"} {"name":"Year_of_Release","type":"date"} {"name":"Genre","type":"text"} {"name":"Publisher","type":"text"} {"name":"na_Sales","type":"float"} {"name":"EU_Sales","type":"float"} {"name":"JP_Sales","type":"float"} {"name":"Other_Sales","type":"float"} {"name":"Global_Sales","type":"float"} {"name":"Critic_Score","type":"long"} {"name":"Critic_Count","type":"long"} {"name":"User_Score","type":"float"} {"name":"User_Count","type":"long"} {"name":"Developer","type":"text"} {"name":"Rating","type":"text"}Di bagian Channel Control, konfigurasikan parameter saluran.
Untuk informasi lebih lanjut, lihat Konfigurasikan Tugas Sinkronisasi Batch Menggunakan Antarmuka tanpa Kode.
Jalankan tugas.
(Opsional) Konfigurasikan properti penjadwalan untuk tugas. Di sisi kanan halaman, klik Scheduling Configuration dan konfigurasikan parameter penjadwalan sesuai kebutuhan. Untuk informasi lebih lanjut, lihat Konfigurasi Penjadwalan.
Di bilah alat, klik ikon Simpan untuk menyimpan tugas.
Di bilah alat, klik ikon Kirim untuk mengirimkan tugas.
Jika Anda mengonfigurasi properti penjadwalan untuk tugas, tugas akan berjalan secara berkala. Anda juga dapat mengklik ikon Jalankan di bilah alat untuk menjalankan tugas segera.
Jika log berisi pesan
Shell run successfully!, tugas berhasil.
Langkah 5: Lihat hasil sinkronisasi data
Masuk ke konsol Kibana dari instans Alibaba Cloud ES tujuan.
Untuk informasi lebih lanjut, lihat Masuk ke Konsol Kibana.
Di panel navigasi di sebelah kiri, klik Dev Tools.
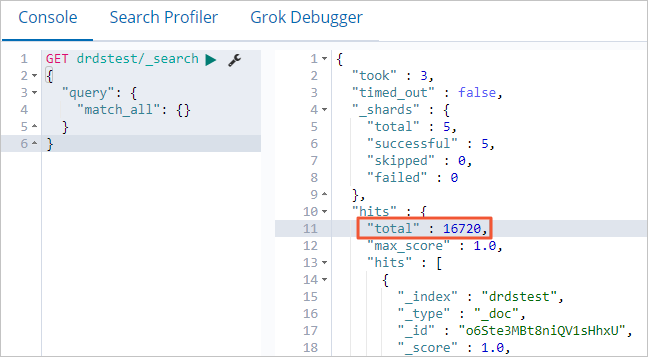
Di Console, jalankan perintah berikut untuk menanyakan jumlah entri data di tujuan.
CatatanAnda dapat membandingkan jumlah entri data di tujuan dengan jumlah entri data di sumber untuk memverifikasi bahwa semua data disinkronkan.
GET drdstest/_search { "query": { "match_all": {} } }Jika perintah berhasil, hasil berikut akan dikembalikan.
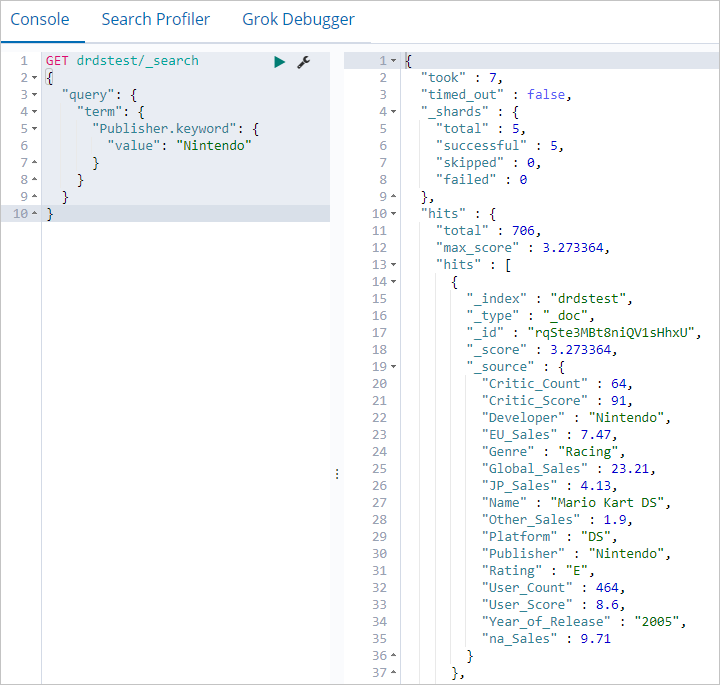
Anda dapat menjalankan perintah berikut untuk mengambil data dari bidang tertentu.
GET drdstest/_search { "query": { "term": { "Publisher.keyword": { "value": "Nintendo" } } } }Jika perintah berhasil dijalankan, keluaran berikut akan dikembalikan.