Data Integration mendukung sinkronisasi real-time seluruh database dari sumber data seperti MySQL ke Elasticsearch. Topik ini menggunakan skenario sinkronisasi dari MySQL ke Elasticsearch untuk menjelaskan cara melakukan sinkronisasi penuh dan inkremental secara real-time.
Prasyarat
Persiapan sumber data
Anda telah membuat sumber data MySQL dan sumber data Elasticsearch. Untuk informasi selengkapnya, lihat Konfigurasi sumber data.
Binlog harus diaktifkan untuk sumber data MySQL. Untuk informasi selengkapnya, lihat Prasyarat.
Kelompok sumber daya: Anda telah membeli kelompok sumber daya serverless.
Konektivitas jaringan: Anda telah menetapkan konektivitas jaringan antara kelompok sumber daya dan sumber data. Untuk informasi selengkapnya, lihat Ikhtisar Solusi Konektivitas Jaringan.
Konfigurasikan tugas
Langkah 1: Buat tugas sinkronisasi
Masuk ke Konsol DataWorks. Di wilayah target, klik di panel navigasi sebelah kiri. Pilih ruang kerja dari daftar drop-down dan klik Go to Data Integration.
Di panel navigasi sebelah kiri, klik Synchronization Task. Pada halaman yang muncul, klik Create Synchronization Task dan konfigurasikan informasi tugas.
Source Type:
MySQL.Destination Type:
Elasticsearch.Specific Type:
real-time synchronization of entire database.Synchronization Mode:
Schema Migration: Secara otomatis membuat struktur indeks yang sesuai, seperti indeks dan pemetaan bidang, di tujuan. Langkah ini tidak melakukan migrasi data.
Full Synchronization (Opsional): Menyalin semua data historis dari objek sumber yang ditentukan, seperti tabel, ke tujuan sekaligus. Biasanya digunakan untuk migrasi data awal atau inisialisasi.
Incremental Sync (Opsional): Setelah sinkronisasi penuh selesai, terus-menerus menangkap perubahan data (insert, update, dan delete) dari sumber dan menyinkronkannya ke tujuan.
Langkah 2: Konfigurasikan sumber data dan sumber daya komputasi
Untuk Source, pilih sumber data
MySQL. Untuk Destination, pilih sumber dataElasticsearch.Pada bagian Running Resources, pilih Resource Group untuk tugas sinkronisasi, lalu alokasikan Resource Group CU ke tugas tersebut.
CatatanJika log tugas menampilkan pesan seperti
Please confirm whether there are enough resources..., hal ini menunjukkan bahwa unit komputasi (CUs) yang tersedia di kelompok sumber daya saat ini tidak mencukupi untuk memulai atau menjalankan tugas. Anda dapat menambah jumlah CU yang dialokasikan ke tugas pada panel Configure Resource Group untuk mengalokasikan lebih banyak sumber daya komputasi.Untuk nilai ukuran sumber daya yang direkomendasikan, lihat CU yang Direkomendasikan untuk Data Integration. Sesuaikan nilai berdasarkan kebutuhan aktual Anda.
Pastikan kedua sumber data (sumber dan tujuan) lulus Connectivity Check.
Langkah 3: Konfigurasikan rencana sinkronisasi
1. Konfigurasikan sumber data
Pada langkah ini, Anda dapat memilih tabel yang akan disinkronkan dari sumber data di bagian Source Tables, lalu klik ikon
 untuk memindahkannya ke bagian Selected Tables di sebelah kanan. Jika terdapat banyak tabel, Anda dapat menggunakan Database Filtering atau Table filtering untuk memilih tabel yang akan disinkronkan dengan mengonfigurasi ekspresi reguler.
untuk memindahkannya ke bagian Selected Tables di sebelah kanan. Jika terdapat banyak tabel, Anda dapat menggunakan Database Filtering atau Table filtering untuk memilih tabel yang akan disinkronkan dengan mengonfigurasi ekspresi reguler.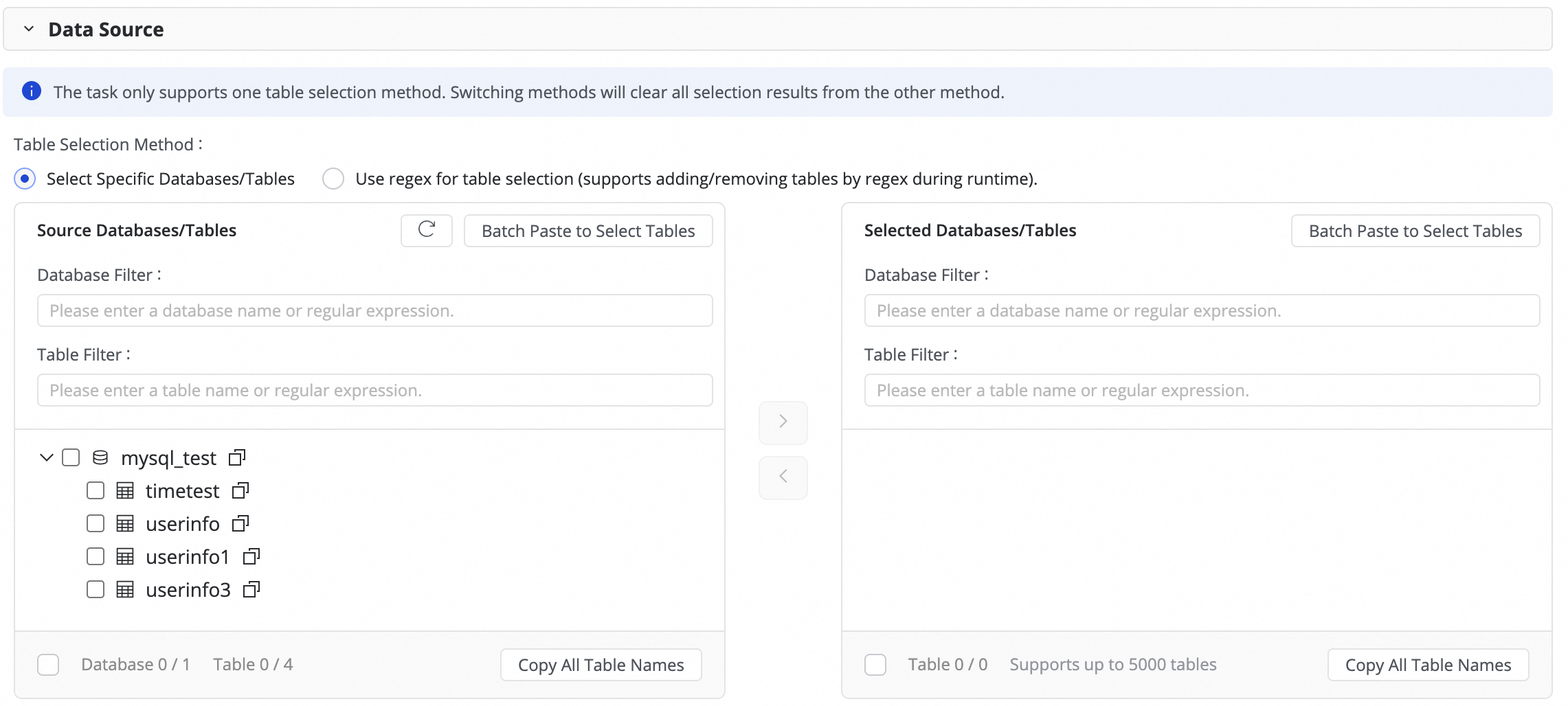
Untuk menulis data dari beberapa tabel sharded (dengan skema yang sama) ke satu tabel tujuan, Anda dapat Select Tables by Regex.
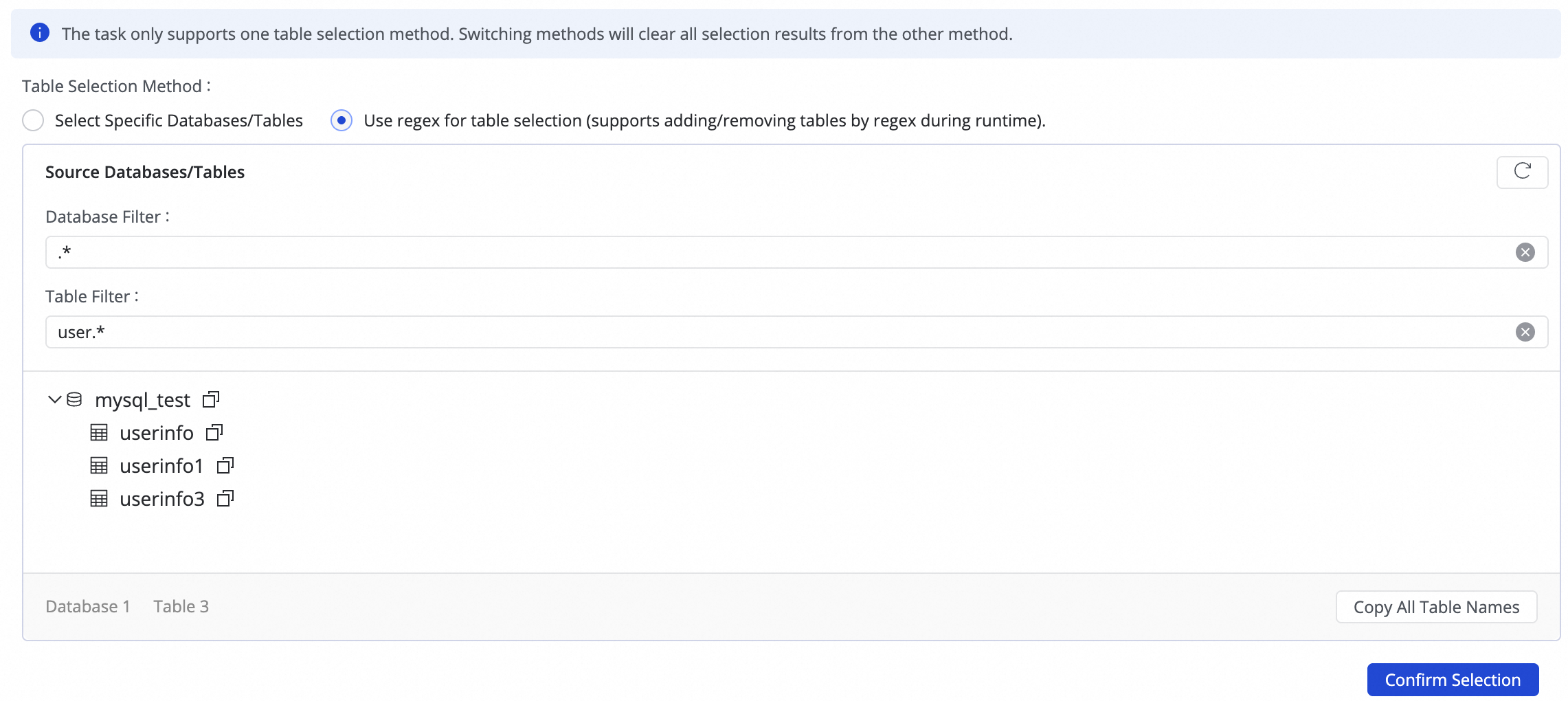
Masukkan ekspresi reguler dalam konfigurasi tabel sumber. DataWorks secara otomatis mengidentifikasi dan mengumpulkan semua tabel sumber yang cocok serta menulis datanya ke tabel tujuan yang dipetakan oleh ekspresi tersebut.CatatanMetode ini berlaku untuk skenario sinkronisasi penggabungan tabel sharded (mirip dengan sinkronisasi berbasis sharding), meningkatkan efisiensi konfigurasi dan menghindari kebutuhan untuk berulang kali menambahkan aturan sinkronisasi banyak-ke-satu.
2. Konfigurasikan pemetaan indeks tujuan
Aksi | Deskripsi | ||||||||||||
Refresh | Sistem secara otomatis mencantumkan tabel sumber yang telah Anda pilih. Namun, properti indeks tujuan hanya berlaku setelah Anda merefresh dan mengonfirmasinya.
| ||||||||||||
Custom Mapping Rule for Destination Index Name (Opsional) | Sistem menggunakan aturan default untuk menghasilkan nama indeks:
Fitur ini mendukung skenario berikut:
| ||||||||||||
Edit Field Type Mapping (Opsional) | Sistem menyediakan pemetaan default antara Source Type dan Destination Type. Anda dapat mengklik Edit Mapping of Field Data Types di pojok kanan atas tabel untuk menyesuaikan pemetaan tipe data bidang antara tabel sumber dan indeks tujuan. Setelah menyelesaikan konfigurasi, klik Apply and Refresh Mapping. Saat mengedit pemetaan tipe bidang, pastikan aturan konversi tipe valid. Jika tidak, kegagalan konversi tipe dapat terjadi, menghasilkan data kotor dan mengganggu tugas. | ||||||||||||
Edit Destination Index (Opsional) | Berdasarkan aturan pemetaan nama indeks kustom, sistem secara otomatis membuat indeks tujuan baru atau menggunakan kembali yang sudah ada dengan nama yang cocok. DataWorks secara otomatis menghasilkan struktur indeks tujuan berdasarkan struktur tabel sumber. Dalam kebanyakan kasus, intervensi manual tidak diperlukan. Saat status indeks tujuan adalah To be created, Anda dapat menambahkan bidang baru ke indeks tujuan berdasarkan struktur tabel aslinya. Lakukan operasi berikut:
| ||||||||||||
Value assignment | Bidang native dipetakan secara otomatis berdasarkan kecocokan nama bidang antara sumber dan tujuan. Anda harus menetapkan nilai secara manual untuk bidang baru dan properti indeks tujuan yang Anda tambahkan. Lakukan operasi berikut:
Anda dapat menetapkan konstanta dan variabel dengan mengubah Value Type. Opsi berikut didukung:
| ||||||||||||
Source split column | Anda dapat memilih bidang dari tabel sumber di daftar drop-down Source split column atau memilih Not Split. Saat tugas sinkronisasi dijalankan, tugas tersebut dibagi menjadi beberapa subtugas berdasarkan kolom ini untuk membaca data secara batch dan paralel. Kami menyarankan agar Anda menggunakan kunci utama tabel sebagai source split column. Tipe string, float, dan date tidak didukung. Source split column hanya didukung ketika sumbernya adalah MySQL. | ||||||||||||
Skip full synchronization | Jika Anda telah mengonfigurasi sinkronisasi penuh di Langkah 3, Anda dapat memilih untuk melewati sinkronisasi penuh untuk tabel tertentu. Hal ini berguna jika Anda telah menyinkronkan data penuh ke tujuan dengan metode lain. | ||||||||||||
Full condition | Terapkan filter ke data sumber selama fase sinkronisasi penuh. Masukkan hanya kondisi filter dari klausa | ||||||||||||
Configure DML Rule | Pemrosesan pesan DML menerapkan penyaringan dan kontrol detail halus pada data perubahan ( |
 dan menggabungkan nilai dari Manual Input dan Built-in Variable. Variabel yang didukung mencakup nama sumber data sumber, nama database sumber, dan nama tabel sumber.
dan menggabungkan nilai dari Manual Input dan Built-in Variable. Variabel yang didukung mencakup nama sumber data sumber, nama database sumber, dan nama tabel sumber. di kolom Destination Index Name dan tambahkan bidang dengan mengedit Statement Used to Create Index.
di kolom Destination Index Name dan tambahkan bidang dengan mengedit Statement Used to Create Index.Langkah 4: Pengaturan lanjutan
Konfigurasi parameter lanjutan
Untuk menyesuaikan tugas, ubah parameter pada tab Advanced Parameters.
Klik Advanced Settings di pojok kanan atas untuk membuka halaman konfigurasi parameter lanjutan.
Ubah nilai parameter berdasarkan deskripsi yang diberikan.
Anda juga dapat menggunakan konfigurasi berbasis AI. Masukkan perintah dalam bahasa alami, seperti perintah untuk menyesuaikan konkurensi tugas, dan model AI akan menghasilkan nilai parameter yang direkomendasikan. Anda dapat memilih apakah akan menerima parameter yang dihasilkan AI.
Selain menerima atau menolak saran, Anda dapat mengklik Regenerate agar Copilot memberikan rekomendasi parameter baru.
Ubah parameter ini hanya jika Anda benar-benar memahami tujuannya. Hal ini membantu mencegah masalah tak terduga seperti latensi tugas, konsumsi sumber daya berlebihan yang menghambat tugas lain, dan kehilangan data.
Konfigurasi kemampuan DDL
Beberapa saluran sinkronisasi real-time dapat mendeteksi perubahan metadata pada skema tabel sumber dan memberi tahu tujuan untuk menyinkronkan pembaruan tersebut, atau melakukan tindakan lain seperti memberi peringatan, mengabaikan, atau menghentikan tugas.
Anda dapat mengklik Configure DDL Capability di pojok kanan atas untuk mengatur kebijakan pemrosesan untuk setiap jenis perubahan. Kebijakan pemrosesan yang didukung bervariasi tergantung salurannya.
Pemrosesan normal: Tujuan memproses informasi perubahan DDL dari sumber.
Abaikan: Pesan perubahan diabaikan, dan tujuan tidak dimodifikasi.
Error: Tugas sinkronisasi real-time seluruh database dihentikan, dan statusnya diatur ke Error.
Peringatan: Peringatan dikirimkan kepada Anda saat jenis perubahan ini terjadi di sumber. Anda harus mengonfigurasi aturan notifikasi DDL di Configure Alert Rule.
Setelah kolom baru ditambahkan di sumber dan dibuat di tujuan melalui sinkronisasi DDL, sistem tidak melakukan backfill data untuk data yang sudah ada di tabel tujuan.
Langkah 5: Terapkan dan jalankan tugas
Setelah menyelesaikan semua konfigurasi, klik Save di bagian bawah halaman untuk menyimpan konfigurasi tugas.
Tugas sinkronisasi seluruh database tidak mendukung debugging langsung. Anda harus menerapkannya ke Operation Center untuk dieksekusi. Oleh karena itu, Anda harus melakukan operasi Deploy agar tugas baru atau yang telah diedit berlaku.
Saat penerapan, jika Anda memilih Start immediately after deployment, tugas akan mulai berjalan bersamaan dengan penerapan. Jika tidak, setelah penerapan, Anda harus membuka dan menjalankan tugas secara manual di kolom Operation pada tugas target.
Klik Name/ID tugas yang sesuai di Tasks untuk melihat proses eksekusi tugas secara rinci.
Langkah 6: Konfigurasi peringatan
1. Buat peringatan
Di daftar , temukan tugas real-time seluruh database, lalu klik di kolom Operation untuk mengonfigurasi kebijakan peringatan untuk tugas tersebut.
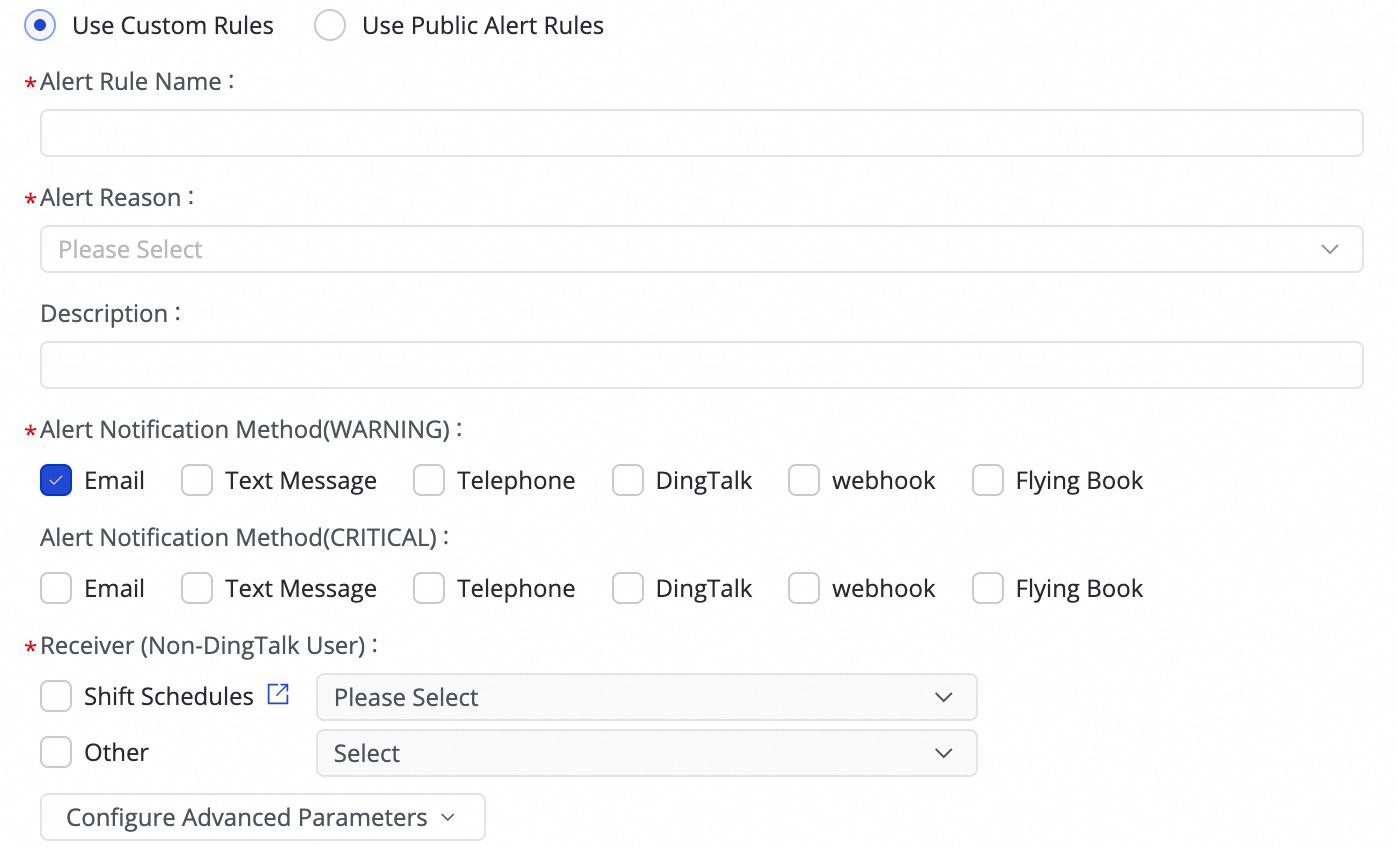
(1) Klik Create Rule untuk mengonfigurasi aturan peringatan.
Anda dapat mengatur Alert Reason untuk memantau metrik tugas seperti Business delay, Failover, Task status, DDL Notification, dan Task Resource Utilization, serta mengatur tingkat peringatan CRITICAL atau WARNING berdasarkan ambang batas yang ditentukan.
Dengan mengonfigurasi Configure Advanced Parameters, Anda dapat mengontrol interval waktu antar pesan peringatan untuk mencegah pengiriman terlalu banyak pesan sekaligus, yang dapat menyebabkan pemborosan dan akumulasi pesan.
Jika alasan peringatan diatur ke Business delay, Task status, atau Task Resource Utilization, Anda juga dapat mengaktifkan notifikasi pemulihan untuk memberi tahu penerima saat tugas kembali normal.
(2) Kelola aturan peringatan.
Untuk aturan peringatan yang sudah ada, Anda dapat menggunakan sakelar peringatan untuk mengaktifkan atau menonaktifkan aturan tersebut. Anda juga dapat mengirim peringatan ke orang yang berbeda berdasarkan tingkat peringatan.
2. Lihat peringatan
Klik di daftar tugas untuk memperluas panel dan membuka halaman event peringatan, tempat Anda dapat melihat peringatan yang telah terjadi.
Kelola tugas
Edit tugas
Di halaman , temukan tugas sinkronisasi yang telah Anda buat. Di kolom Operation, pilih More > Edit untuk memodifikasi informasi tugas. Langkah-langkahnya sama seperti saat mengonfigurasi tugas baru.
Untuk tugas yang tidak sedang berjalan, Anda dapat langsung memodifikasi dan menyimpan konfigurasi, lalu menerapkan tugas ke Operation Center agar perubahan berlaku.
Untuk tugas yang Running, jika Anda mengedit dan menerapkan tugas tanpa memilih Start immediately after deployment, tombol aksi asli berubah menjadi Apply Updates. Anda harus mengklik tombol ini agar perubahan berlaku di Operation Center.
Setelah mengklik Apply Updates, sistem akan menghentikan, menerapkan, dan menjalankan ulang tugas untuk menerapkan perubahan.
Jika Anda menambahkan tabel baru atau mengganti tabel yang ada:
Anda tidak dapat memilih posisi saat menerapkan pembaruan. Setelah mengonfirmasi pembaruan, sistem akan melakukan schema migration dan full synchronization untuk tabel baru. Setelah inisialisasi selesai, sinkronisasi inkremental dimulai untuk tabel-tabel tersebut bersamaan dengan tabel asli.
Jika Anda memodifikasi informasi lainnya:
Anda dapat memilih posisi saat menerapkan pembaruan. Setelah mengonfirmasi, tugas dilanjutkan dari posisi yang ditentukan. Jika Anda tidak menentukan posisi, tugas dilanjutkan dari posisi terakhir saat berhenti (checkpoint terakhir).
Tabel yang tidak dimodifikasi tidak terpengaruh. Setelah pembaruan dan restart, tabel tersebut dilanjutkan dari checkpoint terakhir.
Lihat tugas
Setelah membuat tugas sinkronisasi, Anda dapat melihat daftar tugas yang telah dibuat beserta informasi dasarnya di halaman Synchronization Task.
Di kolom Operation, Anda dapat Start atau Stop tugas sinkronisasi. Di menu More, Anda dapat melakukan operasi lain seperti Edit dan View.
Untuk tugas yang sedang berjalan, Anda dapat melihat statusnya di bagian Execution Overview. Anda juga dapat mengklik area tertentu pada ikhtisar untuk melihat detail eksekusi. Klik View untuk membuka halaman detail tugas sinkronisasi. Bagian Basic Information di bagian atas menampilkan ID tugas, sumber data (misalnya, MySQL_Source → Elasticsearch_Source), waktu pembuatan, kelompok sumber daya sinkronisasi, status (Running), rencana sinkronisasi (real-time synchronization of entire database), dan CU yang digunakan tugas. Bagian Execution Status di tengah menggunakan bilah progres untuk menunjukkan persentase penyelesaian dan status berjalan dari tiga tahap: schema migration, full synchronization, dan sinkronisasi data real-time.
Tugas sinkronisasi real-time dari MySQL ke Elasticsearch terdiri dari tiga tahap:
Schema migration: Menunjukkan cara indeks tujuan dibuat (dari indeks yang sudah ada atau dibuat secara otomatis). Jika indeks dibuat secara otomatis, pernyataan DDL ditampilkan.
Full synchronization: Menampilkan informasi tentang tabel yang disinkronkan menggunakan sinkronisasi offline, progresnya, dan jumlah catatan yang ditulis.
Sinkronisasi data real-time: Menampilkan statistik real-time, termasuk progres, catatan DDL dan DML, serta informasi peringatan.
Jalankan ulang tugas
Dalam skenario tertentu, seperti saat Anda perlu menambahkan atau menghapus tabel, atau memodifikasi skema tabel tujuan atau informasi nama tabel, Anda dapat mengklik Rerun di kolom Operations tugas sinkronisasi. Sistem hanya akan menyinkronkan tabel yang baru ditambahkan atau dimodifikasi. Tabel yang sebelumnya telah disinkronkan atau tidak dimodifikasi tidak akan disinkronkan lagi.
-
Klik Rerun untuk menjalankan ulang inisialisasi penuh dan sinkronisasi real-time.
-
Edit tugas untuk menambahkan atau menghapus tabel, simpan tugas, lalu terapkan. Setelah penerapan, tombol Apply Updates muncul di kolom Operations. Klik Apply Updates untuk memicu jalankan ulang tugas yang dimodifikasi. Hanya tabel yang baru ditambahkan atau dimodifikasi yang disinkronkan. Tabel yang sebelumnya telah disinkronkan tidak disinkronkan lagi.
Lanjutkan dari checkpoint
Kasus penggunaan
Mengatur ulang posisi awal tugas berguna untuk skenario berikut:
Pemulihan tugas dan kelanjutan data: Jika tugas terganggu, tentukan secara manual waktu gangguan sebagai posisi awal baru untuk melanjutkan sinkronisasi data dari titik yang tepat.
Pemecahan masalah data dan rollback: Jika Anda menemukan data yang hilang atau tidak normal setelah sinkronisasi, kembalikan posisi ke waktu sebelum masalah terjadi untuk memutar ulang dan memperbaiki data.
Perubahan konfigurasi tugas besar-besaran: Setelah melakukan penyesuaian signifikan pada konfigurasi tugas, seperti struktur indeks tujuan atau pemetaan bidang, atur ulang posisi untuk memulai sinkronisasi dari titik tertentu. Hal ini memastikan akurasi data di bawah konfigurasi baru.
Prosedur
Klik Start. Pada kotak dialog yang muncul, pilih Whether to reset the site.
Jika Anda tidak memilih kotak centang, tugas dilanjutkan dari titik penghentian terakhir (checkpoint terakhir).
Jika Anda memilih kotak centang dan menentukan waktu, tugas dimulai dari waktu yang ditentukan. Pastikan waktu yang dipilih tidak lebih awal dari posisi paling awal yang tersedia di Binlog sumber.
Jika Anda mengalami kesalahan terkait posisi yang tidak valid atau tidak ada, gunakan solusi berikut:
Atur ulang posisi: Saat memulai tugas sinkronisasi real-time, atur ulang posisi dan pilih posisi paling awal yang tersedia di database sumber.
Atur periode retensi log: Jika posisi database telah kedaluwarsa, tingkatkan periode retensi log di database, misalnya menjadi 7 hari.
Sinkronisasi ulang data: Jika data telah hilang, lakukan sinkronisasi penuh lagi atau konfigurasikan tugas sinkronisasi offline untuk menyinkronkan secara manual data yang hilang.
FAQ
Untuk pertanyaan umum tentang sinkronisasi database real-time, lihat FAQ Data Integration dan Kesalahan Data Integration.