Spark Thrift Server adalah layanan yang disediakan oleh Apache Spark untuk mendukung eksekusi kueri SQL melalui koneksi JDBC atau ODBC, memudahkan integrasi lingkungan Spark dengan alat Business Intelligence (BI), visualisasi data, dan alat analisis lainnya. Topik ini menjelaskan cara membuat dan terhubung ke Spark Thrift Server.
Prasyarat
Sebuah workspace telah dibuat. Untuk informasi lebih lanjut, lihat Mengelola Workspaces.
Buat sesi Spark Thrift Server
Setelah membuat Spark Thrift Server, Anda dapat memilih sesi ini saat membuat tugas Spark SQL.
Buka halaman Sessions.
Masuk ke Konsol EMR.
Di panel navigasi sisi kiri, pilih .
Di halaman Spark, klik nama workspace yang ingin dikelola.
Di panel navigasi sebelah kiri halaman EMR Serverless Spark, pilih Operation Center > Sessions.
Di halaman Session Manager, klik tab Spark Thrift Server Sessions.
Klik Create Spark Thrift Server Session.
Di halaman Create Spark Thrift Server Session, konfigurasikan parameter dan klik Create.
Parameter
Deskripsi
Name
Nama Spark Thrift Server baru.
Nama harus memiliki panjang 1 hingga 64 karakter dan dapat berisi huruf, angka, tanda hubung (-), garis bawah (_), dan spasi.
Deployment Queue
Pilih antrian pengembangan yang sesuai untuk menerapkan sesi. Anda hanya dapat memilih antrian pengembangan atau antrian yang dibagi oleh lingkungan pengembangan dan produksi.
Untuk informasi lebih lanjut tentang antrian, lihat Manajemen Antrian Sumber Daya.
Engine Version
Versi engine yang digunakan oleh sesi saat ini. Untuk informasi lebih lanjut tentang versi engine, lihat Pengenalan Versi Engine.
Use Fusion Acceleration
Fusion dapat mempercepat pelaksanaan beban kerja Spark dan mengurangi total biaya tugas. Untuk informasi penagihan, lihat Penagihan. Untuk informasi lebih lanjut tentang engine Fusion, lihat Engine Fusion.
Auto Stop
Fitur ini diaktifkan secara default. Sesi Spark Thrift Server akan berhenti secara otomatis setelah 45 menit tidak aktif.
Network Connectivity
Spark Thrift Server Port
Nomor port adalah 443 saat Anda mengakses server menggunakan titik akhir publik, dan 80 saat Anda mengakses server menggunakan titik akhir internal wilayah yang sama.
Access Credential
Hanya metode Token yang didukung.
spark.driver.cores
Jumlah core CPU yang digunakan oleh proses Driver dalam aplikasi Spark. Nilai default adalah 1 CPU.
spark.driver.memory
Jumlah memori yang dapat digunakan oleh proses Driver dalam aplikasi Spark. Nilai default adalah 3,5 GB.
spark.executor.cores
Jumlah core CPU yang dapat digunakan oleh setiap proses Executor. Nilai default adalah 1 CPU.
spark.executor.memory
Jumlah memori yang dapat digunakan oleh setiap proses Executor. Nilai default adalah 3,5 GB.
spark.executor.instances
Jumlah executor yang dialokasikan oleh Spark. Nilai default adalah 2.
Dynamic Resource Allocation
Secara default, fitur ini dinonaktifkan. Setelah Anda mengaktifkan fitur ini, Anda harus mengonfigurasi parameter berikut:
Minimum Number of Executors: Nilai default: 2.
Maximum Number of Executors: Jika Anda tidak mengonfigurasi parameter spark.executor.instances, nilai default 10 digunakan.
More Memory Configurations
spark.driver.memoryOverhead: ukuran memori non-heap yang tersedia untuk setiap driver. Jika Anda membiarkan parameter ini kosong, Spark secara otomatis memberikan nilai ke parameter ini berdasarkan rumus berikut:
max(384 MB, 10% × spark.driver.memory).spark.executor.memoryOverhead: ukuran memori non-heap yang tersedia untuk setiap executor. Jika Anda membiarkan parameter ini kosong, Spark secara otomatis memberikan nilai ke parameter ini berdasarkan rumus berikut:
max(384 MB, 10% × spark.executor.memory).spark.memory.offHeap.size: ukuran memori off-heap yang tersedia untuk aplikasi Spark. Nilai default: 1 GB.
Parameter ini hanya valid jika Anda mengatur parameter
spark.memory.offHeap.enabledketrue. Secara default, jika Anda menggunakan engine Fusion, parameter spark.memory.offHeap.enabled diatur ke true dan parameter spark.memory.offHeap.size diatur ke 1 GB.
Spark Configuration
Masukkan informasi konfigurasi Spark. Secara default, parameter dipisahkan oleh spasi, misalnya,
spark.sql.catalog.paimon.metastore dlf.Dapatkan informasi Endpoint.
Di tab Spark Thrift Server Sessions, klik nama Spark Thrift Server baru.
Di tab Overview, salin informasi Endpoint.
Berdasarkan lingkungan jaringan Anda, Anda dapat memilih salah satu dari Endpoint berikut:
Endpoint Publik: Cocok untuk skenario di mana Anda perlu mengakses EMR Serverless Spark melalui Internet, seperti dari mesin pengembangan lokal, jaringan eksternal, atau lingkungan lintas-cloud. Metode ini mungkin menimbulkan biaya lalu lintas. Pastikan Anda mengambil langkah-langkah keamanan yang diperlukan.
Endpoint Internal Wilayah yang Sama: Cocok untuk skenario di mana instance ECS Alibaba Cloud di wilayah yang sama mengakses EMR Serverless Spark melalui jaringan internal. Akses jaringan internal gratis dan lebih aman, tetapi terbatas pada lingkungan jaringan internal Alibaba Cloud di wilayah yang sama.
Buat Token
Di tab Spark Thrift Server Sessions, klik nama sesi Spark Thrift Server baru.
Klik tab Token Management.
Klik Create Token.
Di kotak dialog Create Token, konfigurasikan parameter dan klik OK.
Parameter
Deskripsi
Name
Nama token baru.
Expiration Time
Waktu kedaluwarsa token. Jumlah hari harus lebih besar dari atau sama dengan 1. Fitur ini diaktifkan secara default, dan token kedaluwarsa setelah 365 hari.
Salin informasi token.
PentingSetelah token dibuat, Anda harus segera menyalin informasi token baru. Informasi token tidak dapat dilihat lagi setelah ditutup. Jika token kedaluwarsa atau hilang, Anda dapat membuat token baru atau mengatur ulang token.
Terhubung ke Spark Thrift Server
Saat terhubung ke Spark Thrift Server, ganti informasi berikut sesuai dengan situasi Anda:
<endpoint>: Informasi Endpoint(Public) atau Endpoint(Internal) yang Anda dapatkan di tab Overview.Jika menggunakan endpoint internal wilayah yang sama, akses ke Spark Thrift Server dibatasi untuk sumber daya dalam VPC yang sama.
<port>: Nomor port. Nomor port adalah 443 saat menggunakan endpoint publik, dan 80 saat menggunakan endpoint internal wilayah yang sama.<username>: Nama token yang Anda buat di tab Token Management.<token>: Informasi token yang Anda salin di tab Token Management.
Terhubung ke Spark Thrift Server menggunakan Python
Jalankan perintah berikut untuk menginstal paket PyHive dan Thrift:
pip install pyhive thriftTulis skrip Python untuk terhubung ke Spark Thrift Server.
Berikut adalah contoh skrip Python yang menunjukkan cara terhubung ke Hive dan menampilkan daftar database. Pilih metode koneksi yang sesuai berdasarkan lingkungan jaringan Anda (publik atau internal).
Terhubung menggunakan endpoint publik
from pyhive import hive if __name__ == '__main__': # Ganti <endpoint>, <username>, dan <token> dengan informasi aktual Anda. cursor = hive.connect('<endpoint>', port=443, scheme='https', username='<username>', password='<token>').cursor() cursor.execute('show databases') print(cursor.fetchall()) cursor.close()Terhubung menggunakan endpoint internal wilayah yang sama
from pyhive import hive if __name__ == '__main__': # Ganti <endpoint>, <username>, dan <token> dengan informasi aktual Anda. cursor = hive.connect('<endpoint>', port=80, scheme='http', username='<username>', password='<token>').cursor() cursor.execute('show databases') print(cursor.fetchall()) cursor.close()
Terhubung ke Spark Thrift Server menggunakan Java
Tambahkan dependensi Maven berikut ke file
pom.xml:<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.1.0</version> </dependency> </dependencies>CatatanVersi Hive bawaan di Serverless Spark adalah 2.x. Oleh karena itu, hanya versi hive-jdbc 2.x yang didukung.
Tulis kode Java untuk terhubung ke Spark Thrift Server.
Berikut adalah contoh kode Java yang terhubung ke Spark Thrift Server dan menanyakan daftar database.
Terhubung menggunakan endpoint publik
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; import org.apache.hive.jdbc.HiveStatement; public class Main { public static void main(String[] args) throws Exception { String url = "jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>"; Class.forName("org.apache.hive.jdbc.HiveDriver"); Connection conn = DriverManager.getConnection(url); HiveStatement stmt = (HiveStatement) conn.createStatement(); String sql = "show databases"; System.out.println("Running " + sql); ResultSet res = stmt.executeQuery(sql); ResultSetMetaData md = res.getMetaData(); String[] columns = new String[md.getColumnCount()]; for (int i = 0; i < columns.length; i++) { columns[i] = md.getColumnName(i + 1); } while (res.next()) { System.out.print("Row " + res.getRow() + "=["); for (int i = 0; i < columns.length; i++) { if (i != 0) { System.out.print(", "); } System.out.print(columns[i] + "='" + res.getObject(i + 1) + "'"); } System.out.println(")]"); } conn.close(); } }Terhubung menggunakan endpoint internal wilayah yang sama
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; import org.apache.hive.jdbc.HiveStatement; public class Main { public static void main(String[] args) throws Exception { String url = "jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>"; Class.forName("org.apache.hive.jdbc.HiveDriver"); Connection conn = DriverManager.getConnection(url); HiveStatement stmt = (HiveStatement) conn.createStatement(); String sql = "show databases"; System.out.println("Running " + sql); ResultSet res = stmt.executeQuery(sql); ResultSetMetaData md = res.getMetaData(); String[] columns = new String[md.getColumnCount()]; for (int i = 0; i < columns.length; i++) { columns[i] = md.getColumnName(i + 1); } while (res.next()) { System.out.print("Row " + res.getRow() + "=["); for (int i = 0; i < columns.length; i++) { if (i != 0) { System.out.print(", "); } System.out.print(columns[i] + "='" + res.getObject(i + 1) + "'"); } System.out.println(")]"); } conn.close(); } }
Terhubung ke Spark Thrift Server menggunakan Spark Beeline
Jika menggunakan kluster mandiri, Anda perlu pergi ke direktori
binSpark, kemudian gunakan beeline untuk terhubung ke Spark Thrift Server.Terhubung menggunakan endpoint publik
cd /opt/apps/SPARK3/spark-3.4.2-hadoop3.2-1.0.3/bin/ ./beeline -u "jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>"Terhubung menggunakan endpoint internal wilayah yang sama
cd /opt/apps/SPARK3/spark-3.4.2-hadoop3.2-1.0.3/bin/ ./beeline -u "jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>"CatatanContoh jalur instalasi Spark di kluster EMR pada ECS adalah
/opt/apps/SPARK3/spark-3.4.2-hadoop3.2-1.0.3. Sesuaikan jalur berdasarkan instalasi Spark sebenarnya pada klien Anda. Gunakan perintahenv | grep SPARK_HOMEjika Anda tidak yakin tentang jalur instalasi Spark.Jika menggunakan kluster EMR pada ECS, Anda dapat langsung menggunakan klien Spark Beeline untuk terhubung ke Spark Thrift Server.
Terhubung menggunakan endpoint publik
spark-beeline -u "jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>"Terhubung menggunakan endpoint internal wilayah yang sama
spark-beeline -u "jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>"
Saat menggunakan Hive Beeline untuk terhubung ke Serverless Spark Thrift Server, kesalahan berikut biasanya terjadi karena versi Hive Beeline tidak kompatibel dengan Spark Thrift Server. Oleh karena itu, kami sarankan menggunakan Hive Beeline 2.x.
24/08/22 15:09:11 [main]: ERROR jdbc.HiveConnection: Error opening session
org.apache.thrift.transport.TTransportException: HTTP Response code: 404Terhubung ke Spark Thrift Server dengan mengonfigurasi Apache Superset
Apache Superset adalah platform eksplorasi dan visualisasi data modern dengan berbagai macam bentuk grafik, mulai dari grafik garis sederhana hingga grafik geospasial yang sangat rinci. Untuk informasi lebih lanjut tentang Superset, lihat Superset.
Instal dependensi.
Pastikan Anda telah menginstal paket
thriftversi 0.20.0. Jika belum, instal menggunakan perintah berikut:pip install thrift==0.20.0Mulai Superset dan buka antarmuka Superset.
Untuk informasi lebih lanjut tentang cara memulai Superset, lihat Dokumentasi Superset.
Klik DATABASE di pojok kanan atas halaman untuk pergi ke halaman Connect a database.
Di halaman Connect a database, pilih Apache Spark SQL.
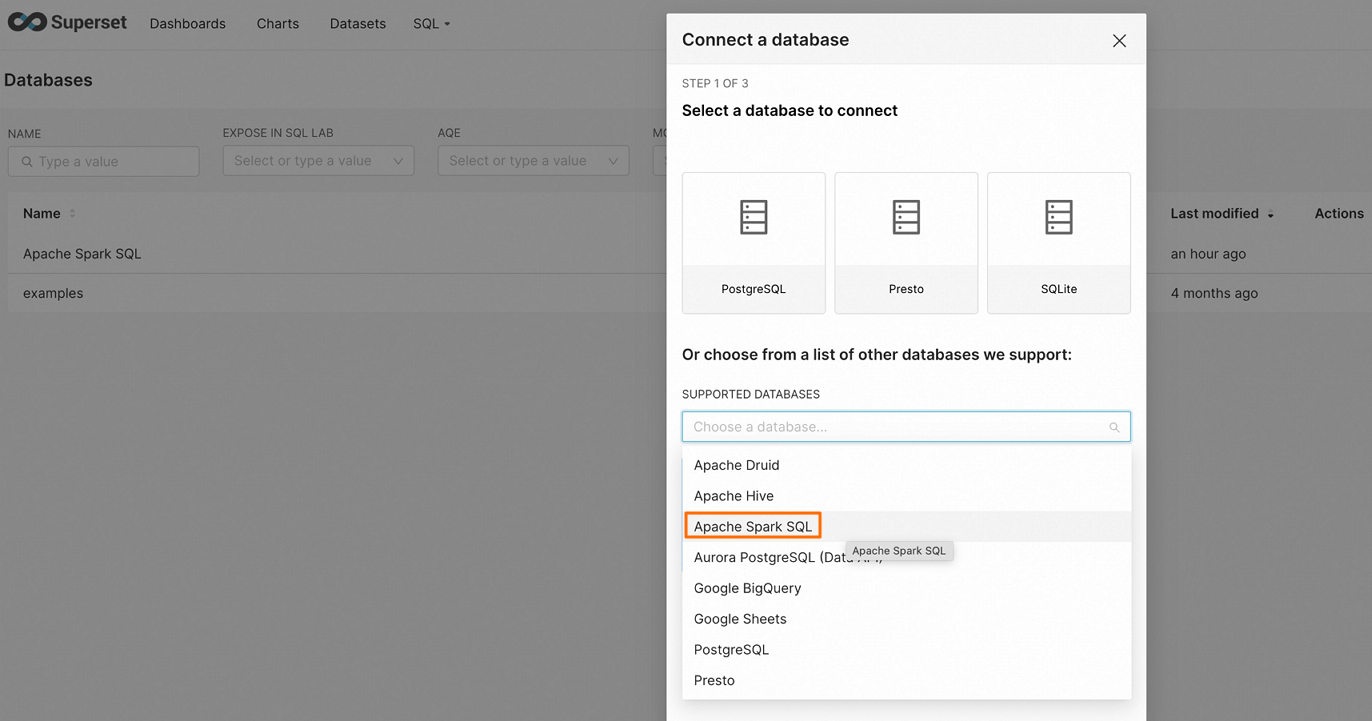
Masukkan string koneksi dan konfigurasikan parameter sumber data terkait.
Terhubung menggunakan endpoint publik
hive+https://<username>:<token>@<endpoint>:443/<db_name>Terhubung menggunakan endpoint internal wilayah yang sama
hive+http://<username>:<token>@<endpoint>:80/<db_name>Klik FINISH untuk mengonfirmasi koneksi dan verifikasi berhasil.
Terhubung ke Spark Thrift Server dengan mengonfigurasi Hue
Hue adalah antarmuka web open-source populer untuk berinteraksi dengan ekosistem Hadoop. Untuk informasi lebih lanjut tentang Hue, lihat Dokumentasi Resmi Hue.
Instal dependensi.
Pastikan Anda telah menginstal paket
thriftversi 0.20.0. Jika belum, instal menggunakan perintah berikut:pip install thrift==0.20.0Tambahkan string koneksi Spark SQL ke file konfigurasi Hue.
Temukan file konfigurasi Hue (biasanya terletak di
/etc/hue/hue.conf) dan tambahkan konten berikut ke file tersebut:Terhubung menggunakan endpoint publik
[[[sparksql]]] name = Spark Sql interface=sqlalchemy options='{"url": "hive+https://<username>:<token>@<endpoint>:443/"}'Terhubung menggunakan endpoint internal wilayah yang sama
[[[sparksql]]] name = Spark Sql interface=sqlalchemy options='{"url": "hive+http://<username>:<token>@<endpoint>:80/"}'Mulai ulang Hue.
Setelah memodifikasi konfigurasi, jalankan perintah berikut untuk memulai ulang layanan Hue agar perubahan diterapkan:
sudo service hue restartVerifikasi koneksi.
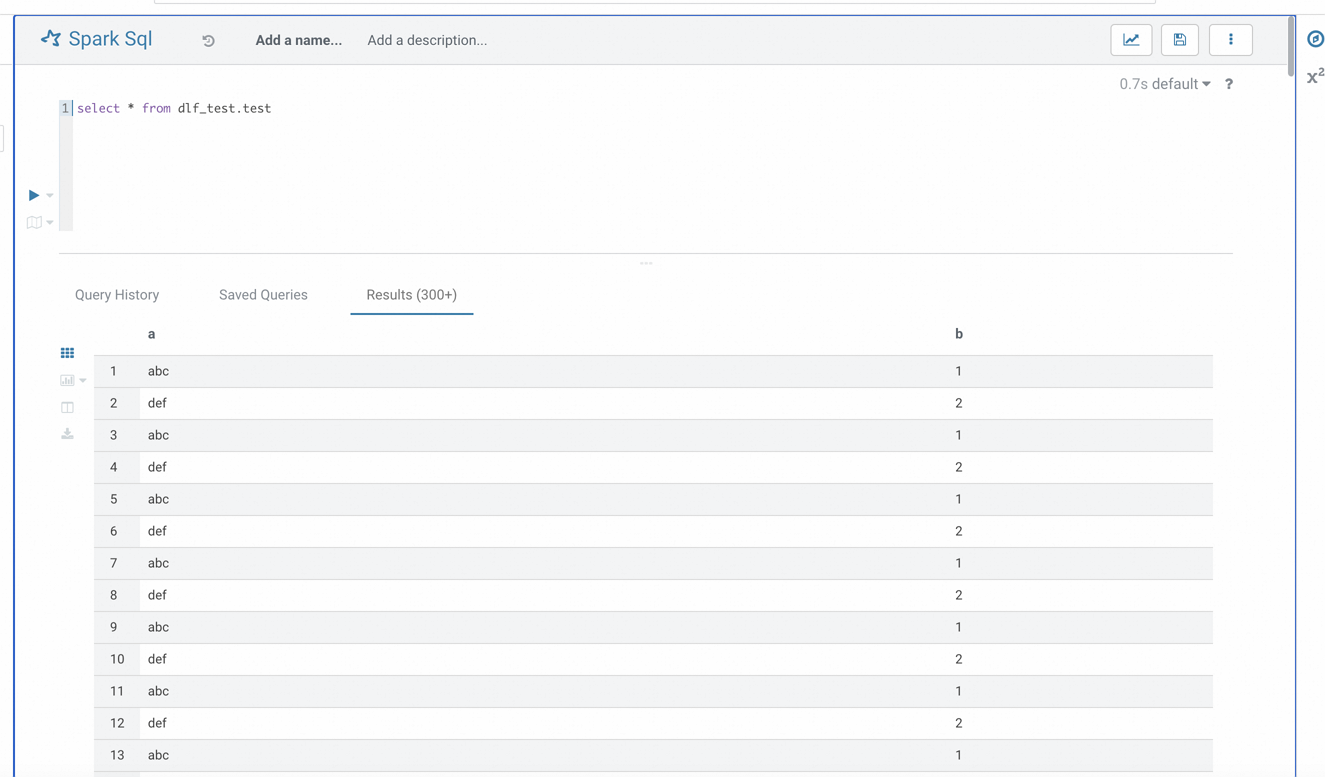
Setelah Hue berhasil dimulai ulang, akses antarmuka Hue dan temukan opsi Spark SQL. Jika konfigurasi benar, Anda seharusnya dapat terhubung ke Spark Thrift Server dan menjalankan kueri SQL.
Terhubung ke Spark Thrift Server menggunakan DataGrip
DataGrip adalah lingkungan manajemen database untuk pengembang, dirancang untuk memfasilitasi penulisan, pembuatan, dan manajemen database. Database dapat berjalan secara lokal, di server, atau di cloud. Untuk informasi lebih lanjut tentang DataGrip, lihat DataGrip.
Instal DataGrip. Untuk informasi lebih lanjut, lihat Instal DataGrip.
Versi DataGrip yang digunakan dalam contoh ini adalah 2025.1.2.
Buka klien DataGrip dan akses antarmuka DataGrip.
Buat proyek.
Klik
 dan pilih .
dan pilih .
Di kotak dialog New Project, masukkan nama proyek, seperti
Spark, dan klik OK
Klik ikon di bilah menu Database Explorer
 . Pilih .
. Pilih .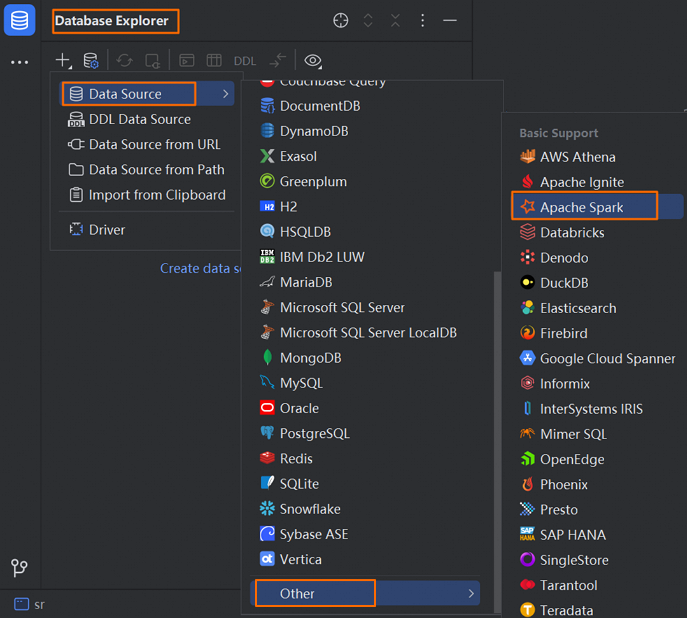
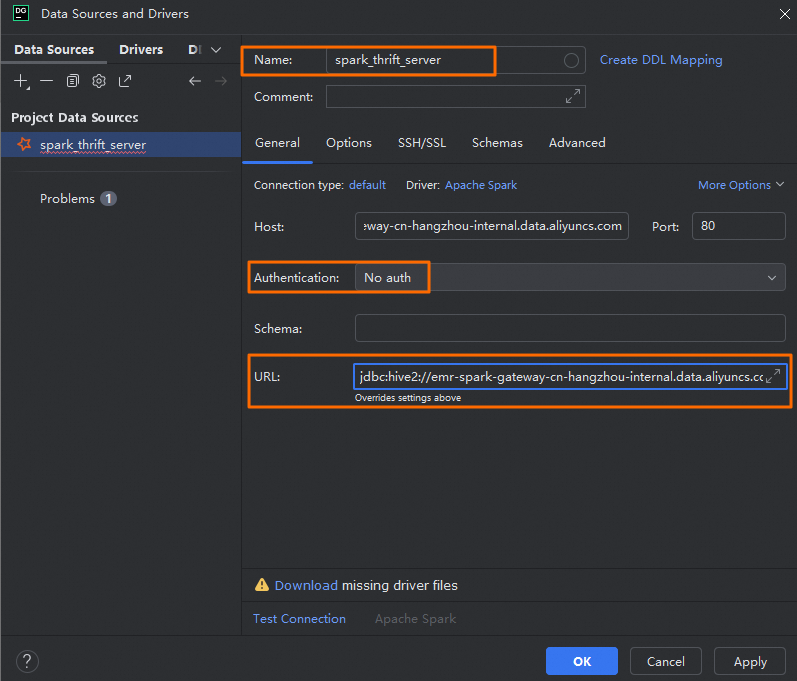
Di kotak dialog Data Sources and Drivers, konfigurasikan parameter berikut:
Tab
Parameter
Deskripsi
General
Name
Nama koneksi kustom. Contohnya, spark_thrift_server.
Authentication
Metode autentikasi. Dalam contoh ini, No auth dipilih.
Dalam lingkungan produksi, pilih User & Password untuk memastikan hanya pengguna yang berwenang yang dapat mengirimkan tugas SQL, yang meningkatkan keamanan sistem.
Driver
Klik Apache Spark, lalu klik Go to Driver untuk memastikan versi Driver adalah
ver. 1.2.2.CatatanKarena versi engine Serverless Spark saat ini adalah 3.x, versi Driver harus 1.2.2 untuk memastikan stabilitas sistem dan kompatibilitas fitur.

URL
URL untuk terhubung ke Spark Thrift Server. Berdasarkan lingkungan jaringan Anda (publik atau internal), Anda dapat memilih metode koneksi yang sesuai.
Terhubung menggunakan endpoint publik
jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>Terhubung menggunakan endpoint internal wilayah yang sama
jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>
Options
Run keep-alive query
Parameter ini opsional. Pilih parameter ini untuk mencegah pemutusan otomatis karena timeout.
Klik Test Connection untuk memastikan sumber data dikonfigurasi dengan sukses.

Klik OK untuk menyelesaikan konfigurasi.
Gunakan DataGrip untuk mengelola Spark Thrift Server.
Setelah DataGrip berhasil terhubung ke Spark Thrift Server, Anda dapat melakukan pengembangan data. Untuk informasi lebih lanjut, lihat Bantuan DataGrip.
Sebagai contoh, di bawah koneksi yang dibuat, Anda dapat mengklik kanan tabel target dan memilih . Kemudian, Anda dapat menulis dan menjalankan skrip SQL di editor SQL di sebelah kanan untuk melihat informasi data tabel.

Hubungkan Redash ke Spark Thrift Server
Redash adalah alat BI open-source yang menyediakan kemampuan penulisan kueri basis data berbasis web dan visualisasi data.
Instal Redash. Untuk instruksi instalasi, lihat Mengatur Instance Redash.
Instal dependensi. Pastikan paket
thriftversi 0.20.0 telah diinstal. Jika belum diinstal, jalankan perintah berikut:pip install thrift==0.20.0Masuk ke Redash.
Di panel navigasi sebelah kiri, klik Settings. Di tab Data Sources, klik +New Data Source.
Di kotak dialog, konfigurasikan parameter berikut, lalu klik Create.

Parameter | Deskripsi | |
Type Selection | Jenis sumber data. Pilih Hive (HTTP). | |
Configuration | Name | Masukkan nama kustom untuk sumber data. |
Host | Masukkan endpoint Spark Thrift Server Anda. Anda dapat menemukan endpoint publik atau internal di tab Overview. | |
Port | Gunakan 443 untuk akses melalui domain publik, atau 80 untuk domain internal. | |
HTTP Path | Atur ke | |
Username | Masukkan username apa saja seperti | |
Password | Masukkan nilai Token yang Anda buat. | |
HTTP Scheme | Masukkan | |
Di bagian atas halaman, pilih . Anda dapat menulis pernyataan SQL di editor.

Lihat pekerjaan yang dijalankan menggunakan sesi tertentu
Anda dapat melihat pekerjaan yang dijalankan menggunakan sesi tertentu di halaman Sessions. Prosedur:
Di halaman Sessions, klik nama sesi yang diinginkan.
Di halaman yang muncul, klik tab Execution Records.
Di tab Execution Records, Anda dapat melihat detail pekerjaan, seperti ID run dan waktu mulai, serta mengakses Spark UI melalui tautan di kolom Spark UI.
