Alibaba Cloud DataWorks mendukung pembuatan node Hive, Spark SQL, Spark, dan lainnya di E-MapReduce untuk mengonfigurasi serta menjadwalkan alur kerja tugas. DataWorks juga menyediakan fitur manajemen metadata dan pemantauan kualitas data untuk membantu pengguna mengembangkan serta mengelola data secara efisien. Topik ini menjelaskan cara mengirim pekerjaan melalui Alibaba Cloud DataWorks.
Jenis kluster yang didukung
DataWorks saat ini mendukung pendaftaran jenis kluster berikut:
Kluster DataLake (data lake baru)
Kluster Kustom
Kluster Hadoop (data lake lama)
Anda dapat menggunakan kluster EMR Hadoop dengan versi berikut di DataWorks:
EMR-3.38.2, EMR-3.38.3, EMR-4.9.0, EMR-5.6.0, EMR-3.26.3, EMR-3.27.2, EMR-3.29.0, EMR-3.32.0, EMR-3.35.0, EMR-4.3.0, EMR-4.4.1, EMR-4.5.0, EMR-4.5.1, EMR-4.6.0, EMR-4.8.0, EMR-5.2.1, EMR-5.4.3.
Kluster Hadoop (data lake lama) tidak lagi direkomendasikan. Anda harus bermigrasi ke kluster DataLake sesegera mungkin. Untuk informasi lebih lanjut, lihat Migrasi Kluster Hadoop ke Kluster DataLake.
Batasan
Tipe Tugas: Anda tidak dapat menjalankan tugas EMR Flink di konsol DataWorks.
Pelaksanaan tugas: Anda dapat menggunakan grup sumber daya serverless (direkomendasikan) atau grup sumber daya eksklusif versi lama untuk penjadwalan guna menjalankan tugas EMR.
Tata kelola tugas:
Hanya tugas SQL pada node EMR Hive, EMR Spark, dan EMR Spark SQL yang dapat digunakan untuk menghasilkan alur data. Jika kluster EMR Anda adalah V3.43.1, V5.9.1, atau versi minor setelah V3.43.1 atau V5.9.1, Anda dapat melihat alur data tingkat tabel dan alur data tingkat bidang dari node sebelumnya yang dibuat berdasarkan kluster tersebut.
CatatanUntuk node EMR berbasis Spark, jika kluster EMR adalah V5.8.0, V3.42.0, atau versi minor setelah V5.8.0 atau V3.42.0, node EMR berbasis Spark tersebut dapat digunakan untuk melihat alur data tingkat tabel dan alur data tingkat bidang. Jika kluster EMR adalah versi minor sebelum V5.8.0 atau V3.42.0, hanya node EMR berbasis Spark yang menggunakan Spark 2.x yang dapat digunakan untuk melihat alur data tingkat tabel.
Jika Anda ingin mengelola metadata untuk kluster DataLake atau kluster kustom di DataWorks, Anda harus mengonfigurasi EMR-HOOK di kluster terlebih dahulu. Tanpa konfigurasi EMR-HOOK, metadata tidak akan ditampilkan secara real-time, log audit tidak dapat dihasilkan, dan alur data tidak akan muncul di DataWorks. Selain itu, tugas tata kelola EMR tidak dapat dijalankan. EMR-HOOK dapat dikonfigurasikan untuk layanan EMR Hive dan EMR Spark SQL. Untuk informasi lebih lanjut, lihat Gunakan fitur ekstensi Hive untuk mencatat alur data dan informasi akses historis dan Gunakan fitur ekstensi Spark SQL untuk mencatat alur data dan informasi akses historis.
Wilayah yang didukung: EMR Serverless Spark tersedia di wilayah China (Hangzhou), China (Shanghai), China (Beijing), China (Zhangjiakou), China (Shenzhen), Singapura, Jerman (Frankfurt), dan AS (Silicon Valley).
Untuk kluster EMR dengan otentikasi Kerberos diaktifkan, Anda harus menambahkan aturan masuk port UDP ke grup keamanan kluster EMR untuk blok CIDR vSwitch yang terkait dengan grup sumber daya.
CatatanUntuk menambahkan aturan masuk, ikuti langkah-langkah berikut: Masuk ke konsol EMR. Pergi ke tab Basic Information dari kluster EMR Anda. Di bagian Keamanan pada tab Informasi Dasar, klik ikon
 di sebelah kanan parameter Cluster Security Group. Pada tab Security Group Details halaman Grup Keamanan, klik tab Inbound di bagian Access Rule. Pada tab Masuk, klik Add Rule. Setel parameter Protocol Type ke Custom UDP, parameter Port Range ke konfigurasi yang ditentukan dalam file
di sebelah kanan parameter Cluster Security Group. Pada tab Security Group Details halaman Grup Keamanan, klik tab Inbound di bagian Access Rule. Pada tab Masuk, klik Add Rule. Setel parameter Protocol Type ke Custom UDP, parameter Port Range ke konfigurasi yang ditentukan dalam file /etc/krb5.confdari kluster EMR Anda, dan parameter Authorization Object ke blok CIDR vSwitch yang terkait dengan grup sumber daya.
Prasyarat
Izin berikut telah diberikan.
Hanya Pengguna RAM atau Peran RAM dengan identitas berikut yang dapat mendaftarkan kluster EMR. Untuk detail operasi, lihat Berikan Izin kepada Pengguna RAM.
Akun Alibaba Cloud.
Pengguna RAM atau Peran RAM yang memiliki peran
workspace administrator roledi DataWorks dan kebijakanAliyunEMRFullAccess.Pengguna RAM atau Peran RAM yang memiliki kebijakan AliyunDataWorksFullAccess
dan AliyunEMRFullAccess.
Jenis kluster EMR yang sesuai telah dibeli. Dalam contoh ini, wilayah kluster EMR adalah China (Shanghai).
Untuk informasi lebih lanjut tentang jenis kluster yang didukung oleh DataWorks, lihat Jenis Kluster yang Didukung.
Perhatian
Jika Anda ingin mengisolasi data EMR di lingkungan pengembangan dari data EMR di lingkungan produksi menggunakan ruang kerja dalam mode standar, Anda harus mendaftarkan kluster EMR yang berbeda di lingkungan pengembangan dan produksi ruang kerja. Selain itu, metadata kluster EMR harus disimpan menggunakan salah satu metode berikut:
Metode 1: Simpan metadata di dua katalog berbeda di DLF. Kami merekomendasikan Anda menggunakan metode ini. Untuk informasi lebih lanjut, lihat Gunakan DLF untuk Penyimpanan Metadata Terpadu.
Metode 2: Simpan metadata di dua database ApsaraDB RDS yang berbeda. Untuk informasi tentang cara mengonfigurasi database ApsaraDB RDS sebagai metabase kluster EMR, lihat Konfigurasikan Database ApsaraDB RDS untuk MySQL yang Dikelola Sendiri.
Anda dapat mendaftarkan kluster EMR ke beberapa ruang kerja dalam Akun Alibaba Cloud yang sama tetapi tidak dapat mendaftarkan kluster EMR ke beberapa ruang kerja lintas Akun Alibaba Cloud. Sebagai contoh, jika Anda mendaftarkan kluster EMR ke ruang kerja dalam Akun Alibaba Cloud saat ini, Anda tidak dapat mendaftarkan kluster tersebut ke ruang kerja di Akun Alibaba Cloud lainnya.
Jika Grup Sumber Daya DataWorks dan kluster EMR diterapkan di virtual private cloud (VPC) yang sama dan menggunakan vSwitch yang sama, tetapi Grup Sumber Daya tidak dapat terhubung ke kluster EMR seperti yang diharapkan, periksa aturan grup keamanan kluster EMR dan tambahkan blok CIDR vSwitch dan aturan masuk port komponen open source umum ke aturan grup keamanan kluster EMR untuk memastikan bahwa Anda dapat menggunakan Grup Sumber Daya DataWorks untuk mengakses kluster EMR seperti yang diharapkan. Untuk informasi lebih lanjut, lihat Kelola Grup Keamanan.
Siapkan lingkungan DataWorks
Sebelum Anda mengembangkan tugas di DataWorks, Anda harus mengaktifkan DataWorks. Untuk informasi lebih lanjut, lihat Persiapkan Lingkungan.
Langkah 1: Buat ruang kerja
Jika ruang kerja ada di wilayah China (Shanghai), lewati langkah ini dan gunakan ruang kerja yang ada.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah China (Shanghai).
Di panel navigasi kiri, klik Workspace. Pada halaman Ruang Kerja, klik Create Workspace untuk membuat ruang kerja dalam mode standar. Untuk informasi lebih lanjut, lihat Buat Ruang Kerja. Untuk ruang kerja dalam mode standar, lingkungan pengembangan dipisahkan dari lingkungan produksi.
Langkah 2: Buat grup sumber daya serverless
Tutorial ini memerlukan grup sumber daya serverless untuk sinkronisasi data dan penjadwalan. Oleh karena itu, Anda perlu membeli dan mengonfigurasi grup sumber daya serverless.
Beli grup sumber daya serverless.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah China (Shanghai). Di panel navigasi kiri, klik Resource Group untuk pergi ke halaman Resource Groups.
Di halaman Grup Sumber Daya, klik Create Resource Group. Di halaman pembelian, atur Region and Zone ke China (Shanghai), tentukan resource group name, konfigurasikan parameter lainnya sesuai petunjuk, dan ikuti instruksi di layar untuk membayar grup sumber daya. Untuk informasi tentang rincian penagihan grup sumber daya serverless, lihat Penagihan Grup Sumber Daya Serverless.
CatatanJika tidak ada virtual private cloud (VPC) atau vSwitch di wilayah saat ini, klik tautan dalam deskripsi parameter untuk pergi ke konsol VPC untuk membuatnya. Untuk informasi lebih lanjut tentang VPC dan vSwitch, lihat Apa itu VPC?
Asosiasikan grup sumber daya serverless dengan ruang kerja DataWorks.
Anda hanya dapat menggunakan grup sumber daya serverless yang Anda beli dalam operasi selanjutnya setelah Anda mengasosiasikan grup sumber daya serverless dengan ruang kerja.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah China (Shanghai). Di panel navigasi kiri, klik Grup Sumber Daya. Di halaman Grup Sumber Daya, temukan grup sumber daya serverless yang Anda beli, dan klik Associate Workspace di kolom Actions. Di panel Asosiasikan Ruang Kerja, temukan ruang kerja yang ingin Anda asosiasikan dan klik Associate di kolom Tindakan.
Aktifkan grup sumber daya serverless untuk mengakses Internet.
Data uji yang digunakan dalam tutorial ini harus diperoleh melalui Internet. Secara default, grup sumber daya serverless tidak dapat digunakan untuk mengakses Internet. Anda harus mengonfigurasi gateway NAT Internet untuk VPC yang terkait dengan grup sumber daya serverless dan mengonfigurasi EIP untuk VPC untuk membangun koneksi jaringan antara VPC dan lingkungan jaringan data uji. Dengan cara ini, Anda dapat menggunakan grup sumber daya serverless untuk mengakses data uji.
Pergi ke halaman Gateway NAT Internet di konsol VPC. Di bilah navigasi atas, pilih wilayah China (Shanghai).
Klik Create Internet NAT Gateway dan konfigurasikan parameter. Tabel berikut menjelaskan parameter utama yang diperlukan dalam tutorial ini. Anda dapat mempertahankan nilai default untuk parameter yang tidak dijelaskan dalam tabel berikut.
Parameter
Deskripsi
Region
Pilih China (Shanghai).
VPC
Pilih VPC dan vSwitch yang terkait dengan grup sumber daya.
Untuk melihat VPC dan vSwitch yang terkait dengan grup sumber daya, lakukan operasi berikut: Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah tempat Anda mengaktifkan DataWorks. Di panel navigasi kiri, klik Resource Group. Di halaman Grup Sumber Daya, temukan grup sumber daya yang dibuat dan klik Network Settings di kolom Actions. Di bagian Data Scheduling & Data Integration tab Pengikatan VPC pada halaman yang muncul, lihat VPC dan vSwitch yang terkait dengan grup sumber daya. Untuk informasi lebih lanjut tentang VPC dan vSwitch, lihat Apa itu VPC?
Associate vSwitch
Access Mode
Pilih Mode SNAT Aktif.
EIP
Pilih Beli EIP.
Service-linked Role
Klik Create Service-linked Role untuk membuat peran terkait layanan jika ini pertama kalinya Anda membuat gateway NAT.
Klik Buy Now. Di halaman Konfirmasi, baca ketentuan layanan, pilih kotak centang untuk Ketentuan Layanan, dan kemudian klik Activate Now.
Untuk informasi lebih lanjut tentang cara membuat dan menggunakan grup sumber daya serverless, lihat Gunakan Grup Sumber Daya Serverless.
Langkah 3: Daftarkan kluster EMR ke DataWorks dan inisialisasi grup sumber daya
Anda hanya dapat menggunakan kluster EMR di DataWorks jika Anda mendaftarkan kluster tersebut ke DataWorks.
Pergi ke halaman Daftar Kluster EMR.
Pergi ke halaman SettingCenter.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah China (Shanghai). Di panel navigasi kiri, pilih . Di halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down dan klik Go to Management Center.
Di panel navigasi kiri halaman SettingCenter, klik Cluster Management. Di halaman Cluster Management, klik Register Cluster. Di kotak dialog Pilih Jenis Kluster, klik E-MapReduce. Halaman Register EMR Cluster muncul.
Daftarkan kluster EMR ke DataWorks.
Di halaman Register EMR Cluster, konfigurasikan informasi kluster. Tabel berikut menjelaskan parameter utama.
Parameter
Deskripsi
Alibaba Cloud Account to Which Cluster Belongs
Atur ke Current Alibaba Cloud Account.
Cluster Type
Pilih Data Lake.
Default Access Identity
Atur ke Cluster Account: hadoop.
Pass Proxy User Information
Atur ke Pass.
Inisialisasi grup sumber daya.
Pergi ke halaman Cluster Management di SettingCenter. Temukan kluster EMR yang didaftarkan ke DataWorks dan klik Initialize Resource Group di bagian yang menampilkan informasi kluster EMR.
Di kotak dialog Inisialisasi Grup Sumber Daya, temukan grup sumber daya yang diinginkan dan klik Initialize.
Setelah inisialisasi selesai, klik OK.
PentingAnda harus memastikan bahwa inisialisasi grup sumber daya berhasil. Jika tidak, tugas yang menggunakan grup sumber daya mungkin gagal. Jika inisialisasi grup sumber daya gagal, Anda dapat melihat penyebab kegagalan dan melakukan diagnosis konektivitas jaringan sesuai petunjuk.
Untuk informasi lebih lanjut tentang cara mendaftarkan kluster EMR, lihat DataStudio (versi lama): Asosiasikan Sumber Daya Komputasi EMR.
Kirim Pekerjaan EMR
Kirim Pekerjaan EMR Hive
Langkah 1: Buat Node EMR Hive
Pergi ke halaman DataStudio.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Di panel navigasi kiri, pilih . Di halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down dan klik Go to Data Development.
Buat Node EMR Hive.
Temukan alur kerja yang diinginkan, klik kanan nama alur kerja, dan pilih .
CatatanSebagai alternatif, Anda bisa mengarahkan pointer ke ikon Create dan pilih .
Di kotak dialog Create Node, konfigurasikan parameter Name, Engine Instance, Node Type, dan Path. Klik Confirm. Tab konfigurasi Node EMR Hive muncul.
CatatanNama node hanya dapat berisi huruf, angka, garis bawah (_), dan titik (.).
Langkah 2: Kembangkan Tugas EMR Hive
Anda dapat mengembangkan tugas Hive di tab konfigurasi Node EMR Hive.
Kembangkan Kode SQL
Di editor SQL, kembangkan kode node. Anda dapat mendefinisikan variabel dalam format ${Variable} di kode node dan mengonfigurasi parameter penjadwalan yang ditetapkan untuk variabel sebagai nilai di bagian Scheduling Parameters tab Scheduling Configuration. Dengan cara ini, nilai parameter penjadwalan diganti secara dinamis di kode node ketika node dijadwalkan untuk dijalankan. Untuk informasi lebih lanjut tentang cara menggunakan parameter penjadwalan, lihat Format yang Didukung Parameter Penjadwalan. Contoh kode:
show tables;
select '${var}'; -- Anda dapat menetapkan parameter penjadwalan tertentu ke variabel var.
select * from userinfo ;Ukuran pernyataan SQL untuk pengembangan tugas Hive tidak boleh melebihi 130 KB.
Jika beberapa sumber daya komputasi EMR terhubung ke ruang kerja Anda di DataStudio, pilih satu sumber daya komputasi. Jika hanya satu sumber daya komputasi EMR yang terhubung ke ruang kerja Anda di DataStudio, Anda tidak perlu memilih sumber data.
Jika Anda ingin mengubah parameter penjadwalan yang ditetapkan ke variabel dalam kode, klik Run with Parameters di bilah alat atas. Untuk informasi lebih lanjut tentang logika penetapan nilai parameter penjadwalan, lihat Apa saja perbedaan dalam logika penetapan nilai parameter penjadwalan antara mode Jalankan, Jalankan dengan Parameter, dan Lakukan Pengujian Asap di Lingkungan Pengembangan?
Jalankan Tugas Hive
Di bilah alat, klik ikon
 . Di kotak dialog Parameters, pilih grup sumber daya yang diinginkan dari daftar drop-down Nama Grup Sumber Daya dan klik Run.Catatan
. Di kotak dialog Parameters, pilih grup sumber daya yang diinginkan dari daftar drop-down Nama Grup Sumber Daya dan klik Run.CatatanJika Anda ingin mengakses sumber daya komputasi di jaringan publik atau lingkungan jaringan VPC, gunakan grup sumber daya penjadwalan yang terhubung ke sumber daya komputasi. Untuk informasi lebih lanjut, lihat Solusi Konektivitas Jaringan.
Untuk mengubah grup sumber daya dalam operasi selanjutnya, Anda dapat mengklik ikon
(Run with Parameters) untuk mengubah grup sumber daya di kotak dialog Parameter.Saat Anda mengquery data menggunakan node EMR Hive, query dapat mengembalikan maksimal 10.000 catatan data, dan ukuran total data yang dikembalikan tidak boleh melebihi 10 MB.
Klik ikon
 di bilah alat atas untuk menyimpan pernyataan SQL.
di bilah alat atas untuk menyimpan pernyataan SQL.Opsional. Lakukan pengujian asap.
Anda dapat melakukan pengujian asap pada node di lingkungan pengembangan saat Anda mengirimkan node atau setelah node dikirimkan. Untuk informasi lebih lanjut, lihat Lakukan Pengujian Asap.
Jika Anda ingin memodifikasi antrian tempat pekerjaan dikirimkan, lihat Konfigurasikan Parameter Lanjutan.
Langkah 3: Konfigurasikan properti penjadwalan
Jika Anda ingin sistem menjalankan tugas secara berkala pada node, Anda dapat mengklik Properties di panel navigasi kanan pada tab konfigurasi node untuk mengonfigurasi properti penjadwalan tugas berdasarkan kebutuhan bisnis Anda. Untuk informasi lebih lanjut, lihat Ikhtisar.
Anda harus mengonfigurasi parameter Rerun dan Parent Nodes di tab Properti sebelum Anda mengirimkan tugas.
Langkah 4: Terapkan tugas
Setelah tugas di node dikonfigurasi, Anda harus mengirimkan dan menerapkan tugas. Setelah Anda mengirimkan dan menerapkan tugas, sistem akan menjalankan tugas secara berkala berdasarkan konfigurasi penjadwalan.
Klik ikon
 di bilah alat atas untuk menyimpan tugas.
di bilah alat atas untuk menyimpan tugas.Klik ikon
 di bilah alat atas untuk mengirimkan tugas.
di bilah alat atas untuk mengirimkan tugas.Di kotak dialog Submit, konfigurasikan parameter Change description. Kemudian, tentukan apakah akan meninjau kode tugas setelah Anda mengirimkan tugas berdasarkan kebutuhan bisnis Anda.
CatatanAnda harus mengonfigurasi parameter Rerun dan Parent Nodes di tab Properti sebelum Anda mengirimkan tugas.
Anda dapat menggunakan fitur tinjauan kode untuk memastikan kualitas kode tugas dan mencegah kesalahan eksekusi tugas yang disebabkan oleh kode tugas yang tidak valid. Jika Anda mengaktifkan fitur tinjauan kode, kode tugas yang dikirimkan hanya dapat diterapkan setelah kode tugas lulus tinjauan kode. Untuk informasi lebih lanjut, lihat Tinjauan Kode.
Jika Anda menggunakan ruang kerja dalam mode standar, Anda harus menerapkan tugas di lingkungan produksi setelah Anda mengirimkan tugas. Untuk menerapkan tugas pada node, klik Deploy di sudut kanan atas tab konfigurasi node. Untuk informasi lebih lanjut, lihat Terapkan Node.
Kirim Pekerjaan EMR Spark SQL
1. Buat Node EMR Spark SQL
Pergi ke halaman DataStudio.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Di panel navigasi kiri, pilih . Di halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down dan klik Go to Data Development.
Buat Node EMR Spark SQL.
Klik kanan alur bisnis target dan pilih .
CatatanSebagai alternatif, arahkan kursor ke New dan pilih .
Di kotak dialog Create Node, atur Name, Engine Instance, Node Type, dan Path. Klik Confirm. Tab konfigurasi Node EMR Spark SQL muncul.
CatatanNama node dapat mencakup huruf, angka, garis bawah (_), dan titik (.).
2. Kembangkan Tugas EMR Spark SQL
Di tab konfigurasi Node EMR Spark SQL, klik dua kali node yang Anda buat. Tab pengembangan tugas muncul.
Kembangkan Kode SQL
Di area pengeditan SQL, kembangkan kode tugas. Anda dapat mendefinisikan variabel dalam kode menggunakan format ${nama_variabel}. Di tab konfigurasi node, Anda dapat menetapkan nilai ke variabel di bagian Scheduling Configuration > Scheduling Parameters di panel navigasi kanan. Ini memungkinkan Anda untuk secara dinamis meneruskan parameter dalam skenario penjadwalan. Untuk informasi lebih lanjut tentang cara menggunakan parameter penjadwalan, lihat Format yang Didukung Parameter Penjadwalan. Berikut adalah contohnya.
SHOW TABLES;
-- Definisikan variabel bernama var menggunakan ${var}. Jika Anda menetapkan nilai ${yyyymmdd} ke variabel ini, Anda dapat membuat tabel dengan cap waktu data sebagai akhiran.
CREATE TABLE IF NOT EXISTS userinfo_new_${var} (
ip STRING COMMENT'Alamat IP',
uid STRING COMMENT'ID Pengguna'
)PARTITIONED BY(
dt STRING
); -- Ini dapat digunakan dengan parameter penjadwalan.Pernyataan SQL tidak boleh melebihi 130 KB.
Jika beberapa sumber daya komputasi EMR dilampirkan ke ruang kerja Anda di Pengembangan Data, Anda harus memilih sumber daya komputasi.
Jalankan tugas SQL
Di bilah alat, klik ikon
. Di kotak dialog Parameters, pilih grup sumber daya penjadwalan yang Anda buat dan klik Run.CatatanUntuk mengakses sumber daya komputasi di lingkungan jaringan publik atau VPC, Anda harus menggunakan grup sumber daya penjadwalan yang telah lulus uji konektivitas dengan sumber daya komputasi. Untuk informasi lebih lanjut, lihat Solusi Konektivitas Jaringan.
Untuk mengubah grup sumber daya untuk eksekusi tugas selanjutnya, Anda dapat mengklik ikon (Run with Parameters)
dan pilih grup sumber daya penjadwalan yang ingin Anda gunakan.Saat Anda mengquery data menggunakan node EMR Spark SQL, query dapat mengembalikan maksimal 10.000 catatan, dan ukuran total data yang dikembalikan tidak boleh melebihi 10 MB.
Klik ikon
untuk menyimpan pernyataan SQL.(Opsional) Lakukan pengujian asap.
Jika Anda ingin melakukan pengujian asap di lingkungan pengembangan, Anda dapat melakukannya saat Anda mengirimkan node atau setelah node dikirimkan. Untuk informasi lebih lanjut, lihat Lakukan Pengujian Asap.
Jika Anda ingin memodifikasi antrian tempat pekerjaan dikirimkan, lihat Konfigurasikan Parameter Lanjutan.
Langkah 3: Konfigurasikan properti penjadwalan
Jika Anda ingin sistem secara berkala menjalankan tugas pada node, Anda dapat mengklik Properties di panel navigasi kanan pada tab konfigurasi node untuk mengonfigurasi properti penjadwalan tugas berdasarkan kebutuhan bisnis Anda. Untuk informasi lebih lanjut, lihat Ikhtisar.
Anda harus mengonfigurasi parameter Rerun dan Parent Nodes di tab Properti sebelum Anda mengirimkan tugas.
Langkah 4: Terapkan tugas
Setelah tugas pada node dikonfigurasi, Anda harus mengirimkan dan menerapkan tugas. Setelah Anda mengirimkan dan menerapkan tugas, sistem akan menjalankan tugas secara berkala berdasarkan konfigurasi penjadwalan.
Klik ikon
di bilah alat atas untuk menyimpan tugas.Klik ikon
di bilah alat atas untuk mengirimkan tugas.Di kotak dialog Submit, konfigurasikan parameter Change description. Kemudian, tentukan apakah akan meninjau kode tugas setelah Anda mengirimkan tugas berdasarkan kebutuhan bisnis Anda.
CatatanAnda harus mengonfigurasi parameter Rerun dan Parent Nodes di tab Properti sebelum Anda mengirimkan tugas.
Anda dapat menggunakan fitur tinjauan kode untuk memastikan kualitas kode tugas dan mencegah kesalahan eksekusi tugas yang disebabkan oleh kode tugas yang tidak valid. Jika Anda mengaktifkan fitur tinjauan kode, kode tugas yang dikirimkan hanya dapat diterapkan setelah kode tugas lulus tinjauan kode. Untuk informasi lebih lanjut, lihat Tinjauan Kode.
Jika Anda menggunakan ruang kerja dalam mode standar, Anda harus menerapkan tugas di lingkungan produksi setelah Anda mengirimkan tugas. Untuk menerapkan tugas pada node, klik Deploy di sudut kanan atas tab konfigurasi node. Untuk informasi lebih lanjut, lihat Terapkan Node.
Kirim Pekerjaan EMR Spark
Langkah 1: Buat Node EMR Spark
Pergi ke halaman DataStudio.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Di panel navigasi kiri, pilih . Di halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down dan klik Go to Data Development.
Buat Node EMR Spark.
Temukan alur kerja yang diinginkan, klik kanan nama alur kerja, dan pilih .
CatatanSebagai alternatif, Anda dapat mengarahkan pointer ke ikon Create dan pilih .
Di kotak dialog Create Node, konfigurasikan parameter Name, Engine Instance, Node Type, dan Path. Klik Confirm. Tab konfigurasi Node EMR Spark muncul.
CatatanNama node dapat berisi huruf, angka, garis bawah (_), dan titik (.).
Langkah 2: Kembangkan Tugas Spark
Anda dapat menggunakan salah satu metode berikut berdasarkan kebutuhan bisnis Anda untuk mengembangkan tugas Spark di tab konfigurasi Node EMR Spark:
(Direkomendasikan) Unggah sumber daya dari mesin lokal Anda ke DataStudio lalu referensikan sumber daya tersebut. Untuk informasi lebih lanjut, lihat bagian Metode 1: Unggah dan Referensikan Sumber Daya JAR EMR dalam topik ini.
Gunakan metode OSS REF untuk merujuk sumber daya OSS. Untuk informasi lebih lanjut, lihat bagian Metode 2: Referensikan Sumber Daya OSS dalam topik ini.
Metode 1: Unggah dan Referensikan Sumber Daya JAR EMR
DataWorks memungkinkan Anda mengunggah sumber daya dari mesin lokal Anda ke DataStudio sebelum Anda mereferensikannya. Anda harus mendapatkan dan menyimpan paket JAR yang dihasilkan setelah kode tugas Spark dikompilasi di EMR. Metode penyimpanan paket JAR bervariasi tergantung pada ukuran paket JAR.
Anda dapat mengunggah paket JAR ke konsol DataWorks sebagai sumber daya JAR EMR dan mengirimkannya. Anda juga dapat menyimpan paket JAR di HDFS EMR. Untuk kluster Spark yang dibuat di halaman EMR on ACK atau kluster EMR Serverless Spark, Anda tidak dapat mengunggah sumber daya ke HDFS.
Paket JAR kurang dari 200 MB
Buat sumber daya JAR EMR.
Anda dapat mengunggah paket JAR dari mesin lokal Anda ke konsol DataWorks sebagai sumber daya JAR EMR. Dengan cara ini, Anda dapat mengelola paket JAR di konsol DataWorks secara visual. Setelah Anda membuat sumber daya JAR EMR, Anda harus mengirimkannya. Untuk informasi lebih lanjut, lihat Buat dan Gunakan Sumber Daya EMR.
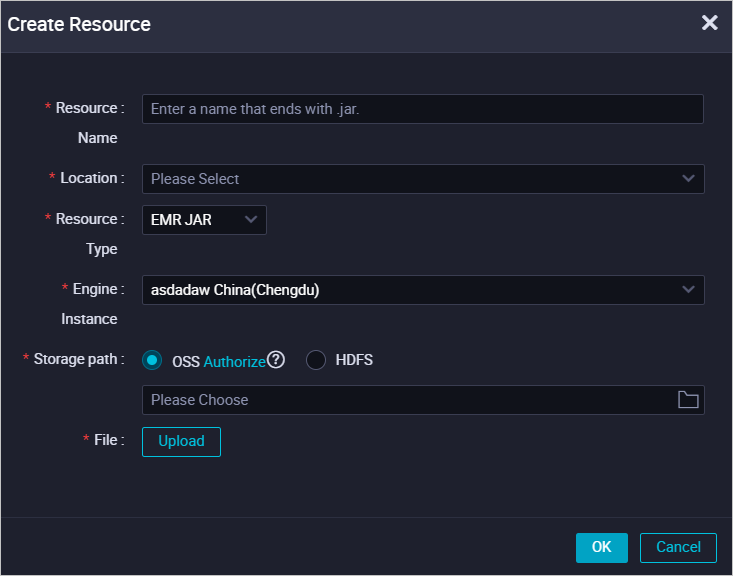 Catatan
CatatanPertama kali Anda membuat sumber daya JAR EMR, Anda harus melakukan otorisasi sesuai petunjuk jika Anda ingin paket JAR disimpan di OSS setelah diunggah.
Referensikan sumber daya JAR EMR.
Klik dua kali nama node EMR Spark yang telah dibuat untuk pergi ke tab konfigurasi node.
Temukan sumber daya JAR EMR yang diinginkan di bawah Resource di folder EMR, klik kanan nama sumber daya, dan pilih Insert Resource Path.
Kode referensi sumber daya ditambahkan secara otomatis ke tab konfigurasi node EMR Spark. Contoh kode:
##@resource_reference{"spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar"} spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jarJika penambahan otomatis kode sebelumnya berhasil, sumber daya direferensikan. spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar adalah nama paket JAR yang Anda unggah.
Tulis ulang kode node EMR Spark dan tambahkan perintah spark-submit. Contoh kode berikut hanya untuk referensi.
CatatanAnda tidak dapat menambahkan komentar saat menulis kode untuk node EMR Spark. Jika Anda menambahkan komentar, kesalahan akan dilaporkan saat Anda menjalankan node EMR Spark. Anda dapat merujuk ke contoh kode berikut untuk menulis ulang kode node EMR Spark.
##@resource_reference{"spark-examples_2.11-2.4.0.jar"} spark-submit --class org.apache.spark.examples.SparkPi --master yarn spark-examples_2.11-2.4.0.jar 100Komponen:
org.apache.spark.examples.SparkPi: kelas utama tugas dalam paket JAR yang dikompilasi.
spark-examples_2.11-2.4.0.jar: nama paket JAR yang Anda unggah.
Anda dapat mempertahankan pengaturan parameter lainnya. Anda juga dapat menjalankan perintah berikut untuk melihat dokumentasi bantuan untuk menggunakan perintah
spark-submitdan memodifikasi perintahspark-submitberdasarkan kebutuhan bisnis Anda.CatatanJika Anda ingin menggunakan parameter yang disederhanakan dengan menjalankan perintah
spark-submit, seperti--executor-memory 2G, dalam node EMR Spark, Anda perlu menambahkan parameter ke kode node EMR Spark.Anda hanya dapat menggunakan node Spark di YARN untuk mengirimkan pekerjaan jika node Anda berada dalam mode kluster.
Jika Anda mengirimkan node menggunakan
spark-submit, kami sarankan Anda mengatur deploy-mode ke kluster daripada klien.
spark-submit --help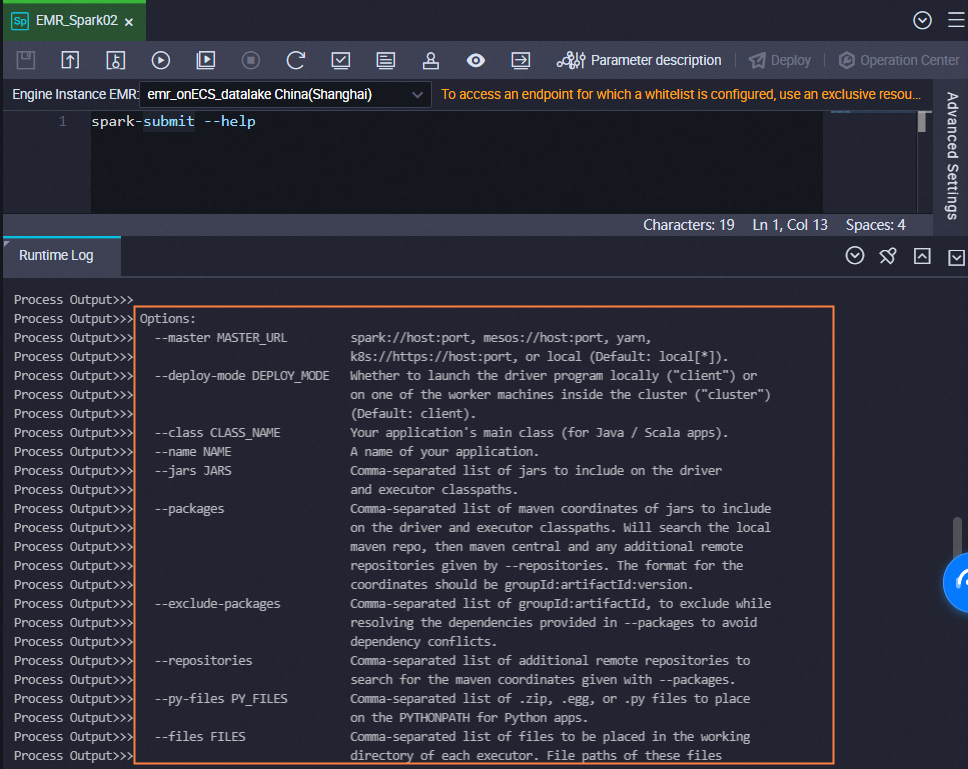
Paket JAR lebih besar dari atau sama dengan 200 MB
Simpan paket JAR di HDFS EMR.
Anda tidak dapat mengunggah paket JAR dari mesin lokal ke konsol DataWorks sebagai sumber daya DataWorks. Sebagai solusi, simpan paket JAR di HDFS EMR dan catat jalur penyimpanannya. Dengan demikian, Anda dapat mereferensikan paket JAR pada jalur tersebut saat menggunakan DataWorks untuk menjadwalkan tugas Spark.
Referensikan paket JAR.
Anda dapat mereferensikan paket JAR dengan menentukan jalur penyimpanan paket JAR dalam kode node EMR Spark.
Klik dua kali nama node EMR Spark yang telah dibuat untuk pergi ke tab konfigurasi node.
Tulis perintah spark-submit. Contoh:
spark-submit --master yarn --deploy-mode cluster --name SparkPi --driver-memory 4G --driver-cores 1 --num-executors 5 --executor-memory 4G --executor-cores 1 --class org.apache.spark.examples.JavaSparkPi hdfs:///tmp/jars/spark-examples_2.11-2.4.8.jar 100Deskripsi parameter:
hdfs:///tmp/jars/spark-examples_2.11-2.4.8.jar: jalur penyimpanan paket JAR di HDFS.
org.apache.spark.examples.JavaSparkPi: kelas utama tugas dalam paket JAR yang dikompilasi.
Pengaturan parameter lainnya dikonfigurasikan di kluster EMR yang digunakan. Anda dapat memodifikasi parameter berdasarkan kebutuhan bisnis Anda. Anda juga dapat menjalankan perintah berikut untuk melihat dokumentasi bantuan untuk menggunakan perintah spark-submit dan memodifikasi perintah spark-submit berdasarkan kebutuhan bisnis Anda.
PentingJika Anda ingin menggunakan parameter yang disederhanakan dengan menjalankan perintah spark-submit, seperti
--executor-memory 2G, dalam node EMR Spark, Anda perlu menambahkan parameter ke kode node EMR Spark.Anda hanya dapat menggunakan node Spark di YARN untuk mengirimkan pekerjaan jika node Anda berada dalam mode kluster.
Jika Anda mengirimkan node menggunakan spark-submit, kami sarankan Anda mengatur deploy-mode ke kluster daripada klien.
spark-submit --help
Metode 2: Referensikan Sumber Daya OSS
Node saat ini dapat mereferensikan sumber daya OSS menggunakan metode OSS REF. Saat menjalankan tugas pada node, DataWorks secara otomatis memuat sumber daya OSS yang ditentukan dalam kode node. Metode ini biasanya digunakan dalam skenario di mana dependensi JAR diperlukan untuk tugas EMR atau ketika tugas EMR perlu bergantung pada skrip.
Kembangkan paket JAR.
Persiapkan dependensi kode.
Anda dapat mengakses kluster EMR dan melihat dependensi kode yang diperlukan di jalur
/usr/lib/emr/spark-current/jars/dari node master. Informasi berikut menggunakan Spark 3.4.2 sebagai contoh. Anda harus membuka proyek IntelliJ IDEA yang ada, dan menambahkan dependensi POM dan plugin referensi.Tambahkan Dependensi POM
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.4.2</version> </dependency> <!-- Apache Spark SQL --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.4.2</version> </dependency> </dependencies>Referensikan Plugin
<build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <configuration> <recompileMode>incremental</recompileMode> </configuration> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> </plugins> </build>Tulis kode. Contoh kode:
package com.aliyun.emr.example.spark import org.apache.spark.sql.SparkSession object SparkMaxComputeDemo { def main(args: Array[String]): Unit = { // Buat sesi Spark. val spark = SparkSession.builder() .appName("HelloDataWorks") .getOrCreate() // Tampilkan versi Spark. println(s"Versi Spark: ${spark.version}") } }Kemas kode menjadi file JAR.
Setelah Anda menulis dan menyimpan kode sebelumnya, kemas kode menjadi file JAR. Dalam contoh ini, file bernama
SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jardihasilkan.
Unggah file JAR.
Masuk ke Konsol OSS. Di bilah navigasi atas, pilih wilayah yang diinginkan. Kemudian, di panel navigasi kiri, klik Buckets.
Di halaman Bucket, temukan bucket yang diinginkan dan klik nama bucket untuk pergi ke halaman Objects.
Dalam contoh ini, bucket
onaliyun-bucket-2digunakan.Di halaman Objek, klik Create Directory untuk membuat direktori yang digunakan untuk menyimpan file JAR.
Di panel Buat Direktori, atur Directory Name ke
emr/jarsdan klik OK.Unggah file JAR ke direktori yang dibuat.
Pergi ke direktori yang dibuat. Klik Upload Object. Di bagian Files to Upload, klik Select Files dan tambahkan file
SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jar. Lalu, klik Upload Object.
Referensikan file JAR.
Tulis kode yang digunakan untuk mereferensikan file JAR.
Di tab konfigurasi node EMR Spark, tulis kode yang digunakan untuk mereferensikan file JAR.
spark-submit --class com.aliyun.emr.example.spark.SparkMaxComputeDemo --master yarn ossref://onaliyun-bucket-2/emr/jars/SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jarDeskripsi parameter:
Parameter
Deskripsi
classNama lengkap kelas utama yang akan dieksekusi.
masterMode operasi aplikasi Spark.
ossrefjalur fileFormat:
ossref://{endpoint}/{bucket}/{object}endpoint: endpoint OSS. Jika parameter endpoint dibiarkan kosong, hanya sumber daya dalam bucket OSS yang berada di wilayah yang sama dengan kluster EMR saat ini yang dapat direferensikan.
bucket: wadah yang digunakan untuk menyimpan objek di OSS. Setiap bucket memiliki nama unik. Anda dapat masuk ke Konsol OSS untuk melihat semua buckets dalam akun log masuk saat ini.
object: nama file atau jalur yang disimpan di bucket.
Jalankan tugas pada node EMR Spark.
Setelah Anda menulis kode, klik ikon
 dan pilih grup sumber daya serverless yang telah dibuat untuk menjalankan tugas pada node EMR Spark. Setelah tugas selesai dijalankan, catat
dan pilih grup sumber daya serverless yang telah dibuat untuk menjalankan tugas pada node EMR Spark. Setelah tugas selesai dijalankan, catat ID aplikasiyang ditampilkan di konsol, sepertiapplication_1730367929285_xxxx.Lihat hasilnya.
Buat node EMR Shell dan jalankan perintah
yarn logs -applicationId application_1730367929285_xxxxpada node EMR Shell untuk melihat hasil eksekusi.
(Opsional) Konfigurasikan Parameter Lanjutan
Anda dapat mengonfigurasi parameter khusus Spark di tab Pengaturan Lanjutan tab konfigurasi node saat ini. Untuk informasi lebih lanjut tentang cara mengonfigurasi parameter, lihat Konfigurasi Spark. Tabel berikut menjelaskan parameter lanjutan yang dapat dikonfigurasi untuk berbagai jenis kluster EMR.
Kluster DataLake atau kluster kustom: dibuat di halaman EMR pada ECS
Parameter lanjutan | Deskripsi |
Antrian | Antrian penjadwalan tempat tugas dikomit. Nilai default: default. Jika Anda telah mengonfigurasi YARN queue tingkat ruang kerja saat mendaftarkan kluster EMR ke ruang kerja DataWorks, konfigurasi berikut berlaku:
Untuk informasi tentang EMR YARN, lihat Penjadwal YARN. Untuk informasi tentang konfigurasi antrian saat mendaftarkan kluster EMR, lihat Konfigurasikan antrian YARN global. |
Prioritas | Prioritas. Nilai default: 1. |
FLOW_SKIP_SQL_ANALYZE | Cara pernyataan SQL dieksekusi. Nilai valid:
Catatan Parameter ini hanya tersedia untuk pengujian di lingkungan pengembangan ruang kerja DataWorks. |
Lainnya |
|
Kluster Hadoop: dibuat di halaman EMR pada ECS
Parameter lanjutan | Deskripsi |
Antrian | Antrian penjadwalan tempat tugas dikomit. Nilai default: default. Jika Anda telah mengonfigurasi YARN queue tingkat ruang kerja saat mendaftarkan kluster EMR ke ruang kerja DataWorks, konfigurasi berikut berlaku:
Untuk informasi tentang EMR YARN, lihat Penjadwal YARN. Untuk informasi tentang konfigurasi antrian saat mendaftarkan kluster EMR, lihat Konfigurasikan antrian YARN global. |
Prioritas | Prioritas. Nilai default: 1. |
FLOW_SKIP_SQL_ANALYZE | Cara pernyataan SQL dieksekusi. Nilai valid:
Catatan Parameter ini hanya tersedia untuk pengujian di lingkungan pengembangan ruang kerja DataWorks. |
USE_GATEWAY | Menentukan apakah akan menggunakan kluster gateway untuk mengirim tugas pada node saat ini. Nilai valid:
Catatan Jika kluster EMR yang dimiliki oleh node tidak terhubung dengan kluster gateway tetapi parameter USE_GATEWAY disetel ke |
Lainnya |
|
Kluster Spark: dibuat di halaman EMR pada ACK
Parameter lanjutan | Deskripsi |
Antrian | Parameter ini tidak didukung. |
Prioritas | Parameter ini tidak didukung. |
FLOW_SKIP_SQL_ANALYZE | Cara pernyataan SQL dieksekusi. Nilai valid:
Catatan Parameter ini hanya tersedia untuk pengujian di lingkungan pengembangan ruang kerja DataWorks. |
Lainnya |
|
Kluster Spark Serverless EMR
Untuk informasi lebih lanjut tentang pengaturan parameter, lihat bagian Langkah 3: Kirim tugas Spark dari topik "Gunakan CLI spark-submit untuk mengirim tugas Spark".
Parameter lanjutan | Deskripsi |
Antrian | Antrian penjadwalan tempat tugas dikomit. Nilai default: dev_queue. |
Prioritas | Prioritas. Nilai default: 1. |
FLOW_SKIP_SQL_ANALYZE | Cara pernyataan SQL dieksekusi. Nilai valid:
Catatan Parameter ini hanya tersedia untuk pengujian di lingkungan pengembangan ruang kerja DataWorks. |
SERVERLESS_RELEASE_VERSION | Versi mesin Spark. Secara default, nilai yang ditentukan oleh parameter Default Engine Version di halaman Daftar Kluster EMR digunakan. Untuk pergi ke halaman Daftar Kluster EMR, Anda dapat melakukan operasi berikut: Pergi ke halaman SettingCenter. Di panel navigasi di sebelah kiri, klik Cluster Management. Di halaman Manajemen Kluster, klik Daftar Kluster dan pilih E-MapReduce di kotak dialog Pilih Tipe Kluster. Anda dapat mengonfigurasi parameter ini untuk menentukan versi mesin yang berbeda untuk jenis tugas yang berbeda. |
SERVERLESS_QUEUE_NAME | Antrian sumber daya. Secara default, nilai yang ditentukan oleh parameter Default Resource Queue di halaman Daftar Kluster EMR digunakan. Anda dapat menambahkan antrian untuk memenuhi persyaratan isolasi dan manajemen sumber daya. Untuk informasi lebih lanjut, lihat Kelola antrian sumber daya. |
Lainnya |
|
Jalankan Pernyataan SQL
Klik ikon
di bilah alat atas. Di kotak dialog Parameters, pilih grup sumber daya penjadwalan yang dibuat dan klik Run.CatatanJika Anda ingin mengakses sumber komputasi melalui Internet atau jaringan VPC, gunakan grup sumber daya penjadwalan yang terhubung ke sumber komputasi tersebut. Untuk informasi lebih lanjut, lihat Solusi Konektivitas Jaringan.
Jika Anda ingin mengubah grup sumber daya dalam operasi selanjutnya, Anda dapat mengklik ikon
(Run with Parameters) untuk mengubah grup sumber daya di kotak dialog Parameter.Jika Anda menggunakan node EMR Spark untuk mengquery data, maksimal 10.000 catatan data dapat dikembalikan, dan ukuran total data yang dikembalikan tidak boleh melebihi 10 MB.
Klik ikon
di bilah alat atas untuk menyimpan pernyataan SQL.(Opsional) Lakukan pengujian asap.
Anda dapat melakukan pengujian asap pada node di lingkungan pengembangan saat atau setelah Anda melakukan commit pada node. Untuk informasi selengkapnya, lihat Melakukan Pengujian Asap.
Langkah 3: Konfigurasikan properti penjadwalan
Jika Anda ingin sistem secara berkala menjalankan tugas pada node, Anda dapat mengklik Properties di panel navigasi kanan pada tab konfigurasi node untuk mengonfigurasi properti penjadwalan tugas berdasarkan kebutuhan bisnis Anda. Untuk informasi lebih lanjut, lihat Ikhtisar.
Anda harus mengonfigurasi parameter Rerun dan Parent Nodes di tab Properti sebelum Anda mengirimkan tugas.
Langkah 4: Terapkan tugas
Setelah tugas pada node dikonfigurasi, Anda harus mengirimkan dan menerapkan tugas. Setelah Anda mengirimkan dan menerapkan tugas, sistem akan menjalankan tugas secara berkala berdasarkan konfigurasi penjadwalan.
Klik ikon
di bilah alat atas untuk menyimpan tugas.Klik ikon
di bilah alat atas untuk mengirimkan tugas.Di kotak dialog Submit, konfigurasikan parameter Change description. Kemudian, tentukan apakah akan meninjau kode tugas setelah Anda mengirimkan tugas berdasarkan kebutuhan bisnis Anda.
CatatanAnda harus mengonfigurasi parameter Rerun dan Parent Nodes di tab Properti sebelum Anda mengirimkan tugas.
Anda dapat menggunakan fitur tinjauan kode untuk memastikan kualitas kode tugas dan mencegah kesalahan eksekusi tugas yang disebabkan oleh kode tugas yang tidak valid. Jika Anda mengaktifkan fitur tinjauan kode, kode tugas yang dikirimkan hanya dapat diterapkan setelah kode tugas lulus tinjauan kode. Untuk informasi lebih lanjut, lihat Tinjauan Kode.
Jika Anda menggunakan ruang kerja dalam mode standar, Anda harus menerapkan tugas di lingkungan produksi setelah Anda mengirimkan tugas. Untuk menerapkan tugas pada node, klik Deploy di sudut kanan atas tab konfigurasi node. Untuk informasi lebih lanjut, lihat Terapkan Node.
Apa Selanjutnya
Setelah tugas diterapkan, itu secara otomatis ditambahkan ke Operation Center. Anda dapat melihat status tugas yang sedang berjalan di Operation Center atau memicu tugas untuk dijalankan secara manual. Untuk informasi lebih lanjut, lihat Operation Center.
FAQ
Setelah saya menyiapkan lingkungan DataWorks dan mengirimkan pekerjaan EMR Hive, kesalahan
java.net.ConnectException: Koneksi habis waktu (Connection timed out)terjadi.Periksa apakah kluster EMR dan lingkungan DataWorks dikonfigurasi dengan benar sesuai dokumentasi, dan pastikan bahwa Grup Sumber Daya DataWorks dan EMR terkait dengan VPC dan vSwitch yang sama.
Periksa aturan grup keamanan kluster EMR untuk memastikan bahwa port
10000dari instance ECS terbuka. Untuk informasi lebih lanjut, lihat Kelola Grup Keamanan. Saat Anda mengirimkan pekerjaan komponen lain di DataWorks, Anda perlu membuka port ECS yang sesuai. Untuk informasi lebih lanjut, lihat Port Umum Komponen Open Source.
Referensi
Jika tugas Anda perlu dijadwalkan secara berkala, Anda perlu mendefinisikan properti penjadwalan terkait tugas, termasuk siklus penjadwalan, dependensi penjadwalan, dan parameter penjadwalan. Untuk informasi lebih lanjut, lihat Konfigurasi Penjadwalan Node.
Jika tugas Anda memerlukan pemrosesan string yang kompleks atau operasi matematika, Anda dapat membuat fungsi yang ditentukan pengguna di DataWorks. Untuk informasi lebih lanjut, lihat Buat Fungsi EMR.