Adopsi yang semakin meningkat dari model bahasa besar (LLMs) telah menimbulkan kekhawatiran perusahaan tentang keamanan data selama tugas inferensi. Topik ini menjelaskan cara menggunakan instans komputasi rahasia heterogen Alibaba Cloud dan solusi Confidential AI (CAI) untuk membangun lingkungan inferensi LLM yang aman.
Latar Belakang
Instans komputasi rahasia heterogen gn8v-tee Alibaba Cloud mengintegrasikan GPU ke dalam lingkungan eksekusi tepercaya (TEE) berbasis CPU Trust Domain Extension (TDX). Hal ini melindungi data selama transmisi antara CPU dan GPU serta selama komputasi di dalam GPU. Anda dapat menggunakan Alibaba Cloud Key Management Service (KMS) sebagai backend penyimpanan kunci dan menerapkan layanan remote attestation Trustee dalam kluster Container Service for Kubernetes (ACK). Setelah konfigurasi sederhana, layanan inferensi Anda dapat dengan mulus menerapkan perlindungan inferensi aman melalui komputasi rahasia tanpa memerlukan modifikasi. Solusi ini membantu Anda membangun lingkungan inferensi LLM yang aman di Alibaba Cloud untuk mendukung bisnis Anda.
Arsitektur solusi
Gambar berikut menunjukkan arsitektur keseluruhan dari solusi ini.
Prosedur
Langkah 1: Persiapkan data model terenkripsi
Langkah ini mencakup pengunduhan, enkripsi, dan pengunggahan model. Proses ini memakan waktu karena ukuran file model yang besar.
Untuk mencoba solusi ini, Anda dapat menggunakan file model terenkripsi yang telah kami siapkan. Jika Anda menggunakan file model terenkripsi kami, Anda dapat melewati langkah ini dan lanjut ke Langkah 2: Siapkan Layanan Remote Attestation Trustee. Klik tautan berikut untuk mendapatkan informasi file model terenkripsi.
1. Unduh model
Sebelum menerapkan model ke cloud, Anda harus mengenkripsinya dan mengunggahnya ke penyimpanan cloud. Kunci dekripsi untuk model dikelola oleh KMS, yang dikontrol oleh layanan remote attestation. Anda harus melakukan enkripsi model dalam lingkungan lokal atau tepercaya. Contoh berikut menunjukkan cara menerapkan model besar Qwen2.5-3B-Instruct.
Jika Anda sudah memiliki model, Anda dapat melewati bagian ini dan melanjutkan ke 2. Enkripsi Model.
Contoh ini menggunakan alat modelscope untuk mengunduh model Qwen2.5-3B-Instruct. Ini memerlukan Python 3.9 atau lebih baru. Anda dapat menjalankan perintah berikut di terminal untuk mengunduh model.
pip3 install modelscope importlib-metadata
modelscope download --model Qwen/Qwen2.5-3B-InstructSetelah perintah berhasil dijalankan, model akan diunduh ke direktori ~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct/.
2. Enkripsi model
Dua metode enkripsi berikut didukung. Topik ini menggunakan Gocryptfs sebagai contoh.
Gocryptfs: Pola enkripsi berbasis AES-256-GCM yang sesuai dengan standar Gocryptfs open source.
Sam: Format enkripsi model AI tepercaya dari Alibaba Cloud. Ini melindungi kerahasiaan model dan mencegah konten lisensi dirusak atau digunakan secara ilegal.
Gunakan Gocryptfs untuk mengenkripsi
Instal Gocryptfs, alat yang digunakan untuk mengenkripsi model. Saat ini, hanya Gocryptfs v2.4.0 dengan parameter default yang didukung. Anda dapat memilih salah satu dari metode berikut untuk menginstalnya:
Metode 1: (Direkomendasikan) Instal dari sumber yum
Jika Anda menggunakan Alinux 3 atau AnolisOS 23, Anda dapat menginstal gocryptfs langsung dari sumber yum.
Alinux 3
sudo yum install gocryptfs -yAnolisOS 23
sudo yum install anolis-epao-release -y sudo yum install gocryptfs -yMetode 2: Unduh binari pra-kompilasi secara langsung
# Unduh paket Gocryptfs pra-kompilasi wget https://github.jobcher.com/gh/https://github.com/rfjakob/gocryptfs/releases/download/v2.4.0/gocryptfs_v2.4.0_linux-static_amd64.tar.gz # Ekstrak dan instal tar xf gocryptfs_v2.4.0_linux-static_amd64.tar.gz sudo install -m 0755 ./gocryptfs /usr/local/binBuat file kunci Gocryptfs untuk digunakan sebagai kunci enkripsi model. Pada langkah selanjutnya, Anda perlu mengunggah kunci ini ke layanan remote attestation (Trustee) untuk manajemen.
Dalam solusi ini,
0Bn4Q1wwY9fN3Pdigunakan sebagai kunci untuk mengenkripsi model. Konten kunci disimpan dalam filecachefs-password. Anda juga dapat menggunakan kunci kustom. Dalam praktiknya, kami sarankan Anda menggunakan kunci kuat yang dihasilkan secara acak.cat << EOF > ~/cachefs-password 0Bn4Q1wwY9fN3P EOFGunakan kunci yang dibuat untuk mengenkripsi model.
Konfigurasikan jalur untuk model teks biasa.
CatatanKonfigurasikan jalur tempat model teks biasa yang baru saja Anda unduh berada. Jika Anda memiliki model lain, ganti jalur dengan jalur aktual model target Anda.
PLAINTEXT_MODEL_PATH=~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct/Gunakan Gocryptfs untuk mengenkripsi struktur direktori model.
Setelah dienkripsi, model disimpan sebagai teks sandi di direktori
./cipher.mkdir -p ~/mount cd ~/mount mkdir -p cipher plain # Instal dependensi runtime Gocryptfs sudo yum install -y fuse # Inisialisasi gocryptfs cat ~/cachefs-password | gocryptfs -init cipher # Mount ke plain cat ~/cachefs-password | gocryptfs cipher plain # Pindahkan model AI ke ~/mount/plain cp -r ${PLAINTEXT_MODEL_PATH}/. ~/mount/plain
Gunakan Sam untuk mengenkripsi
Klik untuk mengunduh paket modul enkripsi Sam RAI_SAM_SDK_2.1.0-20240731.tgz. Kemudian, Anda dapat menjalankan perintah berikut untuk mengekstrak paket tersebut.
# Ekstrak modul enkripsi Sam tar xvf RAI_SAM_SDK_2.1.0-20240731.tgzGunakan modul enkripsi Sam untuk mengenkripsi model.
# Buka direktori enkripsi modul enkripsi Sam cd RAI_SAM_SDK_2.1.0-20240731/tools # Enkripsi model ./do_content_packager.sh <model_directory> <plaintext_key> <key_id>Di mana:
<model_directory>: Direktori tempat model yang akan dienkripsi berada. Anda dapat menggunakan jalur relatif atau absolut, seperti
~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct/.<plaintext_key>: Kunci enkripsi kustom. Panjang valid adalah 4 hingga 128 byte. Sebagai contoh adalah
0Bn4Q1wwY9fN3P. Kunci teks biasa ini adalah kunci dekripsi model yang perlu Anda unggah ke layanan remote attestation (Trustee).<key_id>: Pengenal kunci kustom. Panjang valid adalah 8 hingga 48 byte. Sebagai contoh adalah
LD_Demo_0001.
Setelah dienkripsi, model disimpan sebagai teks sandi di direktori
<key_id>di jalur saat ini.
3. Unggah model
Persiapkan Bucket OSS di wilayah yang sama tempat Anda akan menerapkan instans heterogen. Unggah model terenkripsi ke Alibaba Cloud OSS. Ini memungkinkan Anda menarik dan menerapkan model dari instans heterogen nanti.
Ambil OSS sebagai contoh. Anda dapat membuat bucket dan direktori bernama qwen-encrypted, seperti oss://examplebucket/qwen-encrypted/. Untuk informasi lebih lanjut, lihat Memulai Cepat untuk Konsol. Karena ukuran file model besar, kami sarankan menggunakan ossbrowser untuk mengunggah model terenkripsi ke direktori ini.
Langkah 2: Siapkan layanan remote attestation Trustee
Layanan remote attestation adalah layanan verifikasi yang dikelola pengguna yang bertanggung jawab untuk memverifikasi lingkungan runtime model dan layanan inferensi. Kunci dekripsi model disuntikkan untuk mendekripsi dan memasang model hanya setelah layanan memastikan bahwa lingkungan penerapan model heterogen dapat dipercaya dan memenuhi kondisi yang diharapkan.
Anda dapat menggunakan Alibaba Cloud ACK Serverless untuk menerapkan layanan remote attestation yang memverifikasi lingkungan penerapan dan inferensi model. Anda juga dapat menggunakan Alibaba Cloud KMS untuk memberikan keamanan tingkat profesional untuk kunci dekripsi model. Prosedurnya adalah sebagai berikut:
Kluster ACK tidak perlu berada di wilayah yang sama dengan wilayah tujuan untuk layanan penerapan heterogen.
Instans Alibaba Cloud KMS harus berada di wilayah yang sama dengan kluster ACK tempat layanan remote attestation Trustee Alibaba Cloud akan diterapkan.
Sebelum Anda membuat instans KMS dan kluster ACK, buat virtual private cloud (VPC) dan dua vSwitch. Untuk informasi lebih lanjut, lihat Buat dan Kelola VPC.
1. Buat instans Alibaba Cloud KMS sebagai backend penyimpanan kunci
Buka Konsol Layanan Manajemen Kunci. Di panel navigasi di sebelah kiri, pilih . Pada tab Software Key Management, buat dan aktifkan instans. Saat Anda mengaktifkan instans, pilih VPC yang sama dengan kluster ACK. Untuk informasi lebih lanjut, lihat Pembelian dan Aktivasi Instans KMS.
Tunggu sekitar 10 menit untuk instans mulai.
Setelah instans mulai, di panel navigasi di sebelah kiri, pilih . Pada halaman Manajemen Kunci, buat kunci master pelanggan untuk instans. Untuk informasi lebih lanjut, lihat Langkah 1: Buat Kunci yang Dilindungi Perangkat Lunak.
Di panel navigasi di sebelah kiri, pilih . Pada halaman Titik Akses, buat titik akses aplikasi untuk instans. Atur Cakupan ke instans KMS yang Anda buat. Untuk informasi lebih lanjut tentang konfigurasi lainnya, lihat Metode 1: Pembuatan Cepat.
Setelah titik akses aplikasi dibuat, browser secara otomatis mengunduh file ClientKey***.zip. Setelah Anda mengekstrak file zip, itu berisi:
Application Identity Credential Content (ClientKeyContent): Nama file adalah
clientKey_****.jsonsecara default.Credential Security Token (ClientKeyPassword): Nama file adalah
clientKey_****_Password.txtsecara default.
Pada halaman , klik nama instans KMS. Di area Basic Information, klik Download di sebelah Instance CA Certificate untuk mengekspor file sertifikat kunci publik
PrivateKmsCA_***.pemuntuk instans KMS.
2. Buat kluster layanan ACK dan instal komponen csi-provisioner
Buka halaman Buat Kluster untuk membuat kluster ACK Serverless. Konfigurasi parameter kunci dijelaskan di bawah ini. Untuk informasi lebih lanjut tentang konfigurasi lainnya, lihat Buat Kluster.
Konfigurasi Kluster: Konfigurasikan parameter berikut, lalu klik Berikutnya: Konfigurasi Komponen.
Konfigurasi Utama
Deskripsi
VPC
Pilih Use Existing dan pilih Configure SNAT For VPC. Jika tidak, Anda tidak dapat menarik gambar Trustee.
VSwitch
Pastikan bahwa setidaknya dua switch virtual dibuat di VPC yang ada. Jika tidak, Anda tidak dapat mengekspos ALB publik.
Konfigurasi Komponen: Konfigurasikan parameter berikut, lalu klik Next: Confirm Order.
Konfigurasi Utama
Deskripsi
Service Discovery
Pilih CoreDNS.
Ingress
Pilih ALB Ingress. Untuk sumber instance gateway cloud-native ALB, pilih Create dan pilih dua switch virtual.
Konfirmasi Pesanan: Konfirmasi informasi konfigurasi dan ketentuan layanan, lalu klik Create Cluster.
Setelah kluster dibuat, instal komponen csi-provisioner (dikelola). Untuk informasi lebih lanjut, lihat Kelola Komponen.
3. Terapkan layanan remote attestation Trustee di kluster ACK
Pertama, hubungkan ke kluster melalui Internet atau jaringan internal. Untuk informasi lebih lanjut, lihat Hubungkan ke Kluster.
Unggah kredensial identitas aplikasi (yang diunduh (
clientKey_****.json), token keamanan kredensial (clientKey_****_Password.txt), dan sertifikat CA (PrivateKmsCA_***.pem) untuk instans KMS ke lingkungan yang terhubung ke kluster ACK Serverless. Kemudian, jalankan perintah berikut untuk menerapkan layanan remote attestation Trustee dan menggunakan Alibaba Cloud KMS sebagai backend penyimpanan kunci.# Instal plugin helm plugin install https://github.com/AliyunContainerService/helm-acr helm repo add trustee acr://trustee-chart.cn-hangzhou.cr.aliyuncs.com/trustee/trustee helm repo update export DEPLOY_RELEASE_NAME=trustee export DEPLOY_NAMESPACE=default export TRUSTEE_CHART_VERSION=1.0.0 # Setel informasi wilayah kluster ACK, misalnya, cn-hangzhou export REGION_ID=cn-hangzhou # Informasi tentang instans KMS yang diekspor # Ganti dengan ID instans KMS Anda export KMS_INSTANCE_ID=kst-hzz66a0*******e16pckc # Ganti dengan jalur ke file kredensial identitas aplikasi instans KMS Anda export KMS_CLIENT_KEY_FILE=/path/to/clientKey_KAAP.***.json # Ganti dengan jalur ke file token keamanan kredensial instans KMS Anda export KMS_PASSWORD_FILE=/path/to/clientKey_KAAP.***_Password.txt # Ganti dengan jalur ke file sertifikat CA instans KMS Anda export KMS_CERT_FILE=/path/to/PrivateKmsCA_kst-***.pem helm install ${DEPLOY_RELEASE_NAME} trustee/trustee \ --version ${TRUSTEE_CHART_VERSION} \ --set regionId=${REGION_ID} \ --set kbs.aliyunKms.enabled=true \ --set kbs.aliyunKms.kmsIntanceId=${KMS_INSTANCE_ID} \ --set-file kbs.aliyunKms.clientKey=${KMS_CLIENT_KEY_FILE} \ --set-file kbs.aliyunKms.password=${KMS_PASSWORD_FILE} \ --set-file kbs.aliyunKms.certPem=${KMS_CERT_FILE} \ --namespace ${DEPLOY_NAMESPACE}CatatanPerintah pertama untuk menginstal plugin (
helm plugin install...) mungkin memerlukan waktu lama. Jika instalasi gagal, Anda dapat menjalankan perintahhelm plugin uninstall cm-pushuntuk menghapus plugin, lalu jalankan perintah instalasi lagi.Berikut adalah contoh hasil yang dikembalikan:
NAME: trustee LAST DEPLOYED: Tue Feb 25 18:55:33 2025 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: NoneJalankan perintah berikut di lingkungan yang terhubung ke kluster ACK Serverless untuk mendapatkan endpoint Trustee.
export TRUSTEE_URL=http://$(kubectl get AlbConfig alb -o jsonpath='{.status.loadBalancer.dnsname}')/${DEPLOY_RELEASE_NAME} echo ${TRUSTEE_URL}Contoh hasil yang dikembalikan adalah
http://alb-ppams74szbwg2f****.cn-shanghai.alb.aliyuncsslb.com/trustee.Jalankan perintah berikut di lingkungan yang terhubung ke kluster ACK Serverless untuk menguji konektivitas layanan Trustee.
cat << EOF | curl -k -X POST ${TRUSTEE_URL}/kbs/v0/auth -H 'Content-Type: application/json' -d @- { "version":"0.1.0", "tee": "tdx", "extra-params": "foo" } EOFJika layanan Trustee berjalan normal, keluaran yang diharapkan adalah sebagai berikut:
{"nonce":"PIDUjUxQdBMIXz***********IEysXFfUKgSwk=","extra-params":""}
4. Buat rahasia untuk menyimpan kunci dekripsi model
Kunci dekripsi model yang dikelola oleh Trustee disimpan di KMS. Kunci hanya dapat diakses setelah layanan remote attestation memverifikasi lingkungan target.
Buka Konsol Layanan Manajemen Kunci. Di panel navigasi di sebelah kiri, pilih . Pada tab Generic Secrets, klik Create Generic Secret. Perhatikan konfigurasi utama berikut:
Nama Rahasia: Masukkan nama kustom untuk rahasia. Nama ini digunakan sebagai indeks untuk kunci. Sebagai contoh,
model-decryption-key.Setel Nilai Rahasia: Masukkan kunci yang digunakan untuk mengenkripsi model. Sebagai contoh,
0Bn4Q1wwY9fN3P. Gunakan kunci aktual Anda.Enkripsi CMK: Pilih kunci master yang Anda buat pada langkah sebelumnya.
Langkah 3: Buat instans komputasi rahasia heterogen
Langkah-langkah untuk membuat instans dengan fitur komputasi rahasia heterogen di konsol serupa dengan langkah-langkah untuk membuat instans biasa, tetapi Anda harus memperhatikan beberapa opsi tertentu. Langkah-langkah berikut menjelaskan cara menggunakan gambar Marketplace Alibaba Cloud yang berisi lingkungan komputasi rahasia heterogen dan lingkungan CAI untuk membuat instans komputasi rahasia heterogen. Untuk informasi lebih lanjut tentang lingkungan komputasi rahasia heterogen, lihat Membangun Lingkungan Komputasi Rahasia Heterogen.
Buka halaman Halaman Pembelian Instans.
Pilih tab Custom Launch.
Pilih metode penagihan, wilayah, tipe instans, gambar, dan konfigurasi lainnya.
Tabel berikut menjelaskan item konfigurasi.
Item Konfigurasi
Deskripsi
Keluarga Instans
Anda harus memilih salah satu dari dua tipe instans berikut dari keluarga instans gn8v-tee:
ecs.gn8v-tee.4xlarge
ecs.gn8v-tee.6xlarge
Gambar
Klik tab Marketplace Images, masukkan
Confidential AIuntuk mencari, dan pilih gambarAlibaba Cloud Linux 3.2104 LTS 64-bit Single-card Confidential AI.CatatanUntuk informasi lebih lanjut tentang gambar ini, lihat Gambar Alibaba Cloud Linux 3.2104 LTS 64-bit Single-card Confidential AI. Anda dapat membuat instans komputasi rahasia heterogen di halaman produk gambar.
Disk Sistem
Kami sarankan kapasitas disk sistem minimal 1 TiB. Ukuran spesifik harus diperkirakan secara wajar berdasarkan ukuran file model yang perlu Anda jalankan. Secara umum, kami sarankan kapasitas lebih besar dari dua kali ukuran model. Atur kapasitas sesuai kebutuhan.
Sebelum Anda membuat instans, tinjau konfigurasi keseluruhan di sisi kanan halaman. Konfigurasikan opsi seperti durasi penggunaan untuk memastikan bahwa mereka memenuhi kebutuhan Anda.
Baca dan centang kotak untuk menyetujui Ketentuan Layanan ECS dan perjanjian layanan lainnya. Jika Anda sudah menyetujui, Anda tidak perlu melakukan langkah ini lagi. Ikuti petunjuk di halaman. Lalu, klik Create Order.
Tunggu instans dibuat. Anda dapat pergi ke halaman daftar instans di konsol untuk melihat status instans. Saat status instans berubah menjadi Running, instans telah dibuat.
Langkah 4: Konfigurasikan izin akses untuk instans heterogen ke OSS dan Trustee
1. Konfigurasikan izin akses ke OSS
Selama penerapan, instans perlu mengakses bucket OSS tempat teks sandi model disimpan dan mengakses Trustee untuk mendapatkan kunci dekripsi model. Oleh karena itu, Anda harus mengonfigurasi izin akses untuk instans ke layanan OSS dan Trustee.
Masuk ke Konsol OSS.
Klik Buckets, lalu klik nama bucket target.
Di panel navigasi di sebelah kiri, pilih .
Pada tab Bucket Policy, klik Authorize. Di panel yang muncul, berikan izin
Bucketke alamat IP publik instans komputasi rahasia heterogen.Klik OK.
2. Konfigurasikan izin akses ke Trustee
Buka Konsol Application Load Balancer (ALB), pilih Access Control di sebelah kiri. Lalu klik Create ACL, dan tambahkan alamat IP atau blok CIDR yang perlu mengakses Trustee sebagai entri IP. Untuk informasi lebih lanjut, lihat Kontrol Akses.
Anda harus menambahkan alamat atau rentang alamat berikut:
Alamat IP publik VPC yang terikat selama penerapan layanan heterogen.
Alamat IP keluar klien inferensi.
Jalankan perintah berikut untuk mendapatkan ID instans ALB yang digunakan oleh instans Trustee di kluster.
kubectl get ing --namespace ${DEPLOY_NAMESPACE} kbs-ingress -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | cut -d'.' -f1 | sed 's/[^a-zA-Z0-9-]//g'Keluaran yang diharapkan adalah sebagai berikut:
alb-llcdzbw0qivhk0****Di panel navigasi di sebelah kiri Konsol ALB, pilih . Di wilayah tempat kluster berada, cari instans ALB yang Anda dapatkan pada langkah sebelumnya dan klik ID instans untuk pergi ke halaman detail instans. Di bagian bawah halaman, di area Instance Information, klik Disable Configuration Read-only Mode.
Beralih ke tab Listener, klik Aktifkan di kolom Kontrol Akses instans pendengar target, dan konfigurasikan daftar putih dengan grup kebijakan kontrol akses yang Anda buat pada langkah sebelumnya.
Langkah 5: Terapkan layanan inferensi model bahasa besar vLLM di instans komputasi rahasia heterogen
Anda dapat menerapkan layanan inferensi model bahasa besar vLLM di instans komputasi rahasia heterogen menggunakan docker atau docker compose. Prosedurnya adalah sebagai berikut:
1. Persiapkan file konfigurasi
Hubungkan secara jarak jauh ke instans heterogen. Untuk informasi lebih lanjut, lihat Masuk ke Instans Linux Menggunakan Workbench.
Jalankan perintah berikut untuk membuka file konfigurasi
~/cai.env.vi ~/cai.envTekan tombol
iuntuk masuk ke mode sisipan dan tempelkan informasi konfigurasi yang telah disiapkan ke dalam file.# Konfigurasi untuk dekripsi model TRUSTEE_URL="http://alb-xxxxxxxxx.cn-beijing.alb.aliyuncsslb.com/xxxx/" # URL layanan Trustee MODEL_KEY_ID="kbs:///default/aliyun/model-decryption-key" # ID sumber daya kunci dekripsi model yang dikonfigurasi di Trustee. Sebagai contoh, ID untuk rahasia bernama model-decryption-key adalah kbs:///default/aliyun/model-decryption-key # Konfigurasi untuk distribusi model terenkripsi MODEL_OSS_BUCKET_PATH="<bucket-name>:<model-path>" # Jalur teks sandi model yang disimpan di Alibaba Cloud OSS. Sebagai contoh, conf-ai:/qwen3-32b-gocryptfs/ MODEL_OSS_ENDPOINT="https://oss-cn-beijing-internal.aliyuncs.com" # URL OSS tempat teks sandi model disimpan # MODEL_OSS_ACCESS_KEY_ID="" # ID AccessKey yang digunakan untuk mengakses bucket OSS. # MODEL_OSS_SECRET_ACCESS_KEY="" # Rahasia AccessKey yang digunakan untuk mengakses bucket OSS. # MODEL_OSS_SESSION_TOKEN="" # Token sesi yang digunakan untuk mengakses bucket OSS. Ini hanya diperlukan jika Anda menggunakan kredensial STS untuk mengakses OSS. MODEL_ENCRYPTION_METHOD="gocryptfs" # Metode enkripsi yang digunakan. Nilai valid: "gocryptfs" dan "sam". Nilai default: "gocryptfs". MODEL_MOUNT_POINT=/tmp/model # Titik pemasangan untuk model teks biasa yang didekripsi. Layanan inferensi model dapat memuat model dari jalur ini. # Konfigurasi untuk enkripsi komunikasi layanan model besar MODEL_SERVICE_PORT=8080 # Port TCP yang digunakan oleh layanan. Komunikasi pada port ini dienkripsi secara transparan. # Konfigurasi untuk percepatan distribusi model P2P. Anda dapat mengabaikan ini secara default. TRUSTEE_POLICY="default" # MODEL_SHARING_PEER="172.30.24.146 172.30.24.144"Masukkan
:wqdan tekanEnteruntuk menyimpan file dan keluar dari editor.
2. Terapkan layanan inferensi
Terapkan layanan inferensi menggunakan docker
Gunakan file konfigurasi untuk memulai layanan CAI
Anda harus menggunakan file yang Anda konfigurasikan pada langkah sebelumnya untuk memulai layanan CAI, yang digunakan untuk mendekripsi model terenkripsi. Ini memasang data model teks biasa yang didekripsi ke jalur
/tmp/model, yang ditentukan olehMODEL_MOUNT_POINTdi lingkungan host. Program layanan inferensi Anda, seperti vLLM, dapat memuat model dari jalur ini.Jalankan perintah berikut untuk memulai layanan CAI.
cd ~ docker compose -f /opt/alibaba/cai-docker/docker-compose.yml --env-file ./cai.env up -d --waitKeluaran sampel berikut menunjukkan bahwa layanan CAI telah berhasil dimulai.
[+] Running 5/5 ✔ Container cai-docker-oss-1 Healthy 44.7s ✔ Container cai-docker-attestation-agent-1 Healthy 44.7s ✔ Container cai-docker-tng-1 Healthy 44.7s ✔ Container cai-docker-confidential-data-hub-1 Healthy 44.7s ✔ Container cai-docker-cachefs-1 HealthyLihat File Model yang Didekripsi
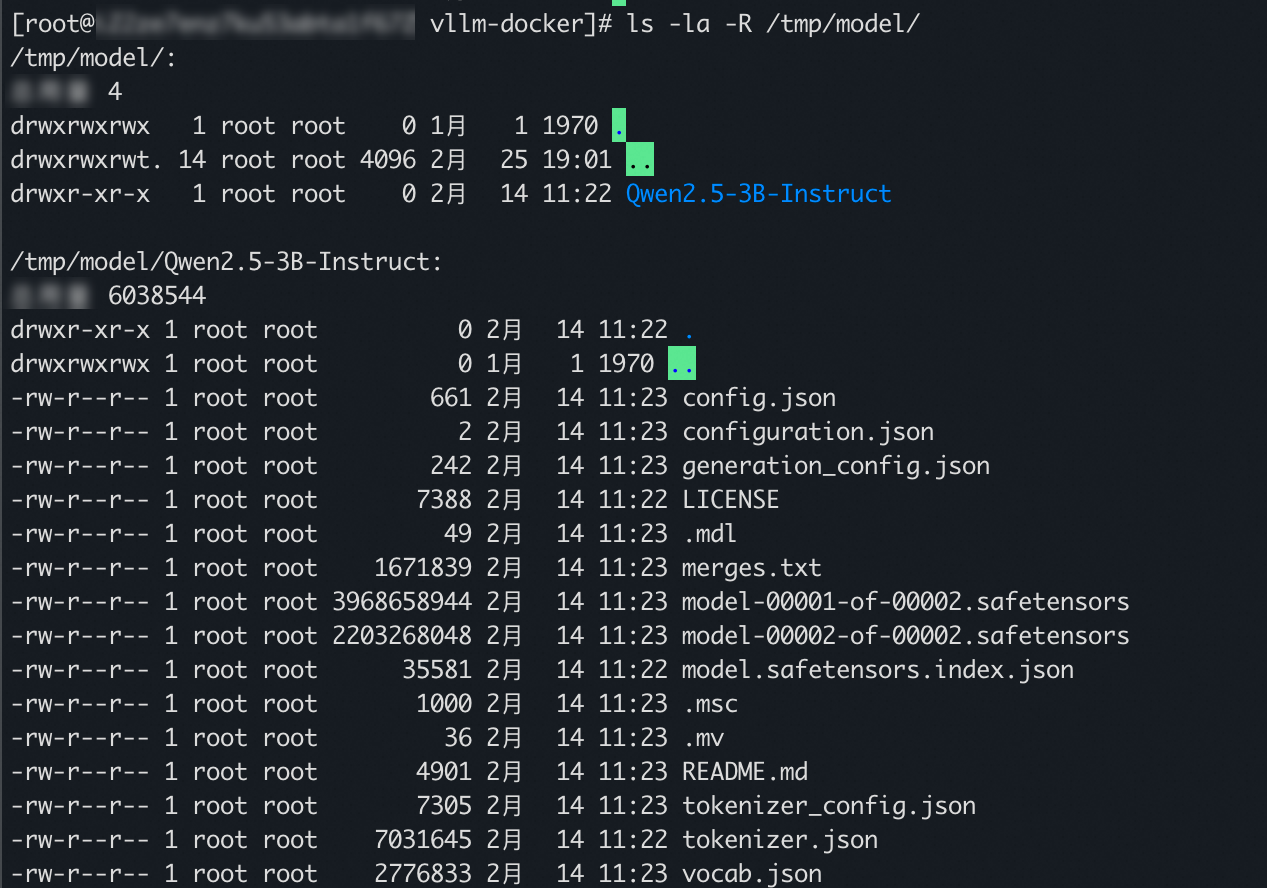
Untuk melihat file model yang didekripsi, Anda dapat menjalankan perintah berikut.
ls -la -R /tmp/modelKeluaran sampel berikut menunjukkan bahwa file model berhasil didekripsi.
Jalankan perintah berikut untuk memulai layanan inferensi vLLM.
docker run --rm \ --net host \ -v /tmp/model:/tmp/model \ --gpus all \ egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.8.5-pytorch2.6-cu124-20250429 \ python3 -m vllm.entrypoints.openai.api_server --model=/tmp/model --trust-remote-code --port 8080 --served-model-name Qwen3-32BKeluaran sampel berikut menunjukkan bahwa layanan inferensi telah berhasil dimulai.
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s] Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:01<00:01, 1.07s/it] Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.21it/s] Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.16it/s] INFO 03-04 07:49:06 model_runner.py:732] Memuat bobot model memakan waktu 5.7915 GB INFO 03-04 07:49:08 gpu_executor.py:102] # Blok GPU: 139032, # Blok CPU: 7281 INFO 03-04 07:49:08 model_runner.py:1024] Menangkap model untuk grafik CUDA. Ini dapat menyebabkan konsekuensi tak terduga jika model tidak statis. Untuk menjalankan model dalam mode eager, atur 'enforce_eager=True' atau gunakan '--enforce-eager' di CLI. INFO 03-04 07:49:08 model_runner.py:1028] Grafik CUDA dapat mengambil memori tambahan 1~3 GiB per GPU. Jika Anda kehabisan memori, pertimbangkan untuk mengurangi `gpu_memory_utilization` atau menegakkan mode eager. Anda juga dapat mengurangi `max_num_seqs` sesuai kebutuhan untuk mengurangi penggunaan memori. INFO 03-04 07:49:18 model_runner.py:1225] Penangkapan grafik selesai dalam 9 detik. WARNING 03-04 07:49:18 serving_embedding.py:171] embedding_mode adalah False. API Embedding tidak akan berfungsi. INFO 03-04 07:49:18 launcher.py:14] Rute yang tersedia adalah: INFO 03-04 07:49:18 launcher.py:22] Rute: /openapi.json, Metode: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Rute: /docs, Metode: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Rute: /docs/oauth2-redirect, Metode: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Rute: /redoc, Metode: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Rute: /health, Metode: GET INFO 03-04 07:49:18 launcher.py:22] Rute: /tokenize, Metode: POST INFO 03-04 07:49:18 launcher.py:22] Rute: /detokenize, Metode: POST INFO 03-04 07:49:18 launcher.py:22] Rute: /v1/models, Metode: GET INFO 03-04 07:49:18 launcher.py:22] Rute: /version, Metode: GET INFO 03-04 07:49:18 launcher.py:22] Rute: /v1/chat/completions, Metode: POST INFO 03-04 07:49:18 launcher.py:22] Rute: /v1/completions, Metode: POST INFO 03-04 07:49:18 launcher.py:22] Rute: /v1/embeddings, Metode: POST INFO: Proses server dimulai [1] INFO: Menunggu startup aplikasi. INFO: Startup aplikasi selesai. INFO: Uvicorn berjalan di http://0.0.0.0:8080 (Tekan CTRL+C untuk keluar)
Terapkan layanan inferensi menggunakan docker compose
Persiapkan file docker-compose.yml.
Jalankan perintah berikut untuk membuka file docker-compose.yml.
vi ~/docker-compose.ymlTekan tombol
iuntuk masuk ke mode sisipan dan tempelkan konten berikut ke dalam file docker-compose.yml.include the following: - path: /opt/alibaba/cai-docker/docker-compose.yml env_file: ./cai.env services: inference: image: egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/llm-inference:vllm0.5.4-deepgpu-llm24.7-pytorch2.4.0-cuda12.4-ubuntu22.04 volumes: - /tmp/model:/tmp/model:shared deploy: resources: reservations: devices: - driver: nvidia count: all capabilities: [gpu] network_mode: host init: true command: "python3 -m vllm.entrypoints.openai.api_server --model=/tmp/model/ --trust-remote-code --port 8080" depends_on: cachefs: condition: service_healthy restart: trueTekan
:wqlalu tekanEnteruntuk menyimpan file dan keluar dari editor.PentingJika Anda berencana memodifikasi file docker-compose.yml untuk menerapkan beban kerja lain yang dijelaskan dalam topik ini, Anda harus melakukan penyesuaian berikut:
Gunakan pernyataan
includeuntuk mengimpor file docker-compose.yml CAI yang sudah terinstal sebelumnya di gambar, dan gunakanenv_fileuntuk menentukan jalur file konfigurasi CAI.Anda harus menambahkan kondisi
depends_onuntuk kontainer layanan vLLM agar memastikan bahwa itu mulai setelah kontainer cachefs.Direktori model yang didekripsi dipasang ke jalur yang ditentukan oleh
MODEL_MOUNT_POINTdi lingkungan host. Oleh karena itu, Anda harus menambahkan entri volume yang sesuai untuk kontainer layanan vLLM untuk berbagi direktori model dengan kontainer layanan inferensi.
Jalankan Layanan Inferensi vLLM
Jalankan perintah berikut untuk menjalankan layanan inferensi vLLM.
docker compose up -dKeluaran sampel berikut menunjukkan bahwa layanan inferensi telah berhasil dimulai.
[+] Running 6/6 ✔ Container root-attestation-agent-1 Healthy 3.6s ✔ Container root-oss-1 Healthy 10.2s ✔ Container root-tng-1 Healthy 44.2s ✔ Container root-confidential-data-hub-1 Healthy 34.2s ✔ Container root-cachefs-1 Healthy 54.7s ✔ Container root-inference-1 Started
Langkah 6: Akses layanan inferensi di instans komputasi rahasia heterogen
Untuk mengakses layanan inferensi di instans komputasi rahasia, Anda harus menyiapkan lingkungan klien dan menginstal klien Trusted Network Gateway. Langkah-langkah berikut menjelaskan cara menggunakan instans ECS biasa sebagai klien untuk mengakses layanan inferensi vLLM yang diterapkan di instans heterogen.
1. Konfigurasikan izin akses untuk lingkungan klien ke instans komputasi rahasia heterogen dan Trustee
Dalam topik ini, lingkungan klien mengakses layanan inferensi yang diterapkan di instans komputasi rahasia heterogen melalui alamat IP publiknya. Oleh karena itu, Anda harus menambahkan aturan ke grup keamanan instans komputasi rahasia heterogen untuk mengizinkan akses dari lingkungan klien. Selain itu, selama proses pembentukan saluran aman dengan server, Trustee diperlukan untuk remote attestation instans komputasi rahasia heterogen. Oleh karena itu, Anda juga harus menambahkan alamat IP publik lingkungan klien ke daftar kontrol akses Trustee. Prosedurnya adalah sebagai berikut:
Tambahkan aturan ke grup keamanan instans komputasi rahasia heterogen untuk mengizinkan akses dari klien. Untuk informasi lebih lanjut, lihat Kelola Aturan Grup Keamanan.
Tambahkan alamat IP publik lingkungan klien ke kontrol akses Trustee.
Anda sudah membuat grup kebijakan kontrol akses dan menambahkannya ke daftar putih di Langkah 4: Konfigurasikan Izin Akses untuk Instans Heterogen ke OSS dan Trustee. Oleh karena itu, Anda tidak perlu membuat yang baru. Anda dapat menambahkan alamat IP publik klien ke grup kebijakan kontrol akses yang ada.
2. Terapkan klien Trusted Network Gateway pada instans klien
Trusted Network Gateway (TNG) adalah komponen jaringan yang dirancang untuk skenario komputasi rahasia. Ini dapat bertindak sebagai proses daemon yang bertanggung jawab untuk membentuk saluran komunikasi aman dan secara transparan mengenkripsi serta mendekripsi lalu lintas jaringan ke dan dari instans rahasia untuk mencapai keamanan data ujung ke ujung. Ini juga memungkinkan Anda mengontrol proses enkripsi dan dekripsi lalu lintas secara fleksibel berdasarkan kebutuhan tanpa memodifikasi aplikasi yang ada.
Terapkan Klien Trusted Network Gateway.
Terapkan menggunakan docker
Instal Docker pada instans klien. Untuk informasi lebih lanjut, lihat Instal dan Gunakan Docker dan Docker Compose.
Jalankan perintah berikut untuk menerapkan klien Trusted Network Gateway menggunakan Docker.
PentingAnda harus memodifikasi nilai bidang
as_addrmenjadi${trsutee_url}/as/berdasarkan layanan Trustee yang sebelumnya Anda terapkan.docker run --rm \ --network=host \ confidential-ai-registry.cn-shanghai.cr.aliyuncs.com/product/tng:2.2.1 \ tng launch --config-content ' { "add_ingress": [ { "http_proxy": { "proxy_listen": { "host": "127.0.0.1", "port": 41000 } }, "verify": { "as_addr": "http://alb-xxxxxxxxxxxxxxxxxx.cn-shanghai.alb.aliyuncsslb.com/cai-test/as/", "policy_ids": [ "default" ] } } ] } '
Terapkan menggunakan file binari
Kunjungi TNG · GitHub untuk mendapatkan alamat unduhan paket instalasi binari yang sesuai dengan arsitektur instans klien.
Jalankan perintah berikut untuk mengunduh file binari klien Trusted Network Gateway. Contoh berikut menggunakan
tng-v2.2.1.x86_64-unknown-linux-gnu.tar.gz. Ganti dengan nama file aktual.wget https://github.com/inclavare-containers/TNG/releases/download/v2.2.1/tng-v2.2.1.x86_64-unknown-linux-gnu.tar.gzJalankan perintah berikut untuk mengekstrak file binari terkompresi yang diunduh dan memberikan izin eksekusi ke file tersebut.
tar -zxvf tng-v2.2.1.x86_64-unknown-linux-gnu.tar.gz chmod +x tngJalankan perintah berikut untuk menjalankan klien Trusted Network Gateway.
PentingAnda harus memodifikasi nilai bidang
as_addrmenjadi${trsutee_url}/as/berdasarkan layanan Trustee yang sebelumnya Anda terapkan../tng launch --config-content ' { "add_ingress": [ { "http_proxy": { "proxy_listen": { "host": "127.0.0.1", "port": 41000 } }, "verify": { "as_addr": "http://alb-xxxxxxxxxxxxxxxxxx.cn-shanghai.alb.aliyuncsslb.com/cai-test/as/", "policy_ids": [ "default" ] } } ] } '
3. Konfigurasikan layanan proxy HTTP untuk proses pada instans klien
Setelah penerapan berhasil, klien Trusted Network Gateway berjalan di latar depan dan membuat layanan proxy HTTP berbasis protokol HTTP CONNECT di 127.0.0.1:41000. Saat Anda menghubungkan aplikasi ke proxy ini, lalu lintas dienkripsi oleh klien Trusted Network Gateway dan dikirim ke layanan vLLM melalui saluran tepercaya.
Anda dapat mengonfigurasi layanan proxy HTTP untuk proses pada instans klien dengan dua cara berikut.
Konfigurasikan proxy berdasarkan jenis protokol
export http_proxy=http://127.0.0.1:41000
export https_proxy=http://127.0.0.1:41000
export ftp_proxy=http://127.0.0.1:41000
export rsync_proxy=http://127.0.0.1:41000Konfigurasikan proxy untuk semua protokol
export all_proxy=http://127.0.0.1:410004. Akses layanan inferensi dari instans klien
Anda dapat mengakses layanan inferensi di instans komputasi rahasia heterogen dengan menjalankan perintah curl di lingkungan klien.
Buka jendela terminal baru untuk instans klien.
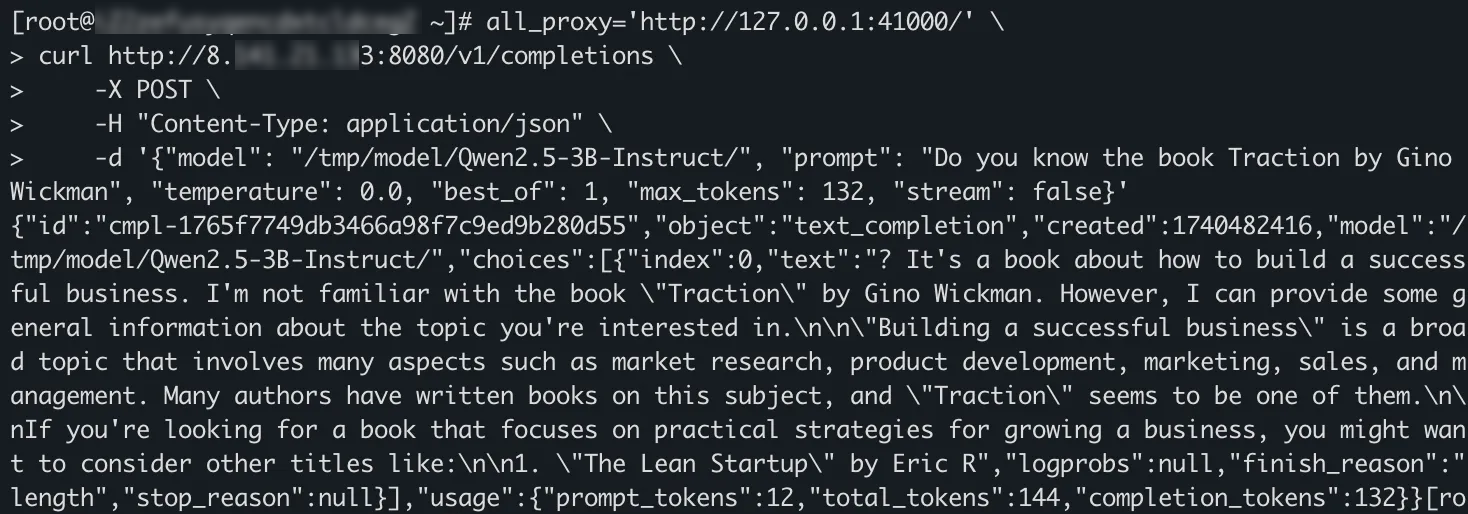
Jalankan perintah berikut untuk mengakses layanan inferensi.
CatatanAnda harus mengganti
<heterogeneous_confidential_computing_instance_public_IP>dalam perintah berikut dengan alamat IP publik instans komputasi rahasia heterogen yang Anda buat di Langkah 3: Buat Instans Komputasi Rahasia Heterogen.Perintah berikut menetapkan variabel lingkungan
all_proxy='http://127.0.0.1:41000/'sebelum perintahcurldijalankan. Ini memastikan bahwa permintaan yang dikirim oleh perintahcurldienkripsi oleh klien Trusted Network Gateway dan dikirim melalui saluran aman.
env all_proxy='http://127.0.0.1:41000/' \ curl http://<heterogeneous_confidential_computing_instance_public_IP>:8080/v1/completions \ -X POST \ -H "Content-Type: application/json" \ -d '{"model": "Qwen3-32B", "prompt": "Apakah Anda tahu buku Traction oleh Gino Wickman", "temperature": 0.0, "best_of": 1, "max_tokens": 132, "stream": false}'Keluaran sampel berikut menunjukkan bahwa permintaan yang dikirim oleh klien menggunakan perintah curl dienkripsi oleh klien Trusted Network Gateway dan kemudian dikirim melalui saluran aman. Layanan model bahasa besar yang diterapkan di instans heterogen berhasil diakses.
FAQ
Kontainer cai-docker-oss gagal memulai saat startup layanan CAI.
Gejala: Kontainer cai-docker-oss gagal memulai saat layanan CAI dimulai.

Penyebab: Masalah ini biasanya terjadi karena instans heterogen tidak dapat mengakses bucket OSS tempat teks sandi model disimpan.
Solusi: Periksa apakah kebijakan kontrol akses OSS dikonfigurasi dengan benar.
Saat Anda memulai layanan CAI, kontainer cai-docker-confidential-data-hub gagal memulai.
Gejala: Kontainer cai-docker-confidential-data-hub gagal memulai saat layanan CAI dimulai.

Penyebab: Kesalahan ini menunjukkan masalah dalam mendapatkan kunci dekripsi model. Masalah ini biasanya terjadi karena instans heterogen tidak dapat mengakses instans Trustee, atau kunci yang dikonfigurasikan tidak ada.
Solusi: Anda dapat melakukan langkah-langkah berikut untuk menyelesaikan masalah ini.
Periksa apakah ID kunci yang Anda konfigurasikan di
cai.envbenar, lalu terapkan ulang layanan.Periksa apakah URL instans Trustee di
cai.envdikonfigurasi dengan benar.Periksa apakah kebijakan kontrol akses instans Trustee dikonfigurasi dengan benar.
Kontainer cai-docker-tng gagal memulai saat layanan CAI dimulai.
Kontainer cai-docker-cachefs gagal memulai saat startup layanan CAI.
Gejala: Kontainer cai-docker-cachefs gagal memulai saat layanan CAI dimulai.

Penyebab: Masalah ini biasanya terjadi karena dekripsi model gagal.
Solusi: Anda dapat melakukan langkah-langkah berikut untuk menyelesaikan masalah ini.
Periksa apakah kredensial kata sandi yang benar telah diunggah ke backend KMS Trustee.
Periksa apakah nilai bidang
MODEL_ENCRYPTION_METHODyang dikonfigurasikan dicai.envsesuai dengan metode enkripsi yang digunakan untuk mengenkripsi model.
Bagaimana cara menggunakan alat untuk mengumpulkan informasi kesalahan setelah layanan CAI gagal memulai?
Referensi
Untuk informasi lebih lanjut tentang cara membangun lingkungan komputasi rahasia heterogen, lihat Membangun Lingkungan Komputasi Rahasia Heterogen.