Sebarkan kluster Hadoop terdistribusi atau pseudo-terdistribusi pada instans ECS Linux untuk penyimpanan dan pemrosesan data besar.
Latar Belakang
Apache Hadoop adalah framework untuk pemrosesan terdistribusi set data skala besar di seluruh kluster komputer. Framework ini dapat diskalakan dari satu server hingga ribuan mesin, masing-masing menyediakan komputasi dan penyimpanan lokal. Hadoop mendeteksi dan menangani kegagalan pada lapisan aplikasi, sehingga memberikan ketersediaan tinggi tanpa bergantung pada redundansi perangkat keras.
Komponen inti Hadoop adalah Hadoop Distributed File System (HDFS) dan MapReduce:
-
HDFS: Sistem file terdistribusi untuk menyimpan dan membaca data aplikasi.
-
MapReduce: Framework komputasi terdistribusi yang membagi tugas menjadi fase Map dan Reduce serta menggunakan penjadwal tugas (JobTracker) untuk mengeksekusinya di seluruh node kluster.
|
Fitur |
Mode pseudo-terdistribusi |
Mode terdistribusi penuh |
|
Jumlah node |
Node tunggal. Semua layanan berjalan pada satu mesin. |
Beberapa node. Layanan didistribusikan di beberapa mesin. |
|
Penggunaan sumber daya |
Menggunakan sumber daya satu mesin. |
Memanfaatkan sumber daya komputasi dan penyimpanan di beberapa mesin. |
|
Toleransi kesalahan |
Rendah. Titik kegagalan tunggal menyebabkan seluruh kluster tidak tersedia. |
Tinggi. Mendukung replikasi data dan konfigurasi ketersediaan tinggi. |
|
Skenario |
|
|
Penerapan cepat
Klik Run Now untuk membuka Terraform Explorer, tempat Anda dapat melihat dan menjalankan kode Terraform guna secara otomatis membangun lingkungan Hadoop pada instans ECS.
Prasyarat
Instans ECS Anda harus memenuhi persyaratan berikut:
|
Lingkungan |
Persyaratan |
|
|
Instance |
Pseudo-terdistribusi |
1 instans |
|
Terdistribusi |
3 instans atau lebih Catatan
Tambahkan instans ke dalam deployment set yang menggunakan strategi High Availability untuk meningkatkan ketersediaan dan menyederhanakan manajemen kluster. |
|
|
Sistem operasi |
Linux |
|
|
Alamat IP publik |
Instans diberi alamat IP publik atau dikaitkan dengan Elastic IP Address (EIP). |
|
|
Security group instans |
Izinkan lalu lintas inbound pada port 22, 443, 8088 (Hadoop YARN web UI), dan 9870 (Hadoop NameNode web UI). Catatan
Untuk penerapan terdistribusi, izinkan juga trafik pada port 9868 (Hadoop Secondary NameNode web UI). Lihat Manage security group rules. |
|
|
Java Development Kit (JDK) Topik ini menggunakan Hadoop 3.2.4 dan Java 8. Untuk versi lainnya, lihat Hadoop Java Versions. |
Versi Hadoop |
Versi Java |
|
Hadoop 3.3 |
Java 8 dan Java 11 |
|
|
Hadoop 3.0.x~3.2.x |
Java 8 |
|
|
Hadoop 2.7.x~2.10.x |
Java 7 dan Java 8 |
|
Prosedur
Terdistribusi
Rencanakan node sebelum menerapkan Hadoop. Contoh ini menggunakan tiga instans: hadoop001 adalah node master, sedangkan hadoop002 dan hadoop003 adalah node worker.
|
Komponen fungsional |
hadoop001 |
hadoop002 |
hadoop003 |
|
HDFS |
|
DataNode |
|
|
YARN |
NodeManager |
|
NodeManager |
Langkah 1: Instal JDK
Instal JDK pada semua node.
-
Hubungkan ke instans ECS sebagai pengguna biasa.
Lihat Menghubungkan ke instans Linux menggunakan Workbench.
PentingKomunitas Hadoop tidak merekomendasikan menjalankan Hadoop sebagai pengguna root karena masalah keamanan dan izin. Gunakan pengguna non-root seperti
ecs-user. -
Unduh paket instalasi JDK 1.8.
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz -
Ekstrak paket instalasi JDK 1.8.
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz -
Pindahkan dan ubah nama folder instalasi JDK.
Contoh ini mengubah nama folder instalasi JDK menjadi
java8. Anda dapat menggunakan nama lain.sudo mv java-se-8u41-ri/ /usr/java8 -
Konfigurasikan variabel lingkungan Java.
Jika Anda mengubah nama folder instalasi JDK, ganti
java8dalam perintah berikut dengan nama yang sebenarnya.sudo sh -c "echo 'export JAVA_HOME=/usr/java8' >> /etc/profile" sudo sh -c 'echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile' source /etc/profile -
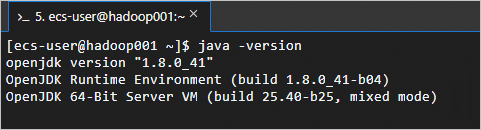
Verifikasi bahwa JDK telah terinstal.
java -versionOutput berikut menunjukkan instalasi berhasil.
Langkah 2: Konfigurasikan logon SSH tanpa password
Lakukan operasi ini pada semua instans.
Siapkan logon SSH tanpa password agar node dapat saling terhubung tanpa autentikasi password, sehingga menyederhanakan manajemen kluster.
-
Konfigurasikan hostname dan resolusi host.
sudo vim /etc/hostsTambahkan informasi
<Primary private IP address> <Hostname>untuk semua instans ke file/etc/hosts. Contohnya:<Primary private IP address> hadoop001 <Primary private IP address> hadoop002 <Primary private IP address> hadoop003 -
Buat kunci publik dan kunci privat.
ssh-keygen -t rsa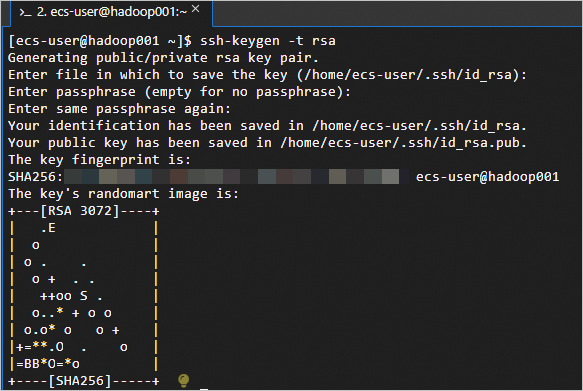
-
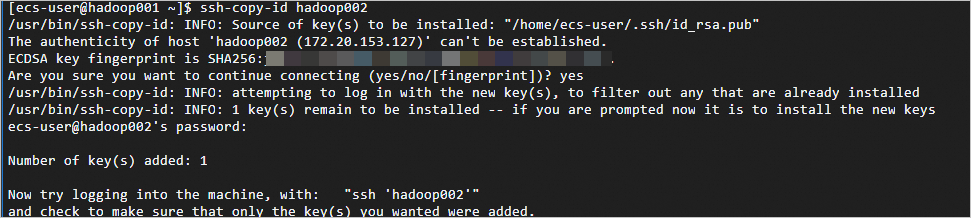
Jalankan
ssh-copy-id <Hostname>, dan ganti hostname dengan nama yang sesuai. Contohnya:Pada
hadoop001, jalankanssh-copy-id hadoop001,ssh-copy-id hadoop002, danssh-copy-id hadoop003. Setelah setiap perintah, masukkan yes dan password untuk instans yang sesuai.ssh-copy-id hadoop001 ssh-copy-id hadoop002 ssh-copy-id hadoop003Logon tanpa password telah dikonfigurasi jika output-nya sesuai dengan berikut.
Langkah 3: Instal Hadoop
Jalankan perintah berikut pada semua instans.
-
Unduh paket instalasi Hadoop.
wget http://mirrors.cloud.aliyuncs.com/apache/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz -
Ekstrak paket instalasi Hadoop ke
/opt/hadoop.sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt/ sudo mv /opt/hadoop-3.2.4 /opt/hadoop -
Konfigurasikan variabel lingkungan Hadoop.
sudo sh -c "echo 'export HADOOP_HOME=/opt/hadoop' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/bin' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/sbin' >> /etc/profile" source /etc/profile -
Ubah file konfigurasi
yarn-env.shdanhadoop-env.sh.sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh' sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh' -
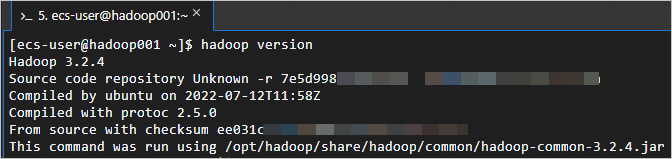
Verifikasi bahwa Hadoop telah terinstal.
hadoop versionOutput berikut menunjukkan instalasi berhasil.
Langkah 4: Konfigurasikan Hadoop
Ubah file konfigurasi Hadoop pada semua node.
-
Ubah file konfigurasi Hadoop
core-site.xml.-
Buka file untuk diedit.
sudo vim /opt/hadoop/etc/hadoop/core-site.xml -
Pada bagian
<configuration></configuration>, sisipkan konten berikut.<!--Tentukan alamat NameNode--> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop001:8020</value> </property> <!--Tentukan direktori untuk menyimpan file yang dihasilkan oleh Hadoop--> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/data</value> </property> <!--Konfigurasikan pengguna statis untuk logon web HDFS sebagai hadoop--> <property> <name>hadoop.http.staticuser.user</name> <value>hadoop</value> </property>
-
-
Ubah file konfigurasi Hadoop
hdfs-site.xml.-
Buka file untuk diedit.
sudo vim /opt/hadoop/etc/hadoop/hdfs-site.xml -
Pada bagian
<configuration></configuration>, sisipkan konten berikut.<!-- Titik akhir web NameNode --> <property> <name>dfs.namenode.http-address</name> <value>hadoop001:9870</value> </property> <!-- Titik akhir web Secondary NameNode --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop003:9868</value> </property>
-
-
Ubah file konfigurasi Hadoop
yarn-site.xml.-
Buka file untuk diedit.
sudo vim /opt/hadoop/etc/hadoop/yarn-site.xml -
Pada bagian
<configuration></configuration>, sisipkan konten berikut.<!--Metode NodeManager untuk memperoleh data adalah shuffle--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--Tentukan alamat YARN (ResourceManager)--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop002</value> </property> <!--Tentukan daftar putih variabel lingkungan yang dapat diteruskan NodeManager ke container--> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property>
-
-
Ubah file konfigurasi Hadoop
mapred-site.xml.-
Buka file untuk diedit.
sudo vim /opt/hadoop/etc/hadoop/mapred-site.xml -
Pada bagian
<configuration></configuration>, sisipkan konten berikut.<!--Beritahu Hadoop untuk menjalankan MapReduce (MR) pada YARN--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
-
-
Ubah file konfigurasi Hadoop
workers.-
Buka file untuk diedit.
sudo vim /opt/hadoop/etc/hadoop/workers -
Pada file
workers, sisipkan informasi instans.hadoop001 hadoop002 hadoop003
-
Langkah 5: Jalankan Hadoop
-
Inisialisasi
namenode.PeringatanInisialisasi
namenodepada ketiga instans hanya dilakukan saat startup pertama kali.hadoop namenode -format -
Jalankan Hadoop.
Penting-
Komunitas Hadoop tidak merekomendasikan menjalankan Hadoop sebagai pengguna root karena masalah keamanan dan izin. Gunakan pengguna non-root seperti
ecs-user. -
Jika Anda harus menjalankan Hadoop sebagai root, pahami model kontrol akses dan risiko terkait sebelum mengubah file konfigurasi berikut.
Catatan: Menjalankan Hadoop sebagai root menimbulkan risiko keamanan serius, termasuk namun tidak terbatas pada pelanggaran data, peningkatan kerentanan terhadap malware yang dapat memperoleh hak istimewa root, dan masalah izin tak terduga. Lihat dokumentasi resmi Hadoop.
File konfigurasi berikut biasanya berada di direktori
/opt/hadoop/sbin.-
Pada file
start-dfs.shdanstop-dfs.sh, tambahkan parameter berikut.HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root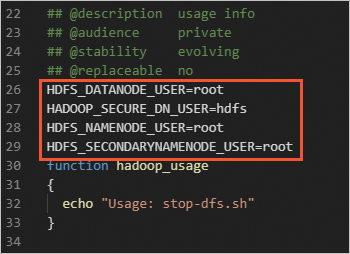
-
Pada file
start-yarn.shdanstop-yarn.sh, tambahkan parameter berikut.YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root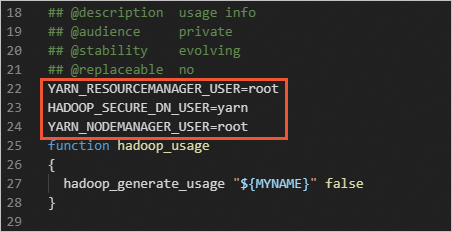
-
Pada
hadoop001, jalankanstart-dfs.shuntuk menjalankan layanan HDFS.Skrip ini menjalankan NameNode, SecondaryNameNode, dan DataNode.
start-dfs.shHDFS sedang berjalan jika output
jpssesuai dengan berikut.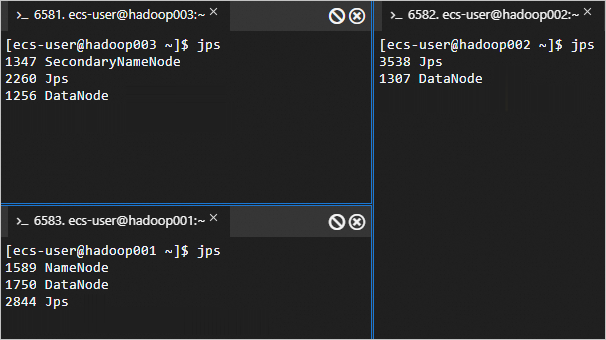
-
Pada
hadoop002, jalankanstart-yarn.shuntuk menjalankan layanan YARN.Skrip ini menjalankan ResourceManager dan NodeManager.
start-yarn.shYARN sedang berjalan jika output-nya sesuai dengan berikut.
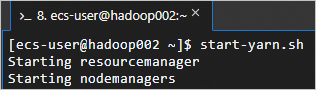
-
-
Lihat proses yang sedang berjalan pada ketiga node.
jpsProses yang sedang berjalan adalah sebagai berikut.
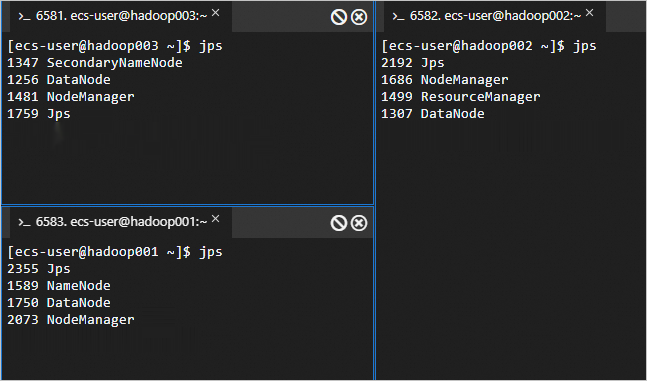
-
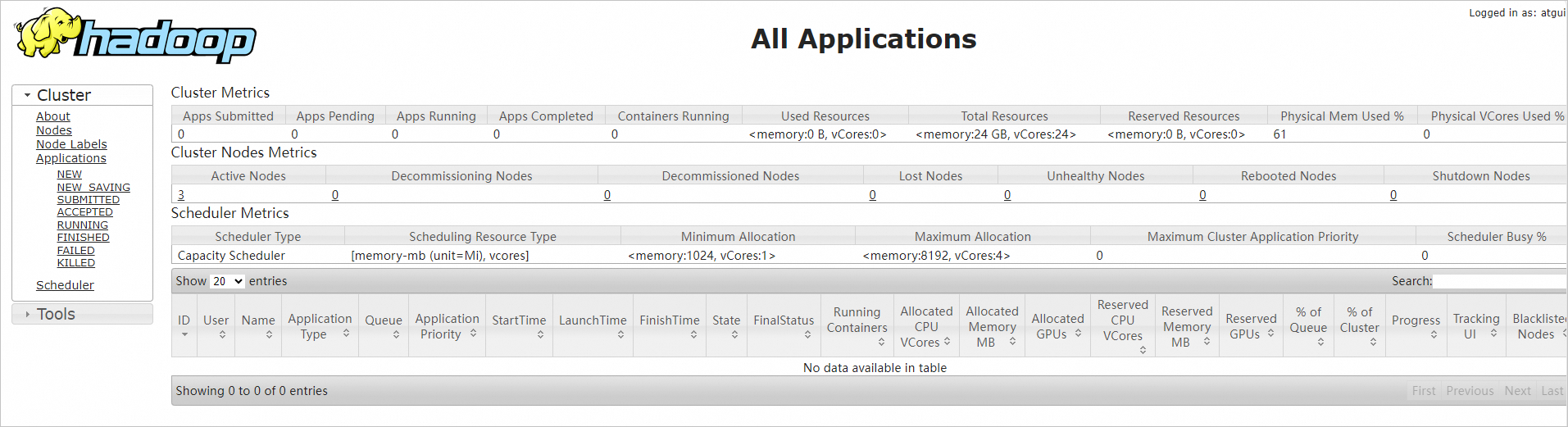
Pada browser Anda, masukkan
http://<Alamat IP publik instans ECS hadoop002>:8088untuk mengakses YARN web UI.Lihat penggunaan sumber daya kluster, status pekerjaan MapReduce, dan informasi antrian.
PentingIzinkan lalu lintas inbound pada port 8088 di security group. Jika tidak, web UI tidak dapat diakses. Lihat Add a security group rule.
-
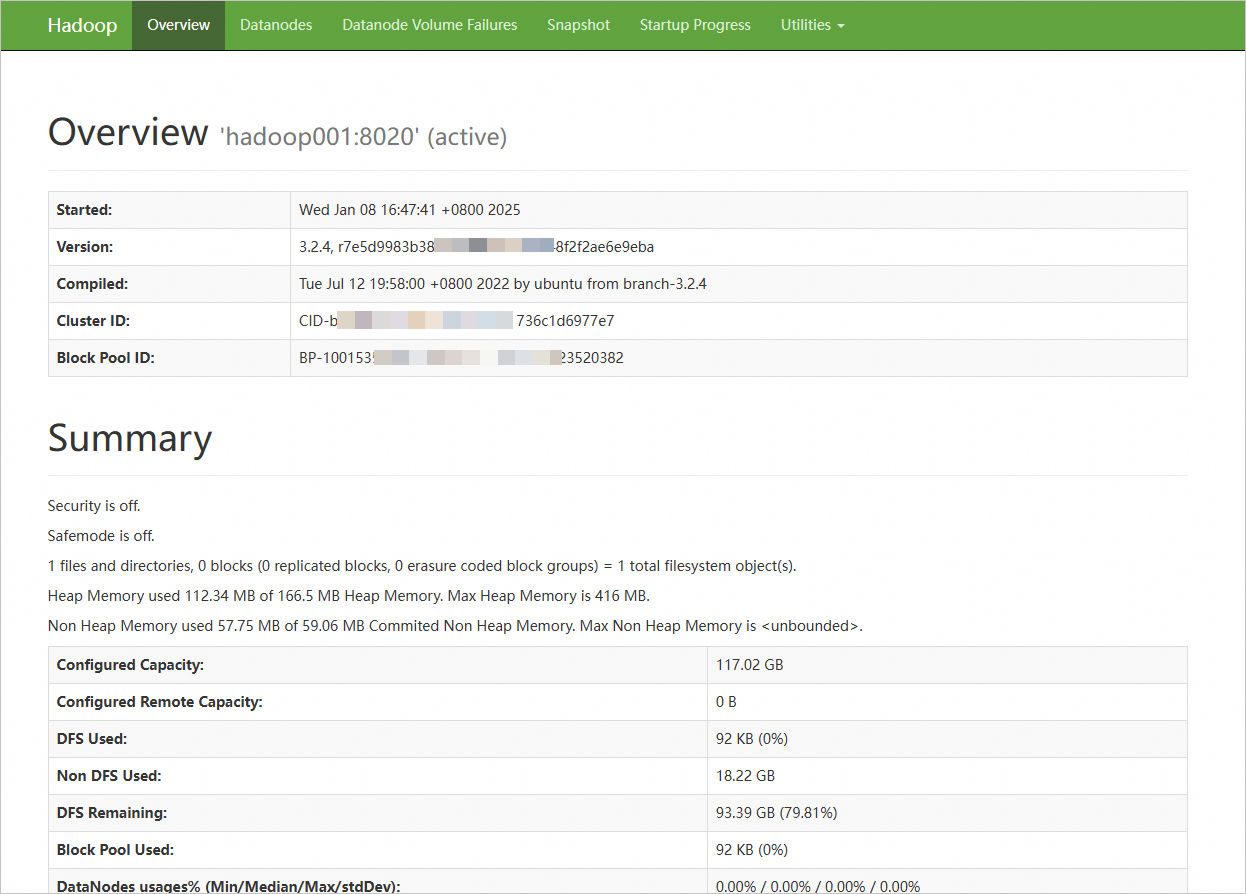
Pada browser Anda, masukkan
http://<Alamat IP publik instans ECS hadoop001>:9870untuk mengakses NameNode web UI. Masukkanhttp://<Alamat IP publik instans ECS hadoop003>:9868untuk mengakses SecondaryNameNode web UI.Lihat status HDFS, kesehatan kluster, node aktif, dan log NameNode.
Laman berikut menunjukkan bahwa lingkungan terdistribusi telah dibangun.
PentingIzinkan lalu lintas inbound pada port 9870 di security group. Jika tidak, web UI tidak dapat diakses. Lihat Add a security group rule.
Pseudo-terdistribusi
Langkah 1: Instal JDK
-
Hubungkan ke instans ECS sebagai pengguna biasa.
Lihat Menghubungkan ke Instans Linux Menggunakan Workbench.
PentingKomunitas Hadoop tidak merekomendasikan menjalankan Hadoop sebagai pengguna root karena masalah keamanan dan izin. Gunakan pengguna non-root seperti
ecs-user. -
Unduh paket instalasi JDK 1.8.
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz -
Ekstrak paket instalasi JDK 1.8.
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz -
Pindahkan dan ubah nama folder instalasi JDK.
Contoh ini mengubah nama folder instalasi JDK menjadi
java8. Anda dapat menggunakan nama lain.sudo mv java-se-8u41-ri/ /usr/java8 -
Konfigurasikan variabel lingkungan Java.
Jika Anda mengubah nama folder instalasi JDK, ganti
java8dalam perintah berikut dengan nama yang sebenarnya.sudo sh -c "echo 'export JAVA_HOME=/usr/java8' >> /etc/profile" sudo sh -c 'echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile' source /etc/profile -
Verifikasi bahwa JDK telah terinstal.
java -versionOutput berikut menunjukkan instalasi berhasil.
Langkah 2: Konfigurasikan logon SSH tanpa password
Node tunggal juga memerlukan logon SSH tanpa password. Jika tidak, menjalankan NameNode dan DataNode akan gagal dengan error permission denied.
-
Buat kunci publik dan kunci privat.
ssh-keygen -t rsa -
Tambahkan kunci publik ke file
authorized_keys.cd .ssh cat id_rsa.pub >> authorized_keys
Langkah 3: Instal Hadoop
-
Unduh paket instalasi Hadoop.
wget http://mirrors.cloud.aliyuncs.com/apache/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz -
Ekstrak paket instalasi Hadoop ke
/opt/hadoop.sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt/ sudo mv /opt/hadoop-3.2.4 /opt/hadoop -
Konfigurasikan variabel lingkungan Hadoop.
sudo sh -c "echo 'export HADOOP_HOME=/opt/hadoop' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/bin' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/sbin' >> /etc/profile" source /etc/profile -
Ubah file konfigurasi
yarn-env.shdanhadoop-env.sh.sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh' sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh' -
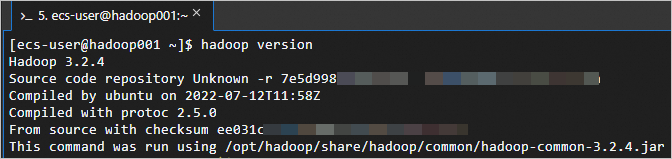
Verifikasi bahwa Hadoop telah terinstal.
hadoop versionOutput berikut menunjukkan instalasi berhasil.
Langkah 4: Konfigurasikan Hadoop
-
Ubah file konfigurasi Hadoop
core-site.xml.-
Buka file untuk diedit.
sudo vim /opt/hadoop/etc/hadoop/core-site.xml -
Pada bagian
<configuration></configuration>, sisipkan konten berikut.<property> <name>hadoop.tmp.dir</name> <value>file:/opt/hadoop/tmp</value> <description>lokasi untuk menyimpan file sementara</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property>
-
-
Ubah file konfigurasi Hadoop
hdfs-site.xml.-
Buka file untuk diedit.
sudo vim /opt/hadoop/etc/hadoop/hdfs-site.xml -
Pada bagian
<configuration></configuration>, sisipkan konten berikut.<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop/tmp/dfs/data</value> </property>
-
Langkah 5: Jalankan Hadoop
-
Inisialisasi
namenode.hadoop namenode -format -
Jalankan Hadoop.
Penting-
Komunitas Hadoop tidak merekomendasikan menjalankan Hadoop sebagai pengguna root karena masalah keamanan dan izin. Gunakan pengguna non-root seperti
ecs-user. -
Jika Anda harus menjalankan Hadoop sebagai root, pahami model kontrol akses dan risiko terkait sebelum mengubah file konfigurasi berikut.
Catatan: Menjalankan Hadoop sebagai root menimbulkan risiko keamanan serius, termasuk namun tidak terbatas pada pelanggaran data, peningkatan kerentanan terhadap malware yang dapat memperoleh hak istimewa root, dan masalah izin tak terduga. Lihat dokumentasi resmi Hadoop.
File konfigurasi berikut biasanya berada di direktori
/opt/hadoop/sbin.-
Pada file
start-dfs.shdanstop-dfs.sh, tambahkan parameter berikut.HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root -
Pada file
start-yarn.shdanstop-yarn.sh, tambahkan parameter berikut.YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
-
Jalankan layanan HDFS.
Skrip ini menjalankan NameNode, SecondaryNameNode, dan DataNode.
start-dfs.shHDFS sedang berjalan jika output-nya sesuai dengan berikut.
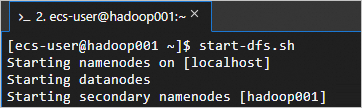
-
Jalankan layanan YARN.
Skrip ini menjalankan ResourceManager, NodeManager, dan ApplicationHistoryServer.
start-yarn.shYARN sedang berjalan jika output-nya sesuai dengan berikut.
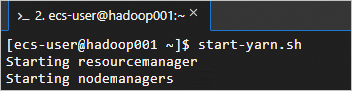
-
-
Lihat proses yang sedang berjalan.
jpsProses yang sedang berjalan adalah sebagai berikut.
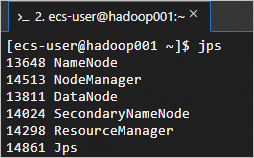
-
Pada browser Anda, masukkan
http://<Alamat IP publik instans ECS>:8088untuk mengakses YARN web UI.Lihat penggunaan sumber daya kluster, status pekerjaan MapReduce, dan informasi antrian.
PentingIzinkan lalu lintas inbound pada port 8088 di security group. Jika tidak, web UI tidak dapat diakses. Lihat Add a security group rule.
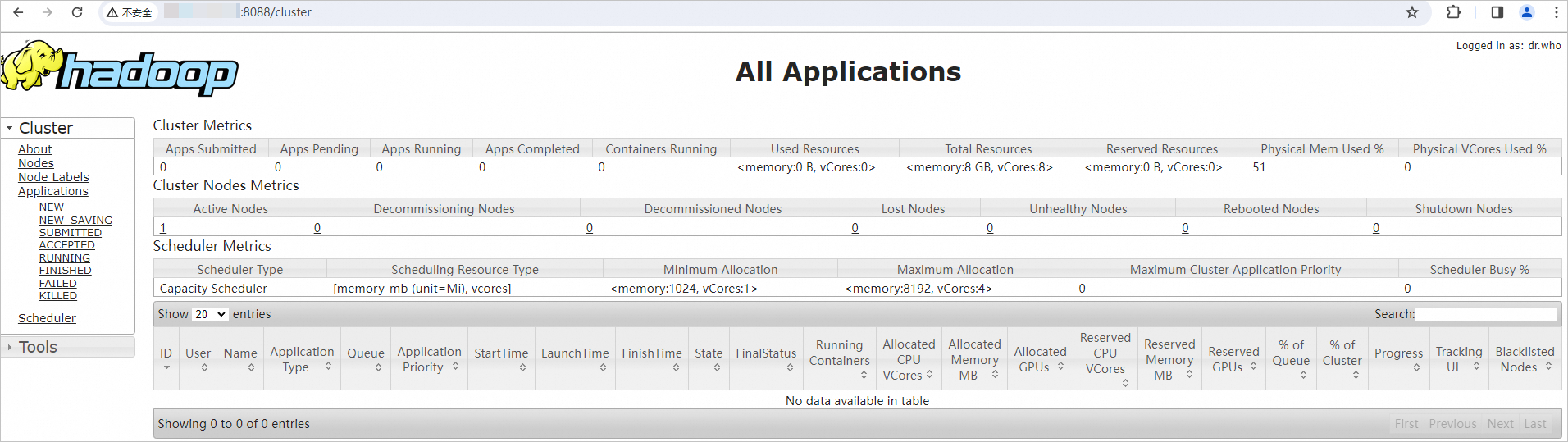
-
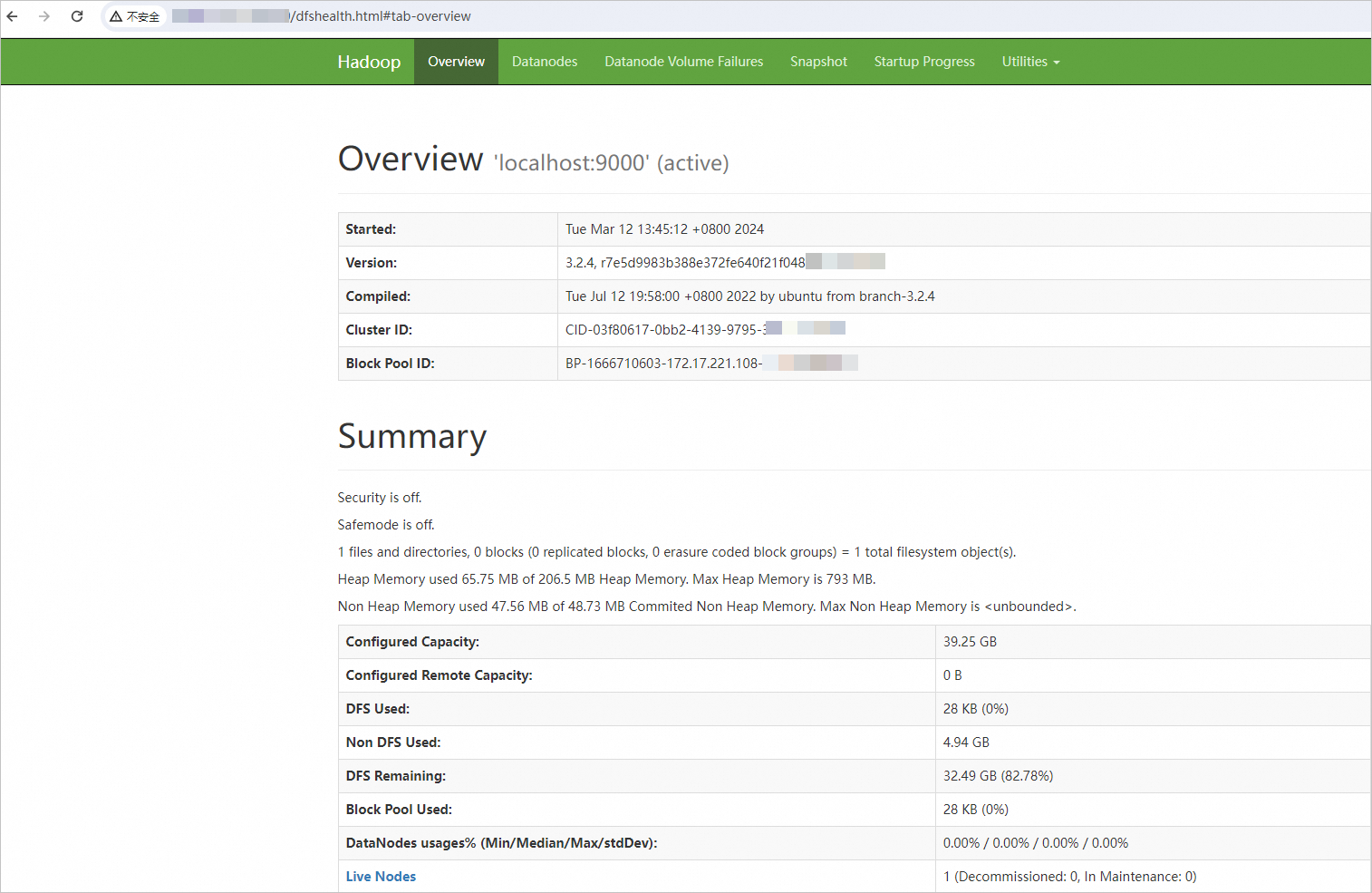
Pada browser Anda, masukkan
http://<Alamat IP publik instans ECS>:9870untuk mengakses NameNode web UI.Lihat status HDFS, kesehatan kluster, node aktif, dan log NameNode.
Laman berikut menunjukkan bahwa lingkungan pseudo-terdistribusi telah dibangun.
PentingIzinkan lalu lintas inbound pada port 9870 di security group. Jika tidak, web UI tidak dapat diakses. Lihat Add a security group rule.
Operasi tambahan
Buat grup snapshot-konsisten
Untuk Hadoop terdistribusi, gunakan grup snapshot-konsisten untuk memastikan konsistensi data di seluruh kluster. Lihat Create a snapshot-consistent group.
Operasi terkait Hadoop
Untuk operasi HDFS, lihat Common HDFS commands.
Referensi
-
Untuk menggunakan lingkungan data besar terintegrasi Alibaba Cloud pada ECS, lihat Quickly create and use a Data Lake Analytics cluster.
-
Untuk menggunakan lingkungan pengembangan dan tata kelola data lake, lihat Advanced: Analyze best-selling product categories from order data.