DataWorks adalah platform pengembangan dan tata kelola data besar (big data) terpadu yang didukung oleh mesin data besar seperti MaxCompute, Hologres, E-MapReduce (EMR), AnalyticDB, dan CDP. Platform ini mendukung arsitektur gudang data (data warehouse), data lake, dan lakehouse. Tutorial ini menunjukkan cara melakukan ingesti data, mengatur alur kerja bisnis, menjadwalkan tugas periodik, serta membuat visualisasi data dengan DataWorks.
Mulai
Tutorial ini menggunakan skenario e-commerce untuk menunjukkan cara membangun Data Pipeline end-to-end—mulai dari ingesti data mentah hingga analisis dan visualisasi data. Mengikuti proses standar ini memungkinkan Anda membangun Alur kerja data yang dapat digunakan kembali secara cepat, memastikan Penjadwalan yang andal dan observabilitas operasional. Pendekatan ini memungkinkan pengguna bisnis mengubah data menjadi insight tanpa keahlian teknis mendalam dan mempermudah organisasi Anda dalam mengadopsi aplikasi data besar.
Dalam tutorial ini, Anda akan:
Sinkronisasi Data: Gunakan modul Data Integration di DataWorks untuk membuat Tugas Batch tabel tunggal yang menyinkronkan data bisnis ke platform komputasi data besar, seperti MaxCompute.
Pembersihan Data: Gunakan modul Data Studio di DataWorks untuk memproses, menganalisis, dan menambang data bisnis.
Visualisasi Data: Gunakan modul Data Analysis di DataWorks untuk mengubah hasil analisis menjadi grafik yang mudah dipahami oleh pengguna bisnis.
Penjadwalan Periodik: Konfigurasikan Penjadwalan Periodik untuk proses Sinkronisasi Data dan Pembersihan Data.
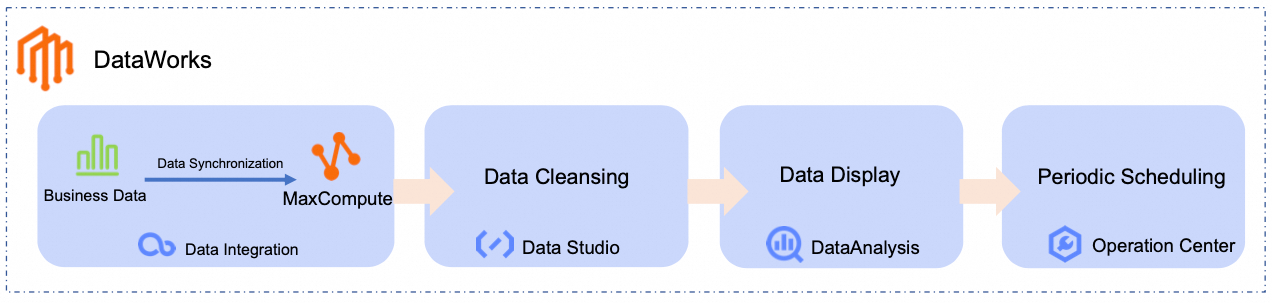
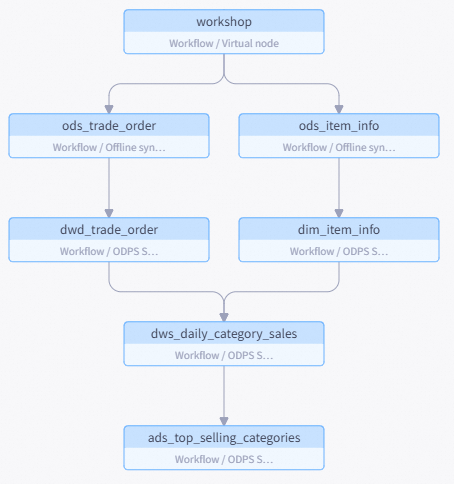
Dalam tutorial ini, Anda akan menggunakan Alur kerja berikut untuk menghasilkan peringkat harian kategori produk terlaris dengan menyinkronkan dan menganalisis data produk dan pesanan mentah dari sumber data publik ke MaxCompute:

Prasyarat
Untuk menyelesaikan tutorial ini, Anda memerlukan Akun Alibaba Cloud atau Pengguna RAM dengan izin AliyunDataWorksFullAccess. Untuk informasi selengkapnya, lihat Siapkan Akun Alibaba Cloud atau Siapkan Pengguna RAM.
DataWorks menyediakan sistem izin komprehensif yang mendukung kontrol akses pada tingkat produk dan modul. Jika Anda memerlukan kontrol akses detail halus, lihat Ikhtisar sistem pengelolaan izin DataWorks.
Prasyarat
Aktifkan DataWorks
Tutorial ini menggunakan wilayah China (Shanghai) untuk menunjukkan cara memulai DataWorks. Anda harus masuk ke Konsol DataWorks, beralih ke wilayah China (Shanghai), dan periksa apakah DataWorks telah diaktifkan.
Pilih wilayah berdasarkan lokasi data bisnis Anda:
Jika data bisnis Anda berada di layanan Alibaba Cloud lainnya, pilih wilayah yang sama dengan layanan tersebut.
Jika bisnis Anda on-premises dan memerlukan akses melalui jaringan publik, pilih wilayah terdekat untuk mengurangi latensi.
Pengguna baru
Jika Anda baru mengenal DataWorks, halaman berikut akan muncul, menunjukkan bahwa DataWorks belum diaktifkan di wilayah saat ini. Klik Purchase Product Portfolio for Free.

Konfigurasikan parameter pada halaman pembelian.
Parameter
Deskripsi
Contoh
Region
Pilih wilayah tempat Anda ingin mengaktifkan DataWorks.
China (Shanghai)
DataWorks edition
Pilih edisi DataWorks yang ingin Anda beli.
CatatanTutorial ini menggunakan Basic Edition sebagai contoh. Semua edisi mendukung fitur yang dibahas dalam tutorial ini. Untuk informasi selengkapnya, lihat Edisi dan fitur DataWorks untuk memilih edisi yang paling sesuai dengan kebutuhan bisnis Anda.
Basic Edition
Klik Confirm Order and Pay untuk menyelesaikan pembayaran.
Telah diaktifkan tetapi kedaluwarsa
Jika Anda sebelumnya telah mengaktifkan DataWorks di wilayah China (Shanghai) tetapi layanan telah kedaluwarsa, prompt berikut akan muncul. Klik Purchase Edition.

Konfigurasikan parameter pada halaman pembelian.
Parameter
Deskripsi
Contoh
Edition
Pilih edisi DataWorks yang ingin Anda beli.
CatatanTutorial ini menggunakan Basic Edition sebagai contoh. Semua edisi mendukung fitur yang dibahas dalam tutorial ini. Untuk informasi selengkapnya, lihat Edisi dan fitur DataWorks untuk memilih edisi yang paling sesuai dengan kebutuhan bisnis Anda.
Basic Edition
Region
Pilih wilayah tempat Anda ingin mengaktifkan DataWorks.
China (Shanghai)
Klik Buy Now untuk menyelesaikan pembayaran.
Jika Anda tidak dapat menemukan edisi DataWorks yang telah Anda beli, coba langkah-langkah berikut:
Tunggu beberapa menit dan refresh halaman, karena mungkin terjadi penundaan sistem.
Pastikan wilayah saat ini sesuai dengan wilayah tempat Anda membeli edisi DataWorks. Jika wilayah tidak cocok, edisi tersebut tidak akan ditampilkan.
Sudah diaktifkan
Jika Anda telah mengaktifkan DataWorks di wilayah China (Shanghai), halaman ikhtisar DataWorks akan muncul. Anda dapat melanjutkan ke langkah berikutnya.
Buat ruang kerja
Siapkan kelompok sumber daya
Aktifkan akses jaringan publik
Tutorial ini menggunakan data uji e-commerce publik yang diakses melalui jaringan publik. Secara default, kelompok sumber daya yang dibuat pada langkah sebelumnya tidak memiliki akses jaringan publik. Anda harus mengonfigurasi Gateway NAT Internet dan menambahkan Alamat IP Elastis (EIP) untuk Virtual Private Cloud (VPC) yang terkait dengan kelompok sumber daya agar dapat mengakses jaringan publik dan mengambil data.
Masuk ke Konsol VPC - Gateway NAT Internet. Di bilah navigasi atas, beralih ke wilayah China (Shanghai), lalu klik Create Internet NAT Gateway. Konfigurasikan parameter berikut.
CatatanAnda dapat mempertahankan nilai default untuk parameter yang tidak tercantum dalam tabel.
Parameter
Nilai
Region
China (Shanghai).
Network and zone
Pilih VPC dan vSwitch yang terkait dengan kelompok sumber daya.
Anda dapat menemukan VPC dan vSwitch di halaman Daftar Kelompok Sumber Daya DataWorks. Beralih ke wilayah China (Shanghai), temukan kelompok sumber daya, lalu klik Network Settings di kolom Actions. Anda dapat menemukan VPC Binding dan vSwitch di bagian Data Scheduling & Data Integration. Untuk informasi selengkapnya tentang VPC, lihat Apa itu Virtual Private Cloud?.
Network type
Internet NAT Gateway.
Elastic IP address (EIP)
Pilih untuk membeli EIP baru.
Create service-linked role
Jika Anda membuat Internet NAT Gateway untuk pertama kalinya, buat peran terkait layanan dengan mengklik Create service-linked role.
Klik Buy Now untuk menyelesaikan pembayaran dan membuat instans Internet NAT Gateway.
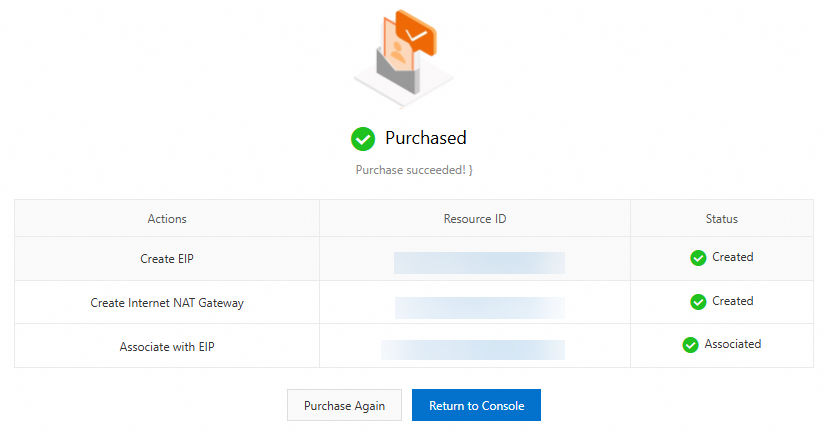
Setelah membuat instans Internet NAT Gateway, kembali ke konsol dan buat entri SNAT untuknya.
CatatanKelompok sumber daya hanya dapat mengakses jaringan publik melalui VPC ini setelah Anda mengonfigurasi entri SNAT.
Di kolom Actions untuk instans baru, klik Manage, lalu klik tab Configure SNAT.
Pada SNAT Entry List, klik Create SNAT Entry dan konfigurasikan parameter utama berikut:
Parameter
Nilai
SNAT entry
Pilih Specify VPC untuk memastikan semua kelompok sumber daya dalam VPC Internet NAT Gateway dapat mengakses jaringan publik menggunakan EIP yang dikonfigurasi.
Select EIP
Pilih EIP yang terikat pada instans Internet NAT Gateway saat ini.
Setelah mengonfigurasi parameter untuk entri SNAT, klik OK untuk membuatnya.
Pada SNAT Entry List, ketika Status entri SNAT baru berubah menjadi Available, VPC yang terkait dengan kelompok sumber daya telah memiliki akses jaringan publik.
Siapkan resource MaxCompute
Prosedur
Tutorial ini menunjukkan fitur inti DataWorks melalui contoh praktis.
Bayangkan sebuah platform e-commerce yang menyimpan informasi produk dan pesanannya dalam database MySQL. Tujuannya adalah menganalisis data ini secara berkala dan memvisualisasikan peringkat harian kategori produk terlaris.
Langkah 1: Sinkronisasi data
Buat sumber data
Pada langkah ini, buat Data Source MySQL untuk menghubungkan ke database sumber tutorial.
Anda tidak perlu menyiapkan data bisnis sendiri. DataWorks menyediakan dataset sampel dalam database MySQL publik untuk tutorial ini. Buat Data Source MySQL untuk menghubungkannya.
Buka halaman Pusat Manajemen DataWorks. Ubah wilayah menjadi China East 2 (Shanghai), pilih Ruang Kerja Anda dari daftar drop-down, lalu klik Go to Management Center.
Di panel navigasi kiri, klik Data Sources untuk membuka halaman Data Source List. Klik Add Data Source, pilih tipe MySQL, lalu konfigurasikan parameter Data Source.
CatatanAnda dapat mempertahankan nilai default untuk parameter yang tidak disebutkan dalam tabel.
Saat menambahkan sumber data untuk pertama kalinya, Anda perlu menyelesaikan cross-service authorization. Ikuti prompt di layar untuk memberikan peran terkait layanan AliyunDIDefaultRole.
Parameter
Deskripsi
Data Source Name
Untuk tutorial ini, masukkan MySQL_Source.
Configuration Mode
Pilih Connection String Mode.
Endpoint
Host Address IP:
rm-bp1z69dodhh85z9qa.mysql.rds.aliyuncs.comPort:
3306
PentingData dalam tutorial ini hanya untuk latihan praktis dengan DataWorks. Data ini hanya untuk tujuan pengujian dan bersifat read-only dalam modul Data Integration.
Database Name
Masukkan
retail_e_commerce.Username
Masukkan
workshop.Password
Masukkan
workshop#2017.Di bagian Connection Configuration, beralih ke tab Data Integration. Temukan kelompok sumber daya yang terikat pada ruang kerja Anda dan klik Test Network Connectivity di kolom Connectivity Status.
CatatanJika pengujian konektivitas untuk sumber data MySQL gagal, lakukan tindakan berikut:
Selesaikan langkah-langkah lanjutan dalam tool diagnostik konektivitas.
Periksa apakah Alamat IP Elastis (EIP) telah dikonfigurasi untuk VPC yang terikat pada kelompok sumber daya. Sumber data MySQL memerlukan kelompok sumber daya untuk memiliki akses jaringan publik. Untuk informasi selengkapnya, lihat Aktifkan akses jaringan publik untuk kelompok sumber daya.
Klik Complete Creation.
Bangun pipeline sinkronisasi
Pada langkah ini, bangun pipeline sinkronisasi untuk menyinkronkan data produk dan pesanan e-commerce ke tabel MaxCompute untuk pemrosesan lebih lanjut.
Klik ikon
 di pojok kiri atas dan pilih untuk membuka halaman DataStudio.
di pojok kiri atas dan pilih untuk membuka halaman DataStudio.Di bagian atas halaman, beralih ke Ruang Kerja Anda. Di panel navigasi kiri, klik
 untuk membuka halaman DataStudio.
untuk membuka halaman DataStudio.Di bagian Workspace Directories, klik
 , pilih Create Workflow, lalu beri nama
, pilih Create Workflow, lalu beri nama dw_quickstart.Pada kanvas alur kerja, seret node Zero Load dan dua node Batch Synchronization dari panel kiri ke kanvas. Konfigurasikan node Batch Synchronization sebagai berikut:
Data Source Type:
MySQLData Destination Type:
MaxComputeSpecific Type: Batch Synchronization Node
Tabel berikut mencantumkan nama node dan fungsinya untuk tutorial ini:
Tipe node
Nama node
Fungsi
 Zero Load
Zero LoadworkshopBerfungsi sebagai titik masuk Alur kerja untuk mendefinisikan alur data yang jelas. Ini adalah tugas Dry-run yang tidak memerlukan kode.
 Batch Synchronization Node
Batch Synchronization Nodeods_item_infoMenyinkronkan tabel sumber informasi produk
item_infodari MySQL ke tabelods_item_infodi MaxCompute.Batch Synchronization Nodeods_trade_orderMenyinkronkan tabel sumber informasi pesanan
trade_orderdari MySQL ke tabelods_trade_orderdi MaxCompute.Hubungkan node dengan menyeret dan melepas, jadikan node
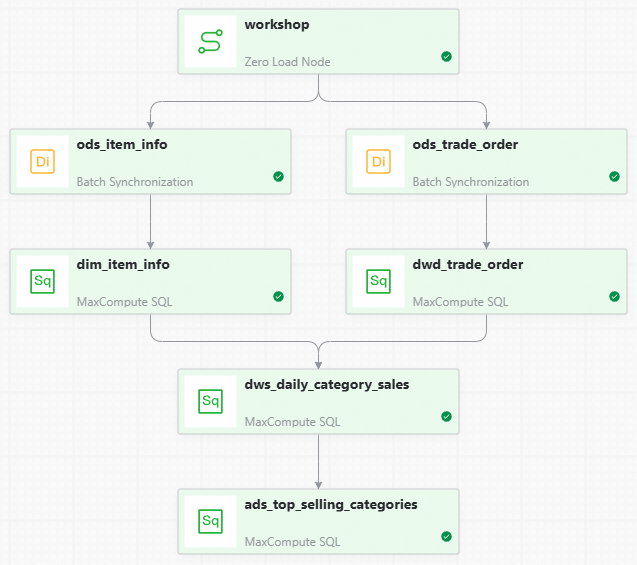
workshopsebagai node hulu untuk kedua node Batch Synchronization. Hasil akhirnya harus terlihat seperti ini:
Konfigurasikan penjadwalan alur kerja.
Di sisi kanan kanvas alur kerja, klik Scheduling dan konfigurasikan parameter. Tabel berikut menjelaskan parameter utama untuk tutorial ini. Gunakan nilai default untuk semua parameter lainnya.
Parameter penjadwalan
Deskripsi
Scheduling Parameters
Atur parameter penjadwalan untuk seluruh alur kerja. Parameter ini dapat digunakan langsung oleh node dalam alur kerja.
Untuk tutorial ini, atur menjadi
bizdate=$[yyyymmdd-1]untuk mendapatkan tanggal hari sebelumnya.CatatanDataWorks menyediakan parameter penjadwalan yang memungkinkan nilai dinamis dalam kode Anda. Anda dapat mendefinisikan variabel dalam kode SQL dengan menggunakan format
${variable_name}dan memberikan nilai di Scheduling > Scheduling Parameters. Untuk format parameter yang didukung, lihat Format yang didukung untuk parameter penjadwalan.Scheduling Cycle
Untuk tutorial ini, atur menjadi
Daily.Scheduling Time
Untuk tutorial ini, atur Scheduling Time menjadi
00:30. Alur kerja akan dimulai pada pukul00:30setiap hari.Scheduling Dependencies
Alur kerja ini tidak memiliki dependensi hulu, sehingga Anda dapat membiarkannya tidak dikonfigurasi. Untuk manajemen terpadu, Anda dapat mengklik Use Workspace Root Node untuk melampirkan alur kerja ke node root ruang kerja.
Node root ruang kerja diberi nama dalam format
WorkspaceName_root.
Konfigurasikan tugas sinkronisasi
Node awal
Sinkronisasi informasi produk (ods_item_info)
Sinkronisasi data pesanan (ods_trade_order)
Langkah 2: Bersihkan dan proses data
Setelah menyinkronkan data ke MaxCompute, gunakan modul DataStudio untuk membersihkan, memproses, dan menganalisis tabel ods_item_info dan ods_trade_order guna menghasilkan peringkat harian kategori produk terlaris.
Bangun pipeline pemrosesan data
Di panel navigasi kiri DataStudio, klik
 untuk membuka halaman DataStudio. Di bagian Workspace Directories, temukan dan klik alur kerja yang telah Anda buat. Pada kanvas alur kerja, seret node SQL MaxCompute dari panel kiri dan beri nama sesuai kebutuhan.
untuk membuka halaman DataStudio. Di bagian Workspace Directories, temukan dan klik alur kerja yang telah Anda buat. Pada kanvas alur kerja, seret node SQL MaxCompute dari panel kiri dan beri nama sesuai kebutuhan.Tabel berikut menunjukkan contoh nama node dan fungsinya untuk tutorial ini:
Tipe node
Nama node
Fungsi
 MaxCompute SQL
MaxCompute SQLdim_item_infoMemproses data produk dari tabel
ods_item_infountuk membuat tabel Dimensidim_item_info.MaxCompute SQLdwd_trade_orderMembersihkan dan mengubah data transaksi dari tabel
ods_trade_orderuntuk membuat tabel Faktadwd_trade_order.MaxCompute SQLdws_daily_category_salesMengagregasi data detail yang telah dibersihkan dan distandarisasi dari tabel
dwd_trade_orderdandim_item_infountuk menghasilkan tabel ringkasan penjualan kategori produk harian,dws_daily_category_sales.MaxCompute SQLads_top_selling_categoriesMenghasilkan tabel peringkat harian kategori produk terlaris,
ads_top_selling_categories, berdasarkan tabeldws_daily_category_sales.Seret dan lepas untuk menghubungkan node serta mengonfigurasi dependensi hulunya. Hasil akhirnya harus terlihat seperti ini:
 Catatan
CatatanAnda dapat mengatur dependensi dengan menghubungkan node secara manual atau mengaktifkan parsing otomatis kode dalam setiap node. Tutorial ini menggunakan metode koneksi manual. Untuk informasi selengkapnya tentang parsing otomatis, lihat Parsing dependensi otomatis.
Konfigurasikan node pemrosesan data
Node dim_item_info
Node dwd_trade_order
Node dws_daily_category_sales
Node ads_top_selling_categories
Langkah 3: Jalankan dan debug alur kerja
Setelah mengonfigurasi Alur kerja, jalankan untuk memverifikasi konfigurasinya sebelum menerapkannya ke Lingkungan produksi.
Di panel navigasi kiri DataStudio, klik
untuk membuka halaman DataStudio, lalu temukan alur kerja yang telah Anda buat di bagian Workspace Directories.Klik Run di bilah alat node. Di kotak dialog Enter running parameters, masukkan tanggal hari sebelumnya (misalnya,
20250416).CatatanNode alur kerja menggunakan parameter penjadwalan untuk kode dinamis. Saat debugging, Anda harus memberikan nilai konstan ke parameter ini untuk pengujian.
Klik OK untuk membuka halaman debugging run.
Tunggu hingga proses selesai. Hasil yang diharapkan adalah sebagai berikut:
Langkah 4: Kueri dan visualisasi data
Sekarang data mentah telah diproses dan diagregasi ke dalam tabel ads_top_selling_categories, Anda dapat mengkuerinya untuk melihat hasilnya.
Klik ikon
 di pojok kiri atas lalu klik .
di pojok kiri atas lalu klik .Di sebelah My Files, klik
 > Create File. Masukkan File Name kustom lalu klik OK.
> Create File. Masukkan File Name kustom lalu klik OK.Di editor SQL Query, masukkan pernyataan SQL berikut.
SELECT * FROM ads_top_selling_categories WHERE pt=${bizdate};Di pojok kanan atas, pilih sumber data MaxCompute lalu klik OK.
Klik tombol Run di bagian atas. Di halaman Cost Estimation, klik Run.
Di hasil kueri, klik
 untuk melihat grafik. Anda dapat mengklik ikon
untuk melihat grafik. Anda dapat mengklik ikon  di pojok kanan atas grafik untuk menyesuaikan gayanya.
di pojok kanan atas grafik untuk menyesuaikan gayanya. Anda juga dapat mengklik Save di pojok kanan atas grafik untuk menyimpannya sebagai kartu. Anda kemudian dapat melihatnya dengan mengklik Card (
 ) di panel navigasi kiri.
) di panel navigasi kiri.
Langkah 5: Konfigurasikan penjadwalan periodik
Untuk mendapatkan pembaruan harian, terapkan Alur kerja ke Lingkungan produksi untuk eksekusi periodik.
Parameter penjadwalan telah dikonfigurasi untuk alur kerja dan nodenya selama langkah sinkronisasi dan pemrosesan data. Anda hanya perlu menerapkan alur kerja ke lingkungan produksi. Untuk informasi selengkapnya tentang konfigurasi penjadwalan, lihat Konfigurasikan penjadwalan node.
Klik ikon
di pojok kiri atas lalu klik .Di panel navigasi kiri DataStudio, klik
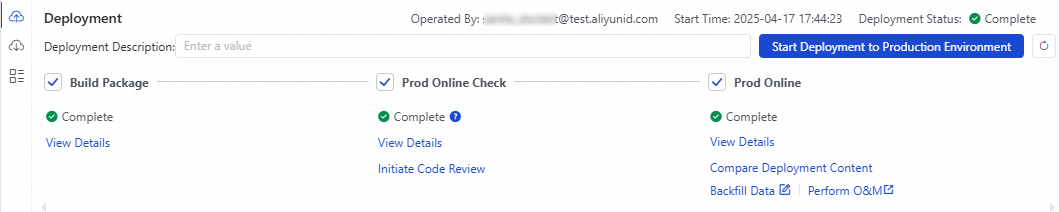
untuk membuka halaman DataStudio. Beralih ke Ruang Kerja yang digunakan untuk tutorial ini, lalu temukan alur kerja yang telah Anda buat di bagian Workspace Directories.Klik Deploy di bilah alat node. Di panel deployment, klik Start Deployment to Production. Tunggu hingga langkah Build Package dan Prod Online Check selesai, lalu klik Deploy.
Setelah status Prod Online berubah menjadi Complete, klik Perform O&M untuk membuka Pusat Operasi.
Di , Anda dapat melihat tugas periodik untuk Alur kerja (bernama
dw_quickstartdalam tutorial ini).Untuk melihat tugas periodik untuk node anak dalam Alur kerja, klik kanan tugas periodik alur kerja tersebut lalu pilih View Internal Tasks.
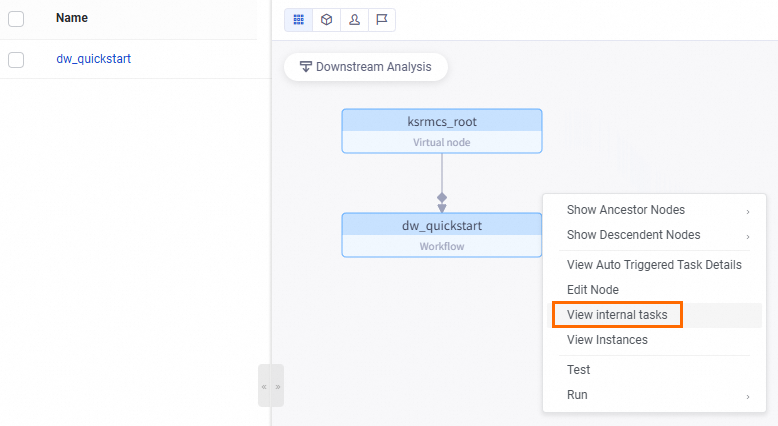
Hasil yang diharapkan adalah sebagai berikut:
Langkah selanjutnya
Untuk detail tentang operasi dan parameter modul yang dibahas dalam tutorial ini, lihat Data Integration, Data Studio (New), Data Analysis, dan Konfigurasi penjadwalan node.
Selain modul yang dibahas dalam tutorial ini, DataWorks juga mendukung modul lain seperti Data Modeling, Data Quality, Data Security Guard, dan DataService Studio untuk menyediakan pemantauan dan O&M data end-to-end.
Untuk tutorial praktis dan studi kasus lainnya, lihat Studi kasus dan tutorial lainnya.
Pembersihan resource
Untuk membersihkan resource yang Anda buat dalam tutorial ini, ikuti langkah-langkah berikut:
Batalkan deployment Node yang Dipicu Otomatis.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Di panel navigasi sebelah kiri, pilih . Di halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down lalu klik Go to Operation Center.
Buka . Pilih kotak centang untuk semua Node yang Dipicu Otomatis yang telah Anda buat. Jangan batalkan deployment node root Ruang Kerja. Lalu, di bagian bawah halaman, klik .
Hapus node pengembangan data dan putuskan asosiasi Resource Komputasi MaxCompute.
Buka halaman Ruang Kerja di Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Temukan ruang kerja yang diinginkan lalu pilih di kolom Actions.
Di panel navigasi kiri Data Studio, klik ikon
untuk membuka halaman Data Development. Di bagian Workspace Directories, temukan dan klik kanan Alur kerja yang telah Anda buat, lalu klik Delete.Di panel navigasi kiri, klik
 > Computing Resources. Temukan Resource Komputasi MaxCompute yang terasosiasi lalu klik Disassociate. Di kotak dialog konfirmasi, pilih kotak centang dan ikuti petunjuk di layar.
> Computing Resources. Temukan Resource Komputasi MaxCompute yang terasosiasi lalu klik Disassociate. Di kotak dialog konfirmasi, pilih kotak centang dan ikuti petunjuk di layar.
Hapus Data Source MySQL.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Di panel navigasi sebelah kiri, pilih . Di halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down lalu klik Go to Management Center.
Di panel navigasi kiri, klik Data Sources. Di halaman Data Sources, temukan Data Source MySQL yang telah Anda buat, klik Delete di kolom Actions, lalu ikuti petunjuk di layar.
Hapus proyek MaxCompute.
Buka halaman Manajemen Proyek MaxCompute. Temukan proyek MaxCompute yang telah Anda buat, klik Delete di kolom Actions, lalu ikuti petunjuk di layar.
Hapus Gateway NAT Internet dan lepas Alamat IP Elastis (EIP).
Buka Konsol VPC - Gateway NAT Internet. Di bilah menu atas, ubah Wilayah menjadi China (Shanghai).
Temukan Gateway NAT Internet yang telah Anda buat lalu klik
 > Delete di kolom Actions. Di kotak dialog konfirmasi, pilih kotak centang Force Delete, lalu klik OK.
> Delete di kolom Actions. Di kotak dialog konfirmasi, pilih kotak centang Force Delete, lalu klik OK.Di panel navigasi kiri, klik . Temukan EIP yang telah Anda buat lalu di kolom Actions, pilih
> Instance Management > Release. Di kotak dialog konfirmasi, klik OK.