Topik ini menjelaskan cara membuat kluster Elastic High Performance Computing (E-HPC) (sebelumnya E-HPC NEXT) yang mendukung elastic Remote Direct Memory Access (eRDMA), serta cara mengonfigurasi parameter waktu proses untuk aplikasi OSU-Benchmark guna mempercepat komunikasi pada aplikasi High Performance Computing (HPC) multi-node.
Informasi latar belakang
Dengan memanfaatkan teknologi eRDMA, tugas HPC paralel multi-node dalam kluster E-HPC (sebelumnya E-HPC NEXT) mencapai kinerja jaringan berkecepatan tinggi yang setara dengan kluster on-premises. Tugas-tugas tersebut—seperti peramalan iklim, simulasi industri, dan dinamika molekuler—memperoleh manfaat dari bandwidth tinggi dan latensi rendah, yang secara signifikan meningkatkan efisiensi simulasi numerik. Anda dapat memanfaatkan keunggulan RDMA pada jaringan yang sudah ada tanpa perlu menyebar controller antarmuka jaringan (NIC) tambahan, sehingga memastikan integrasi tanpa hambatan dan kemudahan penggunaan.
Persiapan
Buka halaman Create Cluster untuk membuat kluster E-HPC. Untuk informasi selengkapnya, lihat Create a Standard Edition cluster.
Tabel berikut menunjukkan contoh konfigurasi kluster.
Instance type: ecs.c7.xlarge. Tipe instans ini menyediakan 4 vCPU dan memori 8 GiB.
Image: aliyun_2_1903_x64_20G_alibase_20240628.vhd
CatatanPaket instalasi osu-benchmark dibuat berdasarkan image Alibaba Cloud Linux 2.1903 LTS 64-bit.
erdma-installer
mpich-aocc
Instance type: ecs.c7.xlarge. Tipe instans ini menyediakan 4 vCPU dan memori 8 GiB.
Image: aliyun_2_1903_x64_20G_alibase_20240628.vhd
Buat pengguna kluster. Untuk informasi selengkapnya, lihat User management.
Configuration Item | Konfigurasi | |
Cluster Configuration | Region | Shanghai |
Network and Zone | Pilih Zone L | |
Series | Standard Edition | |
Deployment Mode | Public Cloud Cluster | |
Cluster Type | SLURM | |
Control Plane Node | ||
Compute Nodes and Queues | Number of Queue Nodes | Node awal: |
Inter-node Interconnection | eRDMA Network Catatan Hanya beberapa spesifikasi node yang mendukung Elastic RDMA Interconnect (ERI). Untuk informasi selengkapnya, lihat elastic Remote Direct Memory Access (eRDMA) dan Enable eRDMA on enterprise-level instances. | |
Instance Type Group | Instance type: ecs.c8ae.xlarge atau instans AMD generasi yang sama lainnya. Image: aliyun_2_1903_x64_20G_alibase_20240628.vhd | |
Shared File Storage | /home cluster mount directory | Secara default, direktori |
/opt cluster mount directory | ||
Software and Service Components | Software to Install | |
Installable Service Components | Logon Node: |
Periksa lingkungan eRDMA
Periksa apakah konfigurasi eRDMA pada node komputasi telah benar.
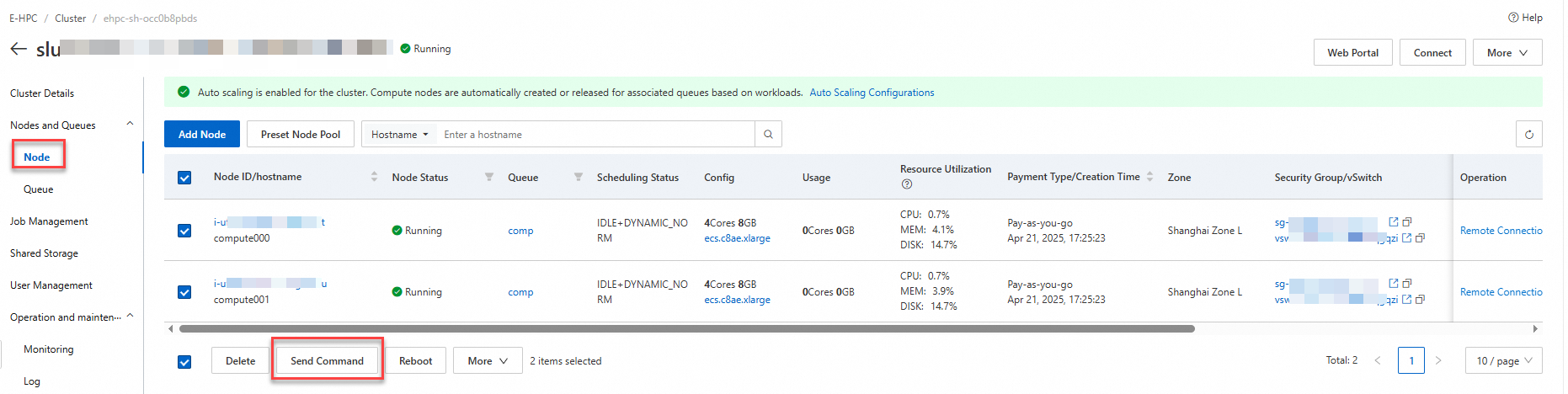
Masuk ke Konsol Elastic High Performance Computing dan klik kluster target.
Pada halaman , pilih semua node komputasi di kluster tersebut, lalu klik Send Command.
Periksa status jaringan eRDMA serta dukungan perangkat keras dan perangkat lunak RDMA pada node komputasi.
Kirim perintah berikut ke semua node komputasi.
hpcacc erdma check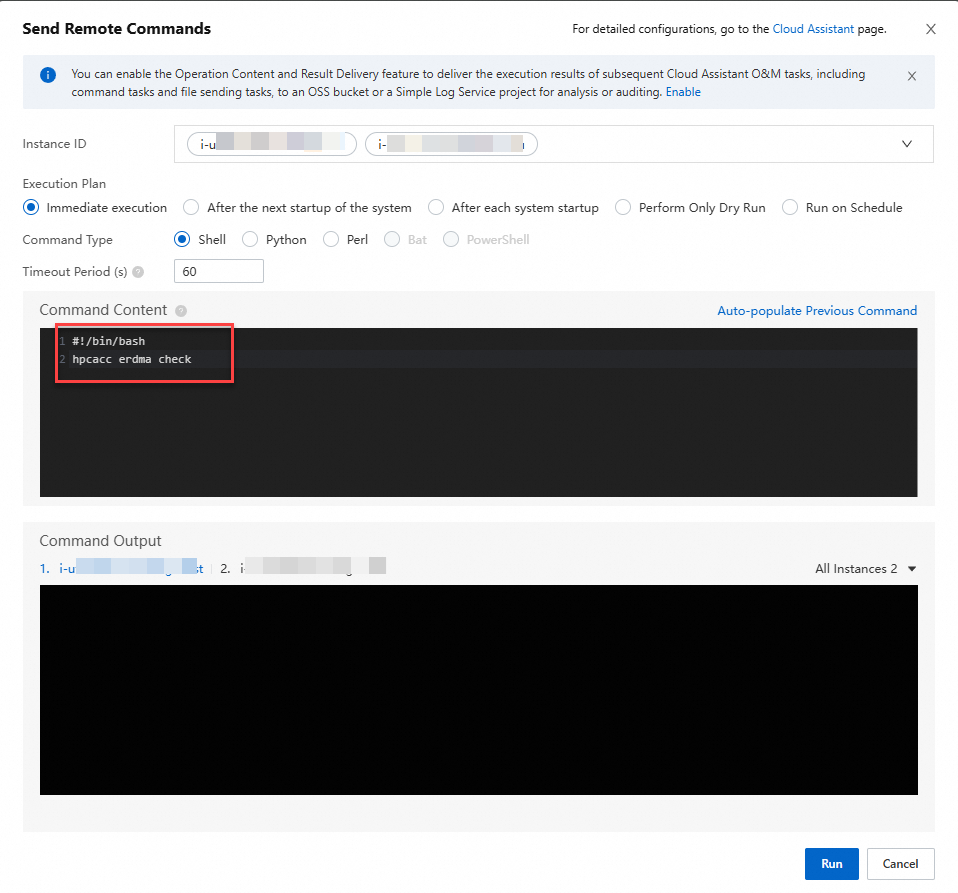
Jika hasil berikut dikembalikan, konfigurasi eRDMA telah benar.
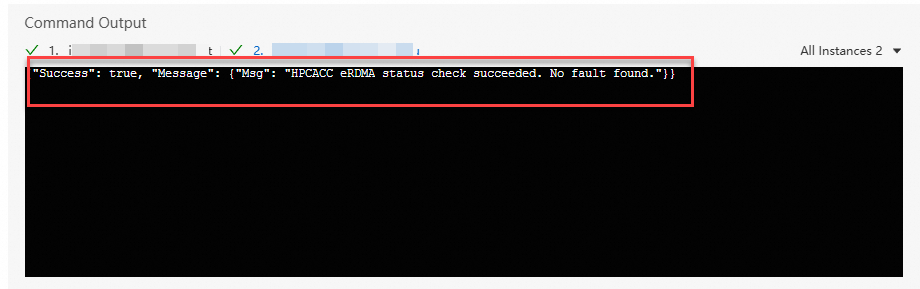
Jika pesan abnormal dikembalikan, jalankan perintah berikut untuk memperbaiki masalah tersebut.
hpcacc erdma repairSetelah masalah diperbaiki, pastikan konfigurasi eRDMA telah benar.
Uji OSU-Benchmark
OSU-Benchmark digunakan untuk mengevaluasi kinerja komunikasi kluster HPC dan sistem terdistribusi. Topik ini menggunakan dua benchmark berikut untuk menguji kinerja komunikasi berdasarkan protokol jaringan yang berbeda (TCP vs. RDMA):
Pengujian latensi jaringan (osu_latency): Mengukur latensi satu arah komunikasi titik-ke-titik, yaitu waktu yang dibutuhkan untuk mengirim pesan dari satu proses ke proses lainnya, tidak termasuk waktu tanggapan. Pengujian ini berfokus pada efisiensi komunikasi pesan kecil, mulai dari 1 B hingga beberapa kilobyte. Latensi pesan kecil mencerminkan kinerja dasar perangkat keras jaringan—seperti akselerasi RDMA—dan tingkat optimalisasi pustaka MPI. Ini merupakan indikator inti responsivitas sistem HPC. Sebagai contoh, latensi rendah secara signifikan mengurangi overhead komunikasi dalam simulasi real-time atau sinkronisasi parameter pembelajaran mesin.
Pengujian bandwidth jaringan (osu_bw): Mengukur bandwidth berkelanjutan komunikasi titik-ke-titik, yaitu jumlah data yang ditransfer per satuan waktu. Pengujian ini berfokus pada efisiensi transfer pesan besar, mulai dari beberapa kilobyte hingga beberapa megabyte. Kinerja bandwidth secara langsung memengaruhi efisiensi transfer data besar, seperti pertukaran matriks dalam komputasi ilmiah atau skenario I/O file. Jika bandwidth yang diukur jauh lebih rendah daripada nilai teoretis, lakukan optimalisasi konfigurasi MPI untuk komunikasi multi-threaded atau periksa pengaturan jaringan seperti MTU dan pembatasan kecepatan.
Prosedur pengujian adalah sebagai berikut:
Hubungkan ke kluster E-HPC sebagai pengguna yang telah Anda buat. Untuk informasi selengkapnya, lihat Connect to a cluster.
Jalankan perintah berikut untuk memeriksa apakah komponen lingkungan yang diperlukan telah terinstal dengan benar.
module availJalankan perintah berikut untuk mengunduh dan mengekstrak paket instalasi osu-benchmark yang telah dikompilasi sebelumnya.
cd ~ && wget https://ehpc-perf.oss-cn-hangzhou.aliyuncs.com/AMD-Genoa/osu-bin.tar.gz tar -zxvf osu-bin.tar.gzJalankan perintah berikut untuk masuk ke direktori kerja pengujian dan mengedit skrip pekerjaan Slurm.
cd ~/pt2pt vim slurm.jobSkrip pengujian adalah sebagai berikut:
#!/bin/bash #SBATCH --job-name=osu-bench #SBATCH --ntasks-per-node=1 #SBATCH --nodes=2 #SBATCH --partition=comp #SBATCH --output=%j.out #SBATCH --error=%j.out # Muat parameter lingkungan module purge module load aocc/4.0.0 gcc/12.3.0 libfabric/1.16.0 mpich-aocc/4.0.3 # Jalankan pengujian latensi MPI: eRDMA echo -e "++++++ use erdma for osu_lat: START" mpirun -np 2 -ppn 1 -genv FI_PROVIDER="verbs;ofi_rxm" ./osu_latency echo -e "------ use erdma for osu_lat: END\n" # Jalankan pengujian latensi MPI: TCP echo -e "++++++ use tcp for osu_lat: START" mpirun -np 2 -ppn 1 -genv FI_PROVIDER="tcp;ofi_rxm" ./osu_latency echo -e "------ use tcp for osu_lat: END\n" # Jalankan pengujian bandwidth MPI: eRDMA echo -e "++++++ use erdma for osu_bw: START" mpirun -np 2 -ppn 1 -genv FI_PROVIDER="verbs;ofi_rxm" ./osu_bw echo -e "------ use erdma for osu_bw: END\n" # Jalankan pengujian bandwidth MPI: TCP echo -e "++++++ use tcp for osu_bw: START" mpirun -np 2 -ppn 1 -genv FI_PROVIDER="tcp;ofi_rxm" ./osu_bw echo -e "------ use tcp for osu_bw: END\n"Catatan-np 2: Menentukan jumlah total proses. Nilai 2 berarti pekerjaan MPI menjalankan dua proses.-ppn 1: Menentukan jumlah proses per node. Nilai 1 berarti satu proses dijalankan di setiap node.-genv: Menyetel variabel lingkungan yang berlaku untuk semua proses.FI_PROVIDER="tcp;ofi_rxm": Menggunakan protokol TCP dan meningkatkan keandalan komunikasi melalui kerangka RXM.FI_PROVIDER="verbs;ofi_rxm": Memrioritaskan protokol Verbs berkinerja tinggi (berbasis RDMA) dan mengoptimalkan transmisi pesan melalui kerangka RXM. Alibaba Cloud eRDMA menyediakan jaringan RDMA elastis berkinerja tinggi.
Jalankan perintah berikut untuk mengirim pekerjaan pengujian.
sbatch slurm.jobBaris perintah akan menampilkan ID pekerjaan.

Jalankan perintah berikut untuk melihat status pekerjaan. Selama pengujian, Anda juga dapat melihat informasi pemantauan E-HPC di konsol, seperti status penyimpanan, pekerjaan, dan node. Untuk informasi selengkapnya, lihat View monitoring information.
squeue
Di direktori saat ini, Anda dapat melihat file log yang sesuai dengan ID pekerjaan. Output-nya adalah sebagai berikut:
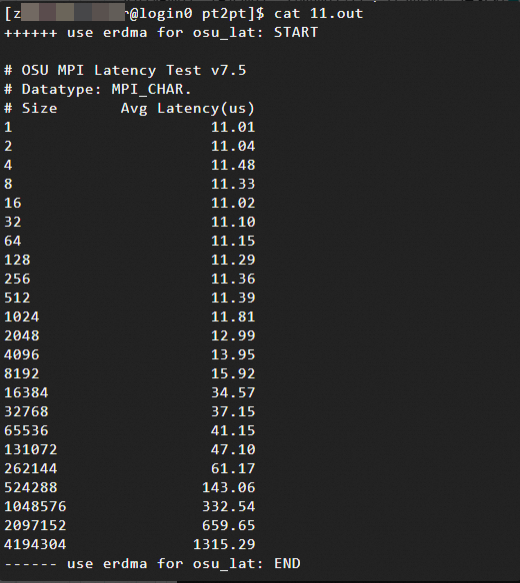
Hasil pengujian latensi jaringan: Hasil ini menunjukkan hubungan antara ukuran pesan (dalam byte, dari 1 B hingga 4 MB) dan latensi rata-rata. Berikut adalah contoh hasil pengujian:
Menggunakan protokol Verbs (berbasis eRDMA)
Menggunakan protokol TCP
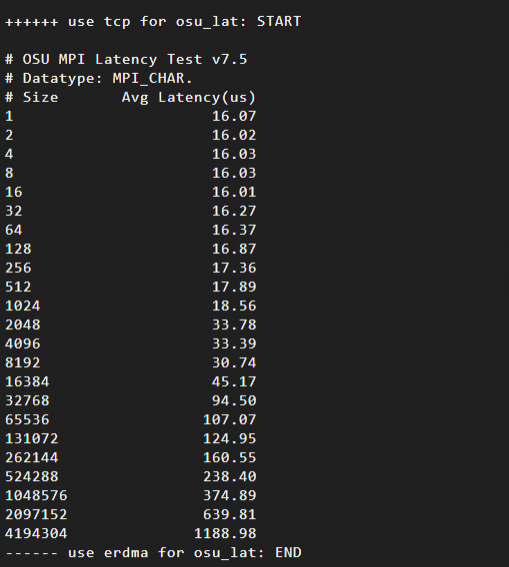
Data pengujian menunjukkan bahwa untuk pesan kecil (1 B hingga 8 KB), latensi eRDMA jauh lebih rendah dibandingkan TCP.
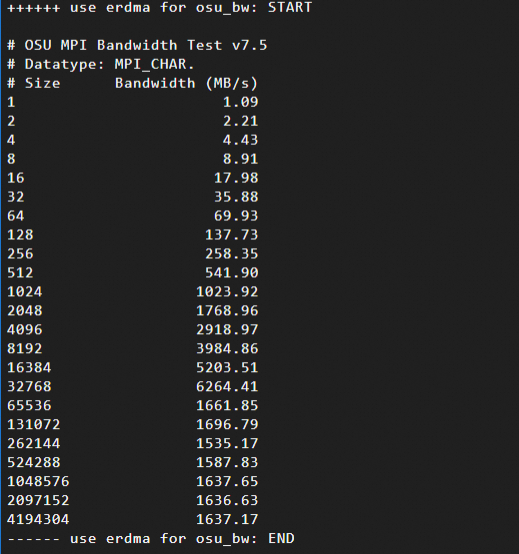
Hasil pengujian bandwidth jaringan: Hasil ini menunjukkan hubungan antara ukuran pesan (dalam byte, dari 1 B hingga 4 MB) dan bandwidth. Berikut adalah contoh hasil pengujian:
Menggunakan protokol Verbs (berbasis eRDMA)
Menggunakan protokol TCP
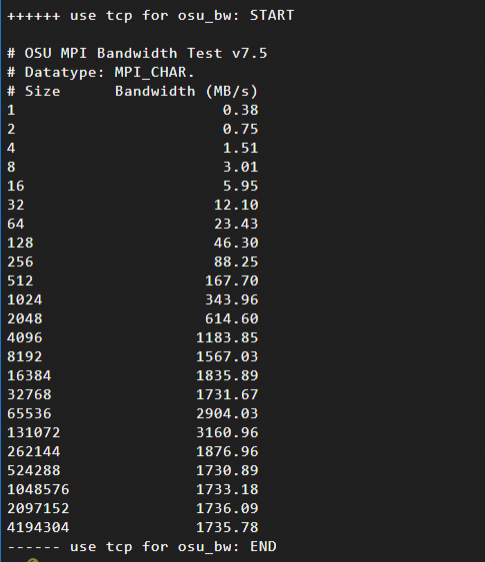
Data pengujian menunjukkan bahwa untuk ukuran pesan dari 16 KB hingga 64 KB, eRDMA sepenuhnya memanfaatkan bandwidth jaringan, sedangkan tumpukan protokol TCP menimbulkan overhead pemrosesan tambahan.