Dasbor Pemantauan E-HPC menyediakan visibilitas real-time terhadap compute node, penyimpanan bersama, dan sumber daya pekerjaan melalui empat tampilan: Ikhtisar, Pemantauan Node, Pemantauan Penyimpanan, dan Pemantauan Pekerjaan. Gunakan data ini untuk mengidentifikasi bottleneck sumber daya, melacak kesehatan antrian pekerjaan, serta membuat keputusan penjadwalan yang tepat.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
Kluster dalam status Running
Kluster dengan mode penyebaran diatur ke Public cloud cluster
Kluster yang menjalankan penjadwal Slurm atau PBS
Komponen monitoring yang telah diinstal pada kluster
(Hanya untuk pengguna RAM) Izin untuk melihat informasi pemantauan di Konsol E-HPC. Untuk detailnya, lihat Berikan izin kepada pengguna RAM
Lihat pemantauan kluster
Masuk ke Konsol E-HPC.
Di bagian kiri bilah navigasi atas, pilih wilayah.
Di panel navigasi sebelah kiri, klik Cluster.
Pada halaman Cluster List, klik ID kluster yang ingin Anda pantau.
Di panel navigasi sebelah kiri, pilih Operation and maintenance management > Monitoring.
Klik tab untuk melihat data pemantauan yang sesuai.
Pada tab Node Monitoring, Storage Monitoring, dan Job Monitoring, gunakan kontrol rentang waktu untuk membatasi cakupan data. Klik tombol preset untuk melihat data selama 1 jam, 4 jam, 12 jam, atau 1 hari terakhir. Untuk menentukan jendela waktu tertentu, pilih waktu mulai dan akhir secara kustom. Rentang kustom maksimum adalah satu bulan.
Untuk daftar lengkap metrik pada setiap tab, lihat Metrik.
Metrik
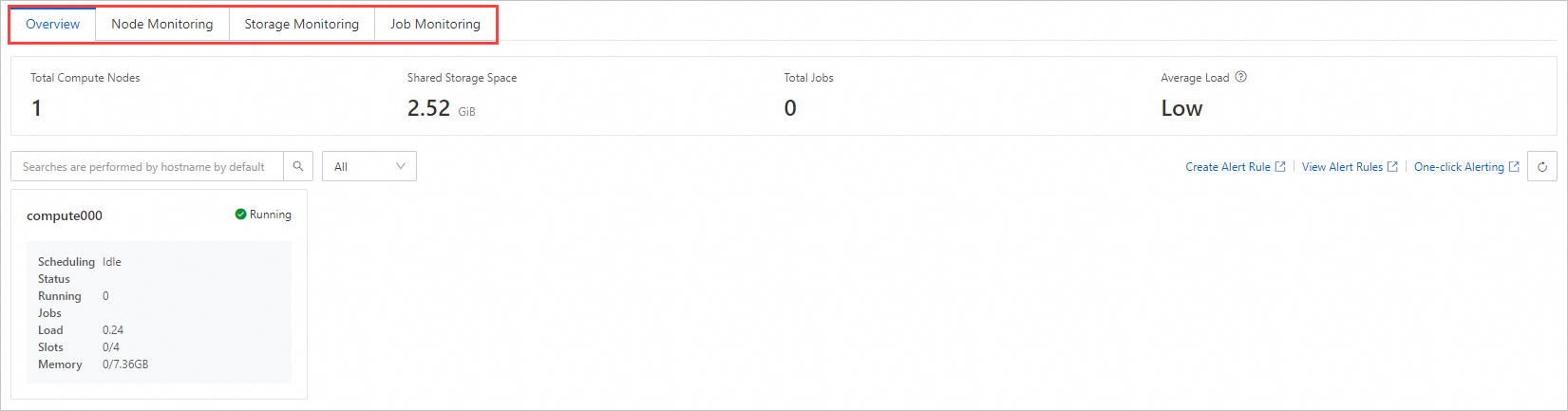
Ikhtisar
Tab Overview menampilkan ringkasan status sumber daya di seluruh kluster:
Total Compute Nodes — jumlah total compute node dalam kluster
Shared Storage Space — kapasitas total penyimpanan bersama
Total Jobs — jumlah total pekerjaan di semua status
Average Load — rata-rata beban sistem di seluruh compute node
Di bawah ringkasan tersebut, setiap compute node ditampilkan beserta status penjadwalannya dan penggunaan sumber dayanya. Nilai status penjadwalan:
| Status | Description |
|---|---|
| Idle | Semua core menganggur. Node tersedia dengan kapasitas penuh dan siap menerima pekerjaan baru. |
| Running | Beberapa core sedang digunakan; core yang tersisa masih dapat menerima pekerjaan baru. |
| Allocated | Semua core telah terisi. Pekerjaan baru akan masuk antrian hingga tersedia core kosong. |
| Offline | Node tidak berpartisipasi dalam komputasi dan tidak menerima pekerjaan baru. |
Pemantauan node
Tab Node Monitoring menampilkan metrik performa compute node. Filter berdasarkan kluster atau antrian untuk mempersempit tampilan.
| Metric | Description |
|---|---|
| CPU Utilization | Persentase daya pemrosesan yang digunakan di compute node. Utilisasi yang terus-menerus di atas 80–90% menunjukkan penggunaan sumber daya yang efisien tetapi dapat menurunkan performa dalam jangka panjang. Utilisasi di kisaran 0–30% mungkin mengindikasikan penggunaan yang kurang optimal atau adanya masalah penjadwalan. |
| Memory Usage | Konsumsi memori pada compute node. Pantau secara berkala untuk mencegah kegagalan pekerjaan akibat luapan buffer. Jika penggunaan memori konsisten tinggi, tingkatkan kapasitas memori atau optimalkan alokasi memori. |
| System Load | Beban kerja pada compute node. Rasio beban terhadap jumlah node yang tinggi menunjukkan tekanan pada sumber daya. Untuk mengurangi beban, tambahkan node (scale-out) atau optimalkan penjadwalan pekerjaan. |
| Disk Usage | Konsumsi ruang penyimpanan disk. Pada penggunaan disk 100%, operasi tulis akan gagal. Hapus data yang tidak diperlukan atau perluas kapasitas penyimpanan sebelum mencapai ambang batas tersebut. |
| Disk Read and Write | Laju pembacaan dan penulisan data. Satuan: KB/s. Gunakan laju ini untuk menilai performa I/O dan mendeteksi bottleneck yang memengaruhi throughput pekerjaan. |
| Network Traffic | Data yang ditransfer antar compute node melalui virtual private network (VPC). Pantau periode trafik puncak untuk mendeteksi masalah bandwidth sedini mungkin. |
Pemantauan penyimpanan
Tab Storage Monitoring menampilkan metrik untuk sistem file Apsara File Storage NAS (NAS) yang disambungkan ke kluster.
| Metric | Description |
|---|---|
| Storage Space | Penggunaan penyimpanan sistem file NAS. Untuk mencegah kehabisan ruang penyimpanan, atur alert pemantauan, lakukan pembersihan data secara berkala, dan perluas kapasitas secara proaktif. |
| Files | Jumlah total file dalam sistem file NAS. Jumlah file yang besar meningkatkan kompleksitas manajemen dan dapat memengaruhi performa pengambilan. Jika jumlah melebihi ambang batas Anda, hapus file yang tidak diperlukan. |
| IOPS | Rata-rata operasi baca dan tulis per detik selama rentang waktu yang dipilih. Satuan: requests/s. |
| Latency | Latensi rata-rata per operasi baca dan tulis selama rentang waktu yang dipilih. Satuan: milidetik. |
| Throughput | Throughput rata-rata baca dan tulis selama rentang waktu yang dipilih. Satuan: KiB. |
| Metadata QPS | Jumlah rata-rata permintaan metadata per detik selama rentang waktu yang dipilih. Satuan: requests/s. |
Untuk informasi lebih lanjut tentang metrik penyimpanan NAS, lihat Performance monitoring dan FAQ about the performance of NAS file systems.
Pemantauan pekerjaan
Tab Job Monitoring menampilkan konsumsi sumber daya pekerjaan dan kesehatan antrian. Filter berdasarkan kluster, antrian, proyek, atau pengguna.
| Metric | Description |
|---|---|
| Jobs | Jumlah pekerjaan yang sedang berjalan. Lonjakan jumlah pekerjaan berjalan relatif terhadap sumber daya yang tersedia dapat menyebabkan konflik sumber daya. Optimalkan penjadwalan atau hapus pekerjaan yang tidak diperlukan untuk meningkatkan throughput. |
| Total Cores Required by Enqueued Jobs | Total core CPU yang diminta oleh pekerjaan yang sedang menunggu dalam antrian. Jika jumlah ini melebihi jumlah core yang tersedia, pekerjaan dalam antrian akan menunggu lebih lama. Tambahkan core atau sesuaikan prioritas pekerjaan untuk mengurangi waktu tunggu. |
| Job Wait Duration | Waktu rata-rata yang dihabiskan pekerjaan dalam antrian. Durasi tunggu yang meningkat menandakan adanya konflik sumber daya. Berikan prioritas pada pekerjaan penting untuk meningkatkan utilisasi keseluruhan. |
| Total Cores Used by Running Jobs | Total core CPU yang digunakan oleh pekerjaan yang sedang berjalan. Gunakan metrik ini bersama CPU Utilization untuk memastikan bahwa core yang dialokasikan benar-benar digunakan secara aktif. |
| Job CPU Utilization | Rasio core CPU yang benar-benar digunakan oleh pekerjaan terhadap core CPU yang diminta. Utilisasi rendah mungkin mengindikasikan konfigurasi pekerjaan yang tidak efisien atau anomali beban kerja. Tinjau spesifikasi pekerjaan dan pola beban kerja untuk meningkatkan efisiensi. |
| Job Memory Usage | Rasio memori yang benar-benar digunakan oleh pekerjaan terhadap memori yang diminta. Untuk mencegah luapan buffer atau kekurangan memori akibat penggunaan memori yang terlalu tinggi, sesuaikan permintaan memori atau tingkatkan spesifikasi node agar sesuai dengan penggunaan aktual. |