Topik ini menjelaskan cara membangun danau data terpadu aliran menggunakan Realtime Compute for Apache Flink, Apache Paimon, dan StarRocks.
Informasi latar belakang
Seiring dengan meningkatnya digitalisasi masyarakat, bisnis memerlukan akses data yang lebih cepat. Gudang data offline tradisional menggunakan pekerjaan terjadwal untuk menggabungkan perubahan baru dari periode sebelumnya ke dalam lapisan gudang data hierarkis, seperti Operational Data Store (ODS), Data Warehouse Detail (DWD), Data Warehouse Summary (DWS), dan Application Data Store (ADS). Namun, pendekatan ini memiliki dua kelemahan utama: latensi tinggi dan biaya tinggi. Pekerjaan offline biasanya dijalankan setiap jam atau harian, sehingga konsumen data hanya dapat melihat data dari jam atau hari sebelumnya. Selain itu, pembaruan data sering kali menimpa seluruh partisi. Proses ini memerlukan pembacaan ulang data asli dalam partisi untuk menggabungkannya dengan perubahan baru dan menghasilkan hasil baru.
Membangun danau data terpadu aliran dengan Realtime Compute for Apache Flink dan Apache Paimon mengatasi masalah tersebut. Kemampuan komputasi real-time Flink memungkinkan data mengalir antar lapisan gudang data secara real time. Kemampuan pembaruan efisien Paimon mengirimkan perubahan data ke konsumen hilir dengan latensi tingkat menit. Dengan demikian, danau data terpadu aliran menawarkan keunggulan baik dari segi latensi maupun biaya.
Untuk informasi lebih lanjut tentang fitur-fitur Apache Paimon, lihat Fitur dan kunjungi situs resmi Apache Paimon.
Arsitektur dan manfaat
Arsitektur
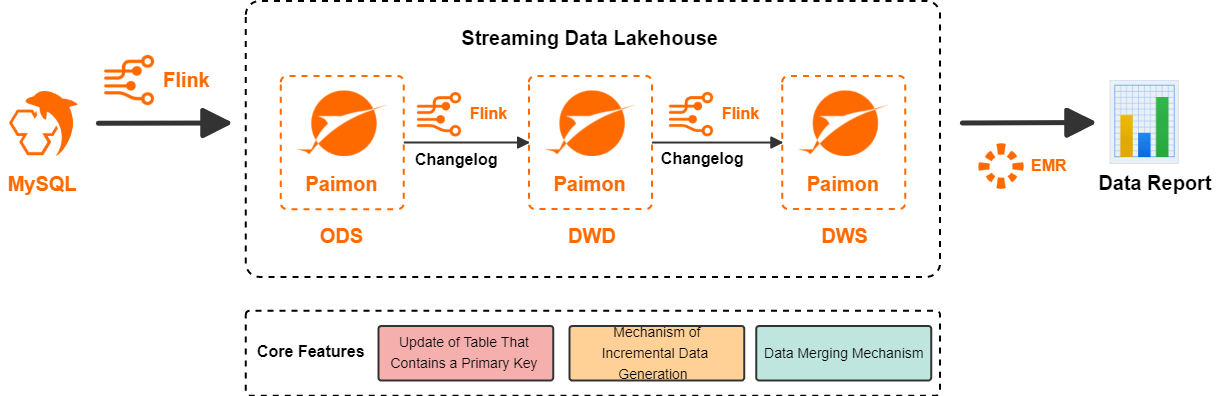
Realtime Compute for Apache Flink adalah mesin komputasi aliran yang andal yang secara efisien memproses sejumlah besar data real-time. Apache Paimon adalah format penyimpanan data lake aliran dan batch terpadu yang mendukung pembaruan throughput tinggi dan kueri latensi rendah. Paimon terintegrasi erat dengan Flink untuk menyediakan solusi danau data terpadu aliran all-in-one. Arsitektur danau data terpadu aliran yang dibangun dengan Flink dan Paimon adalah sebagai berikut:
Flink menulis data dari sumber data ke Paimon untuk membuat lapisan ODS.
Flink berlangganan changelog pada lapisan ODS untuk diproses, lalu menulis ulang data ke Paimon untuk membuat lapisan DWD.
Flink berlangganan changelog pada lapisan DWD untuk diproses, lalu menulis ulang data ke Paimon untuk membuat lapisan DWS.
Akhirnya, StarRocks pada platform big data open source EMR membaca tabel eksternal Paimon untuk mendukung kueri aplikasi.
Manfaat
Solusi ini memberikan manfaat berikut:
Setiap lapisan Paimon dapat mengirimkan perubahan ke hilir dengan latensi tingkat menit. Hal ini mengurangi latensi gudang data offline tradisional dari hitungan jam atau hari menjadi hitungan menit.
Setiap lapisan Paimon dapat langsung menerima data perubahan tanpa menimpa partisi. Hal ini secara signifikan mengurangi biaya pembaruan dan koreksi data pada gudang data offline tradisional. Solusi ini juga mengatasi kesulitan dalam mengkueri, memperbarui, atau mengoreksi data pada lapisan antara.
Modelnya terpadu dan arsitekturnya disederhanakan. Logika pipeline ekstrak, transformasi, dan muat (ETL) diimplementasikan menggunakan Flink SQL. Data pada lapisan ODS, DWD, dan DWS disimpan secara seragam dalam format Paimon. Hal ini mengurangi kompleksitas arsitektur dan meningkatkan efisiensi pemrosesan data.
Solusi ini bergantung pada tiga kemampuan inti Paimon, seperti yang ditunjukkan dalam tabel berikut.
Kemampuan inti Paimon | Detail |
Pembaruan tabel kunci primer | Paimon menggunakan struktur data Log-Structured Merge-tree (LSM tree) pada lapisan dasar untuk mencapai pembaruan data yang efisien. Untuk informasi lebih lanjut tentang tabel kunci primer Paimon dan struktur data dasarnya, lihat Tabel Kunci Primer dan Tata Letak File. |
Produsen changelog | Paimon dapat menghasilkan changelog lengkap untuk aliran data masukan apa pun. Semua data `update_after` memiliki data `update_before` yang sesuai. Hal ini memastikan bahwa perubahan data sepenuhnya diteruskan ke hilir. Untuk informasi lebih lanjut, lihat Mekanisme produksi changelog. |
Mesin penggabungan | Ketika tabel kunci primer Paimon menerima beberapa catatan dengan kunci primer yang sama, tabel sink menggabungkannya menjadi satu catatan untuk menjaga keunikan kunci primer. Paimon mendukung berbagai perilaku penggabungan, seperti deduplikasi, pembaruan parsial, dan pra-agregasi. Untuk informasi lebih lanjut, lihat Mekanisme penggabungan data. |
Skenario
Topik ini menggunakan platform e-commerce sebagai contoh untuk menunjukkan cara membangun danau data terpadu aliran guna memproses dan membersihkan data serta mendukung kueri data dari aplikasi lapisan atas. Danau data terpadu aliran ini menerapkan pelapisan dan penggunaan ulang data. Solusi ini mendukung berbagai skenario bisnis, seperti kueri laporan untuk dasbor transaksi, analitik data perilaku, penandaan persona pengguna, dan rekomendasi personalisasi.
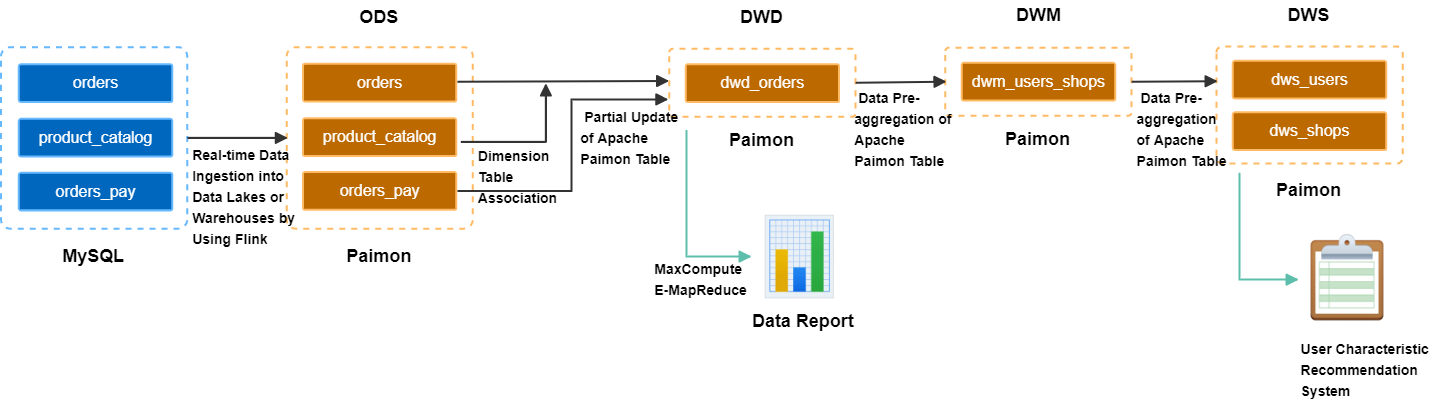
Membangun lapisan ODS: Ingesti data dari database bisnis ke gudang data secara real time.
Database MySQL berisi tiga tabel bisnis: `orders`, `orders_pay`, dan `product_catalog`. Flink menulis data dari tabel-tabel ini ke OSS secara real time dan menyimpannya dalam format Paimon untuk membuat lapisan ODS.Membangun lapisan DWD: Membuat tabel lebar berbasis topik.
Gunakan mekanisme penggabungan pembaruan parsial Paimon untuk memperlebar tabel `orders`, `product_catalog`, dan `orders_pay`. Hal ini menghasilkan tabel lebar lapisan DWD dan menghasilkan changelog dengan latensi tingkat menit.Membangun lapisan DWS: Menghitung metrik.
Flink mengonsumsi changelog tabel lebar secara real time. Flink menggunakan mekanisme penggabungan agregasi Paimon untuk menghasilkan tabel antara `dwm_users_shops` (agregasi pengguna-pedagang) pada lapisan DWM. Akhirnya, Flink menghasilkan tabel `dws_users` (metrik agregasi pengguna) dan `dws_shops` (metrik agregasi pedagang) pada lapisan DWS.
Prasyarat
Data Lake Formation (DLF) diaktifkan. Gunakan DLF 2.5 sebagai layanan penyimpanan. Untuk informasi lebih lanjut, lihat Memulai dengan DLF.
Flink yang sepenuhnya dikelola diaktifkan. Untuk informasi lebih lanjut, lihat Aktifkan Realtime Compute for Apache Flink.
StarRocks pada EMR diaktifkan. Untuk informasi lebih lanjut, lihat Cepat menggunakan instance terpisah komputasi-penyimpanan.
Instans StarRocks dan DLF harus berada di Wilayah yang sama dengan ruang kerja Flink.
Batasan
Hanya Realtime Compute for Apache Flink yang menggunakan Ververica Runtime (VVR) 11.1.0 atau yang lebih baru yang mendukung solusi danau data terpadu aliran ini.
Membangun data lakehouse streaming
Siapkan sumber data CDC MySQL
Contoh ini menggunakan instans ApsaraDB RDS for MySQL. Buat database bernama `order_dw` dan tiga tabel bisnis beserta datanya.
Buat instansi ApsaraDB RDS for MySQL.
PentingInstans ApsaraDB RDS for MySQL harus berada di VPC yang sama dengan ruang kerja Flink. Jika tidak berada di VPC yang sama, lihat Bagaimana cara mengakses layanan lain lintas VPC?
Buat database bernama `order_dw`. Buat akun istimewa atau akun standar dengan izin baca dan tulis pada database `order_dw`.
Buat tiga tabel dan masukkan data.
CREATE TABLE `orders` ( order_id bigint not null primary key, user_id varchar(50) not null, shop_id bigint not null, product_id bigint not null, buy_fee bigint not null, create_time timestamp not null, update_time timestamp not null default now(), state int not null ); CREATE TABLE `orders_pay` ( pay_id bigint not null primary key, order_id bigint not null, pay_platform int not null, create_time timestamp not null ); CREATE TABLE `product_catalog` ( product_id bigint not null primary key, catalog_name varchar(50) not null ); -- Persiapkan data. INSERT INTO product_catalog VALUES(1, 'phone_aaa'),(2, 'phone_bbb'),(3, 'phone_ccc'),(4, 'phone_ddd'),(5, 'phone_eee'); INSERT INTO orders VALUES (100001, 'user_001', 12345, 1, 5000, '2023-02-15 16:40:56', '2023-02-15 18:42:56', 1), (100002, 'user_002', 12346, 2, 4000, '2023-02-15 15:40:56', '2023-02-15 18:42:56', 1), (100003, 'user_003', 12347, 3, 3000, '2023-02-15 14:40:56', '2023-02-15 18:42:56', 1), (100004, 'user_001', 12347, 4, 2000, '2023-02-15 13:40:56', '2023-02-15 18:42:56', 1), (100005, 'user_002', 12348, 5, 1000, '2023-02-15 12:40:56', '2023-02-15 18:42:56', 1), (100006, 'user_001', 12348, 1, 1000, '2023-02-15 11:40:56', '2023-02-15 18:42:56', 1), (100007, 'user_003', 12347, 4, 2000, '2023-02-15 10:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2001, 100001, 1, '2023-02-15 17:40:56'), (2002, 100002, 1, '2023-02-15 17:40:56'), (2003, 100003, 0, '2023-02-15 17:40:56'), (2004, 100004, 0, '2023-02-15 17:40:56'), (2005, 100005, 0, '2023-02-15 18:40:56'), (2006, 100006, 0, '2023-02-15 18:40:56'), (2007, 100007, 0, '2023-02-15 18:40:56');
Kelola metadata
Buat katalog Paimon
Masuk ke Konsol Realtime Compute for Apache Flink.
Pada panel navigasi di sebelah kiri, klik Catalogs, lalu klik Create Catalog.
Pada tab Built-in Catalog, klik Apache Paimon, lalu klik Next.
Konfigurasikan parameter berikut, pilih DLF sebagai jenis penyimpanan, lalu klik OK.
Parameter
Deskripsi
Wajib
Catatan:
metastore
Jenis metastore.
Ya
Dalam contoh ini, pilih dlf.
catalog name
Nama katalog data DLF.
PentingJika Anda menggunakan Pengguna Resource Access Management (RAM) atau peran, pastikan Anda memiliki izin baca dan tulis pada DLF. Untuk informasi lebih lanjut, lihat Manajemen otorisasi.
Ya
Gunakan DLF 2.5. Anda tidak perlu memasukkan Pasangan Kunci Akses. Anda dapat memilih katalog data DLF yang sudah ada. Untuk informasi lebih lanjut tentang cara membuat katalog data, lihat Katalog Data.
Dalam contoh ini, pilih katalog data bernama paimoncatalog.
Buat database `order_dw` dalam katalog data untuk menyinkronkan semua data tabel dari database `order_dw` di MySQL.
Pada panel navigasi kiri, pilih dan klik New untuk membuat kueri sementara.
-- Gunakan sumber data paimoncatalog. USE CATALOG paimoncatalog; -- Buat database order_dw. CREATE DATABASE order_dw;Pesan
Pernyataan berikut telah berhasil dieksekusi!menunjukkan bahwa database telah dibuat.
Untuk informasi lebih lanjut tentang cara menggunakan katalog Paimon, lihat Kelola katalog Paimon.
Buat katalog MySQL
Pada halaman Catalogs, klik Create Catalog.
Pada tab Built-in Catalog, klik MySQL, lalu klik Next.
Untuk membuat katalog MySQL bernama mysqlcatalog, konfigurasikan parameter berikut dan klik OK.
Parameter
Deskripsi
Wajib
Catatan:
nama katalog
Nama katalog.
Ya
Masukkan nama kustom. Contoh ini menggunakan mysqlcatalog.
hostname
Alamat IP atau hostname database MySQL.
Ya
Untuk informasi lebih lanjut, lihat Lihat dan kelola titik akhir serta port instans. Karena instans ApsaraDB RDS for MySQL dan ruang kerja Flink yang sepenuhnya dikelola berada di VPC yang sama, masukkan Titik akhir internal.
port
Nomor port layanan database MySQL. Nilai default adalah 3306.
Tidak
Untuk informasi lebih lanjut, lihat Lihat dan kelola titik akhir dan port instansi.
default-database
Nama database MySQL default.
Ya
Masukkan nama database yang akan disinkronkan, `order_dw`.
username
Nama pengguna untuk layanan database MySQL.
Ya
Ini adalah akun yang dibuat di bagian Persiapkan sumber data CDC MySQL.
password
Kata sandi untuk layanan database MySQL.
Ya
Ini adalah kata sandi yang dibuat di bagian Persiapkan sumber data CDC MySQL.
Bangun lapisan ODS: Ingesti data dari database bisnis ke gudang data secara real time
Gunakan Flink CDC untuk menyinkronkan data dari MySQL ke Paimon melalui pekerjaan ingesti data YAML. Hal ini membangun lapisan ODS dalam satu langkah.
Buat dan mulai pekerjaan ingesti data YAML.
Di Konsol Realtime Compute for Apache Flink, buka halaman dan buat draf YAML kosong bernama ods.
Salin kode berikut ke editor. Pastikan untuk memodifikasi parameter seperti username dan password.
source: type: mysql name: MySQL Source hostname: rm-bp1e********566g.mysql.rds.aliyuncs.com port: 3306 username: ${secret_values.username} password: ${secret_values.password} tables: order_dw.\.* # Gunakan ekspresi reguler untuk membaca semua tabel dalam database order_dw. sink: type: paimon name: Paimon Sink catalog.properties.metastore: rest catalog.properties.uri: http://cn-beijing-vpc.dlf.aliyuncs.com catalog.properties.warehouse: paimoncatalog catalog.properties.token.provider: dlf pipeline: name: MySQL to Paimon PipelineParameter
Deskripsi
Wajib
Contoh
catalog.properties.metastoreJenis Metastore. Tetapkan ke `rest`.
Ya
rest
catalog.properties.token.providerPenyedia token. Tetapkan ke `dlf`.
Ya
dlf
catalog.properties.uriURI untuk mengakses Server Katalog Rest DLF. Formatnya adalah
http://[region-id]-vpc.dlf.aliyuncs.com. Untuk informasi lebih lanjut, lihat ID Wilayah di Titik akhir layanan.Ya
http://cn-beijing-vpc.dlf.aliyuncs.com
catalog.properties.warehouseNama Katalog DLF.
Ya
paimoncatalog
Untuk informasi lebih lanjut tentang cara mengoptimalkan kinerja penulisan Paimon, lihat Optimasi kinerja Paimon.
Di pojok kanan atas, klik Deploy.
Buka . Temukan pekerjaan `ods` yang baru saja Anda sebarkan. Di kolom Actions, klik Start dan pilih Start Without Initial State. Untuk informasi lebih lanjut tentang konfigurasi startup pekerjaan, lihat Mulai pekerjaan.
Lihat data dari tiga tabel yang disinkronkan dari MySQL ke Paimon.
Di Konsol Realtime Compute for Apache Flink, buka halaman . Pada tab Query Scripts, salin kode berikut ke skrip kueri. Pilih potongan kode dan klik Run di pojok kanan atas.
SELECT * FROM paimoncatalog.order_dw.orders ORDER BY order_id;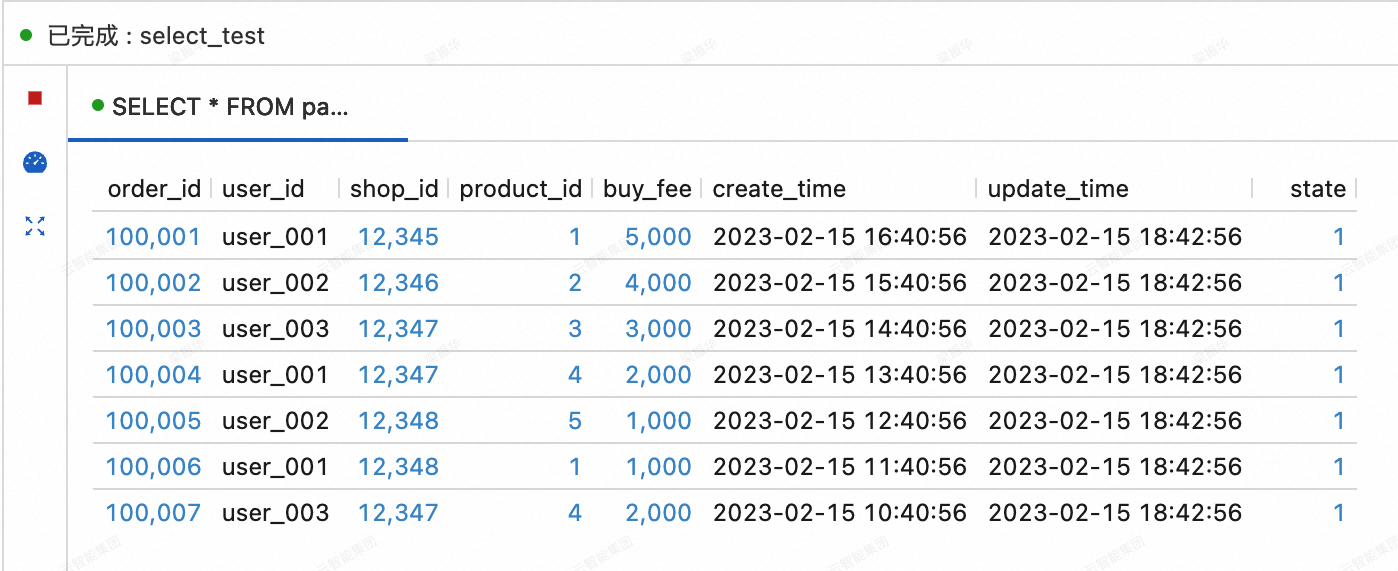
Bangun lapisan DWD: Buat tabel lebar berbasis topik
Buat tabel lebar DWD layer Paimon dwd_orders
Di Konsol Realtime Compute for Apache Flink, buka halaman . Pada tab Query Scripts, salin kode berikut ke skrip kueri. Pilih potongan kode dan klik Run di pojok kanan atas.
CREATE TABLE paimoncatalog.order_dw.dwd_orders ( order_id BIGINT, order_user_id STRING, order_shop_id BIGINT, order_product_id BIGINT, order_product_catalog_name STRING, order_fee BIGINT, order_create_time TIMESTAMP, order_update_time TIMESTAMP, order_state INT, pay_id BIGINT, pay_platform INT COMMENT 'platform 0: phone, 1: pc', pay_create_time TIMESTAMP, PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( 'merge-engine' = 'partial-update', -- Gunakan mesin penggabungan pembaruan parsial untuk menghasilkan tabel lebar. 'changelog-producer' = 'lookup' -- Gunakan produsen changelog lookup untuk menghasilkan changelog dengan latensi rendah. );Pesan
Kueri telah dieksekusimenunjukkan bahwa tabel telah dibuat.Konsumsi changelog tabel orders dan orders_pay lapisan ODS secara real time
Di Konsol Realtime Compute for Apache Flink, buka halaman . Buat pekerjaan streaming SQL baru bernama `dwd`, lalu salin kode berikut ke editor SQL. Kemudian, Deploy pekerjaan tersebut dan Start tanpa status awal.
Pekerjaan SQL ini menggabungkan tabel `orders` dengan tabel `product_catalog`. Hasil gabungan dan tabel `orders_pay` ditulis ke tabel `dwd_orders`. Mesin penggabungan pembaruan parsial Paimon memperlebar data dari tabel `orders` dan `orders_pay` yang memiliki `order_id` yang sama.
SET 'execution.checkpointing.max-concurrent-checkpoints' = '3'; SET 'table.exec.sink.upsert-materialize' = 'NONE'; SET 'execution.checkpointing.interval' = '10s'; SET 'execution.checkpointing.min-pause' = '10s'; -- Paimon saat ini tidak mendukung beberapa pernyataan INSERT ke tabel yang sama dalam satu pekerjaan. Oleh karena itu, gunakan UNION ALL. INSERT INTO paimoncatalog.order_dw.dwd_orders SELECT o.order_id, o.user_id, o.shop_id, o.product_id, dim.catalog_name, o.buy_fee, o.create_time, o.update_time, o.state, NULL, NULL, NULL FROM paimoncatalog.order_dw.orders o LEFT JOIN paimoncatalog.order_dw.product_catalog FOR SYSTEM_TIME AS OF proctime() AS dim ON o.product_id = dim.product_id UNION ALL SELECT order_id, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, pay_id, pay_platform, create_time FROM paimoncatalog.order_dw.orders_pay;Lihat data tabel lebar dwd_orders
Di Konsol Realtime Compute for Apache Flink, buka halaman . Pada tab Query Scripts, salin kode berikut ke skrip kueri. Pilih potongan kode dan klik Run di pojok kanan atas.
SELECT * FROM paimoncatalog.order_dw.dwd_orders ORDER BY order_id;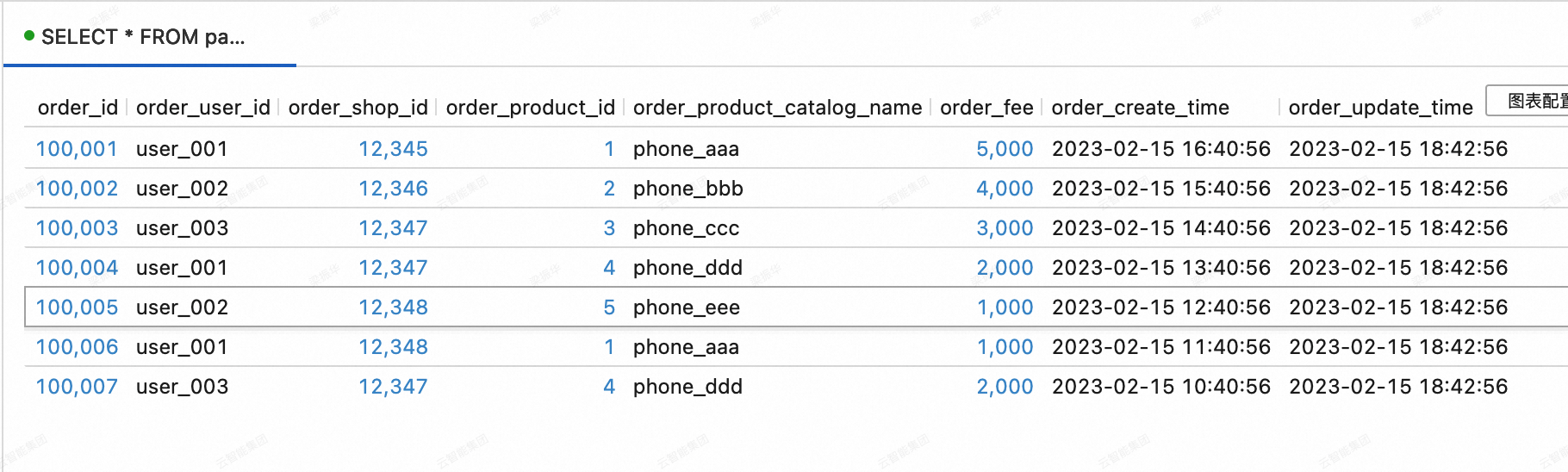
Bangun lapisan DWS: Hitung metrik
Buat tabel agregasi lapisan DWS dws_users dan dws_shops
Di Konsol Realtime Compute for Apache Flink, buka halaman . Pada tab Query Scripts, salin kode berikut ke skrip kueri, pilih potongan kode, lalu klik Run di pojok kanan atas.
-- Tabel metrik agregasi dimensi pengguna. CREATE TABLE paimoncatalog.order_dw.dws_users ( user_id STRING, ds STRING, payed_buy_fee_sum BIGINT COMMENT 'Total jumlah pembayaran yang diselesaikan pada hari tersebut', PRIMARY KEY (user_id, ds) NOT ENFORCED ) WITH ( 'merge-engine' = 'aggregation', -- Gunakan mesin penggabungan agregasi untuk menghasilkan tabel agregasi. 'fields.payed_buy_fee_sum.aggregate-function' = 'sum' -- Jumlahkan data payed_buy_fee_sum untuk menghasilkan hasil agregasi. -- Karena tabel dws_users tidak lagi dikonsumsi secara streaming di hilir, Anda tidak perlu menentukan produsen changelog. ); -- Tabel metrik agregasi dimensi pedagang. CREATE TABLE paimoncatalog.order_dw.dws_shops ( shop_id BIGINT, ds STRING, payed_buy_fee_sum BIGINT COMMENT 'Total jumlah pembayaran yang diselesaikan pada hari tersebut', uv BIGINT COMMENT 'Total jumlah pengguna pembeli unik pada hari tersebut', pv BIGINT COMMENT 'Total jumlah pembelian oleh pengguna pada hari tersebut', PRIMARY KEY (shop_id, ds) NOT ENFORCED ) WITH ( 'merge-engine' = 'aggregation', -- Gunakan mesin penggabungan agregasi untuk menghasilkan tabel agregasi. 'fields.payed_buy_fee_sum.aggregate-function' = 'sum', -- Jumlahkan data payed_buy_fee_sum untuk menghasilkan hasil agregasi. 'fields.uv.aggregate-function' = 'sum', -- Jumlahkan data uv untuk menghasilkan hasil agregasi. 'fields.pv.aggregate-function' = 'sum' -- Jumlahkan data pv untuk menghasilkan hasil agregasi. -- Karena tabel dws_shops tidak lagi dikonsumsi secara streaming di hilir, Anda tidak perlu menentukan produsen changelog. ); -- Untuk menghitung kedua tabel agregasi dari perspektif pengguna dan pedagang, buat tabel antara dengan pengguna + pedagang sebagai kunci primer. CREATE TABLE paimoncatalog.order_dw.dwm_users_shops ( user_id STRING, shop_id BIGINT, ds STRING, payed_buy_fee_sum BIGINT COMMENT 'Total jumlah yang dibayarkan pengguna kepada pedagang pada hari tersebut', pv BIGINT COMMENT 'Jumlah pembelian yang dilakukan pengguna kepada pedagang pada hari tersebut', PRIMARY KEY (user_id, shop_id, ds) NOT ENFORCED ) WITH ( 'merge-engine' = 'aggregation', -- Gunakan mesin penggabungan agregasi untuk menghasilkan tabel agregasi. 'fields.payed_buy_fee_sum.aggregate-function' = 'sum', -- Jumlahkan data payed_buy_fee_sum untuk menghasilkan hasil agregasi. 'fields.pv.aggregate-function' = 'sum', -- Jumlahkan data pv untuk menghasilkan hasil agregasi. 'changelog-producer' = 'lookup', -- Gunakan produsen changelog lookup untuk menghasilkan changelog dengan latensi rendah. -- Tabel antara pada lapisan DWM umumnya tidak dikueri langsung oleh aplikasi lapisan atas, sehingga Anda dapat mengoptimalkan kinerja penulisan. 'file.format' = 'avro', -- Format penyimpanan baris avro memberikan kinerja penulisan yang lebih efisien. 'metadata.stats-mode' = 'none' -- Mengabaikan informasi statistik meningkatkan biaya kueri OLAP (tanpa efek pada pemrosesan aliran berkelanjutan), tetapi membuat kinerja penulisan lebih efisien. );Pesan
Kueri telah dieksekusimenunjukkan bahwa tabel telah dibuat.Konsumsi changelog tabel dwd_orders lapisan DWD
Di Konsol Realtime Compute for Apache Flink, buka tab . Buat pekerjaan streaming SQL bernama `dwm`. Salin kode berikut ke editor SQL. Kemudian, Deploy dan Start pekerjaan tanpa status awal.
Pekerjaan SQL ini menulis data dari tabel `dwd_orders` ke tabel `dwm_users_shops`. Pekerjaan ini menggunakan mesin penggabungan pra-agregasi Paimon untuk secara otomatis menjumlahkan `order_fee` guna menghitung total pengeluaran pengguna di pedagang tersebut. Pekerjaan ini juga menjumlahkan `1` untuk menghitung jumlah kali pengguna melakukan pembelian dari pedagang tersebut.
SET 'execution.checkpointing.max-concurrent-checkpoints' = '3'; SET 'table.exec.sink.upsert-materialize' = 'NONE'; SET 'execution.checkpointing.interval' = '10s'; SET 'execution.checkpointing.min-pause' = '10s'; INSERT INTO paimoncatalog.order_dw.dwm_users_shops SELECT order_user_id, order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds, order_fee, 1 -- Satu rekaman input mewakili satu pembelian. FROM paimoncatalog.order_dw.dwd_orders WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL;Konsumsi changelog tabel dwm_users_shops lapisan DWM secara real time
Di Konsol Realtime Compute for Apache Flink, buka halaman . Buat pekerjaan streaming SQL baru bernama `dws`. Salin kode berikut ke editor SQL. Kemudian, Deploy dan Start pekerjaan tanpa status awal.
Pekerjaan SQL ini menulis data dari tabel `dwm_users_shops` ke tabel `dws_users` dan `dws_shops`. Pekerjaan ini menggunakan mesin penggabungan pra-agregasi Paimon untuk menghitung total pengeluaran setiap pengguna (`payed_buy_fee_sum`) dalam tabel `dws_users`. Dalam tabel `dws_shops`, pekerjaan ini menghitung total pendapatan pedagang (`payed_buy_fee_sum`), jumlah pengguna pembeli dengan menjumlahkan `1`, dan total jumlah pembelian (`pv`).
SET 'execution.checkpointing.max-concurrent-checkpoints' = '3'; SET 'table.exec.sink.upsert-materialize' = 'NONE'; SET 'execution.checkpointing.interval' = '10s'; SET 'execution.checkpointing.min-pause' = '10s'; -- Berbeda dengan DWD, setiap pernyataan INSERT di sini menulis ke tabel Paimon yang berbeda, sehingga dapat berada dalam satu pekerjaan yang sama. BEGIN STATEMENT SET; INSERT INTO paimoncatalog.order_dw.dws_users SELECT user_id, ds, payed_buy_fee_sum FROM paimoncatalog.order_dw.dwm_users_shops; -- Dengan pedagang sebagai kunci primer, beberapa pedagang populer mungkin memiliki data jauh lebih banyak daripada yang lain. -- Oleh karena itu, gunakan penggabungan lokal untuk pra-agregasi di memori sebelum menulis ke Paimon guna mengurangi kesenjangan data. INSERT INTO paimoncatalog.order_dw.dws_shops /*+ OPTIONS('local-merge-buffer-size' = '64mb') */ SELECT shop_id, ds, payed_buy_fee_sum, 1, -- Satu catatan masukan mewakili semua pembelian pengguna di pedagang ini. pv FROM paimoncatalog.order_dw.dwm_users_shops; END;Lihat data dalam tabel dws_users dan dws_shops
Di Konsol Realtime Compute for Apache Flink, buka . Pada tab Query Scripts, salin kode berikut ke editor. Pilih potongan kode dan klik Run di pojok kanan atas.
--Lihat data tabel dws_users SELECT * FROM paimoncatalog.order_dw.dws_users ORDER BY user_id;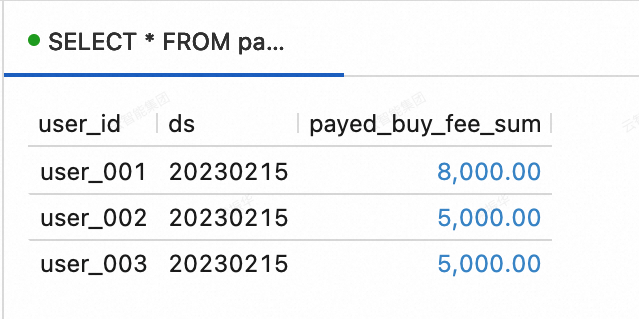
--Lihat data tabel dws_shops SELECT * FROM paimoncatalog.order_dw.dws_shops ORDER BY shop_id;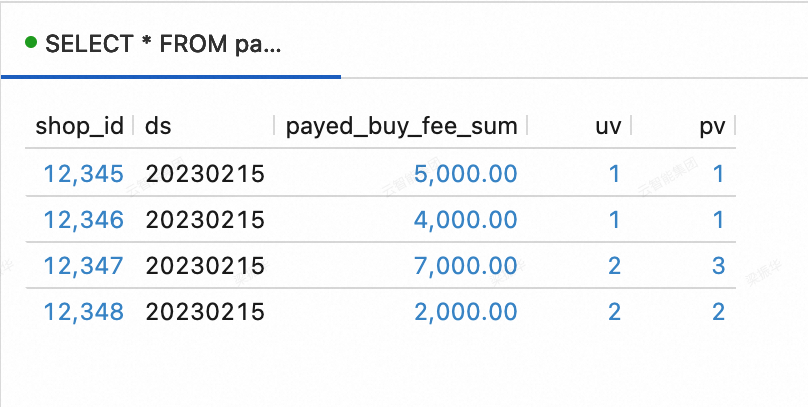
Tangkap perubahan di database bisnis
Sekarang Anda telah membangun danau data terpadu aliran, langkah-langkah berikut menguji kemampuannya untuk menangkap perubahan dari database bisnis.
Masukkan data berikut ke database `order_dw` di MySQL.
INSERT INTO orders VALUES (100008, 'user_001', 12345, 3, 3000, '2023-02-15 17:40:56', '2023-02-15 18:42:56', 1), (100009, 'user_002', 12348, 4, 1000, '2023-02-15 18:40:56', '2023-02-15 19:42:56', 1), (100010, 'user_003', 12348, 2, 2000, '2023-02-15 19:40:56', '2023-02-15 20:42:56', 1); INSERT INTO orders_pay VALUES (2008, 100008, 1, '2023-02-15 18:40:56'), (2009, 100009, 1, '2023-02-15 19:40:56'), (2010, 100010, 0, '2023-02-15 20:40:56');Lihat data dalam tabel dws_users dan dws_shops. Di Konsol Realtime Compute for Apache Flink, buka halaman . Pada tab Query Scripts, salin kode berikut ke skrip kueri. Pilih potongan kode dan klik Run di pojok kanan atas.
tabel dws_users
SELECT * FROM paimoncatalog.order_dw.dws_users ORDER BY user_id;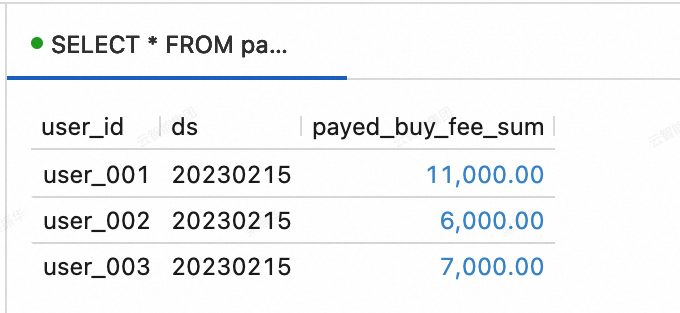
tabel dws_shops
SELECT * FROM paimoncatalog.order_dw.dws_shops ORDER BY shop_id;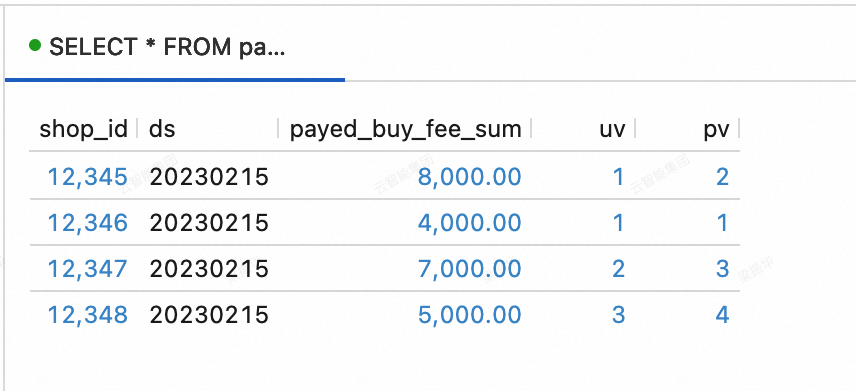
Gunakan data lakehouse streaming
Bagian sebelumnya menunjukkan cara membuat katalog Paimon dan menulis ke tabel Paimon di Flink. Bagian ini menjelaskan skenario analisis data sederhana menggunakan StarRocks setelah danau data terpadu aliran dibangun.
Pertama, masuk ke instans StarRocks dan buat katalog `oss-paimon`. Untuk informasi lebih lanjut, lihat Katalog Paimon.
CREATE EXTERNAL CATALOG paimon_catalog
PROPERTIES
(
'type' = 'paimon',
'paimon.catalog.type' = 'filesystem',
'aliyun.oss.endpoint' = 'oss-cn-beijing-internal.aliyuncs.com',
'paimon.catalog.warehouse' = 'oss://<bucket>/<object>'
);Properti | Wajib | Keterangan |
type | Ya | Jenis sumber data. Tetapkan ke `paimon`. |
paimon.catalog.type | Ya | Jenis metastore yang digunakan oleh Paimon. Contoh ini menggunakan `filesystem` sebagai jenis metastore. |
aliyun.oss.endpoint | Ya | Jika Anda menggunakan OSS atau OSS-HDFS sebagai gudang, Anda harus menentukan titik akhir yang sesuai. |
paimon.catalog.warehouse | Ya | Formatnya adalah oss://<bucket>/<object>, di mana:
Anda dapat melihat nama bucket dan object Anda di Konsol OSS. |
Kueri peringkat
Untuk menganalisis tabel agregasi lapisan DWS, kode contoh berikut menunjukkan cara menggunakan StarRocks untuk mengkueri tiga pedagang teratas dengan jumlah transaksi tertinggi pada 15 Februari 2023.
SELECT ROW_NUMBER() OVER (ORDER BY payed_buy_fee_sum DESC) AS rn, shop_id, payed_buy_fee_sum
FROM dws_shops
WHERE ds = '20230215'
ORDER BY rn LIMIT 3;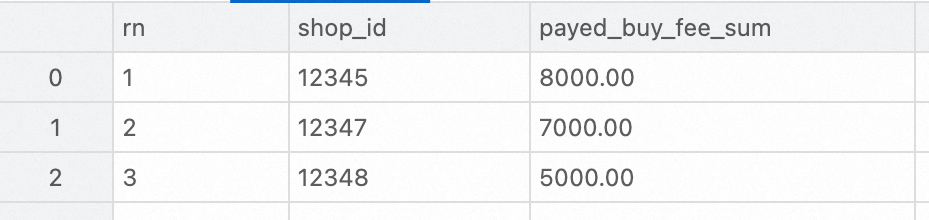
Kueri detail
Untuk menganalisis tabel lebar pada lapisan DWD, kode contoh berikut menunjukkan cara menggunakan StarRocks untuk mengkueri detail pesanan yang dibayar oleh pelanggan pada platform pembayaran tertentu pada Februari 2023:
SELECT * FROM dwd_orders
WHERE order_create_time >= '2023-02-01 00:00:00' AND order_create_time < '2023-03-01 00:00:00'
AND order_user_id = 'user_001'
AND pay_platform = 0
ORDER BY order_create_time;;
Laporan data
Untuk menganalisis tabel lebar pada lapisan DWD, kode contoh berikut menunjukkan cara menggunakan StarRocks untuk mengkueri jumlah total pesanan dan jumlah total pesanan untuk setiap kategori pada Februari 2023:
SELECT
order_create_time AS order_create_date,
order_product_catalog_name,
COUNT(*),
SUM(order_fee)
FROM
dwd_orders
WHERE
order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
GROUP BY
order_create_date, order_product_catalog_name
ORDER BY
order_create_date, order_product_catalog_name;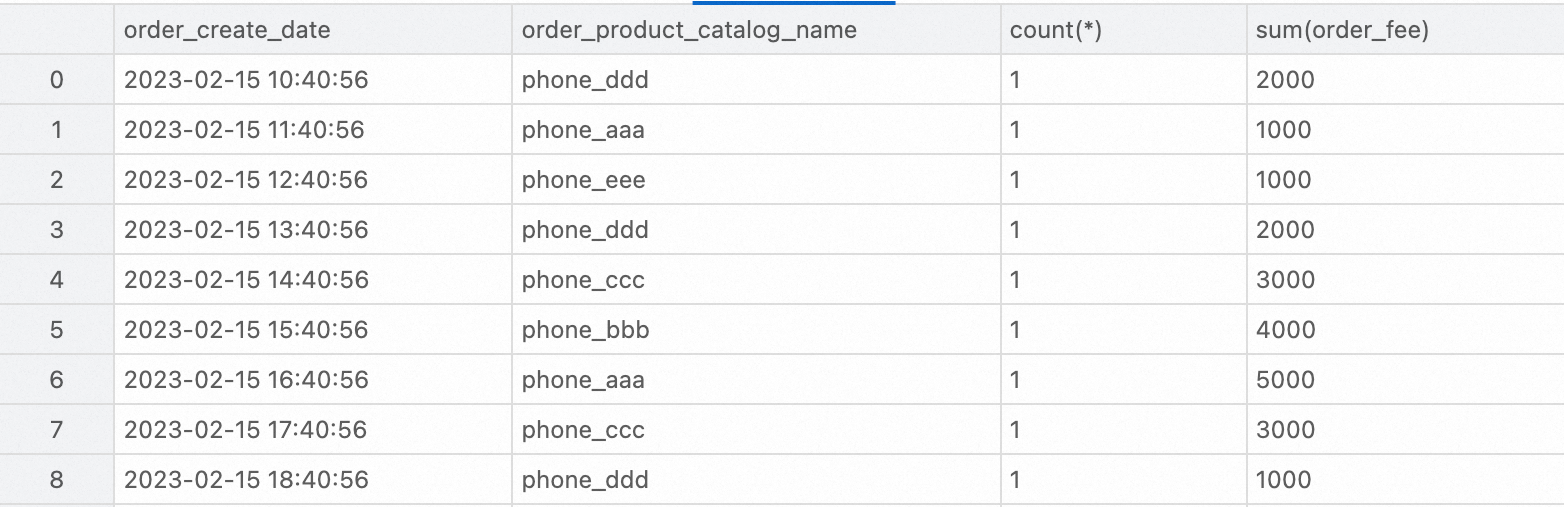
Referensi
Bangun danau data Paimon offline menggunakan kemampuan pemrosesan batch Flink. Untuk informasi lebih lanjut, lihat Memulai dengan pemrosesan batch Flink.