Ikhtisar
Alibaba Cloud OpenLake adalah platform lakehouse terbuka generasi berikutnya yang dirancang untuk skenario integrasi data besar, pencarian, dan artificial intelligence (AI). Platform ini membangun katalog metadata terpadu di atas Data Lake Formation (DLF), menggabungkan data terstruktur, semi-terstruktur, tidak terstruktur, dan data vektor dalam satu arsitektur Agentic Data. Arsitektur ini memungkinkan penggunaan satu salinan data oleh berbagai mesin komputasi, mendukung pencarian global, serta tata kelola end-to-end.
OpenLake mendukung format tabel terbuka populer seperti Paimon, Iceberg, dan Lance, serta menyediakan alur kerja lengkap mulai dari ingesti data, rekayasa fitur, dan vektorisasi hingga Generasi yang Diperkaya dengan Pengambilan Data (RAG), pelatihan model, dan inferensi. Platform ini menawarkan infrastruktur berkinerja tinggi, berbiaya rendah, beravailabilitas tinggi (HA), dan mudah dikelola untuk menangani data multimodal.
Platform ini cocok untuk perusahaan di berbagai industri, termasuk Internet, keuangan, ritel, manufaktur, pendidikan, dan kendaraan otonom, yang perlu memproses data multimodal dan membangun aplikasi AI-native.

Manfaat
Standar terbuka untuk menghilangkan silodata
Platform ini sepenuhnya kompatibel dengan format tabel open source seperti Paimon, Iceberg, dan Lance, serta mendukung standar file terbuka seperti Parquet, ORC, Avro, dan CSV.
Platform ini terintegrasi secara mulus dengan mesin komputasi populer seperti Spark, Flink, Trino, StarRocks, Hologres, dan MaxCompute, sehingga menghindari biaya migrasi data dan konversi format.
Platform ini menggunakan DLF Omni Catalog untuk membuat katalog terpadu bagi lima jenis data: terstruktur, semi-terstruktur, tidak terstruktur, vektor, dan streaming, memungkinkan Anda melakukan ingesti data sekali dan menggunakannya di mana saja.
Kolaborasi mesin berkinerja tinggi untuk komputasi efisien
Berbagai mesin, seperti Spark, Flink, StarRocks, Hologres, dan MaxCompute, dapat mengakses data lake yang sama tanpa salinan berlebih.
Layanan metadata terpadu DLF memastikan konsistensi izin, sinkronisasi skema, dan isolasi transaksi di seluruh mesin.
Pemrosesan batch, komputasi stream, kueri interaktif, dan pelatihan AI berbagi penyimpanan yang sama, sehingga secara signifikan meningkatkan pemanfaatan sumber daya dan efisiensi end-to-end.
Platform ini mendukung beban kerja campuran berkonkurensi tinggi dengan latensi rendah, memenuhi kebutuhan skenario yang memerlukan pemrosesan batch T+1 sekaligus analitik real-time dengan latensi pada tingkat detik.
Pengembangan dan tata kelola terpadu untuk mengurangi kompleksitas
OpenLake Studio, yang terintegrasi dengan DataWorks, menyediakan pengalaman pengembangan terpadu melalui Notebook, IDE SQL, dan penjadwalan visual.
Manajemen terpusat metadata, izin data, alur data, orkestrasi tugas, dan pemantauan kualitas memungkinkan tata kelola sejak awal pengembangan.
Platform ini mendukung penjadwalan tugas berskala besar dan berkonkurensi tinggi untuk memastikan Service-Level Agreement (SLA) dan stabilitas kelas enterprise.
Seluruh pipa data dapat dilacak, diaudit, dan mendukung rollback guna memenuhi persyaratan kepatuhan.
Integrasi Data, Pencarian, dan AI untuk membuka nilai data
Platform ini menggabungkan tabel terstruktur, file tidak terstruktur (seperti gambar, audio, video, dan dokumen), serta data vektor untuk membangun lakehouse multimodal terpadu.
Platform ini secara native mendukung kueri SQL, pencarian teks lengkap (OpenSearch atau Elasticsearch), dan pencarian kemiripan vektor (Milvus atau PgVector).
Platform ini menyediakan pipa data berkualitas tinggi, dapat dicari, dan dapat ditata untuk Generasi yang Diperkaya dengan Pengambilan Data (RAG) Large Language Model (LLM) dan agen cerdas.
Platform ini menyederhanakan seluruh alur kerja mulai dari ingesti data, rekayasa fitur, dan vektorisasi hingga augmentasi pengambilan dan inferensi model, sehingga mempercepat implementasi aplikasi AI.
Fitur utama
Fitur | Deskripsi | Dokumentasi |
Manajemen metadata dan tabel terpadu | Menggunakan DLF untuk mendukung katalog terpadu bagi format seperti Paimon, Iceberg, Lance, dan Parquet. | |
Optimasi biaya penyimpanan | Mengurangi biaya penyimpanan menggunakan tiering cerdas OSS, kompresi, dan kebijakan siklus hidup. | |
Integrasi Real-time antara Data Lake dan Stream | Flink, Streaming Storage Fluss, dan DLF memungkinkan ingesti data dalam hitungan detik dan visibilitas data dalam hitungan menit. | |
Mesin berkinerja tinggi kelas enterprise | Mengintegrasikan mesin cloud-native seperti Serverless Spark, Flink, Hologres, dan MaxCompute. | Apa itu EMR Serverless Spark, Apa itu Realtime Compute for Apache Flink, Apa itu Hologres, Apa itu MaxCompute |
Pengembangan kolaboratif untuk data besar dan AI | OpenLake Studio menggabungkan Notebook, SQL, dan penjadwalan visual. | |
Integrasi Agent dan Copilot | Protokol OpenLake Agent / MCP memungkinkan agen cerdas multimodal mengakses lakehouse secara langsung. |
Solusi arsitektur khas
Solusi 1: Arsitektur lakehouse klasik (Serverless Spark + StarRocks + DLF)
Skenario: Solusi ini terutama untuk pemrosesan batch T+1 dan dirancang untuk skenario analitik batch yang hemat biaya dan sepenuhnya terkelola, seperti laporan, intelijen bisnis, dan persona pengguna.
Komponen: EMR Serverless Spark (pemrosesan batch) + StarRocks (kueri sub-detik) + DLF (metadata terpadu).
Solusi alternatif: AWS Redshift + Glue, Databricks (pemrosesan batch), Hive + Presto.
Manfaat: Mengurangi biaya lebih dari 30%, meningkatkan performa kueri 3 hingga 5 kali lipat, dan sepenuhnya terkelola.
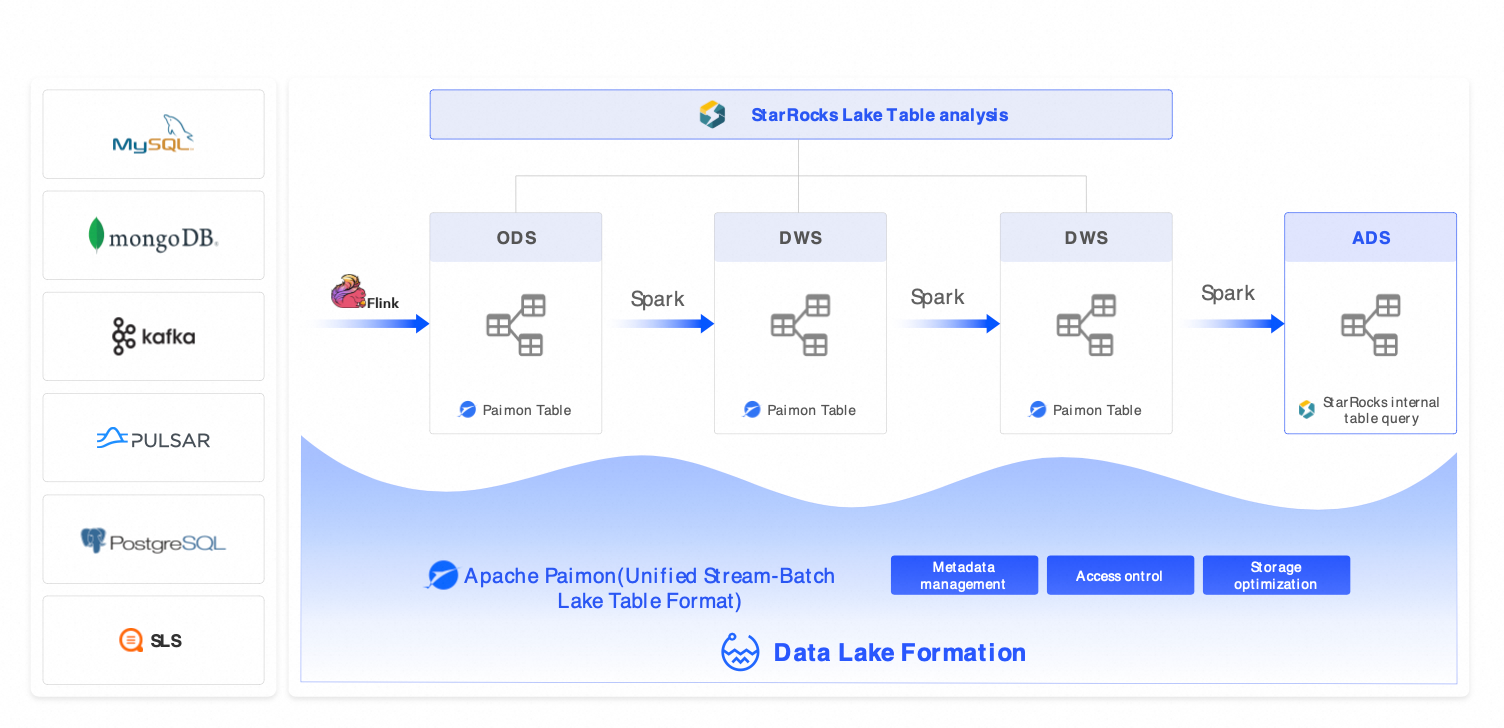
Solusi 2: Arsitektur lakehouse streaming (Flink + Hologres + DLF)
Skenario: Solusi ini untuk analitik near-real-time dengan latensi detik hingga menit, seperti pengendalian risiko real-time, pemantauan performa iklan, dan pemantauan perangkat IoT.
Komponen: Flink (ekstrak, transformasi, dan muat (ETL) streaming) + Hologres (serving real-time) + DLF (kolaborasi lintas mesin).
Solusi alternatif: Kafka + ClickHouse + Hive, AWS Kinesis + Redshift.
Manfaat: Visibilitas data end-to-end dalam waktu kurang dari 10 menit dan latensi kueri kurang dari 1 detik.

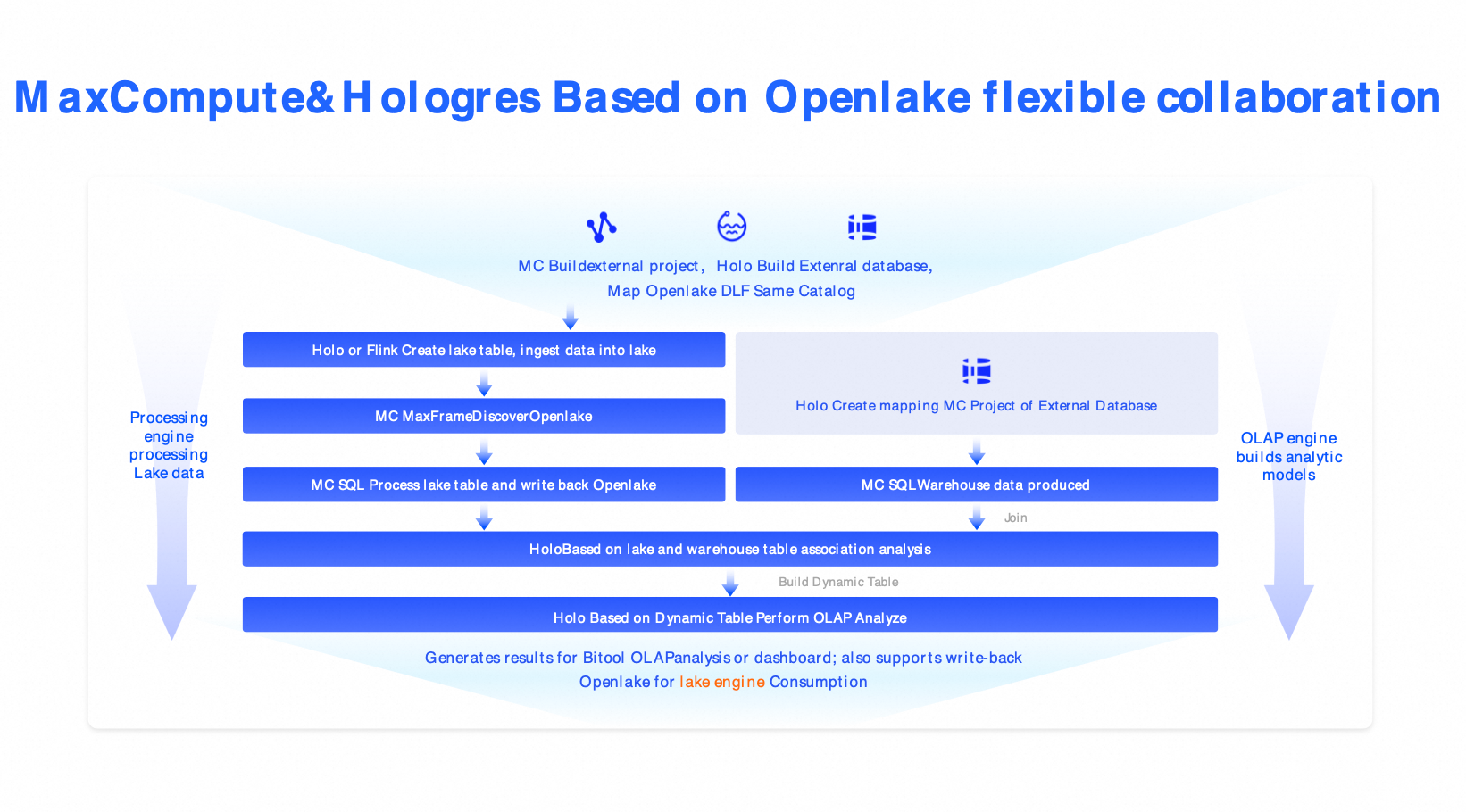
Solusi 3: Arsitektur lakehouse cloud-native (MaxCompute + Hologres + DLF)
Skenario: Solusi ini untuk industri seperti keuangan dan pemerintahan yang memiliki persyaratan ketat terkait keamanan, kepatuhan, dan pemrosesan skala besar.
Komponen: MaxCompute (pemrosesan batch skala petabyte) + Hologres (penulisan milidetik) + DLF (tata kelola).
Solusi alternatif: Snowflake, Azure Synapse, edisi komersial Databricks.
Manfaat: Keamanan kelas enterprise, skalabilitas elastis, RPO=0, dan RTO < 30 menit.
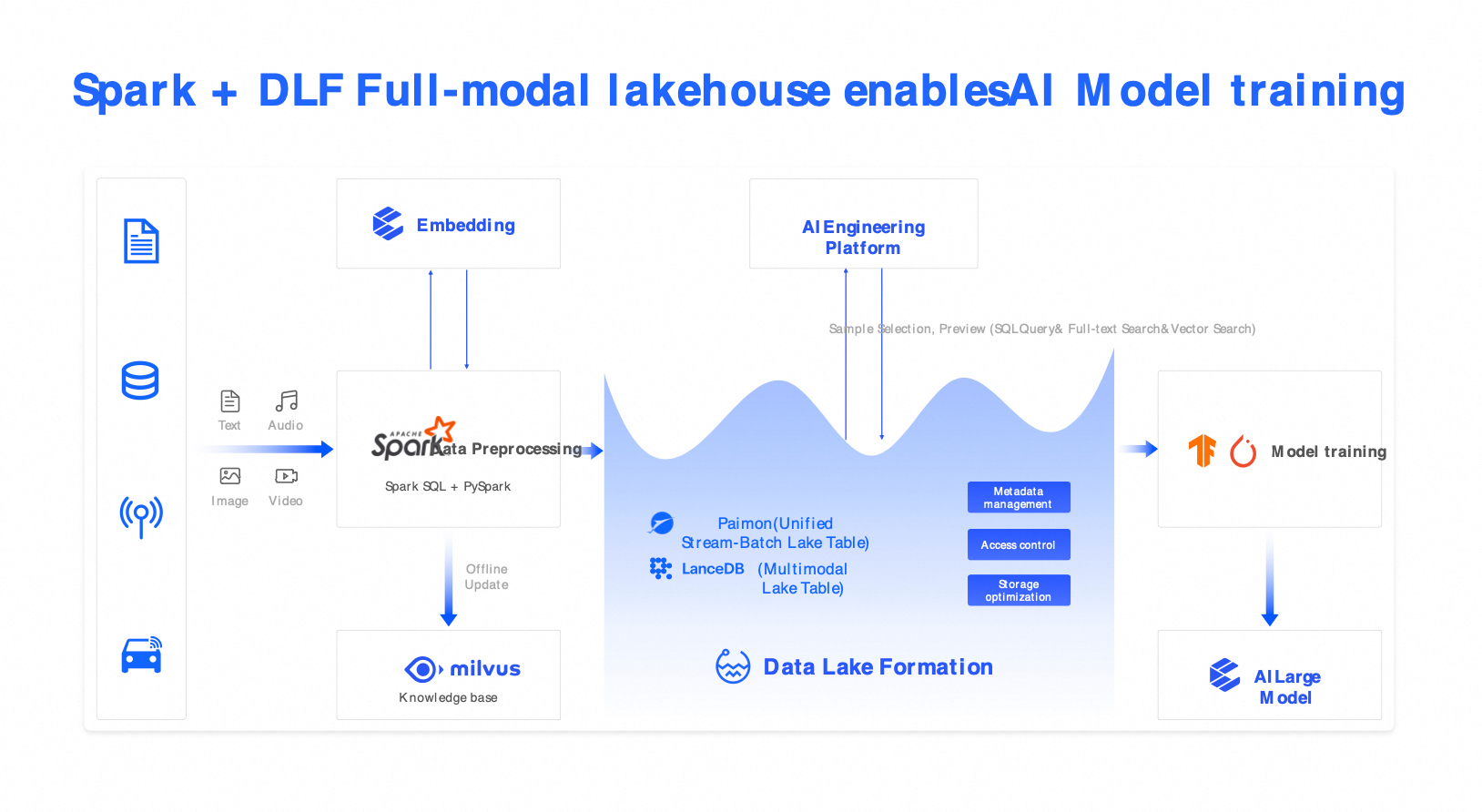
Solusi 4: Lake vektor omni-modal (Spark + Milvus + DLF)
Skenario: Solusi ini untuk pelatihan AI, pencarian semantik multimodal, aplikasi RAG, layanan pelanggan cerdas, dan manajemen data persepsi kendaraan otonom.
Komponen: Spark (pra-pemrosesan multimodal), Milvus (pencarian vektor), dan DLF (katalog terpadu).
Kemampuan: Mendukung pencarian hibrida lintas teks, gambar, audio, dan video menggunakan kueri SQL dan vektor gabungan.
Manfaat: Meningkatkan efisiensi pemilihan sampel hingga 5 kali lipat dan mendukung fine-tuning berkualitas tinggi untuk LLM.
Kasus penggunaan: Pelatihan AI, pencarian semantik multimodal, aplikasi RAG, layanan pelanggan cerdas, dan manajemen data persepsi kendaraan otonom.