Topik ini menjelaskan cara menggunakan node MaxCompute di DataWorks untuk memproses data dari tabel informasi pengguna ods_user_info_d dan tabel log akses ods_raw_log_d guna menghasilkan data profil pengguna. Anda akan mempelajari cara menggunakan DataWorks dan MaxCompute untuk menghitung dan menganalisis data yang telah disinkronkan serta menyelesaikan tugas pemrosesan data sederhana dalam gudang data.
Prasyarat
Sebelum memulai, pastikan Anda telah menyelesaikan langkah-langkah dalam Sinkronisasi data.
1. Bangun pipeline pemrosesan data
Pada langkah Sinkronisasi data, data telah disinkronkan ke MaxCompute. Sekarang Anda harus memproses data tersebut untuk menghasilkan data profil pengguna dasar.
-
Di panel navigasi kiri Data Studio, klik ikon
 untuk membuka halaman Pengembangan Data. Di bagian Project Directory, temukan alur kerja yang telah Anda buat lalu klik untuk membuka kanvas alur kerja.
untuk membuka halaman Pengembangan Data. Di bagian Project Directory, temukan alur kerja yang telah Anda buat lalu klik untuk membuka kanvas alur kerja.Tabel berikut menjelaskan node yang digunakan dalam tutorial ini.
Jenis node
Nama node
Fungsi node
 MaxCompute SQL
MaxCompute SQLdwd_log_info_diMemisahkan data log mentah dari tabel
ods_raw_log_dmenjadi beberapa kolom dalam tabeldwd_log_info_dimenggunakan fungsi bawaan dan user-defined function (UDF) bernamagetregion.MaxCompute SQLdws_user_info_all_diMenggabungkan data dari tabel informasi pengguna (
ods_user_info_d) dan tabel log yang telah diproses (dwd_log_info_di), lalu menulis hasilnya ke tabeldws_user_info_all_di.MaxCompute SQLads_user_info_1dMemproses lebih lanjut data dari tabel
dws_user_info_all_didan menulis hasilnya ke tabelads_user_info_1duntuk menghasilkan profil pengguna dasar. -
Tarik secara manual untuk menggambar garis antar node guna mengonfigurasi dependensi hulu. Hasil akhirnya sebagai berikut:
CatatanAnda dapat mengatur dependensi hulu dan hilir antar node dengan menggambar garis secara manual di alur kerja. Anda juga dapat menggunakan penguraian kode di node anak untuk mengidentifikasi dependensi node secara otomatis. Tutorial ini menggunakan pendekatan manual. Untuk informasi selengkapnya tentang penguraian kode, lihat Mekanisme penguraian otomatis.
2. Daftarkan UDF
Untuk memastikan tugas pemrosesan data berikutnya berjalan dengan baik, Anda harus mendaftarkan UDF MaxCompute (getregion) guna mengurai struktur data log yang disinkronkan ke MaxCompute pada langkah Sinkronisasi data menjadi tabel.
-
Tutorial ini menyediakan resource yang dibutuhkan oleh fungsi untuk mengonversi alamat IP ke wilayah. Anda hanya perlu mengunduh resource tersebut ke komputer Anda dan mengunggahnya ke ruang kerja DataWorks sebelum mendaftarkan fungsi.
-
Fungsi ini hanya ditujukan untuk tutorial ini (resource IP contoh). Untuk menerapkan pemetaan IP ke wilayah di lingkungan produksi, gunakan layanan pencarian IP profesional dari penyedia khusus.
Unggah resource (ip2region.jar)
-
Unduh ip2region.jar.
CatatanResource
ip2region.jarmerupakan contoh yang hanya ditujukan untuk tutorial ini. -
Di panel navigasi kiri Data Studio, klik
 untuk menuju halaman manajemen resource. Klik
untuk menuju halaman manajemen resource. Klik  > New Resource > Maxcompute Jar, tentukan nama resource, lalu buka halaman unggah resource.Catatan
> New Resource > Maxcompute Jar, tentukan nama resource, lalu buka halaman unggah resource.CatatanNama resource tidak perlu sama dengan nama file yang diunggah.
-
Atur Document Source ke Local, klik Click Upload di samping bidang konten file, lalu pilih file
ip2region.jaryang telah Anda unduh. -
Atur Data Source ke sumber daya komputasi MaxCompute yang telah Anda asosiasikan pada langkah Persiapkan lingkungan.
-
Di bilah alat node, klik Save, lalu klik Publish. Ikuti petunjuk di panel penerapan untuk menerapkan resource ke proyek MaxCompute di lingkungan pengembangan dan lingkungan produksi.
Daftarkan fungsi (getregion)
-
Di halaman manajemen resource, klik
> New Function > Maxcompute Function, tentukan nama fungsi, lalu buka halaman pendaftaran fungsi. Dalam tutorial ini, fungsi diberi nama getregion. -
Di halaman Register Function, konfigurasikan parameter yang diperlukan. Tabel berikut hanya menjelaskan parameter utama untuk tutorial ini. Pertahankan nilai default untuk parameter yang tidak tercantum.
Parameter
Deskripsi
Function type
Pilih
OTHER.Data Source
Pilih sumber daya komputasi MaxCompute yang telah Anda asosiasikan pada langkah Persiapkan lingkungan.
Class Name
Masukkan
org.alidata.odps.udf.Ip2Region.Resource List
Pilih
ip2region.jar.Description
Mengonversi alamat IP menjadi wilayah.
Command Format
Masukkan
getregion('ip').Parameter Description
Alamat IP.
-
Di bilah alat node, klik Save, lalu klik Publish. Ikuti petunjuk di panel penerapan untuk menerapkan fungsi ke proyek MaxCompute di lingkungan pengembangan dan lingkungan produksi.
3. Konfigurasikan node pemrosesan data
Pemrosesan data memerlukan penerapan logika pemrosesan untuk setiap lapisan melalui penjadwalan MaxCompute SQL. Tutorial ini menyediakan kode SQL contoh lengkap untuk pemrosesan data. Anda harus mengonfigurasi node berikut secara berurutan: dwd_log_info_di, dws_user_info_all_di, dan ads_user_info_1d.
Konfigurasikan node dwd_log_info_di
Kode contoh untuk node ini menggunakan fungsi yang telah Anda buat untuk memproses kolom dari tabel hulu ods_raw_log_d dan menulis hasilnya ke tabel dwd_log_info_di.
-
Di panel navigasi kiri Data Studio, klik ikon
untuk membuka halaman Pengembangan Data. Di bagian Project Directory, temukan alur kerja yang telah Anda buat lalu klik untuk membuka kanvas alur kerja. -
Di kanvas alur kerja, arahkan kursor ke node
dwd_log_info_dilalu klik Open Node. -
Tempel kode berikut ke editor node.
-
Konfigurasikan parameter debug.
Di sisi kanan editor node MaxCompute SQL, klik Run Configuration dan konfigurasikan parameter berikut. Parameter ini digunakan selama eksekusi debug di Langkah 4 untuk menguji tugas dengan parameter Run Configuration.
Item konfigurasi
Deskripsi
Computing Resources
Pilih sumber daya komputasi MaxCompute yang telah Anda asosiasikan pada langkah Persiapkan lingkungan dan kuota komputasinya yang sesuai.
Resource Group
Pilih kelompok sumber daya arsitektur tanpa server yang telah Anda beli pada langkah Persiapkan lingkungan.
Script Parameters
Tidak perlu konfigurasi. Kode contoh dalam tutorial ini menggunakan
${bizdate}untuk merepresentasikan tanggal bisnis. Saat melakukan debug alur kerja di Langkah 4, atur This operation value ke konstanta tertentu (misalnya,20250223). Tugas akan menggunakan konstanta ini untuk menggantikan variabel yang didefinisikan dalam kode. -
(opsional) Konfigurasikan pengaturan penjadwalan.
Untuk tutorial ini, pertahankan nilai default untuk pengaturan penjadwalan. Anda dapat mengklik Scheduling Configuration di sisi kanan halaman MaxCompute SQL. Untuk informasi selengkapnya tentang parameter pengaturan penjadwalan, lihat Schedule settings.
-
Scheduling Parameters: Tutorial ini telah mengonfigurasi parameter penjadwalan di tingkat alur kerja. Tidak diperlukan konfigurasi tambahan untuk node individual dalam alur kerja. Anda dapat langsung menggunakan parameter ini dalam tugas atau kode.
-
Scheduling Policy: Anda dapat menggunakan parameter Delayed execution time untuk menentukan berapa lama node anak harus menunggu sebelum dijalankan setelah alur kerja mulai berjalan. Tutorial ini tidak mengatur parameter ini.
-
-
Di bilah alat node, klik Save.
Konfigurasikan node dws_user_info_all_di
Node ini menggabungkan data dari tabel informasi pengguna (ods_user_info_d) dan tabel log yang telah diproses (dwd_log_info_di), lalu menulis hasilnya ke tabel dws_user_info_all_di.
-
Di kanvas alur kerja, arahkan kursor ke node
dws_user_info_all_dilalu klik Open Node. -
Tempel kode berikut ke editor node.
-
Konfigurasikan parameter debug.
Di sisi kanan editor node MaxCompute SQL, klik Run Configuration dan konfigurasikan parameter berikut. Parameter ini digunakan selama eksekusi debug di Langkah 4 untuk menguji tugas dengan parameter Run Configuration.
Item konfigurasi
Deskripsi
Computing Resources
Pilih sumber daya komputasi MaxCompute yang telah Anda asosiasikan pada langkah Persiapkan lingkungan dan kuota komputasinya yang sesuai.
Resource Group
Pilih kelompok sumber daya arsitektur tanpa server yang telah Anda beli pada langkah Persiapkan lingkungan.
Script Parameters
Tidak perlu konfigurasi. Kode contoh dalam tutorial ini menggunakan
${bizdate}untuk merepresentasikan tanggal bisnis. Saat melakukan debug alur kerja di Langkah 4, atur This operation value ke konstanta tertentu (misalnya,20250223). Tugas akan menggunakan konstanta ini untuk menggantikan variabel yang didefinisikan dalam kode. -
(opsional) Konfigurasikan pengaturan penjadwalan.
Untuk tutorial ini, pertahankan nilai default untuk pengaturan penjadwalan. Anda dapat mengklik Scheduling Configuration di sisi kanan halaman MaxCompute SQL. Untuk informasi selengkapnya tentang parameter pengaturan penjadwalan, lihat Schedule settings.
-
Scheduling Parameters: Tutorial ini telah mengonfigurasi parameter penjadwalan di tingkat alur kerja. Tidak diperlukan konfigurasi tambahan untuk node individual dalam alur kerja. Anda dapat langsung menggunakan parameter ini dalam tugas atau kode.
-
Scheduling Policy: Anda dapat menggunakan parameter Delayed execution time untuk menentukan berapa lama node anak harus menunggu sebelum dijalankan setelah alur kerja mulai berjalan. Tutorial ini tidak mengatur parameter ini.
-
-
Di bilah alat node, klik Save.
Konfigurasikan node ads_user_info_1d
Node ini memproses lebih lanjut data dari tabel dws_user_info_all_di dan menulis hasilnya ke tabel ads_user_info_1d untuk menghasilkan profil pengguna dasar.
-
Di kanvas alur kerja, arahkan kursor ke node
ads_user_info_1dlalu klik Open Node. -
Tempel kode berikut ke editor node.
-
Konfigurasikan parameter debug.
Di sisi kanan editor node MaxCompute SQL, klik Run Configuration dan konfigurasikan parameter berikut. Parameter ini digunakan selama eksekusi debug di Langkah 4 untuk menguji tugas dengan parameter Run Configuration.
Item konfigurasi
Deskripsi
Computing Resources
Pilih sumber daya komputasi MaxCompute yang telah Anda asosiasikan pada langkah Persiapkan lingkungan dan kuota komputasinya yang sesuai.
Resource Group
Pilih kelompok sumber daya arsitektur tanpa server yang telah Anda beli pada langkah Persiapkan lingkungan.
Script Parameters
Tidak perlu konfigurasi. Kode contoh dalam tutorial ini menggunakan
${bizdate}untuk merepresentasikan tanggal bisnis. Saat melakukan debug alur kerja di Langkah 4, atur This operation value ke konstanta tertentu (misalnya,20250223). Tugas akan menggunakan konstanta ini untuk menggantikan variabel yang didefinisikan dalam kode. -
(opsional) Konfigurasikan pengaturan penjadwalan.
Untuk tutorial ini, pertahankan nilai default untuk pengaturan penjadwalan. Anda dapat mengklik Scheduling Configuration di sisi kanan halaman MaxCompute SQL. Untuk informasi selengkapnya tentang parameter pengaturan penjadwalan, lihat Schedule settings.
-
Scheduling Parameters: Tutorial ini telah mengonfigurasi parameter penjadwalan di tingkat alur kerja. Tidak diperlukan konfigurasi tambahan untuk node individual dalam alur kerja. Anda dapat langsung menggunakan parameter ini dalam tugas atau kode.
-
Scheduling Policy: Anda dapat menggunakan parameter Delayed execution time untuk menentukan berapa lama node anak harus menunggu sebelum dijalankan setelah alur kerja mulai berjalan. Tutorial ini tidak mengatur parameter ini.
-
-
Di bilah alat node, klik Save.
4. Proses data
-
Proses data.
Di bilah alat alur kerja, klik Run, atur nilai variabel parameter yang didefinisikan di setiap node untuk eksekusi ini (tutorial ini menggunakan
20250223, dan Anda dapat mengubah nilainya sesuai kebutuhan), klik OK, lalu tunggu hingga eksekusi selesai. -
Kueri hasil pemrosesan data.
-
Di panel navigasi kiri DataStudio, klik
 untuk membuka halaman Pengembangan Data. Lalu, di folder pribadi, klik
untuk membuka halaman Pengembangan Data. Lalu, di folder pribadi, klik  untuk membuat file
untuk membuat file .sql. Gunakan nama file apa pun. -
Di bagian bawah halaman, pastikan mode bahasa adalah
MaxCompute SQL.
-
Di editor SQL, masukkan pernyataan SQL berikut untuk mengkueri jumlah catatan pada tabel hasil akhir
ads_user_info_1ddan verifikasi apakah hasil pemrosesan data telah dihasilkan.-- You need to modify the partition filter condition to the actual business date of your current operation. In this tutorial, the debug parameter bizdate (business date) configured earlier is 20250223. SELECT count(*) FROM ads_user_info_1d WHERE dt='business date';-
Jika kueri mengembalikan data, pemrosesan data telah selesai.
-
Jika kueri mengembalikan jumlah nol, pastikan This operation value sesuai dengan tanggal bisnis pada partisi
dtdalam kueri Anda. Untuk memeriksa nilainya, buka panel Runtime Logs di sisi kanan alur kerja lalu klik View di kolom Operation untuk eksekusi tersebut. Log eksekusi menampilkan nilai tanggal bisnis, misalnya,partition=[dt=20250223].
-
-
5. Terapkan alur kerja
Tugas harus diterapkan ke lingkungan produksi sebelum dapat dijadwalkan secara otomatis. Ikuti langkah-langkah berikut untuk menerapkan alur kerja ke lingkungan produksi.
Tutorial ini telah mengonfigurasi parameter penjadwalan di tingkat alur kerja dalam Pengaturan penjadwalan alur kerja. Anda tidak perlu mengonfigurasi parameter penjadwalan untuk setiap node secara individual sebelum penerapan.
-
Di panel navigasi kiri Data Studio, klik ikon
untuk membuka halaman Pengembangan Data. Di bagian Project Directory, temukan alur kerja yang telah Anda buat lalu klik untuk membuka kanvas alur kerja. -
Di bilah alat node, klik Publish untuk membuka panel penerapan.
-
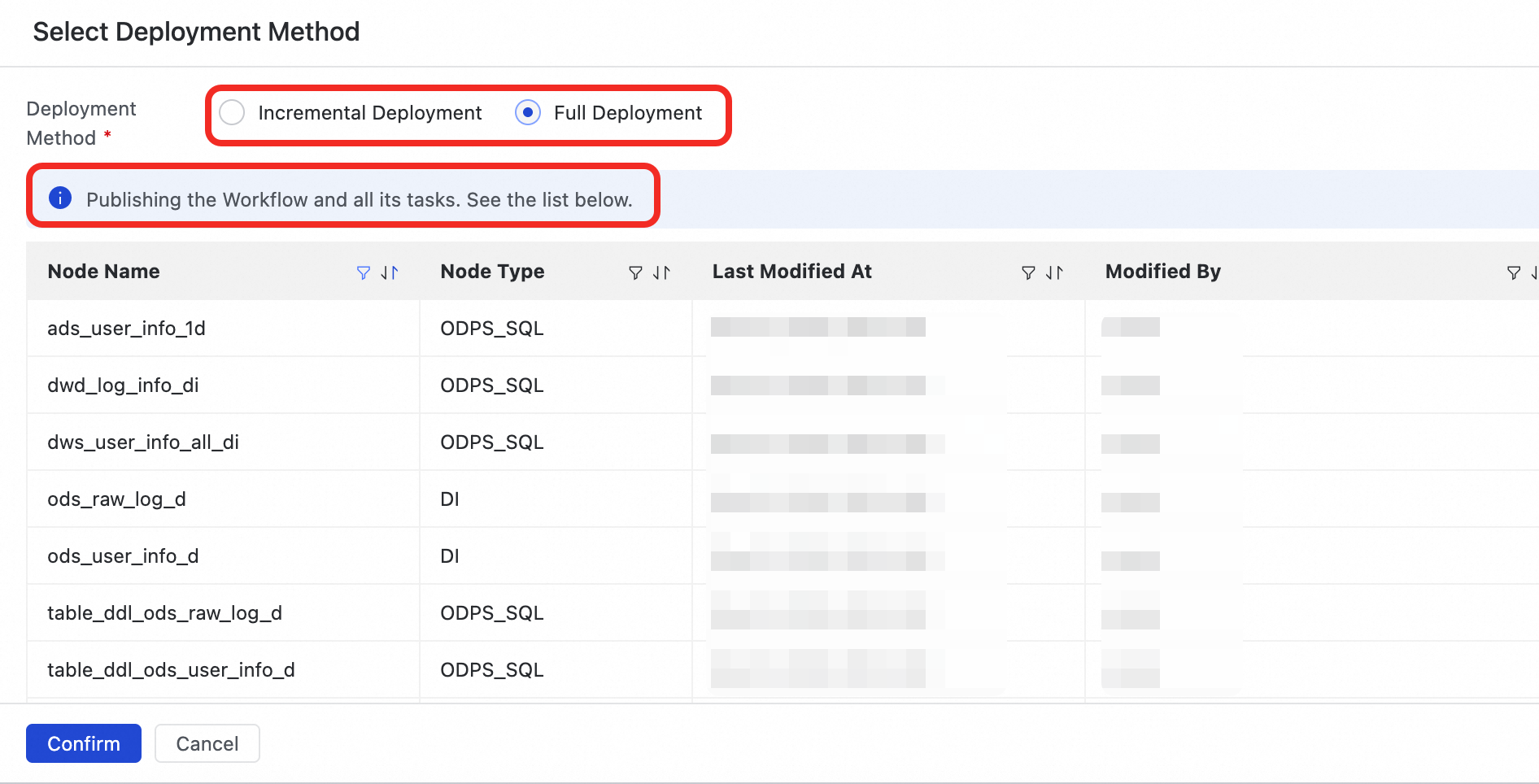
Klik Start Release Production. Di dialog konfirmasi metode penerapan, pilih metode penerapan sesuai kebutuhan Anda:
-
Full deployment: Menerapkan alur kerja saat ini beserta semua tugasnya.
-
Incremental deployment: Hanya menerapkan alur kerja saat ini dan node tugas internal yang kontennya berbeda dari garis dasar saat ini di semua lingkungan penerapan. Metode ini cocok untuk optimasi iteratif dan pembaruan skala kecil.
-
-
Setelah Anda mengonfirmasi metode penerapan, sistem secara otomatis menerapkan alur kerja dan node tugas yang dipilih ke lingkungan pengembangan dan lingkungan produksi secara berurutan. Saat menerapkan ke lingkungan produksi, klik Confirm Release untuk menyelesaikan penerapan.

6. Jalankan tugas di lingkungan produksi
Setelah tugas diterapkan, instans dihasilkan dan dijalankan pada hari berikutnya. Anda dapat menggunakan Supplementary data untuk mengisi ulang data untuk alur kerja yang telah diterapkan dan memverifikasi apakah tugas dapat dijalankan di lingkungan produksi. Untuk informasi selengkapnya, lihat Backfill data.
-
Setelah tugas diterapkan, klik Operation and Maintenance Center di pojok kanan atas.
Anda juga dapat mengklik ikon
 di pojok kiri atas lalu pilih .
di pojok kiri atas lalu pilih . -
Di panel navigasi kiri, pilih untuk menuju halaman Auto Triggered Node, lalu klik node virtual
workshop_start. -
Di DAG di sisi kanan, klik kanan node
workshop_startlalu pilih . -
Pilih tugas yang ingin Anda isi ulang datanya, atur tanggal bisnis, lalu klik Submit and Redirect.
-
Di halaman pengisian ulang data, klik Refresh hingga semua tugas SQL berhasil dijalankan.
Setelah menyelesaikan tutorial ini, untuk menghindari biaya tambahan, Anda dapat mengatur periode validitas penjadwalan untuk node atau freeze node akar alur kerja (node virtual workshop_start).
Langkah selanjutnya
-
Visualisasi data: Setelah analisis profil pengguna selesai, gunakan modul Analisis Data untuk memvisualisasikan data yang telah diproses sebagai grafik guna memperoleh wawasan cepat mengenai informasi kunci dan tren bisnis.
-
Pantau kualitas data: Konfigurasikan pemantauan kualitas data untuk tabel yang dihasilkan oleh pemrosesan data guna mengidentifikasi dan memblokir data kotor sedini mungkin serta mencegah penyebaran masalah data.
-
Lihat metadata: Setelah alur kerja analisis profil pengguna selesai, tabel data yang sesuai dibuat di MaxCompute. Anda dapat melihat tabel yang dihasilkan di modul Peta Data dan menggunakan lineage untuk melihat hubungan antar tabel.
-
Bagikan data melalui API: Setelah data hasil pemrosesan akhir tersedia, gunakan modul Layanan Data untuk membagikan dan menerapkan data melalui titik akhir API yang distandarkan, menyediakan data ke modul bisnis lain yang mengonsumsi data melalui API.