Saat beberapa pipeline berbagi logika SQL yang sama tetapi beroperasi pada tabel berbeda, memelihara salinan terpisah dari kode tersebut menimbulkan beban pemeliharaan: setiap perubahan logika harus diterapkan pada semua salinan, dan kesalahan salin-tempel mudah terlewat. Templat skrip mengatasi masalah ini dengan memungkinkan Anda mendefinisikan logika SQL sekali saja, lalu menggunakannya kembali di berbagai pipeline dengan tabel input dan output yang berbeda. Topik ini menjelaskan cara membuat, mereferensikan, dan mengelola templat skrip di DataWorks.
Cara kerja
Templat skrip bekerja seperti fungsi dalam bahasa pemrograman: definisikan logika sekali, lalu panggil berulang kali dengan argumen berbeda. Badan templat berisi placeholder @@{parameter_name} untuk nama tabel variabel dan nilai string. Saat node SQL Snippet mereferensikan templat dan menyediakan nilai parameter konkret, DataWorks mengganti placeholder tersebut dan menghasilkan SQL yang dapat dieksekusi.
Sebagai contoh, badan templat mungkin berisi:
INSERT OVERWRITE TABLE @@{myoutput} PARTITION (pt='${bizdate}')
SELECT ...
FROM @@{myinputtable}
WHERE r2.rank <= @@{topn};Saat node SQL Snippet mengikat myinputtable ke company_sales_record, myoutput ke company_sales_top_n, dan topn ke 10, DataWorks mengganti nilai-nilai tersebut dan menjalankan SQL yang dihasilkan.
Templat skrip hanya berfungsi dengan node SQL Snippet. Untuk menjalankan pipeline berbasis templat, buat node SQL Snippet yang mereferensikan templat tersebut.
Konsep utama
| Konsep | Deskripsi |
|---|---|
| Script template | Proses kode SQL yang dapat digunakan kembali dengan parameter input dan output bernama dalam format @@{parameter_name} |
| SQL Snippet node | Jenis node yang mereferensikan templat skrip dan menyediakan nilai parameter konkret |
| Input parameter (Table) | Mengikat tabel sumber ke templat. Tabel yang diikat harus memiliki jumlah bidang yang sama dan tipe bidang yang kompatibel dengan definisi parameter. |
| Input parameter (String) | Mengikat nilai string atau variabel ke templat, seperti ambang batas filter atau nama provinsi |
| Output parameter | Menentukan tabel output yang dihasilkan oleh proses kode SQL. Harus bertipe Table. |
| Workspace-level template | Hanya tersedia bagi anggota ruang kerja saat ini setelah deployment |
| Public template | Dipublikasikan ke penyewa saat ini sehingga semua pengguna penyewa dapat menggunakannya |
Definisi parameter hanya bersifat referensi. DataWorks tidak melakukan pemeriksaan skema secara langsung. Ketidaksesuaian antara definisi parameter dan skema tabel aktual akan menyebabkan error saat waktu proses ketika node dijalankan.
Batasan
Node SQL Snippet memerlukan DataWorks Edisi Standar atau edisi yang lebih tinggi. Untuk detailnya, lihat Perbedaan antar edisi DataWorks.
Templat tingkat ruang kerja muncul di tab Workspace-Specific. Hanya anggota ruang kerja yang dapat menggunakannya.
Templat publik muncul di tab Public. Semua pengguna dalam penyewa dapat menggunakannya.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
Peran Development di ruang kerja target. Untuk menetapkan peran, lihat bagian Tambahkan Pengguna RAM ke ruang kerja sebagai anggota dan tetapkan peran kepada anggota dalam "Kelola izin pada layanan tingkat ruang kerja."
DataWorks Edisi Standar atau edisi yang lebih tinggi
Definisikan templat skrip
Langkah 1: Buka panel Snippets
Masuk ke Konsol DataWorks. Pada bilah navigasi atas, pilih Wilayah tujuan. Di panel navigasi kiri, pilih Data Development and O&M > Data Development. Pilih ruang kerja tujuan, lalu klik Go to Data Development.
Di panel navigasi kiri halaman DataStudio, klik Snippets.
Jika Snippets tidak terlihat, klik ikon
 di pojok kiri bawah dan ikuti petunjuk di Konfigurasi pengaturan di bagian Modul DataStudio untuk menambahkannya.
di pojok kiri bawah dan ikuti petunjuk di Konfigurasi pengaturan di bagian Modul DataStudio untuk menambahkannya.
Langkah 2: Buat templat
Di panel Snippets, gunakan tindakan yang ditunjukkan pada gambar berikut untuk membuat dan memberi nama templat skrip.
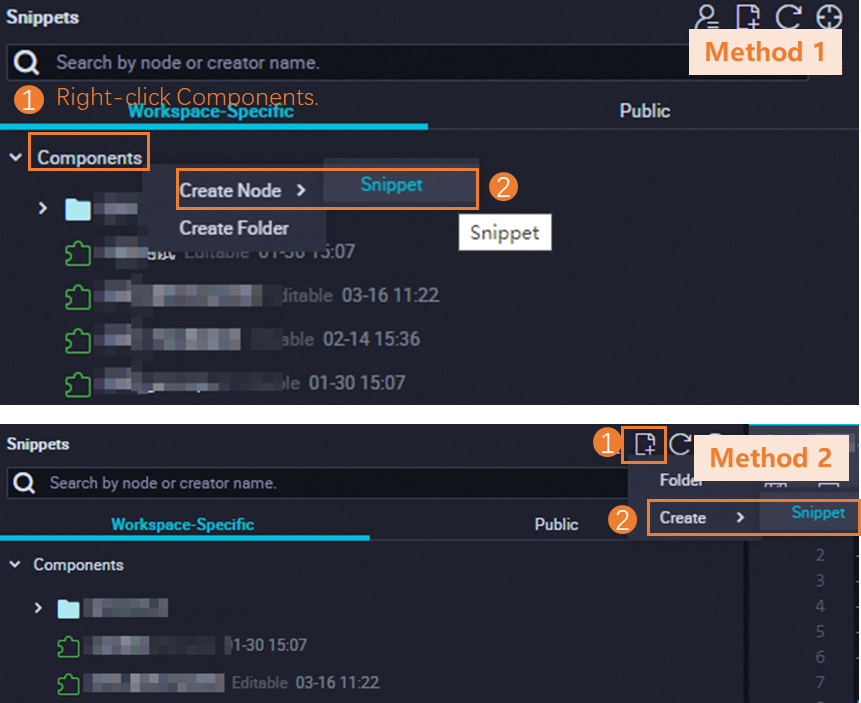
Templat yang dibuat oleh akun anggota di ruang kerja saat ini muncul di tab Workspace-Specific. Templat yang dibuat dalam penyewa muncul di tab Public.
Langkah 3: Konfigurasi templat
Tab konfigurasi terdiri dari tiga bagian: proses kode SQL, parameter input, dan parameter output.
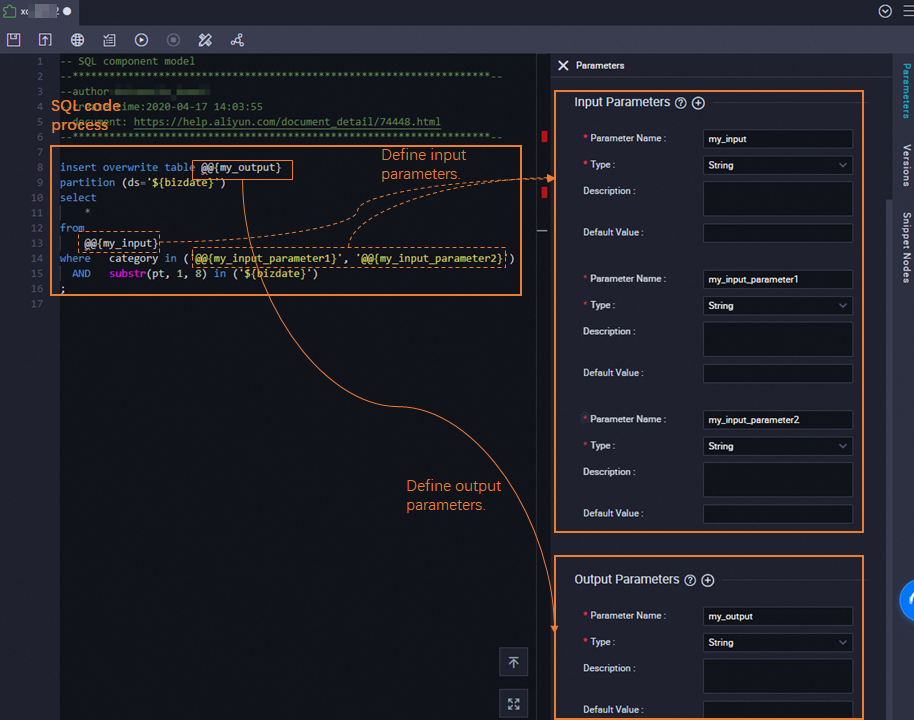
Proses kode SQL
Tulis logika SQL di editor kode. Ganti nama tabel variabel dan nilai string dengan placeholder @@{parameter_name}. DataWorks akan mengganti placeholder ini dengan nilai aktual saat node SQL Snippet dijalankan.
Parameter input
Tambahkan satu atau beberapa parameter input. Setiap parameter memiliki salah satu tipe berikut:
Table: Mengikat tabel sumber. Definisikan skema yang diharapkan sebagai blok teks agar pengguna mengetahui skema yang harus disediakan. Definisikan skema dalam format berikut:
Nama Bidang 1 Tipe Bidang 1 Deskripsi Bidang 1 Nama Bidang 2 Tipe Bidang 2 Deskripsi Bidang 2 ... Nama Bidang n Tipe Bidang n Deskripsi Bidang nContoh:
area_id string 'Region ID' city_id string 'City ID' order_amt double 'Order amount'String: Mengikat nilai string, seperti ambang batas numerik atau kondisi filter. Secara opsional, atur nilai default yang digunakan saat tidak ada nilai yang diberikan saat referensi. Kasus penggunaan:
Ekspor N kota teratas berdasarkan penjualan: gunakan parameter String untuk meneruskan nilai N.
Filter berdasarkan provinsi: gunakan parameter String untuk meneruskan nama provinsi.
Output Parameters
Tambahkan satu atau beberapa parameter output bertipe Table. Definisikan skema output yang diharapkan sebagai referensi.
Contoh:
area_id string 'Region ID'
city_id string 'City ID'
order_amt double 'Order amount'
rank bigint 'Ranking'Sebuah templat dapat berisi beberapa parameter input dan output.
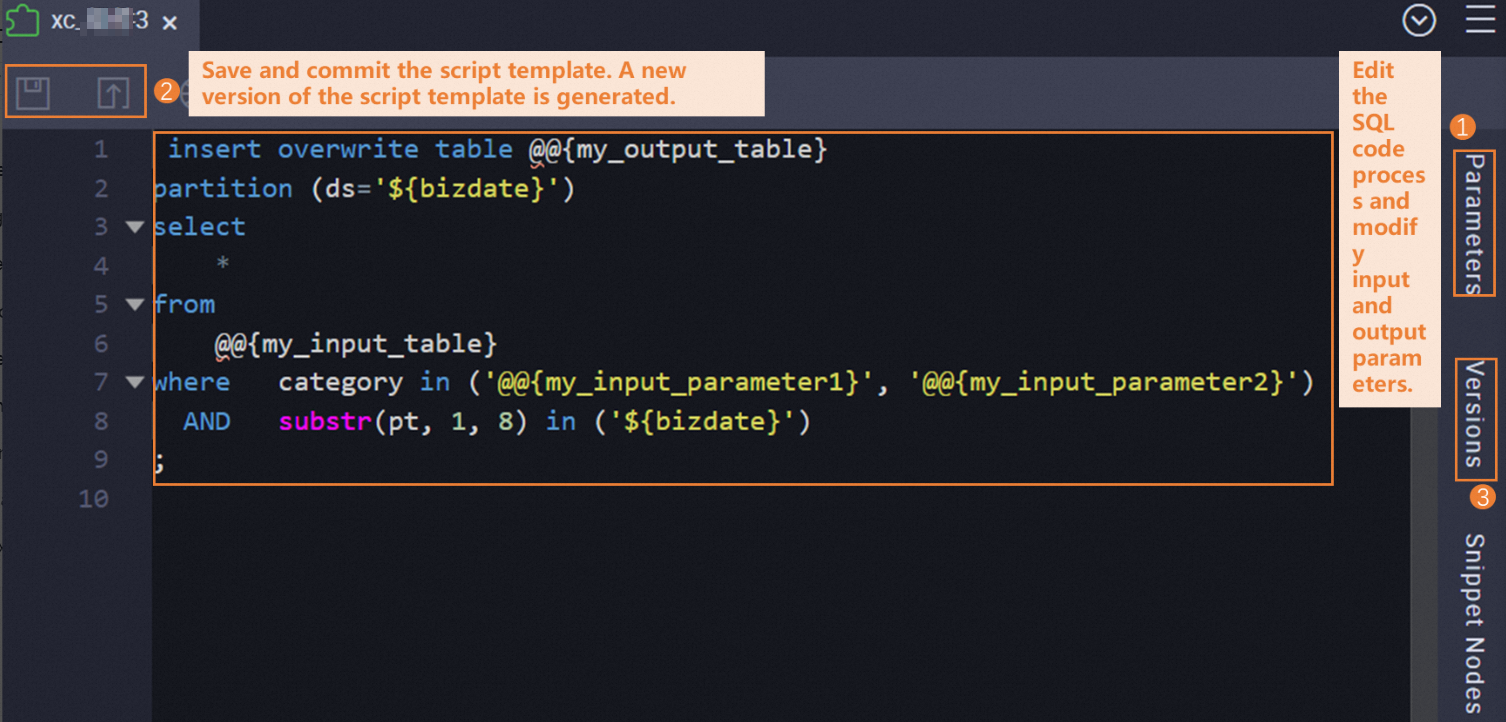
Langkah 4: Simpan dan commit templat
Di bilah alat pada tab konfigurasi, klik ikon ![]() untuk menyimpan, lalu klik ikon
untuk menyimpan, lalu klik ikon ![]() untuk commit. Setelah templat di-commit, templat tersebut tersedia untuk direferensikan oleh node SQL Snippet.
untuk commit. Setelah templat di-commit, templat tersebut tersedia untuk direferensikan oleh node SQL Snippet.
Referensikan templat skrip
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
Templat skrip yang telah dibuat. Lihat Definisikan templat skrip.
Node SQL Snippet. Lihat Buat dan kelola node ODPS.
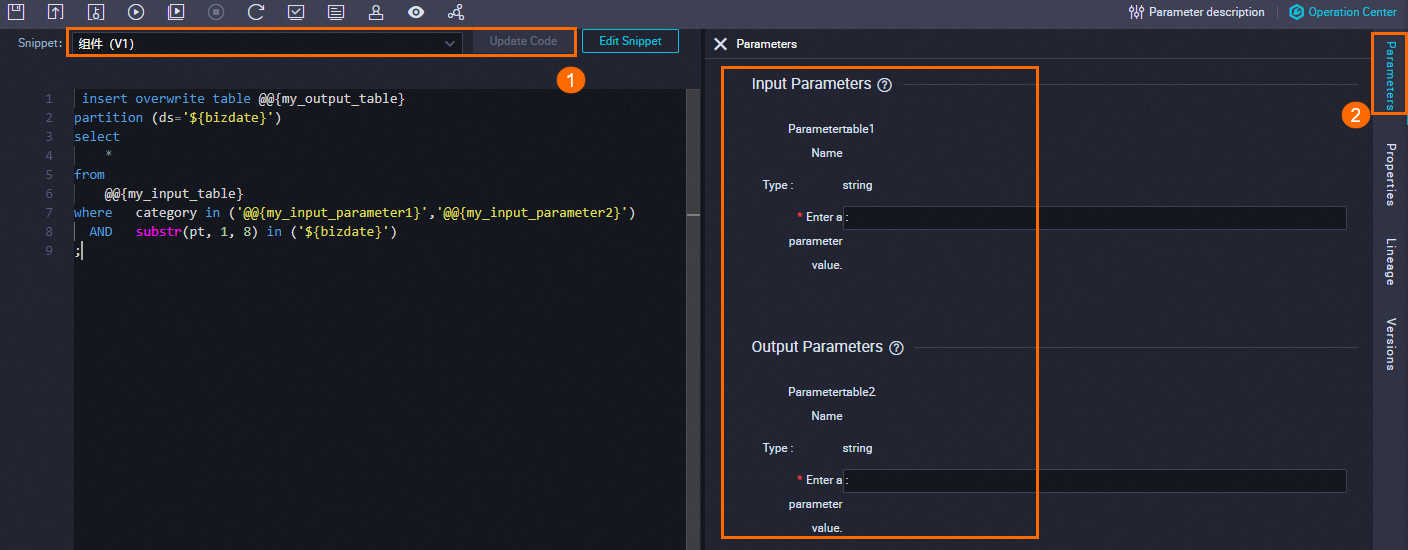
Referensikan templat
Pada tab konfigurasi node SQL Snippet, ikuti langkah-langkah pada gambar berikut untuk memilih dan mengonfigurasi templat skrip.
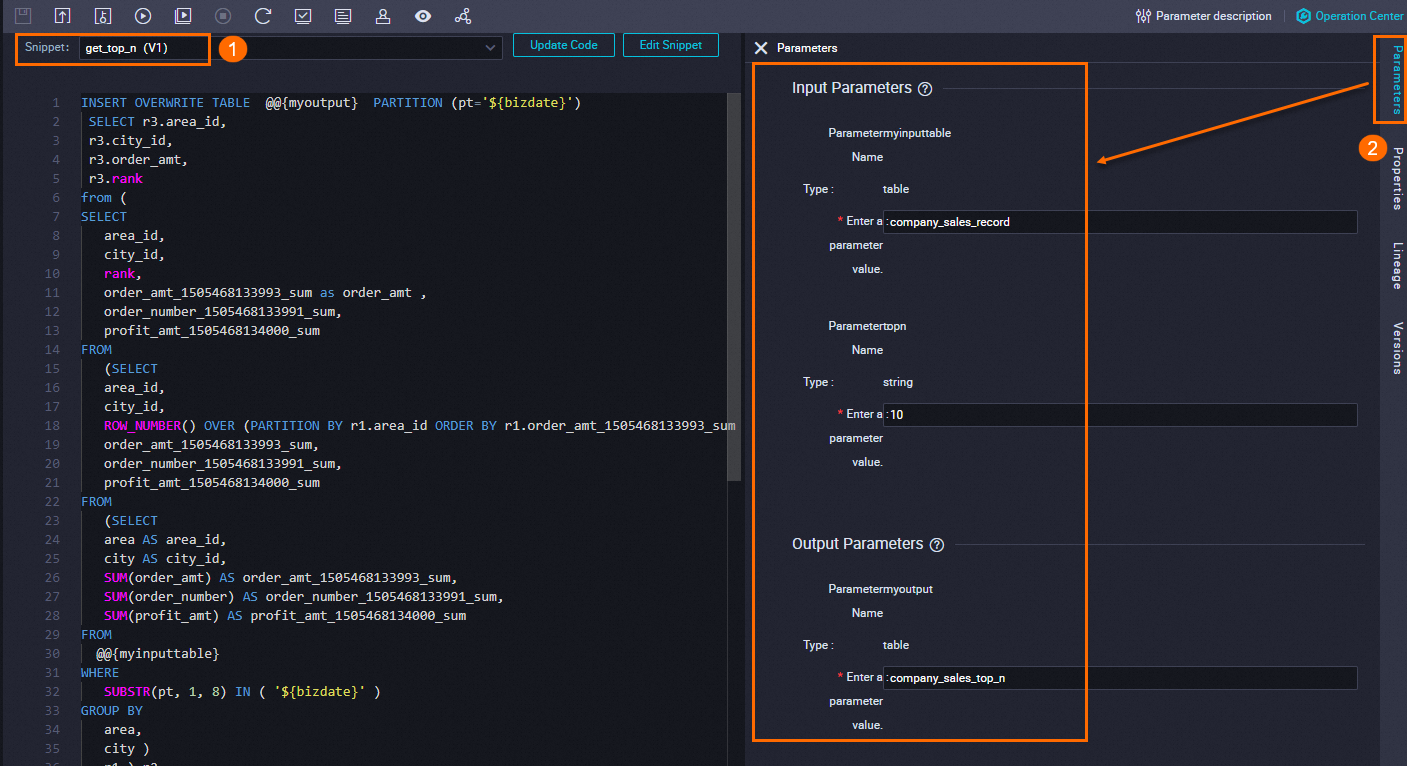
Pilih templat skrip yang akan direferensikan.
Jika tersedia versi templat yang lebih baru, klik Update Code untuk mengambilnya.
Untuk memeriksa definisi templat, klik Edit Snippet.
Konfigurasikan nilai parameter input dan output berdasarkan tabel dan kebutuhan pipeline Anda.
Kelola templat skrip
Publikasikan templat ke semua pengguna penyewa
Setelah deployment, templat secara default bersifat tingkat ruang kerja. Untuk membuatnya tersedia bagi semua pengguna dalam penyewa, klik ikon Publish Snippet (ditandai 1 pada gambar) di bilah alat pada tab konfigurasi templat.
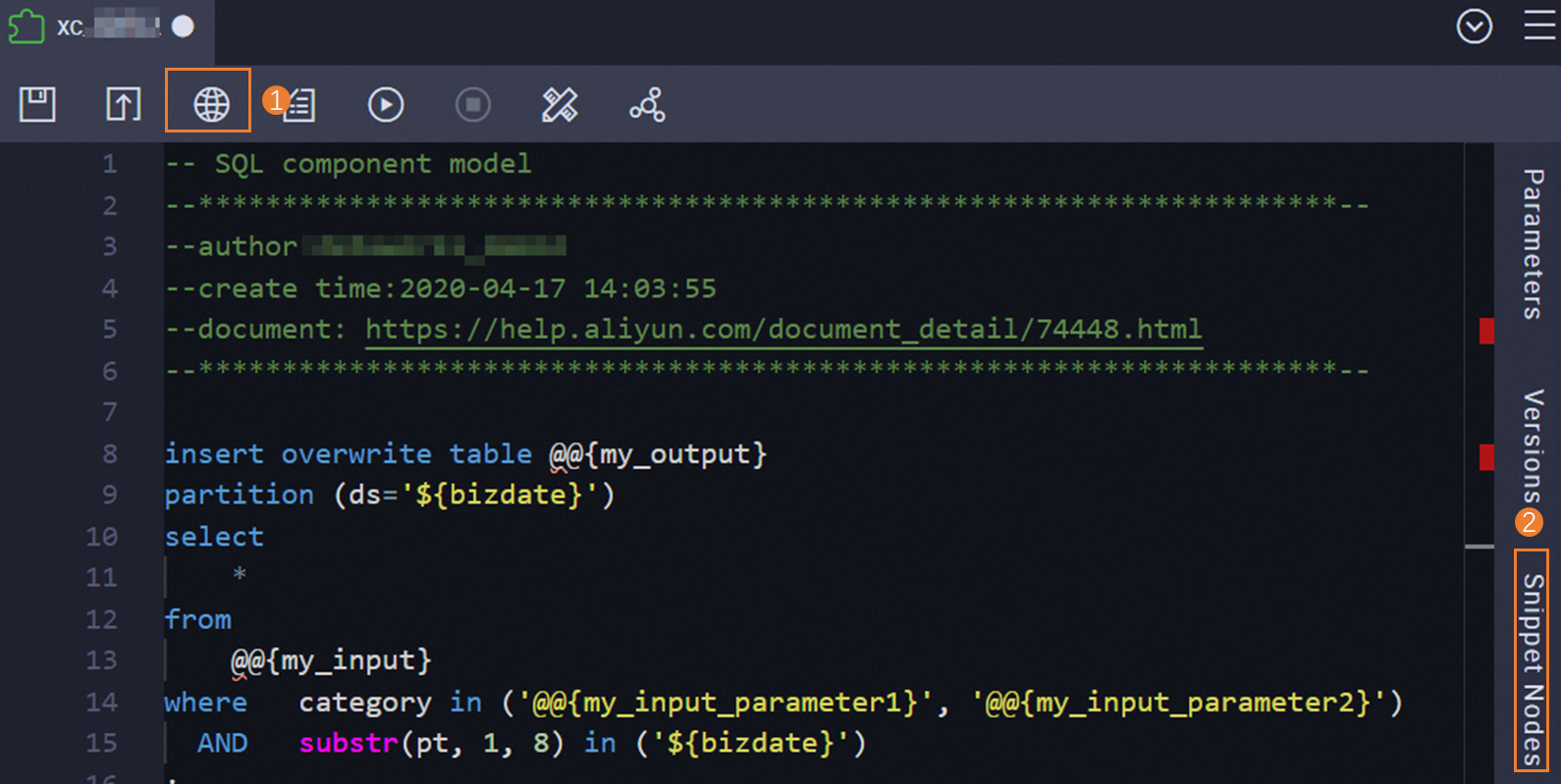
Lihat catatan referensi
Pada tab Snippet Nodes (ditandai 2 pada gambar), lihat semua node yang mereferensikan templat saat ini. Tinjau daftar ini sebelum memodifikasi templat untuk memahami dampak downstream-nya.
Peningkatan templat
Edit kode SQL atau pengaturan parameter dalam templat, lalu simpan dan commit ulang. Setiap commit ulang membuat versi baru. Lihat riwayat versi di tab Versions (ditandai 3 pada gambar) di panel navigasi kanan.
Dampak pada node yang mereferensikan
Saat templat ditingkatkan, Anda dapat menentukan apakah akan menggunakan versi terbaru templat di node SQL Snippet Anda. Untuk mengadopsi versi baru, buka node SQL Snippet, klik Update Code, verifikasi bahwa pengaturan parameter baru sesuai untuk pipeline Anda, lalu commit dan deploy node tersebut.
Contoh skenario
Developer C membuat versi V1.0 templat. Pengguna A mereferensikan V1.0. Developer C kemudian meningkatkan ke V2.0. Pengguna A melihat bahwa versi yang lebih baru tersedia, meninjau detail V2.0, dan memutuskan apakah akan memperbarui node mereka untuk menggunakan V2.0.
Referensi tab konfigurasi

| Fitur | Deskripsi |
|---|---|
| Save | Menyimpan pengaturan templat saat ini |
| Steal Lock | Mengambil alih kunci edit dari pengguna lain sehingga Anda dapat mengedit templat, jika Anda bukan pemilik templat skrip tersebut |
| Submit | Commit templat ke lingkungan pengembangan |
| Publish Snippet | Membuat templat tersedia bagi semua pengguna dalam penyewa saat ini |
| Parse I/O Parameters | Mengurai parameter input dan output dari kode SQL |
| Run | Menjalankan templat di lingkungan pengembangan |
| Stop | Menghentikan templat yang sedang Berjalan |
| Format Code | Memformat kode SQL berdasarkan kata kunci |
| Parameters | Lihat informasi dasar dan konfigurasikan parameter input dan output |
| Versions | Lihat semua versi templat yang telah diterapkan |
| Snippet Nodes | Lihat semua node yang mereferensikan templat |
Praktik terbaik: peringkat penjualan top-N
Contoh ini memandu Anda membuat templat skrip get_top_n yang mengembalikan N kota teratas berdasarkan total penjualan di setiap wilayah, lalu mereferensikannya dari node SQL Snippet.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
Node SQL Snippet. Lihat Buat dan kelola node ODPS.
Tabel input dan tabel output yang telah dibuat di node ODPS SQL.
Langkah 1: Definisikan templat get_top_n
Buat templat skrip bernama get_top_n. Lihat Definisikan templat skrip untuk prosedur lengkapnya. Gunakan konfigurasi berikut.
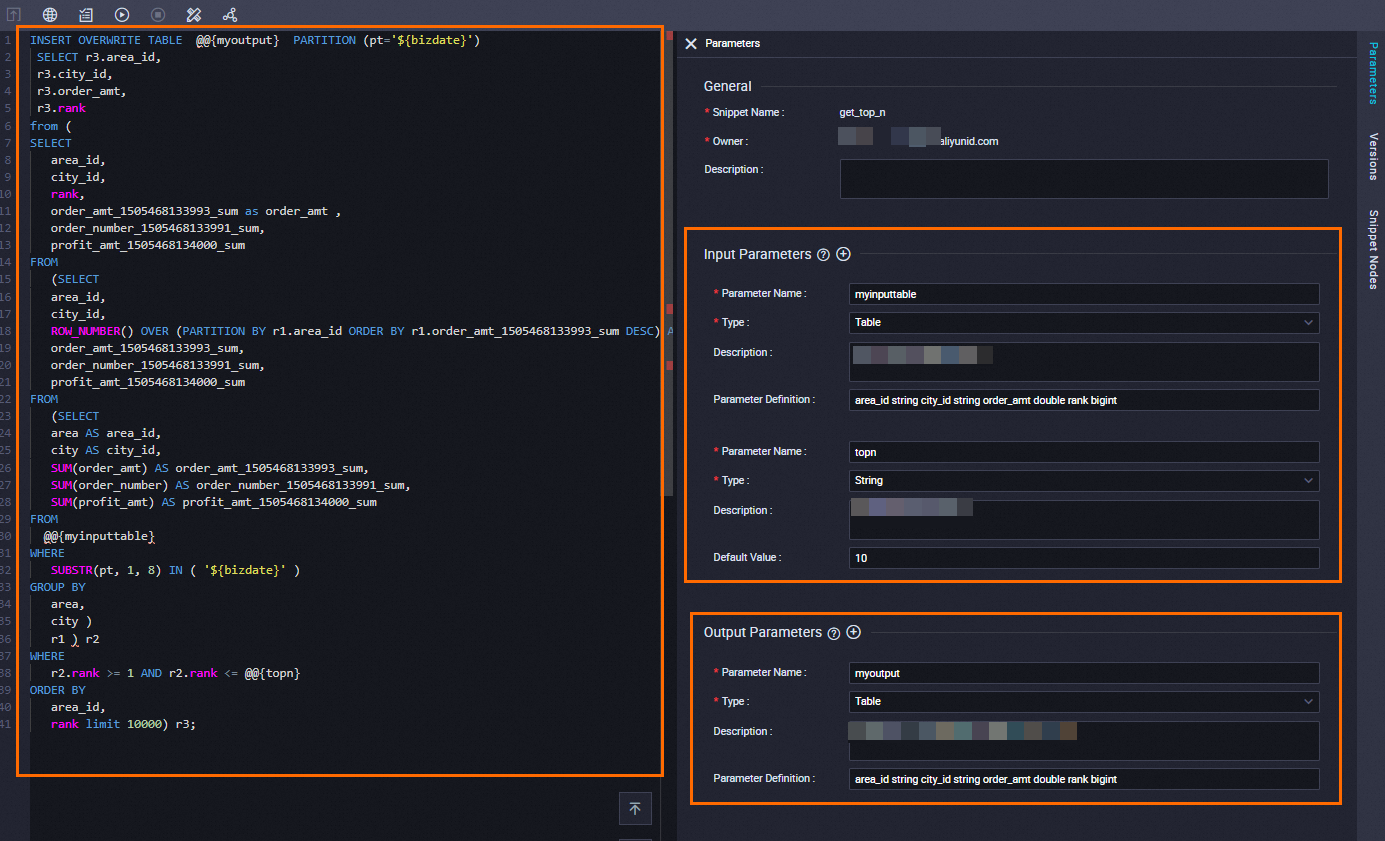
Parameter settings
| Kategori | Parameter | Tipe | Deskripsi | Definisi parameter |
|---|---|---|---|---|
| Input parameter | myinputtable | Table | Tabel data penjualan | area_id string, city_id string, order_amt double, rank bigint |
| Input parameter | topn | String | Jumlah kota teratas yang akan dikembalikan | N/A |
| Output parameter | myoutput | Table | Peringkat kota teratas per wilayah | area_id string, city_id string, order_amt double, rank bigint |
Proses kode SQL
Templat menggunakan @@{myinputtable}, @@{myoutput}, dan @@{topn} sebagai placeholder. DataWorks menggantinya dengan nilai yang diikat saat node dijalankan.
INSERT OVERWRITE TABLE @@{myoutput} PARTITION (pt='${bizdate}')
SELECT r3.area_id,
r3.city_id,
r3.order_amt,
r3.rank
from (
SELECT
area_id,
city_id,
rank,
order_amt_1505468133993_sum as order_amt ,
order_number_1505468133991_sum,
profit_amt_1505468134000_sum
FROM
(SELECT
area_id,
city_id,
ROW_NUMBER() OVER (PARTITION BY r1.area_id ORDER BY r1.order_amt_1505468133993_sum DESC) AS rank,
order_amt_1505468133993_sum,
order_number_1505468133991_sum,
profit_amt_1505468134000_sum
FROM
(SELECT
area AS area_id,
city AS city_id,
SUM(order_amt) AS order_amt_1505468133993_sum,
SUM(order_number) AS order_number_1505468133991_sum,
SUM(profit_amt) AS profit_amt_1505468134000_sum
FROM
@@{myinputtable}
WHERE
SUBSTR(pt, 1, 8) IN ( '${bizdate}' )
GROUP BY
area,
city )
r1 ) r2
WHERE
r2.rank >= 1 AND r2.rank <= @@{topn}
ORDER BY
area_id,
rank limit 10000) r3;Langkah 2: Referensikan templat dari node SQL Snippet
Buat node SQL Snippet bernama xc_Referenced script template_get_top_n, pilih templat get_top_n, dan konfigurasikan parameter seperti yang ditunjukkan di bawah ini.
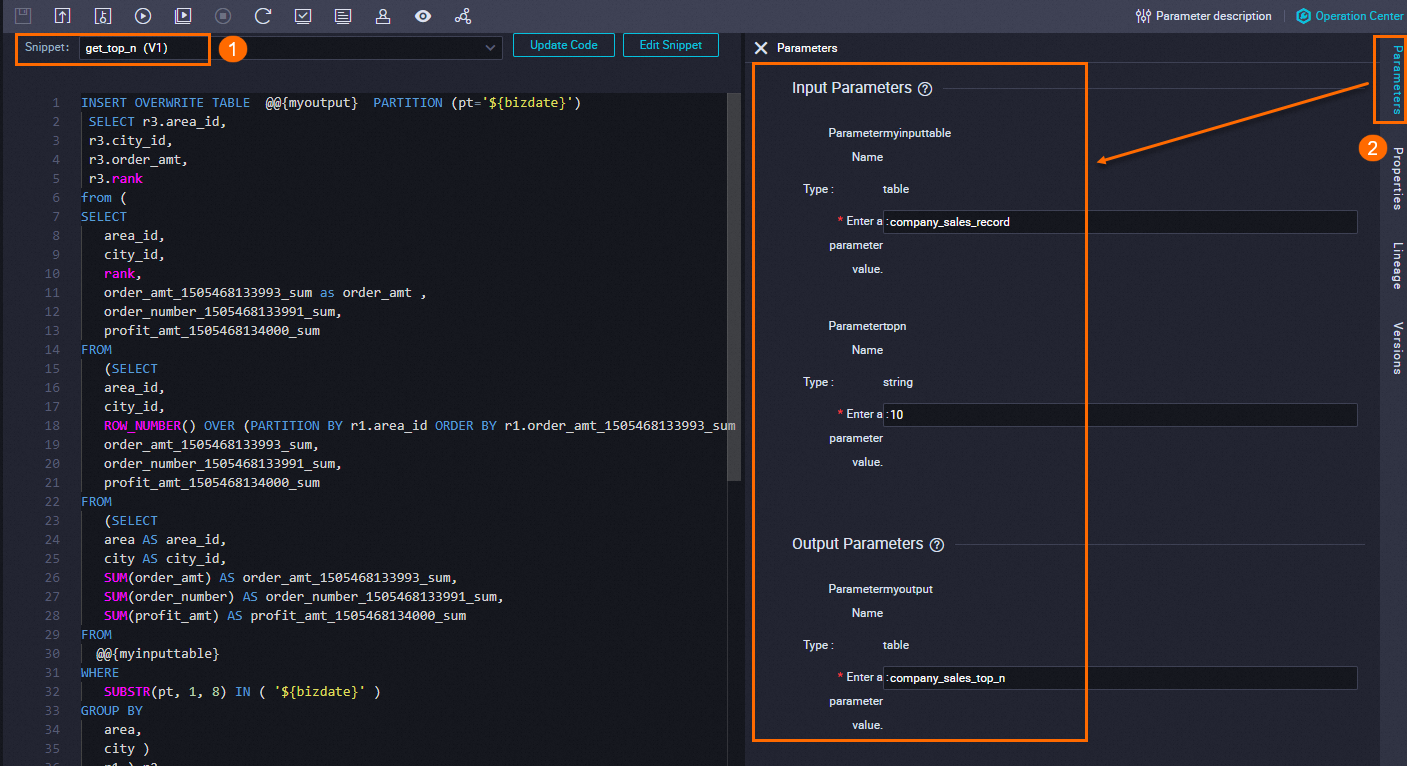
Konfigurasi parameter
myinputtable: ikat kecompany_sales_record, tabel partisi dengan siklus hidup 365 hari.CREATE TABLE IF NOT EXISTS company_sales_record ( order_id STRING COMMENT 'Order ID (PK)', report_date STRING COMMENT 'Order generation date', customer_name STRING COMMENT 'Customer name', order_level STRING COMMENT 'Order level', order_number DOUBLE COMMENT 'Number of orders', order_amt DOUBLE COMMENT 'Order amount', back_point DOUBLE COMMENT 'Discount', shipping_type STRING COMMENT 'Transportation method', profit_amt DOUBLE COMMENT 'Amount of profit', price DOUBLE COMMENT 'Unit price', shipping_cost DOUBLE COMMENT 'Cost of transportation', area STRING COMMENT 'Region', province STRING COMMENT 'Province', city STRING COMMENT 'City', product_type STRING COMMENT 'Product type', product_sub_type STRING COMMENT 'Product subtype', product_name STRING COMMENT 'Product name', product_box STRING COMMENT 'Product packaging', shipping_date STRING COMMENT 'Date of transportation' ) COMMENT 'Detailed sales data' PARTITIONED BY ( pt STRING ) LIFECYCLE 365;topn: atur ke10untuk mengembalikan 10 kota teratas berdasarkan total penjualan di setiap wilayah.myoutput: ikat kecompany_sales_top_n.CREATE TABLE IF NOT EXISTS company_sales_top_n ( area STRING COMMENT 'Region', city STRING COMMENT 'City', sales_amount DOUBLE COMMENT 'Sales amount', rank BIGINT COMMENT 'Ranking' ) COMMENT 'Company sales rankings' PARTITIONED BY (pt STRING COMMENT '') LIFECYCLE 365;
Langkah selanjutnya
Setelah pengembangan selesai, konfigurasikan node untuk produksi:
Konfigurasikan properti penjadwalan: Atur penjadwalan periodik, pengaturan jalankan ulang, dan dependensi penjadwalan. Lihat Ikhtisar.
Debug node: Uji logika kode sebelum deployment. Lihat Prosedur debugging.
Deploy node: Deploy untuk mengaktifkan penjadwalan periodik. Lihat Deploy nodes.