DataWorks Data Integration menyediakan Tugas Sinkronisasi Real-time untuk satu tabel yang mendukung replikasi data dengan latensi rendah dan throughput tinggi antar berbagai Sumber data. Fitur ini berjalan di atas mesin komputasi real-time canggih yang menangkap perubahan data (penyisipan, penghapusan, dan pembaruan) di sumber dan menerapkannya ke destinasi. Topik ini menggunakan contoh sinkronisasi dari Kafka ke MaxCompute untuk menjelaskan proses konfigurasinya.
Prasyarat
Persiapkan Sumber Data
Buat sumber data sumber dan destinasi. Untuk informasi selengkapnya, lihat Manajemen Sumber Data.
Pastikan sumber data mendukung sinkronisasi real-time. Untuk informasi selengkapnya, lihat Sumber data yang didukung dan solusi sinkronisasi.
Beberapa sumber data, seperti Hologres dan Oracle, mengharuskan Anda mengaktifkan logging. Metode pengaktifan log bervariasi tergantung pada sumber datanya. Untuk informasi selengkapnya, lihat Daftar sumber data.
Resource Group: Beli dan konfigurasikan Resource Group Serverless.
Konektivitas Jaringan: Selesaikan konfigurasi konektivitas jaringan antara Resource Group dan sumber data.
Langkah 1: Buat tugas sinkronisasi
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih Wilayah yang diinginkan. Di panel navigasi kiri, pilih . Pada halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down lalu klik Go to Data Integration.
Di panel navigasi kiri, klik Sync Tasks. Di bagian atas halaman, klik Create Synchronization Task dan konfigurasikan parameter tugas. Topik ini menggunakan contoh sinkronisasi data dari Kafka ke MaxCompute.
Source type:
Kafka.Destination type:
MaxCompute.Task type:
Single-table Real-time.Synchronization Mode:
Schema Migration: Secara otomatis membuat objek basis data (seperti tabel, Fields, dan tipe data) di destinasi yang sesuai dengan sumber, tetapi tidak termasuk data.
Incremental Sync (Opsional): Setelah Full Synchronization selesai, langkah ini secara berkelanjutan menangkap perubahan data (penyisipan, pembaruan, dan penghapusan) dari sumber dan menyinkronkannya ke destinasi.
Jika sumbernya adalah Hologres, Full Synchronization juga didukung, artinya data yang sudah ada pertama-tama disinkronkan sepenuhnya ke tabel destinasi, diikuti oleh Incremental Synchronization otomatis.
Untuk informasi lebih lanjut tentang sumber data yang didukung dan solusi sinkronisasi, lihat Sumber data yang didukung dan solusi sinkronisasi.
Langkah 2: Konfigurasikan sumber data dan resource runtime
Untuk Source Information, pilih sumber data
Kafkayang telah dikonfigurasi. Untuk Destination, pilih sumber dataMaxComputeyang telah dikonfigurasi.Pada bagian Running Resources, pilih Resource Group untuk Tugas Sinkronisasi dan alokasikan Resource Group CUs untuk tugas tersebut. Anda dapat mengatur CUs secara terpisah untuk Full Synchronization dan Incremental Synchronization guna mengontrol resource secara tepat dan mencegah pemborosan. Jika Tugas Sinkronisasi Anda mengalami error out-of-memory (OOM) akibat resource yang tidak mencukupi, tingkatkan nilai CU untuk Resource Group tersebut.
Pastikan kedua sumber data, baik sumber maupun destinasi, lulus Connectivity Check.
Langkah 3: Konfigurasikan rencana sinkronisasi
1. Konfigurasikan sumber
Pada tab Configuration, pilih topik dalam sumber data Kafka yang ingin Anda sinkronkan.
Anda dapat menggunakan nilai default untuk pengaturan lainnya atau memodifikasinya sesuai kebutuhan. Untuk detail parameter, lihat dokumentasi resmi Kafka.
Klik Data Sampling di pojok kanan atas.
Pada kotak dialog yang muncul, tentukan Start time dan Sampled Data Records, lalu klik Start Collection. Ini akan mengambil sampel data dari topik Kafka yang ditentukan dan memungkinkan Anda melihat pratinjau data, yang menjadi masukan untuk pratinjau data dan konfigurasi visual pada node Pemrosesan data berikutnya.
Pada tab Configure Output Field, pilih Fields yang ingin Anda sinkronkan.
Secara default, Kafka menyediakan enam Fields.
Parameter
Description
__key__
The key of the Kafka record.
__value__
The value of the Kafka record.
__partition__
The partition number where the Kafka record is located. Partition numbers are integers starting from 0.
__headers__
The headers of the Kafka record.
__offset__
The Offset of the Kafka record in its partition. Offsets are integers starting from 0.
__timestamp__
The 13-digit integer millisecond Timestamp of the Kafka record.
Anda juga dapat melakukan transformasi lebih lanjut pada Fields ini di node Pemrosesan data.
2. Pemrosesan data
Aktifkan Data Processing. Tersedia lima metode pemrosesan data: Data Masking, String Replace, Data Filtering, JSON Parsing, dan Edit and Assign Fields. Anda dapat mengatur urutan langkah-langkah ini secara bebas. Saat runtime, langkah-langkah pemrosesan dijalankan sesuai urutan yang ditentukan.

Setelah mengonfigurasi setiap node pemrosesan data, klik Preview Data Output di pojok kanan atas.
Tabel di bawah data masukan menampilkan hasil dari langkah Data Sampling. Anda dapat mengklik Re-obtain Output of Ancestor Node untuk memperbarui hasilnya.
Jika tidak ada output hulu, Anda dapat menggunakan Manually Construct Data untuk mensimulasikan output sebelumnya.
Klik Preview untuk melihat output dari tahap hulu setelah diproses oleh komponen Pemrosesan data.

Pratinjau output data dan pemrosesan data sangat bergantung pada Data Sampling dari sumber Kafka. Sebelum mengonfigurasi pemrosesan data, Anda harus menyelesaikan pengambilan sampel data terlebih dahulu pada konfigurasi sumber Kafka.
3. Konfigurasikan destinasi
Pada area Destination, pilih kelompok sumber daya Tunnel. Secara default, "Public transfer resources" dipilih, yang mengacu pada kuota gratis untuk MaxCompute.
Pilih apakah akan menulis ke tabel baru atau tabel yang sudah ada. Pilih Create atau Use Existing Table.
Jika Anda memilih membuat tabel baru, tabel dengan skema yang sama dengan sumber akan dibuat secara default. Anda dapat memodifikasi nama dan skema tabel destinasi secara manual.
Jika Anda memilih menggunakan tabel yang sudah ada, pilih tabel target dari daftar drop-down.
(Opsional) Edit skema tabel.
Klik ikon edit di sebelah nama tabel untuk mengedit skema tabel. Anda dapat mengklik Re-generate Table Schema Based on Output Column of Ancestor Node untuk menghasilkan skema secara otomatis berdasarkan kolom output dari node hulu. Anda kemudian dapat memilih Field dalam skema yang dihasilkan secara otomatis sebagai Primary Key.
4. Konfigurasikan pemetaan field
Setelah memilih sumber dan destinasi, Anda harus menentukan pemetaan antara Fields sumber dan Fields destinasi. Tugas akan menulis data dari Fields sumber ke Fields destinasi yang sesuai berdasarkan Pemetaan Field tersebut.
Sistem secara otomatis menghasilkan pemetaan antara Fields hulu dan Fields tabel target berdasarkan aturan Same Name Mapping. Anda dapat menyesuaikan pemetaan sesuai kebutuhan. Anda dapat memetakan satu Field hulu ke beberapa Fields tabel target, tetapi tidak boleh memetakan beberapa Fields hulu ke satu Field tabel target. Jika suatu Field hulu tidak dipetakan ke kolom tabel target, data dari Field tersebut tidak akan ditulis ke tabel target.
Anda dapat mengonfigurasi JSON Parsing khusus untuk Fields Kafka. Gunakan komponen pemrosesan data untuk mengekstrak konten field value guna konfigurasi field yang lebih detail.

Konfigurasikan partisi (Opsional).
Automatic Time-based Partitioning membuat partisi berdasarkan Field waktu bisnis (dalam kasus ini,
__timestamp__). Partisi tingkat pertama berdasarkan tahun, tingkat kedua berdasarkan bulan, dan seterusnya.Dynamic Partitioning by Field Content menulis baris data dari Field sumber tertentu ke partisi yang sesuai dalam tabel MaxCompute dengan menentukan pemetaan antara Field sumber dan Field partisi target.
Langkah 4: Konfigurasikan parameter lanjutan
Tugas Sinkronisasi menyediakan parameter lanjutan untuk konfigurasi detail halus. Sistem menyediakan nilai default, dan biasanya Anda tidak perlu mengubahnya. Jika diperlukan, ikuti langkah-langkah berikut:
Di pojok kanan atas antarmuka, klik Advanced Settings untuk membuka halaman konfigurasi Advanced Parameters.
CatatanParameter lanjutan untuk pengembangan data terletak di tab kanan antarmuka konfigurasi tugas.
Anda dapat mengatur parameter untuk reader dan writer Tugas Sinkronisasi secara terpisah. Untuk menyesuaikan Runtime settings, atur Auto-configure Runtime Settings ke false.
Ubah nilai parameter berdasarkan tooltip dan deskripsinya. Untuk rekomendasi konfigurasi beberapa parameter, lihat Advanced parameters for real-time Synchronization.
Untuk menghindari error tak terduga atau masalah kualitas data, ubah parameter ini hanya jika Anda benar-benar memahami tujuan dan konsekuensinya.
Langkah 5: Jalankan uji coba
Setelah menyelesaikan semua konfigurasi tugas, klik Perform Simulated Running di pojok kiri bawah untuk men-debug tugas. Ini mensimulasikan seluruh proses tugas dalam memproses sampel data kecil dan memungkinkan Anda melihat pratinjau hasil untuk tabel target. Jika terdapat kesalahan konfigurasi, pengecualian selama Test Run, atau Dirty Data, sistem akan memberikan umpan balik secara real-time. Hal ini membantu Anda menilai kebenaran konfigurasi tugas dengan cepat dan menentukan apakah hasilnya sesuai harapan.
Pada kotak dialog yang muncul, atur parameter pengambilan sampel (Start time dan Sampled Data Records).
Klik Start Collection untuk mendapatkan data sampel.
Klik Preview Result untuk mensimulasikan eksekusi tugas dan melihat hasil outputnya.
Output dari Test Run hanya untuk pratinjau dan tidak ditulis ke sumber data destinasi. Ini tidak memengaruhi data produksi.
Langkah 6: Publikasikan dan jalankan tugas
Setelah menyelesaikan semua konfigurasi, klik Save di bagian bawah halaman.
Tugas Data Integration harus dipublikasikan ke lingkungan produksi agar dapat dijalankan. Oleh karena itu, baik saat membuat tugas baru maupun mengedit tugas yang sudah ada, Anda harus melakukan operasi Deploy agar perubahan berlaku. Selama publikasi, jika Anda memilih Start immediately after deployment, tugas akan otomatis dimulai setelah dipublikasikan. Jika tidak, setelah publikasi, Anda perlu membuka halaman dan menjalankan tugas secara manual dari kolom Actions.
Pada Tasks, klik Name/ID tugas yang sesuai untuk melihat proses eksekusi secara detail.
Langkah 7: Konfigurasikan aturan notifikasi
Setelah tugas dipublikasikan dan berjalan, Anda dapat mengonfigurasi Aturan Notifikasi untuknya. Hal ini memungkinkan Anda menerima pemberitahuan segera jika terjadi pengecualian, sehingga menjamin stabilitas dan ketepatan waktu lingkungan produksi Anda. Pada daftar Tugas Data Integration, klik di kolom Actions untuk tugas target.
1. Tambahkan aturan notifikasi
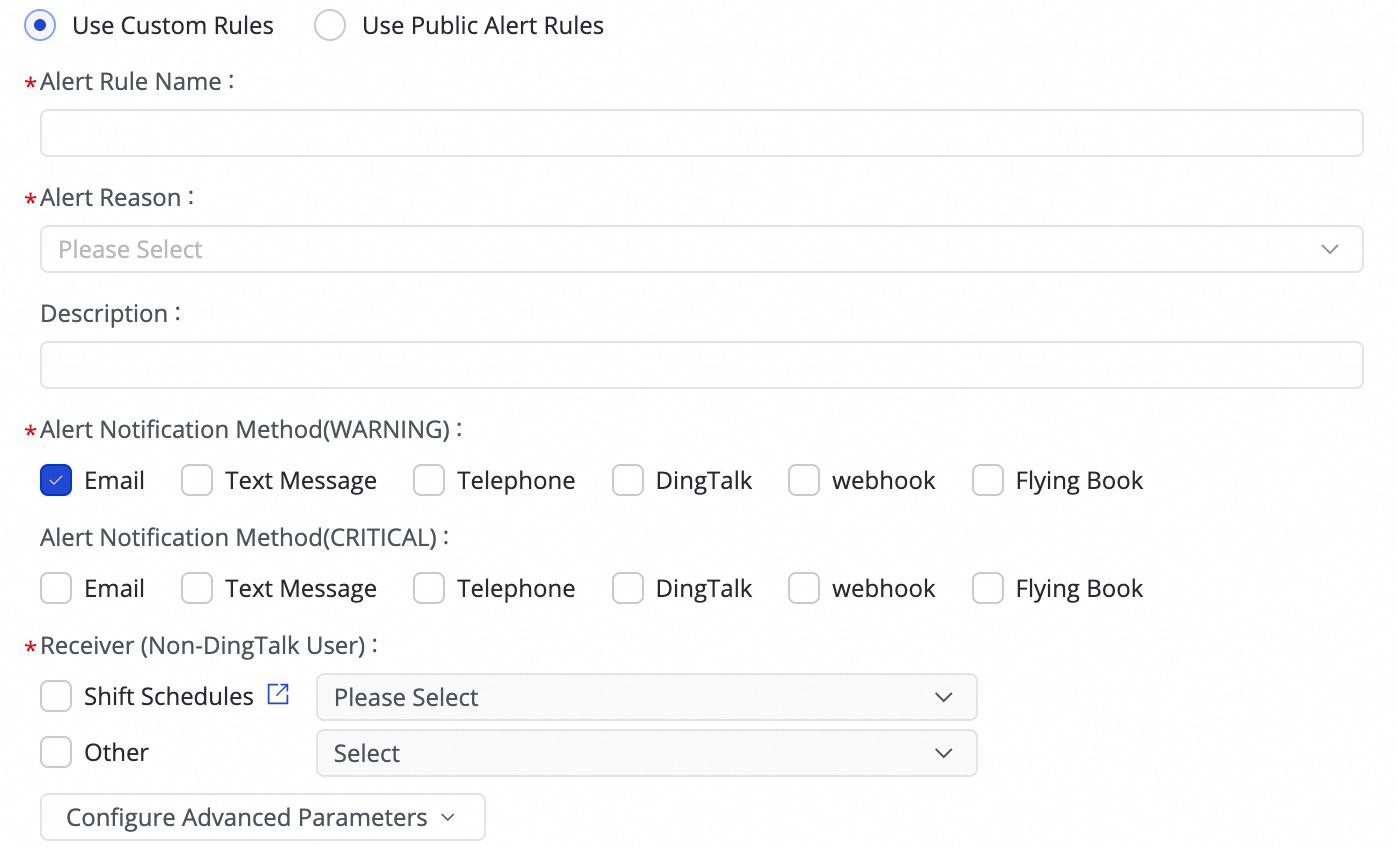
(1) Klik Create Rule untuk mengonfigurasi Aturan Notifikasi.
Dengan mengatur Alert Reason, Anda dapat memantau metrik seperti Business delay, Failover, Task status, DDL Notification, dan Task Resource Utilization. Anda dapat mengatur notifikasi level CRITICAL atau WARNING berdasarkan ambang batas tertentu.
Setelah mengatur metode notifikasi, Anda dapat menggunakan Configure Advanced Parameters untuk mengontrol interval pengiriman pesan notifikasi. Hal ini mencegah notifikasi berlebihan yang dapat memboroskan sumber daya dan menyebabkan penumpukan.
Jika kondisi notifikasi diatur ke Business delay, Task status, atau Task Resource Utilization, Anda juga dapat mengaktifkan notifikasi pemulihan untuk memberi tahu penerima ketika tugas kembali normal.
(2) Kelola aturan notifikasi.
Untuk Aturan Notifikasi yang telah dibuat, Anda dapat menggunakan sakelar notifikasi untuk mengaktifkan atau menonaktifkannya. Anda juga dapat mengirim notifikasi kepada personel yang berbeda berdasarkan tingkat keparahan notifikasi.
2. Lihat notifikasi
Pada daftar tugas, klik dan buka tab Alert Events untuk melihat riwayat notifikasi yang dipicu.
Langkah selanjutnya
Setelah tugas dimulai, Anda dapat mengklik nama tugas untuk melihat detail eksekusinya terkait Operasi, maintenance, dan optimasi Tugas.
FAQ
Untuk pertanyaan umum tentang Tugas Sinkronisasi Real-time, lihat FAQ tentang sinkronisasi real-time.
Contoh lainnya
Sinkronisasi real-time tabel tunggal dari Kafka ke ApsaraDB for OceanBase
Ingesti real-time tabel tunggal dari Log Service (SLS) ke Data Lake Formation
Sinkronisasi real-time tabel tunggal dari Hologres ke Doris
Sinkronisasi real-time tabel tunggal dari Hologres ke Hologres
Sinkronisasi real-time tabel tunggal dari Kafka ke Hologres
Sinkronisasi real-time tabel tunggal dari Log Service (SLS) ke Hologres
Sinkronisasi real-time tabel tunggal dari Kafka ke Hologres
Sinkronisasi real-time tabel tunggal dari Hologres ke Kafka
Sinkronisasi real-time tabel tunggal dari Log Service (SLS) ke MaxCompute
Sinkronisasi real-time tabel tunggal dari Kafka ke data lake OSS
Sinkronisasi real-time tabel tunggal dari Kafka ke StarRocks
Sinkronisasi real-time tabel tunggal dari Oracle ke Tablestore