Data Integration mendukung sinkronisasi real-time tabel tunggal dari sumber data seperti DataHub, Kafka, dan LogHub ke MaxCompute. Panduan ini memandu Anda dalam membuat dan menjalankan tugas Single Logstore Realtime Sync untuk menyinkronkan data real-time dari logstore LogHub (SLS) ke MaxCompute di Konsol DataWorks.
Prasyarat
Sebelum memulai, pastikan Anda telah:
-
Memiliki grup sumber daya Serverless atau grup sumber daya eksklusif untuk Data Integration. Lihat Serverless resource group dan Exclusive resource group for Data Integration.
-
Memiliki sumber data LogHub (SLS) dan sumber data MaxCompute. Lihat Data Source Configuration.
-
Memiliki konektivitas jaringan antara grup sumber daya dan kedua sumber data tersebut. Lihat Overview of network connection solutions.
Batasan
Sinkronisasi data sumber ke tabel eksternal MaxCompute tidak didukung.
Buat dan konfigurasikan tugas sinkronisasi
Wizard pembuatan terdiri dari delapan langkah. Langkah 4, 5, dan 6 bersifat opsional dan dapat dikunjungi ulang setelah tugas disimpan.
Langkah 1: Pilih jenis tugas sinkronisasi
-
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Di panel navigasi kiri, pilih Data Integration > Data Integration. Pada halaman yang muncul, pilih ruang kerja Anda dari daftar drop-down dan klik Go to Data Integration.
-
Di panel navigasi, klik Synchronization Task. Di bagian atas halaman, klik Create Synchronization Task dan konfigurasikan hal berikut:
-
Source:
LogHub -
Destination:
MaxCompute -
Task Name: Masukkan nama untuk tugas sinkronisasi.
-
Task Type:
Single Logstore Realtime Sync
-
Langkah 2: Konfigurasi jaringan dan sumber daya
-
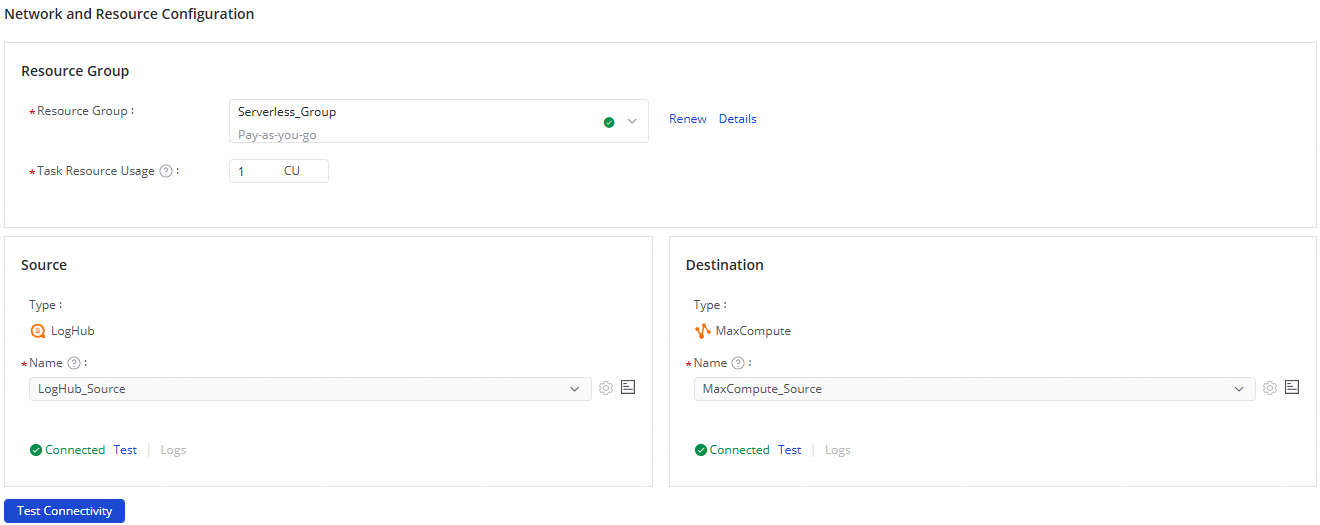
Di bagian Network and Resource Configuration, pilih Resource Group untuk tugas sinkronisasi. Untuk Task Resource Usage, alokasikan CUs (Compute Units) sesuai kebutuhan Anda.
-
Atur Source ke sumber data LogHub (SLS) Anda dan Destination ke sumber data MaxCompute Anda, lalu klik Test Connectivity.
-
Setelah memastikan kedua sumber data terhubung, klik Next.
Langkah 3: Konfigurasi tautan sinkronisasi
Tautan sinkronisasi terdiri dari tiga bagian: sumber SLS, node pemrosesan data opsional, dan tujuan MaxCompute. Konfigurasikan masing-masing secara berurutan.
Konfigurasi sumber SLS
Klik sumber SLS di bagian atas halaman untuk membuka panel Source Information.

-
Di bagian Source Information, pilih logstore yang akan disinkronkan.
-
Di pojok kanan atas, klik Data Sampling. Tentukan Start Time dan Sampled Data Records, lalu klik Start Collection. Ini mengambil sampel data dari logstore dan menghasilkan pratinjau untuk mengonfigurasi node downstream.
-
Setelah Anda memilih logstore, bidang-bidangnya dimuat secara otomatis ke bagian Configure Output Field. Sesuaikan Data Type, hapus bidang menggunakan Delete, atau tambahkan bidang baru dengan Add Output Field sesuai kebutuhan.
Jika bidang yang dikonfigurasi tidak ada di SLS, nilainya dikeluarkan sebagai NULL ke node downstream.
Tambahkan node pemrosesan data (opsional)
Klik ikon ![]() untuk menyisipkan node pemrosesan data di antara sumber dan tujuan. Metode berikut tersedia:
untuk menyisipkan node pemrosesan data di antara sumber dan tujuan. Metode berikut tersedia:
| Method | When to use |
|---|---|
| Data Masking | Anonimkan bidang sensitif sebelum menulis ke tujuan |
| Replace String | Temukan dan ganti nilai string dalam suatu bidang |
| Data Filtering | Saring catatan yang tidak sesuai dengan kondisi yang ditentukan |
| JSON Parsing | Ekstrak bidang dari kolom berformat JSON |
| Edit Field and Assign Value | Tambahkan kolom turunan atau timpa nilai bidang |
Atur urutan node sesuai alur pemrosesan data yang diinginkan. Saat waktu proses, data mengalir melalui node sesuai urutan yang Anda tentukan.
Untuk memverifikasi output node, klik Preview Data Output di pojok kanan atas, lalu klik Re-obtain Output of Ancestor Node untuk mensimulasikan output dari data log sampel.
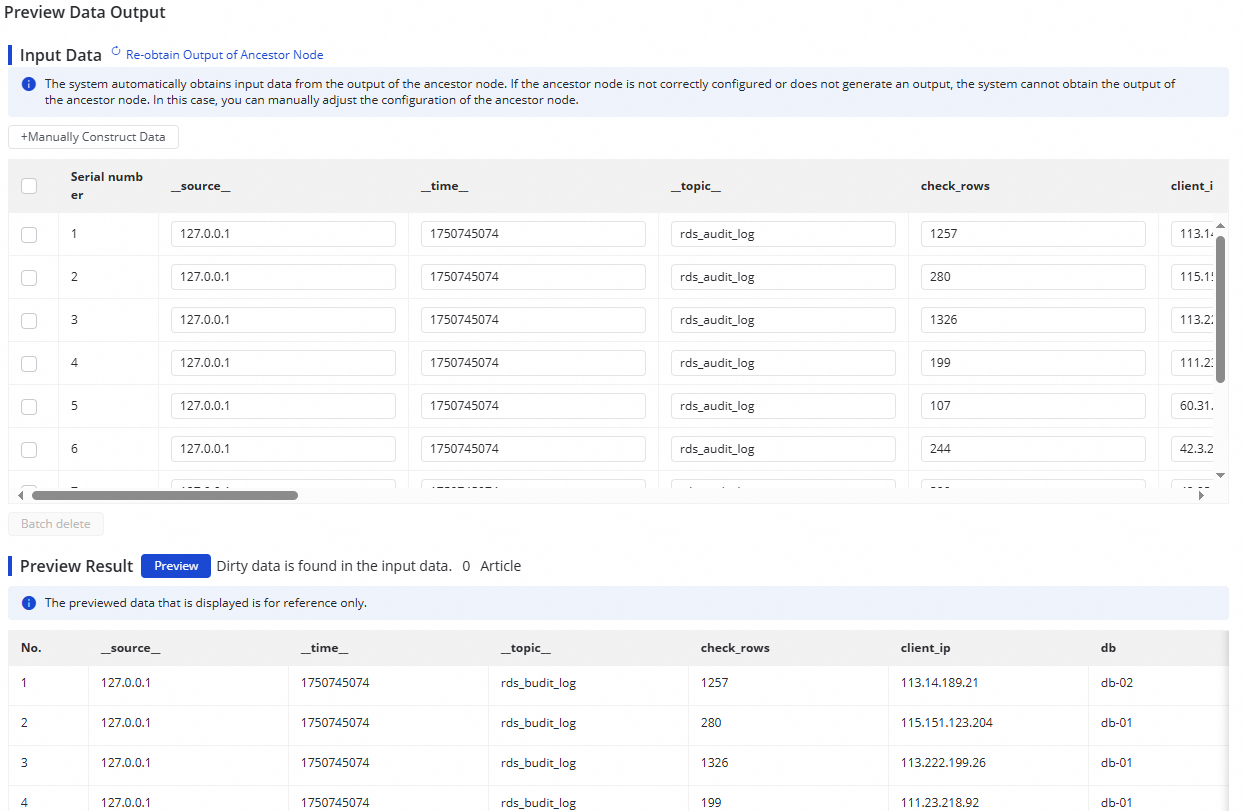
Pratinjau output data memerlukan Data Sampling yang telah diselesaikan pada sumber SLS. Selesaikan pengambilan sampel data terlebih dahulu jika pratinjau tidak tersedia.
Konfigurasi tujuan MaxCompute
Klik tujuan MaxCompute di bagian atas halaman untuk membuka panel Destination Information.

-
Di area Destination Information, pilih cara membuat tabel tujuan:
-
Create tables automatically: Tabel dibuat dengan nama yang sama seperti tabel sumber. Ubah nama jika diperlukan.
-
Use Existing Table: Pilih tabel yang sudah ada dari daftar drop-down.
-
-
(Opsional) Edit skema tabel tujuan. Jika Anda memilih Create tables automatically, klik Edit Table Schema untuk menyesuaikan skema. Klik Re-generate Table Schema Based on Output Column of Ancestor Node untuk mengisi skema dari kolom output node hulu. Pilih kolom dan tandai sebagai primary key.
Tabel tujuan harus memiliki primary key. Konfigurasi tugas tidak dapat disimpan tanpa primary key.
-
Tinjau pemetaan bidang. Setelah konfigurasi tujuan selesai, sistem memetakan bidang berdasarkan nama secara otomatis (Map Fields with Same Name). Sesuaikan pemetaan sesuai kebutuhan. Satu bidang sumber dapat dipetakan ke beberapa bidang tujuan, tetapi beberapa bidang sumber tidak dapat dipetakan ke bidang tujuan yang sama. Bidang sumber yang tidak dipetakan tidak akan disinkronkan.
-
Pilih metode partisi:
-
Automatic Time-based Partitioning: Mempartisi data berdasarkan waktu secara otomatis.
-
Dynamic Partitioning By Field Value: Mempartisi data berdasarkan nilai bidang tertentu.
-
Langkah 4: Konfigurasi aturan peringatan (opsional)
Konfigurasikan aturan peringatan sebelum memulai tugas. Ketika peringatan diatur sejak awal, mendeteksi dan mendiagnosis kegagalan pengiriman menjadi jauh lebih mudah.
Siapkan aturan peringatan untuk menerima notifikasi ketika tugas sinkronisasi mengalami masalah yang dapat menyebabkan latensi data.
-
Di pojok kanan atas halaman konfigurasi, klik Configure Alert Rule untuk membuka panel Alert Rule Configurations for Real-time Synchronization Subnode.
-
Klik Add Alert Rule dan konfigurasikan parameter peringatan.
Aturan peringatan yang dikonfigurasi di sini berlaku untuk subtugas sinkronisasi real-time yang dihasilkan oleh tugas sinkronisasi ini. Setelah tugas sinkronisasi disimpan, Anda juga dapat mengubah aturan peringatan dari halaman Real-time Synchronization Task. Lihat Run and manage real-time synchronization tasks.
-
Aktifkan atau nonaktifkan aturan peringatan sesuai kebutuhan. Tetapkan penerima peringatan yang berbeda berdasarkan tingkat keparahan.
Langkah 5: Konfigurasi parameter lanjutan (opsional)
Klik Configure Advanced Parameters di pojok kanan atas untuk melihat dan mengubah nilai konfigurasi lanjutan.
Pahami dampak setiap parameter sebelum mengubah nilainya untuk menghindari error tak terduga atau masalah kualitas data.
Langkah 6: Tinjau pengaturan grup sumber daya (opsional)
Klik Configure Resource Group di pojok kanan atas untuk melihat atau mengubah grup sumber daya yang ditugaskan untuk tugas sinkronisasi ini.
Langkah 7: Jalankan uji simulasi
Sebelum memulai tugas, jalankan uji simulasi untuk memvalidasi konfigurasi Anda terhadap data sampel.
-
Klik Perform Simulated Running di pojok kanan atas.
-
Di kotak dialog, atur waktu Start At dan jumlah Sampled Data Records, lalu klik Start Collection untuk mengambil sampel data dari sumber.
-
Klik Preview untuk mendorong data sampel hingga ke tabel tujuan.
Jika konfigurasi tertentu dari tugas sinkronisasi tidak valid, terjadi pengecualian selama uji coba, atau data kotor dihasilkan, sistem melaporkan error secara real time. Hal ini membantu Anda memeriksa konfigurasi tugas sinkronisasi dan menentukan apakah hasil yang diharapkan dapat diperoleh sedini mungkin.
Langkah 8: Mulai tugas sinkronisasi
-
Setelah menyelesaikan semua konfigurasi, klik Complete di bagian bawah halaman.
-
Buka Data Integration > Synchronization Task. Temukan tugas yang telah Anda buat dan klik Start di kolom Operation.
-
Klik Name or ID tugas di bagian Tasks untuk melihat progres eksekusi detail.
Monitor dan kelola tugas sinkronisasi
Lihat status tugas yang sedang berjalan
Setelah membuat tugas sinkronisasi, pantau statusnya dari halaman Synchronization Task.

Gunakan kolom Actions untuk Start atau Stop tugas. Klik More untuk operasi tambahan, termasuk Edit dan View.
Bagian Execution Overview menampilkan status berjalan. Klik tugas untuk melihat detail eksekusi.
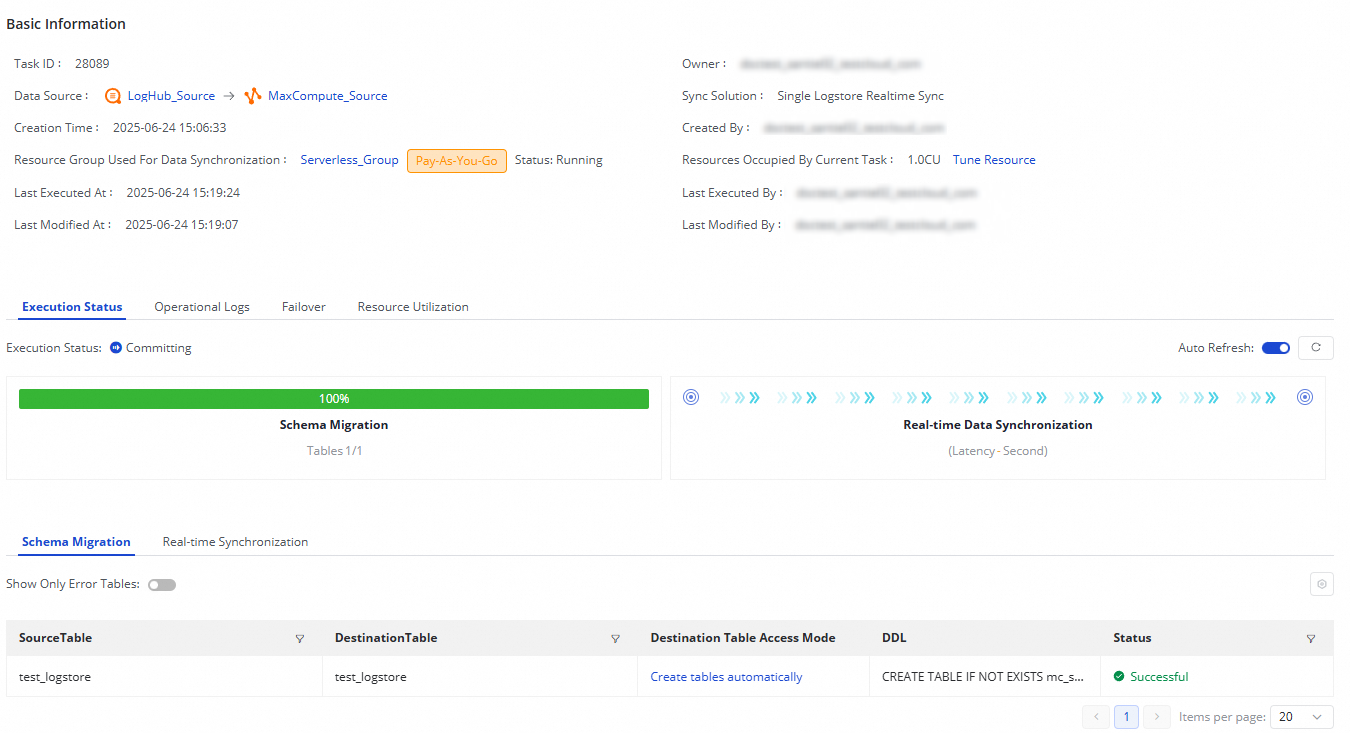
Setiap tugas sinkronisasi dari LogHub (SLS) ke MaxCompute berjalan melalui dua tahap:
-
Schema Migration: Memastikan apakah tabel yang sudah ada digunakan atau tabel baru dibuat. Jika pemilihan pembuatan tabel otomatis dipilih, pernyataan Data Definition Language (DDL) untuk tabel tersebut ditampilkan di sini.
-
Real-time Data Synchronization: Menampilkan statistik kinerja, informasi waktu proses real-time, catatan DDL, dan detail peringatan.
Jalankan ulang tugas sinkronisasi
Jalankan ulang tugas sinkronisasi ketika Anda perlu mengubah bidang yang disinkronkan, bidang tabel tujuan, atau nama tabel. Sistem hanya menyinkronkan perubahan — data yang telah disinkronkan dan tidak berubah tidak diproses ulang.
Dua metode jalankan ulang tersedia:
-
Rerun without changes: Klik Rerun di kolom Operation untuk menjalankan ulang tugas dengan konfigurasi saat ini.
-
Rerun after changes: Ubah konfigurasi tugas dan klik Complete. Lalu klik Apply Updates di kolom Operation untuk menjalankan ulang dengan konfigurasi yang diperbarui.