Topik ini menjelaskan cara melakukan sinkronisasi data offline dari seluruh database MySQL ke Hive. Contoh ini menggunakan MySQL sebagai sumber dan Hive sebagai tujuan.
Prasyarat
Beli resource group arsitektur tanpa server atau grup sumber daya eksklusif untuk Data Integration.
Buat sumber data MySQL dan sumber data Hive. Untuk informasi lebih lanjut, lihat Konfigurasi sumber data.
Buat koneksi jaringan antara kelompok sumber daya dan sumber data. Untuk informasi lebih lanjut, lihat Ikhtisar solusi konektivitas jaringan.
Prosedur
1. Pilih jenis tugas sinkronisasi
Buka halaman Data Integration.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Di panel navigasi sebelah kiri, pilih . Di halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down lalu klik Go to Data Integration.
Di panel navigasi sebelah kiri, klik Synchronization Task. Di bagian atas halaman, klik Create Synchronization Task untuk membuka halaman pembuatan tugas. Konfigurasikan informasi dasar berikut.
Source and Destination:
MySQL→HiveNew Task Name: Masukkan nama untuk tugas sinkronisasi.
Synchronization Type:
Entire Database Offline.Synchronization Steps: Pilih Full Synchronization dan Incremental Synchronization.
2. Konfigurasi jaringan dan sumber daya
Di bagian Network and Resource Configuration, pilih Resource Group untuk tugas sinkronisasi. Anda juga dapat menentukan jumlah CU untuk Task Resource Usage.
Atur Source Data Source menjadi sumber data
MySQLdan Destination Data Source menjadi sumber dataHive. Lalu, klik Test Connectivity.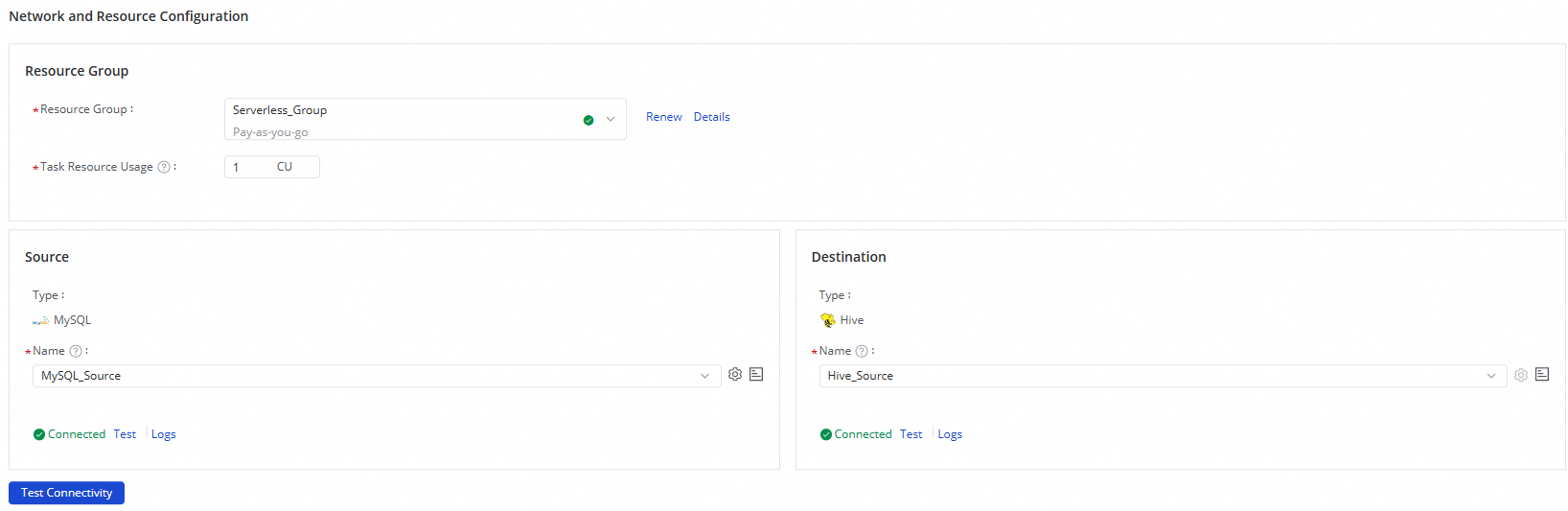
Setelah pengujian konektivitas untuk sumber data dan tujuan berhasil, klik Next.
3. Pilih database dan tabel yang akan disinkronkan
Di area Source Table, pilih tabel yang akan disinkronkan dari sumber data. Klik ikon ![]() untuk memindahkan tabel ke daftar Selected Tables.
untuk memindahkan tabel ke daftar Selected Tables.

4. Atur properti database tujuan
Operasi ini memengaruhi skema tabel baru yang dibuat oleh Data Integration. Skema tabel yang sudah ada tidak terpengaruh.
Storage Mode For New Tables: Anda dapat memilih Internal Table atau External Table untuk menentukan apakah tabel tujuan baru merupakan tabel internal atau eksternal.
Format For New Tables: Anda dapat memilih parquet, orc, atau txt untuk menentukan format penyimpanan tabel tujuan baru.
Write Mode: Menentukan apakah akan mengosongkan tabel tujuan atau mempertahankan data historis selama operasi penulisan.
Partition Initialization Settings: Menentukan nilai partisi awal untuk tabel baru. Secara default, hanya partisi hash yang dibuat. Anda dapat mengklik tombol konfigurasi untuk mengubah pengaturan ini.
5. Konfigurasi sinkronisasi penuh dan inkremental
Konfigurasikan jenis sinkronisasi penuh dan inkremental untuk tugas.
Jika Anda memilih Full Sync dan Incremental Sync di Sync Step, tugas secara default akan melakukan sinkronisasi penuh satu kali dan sinkronisasi inkremental berulang. Pengaturan ini tidak dapat diubah.
Jika Anda memilih Full Sync di Sync Step, Anda dapat mengonfigurasi tugas untuk sinkronisasi penuh satu kali atau sinkronisasi penuh berulang.
Jika Anda memilih Incremental Sync di Sync Step, Anda dapat mengonfigurasi tugas sebagai sinkronisasi inkremental satu kali atau berulang.
CatatanLangkah-langkah berikut menggunakan contoh tugas sinkronisasi penuh satu kali dan sinkronisasi inkremental berulang.
Konfigurasikan parameter penjadwalan berulang.
Jika Anda ingin tugas dijalankan sesuai jadwal berulang, klik Recurring Schedule Parameters.
6. Konfigurasi pemetaan tabel tujuan
Setelah Anda memilih tabel yang akan disinkronkan pada langkah sebelumnya, tabel tersebut akan ditampilkan secara otomatis di halaman ini. Tabel tujuan memiliki status 'mapping to be refreshed'. Anda harus menentukan pemetaan antara tabel sumber dan tabel tujuan, yang menentukan cara data dibaca dari tabel sumber dan ditulis ke tabel tujuan. Lalu, klik Refresh Mapping untuk melanjutkan. Anda dapat langsung merefresh pemetaan atau menyesuaikan aturan tabel tujuan terlebih dahulu.
Pilih tabel yang akan disinkronkan lalu klik Batch Refresh Mapping. Jika aturan pemetaan belum dikonfigurasi, sistem akan menerapkan aturan penamaan default untuk tabel tujuan:
${SourceDatabaseName}_${TableName}. Jika tabel dengan nama yang ditentukan tidak ada di tujuan, tabel tersebut akan dibuat secara otomatis.Karena tugas ini dijalankan sesuai jadwal berulang, Anda harus mengonfigurasi properti penjadwalannya. Properti ini mencakup Scheduling Cycle, Effective Date, dan Skip Execution. Konfigurasi penjadwalan untuk tugas sinkronisasi ini sama dengan konfigurasi penjadwalan node di Data Development. Untuk informasi lebih lanjut, lihat Node scheduling.
Berdasarkan Sync Step yang dipilih, atur Incremental Condition dan Full Condition. Kondisi ini menerapkan klausa WHERE untuk memfilter data sumber. Masukkan hanya isi klausa, bukan kata kunci WHERE. Jika Anda mengaktifkan jadwal berulang, Anda dapat menggunakan parameter sistem.
Di kolom Custom Destination Database Name Mapping, klik Configure untuk menyesuaikan aturan penamaan database tujuan.
Anda dapat menggunakan variabel bawaan dan string yang dimasukkan secara manual untuk membuat nama database tujuan. Anda juga dapat mengedit variabel bawaan tersebut. Misalnya, Anda dapat membuat aturan penamaan database baru yang menambahkan akhiran ke nama database sumber untuk membentuk nama database tujuan.
Di kolom Custom Destination Table Name Mapping, klik Edit untuk menyesuaikan aturan penamaan tabel tujuan.
Anda dapat menggunakan variabel bawaan dan string yang dimasukkan secara manual untuk membuat nama tabel tujuan. Anda juga dapat mengedit variabel bawaan tersebut. Misalnya, Anda dapat membuat aturan penamaan tabel baru yang menambahkan akhiran ke nama tabel sumber untuk membentuk nama tabel tujuan.
1. Edit pemetaan tipe field
Tugas sinkronisasi secara default memetakan tipe field sumber ke tipe field tujuan. Untuk menyesuaikan pemetaan ini, klik Edit Field Type Mapping di pojok kanan atas tabel. Setelah Anda mengonfigurasi pemetaan, klik Apply And Refresh Mapping.
2. Edit skema tabel tujuan dan tetapkan nilai field
Jika tabel tujuan memiliki status To Be Created, Anda dapat menambahkan field ke skemanya. Ikuti langkah-langkah berikut:
Tambahkan field ke tabel tujuan.
Untuk menambahkan field ke satu tabel, klik tombol
 di kolom Target Table Name.
di kolom Target Table Name.Untuk menambahkan field secara batch, pilih semua tabel yang akan disinkronkan. Di bagian bawah tabel, pilih .
Tetapkan nilai ke field tersebut. Anda dapat menggunakan operasi berikut untuk menetapkan nilai ke field yang baru saja ditambahkan.
Untuk menetapkan nilai ke satu tabel: Di kolom Destination Table Field Assignment, klik Configure.
Untuk menetapkan nilai secara batch, di bagian bawah daftar, pilih untuk menetapkan nilai ke field yang identik di beberapa tabel tujuan.
CatatanAnda dapat menetapkan konstanta atau variabel. Klik ikon
 untuk beralih antara mode penetapan.
untuk beralih antara mode penetapan.
3. Sesuaikan parameter lanjutan
Untuk kontrol detail halus terhadap tugas, klik Configure di kolom Customize Advanced Parameters.
Ubah parameter ini hanya jika Anda benar-benar memahami fungsinya. Pengaturan yang salah dapat menyebabkan kesalahan tak terduga atau masalah kualitas data.
4. Atur kolom chunking sumber
Di kolom chunking sumber, Anda dapat memilih field dari tabel sumber dalam daftar drop-down atau memilih Do Not Chunk.
7. Konfigurasi parameter lanjutan
Tugas sinkronisasi menyediakan beberapa parameter yang dapat Anda ubah sesuai kebutuhan. Misalnya, Anda dapat membatasi jumlah maksimum koneksi untuk mencegah tugas sinkronisasi memberikan tekanan berlebihan pada database produksi Anda.
Ubah parameter ini hanya jika Anda benar-benar memahami fungsinya. Pengaturan yang salah dapat menyebabkan kesalahan tak terduga atau masalah kualitas data.
Di pojok kanan atas halaman, klik Advanced Parameter Configuration untuk membuka halaman konfigurasi parameter lanjutan.
Di halaman Advanced Parameter Configuration, ubah nilai parameter.
8. Konfigurasi kelompok sumber daya
Di pojok kanan atas halaman, klik Resource Group Configuration untuk melihat atau mengganti kelompok sumber daya untuk tugas saat ini.
9. Jalankan tugas sinkronisasi
Setelah selesai mengonfigurasi, klik Complete Configuration di bagian bawah halaman.
Di halaman , temukan tugas sinkronisasi yang telah dibuat lalu klik Start di kolom Actions.
Di Task List, klik Name/ID tugas untuk melihat detail eksekusi.
10. Konfigurasi peringatan
Setelah tugas dijalankan, pekerjaan terjadwal akan dibuat di Pusat Operasi. Untuk mencegah kesalahan tugas menyebabkan latensi sinkronisasi data, Anda dapat mengatur kebijakan alarm untuk tugas sinkronisasi tersebut.
Di Task List, temukan tugas sinkronisasi yang sedang berjalan. Di kolom Actions, pilih untuk membuka halaman pengeditan tugas.
Klik Next. Lalu, klik Alarm Configuration di pojok kanan atas halaman untuk membuka halaman pengaturan alarm.
Di kolom Scheduling Information, klik pekerjaan terjadwal untuk membuka halaman detail tugas di Pusat Operasi dan ambil Task ID.
Di panel navigasi sebelah kiri Pusat Operasi, pilih untuk membuka halaman Manajemen Aturan.
Klik Create Custom Rule dan atur Rule Object, Trigger Method, dan Alarm Behavior. Untuk informasi lebih lanjut, lihat Manajemen aturan.
Di bidang Rule Object, cari tugas target menggunakan Task ID yang diperoleh lalu atur peringatan.
O&M tugas sinkronisasi
Lihat status tugas
Setelah Anda membuat tugas sinkronisasi, Anda dapat melihat daftar tugas yang telah dibuat beserta informasi dasarnya di halaman tugas sinkronisasi.

Di kolom Actions, Anda dapat Start atau Stop tugas sinkronisasi. Di bawah More, Anda dapat melakukan operasi lain, seperti Edit dan View.
Di bagian Execution Overview, Anda dapat melihat status dasar tugas yang sedang berjalan dan mengklik area yang sesuai untuk melihat detail eksekusinya.
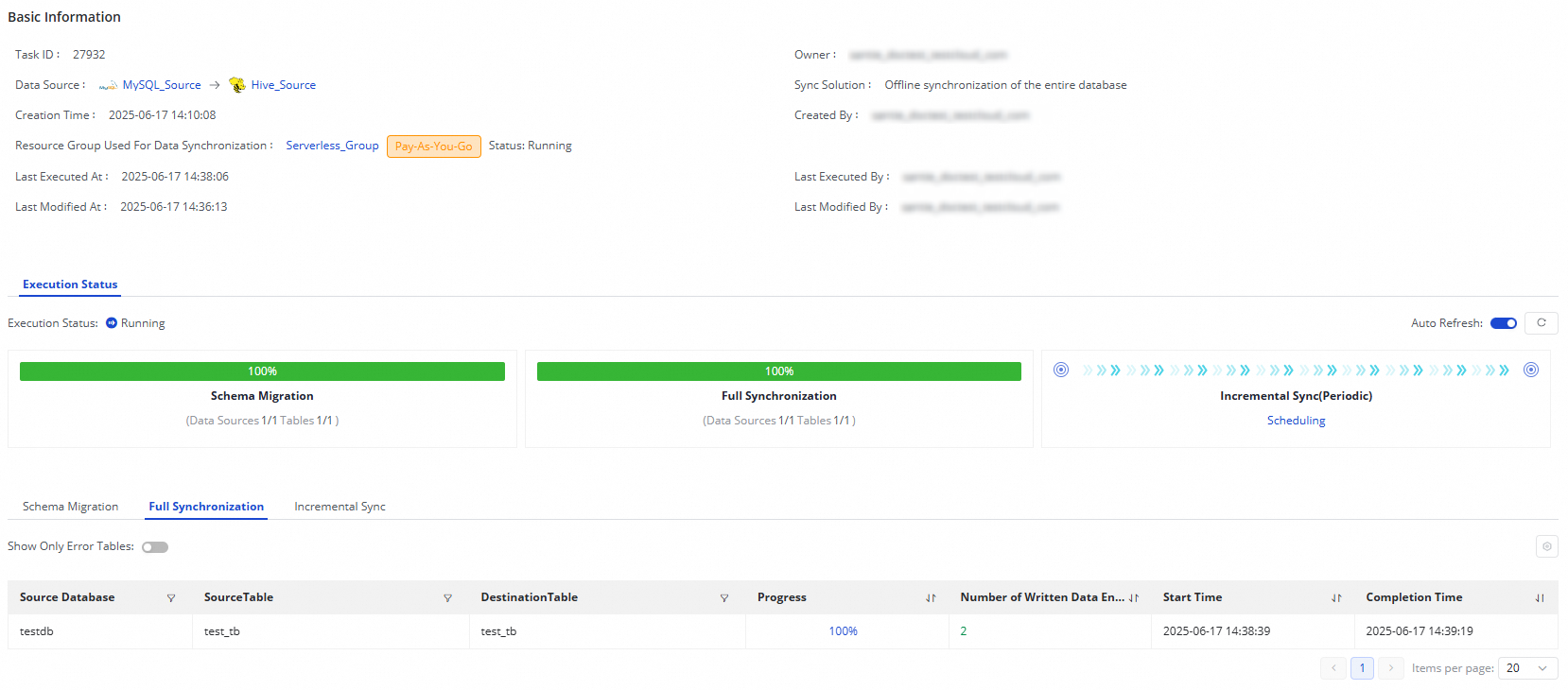
Untuk tugas sinkronisasi offline dari MySQL ke Hive:
Jika langkah sinkronisasi tugas Anda adalah Full Synchronization, migrasi skema dan sinkronisasi penuh akan ditampilkan.
Jika langkah sinkronisasi tugas Anda adalah Incremental Synchronization, migrasi skema dan sinkronisasi inkremental akan ditampilkan.
Jika langkah sinkronisasi tugas Anda adalah Full Synchronization + Incremental Synchronization, bagian ini menampilkan migrasi skema, sinkronisasi penuh, dan sinkronisasi inkremental.
Jalankan ulang tugas
Klik Rerun untuk menjalankan ulang tugas tanpa mengubah konfigurasi tugas.
Efek: Operasi ini menjalankan ulang tugas satu kali atau memperbarui properti tugas berulang.
Untuk menjalankan ulang tugas setelah memodifikasinya dengan menambahkan atau menghapus tabel, edit tugas tersebut lalu klik Complete. Status tugas kemudian berubah menjadi Apply Update. Klik Apply Update untuk segera memicu jalankan ulang tugas yang telah dimodifikasi.
Efek: Hanya tabel baru yang disinkronkan. Tabel yang sebelumnya telah disinkronkan tidak disinkronkan lagi.
Setelah Anda mengedit tugas (misalnya, dengan mengubah nama tabel tujuan atau beralih ke tabel tujuan berbeda) dan mengklik Complete, operasi yang tersedia untuk tugas berubah menjadi Apply Update. Klik Apply Update untuk segera memicu jalankan ulang tugas yang telah dimodifikasi.
Efek: Tabel yang dimodifikasi disinkronkan. Tabel yang tidak dimodifikasi tidak disinkronkan lagi.
Kasus penggunaan
Jika Anda memiliki dependensi data downstream dan perlu melakukan operasi pengembangan data, Anda dapat mengatur dependensi upstream dan downstream untuk node seperti yang dijelaskan dalam Node scheduling. Anda dapat melihat informasi node tugas berulang yang sesuai di kolom Recurring Configuration.
