Panduan ini menjelaskan cara meningkatkan efisiensi pengembangan melalui praktik rekayasa seperti penggunaan ulang kode, pemasangan dataset, dan manajemen parameter, serta praktik terbaik dan teknik debugging untuk menghubungkan ke mesin komputasi seperti MaxCompute Spark, EMR Serverless Spark, dan AnalyticDB for Spark.
Kami menyarankan Anda membaca Pengembangan notebook dasar terlebih dahulu.
Lingkungan pengembangan dan produksi
DataWorks Notebook adalah tool pengembangan dan analisis yang dapat dijadwalkan. Artinya, tool ini beroperasi dalam dua lingkungan runtime yang berbeda:
Lingkungan pengembangan: Di halaman pengeditan node notebook di DataStudio, Anda dapat menjalankan sel untuk mengeksekusi kode secara langsung dalam instans lingkungan pengembangan pribadi. Lingkungan ini digunakan untuk validasi dan debugging logika kode secara cepat.
Lingkungan produksi: Setelah Anda melakukan commit dan menerbitkan node notebook, eksekusinya dipicu oleh penjadwalan periodik, pengisian ulang data, atau aksi serupa lainnya. Kode dijalankan dalam instans tugas yang terisolasi dan bersifat sementara. Lingkungan ini digunakan untuk eksekusi produksi yang stabil dan andal.
Memahami perbedaan fitur signifikan antara kedua lingkungan ini merupakan kunci pengembangan yang efisien.
Referensi cepat: perbandingan lingkungan pengembangan vs. produksi
Fitur | Lingkungan pengembangan (menjalankan sel) | Lingkungan produksi (eksekusi terjadwal) |
Mereferensikan resource proyek ( |
| Berlaku secara otomatis. |
Membaca dan menulis dataset (OSS/NAS) | Pasang dataset di lingkungan pengembangan pribadi. | Pasang dataset di konfigurasi penjadwalan. |
Mereferensikan parameter ruang kerja ( | Didukung. Penggantian teks dilakukan secara otomatis sebelum eksekusi kode. | Didukung. Penggantian teks dilakukan secara otomatis sebelum eksekusi tugas. |
Manajemen sesi Spark | Secara default, sesi Spark dilepas secara otomatis setelah 2 jam tidak aktif. | Sesi berumur pendek dibuat untuk setiap instans tugas dan dihapus bersamaan dengannya. |
Gunakan ulang kode dan data di lingkungan produksi
Mereferensikan resource proyek (file .py)
Untuk membuat kode Anda lebih modular, dapat digunakan ulang, dan mudah dikelola, kelompokkan fungsi atau kelas umum dalam file .py terpisah. Anda kemudian dapat mereferensikan file-file ini sebagai resource MaxCompute menggunakan sintaks ##@resource_reference{"custom_name.py"}.
Buat dan terbitkan resource Python
Di panel navigasi kiri DataWorks DataStudio, klik
 dan buka Resource Management.
dan buka Resource Management.Di pohon direktori Resource Management, klik kanan direktori target atau klik + di pojok kanan atas. Pilih New Resource > MaxCompute Python dan beri nama file
my_utils.py.Di bagian Document Content, klik Online Editing, tempel kode fungsi utilitas Anda ke editor kode, lalu klik Save.
# my_utils.py def greet(name): return f"Hello, {name} from resource file!"Di bilah alat, klik Save lalu Publish resource tersebut. Hal ini membuat resource tersedia untuk tugas di lingkungan pengembangan maupun produksi.
Mereferensikan resource di notebook
Di baris pertama sel Python di notebook Anda, gunakan sintaks
##@resource_referenceuntuk mereferensikan resource yang telah diterbitkan.##@resource_reference{"my_utils.py"} # Jika resource berada di subdirektori, misalnya my_folder/my_utils.py, referensikan hanya dengan nama filenya, tanpa path direktori: ##@resource_reference{"my_utils.py"} from my_utils import greet message = greet('DataWorks') print(message)Debug di lingkungan pengembangan
Jalankan sel Python tersebut. Output-nya adalah:
Hello, DataWorks from resource file!PentingSaat debugging di lingkungan pengembangan, sistem mendeteksi deklarasi
##@resource_referencedan secara otomatis mengunduh file yang sesuai dari Resource Management ke pathworkspace/_dataworks/resource_referencesdi direktori pribadi Anda, sehingga kode Anda dapat mengaksesnya.Jika terjadi error
ModuleNotFoundError, klik tombol Restart di bilah alat editor untuk memuat ulang resource, lalu coba lagi.Terbitkan ke lingkungan produksi dan verifikasi
Setelah Anda Save dan Publish node notebook, buka Operation and Maintenance Center > Auto Triggered Task lalu klik Test untuk menjalankan tugas tersebut. Setelah tugas berhasil, output
Hello, DataWorks from resource file!akan muncul di log.PentingJika muncul error
There is no file with id ..., pastikan Anda telah menerbitkan resource Python ke lingkungan produksi.
Untuk informasi lebih lanjut, lihat Resource dan fungsi MaxCompute.
Membaca dan menulis dataset (OSS/NAS)
Saat tugas notebook dijalankan, Anda dapat dengan mudah membaca dari dan menulis ke file skala besar yang disimpan di OSS atau NAS.
Debugging di lingkungan pengembangan
Pasang dataset: Di halaman detail lingkungan pengembangan pribadi Anda, buka Storage Settings > Datasets untuk mengonfigurasinya.
Akses dataset di kode Anda: Dataset dipasang ke path mount tertentu di lingkungan pengembangan pribadi Anda. Anda dapat langsung membaca dari atau menulis ke path tersebut dalam kode Anda.
# Asumsikan dataset dipasang ke path /mnt/data/dataset. import pandas as pd # Gunakan path mount secara langsung. file_path = '/mnt/data/dataset/testfile.csv' df = pd.read_csv(file_path) # Gunakan PyODPS untuk menulis data ke MaxCompute. o = %odps o.write_table('mc_test_table', df, overwrite=True) print(f"Berhasil menulis data ke tabel MaxCompute mc_test_table.")
Penerapan di lingkungan produksi
Pasang dataset: Di halaman pengeditan node notebook, buka Scheduling Settings > Scheduling Policy di panel navigasi kanan dan tambahkan dataset yang sama.
Akses dataset di kode Anda: Setelah Anda melakukan commit dan menerbitkan node, dataset dipasang di lingkungan produksi. Gunakan path mount yang sama dalam kode Anda untuk mengaksesnya.
# Asumsikan dataset dipasang ke path /mnt/data/dataset. import pandas as pd # Gunakan path mount secara langsung. file_path = '/mnt/data/dataset/testfile.csv' df = pd.read_csv(file_path) # Gunakan PyODPS untuk menulis data ke MaxCompute. o = %odps o.write_table('mc_test_table', df, overwrite=True) print(f"Berhasil menulis data ke tabel MaxCompute mc_test_table.")
Untuk informasi lebih lanjut, lihat Menggunakan dataset di lingkungan pengembangan pribadi.
Gunakan parameter ruang kerja
Fitur ini hanya tersedia di DataWorks Edisi Profesional atau lebih tinggi.
DataWorks menyediakan parameter ruang kerja, yang memperluas parameter penjadwalan yang sudah ada. Parameter ini memungkinkan penggunaan ulang konfigurasi global dan isolasi lingkungan lintas tugas dan node. Anda dapat mereferensikan parameter ruang kerja di sel SQL atau sel Python menggunakan format ${workspace.param}, di mana param adalah nama parameter ruang kerja Anda.
1. Buat parameter ruang kerja: Sebelum memulai, buka Operation and Maintenance Center > Scheduling Settings > Workspace Parameters di DataWorks untuk membuat parameter yang diperlukan.
2. Mereferensikan parameter ruang kerja:
Mereferensikan parameter ruang kerja di sel SQL.
SELECT '${workspace.param}';Saat sel dijalankan, nilai parameter ruang kerja yang telah diselesaikan akan dicetak.
Mereferensikan parameter ruang kerja di sel Python.
print('${workspace.param}')Saat sel dijalankan, nilai parameter ruang kerja yang telah diselesaikan akan dicetak.
Untuk detail lebih lanjut, lihat Menggunakan parameter ruang kerja.
Gunakan perintah magic dengan mesin komputasi
Perintah magic adalah perintah khusus yang diawali dengan % atau %% yang menyederhanakan interaksi antara sel Python dan berbagai sumber daya komputasi.
Hubungkan ke MaxCompute
Sebelum menghubungkan ke sumber daya komputasi MaxCompute, pastikan Anda telah mengikat sumber daya komputasi MaxCompute.
%odps: Dapatkan objek entri PyODPSPerintah ini mengembalikan objek PyODPS terotentikasi yang terikat ke proyek MaxCompute saat ini. Metode ini direkomendasikan untuk berinteraksi dengan MaxCompute karena menghindari hard-coding AccessKey di kode Anda.
Gunakan perintah magic untuk membuat koneksi MaxCompute. Masukkan
%odps. Pemilih sumber daya komputasi MaxCompute muncul di pojok kanan bawah dan secara otomatis memilih sumber daya komputasi. Klik nama proyek MaxCompute di pojok kanan bawah untuk mengganti proyek.o=%odpsGunakan sumber daya komputasi MaxCompute yang telah diambil untuk menjalankan skrip PyODPS.
Contohnya, untuk mendapatkan semua tabel di proyek saat ini:
with o.execute_sql('show tables').open_reader() as reader: print(reader.raw)
%maxframe: Membuat koneksi MaxFramePerintah ini membuat sesi MaxFrame, yang menyediakan kemampuan pemrosesan data terdistribusi mirip pandas untuk MaxCompute.
# Hubungkan ke dan akses Sesi MaxFrame MaxCompute mf_session = %maxframe df = mf_session.read_odps_table('your_mc_table') print(df.head()) # Setelah pengembangan dan debugging, hancurkan sesi secara manual untuk melepas sumber daya mf_session.destroy()
Hubungkan ke sumber daya komputasi Spark
DataWorks Notebook mendukung koneksi ke beberapa mesin Spark. Mesin-mesin ini berbeda dalam metode koneksi, konteks eksekusi, dan manajemen sumber daya.
Satu node notebook hanya dapat menggunakan perintah magic untuk menghubungkan ke satu jenis sumber daya komputasi dalam satu waktu.
Perbandingan mesin
Fitur | MaxCompute Spark | EMR Serverless Spark | AnalyticDB for Spark |
Perintah |
|
|
|
Catatan Setelah menjalankan perintah, konteks eksekusi seluruh kernel notebook beralih ke lingkungan PySpark remote. Anda kemudian dapat langsung menulis kode PySpark di sel-sel berikutnya. | |||
Prasyarat | Ikat sumber daya komputasi MaxCompute. | Ikat sumber daya komputasi EMR dan buat Livy Gateway. | Ikat sumber daya komputasi ADB Spark. |
Mode pengembangan | Otomatis membuat atau menggunakan kembali sesi Livy. | Terhubung ke Livy Gateway yang sudah ada dan membuat sesi. | Otomatis membuat atau menggunakan kembali Spark Connect Server. |
Mode produksi | Mode Livy: Mengirimkan pekerjaan Spark melalui layanan Livy. | Mode batch spark-submit: Pemrosesan batch murni; status sesi tidak dipertahankan. | Mode Spark Connect Server: Berinteraksi melalui layanan koneksi Spark. |
Pelepasan sumber daya | Sistem secara otomatis melepas sesi setelah instans tugas berakhir. | Sistem secara otomatis membersihkan sumber daya setelah instans tugas berakhir. | Sistem secara otomatis melepas sumber daya setelah instans tugas berakhir. |
Kasus Penggunaan | Pemrosesan batch tujuan umum dan tugas ETL yang terintegrasi erat dengan ekosistem MaxCompute. | Tugas analisis kompleks yang memerlukan konfigurasi fleksibel dan interaksi dengan ekosistem data besar open-source, seperti Hudi dan Iceberg. | Kueri dan analisis interaktif berkinerja tinggi pada tabel C-Store di AnalyticDB for MySQL. |
MaxCompute Spark
Sebelum menghubungkan ke sumber daya komputasi MaxCompute, pastikan Anda telah mengikat sumber daya komputasi MaxCompute.
Hubungkan ke mesin Spark yang terintegrasi dalam proyek MaxCompute melalui Livy.
Buat koneksi: Jalankan perintah berikut di sel Python. Sistem secara otomatis membuat atau menggunakan kembali sesi Spark.
# Buat Sesi Spark. %maxcompute_sparkEksekusi kode PySpark: Setelah koneksi terbentuk, gunakan magic sel
%%sparkdi sel Python baru untuk mengeksekusi kode PySpark.# Saat menggunakan MaxCompute Spark, sel Python harus diawali dengan %%spark. %%spark df = spark.sql("SELECT * FROM your_mc_table LIMIT 10") df.show()Hentikan koneksi secara manual: Setelah selesai debugging, Anda dapat menghentikan atau menghapus sesi secara manual. Saat dijalankan di lingkungan produksi, sistem secara otomatis menghentikan dan menghapus sesi Livy untuk instans tugas saat ini, sehingga tidak diperlukan tindakan manual.
# Bersihkan Sesi Spark dan hentikan Livy. %maxcompute_spark stop # Bersihkan Sesi Spark, hentikan Livy, lalu hapus Livy. %maxcompute_spark delete
EMR Serverless Spark
Sebelum membuat koneksi ke sumber daya komputasi, ikat sumber daya komputasi EMR Serverless Spark ke ruang kerja Anda dan buat Livy Gateway.
Hubungkan ke Livy Gateway yang telah ada untuk berinteraksi dengan EMR Serverless Spark.
Buat koneksi: Sebelum menjalankan perintah, pilih sumber daya komputasi EMR dan Livy Gateway di pojok kanan bawah sel.
# Koneksi dasar %emr_serverless_spark # Atau, berikan parameter Spark kustom saat menghubungkan. Perhatikan bahwa dua tanda persen (%%) # diperlukan saat memberikan parameter Spark kustom. %%emr_serverless_spark { "spark_conf": { "spark.emr.serverless.environmentId": "<ID lingkungan runtime EMR Serverless Spark>", "spark.emr.serverless.network.service.name": "<ID koneksi jaringan EMR Serverless Spark>", "spark.driver.cores": "1", "spark.driver.memory": "8g", "spark.executor.cores": "1", "spark.executor.memory": "2g", "spark.driver.maxResultSize": "32g" } }CatatanHubungan antara parameter kustom dan konfigurasi global
Perilaku default: Parameter kustom yang ditentukan di sini hanya berlaku untuk koneksi (sesi) saat ini dan bersifat sekali pakai. Jika Anda tidak memberikan parameter kustom, sistem menggunakan parameter global yang dikonfigurasi di Admin Center.
Penggunaan yang direkomendasikan: Untuk konfigurasi yang perlu digunakan ulang di banyak tugas atau oleh banyak pengguna, konfigurasikan secara global di Admin Center > Serverless Spark > SPARK parameters untuk memastikan konsistensi dan menyederhanakan manajemen.
Aturan prioritas: Saat parameter yang sama diatur baik di parameter kustom maupun konfigurasi global, pengaturan yang berlaku bergantung pada opsi Global Configuration Priority di Admin Center.
Dipilih: Konfigurasi global menggantikan parameter kustom untuk sesi ini.
Tidak dipilih: Parameter kustom untuk sesi ini menggantikan konfigurasi global.
(Opsional) Sambung ulang: Jika administrator secara tidak sengaja menghapus token dari halaman Livy Gateway, gunakan perintah ini untuk membuat ulang token tersebut.
# Sambung ulang dan perbarui token Livy untuk lingkungan pengembangan pribadi saat ini. %emr_serverless_spark refresh_tokenEksekusi kode PySpark atau SQL: Setelah koneksi terbentuk, kernel beralih. Anda dapat langsung menulis kode PySpark di sel Python atau menulis SQL di sel EMR Spark SQL.
Kirim dan eksekusi kode SQL melalui sel EMR Spark SQL
Setelah membuat koneksi dengan
%emr_serverless_spark, Anda dapat langsung menulis pernyataan SQL di sel EMR Spark SQL tanpa memilih sumber daya komputasi di sel tersebut.Sel EMR Spark SQL menggunakan kembali koneksi
%emr_serverless_sparkuntuk mengirimkan pekerjaan ke sumber daya komputasi target guna dieksekusi.
Kirim dan eksekusi kode PySpark melalui sel Python
Setelah membuat koneksi dengan
%emr_serverless_spark, Anda dapat mengirim dan mengeksekusi kode PySpark di sel Python baru. Anda tidak perlu menambahkan awalan%%sparkke sel tersebut.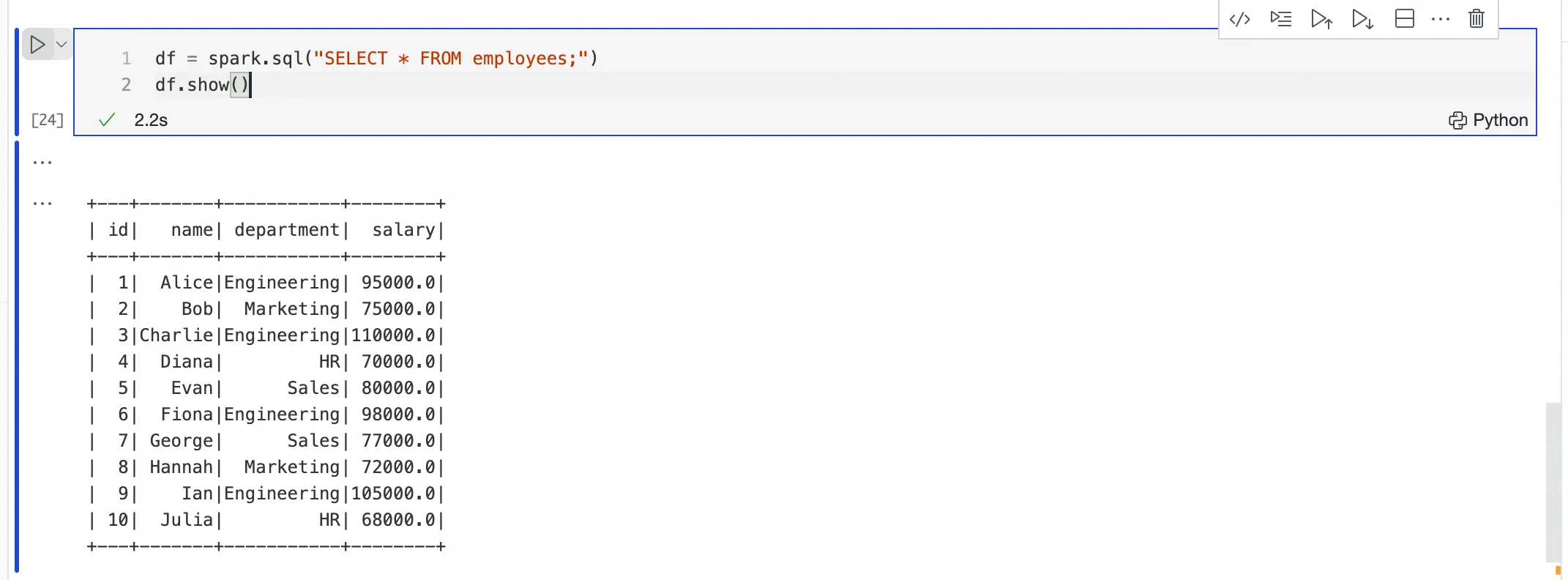
Hentikan koneksi secara manual
PentingJika beberapa pengguna berbagi Livy Gateway, perintah
stopataudeleteakan memengaruhi semua pengguna yang menggunakan gateway tersebut. Gunakan perintah ini dengan hati-hati.# Bersihkan Sesi Spark dan hentikan Livy. %emr_serverless_spark stop # Bersihkan Sesi Spark, hentikan Livy, lalu hapus Livy. %emr_serverless_spark delete
AnalyticDB for Spark
Sebelum membuat koneksi ke sumber daya komputasi, ikat sumber daya komputasi AnalyticDB for Spark ke ruang kerja Anda.
Hubungkan ke mesin AnalyticDB for Spark dengan membuat Spark Connect Server.
Buat koneksi: Untuk memastikan konektivitas jaringan, Anda harus mengonfigurasi ID vSwitch dan ID grup keamanan dengan benar di parameter koneksi. Sebelum menjalankan perintah, pilih sumber daya komputasi ADB Spark di pojok kanan bawah sel.
# Anda harus mengonfigurasi ID vSwitch dan ID grup keamanan untuk membuat koneksi jaringan. %adb_spark add \ --spark-conf spark.adb.version=3.5 \ --spark-conf spark.adb.eni.enabled=true \ --spark-conf spark.adb.eni.vswitchId=<ID vSwitch ADB> \ --spark-conf spark.adb.eni.securityGroupId=<ID grup keamanan lingkungan pengembangan pribadi>Eksekusi kode PySpark: Setelah koneksi terbentuk, eksekusi kode PySpark di sel Python baru.
# Anda hanya dapat menjalankan operasi pada tabel C-Store. df = spark.sql("SELECT * FROM my_adb_cstore_table LIMIT 10") df.show()Catatan: Mesin AnalyticDB for Spark saat ini hanya dapat memproses tabel C-Store yang memiliki atribut
'storagePolicy'='COLD'.Hentikan koneksi secara manual: Setelah selesai debugging di lingkungan pengembangan, bersihkan sesi koneksi secara manual untuk menghemat sumber daya. Saat dijalankan di lingkungan produksi, sistem secara otomatis membersihkan sumber daya.
%adb_spark cleanup
Hubungkan ke Lindorm Ray
Kelompok sumber daya RAY dari mesin komputasi Lindorm menyediakan layanan komputasi terdistribusi dan mendukung beban kerja AI end-to-end. Anda dapat menggunakan perintah magic untuk terhubung secara mulus ke sumber daya Lindorm Ray di notebook guna pengembangan dan debugging interaktif, lalu menerbitkan notebook tersebut sebagai tugas produksi terjadwal.
Buat koneksi: Jalankan perintah
%lindorm_raydi sel Python. Pemilih sumber daya komputasi muncul di pojok kanan bawah sel. Pilih sumber daya komputasi Lindorm dan kelompok sumber daya RAY yang telah dibuat.# Hubungkan ke kelompok sumber daya Lindorm Ray yang ditentukan. %lindorm_rayPentingSetelah terhubung ke sumber daya komputasi Lindorm Ray, Anda tidak dapat lagi menjalankan sel SQL di notebook yang sama. Mesin Lindorm Ray hanya mengeksekusi kode Python dan Ray.
Jika Anda menjalankan sel kode yang sama beberapa kali, sistem secara otomatis menghentikan pekerjaan Ray sebelumnya dan memulai yang baru. Hal ini membantu mencegah pemborosan sumber daya dan konflik tugas.
Eksekusi kode Ray: Setelah koneksi terbentuk, Anda dapat langsung menulis dan mengeksekusi kode Ray di sel Python baru. Log dialirkan kembali ke area output sel secara real time, yang memfasilitasi debugging interaktif.
Contoh berikut mendefinisikan tugas remote sederhana (menggunakan dekorator
@ray.remote) yang dieksekusi di kluster Ray dan mengembalikan log serta hasil akhir ke area output sel.import ray import time @ray.remote def hello_world(): print("Hello from Lindorm Ray!") time.sleep(5) return "Task finished." # Kirim tugas remote result_ref = hello_world.remote() print(ray.get(result_ref))(Opsional) Tentukan parameter startup kustom: Jika Anda perlu menentukan konfigurasi tambahan untuk lingkungan Ray, seperti menginstal paket Python pihak ketiga atau mengunggah file kode lokal, gunakan perintah
%%lindorm_rayuntuk membuat koneksi.Contoh 1: Instal dependensi
Gunakan parameter
pipuntuk menginstal paketjiebadi lingkungan Ray.%%lindorm_ray { "runtime_env": { "pip": ["jieba"] } }Setelah lingkungan siap, impor dan gunakan paket tersebut di pekerjaan Ray berikutnya. Contoh berikut menunjukkan cara memanggil
jiebadalam fungsi remote untuk melakukan segmentasi kata bahasa Tionghoa:import ray @ray.remote def do_work(x): import jieba return "/".join(jieba.cut(x)) print(ray.get(do_work.remote("Welcome to the DataWorks+LindormRay solution")))Contoh 2: Unggah dan gunakan resource DataWorks
Parameter
working_dirdigunakan untuk mengunggah resource dari Resource Management DataWorks ke kluster Ray sehingga dapat diimpor dan dipanggil dalam tugas.PentingSaat menggunakan
working_diruntuk mengunggah resource, file diunggah langsung dari lingkungan pengembangan Anda ke kluster Ray dan tunduk pada batas ukuran 100 MB. Jika paket resource terlalu besar, unggahan mungkin gagal atau node Ray menjadi tidak stabil.
# Referensikan resource yang diunggah di Resource Management DataStudio dan deklarasikan path-nya. %%lindorm_ray { "runtime_env": { "working_dir": "/mnt/workspace/_dataworks/resource_references" } }Anggap Anda mengunggah file ray_resource.py ke Resource Management di DataStudio. Saat Anda menulis dan mengeksekusi sel berikut, sistem secara otomatis mengurai deklarasi
##@resource_referencedi kode berikutnya dan mengunduh resource yang sesuai ke path/mnt/workspace/_dataworks/resource_references.PentingDi lingkungan pengembangan, setelah Anda mengeksekusi sel yang berisi ##@resource_reference, Anda harus menjalankan ulang sel
%%lindorm_raydi atas untuk mengunggah resource yang telah diunduh di working_dir ke kluster Ray. Di lingkungan produksi, Anda tidak perlu menjalankan ulang.import ray ##@resource_reference{"ray_resource.py"} @ray.remote def do_work(x): print('Ray says:', x) from ray_resource import fun fun() return x worker = do_work.remote("Welcome to the DataWorks+LindormRay solution") print(ray.get(worker))
Penjadwalan produksi dan O&M: Setelah pengembangan dan debugging selesai, Anda dapat melakukan commit dan menerbitkan node notebook. Node tersebut kemudian akan dijadwalkan secara periodik sebagai node Lindorm Ray dalam DAG.
Parameterisasi: Kode Anda dapat menggunakan parameter penjadwalan DataWorks standar, seperti
${bizdate}.Penampilan log: Di lingkungan produksi, untuk mencegah log berlebihan memengaruhi kinerja, sistem hanya memuat 1 MB log pertama secara default. Jika log terpotong, output mencakup tautan yang mengarahkan Anda ke konsol Lindorm untuk melihat log tugas lengkap.
Pelepasan sumber daya: Setelah tugas produksi terjadwal selesai, tugas Lindorm Ray memasuki status terminal dan tidak lagi menggunakan sumber daya. Selama pengembangan interaktif, Anda dapat menghentikan tugas Lindorm Ray dengan me-restart kernel atau menutup notebook.
Lampiran: Referensi cepat perintah magic
Magic command | Deskripsi | Compute Engine |
| Dapatkan objek entri PyODPS | MaxCompute |
| Buat koneksi MaxFrame | |
| Buat sesi Spark | MaxCompute Spark |
| Bersihkan sesi Spark dan hentikan Livy. | |
| Bersihkan sesi Spark, lalu hentikan dan hapus Livy. | |
| Di sel Python, hubungkan ke sumber daya komputasi Spark yang telah dibuat. | |
| Buat sesi Spark | EMR Serverless Spark |
| Lihat informasi detail tentang Livy Gateway. | |
| Bersihkan sesi Spark dan hentikan Livy. | |
| Bersihkan sesi Spark, lalu hentikan dan hapus Livy. | |
| Perbarui token Livy untuk lingkungan pengembangan pribadi. | |
| Buat dan hubungkan ke sesi ADB Spark yang dapat digunakan ulang. | AnalyticDB for Spark |
| Lihat informasi sesi Spark. | |
| Hentikan dan bersihkan sesi koneksi Spark saat ini. | |
| Buat koneksi Lindorm Ray. | Lindorm Ray |
| Buat koneksi Lindorm Ray dan konfigurasikan lingkungan runtime kustom, seperti menginstal dependensi atau mengunggah kode. |
FAQ
T: Mengapa saya menerima error
ModuleNotFoundErroratauThere is no file with id ...saat mereferensikan resource ruang kerja?A: Ikuti langkah-langkah berikut untuk mengatasi masalah ini:
Buka Data Development > Resource Management untuk memastikan resource Python MaxCompute telah disimpan. Jika error ini terjadi di lingkungan produksi, verifikasi bahwa resource telah diterbitkan ke lingkungan tersebut.
Di bilah alat editor Notebook, klik Restart untuk memuat ulang resource.
T: Mengapa resource lama masih direferensikan setelah saya memperbarui resource ruang kerja?
J: Saat menerbitkan ulang resource yang telah dimodifikasi, atur
Dataworks › Notebook › Resource Reference: Download Strategyke autoOverwrite di pengaturan Data Studio Anda, lalu klik Restart Kernel di bilah alat Notebook.T: Mengapa saya menerima error
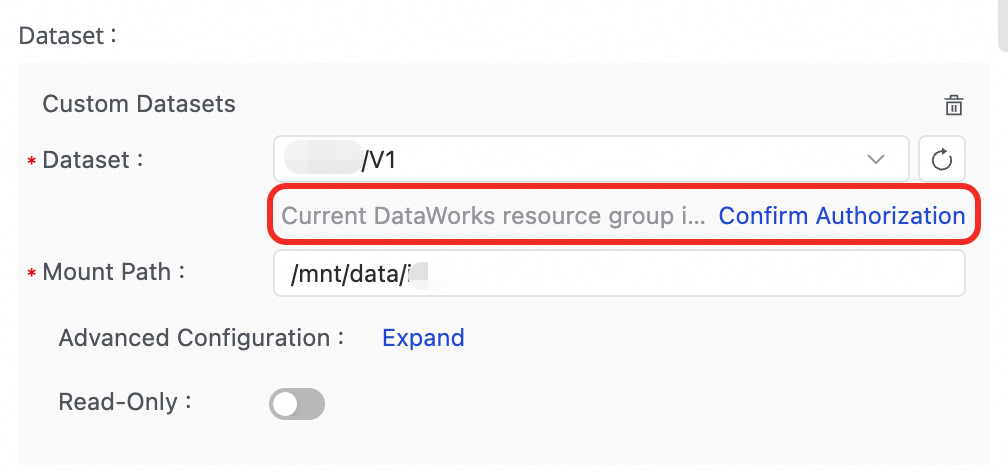
FileNotFoundErrordi lingkungan pengembangan saat mereferensikan dataset?J: Pastikan dataset dipasang di lingkungan pengembangan pribadi yang saat ini dipilih.
T: Mengapa mereferensikan dataset berhasil di lingkungan pengembangan tetapi gagal di lingkungan produksi dengan error
Execute mount dataset exception! Please check your dataset config?A: Pastikan set data telah dipasang di Scheduling Settings pada node Notebook dan Anda telah memberikan izin yang diperlukan ke set data OSS.
T: Bagaimana cara memeriksa versi lingkungan pengembangan pribadi saya?
J: Di lingkungan pengembangan pribadi Anda, tekan
Cmd+Shift+Pdan masukkanABOUTuntuk melihat versi saat ini. Jika diperlukan pembaruan ke versi 0.5.69 atau lebih baru, prompt peningkatan akan muncul. Klik One-click Upgrade untuk memperbarui instans Anda.T: Mengapa koneksi ke mesin Spark gagal?
A: Ikuti langkah-langkah berikut:
Pemeriksaan umum: Di daftar sumber daya komputasi halaman detail ruang kerja, pastikan sumber daya komputasi target (MaxCompute, EMR, atau ADB) telah diikat dengan benar ke ruang kerja Anda dan akun Anda memiliki izin yang diperlukan.
EMR Serverless Spark: Verifikasi bahwa Livy Gateway ada dan dalam kondisi sehat.
AnalyticDB for Spark: Fokus pada masalah jaringan. Pastikan
vswitchIddansecurityGroupIddikonfigurasi dengan benar untuk memastikan konektivitas jaringan antara lingkungan pengembangan pribadi Anda dan instans ADB Spark. Verifikasi bahwa aturan grup keamanan Anda mengizinkan trafik pada port yang diperlukan.