Dalam Service Mesh (ASM), Anda mungkin perlu mengumpulkan data observabilitas yang berbeda untuk layanan yang berbeda. Oleh karena itu, Anda harus mendefinisikan aturan konfigurasi pengumpulan data observabilitas secara terpisah untuk proxy sisi dan pod gateway serta menstandarkan aturan konfigurasi pengumpulan untuk meningkatkan observabilitas aplikasi cloud-native. Observabilitas sangat penting untuk memantau operasi dan kinerja layanan secara real-time, serta menemukan dan menyelesaikan masalah layanan dan hambatan. Dengan demikian, ini dapat membantu meningkatkan keandalan dan kinerja aplikasi. ASM menyediakan mode terpusat dan distandarisasi bagi Anda untuk menghasilkan dan mengumpulkan data observabilitas aplikasi cloud-native. Topik ini menjelaskan konsep dan fitur terkait observabilitas.
Pendahuluan
Karena kompleksitas aplikasi dalam arsitektur mikro-layanan, sulit untuk memastikan bahwa semua layanan berjalan dalam keadaan stabil. Beberapa layanan mungkin mengalami penurunan kinerja karena beberapa masalah. Oleh karena itu, aplikasi harus andal dan tangguh, dan alat observabilitas tersedia untuk memantau status aplikasi dan infrastruktur selama runtime. Jika Anda dapat memperoleh informasi runtime, Anda dapat mendeteksi kegagalan dan melakukan debugging mendalam ketika situasi tak terduga terjadi. Ini membantu mengurangi waktu pemulihan rata-rata layanan dan mengurangi dampak pada bisnis Anda.
Observabilitas adalah kemampuan yang bergantung pada metrik di berbagai tingkat seperti aplikasi, jaringan, dan infrastruktur (misalnya, database dan penyimpanan). Dengan metrik tersebut, Anda dapat memahami secara menyeluruh masalah tak terduga ketika hal itu terjadi. ASM dapat secara efektif memfasilitasi pengumpulan metrik aplikasi dalam hal observabilitas. Dari sudut pandang praktis, Anda harus lebih memperhatikan stabilitas aplikasi Anda dan mengetahui status runtime aplikasi secara real-time. Dengan cara ini, Anda dapat dengan cepat mendeteksi masalah dan mengambil langkah-langkah yang sesuai untuk menjaga ketersediaan aplikasi.
Proxy sisi pada bidang data ditempatkan pada jalur permintaan layanan. Anda dapat memantau status runtime layanan dan service mesh yang sesuai dengan menganalisis data observabilitas dari proxy sisi.
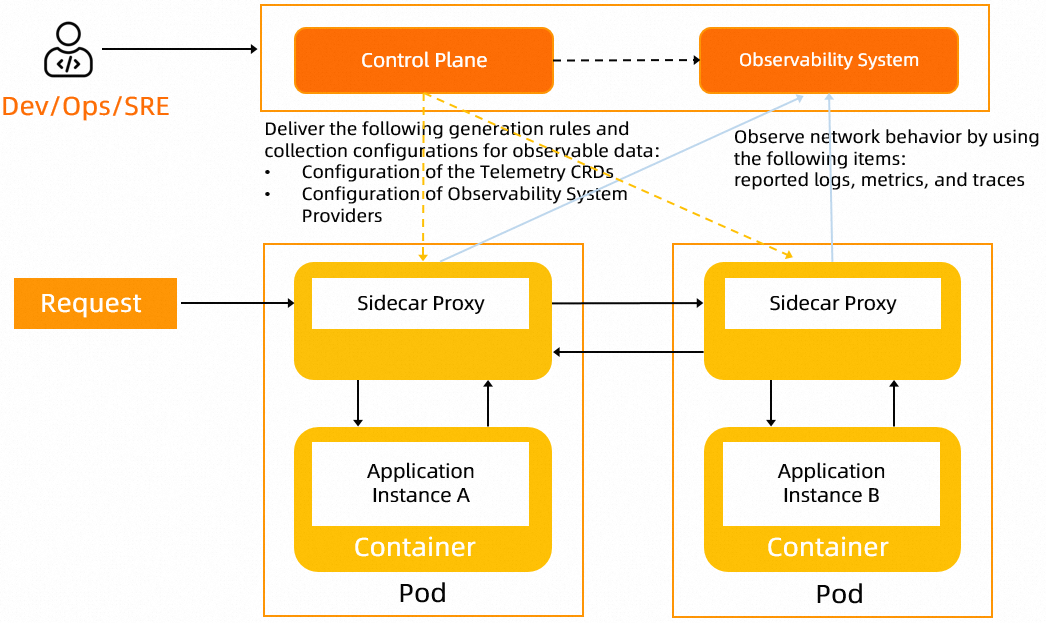
Implementasi fitur observabilitas ASM melibatkan konfigurasi aturan untuk menghasilkan dan mengumpulkan data observabilitas seperti log, metrik, dan analisis jejak. Selain itu, fitur observabilitas harus menyediakan metode untuk mengumpulkan data observabilitas ke layanan berbasis cloud atau layanan yang dikelola sendiri. Untuk memenuhi berbagai kebutuhan, fitur observabilitas harus mendukung konfigurasi pengumpulan kustom untuk proxy sisi dan pod gateway. ASM menyediakan mode terpusat dan distandarisasi bagi Anda untuk menghasilkan dan mengumpulkan data observabilitas aplikasi cloud-native. 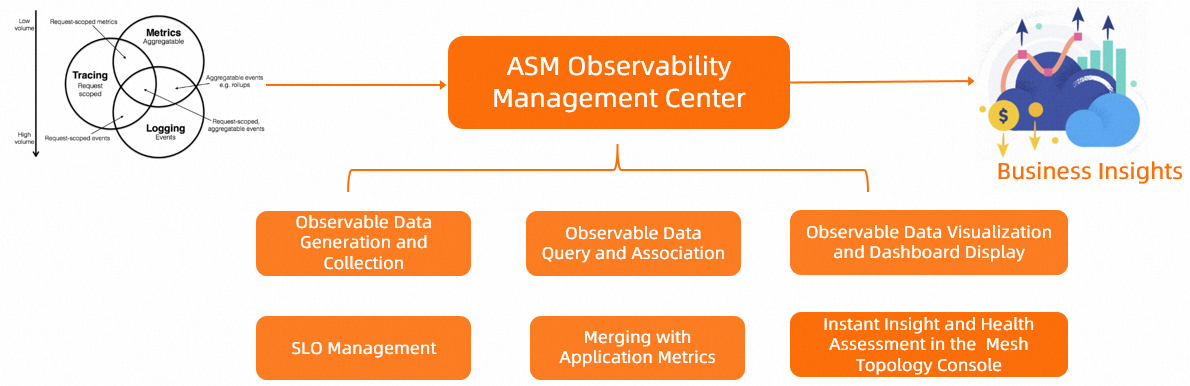
Praktik Terbaik
Telemetry CustomResourceDefinitions (CRD) dapat digunakan untuk membuat beberapa sumber daya di beberapa namespace. Namun, jika Anda mendefinisikan CRD secara sembarangan, konflik dan hasil yang tidak diharapkan mungkin terjadi. Bagian berikut mencantumkan praktik terbaik berdasarkan pengalaman dunia nyata:
Hanya satu Telemetry CRD yang dapat ada di namespace root istio-system. Anda tidak dapat mendefinisikan beberapa Telemetry CRD di namespace istio-system. ASM menerapkan praktik terbaik ini dan memungkinkan Anda mendefinisikan hanya satu Telemetry CRD bernama default di namespace istio-system.
Anda hanya dapat mendefinisikan satu Telemetry CRD yang pemilih beban kerjanya dibiarkan kosong dan namanya default di semua namespace.
Untuk menimpa beban kerja tertentu, Anda dapat mendefinisikan pemilih beban kerja dalam Telemetry CRD baru untuk memilih beban kerja untuk namespace yang diinginkan.
Jika dua Telemetry CRD memiliki pemilih beban kerja yang sama, tidak pasti mana dari kedua CRD yang akan dieksekusi.
Jika metrik tidak dikonfigurasikan dalam Telemetry CRD di namespace istio-system, tidak ada metrik yang dihasilkan.
Log
Dalam ASM, pengumpulan log adalah sarana penting untuk mengamati layanan. Untuk mengelola dan mengambil log secara seragam, Anda harus menggabungkan log dari semua layanan bersama-sama. Untuk melakukannya, Anda harus mencetak log setiap layanan ke stdout atau stderr dan menggunakan agen logging untuk mengumpulkan log ke sistem logging terpusat. ASM menyediakan fitur penyaringan log dan format log. Anda dapat menyaring log dan mengonfigurasi format log sesuai kebutuhan untuk lebih baik mengambil dan menganalisis log.
Konfigurasikan aturan format log
Format log layanan yang berbeda mungkin berbeda. Oleh karena itu, Anda perlu mengonfigurasi aturan pembuatan untuk mengontrol bagaimana log dihasilkan. Setelah Anda menambahkan kluster Kubernetes ke instance ASM, proxy Envoy yang diterapkan pada bidang data instance ASM dapat mencetak semua log akses kluster. ASM memungkinkan Anda menyesuaikan bidang log akses yang dicetak oleh proxy Envoy.
Berdasarkan Telemetry CRD, ASM menyediakan antarmuka grafis seperti yang ditunjukkan pada gambar berikut untuk menyederhanakan konfigurasi format data log. Untuk informasi lebih lanjut, lihat Sesuaikan log akses pada bidang data. 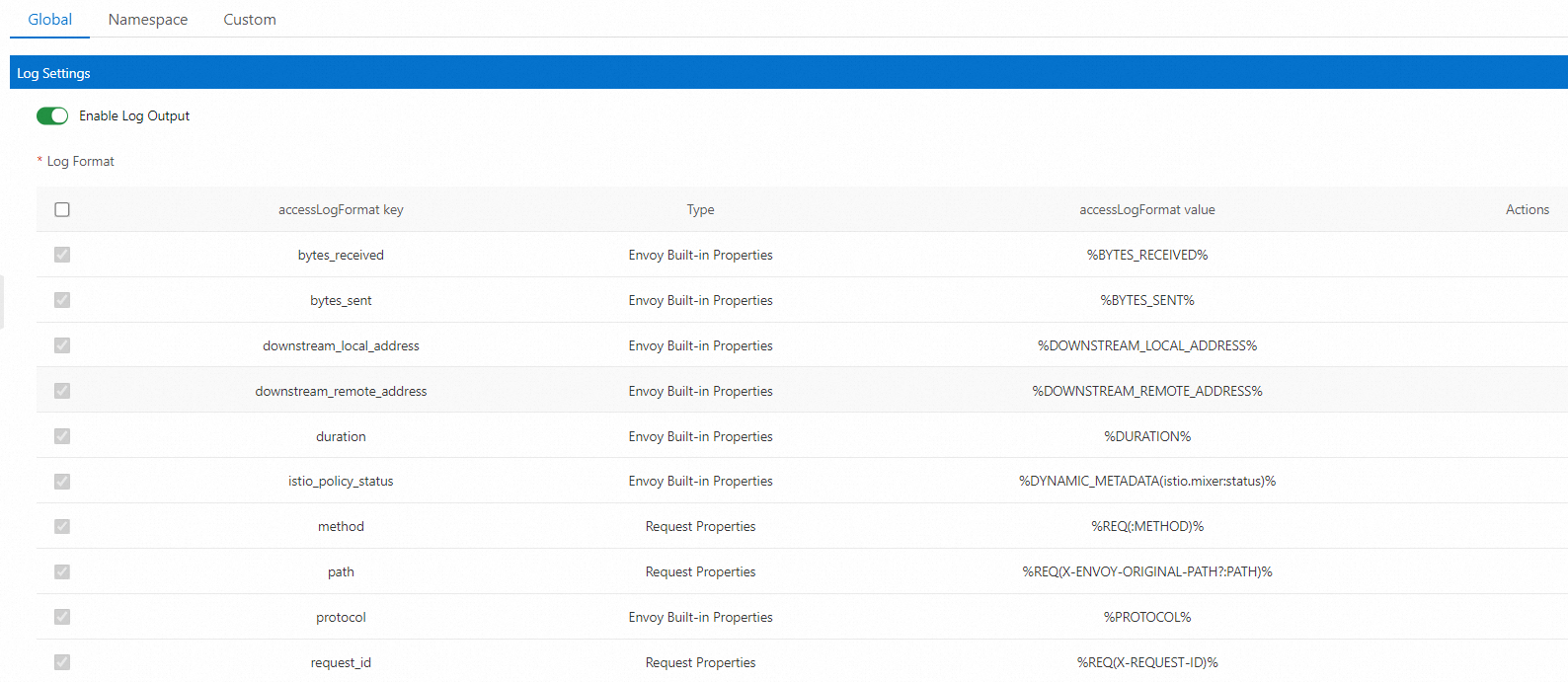
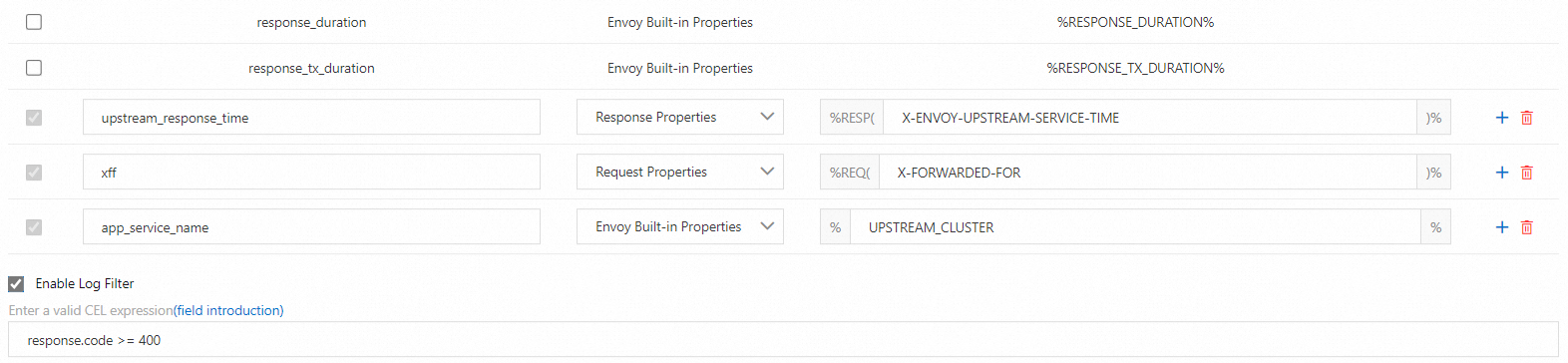
Kode sampel berikut setara dengan konfigurasi pembuatan log pada antarmuka grafis sebelumnya.
envoyFileAccessLog:
logFormat:
text: '{"bytes_received":"%BYTES_RECEIVED%","bytes_sent":"%BYTES_SENT%","downstream_local_address":"%DOWNSTREAM_LOCAL_ADDRESS%","downstream_remote_address":"%DOWNSTREAM_REMOTE_ADDRESS%","duration":"%DURATION%","istio_policy_status":"%DYNAMIC_METADATA(istio.mixer:status)%","method":"%REQ(:METHOD)%","path":"%REQ(X-ENVOY-ORIGINAL-PATH?:PATH)%","protocol":"%PROTOCOL%","request_id":"%REQ(X-REQUEST-ID)%","requested_server_name":"%REQUESTED_SERVER_NAME%","response_code":"%RESPONSE_CODE%","response_flags":"%RESPONSE_FLAGS%","route_name":"%ROUTE_NAME%","start_time":"%START_TIME%","trace_id":"%REQ(X-B3-TRACEID)%","upstream_cluster":"%UPSTREAM_CLUSTER%","upstream_host":"%UPSTREAM_HOST%","upstream_local_address":"%UPSTREAM_LOCAL_ADDRESS%","upstream_service_time":"%RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)%","upstream_transport_failure_reason":"%UPSTREAM_TRANSPORT_FAILURE_REASON%","user_agent":"%REQ(USER-AGENT)%","x_forwarded_for":"%REQ(X-FORWARDED-FOR)%","authority_for":"%REQ(:AUTHORITY)%","upstream_response_time":"%RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)%","xff":"%REQ(X-FORWARDED-FOR)%","app_service_name":"%UPSTREAM_CLUSTER%"}'
path: /dev/stdoutKode sampel berikut setara dengan konfigurasi kondisi filter yang sesuai pada antarmuka grafis sebelumnya.
accessLogging:
- disabled: false
filter:
expression: response.code >= 400
providers:
- name: envoyKonfigurasikan pengumpulan log bidang data
Saat Anda mengumpulkan log dari bidang data ke Simple Log Service, Anda harus mengonfigurasi aturan pengumpulan log untuk mengontrol metode pengumpulan dan periode validitas penyimpanan log. Container Service for Kubernetes (ACK) terintegrasi dengan Simple Log Service. Anda dapat mengumpulkan log akses kluster pada bidang data instance ASM. Untuk informasi lebih lanjut, lihat Gunakan Simple Log Service untuk mengumpulkan log akses pada bidang data.
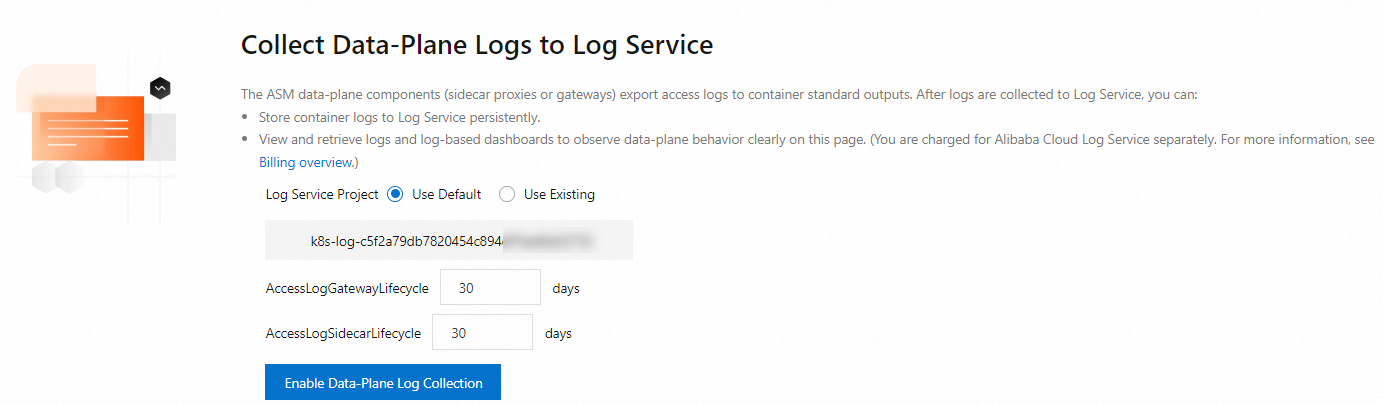
Kumpulkan log bidang kontrol dan konfigurasikan notifikasi
ASM memungkinkan Anda mengumpulkan log bidang kontrol dan mengirimkan notifikasi kepada Anda berdasarkan data log. Misalnya, Anda dapat mengumpulkan log terkait dorongan konfigurasi dari bidang kontrol instance ASM ke proxy sisi pada bidang data. Salah satu fitur utama komponen pada bidang kontrol ASM adalah mendorong konfigurasi ke proxy sisi atau ingress gateway pada bidang data. Jika terjadi konflik konfigurasi, proxy sisi atau ingress gateway tidak dapat menerima konfigurasi. Proxy sisi atau ingress gateway mungkin terus berjalan berdasarkan konfigurasi yang sebelumnya mereka terima. Namun, proxy sisi atau ingress gateway kemungkinan besar gagal jika pod tempat mereka berada di-restart. Dalam banyak situasi praktis, proxy sisi atau ingress gateway menjadi tidak tersedia karena konfigurasi yang tidak tepat. Oleh karena itu, kami merekomendasikan agar Anda mengaktifkan peringatan berbasis log untuk mendeteksi dan menyelesaikan masalah secara tepat waktu. Untuk informasi lebih lanjut, lihat Aktifkan pengumpulan log bidang kontrol dan peringatan berbasis log dalam instance ASM versi sebelum 1.17.2.35 atau Aktifkan pengumpulan log bidang kontrol dan peringatan berbasis log dalam instance ASM versi 1.17.2.35 atau lebih baru.
Metrik
Metrik penting bagi pengguna untuk mengamati layanan dalam ASM. Metrik digunakan untuk menggambarkan pemrosesan permintaan dan komunikasi antar layanan. Istio menggunakan Agen Prometheus untuk mengumpulkan dan menyimpan metrik. Envoy proxy dari setiap layanan menghasilkan sejumlah besar metrik. Metrik dapat digunakan untuk memantau operasi dan kinerja layanan secara real-time. Metrik juga dapat digunakan dalam skenario seperti deteksi anomali dan penskalaan otomatis.
Konfigurasikan aturan pembuatan data metrik
Jika Anda mengaktifkan metrik bidang data, bidang data menghasilkan data metrik terkait status operasi gateway dan proxy sisi. Anda dapat mengumpulkan metrik ke Managed Service for Prometheus untuk melihat laporan pemantauan. Anda mungkin dikenakan biaya untuk mengumpulkan metrik. Sebagai alternatif, Anda dapat membuat instance Prometheus yang dikelola sendiri untuk mengumpulkan metrik dari bidang data instance ASM.
Berdasarkan Telemetry CRD, ASM menyediakan antarmuka grafis seperti yang ditunjukkan pada gambar berikut untuk menyederhanakan konfigurasi metrik kustom. Untuk informasi lebih lanjut, lihat Buat metrik kustom di ASM. 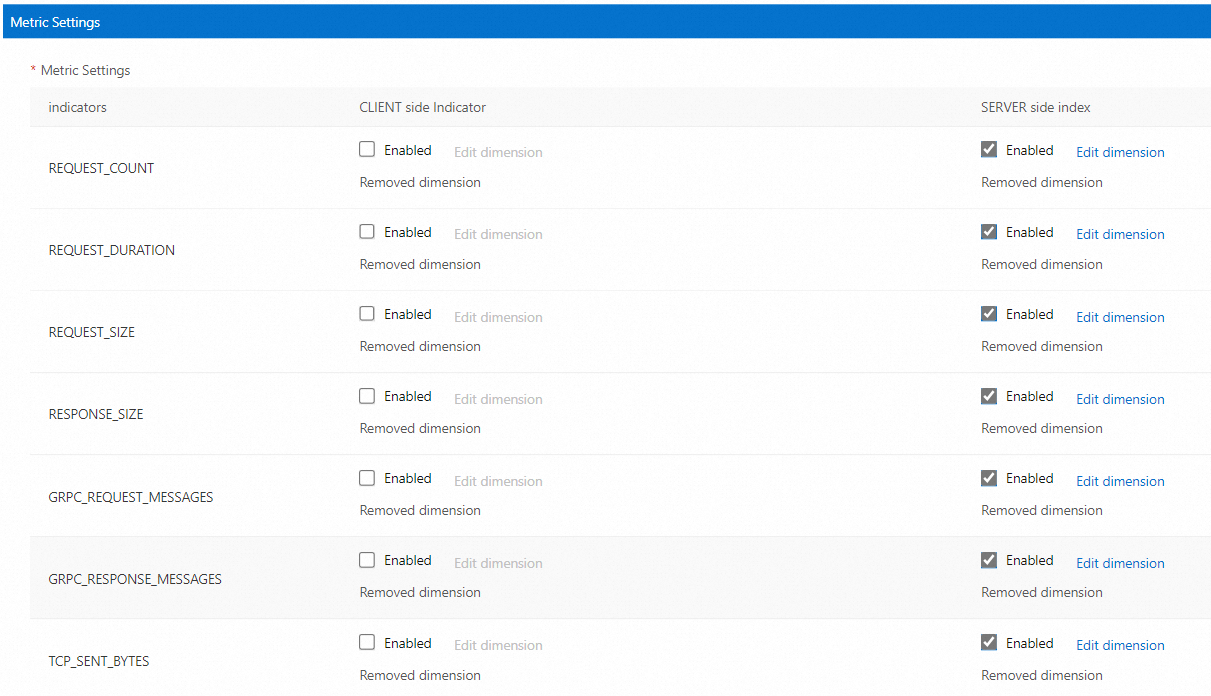
Kode sampel berikut setara dengan konfigurasi metrik kustom pada antarmuka grafis sebelumnya.
Pertimbangan untuk metrik
Manage Service for Prometheus adalah layanan berbayar. Saat Anda mengaktifkannya untuk pertama kali, tentukan ruang lingkup metrik yang ingin Anda amati berdasarkan kebutuhan bisnis Anda. Mengamati sejumlah besar metrik mengakibatkan biaya yang berlebihan. Misalnya, jika Anda ingin memantau gateway, Anda harus mengaktifkan metrik sisi klien. Jika Anda telah mengaktifkan metrik, pengaturan sebelumnya dari metrik tersebut dipertahankan saat Anda mengaktifkan metrik lagi.
Fitur Mesh Topology bergantung pada metrik yang dilaporkan oleh proxy sisi. Jika Anda mengaktifkan Mesh Topology, menonaktifkan beberapa metrik dapat memengaruhi operasi normal Mesh Topology.
Jika Anda tidak mengaktifkan metrik sisi server REQUEST_COUNT, topologi layanan HTTP atau gRPC tidak dapat dihasilkan.
Jika Anda tidak mengaktifkan metrik sisi server TCP_SENT_BYTES, topologi layanan TCP tidak dapat dihasilkan.
Jika Anda menonaktifkan metrik sisi server REQUEST_SIZE dan REQUEST_DURATION dan metrik sisi klien REQUEST_SIZE, informasi pemantauan beberapa node dalam topologi mungkin gagal ditampilkan.
Konfigurasikan pengumpulan metrik
Setelah Anda mengaktifkan Managed Service for Prometheus, Anda dapat mengumpulkan metrik ke Managed Service for Prometheus untuk penyimpanan dan analisis. ASM mengintegrasikan Managed Service for Prometheus untuk memantau service mesh. Untuk informasi lebih lanjut, lihat Integrasikan Managed Service for Prometheus untuk memantau instance ASM.
Interval pengumpulan metrik memiliki dampak signifikan pada overhead pengumpulan metrik. Interval yang lebih lama berarti frekuensi penangkapan data yang lebih rendah. Ini mengurangi overhead yang timbul dari pemrosesan, penyimpanan, dan komputasi metrik. Interval pengumpulan metrik diatur ke 15 detik secara default. Nilai ini mungkin terlalu kecil untuk skenario produksi. Anda dapat mengatur interval pengumpulan metrik yang sesuai berdasarkan kebutuhan bisnis Anda. Jika Anda mengumpulkan metrik menggunakan Managed Service for Prometheus, konfigurasikan parameter yang diperlukan di konsol Application Real-Time Monitoring Service (ARMS). Untuk informasi lebih lanjut, lihat Konfigurasikan aturan pengumpulan data.
Metrik yang diwakili oleh histogram seperti istio_request_duration_milliseconds_bucket, istio_request_bytes_bucket, dan istio_response_bytes_bucket melibatkan sejumlah besar data dan menghasilkan overhead tinggi. Untuk menghindari biaya berkelanjutan yang disebabkan oleh metrik kustom ini, Anda dapat membuang metrik kustom ini. Jika Anda menggunakan Managed Service for Prometheus, buka konsol ARMS untuk mengonfigurasi metrik. Untuk informasi lebih lanjut, lihat Buang metrik.
Anda dapat menerapkan instance Prometheus yang dikelola sendiri untuk memantau instance ASM. Untuk informasi lebih lanjut, lihat Pantau instance ASM menggunakan instance Prometheus yang dikelola sendiri.
Seperti yang ditunjukkan pada gambar berikut, Anda dapat melihat metrik pada dasbor Grafana.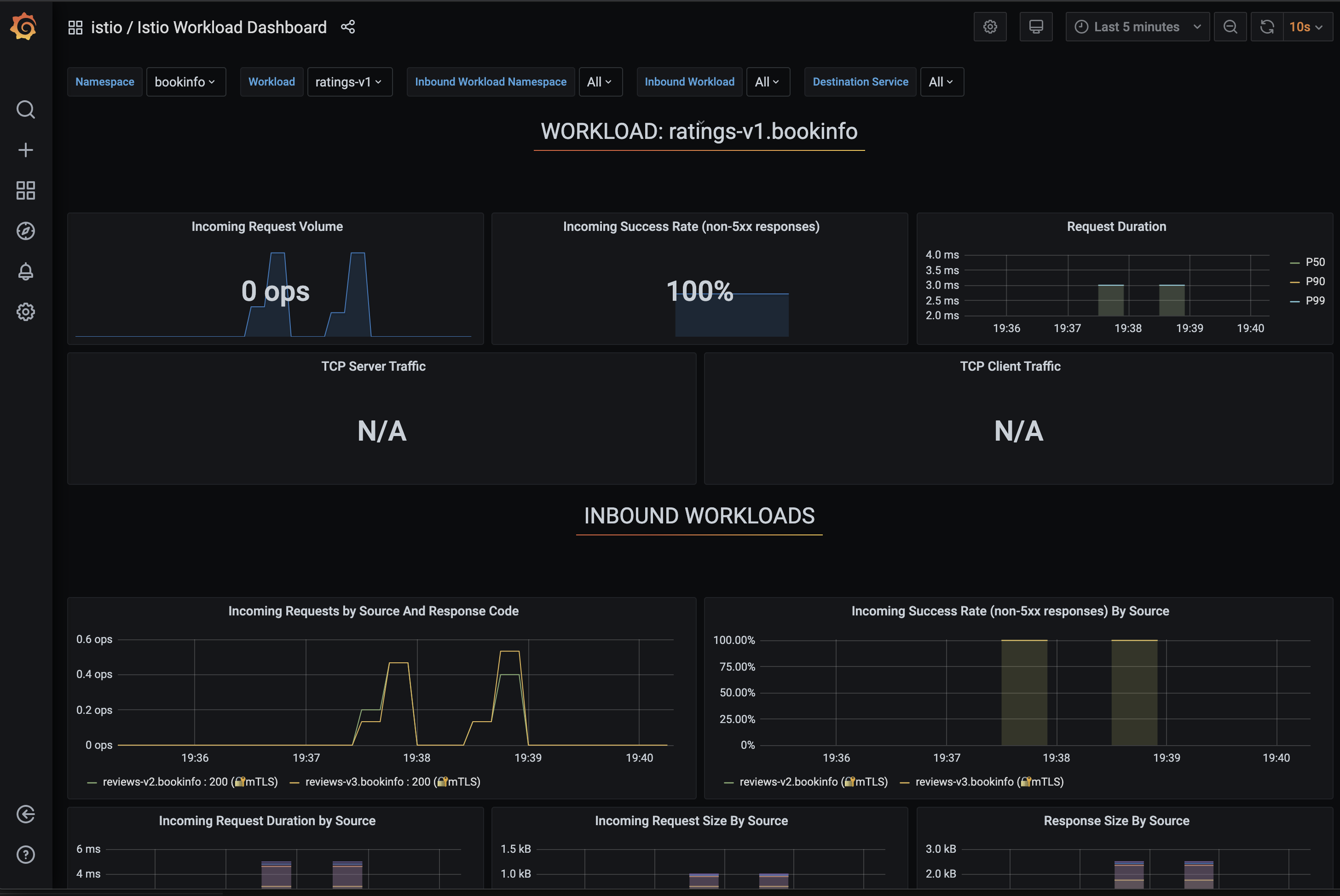
Gabungkan metrik Istio dengan metrik aplikasi
Untuk aplikasi yang terintegrasi dengan Prometheus, Anda dapat menggunakan proxy sisi untuk mengekspos metrik aplikasi dengan menggabungkan metrik Istio dengan metrik aplikasi. Setelah Anda mengaktifkan fitur penggabungan metrik Istio dengan metrik aplikasi, ASM menggabungkan metrik aplikasi dengan metrik Istio. Anotasi prometheus.io aplikasi ditambahkan ke semua pod pada bidang data untuk mengaktifkan kemampuan pengumpulan metrik Prometheus. Jika anotasi ini sudah ada, mereka akan ditimpa. Proxy sisi menggabungkan metrik Istio dengan metrik aplikasi. Prometheus dapat memperoleh metrik gabungan dari titik akhir :15020/stats/prometheus. Untuk informasi lebih lanjut, lihat Gabungkan metrik Istio dengan metrik aplikasi.
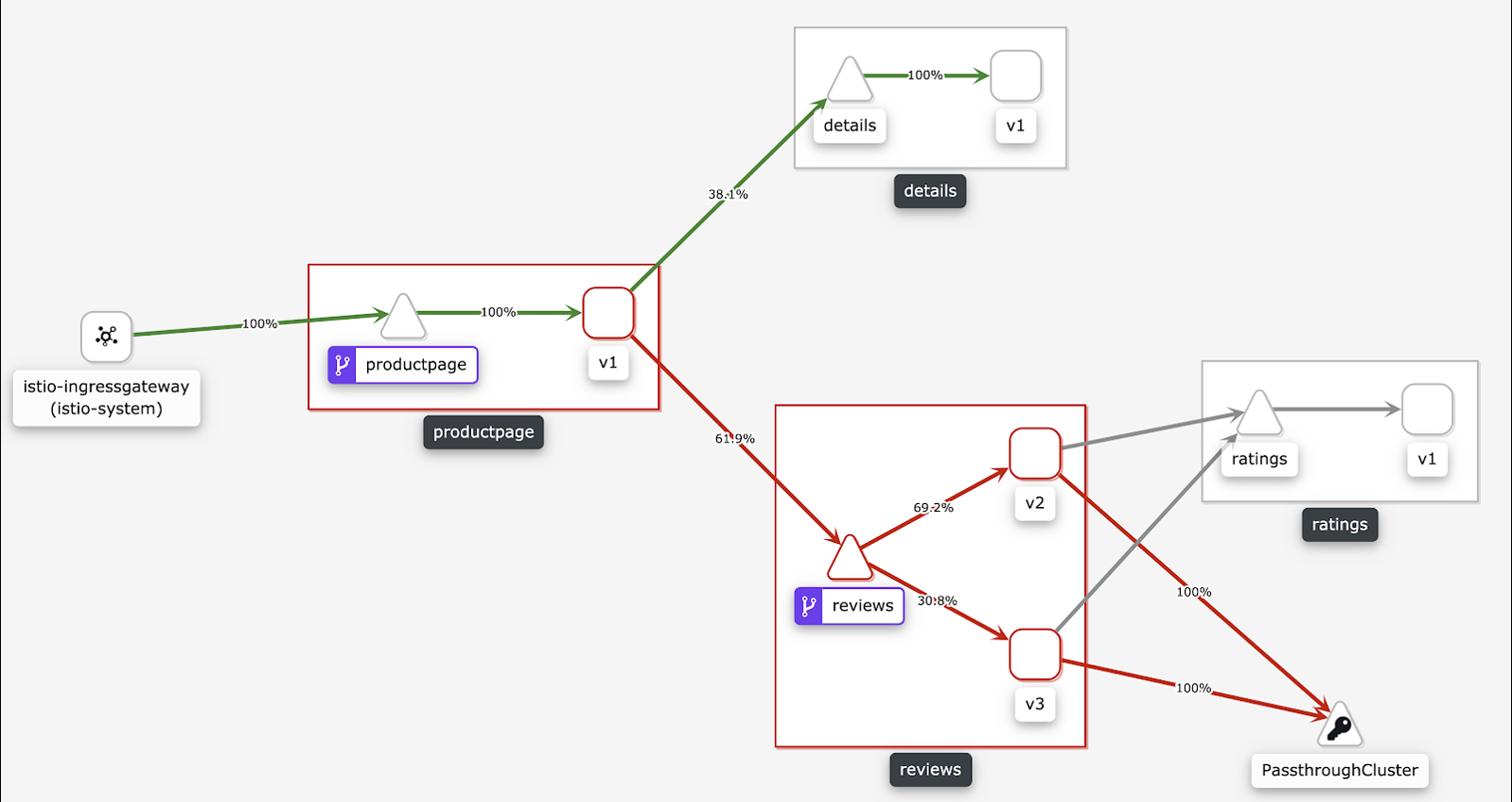
Mesh Topology
Mesh Topology adalah alat yang digunakan untuk mengamati instance ASM. Alat ini menyediakan GUI yang memungkinkan Anda melihat layanan dan konfigurasi terkait. Gambar berikut menunjukkan topologi layanan aplikasi. Untuk informasi lebih lanjut, lihat Aktifkan Mesh Topology untuk meningkatkan observabilitas.
SLO
Indikator tingkat layanan (SLI) adalah metrik yang mengukur kesehatan layanan. Tujuan tingkat layanan (SLO) adalah tujuan atau rentang tujuan yang perlu dicapai oleh layanan. SLO terdiri dari satu atau lebih SLI.
SLO memberikan cara formal untuk menggambarkan, mengukur, dan memantau kinerja, kualitas, dan keandalan aplikasi berorientasi mikro-layanan. SLO adalah tolok ukur kualitas bersama untuk pengembang aplikasi, operator platform, dan personel O&M. Mereka dapat menggunakan SLO sebagai referensi untuk mengukur dan terus meningkatkan kualitas layanan. SLO membantu menggambarkan kesehatan layanan secara lebih akurat.
Contoh SLO:
Rata-rata permintaan per detik (QPS) > 100.000/s
Latensi 99% permintaan akses < 500 ms
Bandwidth per menit untuk 99% permintaan akses > 200 MB/s
ASM menyediakan kemampuan pemantauan dan peringatan out-of-the-box berdasarkan SLO. Anda dapat memantau metrik kinerja panggilan antar layanan aplikasi, seperti latensi dan tingkat kesalahan.
ASM mendukung jenis SLI berikut:
Ketersediaan layanan: menunjukkan proporsi permintaan akses yang berhasil direspons. Jenis plugin untuk jenis SLI ini adalah availability. Jika kode status HTTP yang dikembalikan ke permintaan akses adalah 429 atau 5XX, permintaan akses tidak berhasil direspons. 5XX berarti bahwa kode status dimulai dengan 5.
Latensi: menunjukkan waktu yang diperlukan layanan untuk mengembalikan respons ke permintaan. Jenis plugin untuk jenis SLI ini adalah latency. Anda dapat menentukan latensi maksimum. Respons yang dikembalikan lebih lambat dari periode waktu yang ditentukan dianggap tidak memenuhi syarat.
Gambar berikut menunjukkan GUI yang disediakan oleh ASM bagi Anda untuk mendefinisikan konfigurasi SLO. 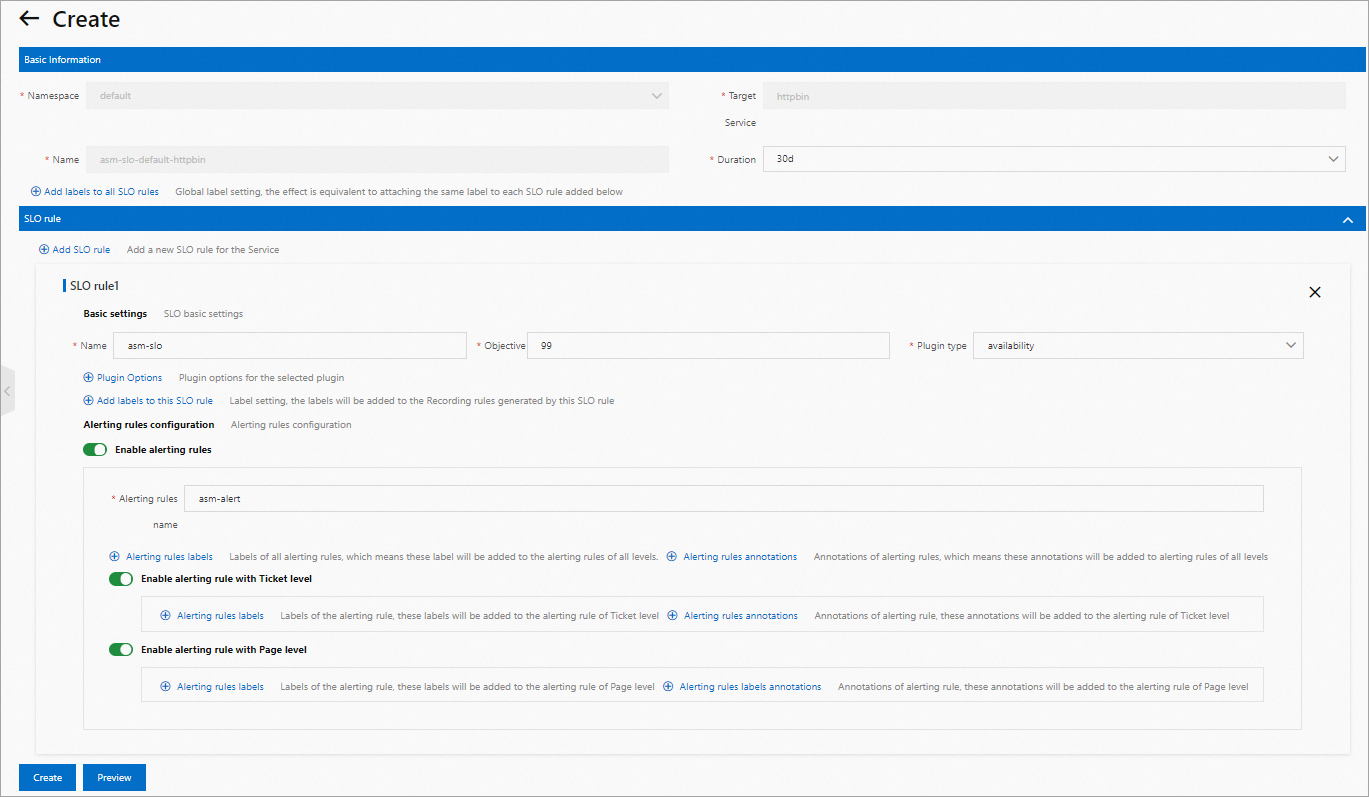
Setelah Anda mengonfigurasi SLO untuk aplikasi di ASM, aturan Prometheus secara otomatis dihasilkan. Anda dapat mengimpor aturan Prometheus yang dihasilkan ke sistem Prometheus agar SLO berlaku. Komponen Alertmanager mengumpulkan peringatan yang dihasilkan oleh server Prometheus dan mengirimkan peringatan ke kontak yang ditentukan. Gambar berikut menunjukkan halaman Alertmanager di mana Anda dapat melihat bahwa informasi peringatan kustom dikumpulkan. Untuk informasi lebih lanjut tentang SLO, lihat Manajemen SLO. 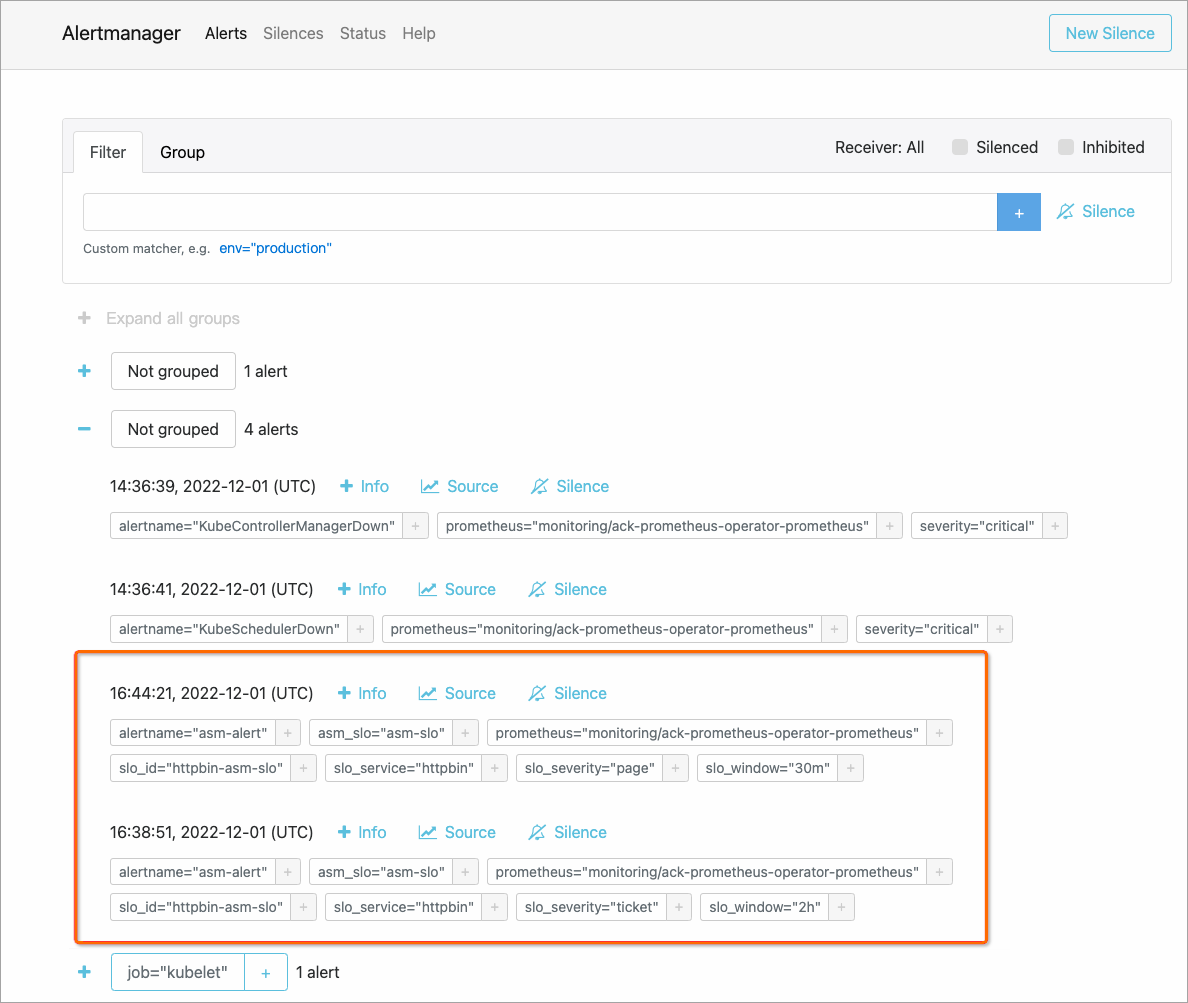
Pelacakan terdistribusi
Pelacakan terdistribusi dapat digunakan untuk memprofilkan dan memantau aplikasi, terutama yang dibangun menggunakan model mikro-layanan. Ini adalah fitur kunci untuk observabilitas dalam ASM. Dalam model mikro-layanan, sebuah mesh mengontrol komunikasi antar layanan. Oleh karena itu, perlu menggunakan teknologi pelacakan terdistribusi untuk melacak dan memantau panggilan antar layanan. Di Istio, Anda dapat menggunakan alat pelacakan terdistribusi seperti Jaeger dan Zipkin untuk mencapai tujuan ini. Dalam pelacakan terdistribusi, dua konsep berikut penting: jejak dan rentang.
Rentang: blok bangunan dasar pelacakan terdistribusi. Rentang mewakili unit pekerjaan atau operasi. Rentang dapat bersarang. Beberapa rentang membentuk jejak.
Jejak: mewakili proses lengkap untuk permintaan - dari inisiasinya hingga penyelesaiannya. Jejak terdiri dari beberapa rentang.
Meskipun proxy Istio dapat secara otomatis mengirim rentang, mereka memerlukan beberapa petunjuk untuk menghubungkan seluruh jejak. Aplikasi perlu menyebarkan header HTTP yang sesuai sehingga rentang yang dikirim oleh proxy Istio dapat dikorelasikan dengan benar menjadi satu jejak. Untuk melakukannya, aplikasi perlu mengumpulkan header berikut dan menyebarkannya dari permintaan masuk ke semua permintaan keluar:
x-request-id
x-b3-traceid
x-b3-spanid
x-b3-parentspanid
x-b3-sampled
x-b3-flags
x-ot-span-context
Konfigurasikan aturan pembuatan data pelacakan
Berdasarkan Telemetry CRD, ASM menyediakan antarmuka grafis seperti yang ditunjukkan pada gambar berikut untuk menyederhanakan konfigurasi aturan pembuatan data pelacakan terdistribusi. 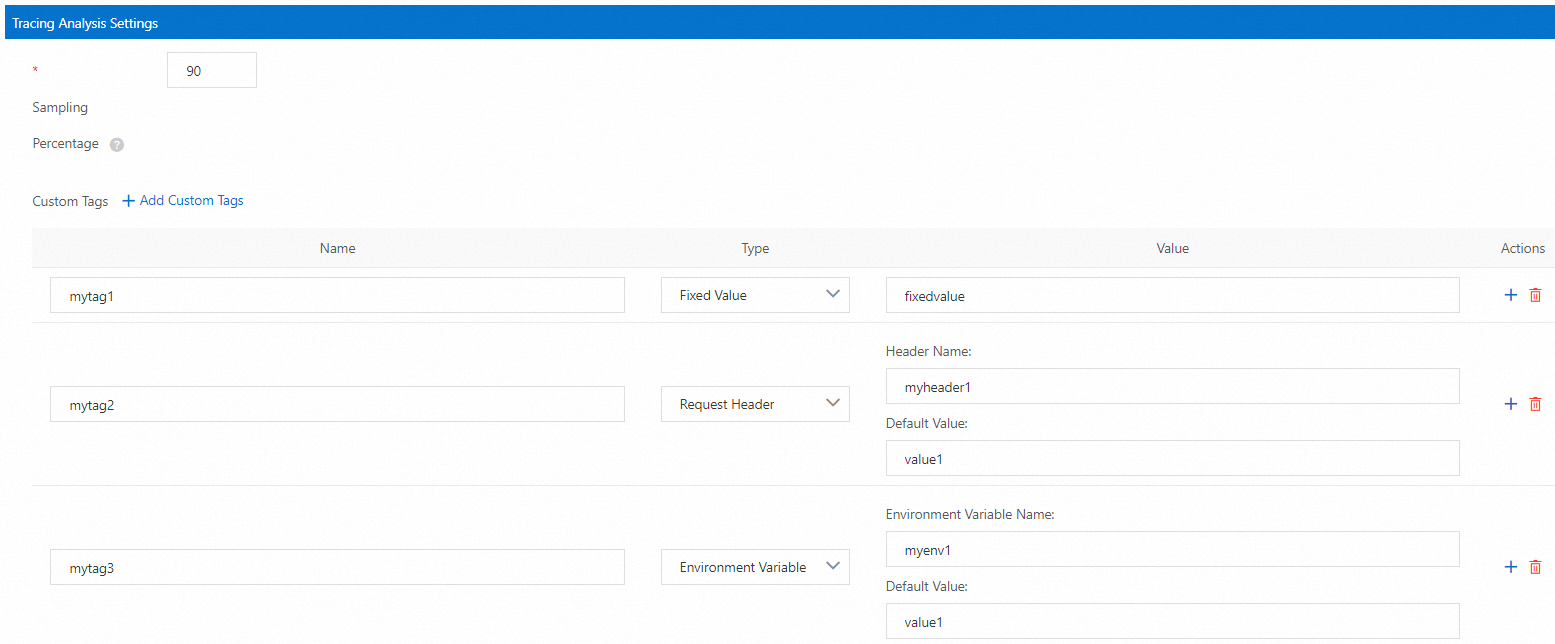
Kode sampel berikut setara dengan konfigurasi aturan pembuatan data pelacakan terdistribusi pada antarmuka grafis sebelumnya.
tracing:
- customTags:
mytag1:
literal:
value: fixedvalue
mytag2:
header:
defaultValue: value1
name: myheader1
mytag3:
environment:
defaultValue: value1
name: myenv1
providers:
- name: zipkin
randomSamplingPercentage: 90Konfigurasikan pengumpulan data pelacakan
Jika Anda perlu mengirim data pelacakan yang dikumpulkan ke layanan cloud terkelola atau layanan yang dikelola sendiri, Anda dapat menggunakan metode berikut:
Dalam layanan cloud terkelola, Anda dapat menggunakan layanan manajemen aplikasi cloud-native untuk mengumpulkan dan menganalisis data. Untuk informasi lebih lanjut, lihat Aktifkan pelacakan terdistribusi di ASM.
Dalam layanan yang dikelola sendiri, Anda dapat menggunakan alat pengumpulan dan analisis data open source, seperti Zipkin dan Jaeger, untuk mengumpulkan dan menganalisis data. Untuk informasi lebih lanjut, lihat Ekspor data pelacakan ASM ke sistem yang dikelola sendiri.