Tutorial ini memandu Anda melalui konfigurasi solusi rekomendasi kustom di PAI-Rec menggunakan dataset publik. Pada akhirnya, Anda akan memiliki pipeline rekomendasi end-to-end yang berfungsi, mencakup rekayasa fitur, recall, dan peringkat detail halus—dengan alur kerja yang diterapkan ke DataWorks.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Mengaktifkan PAI. Lihat Aktifkan PAI dan buat ruang kerja default.
Membuat virtual private cloud (VPC) dan vSwitch. Lihat Buat VPC dengan Blok CIDR IPv4.
Mengaktifkan PAI-FeatureStore dengan FeatureDB sebagai online store (jangan aktifkan Hologres). Lihat bagian Prasyarat dari Buat sumber data dan Buat online store: FeatureDB.
MaxCompute telah diaktifkan dan proyek MaxCompute bernama project_mc telah dibuat. Lihat Aktifkan MaxCompute dan Buat proyek MaxCompute.
Membuat bucket Object Storage Service (OSS). Lihat Buat bucket.
Mengaktifkan DataWorks dan menyelesaikan pengaturan berikut:
Membuat ruang kerja DataWorks. Lihat Buat ruang kerja.
Membeli kelompok sumber daya Serverless untuk DataWorks (digunakan untuk menyinkronkan data ke PAI-FeatureStore dan menjalankan perintah eascmd guna membuat serta memperbarui layanan PAI-EAS). Lihat Gunakan kelompok sumber daya Serverless.
Mengonfigurasi sumber data OSS dan sumber data MaxCompute di DataWorks. Lihat Manajemen sumber data dan Sambungkan sumber daya komputasi MaxCompute.
Membuat proyek FeatureStore dan entitas fitur. Lewati langkah ini jika Anda menggunakan kelompok sumber daya Serverless. Jika Anda menggunakan kelompok sumber daya khusus, instal SDK Python FeatureStore. Lihat II. Buat dan daftarkan FeatureStore dan Instal SDK Python FeatureStore.
Mengaktifkan Flink dengan Storage Type diatur ke OSS bucket (bukan Fully Managed Storage). Bucket OSS untuk Flink harus sama dengan yang dikonfigurasi untuk PAI-Rec. Flink digunakan untuk mencatat data perilaku pengguna real-time dan menghitung fitur pengguna real-time. Lihat Aktifkan Realtime Compute for Apache Flink.
(Bersyarat) Jika Anda menggunakan EasyRec (TensorFlow): model dilatih di MaxCompute secara default.
(Bersyarat) Jika Anda menggunakan TorchEasyRec (PyTorch): model dilatih di PAI-DLC secara default. Untuk mengunduh data MaxCompute di PAI-DLC, aktifkan Data Transmission Service (DTS). Lihat Beli dan gunakan kelompok sumber daya khusus untuk Data Transmission Service.
Langkah 1: Buat instans PAI-Rec dan inisialisasi layanan
Langkah ini menyediakan instans PAI-Rec Edisi Premium dan menghubungkannya ke sumber daya cloud yang telah Anda siapkan dalam prasyarat. Edisi Premium wajib digunakan—edisi ini mencakup diagnostik data dan fitur solusi rekomendasi kustom yang digunakan dalam tutorial ini.
Masuk ke halaman utama Personalized Recommendation Platform dan klik Buy Now.
Pada halaman pembelian, atur parameter berikut dan klik Buy Now.
Parameter Deskripsi Region and zone Wilayah tempat layanan cloud Anda diterapkan. Service type Pilih Premium Edition. Edisi Premium menambahkan fitur diagnostik data dan solusi rekomendasi kustom dibandingkan Edisi Standar. Masuk ke Konsol PAI-Rec dan pilih wilayah Anda dari bilah menu atas.
Di panel navigasi kiri, klik Instance list. Klik nama instans untuk membuka halaman detail instans.
Pada bagian Operation guide, klik Init. Anda akan diarahkan ke System configurations > End-to-End service. Klik Edit, konfigurasikan sumber daya pada tabel berikut, lalu klik Done.
Di panel navigasi kiri, pilih System configurations > Permission management. Pada tab Access service, verifikasi bahwa akses telah diberikan untuk setiap produk cloud.
Langkah 2: Klon dataset publik
Langkah ini memuat data sampel ke dalam proyek MaxCompute Anda. PAI-Rec menyediakan tiga tabel bersama di proyek publik pai_online_project:
Tabel pengguna:
pai_online_project.rec_sln_demo_user_tableTabel item:
pai_online_project.rec_sln_demo_item_tableTabel perilaku:
pai_online_project.rec_sln_demo_behavior_table
Data dalam tabel-tabel ini dihasilkan secara acak dan tidak memiliki makna bisnis nyata, sehingga metrik pelatihan seperti Area Under the Curve (AUC) akan rendah. Hal ini diharapkan untuk pengaturan demo.
Dua metode tersedia:
| Metode | Dukungan penjadwalan | Kapan digunakan |
|---|---|---|
| Sinkronkan jendela waktu tetap menggunakan SQL | Tidak | Pengaturan satu kali untuk menjelajahi tutorial |
| Hasilkan data menggunakan skrip Python | Ya (harian) | Pelatihan model rutin dengan tugas terjadwal |
Untuk pembuatan data harian dan pelatihan model, gunakan metode skrip Python.
Sinkronkan jendela waktu tetap
Jalankan perintah SQL di DataWorks untuk menyalin ketiga tabel dari pai_online_project ke proyek MaxCompute Anda (misalnya, project_mc).
Masuk ke Konsol DataWorks dan pilih wilayah Anda.
Di panel navigasi kiri, klik Data development and O&M > Data development.
Pilih ruang kerja DataWorks yang telah Anda buat dan klik Go to data development.
Arahkan kursor ke Create dan pilih Create node > MaxCompute > ODPS SQL. Atur parameter berikut dan klik Confirm.
Di editor node, tempel dan jalankan SQL berikut. Sebelum menjalankan, konfigurasikan variabel penjadwalan agar
${bizdate}diatur ke tanggal kemarin dan${bizdate_100}diatur ke 100 hari sebelum${bizdate}. Konfigurasikan parameter penjadwalan sebagai berikut: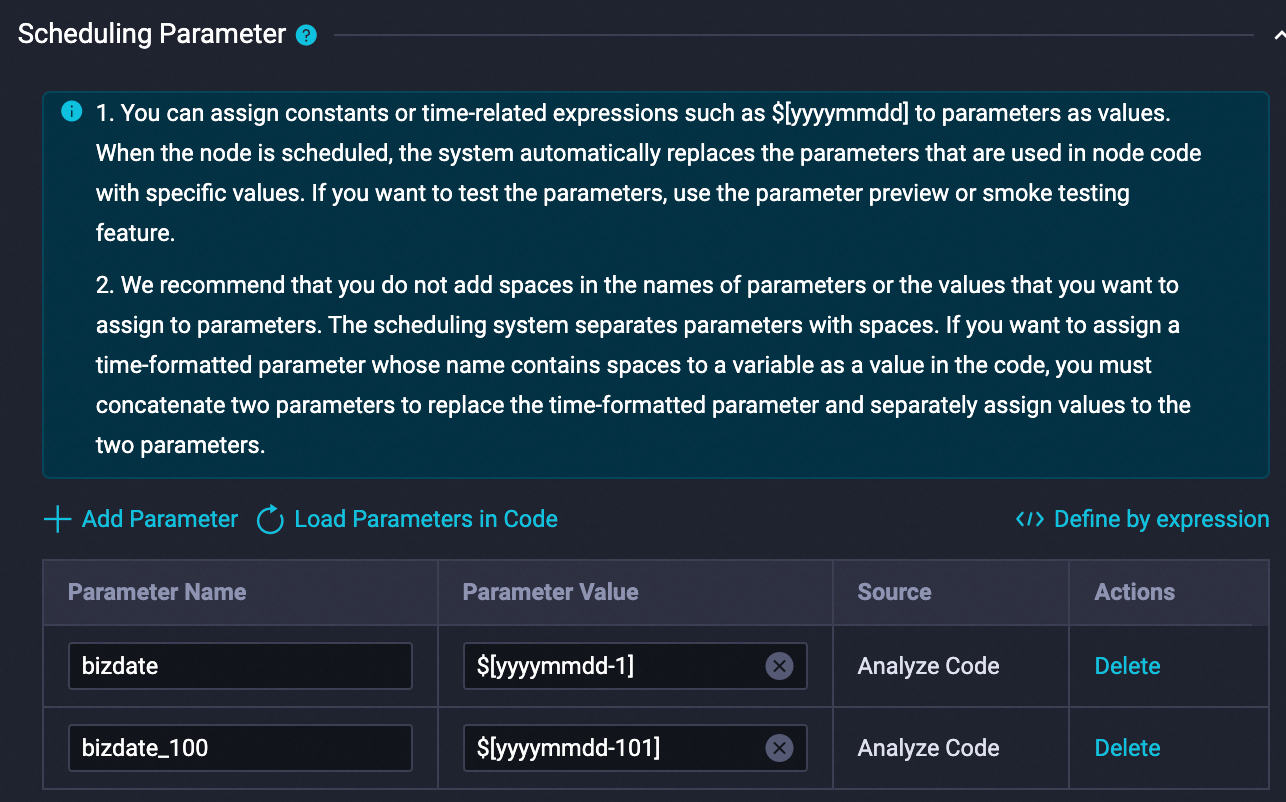 Jalankan SQL berikut sekali untuk menyalin data dari proyek publik ke proyek Anda:
Jalankan SQL berikut sekali untuk menyalin data dari proyek publik ke proyek Anda:CREATE TABLE IF NOT EXISTS rec_sln_demo_user_table_v1( user_id BIGINT COMMENT 'Unique user ID', gender STRING COMMENT 'Gender', age BIGINT COMMENT 'Age', city STRING COMMENT 'City', item_cnt BIGINT COMMENT 'Number of created items', follow_cnt BIGINT COMMENT 'Number of follows', follower_cnt BIGINT COMMENT 'Number of followers', register_time BIGINT COMMENT 'Registration time', tags STRING COMMENT 'User tags' ) PARTITIONED BY (ds STRING) STORED AS ALIORC; INSERT OVERWRITE TABLE rec_sln_demo_user_table_v1 PARTITION(ds) SELECT * FROM pai_online_project.rec_sln_demo_user_table WHERE ds >= "${bizdate_100}" and ds <= "${bizdate}"; CREATE TABLE IF NOT EXISTS rec_sln_demo_item_table_v1( item_id BIGINT COMMENT 'Item ID', duration DOUBLE COMMENT 'Video duration', title STRING COMMENT 'Title', category STRING COMMENT 'Primary tag', author BIGINT COMMENT 'Author', click_count BIGINT COMMENT 'Total clicks', praise_count BIGINT COMMENT 'Total likes', pub_time BIGINT COMMENT 'Publication time' ) PARTITIONED BY (ds STRING) STORED AS ALIORC; INSERT OVERWRITE TABLE rec_sln_demo_item_table_v1 PARTITION(ds) SELECT * FROM pai_online_project.rec_sln_demo_item_table WHERE ds >= "${bizdate_100}" and ds <= "${bizdate}"; CREATE TABLE IF NOT EXISTS rec_sln_demo_behavior_table_v1( request_id STRING COMMENT 'Instrumentation ID/Request ID', user_id STRING COMMENT 'Unique user ID', exp_id STRING COMMENT 'Experiment ID', page STRING COMMENT 'Page', net_type STRING COMMENT 'Network type', event_time BIGINT COMMENT 'Behavior time', item_id STRING COMMENT 'Item ID', event STRING COMMENT 'Behavior type', playtime DOUBLE COMMENT 'Playback/Read duration' ) PARTITIONED BY (ds STRING) STORED AS ALIORC; INSERT OVERWRITE TABLE rec_sln_demo_behavior_table_v1 PARTITION(ds) SELECT * FROM pai_online_project.rec_sln_demo_behavior_table WHERE ds >= "${bizdate_100}" and ds <= "${bizdate}";
Hasilkan data menggunakan skrip Python
Gunakan metode ini untuk menjadwalkan pembuatan data harian. Skrip ini menghasilkan data sintetis untuk rentang waktu tertentu.
Di konsol DataWorks, buat node PyODPS 3. Lihat Buat dan kelola node MaxCompute.
Unduh create_data.py dan tempel isinya ke dalam node PyODPS 3.
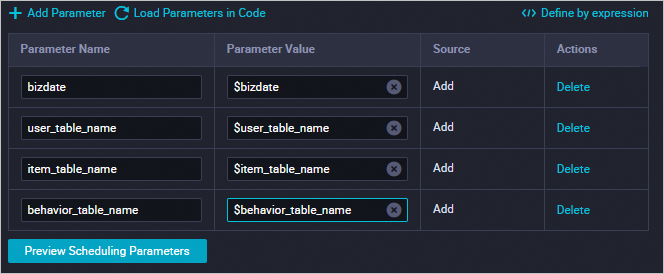
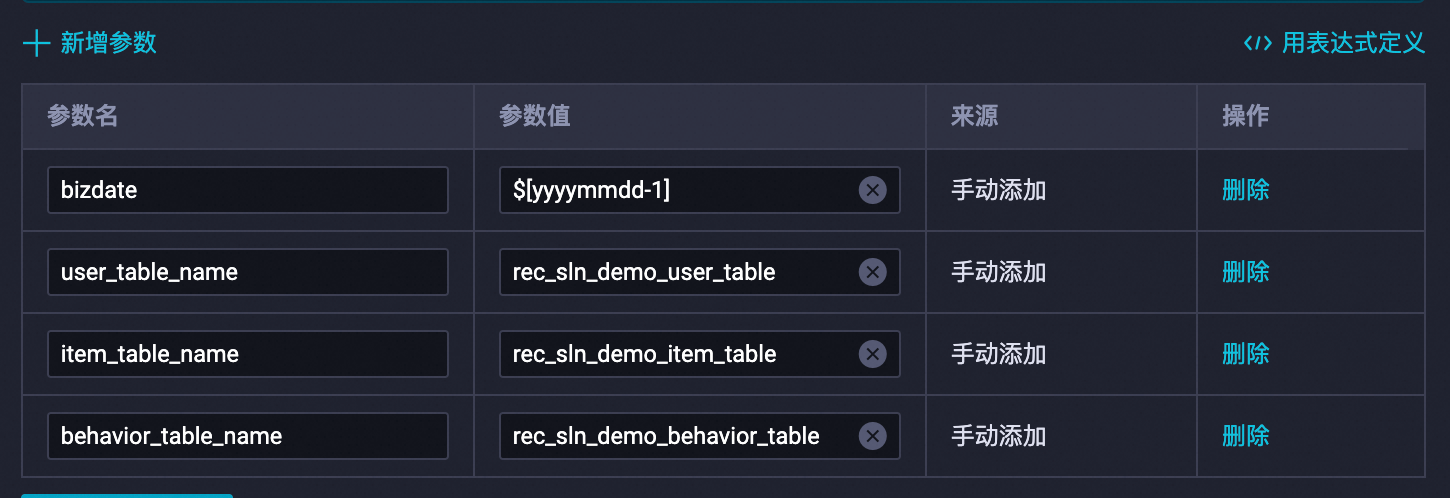
Di panel kanan, klik Scheduling configurations dan konfigurasikan parameter penjadwalan. Ganti variabel berikut: Setelah penggantian: Konfigurasikan dependensi penjadwalan, lalu klik ikon Simpan
 dan Submit
dan Submit  .
.$user_table_name→rec_sln_demo_user_table$item_table_name→rec_sln_demo_item_table$behavior_table_name→rec_sln_demo_behavior_table
Buka Operation center dan pilih Periodic task O&M > Periodic tasks.
Di kolom Actions tugas target, pilih Backfill data > Current and descendant nodes.
Di panel Backfill data, atur waktu data dan klik Submit and go. Atur waktu data ke
Scheduled task date - 60untuk mengisi ulang data selama 60 hari dan memastikan integritas data.
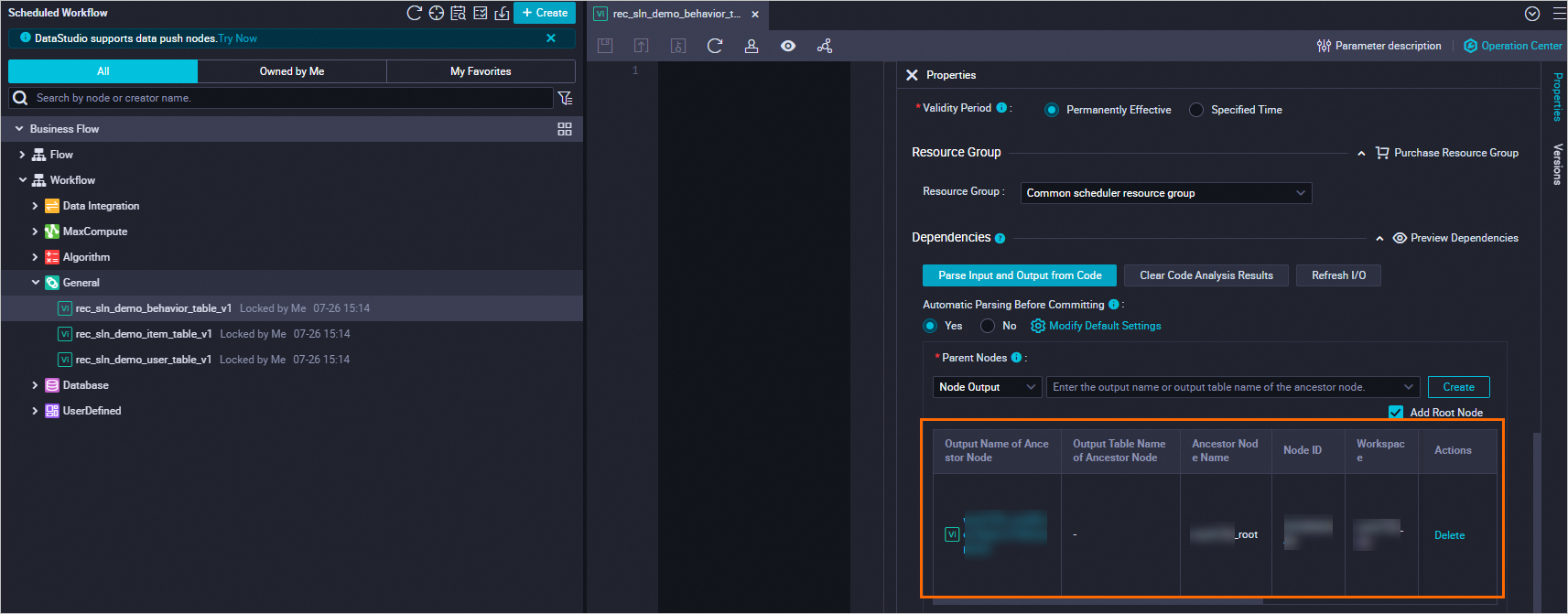
Konfigurasi node dependensi
Tambahkan tiga node virtual ke proyek DataWorks Anda. Node-node ini berfungsi sebagai jangkar dependensi untuk tabel data, memastikan tugas downstream menunggu data tersedia sebelum dijalankan.
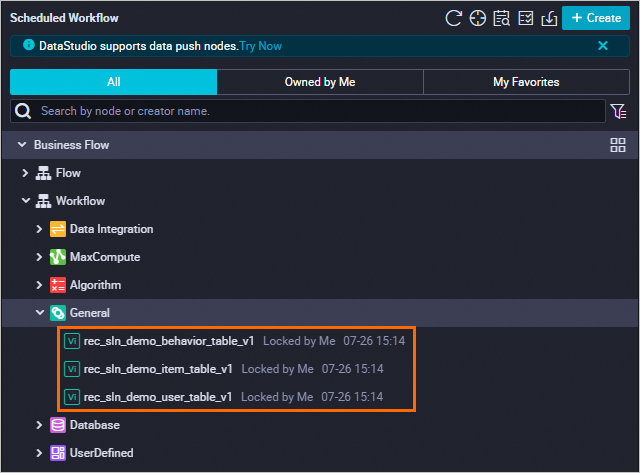
Arahkan kursor ke Create dan pilih Create node > General > Virtual node. Buat tiga node virtual menggunakan pengaturan berikut dan klik Confirm.
Untuk setiap node virtual, atur konten node menjadi
select 1;. Lalu klik Scheduling configurations di panel kanan dan lengkapi pengaturan berikut: Konfigurasikan ketiga node tersebut.Di bawah Time property, atur Rerun property ke Rerun when succeeded or failed.
Di bawah Scheduling dependencies > Upstream dependencies, masukkan nama ruang kerja DataWorks, pilih node dengan akhiran _root, lalu klik Add.
Klik ikon
 di depan setiap node virtual untuk mengirimnya.
di depan setiap node virtual untuk mengirimnya.
Langkah 3: Daftarkan data
Daftarkan ketiga tabel yang telah disinkronkan di PAI-Rec agar tersedia untuk rekayasa fitur, recall, dan konfigurasi peringkat pada langkah-langkah berikutnya.
Masuk ke Konsol PAI-Rec dan pilih wilayah Anda.
Di panel navigasi kiri, klik Instance list. Klik nama instans untuk membuka halaman detail instans.
Di panel navigasi kiri, pilih Custom recommendation solution > Data registration. Pada tab MaxCompute table, klik Add data table. Tambahkan satu tabel pengguna, satu tabel item, dan satu tabel perilaku menggunakan pengaturan berikut, lalu klik Start import.
Parameter Deskripsi Contoh MaxCompute project Proyek MaxCompute yang telah Anda buat. project_mcMaxCompute table Tabel data yang telah disinkronkan. Pengguna: rec_sln_demo_user_table_v1; Item:rec_sln_demo_item_table_v1; Perilaku:rec_sln_demo_behavior_table_v1Data table name Nama tampilan kustom untuk tabel. User Table,Item Table,Behavior Table
Langkah 4: Buat skenario rekomendasi
Buat skenario rekomendasi untuk menentukan konteks di mana rekomendasi disajikan (misalnya, feed halaman utama). Untuk latar belakang tentang skenario rekomendasi dan ID trafik, lihat Terms.
Di panel navigasi kiri, pilih Recommendation scenarios. Klik Create scenario, konfigurasikan parameter berikut, lalu klik OK.
Langkah 5: Buat dan konfigurasi solusi algoritma
Langkah ini mengonfigurasi algoritma recall dan peringkat untuk skenario rekomendasi Anda. Untuk pengaturan produksi lengkap, algoritma berikut tersedia:
Global hot recall: Mengurutkan item top-k berdasarkan statistik klik dari data log.
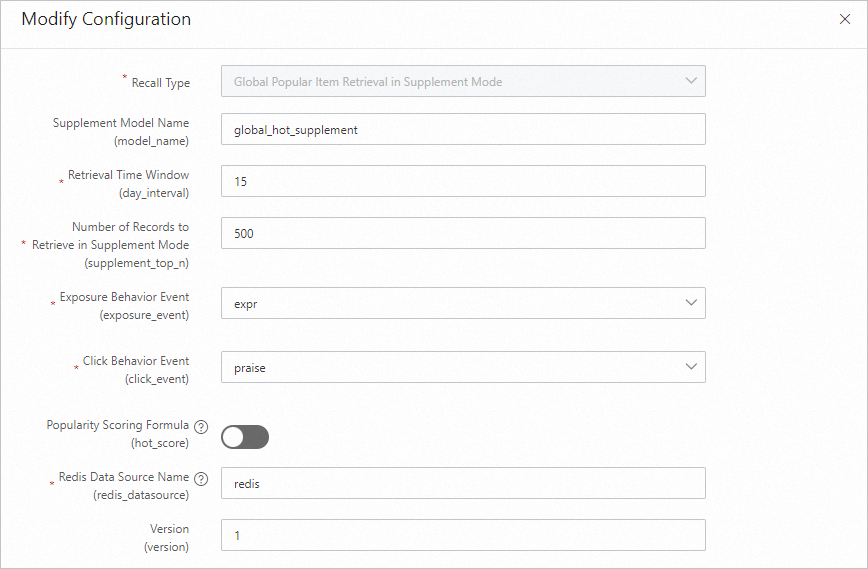
Global hot fallback recall: Menyimpan set kandidat cadangan di Redis untuk mencegah hasil kosong jika mesin recall utama gagal.
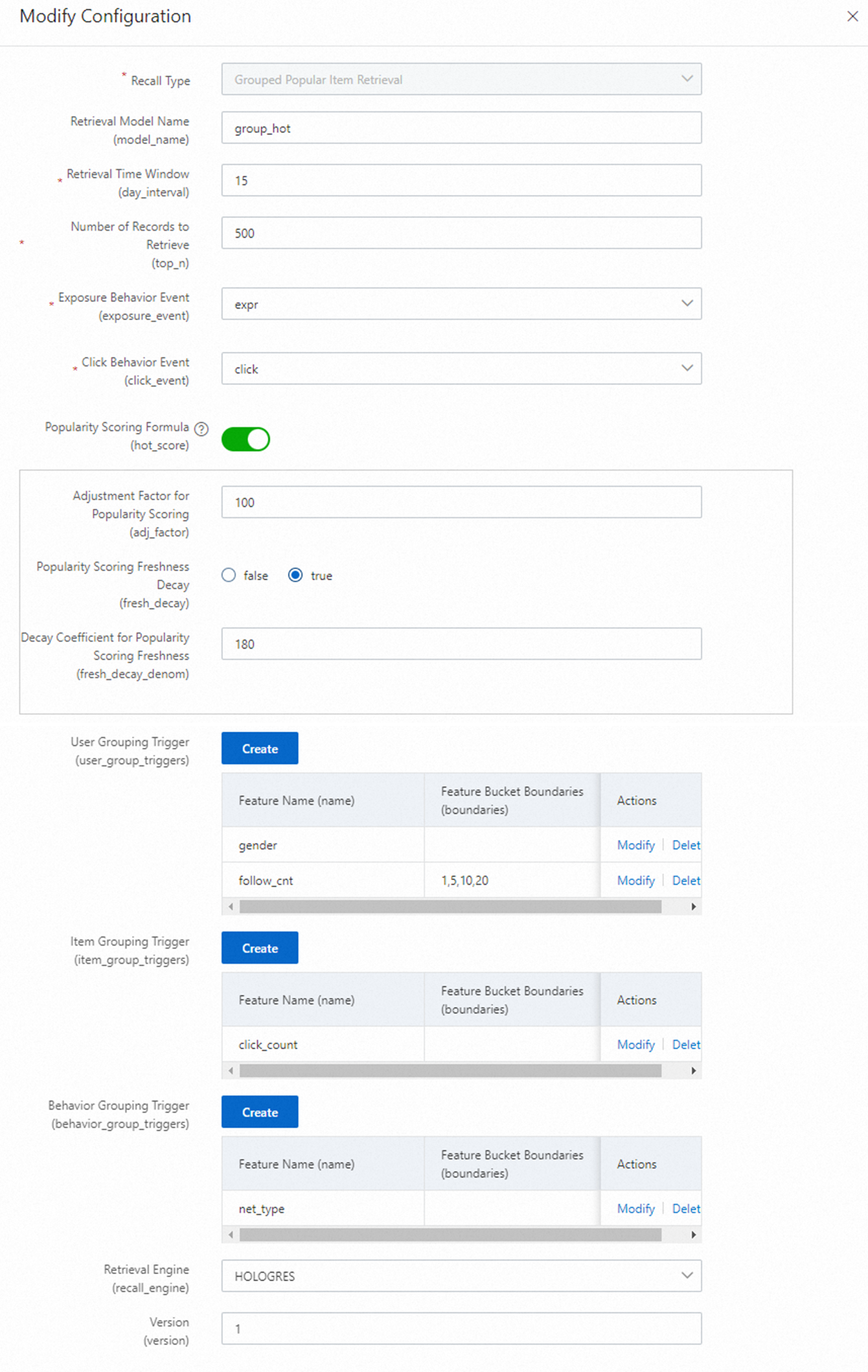
Grouped hot recall: Melakukan recall item berdasarkan grup atribut (misalnya, kota atau jenis kelamin) untuk meningkatkan personalisasi item populer.
etrec u2i recall: Recall pengguna-ke-item berdasarkan algoritma filtering kolaboratif etrec.
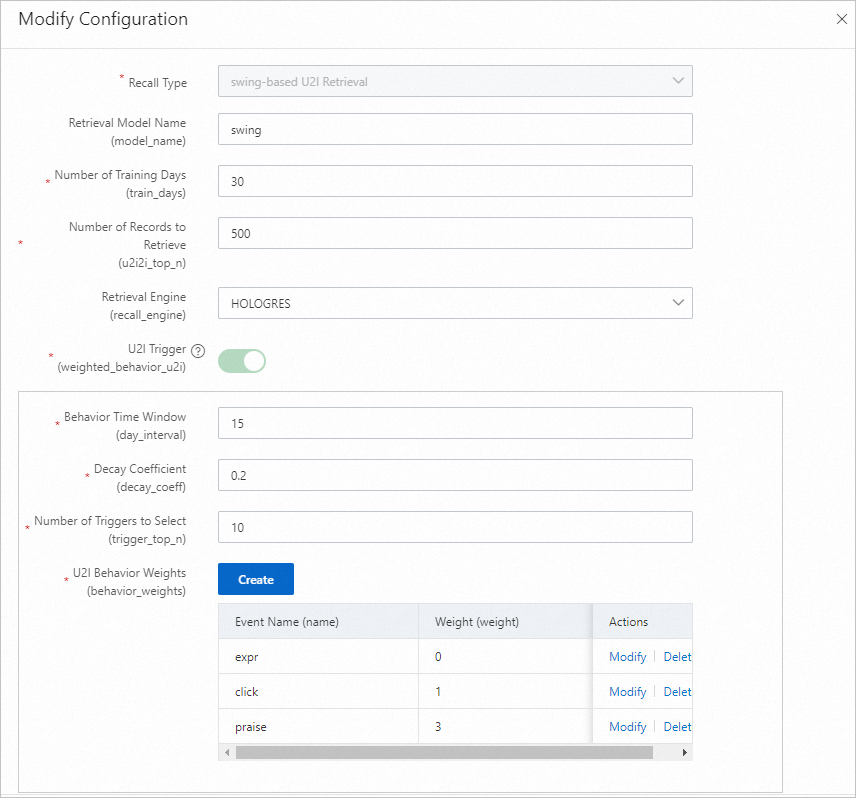
Swing u2i recall (opsional): Recall pengguna-ke-item berdasarkan algoritma Swing.
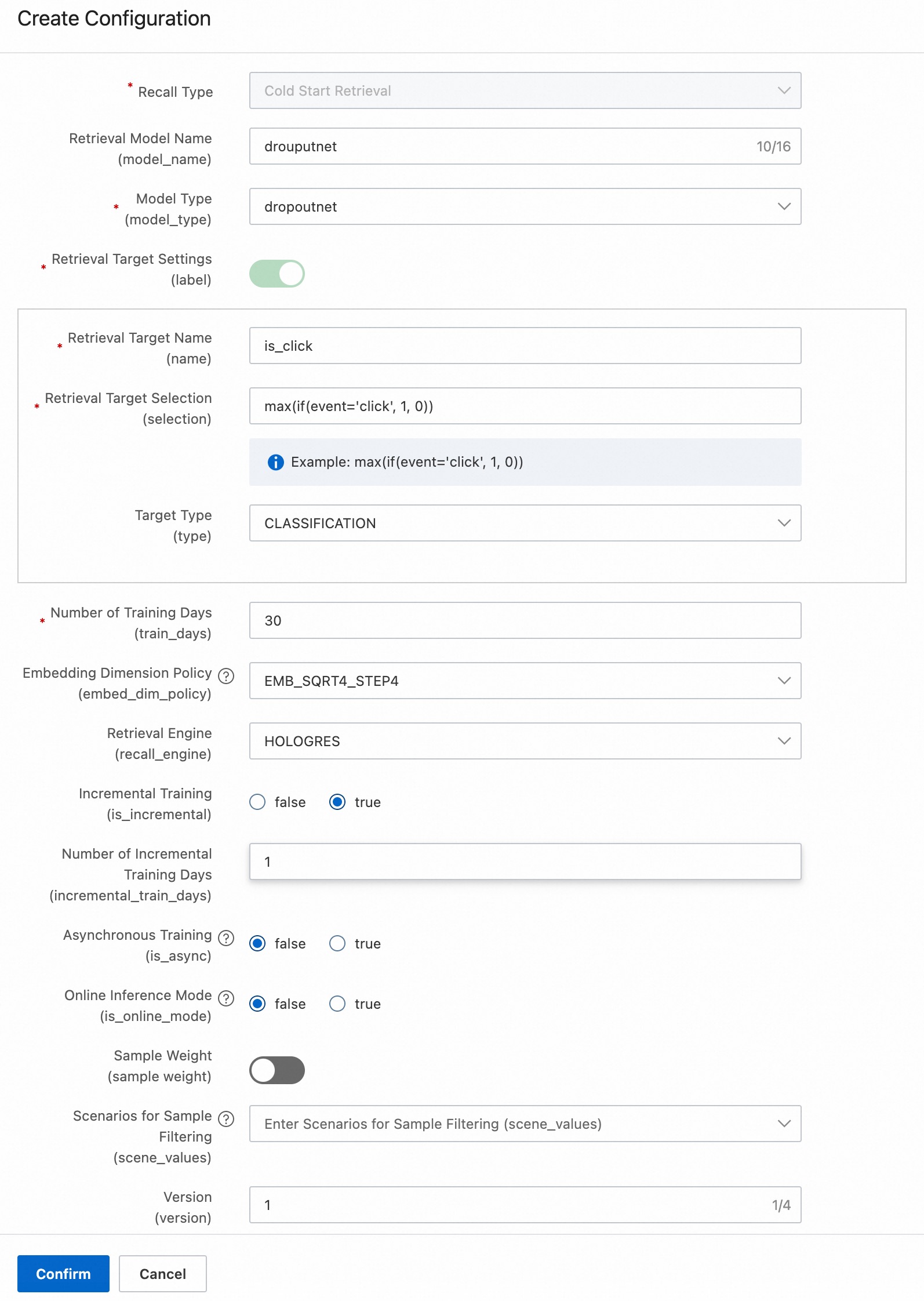
Cold-start recall (opsional): Recall untuk pengguna dan item baru menggunakan algoritma DropoutNet.
Fine-grained ranking: Pilih MultiTower untuk peringkat tujuan tunggal atau DBMTL untuk peringkat multi-tujuan.
Recall vektor dan recall PDN biasanya ditambahkan setelah tahap recall dasar selesai. Recall vektor memerlukan mesin recall vektor dan tidak dibahas dalam tutorial ini karena FeatureDB tidak mendukungnya.
Untuk menyelesaikan penyebaran dengan cepat, tutorial ini hanya mengonfigurasi global hot recall dan etrec u2i recall untuk tahap recall, serta fine-grained ranking untuk tahap peringkat.
Di panel navigasi kiri, pilih Custom recommendation solution > Solution configuration. Pilih skenario yang telah Anda buat, klik Create recommendation solution, isi parameter berikut, lalu klik Save and configure algorithm solution. Untuk parameter yang tidak tercantum di sini, pertahankan nilai default. Lihat Data table configuration untuk detailnya.
Pada node Data table configuration, klik Add di sebelah setiap tabel data. Konfigurasikan tabel log perilaku, tabel pengguna, dan tabel item seperti dijelaskan di bawah, lalu klik Next. Untuk parameter yang tidak tercantum di sini, pertahankan nilai default. Lihat Data table configuration. Tabel log perilaku Saat mengonfigurasi tabel log perilaku, sesuaikan field agar sesuai dengan data aktual Anda. Log perilaku demo berisi: ID permintaan, ID pengguna, halaman, waktu perilaku, dan jenis perilaku. Jika data Anda memiliki dimensi tambahan, klasifikasikan sebagai informasi pengguna atau item untuk rekayasa fitur.
User table
Item table
Pada node Feature configuration, atur parameter berikut, klik Generate features, atur versi fitur, lalu klik Next. Setelah mengklik Generate features, sistem akan menurunkan fitur statistik untuk pengguna dan item. Nilai default sudah cukup untuk tutorial ini. Lihat Feature configuration untuk menyesuaikan fitur turunan.
Pada node Recall configuration, klik Add di sebelah kategori recall target, konfigurasikan parameter, klik Confirm, lalu klik Next.
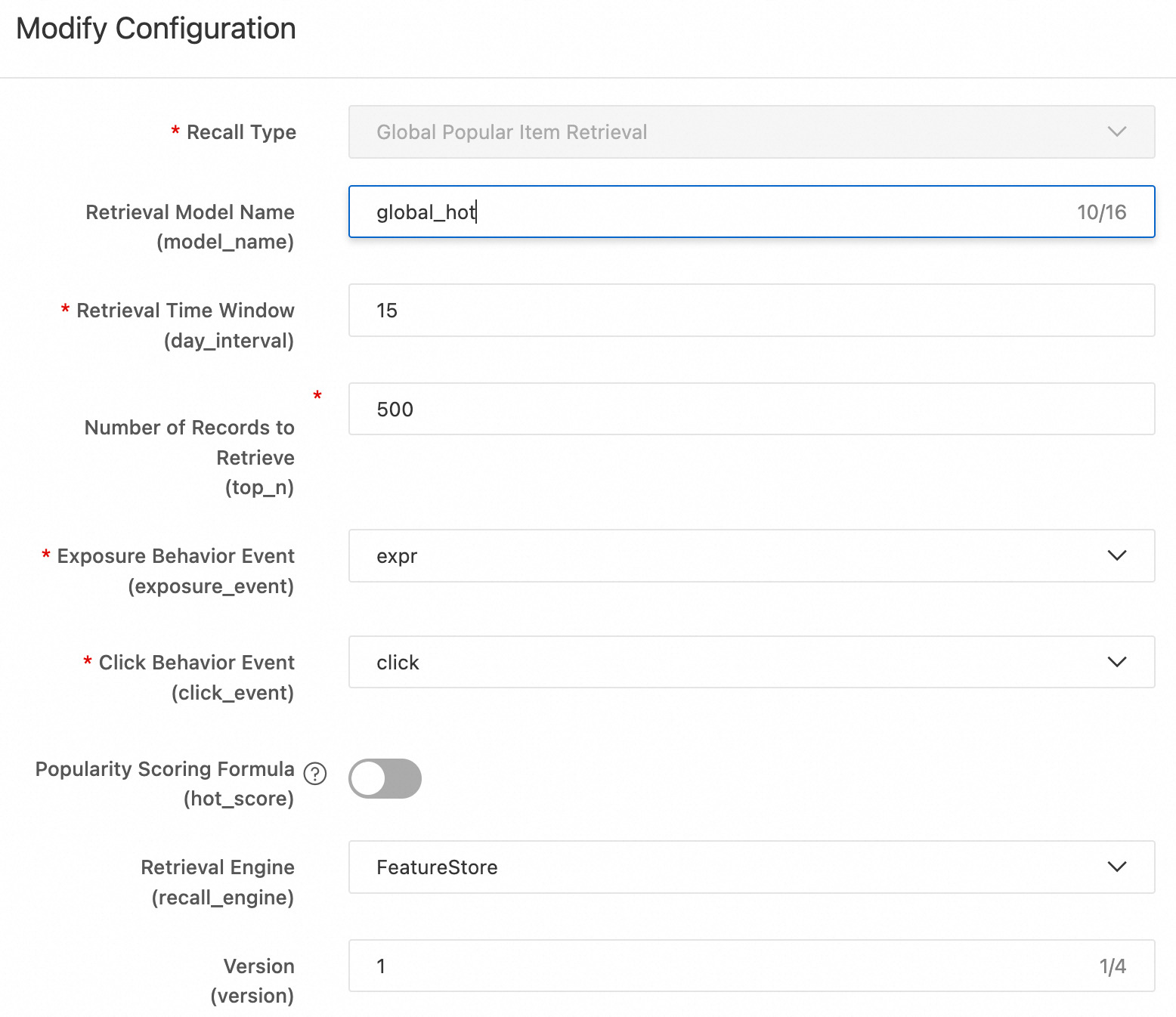
Bagian berikut menjelaskan setiap metode recall. Untuk penyebaran cepat, konfigurasikan hanya Global hot recall dan etrec u2i recall. Metode lainnya hanya sebagai referensi. #### Global hot recall Global hot recall menghasilkan daftar item populer yang diurutkan (
top_nitem) berdasarkan statistik event klik. Setelah kode diterapkan ke DataWorks, Anda dapat memodifikasi formula skor atau event target. Formula skornya adalah:Global hot recall
Global hot recall menghasilkan daftar item populer yang diurutkan (
top_nitem) berdasarkan statistik event klik. Setelah kode diterapkan ke DataWorks, Anda dapat memodifikasi formula skor atau event target.Formula skornya adalah:
click_uv * click_uv / (expr + adj_factor) * exp(-item_publish_days / fresh_decay_denom)Di mana:
click_uv: Untuk tingkat klik (CTR) yang sama, jumlah klik yang lebih besar menunjukkan popularitas yang lebih tinggi.click_uv / (expr + adj_factor): CTR yang telah dihaluskan.click_uvadalah jumlah pengguna unik yang mengklik;expradalah jumlah impresi. Faktor penyesuaianadj_factormencegah penyebut nol dan mengoreksi CTR saat jumlah impresi rendah.exp(-item_publish_days / fresh_decay_denom): Penalti kesegaran yang mengurangi skor item lama.item_publish_daysadalah jumlah hari sejak publikasi.
etrec u2i recall
etrec adalah algoritma filtering kolaboratif berbasis item. Lihat Collaborative filtering etrec untuk detailnya.
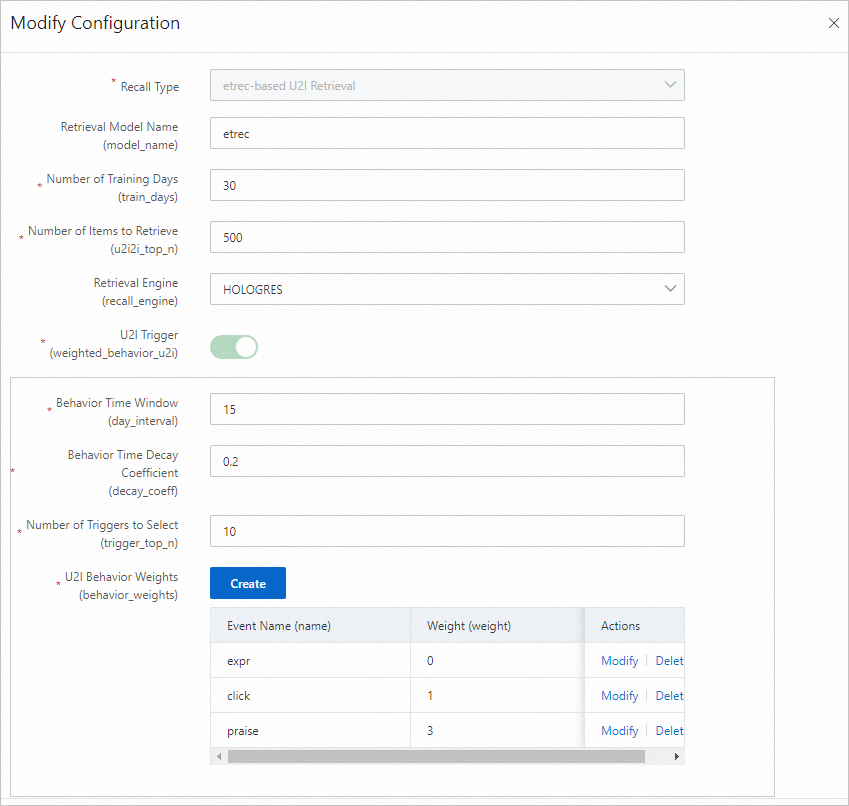
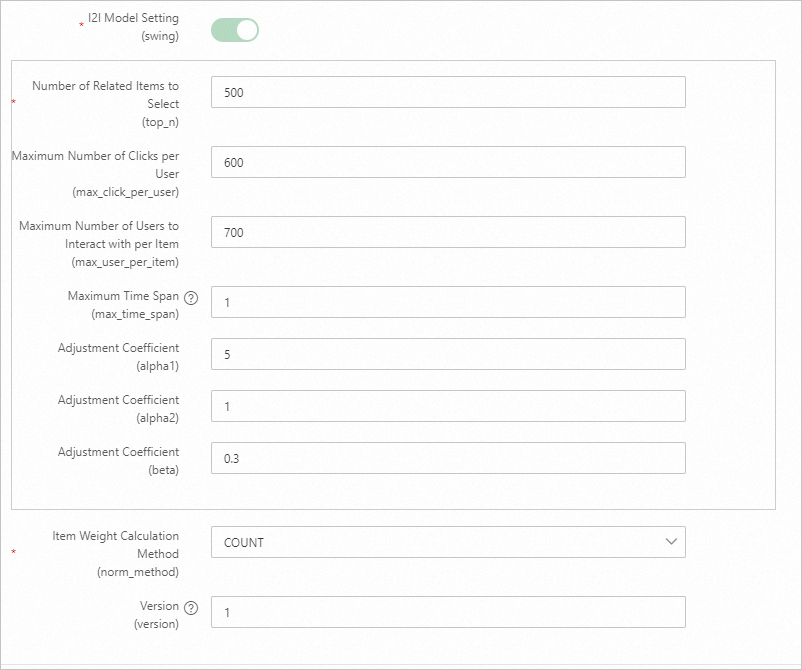
Parameter Deskripsi Training days Jumlah hari log perilaku yang digunakan untuk pelatihan. Default: 30. Sesuaikan berdasarkan volume log. Recall count Jumlah akhir pasangan pengguna-ke-item yang dihasilkan secara offline. U2ITrigger Item yang telah berinteraksi dengan pengguna (misalnya, diklik, difavoritkan, atau dibeli). Jangan sertakan item yang hanya terkena impresi. Behavior time window Jumlah hari data perilaku yang dikumpulkan. Default: 15. Behavior time attenuation coefficient Nilai antara 0 dan 1. Nilai lebih tinggi menyebabkan perilaku masa lalu lebih cepat meluruh, sehingga mengurangi bobotnya dalam membangun item pemicu. Trigger selection count Jumlah ID item per pengguna yang digunakan untuk melakukan Produk Kartesius dengan data i2i dari etrec. Nilai antara 10 dan 50 umumnya digunakan. Terlalu banyak pemicu menghasilkan set kandidat yang terlalu besar. U2i behavior weight Atur bobot event impresi ke 0 atau biarkan tidak diatur. I2I model settings Parameter model etrec. Lihat Collaborative filtering etrec. Hindari mengatur jumlah pemilihan item terkait terlalu tinggi. 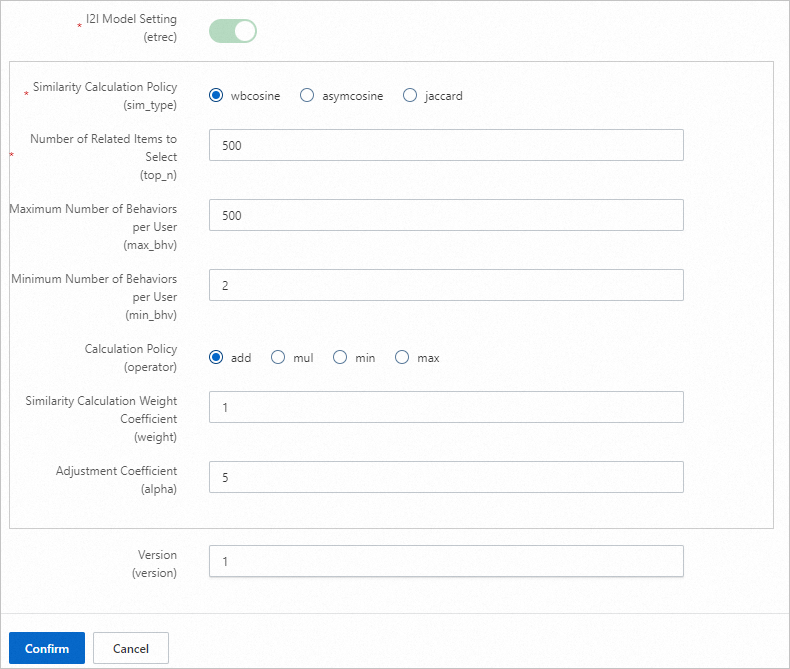
Grouped hot recall
Siapkan peringkat berdasarkan grup atribut (misalnya, kota dan jenis kelamin) untuk memberikan personalisasi awal. Contoh berikut menggunakan kombinasi jenis kelamin dan nilai bucket dari atribut numerik sebagai grup.
Swing u2i recall
Swing mengukur kemiripan item berdasarkan prinsip Pengguna-Item-Pengguna.
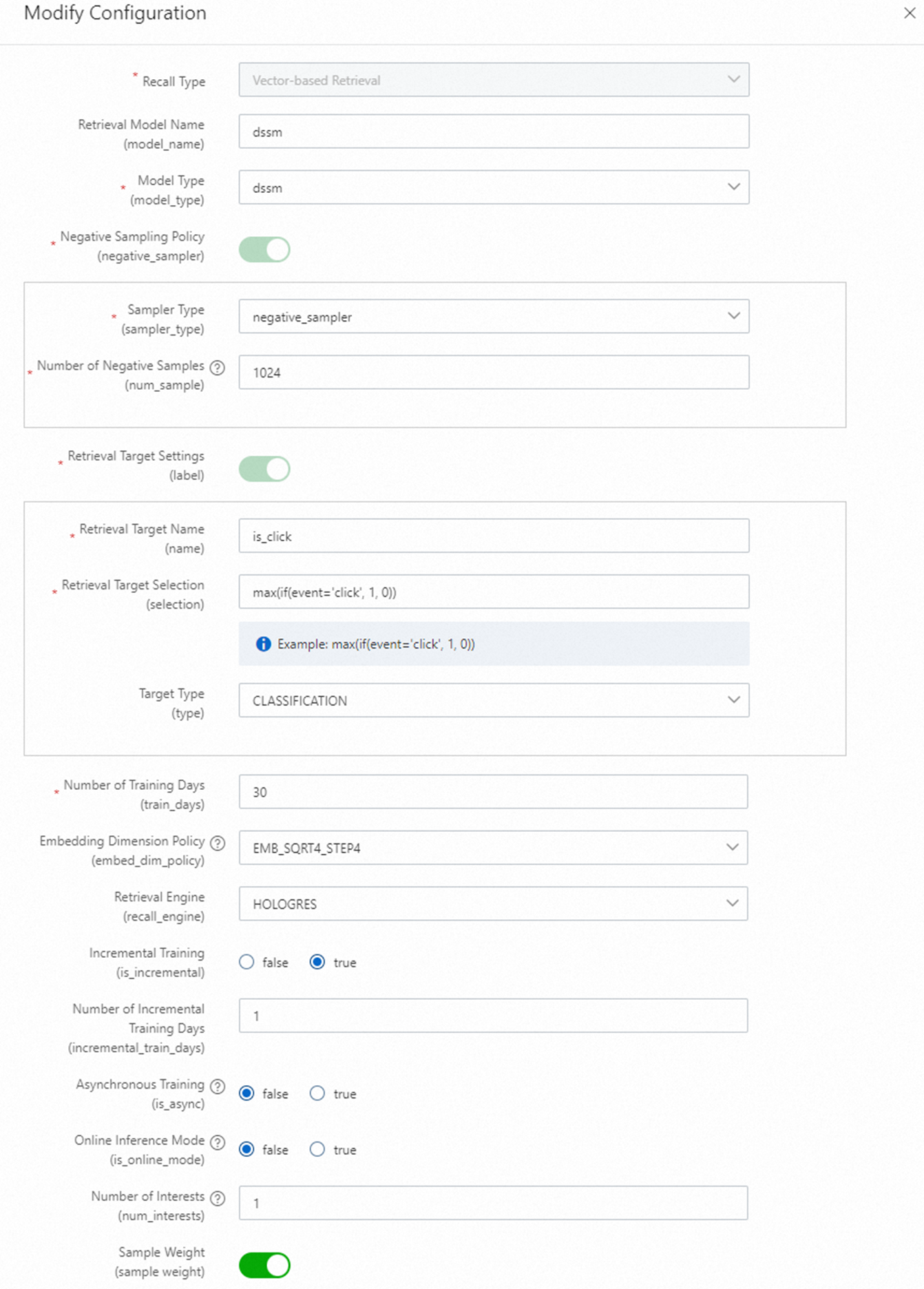
Vector recall
Dua metode recall vektor tersedia: DSSM dan MIND.
Atur target recall sebagai berikut:
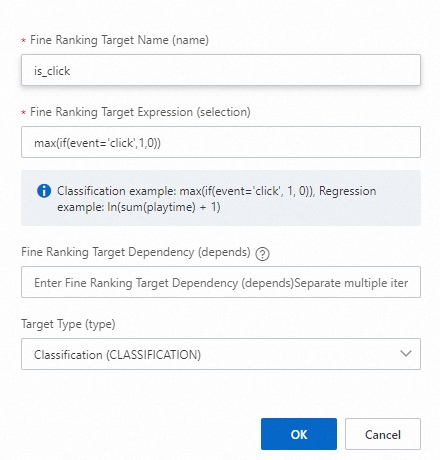
Recall target name:
is_clickRecall target selection:
max(if(event='click', 1, 0))
SQL berikut menghasilkan target recall:
select max(if(event='click',1,0)) is_click, ... from ${behavior_table} where dt between ${bizdate_start} and ${bizdate_end} group by req_id, user_id, itemDi mana:
${behavior_table}: Tabel perilaku.${bizdate_start}: Tanggal mulai jendela waktu perilaku.event: Field event di tabel perilaku. Pilih nilai berdasarkan field spesifik Anda.is_click: Nama target.
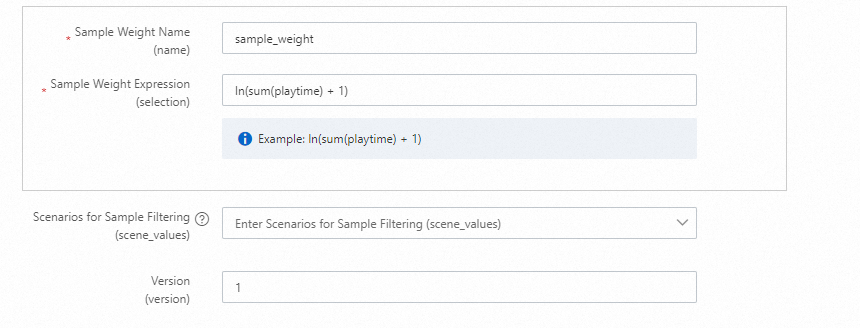
Rumus dimensi embedding:
EMB_SQRT4_STEP8: (8 + Pow(count, 0.25)) / 8) * 8 EMB_SQRT4_STEP4: (4 + Pow(count, 0.25)) / 4) * 4 EMB_LN_STEP8: (8 + Log(count + 1)) / 8) * 8 EMB_LN_STEP4: (4 + Log(count + 1)) / 4) * 4Gunakan fungsi Log saat jumlah nilai fitur besar.
Cold-start recall
DropoutNet adalah model recall menara ganda (menara pengguna + menara item) yang cocok untuk pengguna dan item populer, serta pengguna dan item ekor panjang dan baru. Lihat DropoutNet.
Global hot fallback recall
Global hot fallback recall berfungsi sebagai jaring pengaman: jika mesin recall utama gagal, ia mengembalikan set kandidat yang telah dihitung sebelumnya dan disimpan di Redis. Output-nya adalah satu baris data.
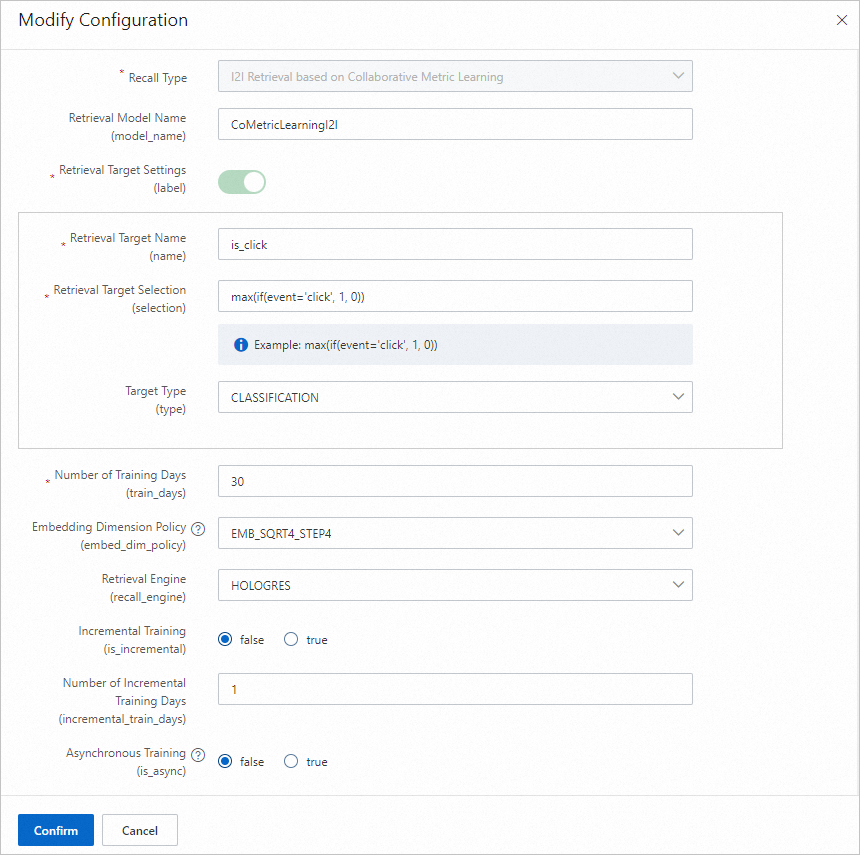
Collaborative metric learning i2i recall
Model recall Collaborative Metric Learning I2I menghitung kemiripan item berdasarkan data klik sesi.
Pada node Ranking configuration, klik Add di sebelah Fine-grained ranking, konfigurasikan parameter, klik Confirm, lalu klik Next.
PAI-Rec mendukung berbagai model peringkat. Lihat Ranking models untuk daftar lengkapnya. Berikut cara mengonfigurasi DBMTL, model peringkat multi-tujuan.
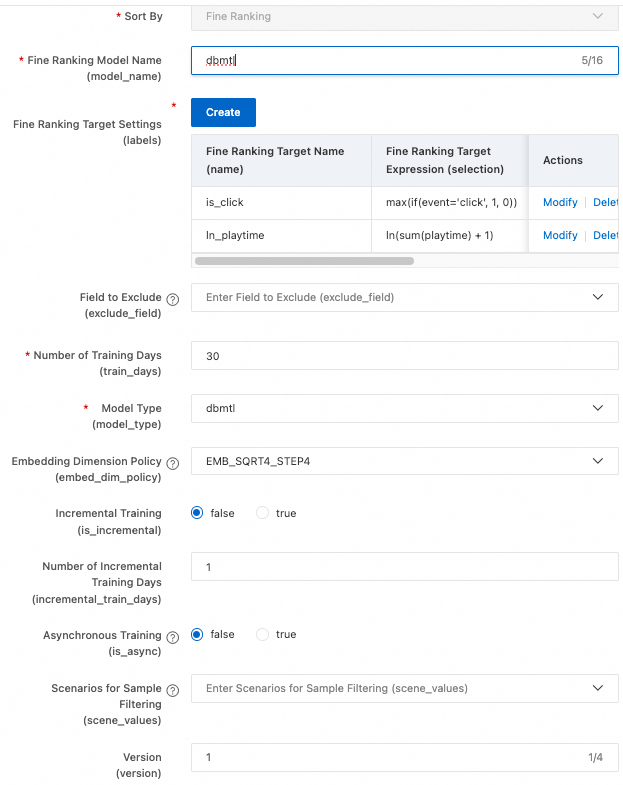
Klik Add di sebelah Refined ranking target settings (labels) dan tambahkan dua label:
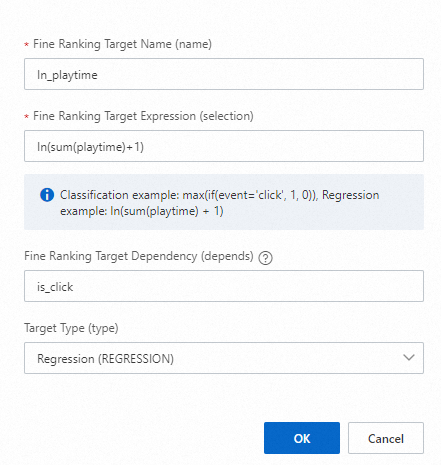
Target 1
Target 2 (huruf 'l' dalam 'ln' adalah huruf L kecil)
Pada node Generate script, klik Generate deployment script.
PentingSetelah skrip dihasilkan, sistem menghasilkan alamat OSS tempat semua file penyebaran disimpan. Simpan alamat ini secara lokal—Anda akan membutuhkannya jika menerapkan secara manual melalui Migration Assistant.
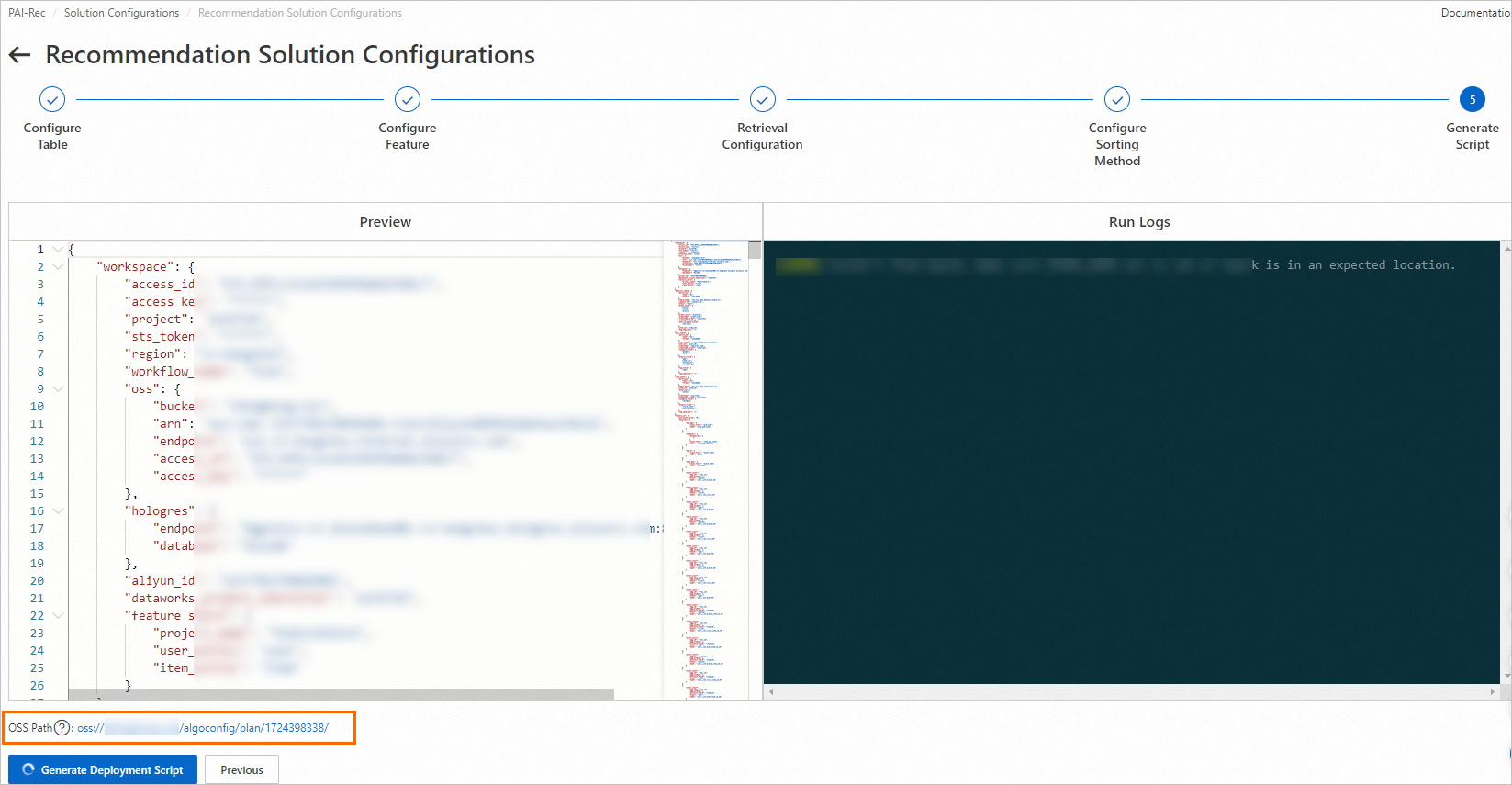
Setelah pembuatan skrip selesai, klik OK di kotak dialog. Anda akan diarahkan ke Custom recommendation solution > Deployment records. Jika pembuatan gagal, tinjau log eksekusi, perbaiki error, lalu hasilkan ulang skrip.
Langkah 6: Terapkan solusi rekomendasi
Setelah skrip dihasilkan, terapkan ke DataWorks menggunakan salah satu dari dua metode.
Metode 1: Terapkan melalui Personalized Recommendation Platform
Klik Go to deploy di sebelah solusi target.
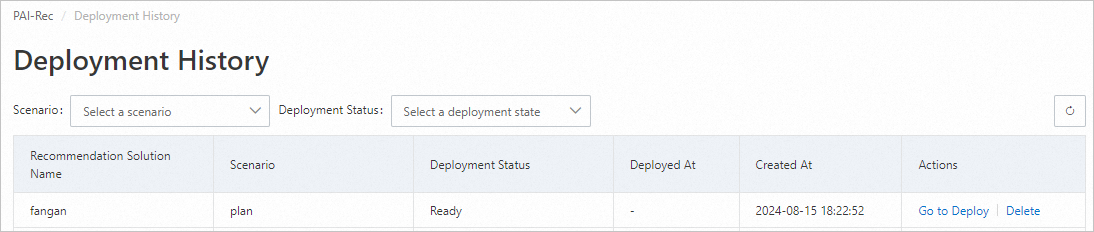
Pada halaman Deployment preview, di bagian File diff, pilih file yang akan diterapkan. Untuk penerapan pertama, klik Select all, lalu klik Deploy to DataWorks. Halaman akan kembali ke Deployment records, menampilkan proses penerapan sedang berlangsung.

Klik
 untuk memperbarui daftar dan memeriksa status penerapan.
untuk memperbarui daftar dan memeriksa status penerapan.Jika penerapan gagal, klik View log di kolom Actions, perbaiki error, lalu hasilkan ulang dan terapkan kembali skrip.
Ketika Deployment status berubah menjadi Success, skrip telah diterapkan. Buka halaman Pengembangan Data DataWorks untuk melihat kode yang diterapkan. Lihat Panduan proses pengembangan data.
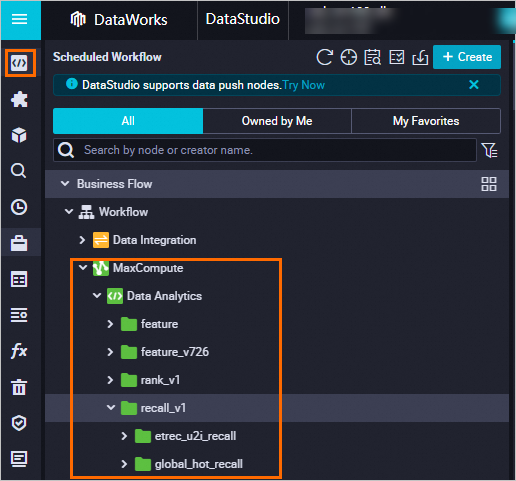
Jalankan pengisian ulang data untuk mengisi data historis guna pelatihan.
Pada halaman Deployment records, klik Details di sebelah solusi yang berhasil diterapkan.
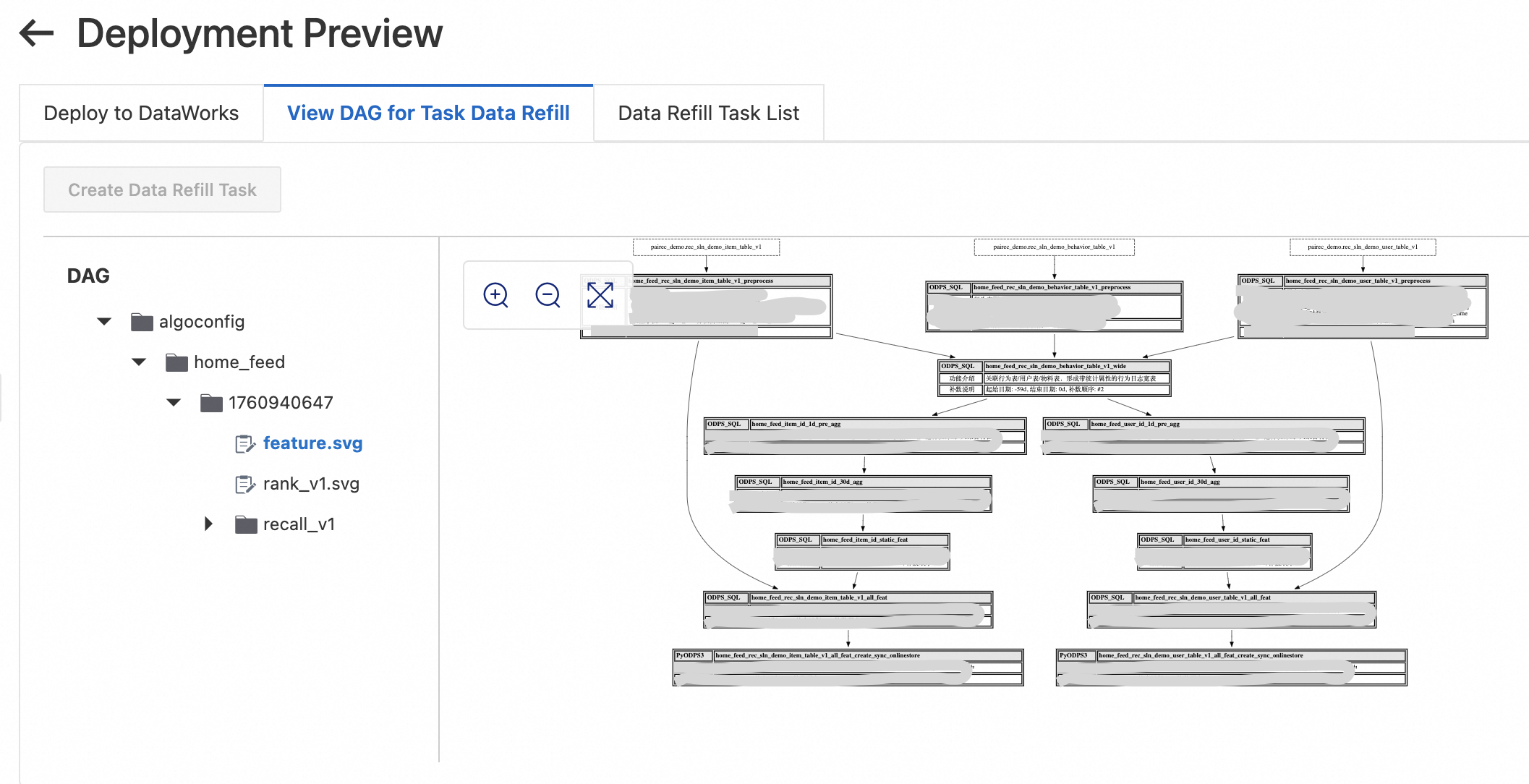
Pada halaman Deployment preview, klik View task data backfill process untuk meninjau instruksi pengisian ulang data dan memastikan integritas data.
Konfirmasi bahwa tabel pengguna, tabel item, dan tabel perilaku semuanya berisi data untuk _n_ hari terakhir, di mana _n_ sama dengan jumlah jendela waktu pelatihan dan jendela waktu fitur maksimum. Jika Anda menggunakan data demo dari tutorial ini, sinkronkan partisi data terbaru. Jika Anda menghasilkan data dengan skrip Python, lakukan pengisian ulang melalui Operation center DataWorks.
Klik Create deployment task. Di bawah Backfill task list, klik Start tasks sequentially. Tunggu hingga semua tugas berhasil selesai. Jika suatu tugas gagal, klik Details untuk melihat log, perbaiki kesalahan tersebut, jalankan ulang tugasnya, lalu klik Continue untuk melanjutkan.
Metode 2: Terapkan menggunakan Migration Assistant
Setelah skrip dihasilkan, terapkan secara manual melalui DataWorks Migration Assistant. Untuk instruksi lengkap, lihat Buat dan lihat tugas impor DataWorks. Parameter utamanya adalah:
Import name: Atur sesuai petunjuk di konsol.
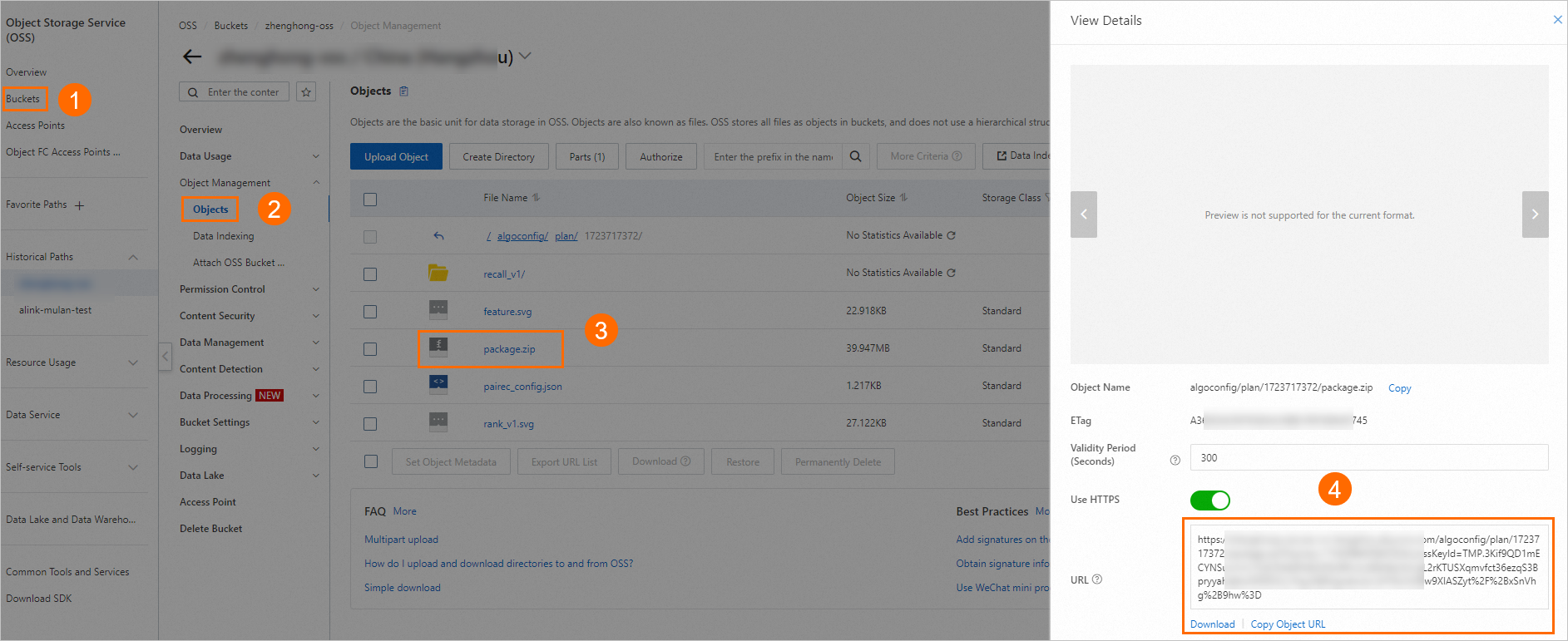
Upload method: Pilih OSS file, masukkan OSS link dari Langkah 5, lalu klik Verify.
Paket penyebaran disimpan di alamat OSS yang dihasilkan di Langkah 5, misalnya: oss://examplebucket/algoconfig/plan/1723717372/package.zip. Masuk ke Konsol OSS untuk mengambil URL file.
Langkah 7: Bekukan node
Tutorial ini menggunakan data demo. Setelah pengisian ulang data selesai, bekukan tiga node virtual yang dibuat di Langkah 2 untuk mencegahnya berjalan sesuai jadwal harian.
Di Operation center DataWorks, pilih Periodic task O&M > Periodic tasks. Cari nama node (misalnya, rec_sln_demo_user_table_v1), pilih node target (Ruang Kerja.Nama node), lalu pilih Pause (Freeze).